YOLOv8模型调试记录
前言
新年伊始,ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。
值得一提的是,在博主的印象中,YOLO系列都是完成目标检测方面的任务,而YOLOv8中还可进行分类与语义分割任务。
无论哪个YOLOv8模型都有对应的预训练模型。目标检测和分割模型是在 COCO 数据集上预训练的,而分类模型是在 ImageNet 数据集上预训练的。大家只需要下载对应模型即可。
前期准备
首先我们需要下载其源代码:
https://github.com/ultralytics/ultralytics
随后我们使用Pycharm打开下载后的文件。
创建conda环境:conda create -n yolov8 python=3.8
在Pycharm中为项目选择conda环境
安装依赖
随后在我们的pycharm的Terminal中安装所需环境:
这里由于博主将控制台改为了Linux系统的形式,大家使用windows命令即可。
source activate yolov8 Linux下激活
activate yolov8 Windows下激活

对于使用Pycharm连接远程服务器的安装方式,可以先激活conda环境,然后再切换到对应的文件目录下再执行安装命令:

安装所需依赖包:
pip install -r requirements.txt -i https://mirrors.bfsu.edu.cn/pypi/web/simple/
安装成功了,在setting中会显示出来。
注意:其默认下载最新版的,该版本中pytorch下载的为1.13,由于博主没有与之对应的conda环境,导致只能使用CPU进行运行,因此博主需要自己再手动安装一下,大家按照自己所需的即可。
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
简单测试
首先使用他自带的权重文件进行检测测试。
下载权重文件:
https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt
方法一
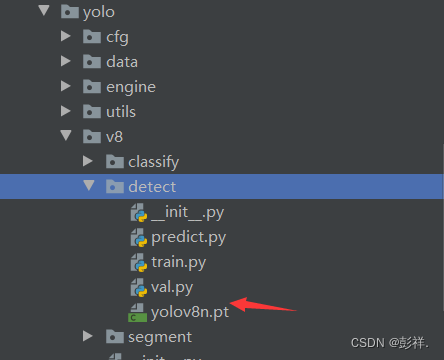
这里虽然在运行时会自动下载,但有时却容易出错,我们手动下载即可,下载完成后将其放入ultralytics-main\ultralytics\yolo\v8\detect\yolov8n.pt目录:同时运行该文件下的predict文件。
运行成功,结果保存在下图箭头所指示的文件夹中:
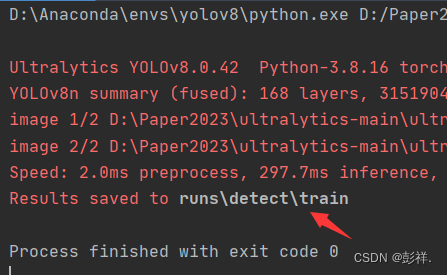
查看运行结果:总体而言相比较博主原本的模型要强一些。

方法二
在该项目的readme中提到,可以使用一下命令在控制台进行执行
yolo predict model=yolov8n.pt source="https://ultralytics.com/images/bus.jpg"
但这个前提是需要安装:ultralytics
pip install ultralytics
使用自制数据集进行训练
博主的数据集使用的时cadc数据集,其标注方式为VOC格式,我们需要将其转换为yolo格式,并对其进行划分训练集,验证集,测试集。这里我们一定要将其转换为官方格式,避免出错。
注意:大家尽量按照我的这个步骤来进行数据集制作,否则在进行训练时会报错:
FileNotFoundError: train: No labels found in data\labels.cache, can
not start training.
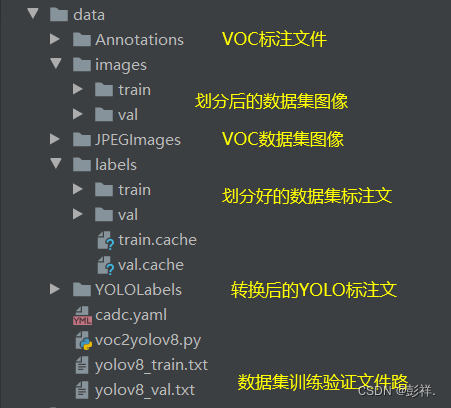
博主首先来讲一下流程,首先我们需要得到VOC数据集的图像与标注文件,随后我们要将该数据集的标注文件格式转换为YOLO标准格式,随后我们将对数据集进行划分,将图片保存在images中,将标注文件放在labels中,train与val文件夹内的文件分别对应训练集与验证集。
按照上面的说法,我们在使用时只需要给出Annotations和JPEGImage文件夹即可。其余的文件都是通过voc2yolo8.py文件生成的。
完成后的文件目录格式如下:
我们将使用voc2yolo文件来执行该过程:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile# 根据自己的数据标签修改
classes=['car', 'truck', 'bus', 'person']def clear_hidden_files(path):dir_list = os.listdir(path)for i in dir_list:abspath = os.path.join(os.path.abspath(path), i)if os.path.isfile(abspath):if i.startswith("._"):os.remove(abspath)else:clear_hidden_files(abspath)def convert(size, box):dw = 1./size[0]dh = 1./size[1]x = (box[0] + box[1])/2.0y = (box[2] + box[3])/2.0w = box[1] - box[0]h = box[3] - box[2]x = x*dww = w*dwy = y*dhh = h*dhreturn (x,y,w,h)def convert_annotation(image_id):in_file = open('D:/Paper2023/ultralytics-main/ultralytics-main/data/Annotations/%s.xml' %image_id)out_file = open('D:/Paper2023/ultralytics-main/ultralytics-main/data/YOLOLabels/%s.txt' %image_id, 'w')tree=ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):#difficult = obj.find('difficult').textcls = obj.find('name').text#if cls not in classes or int(difficult) == 1:#continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))bb = convert((w,h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')in_file.close()out_file.close()wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "")
print(data_base_dir)
if not os.path.isdir(data_base_dir):os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "")
if not os.path.isdir(work_sapce_dir):os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)train_file = open(os.path.join(wd, "yolov8_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov8_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov8_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov8_val.txt"), 'a')
print(image_dir)
list_imgs = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("1Probobility: %d" % probo)
print(list_imgs)
for i in range(0,len(list_imgs)):path = os.path.join(image_dir,list_imgs[i])if os.path.isfile(path):image_path = image_dir + list_imgs[i]voc_path = list_imgs[i](nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))annotation_name = nameWithoutExtention + '.xml'annotation_path = os.path.join(annotation_dir, annotation_name)label_name = nameWithoutExtention + '.txt'label_path = os.path.join(yolo_labels_dir, label_name)probo = random.randint(1, 100)print("2Probobility: %d" % probo)if(probo < 80): # train datasetif os.path.exists(annotation_path):train_file.write(image_path + '\n')convert_annotation(nameWithoutExtention) # convert labelcopyfile(image_path, yolov5_images_train_dir + voc_path)copyfile(label_path, yolov5_labels_train_dir + label_name)else: # test datasetif os.path.exists(annotation_path):test_file.write(image_path + '\n')convert_annotation(nameWithoutExtention) # convert labelcopyfile(image_path, yolov5_images_test_dir + voc_path)copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
只需要修改代码中的路径就OK了。
随后还要创建一个yaml配置文件,给出我们数据集路径与数据集相关信息
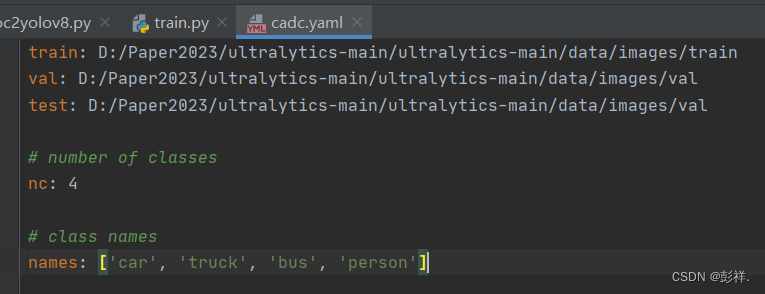
开始训练
找到train.py文件,修改下图中框选的部分即可,分别为权重文件与数据集配置文件。

此外,关于batch-size,epoch等参数的配置在cfg文件夹下的default文件中。
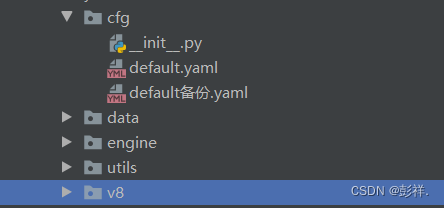
修改完成后运行train.py即可。
值得一提的是,在本地的环境配置中要求pytorch和cuda ,cudnn相对应,而在安装时容易出问题,而在服务器上安装时,却十分轻松。
至于连接远程服务器的调试也是如法炮制。

训练完成:
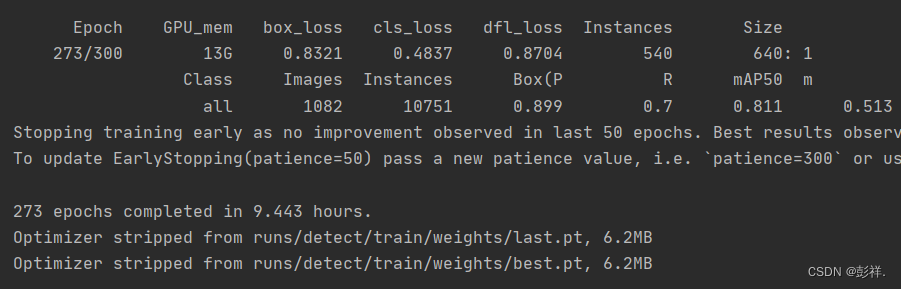
验证结果:
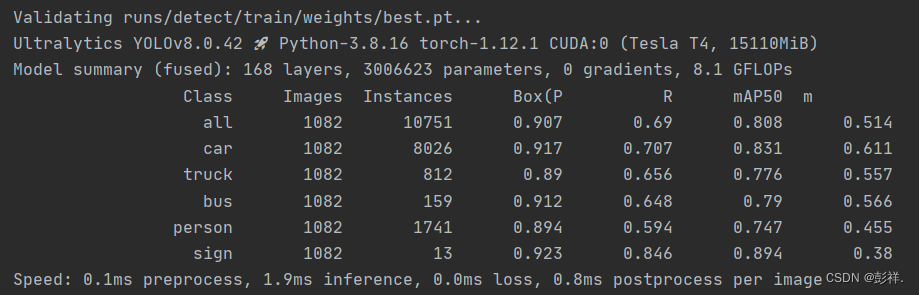
推理结果:

以上便是YOLOv8的调试训练与推理过程,接下来博主还会对YOLOv8相关模型进行学习,以期进行模型修改。
此外,最后在运行完成时转换结果(将csv作图)时出现错误:这个无伤大雅,不用理会。
File "/home/ubuntu/.conda/envs/yolov8/lib/python3.8/site-packages/matplotlib/pyplot.py", line 208, in _get_backend_modswitch_backend(rcParams._get("backend"))File "/home/ubuntu/.conda/envs/yolov8/lib/python3.8/site-packages/matplotlib/pyplot.py", line 331, in switch_backendmanager_pyplot_show = vars(manager_class).get("pyplot_show")
TypeError: vars() argument must have __dict__ attribute
相关文章:
YOLOv8模型调试记录
前言 新年伊始,ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。 值得一提的是,在博主的印象中,YOLO系…...

算法刷题打卡第97天:删除字符串两端相同字符后的最短长度
删除字符串两端相同字符后的最短长度 难度:中等 给你一个只包含字符 a,b 和 c 的字符串 s ,你可以执行下面这个操作(5 个步骤)任意次: 选择字符串 s 一个 非空 的前缀,这个前缀的所有字符都相…...
---使用IndexBuffer(索引缓冲区))
WebGPU学习(3)---使用IndexBuffer(索引缓冲区)
现在让我们将 IndexBuffer 与 VertexBuffer 一起使用。演示示例 1.准备索引数据 我们用 Uint16Array 类型来准备索引数据。我们将矩形的4个点放到 VertexBuffer 中,然后根据三角形绘制顺序,组织成 0–1–2 和 0–2–3 的结构。 const quadIndexArray …...

Java代码加密混淆工具有哪些?
在Java中,代码加密混淆工具可以帮助开发者将源代码进行加密和混淆处理,以增加代码的安全性和保护知识产权。以下是一些流行的Java代码加密混淆工具: 第一款:ProGuard:ProGuard ProGuard:ProGuard…...
 | 机试题+算法思路+考点+代码解析 【2023】)
华为OD机试 - 高效的任务规划(Python) | 机试题+算法思路+考点+代码解析 【2023】
高效的任务规划 题目 你有 n 台机器编号为1-n,每台都需要完成一项工作, 机器经过配置后都能独立完成一项工作。 假设第i台机器你需要花 Bi 分钟进行设置, 然后开始运行,Ji分钟后完成任务。 现在,你需要选择布置工作的顺序,使得用最短的时间完成所有工作。 注意,不能同…...

ChatGPT写程序如何?
前言ChatGPT最近挺火的,据说还能写程序,感到有些惊讶。于是在使用ChatGPT有一周左右后,分享一下用它写程序的效果如何。1、对于矩阵,把减法操作转换加法?感觉不错的,能清晰介绍原理,然后写示例程…...
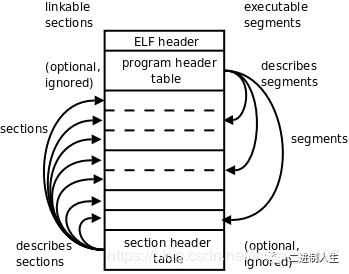
编译链接实战(9)elf符号表
文章目录符号的概念符号表探索前面介绍了elf文件的两种视图,以及两种视图的各自几个组成部分:elf文件有两种视图,链接视图和执行视图。在链接视图里,elf文件被划分成了elf 头、节头表、若干的节(section)&a…...

React合成事件的原理是什么
事件介绍 什么是事件? 事件是在编程时系统内发生的动作或者发生的事情,而开发者可以某种方式对事件做出回应,而这里有几个先决条件 事件对象 给事件对象注册事件,当事件被触发后需要做什么 事件触发 举个例子 在机场等待检票…...
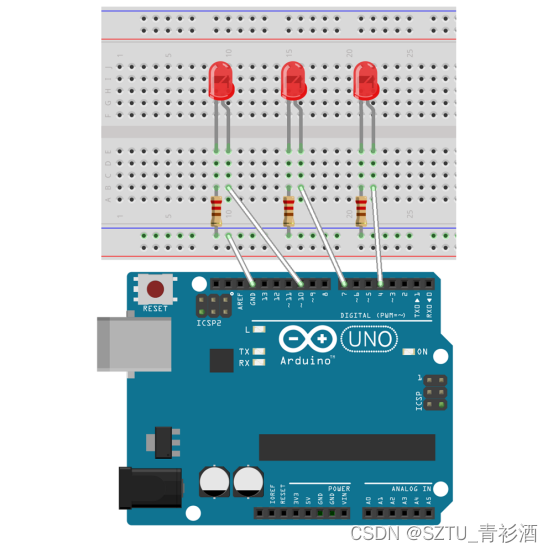
Arduino-交通灯
LED交通灯实验实验器件:■ 红色LED灯:1 个■ 黄色LED灯:1 个■ 绿色LED灯:1 个■ 220欧电阻:3 个■ 面包板:1 个■ 多彩杜邦线:若干实验连线1.将3个发光二极管插入面包板,2.用杜邦线…...
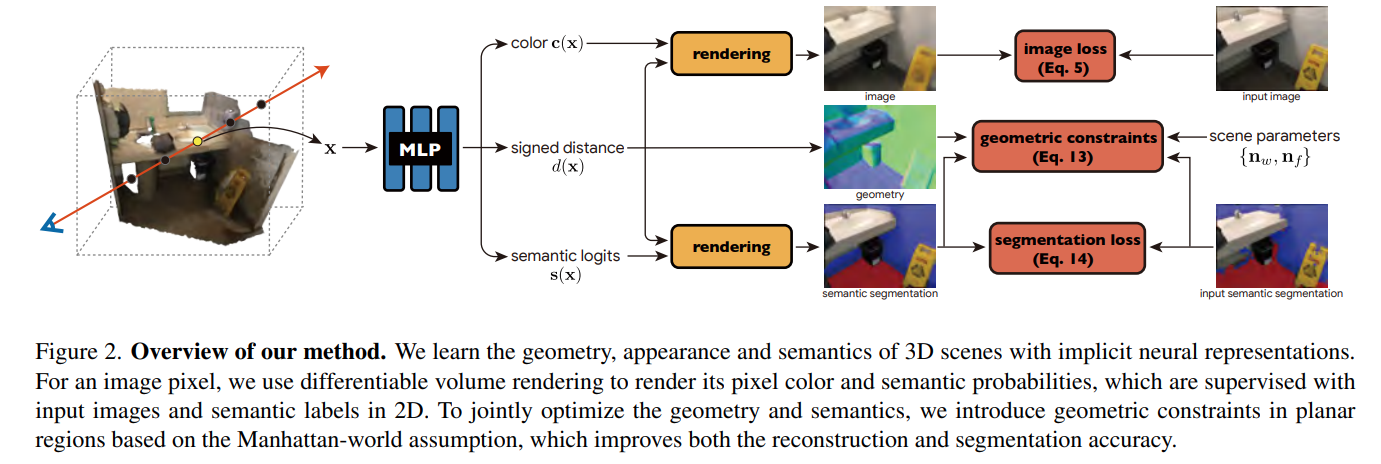
【论文笔记】Manhattan-SDF == ZJU == CVPR‘2022 Oral
Neural 3D Scene Reconstruction with the Manhattan-world Assumption 本文工作:基于曼哈顿世界假设,重建室内场景三维模型。 1.1 曼哈顿世界假设 参考阅读文献:Structure-SLAM: Low-Drift Monocular SLAM in Indoor EnvironmentsIEEE IR…...
好消息!Ellab(易来博)官方微信公众号开通了!携虹科提供专业验证和监测解决方案
自1949年以来,丹麦Ellab一直通过全球范围内的验证和监测解决方案,协助全球生命科学和食品公司优化和改进其流程的质量。Ellab全面的无线数据记录仪,热电偶系统,无线环境监测系统,校准设备,软件解决方案等等…...
想要去字节跳动面试Android岗,给你这些面试知识点
关于面试字节跳动,我总结一些面试点,希望可以帮到更多的小伙伴,由于篇幅问题这里没有把全部的面试知识点问题都放上来!!目录:1.网络2.Java 基础&容器&同步&设计模式3.Java 虚拟机&内存结构…...

Java的Lambda表达式的使用
Lambda表达式是Java 8中引入的一个重要特性,它是一种简洁而强大的语法结构,可以用于替代传统的匿名内部类。 Lambda表达式的语法结构如下: (parameters) -> expression或者 (parameters) -> { statements; }其中,paramet…...
Spring MVC 源码 - HandlerMapping 组件(三)之 AbstractHandlerMethodMapping
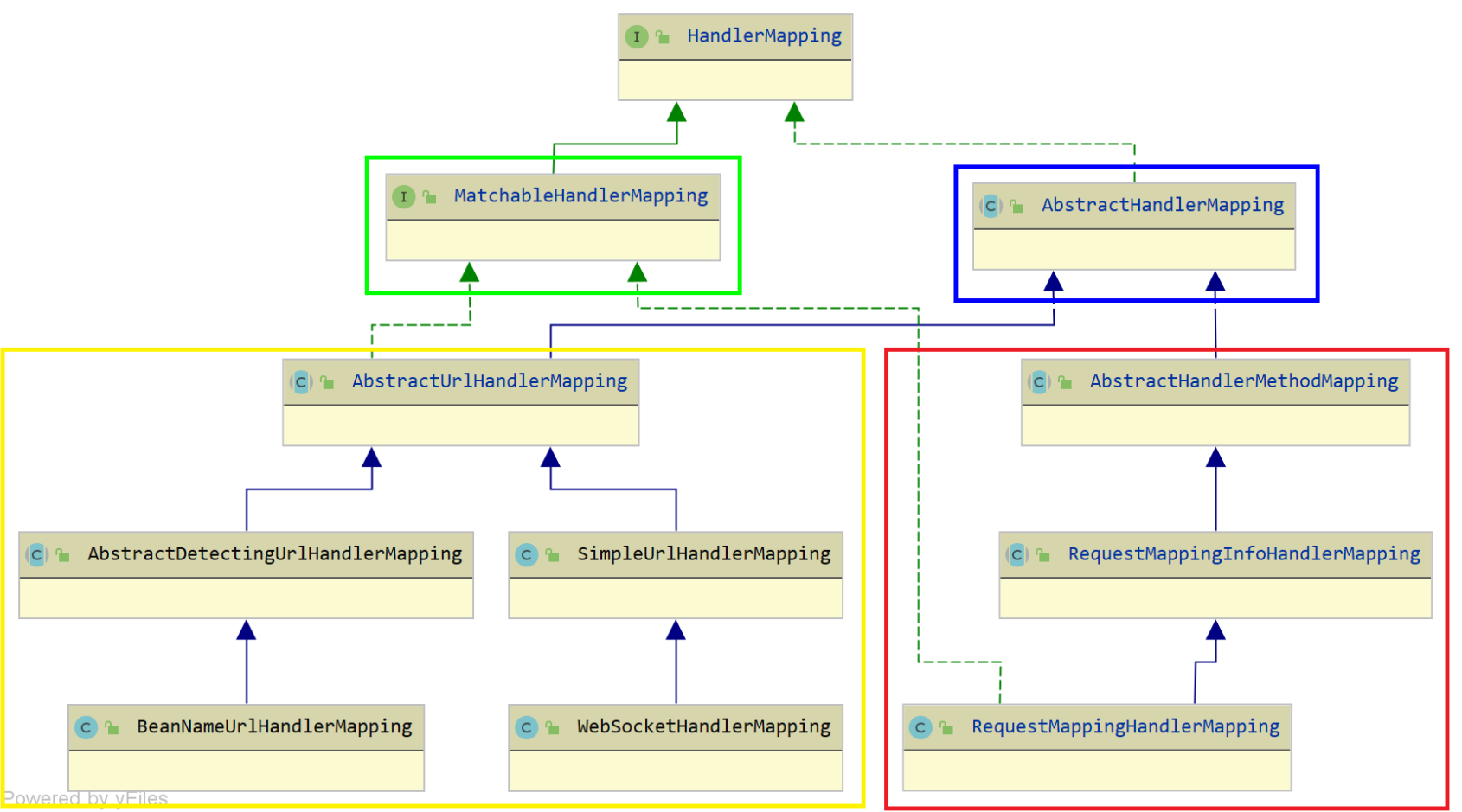
HandlerMapping 组件HandlerMapping 组件,请求的处理器匹配器,负责为请求找到合适的 HandlerExecutionChain 处理器执行链,包含处理器(handler)和拦截器们(interceptors)handler 处理器是 Objec…...

超店有数,为什么商家要使用tiktok达人进行营销推广呢?
近几年互联网发展萌生出更多的短视频平台,而tittok这个平台在海外也越来越火爆。与此同时,很多商家也开始用tiktok进行营销推广。商家使用较多的方式就是达人营销,这种方法很常见且转化效果不错。那为什么现在这么多商家喜欢用tiktok达人进行…...

【分享】订阅万里牛集简云连接器同步企业采购审批至万里牛系统
方案场景 面临着数字化转型的到来,不少公司希望实现业务自动化需求,公司内部将钉钉作为办公系统,万里牛作为ERP系统,两个系统之前的数据都储存在各自的后台,导致数据割裂,数据互不相通,人工手动…...

C++类和对象_02----对象模型和this指针
目录C对象模型和this指针1、成员变量和成员函数分开存储1.1、空类大小1.2、非空类大小1.3、结论2、this指针概念2.1、解决名称冲突2.2、在类的非静态成员函数中返回对象本身,可使用return *this2.3、拷贝构造函数返回值为引用的时候,可进行链式编程3、空…...

瑞芯微RK3568开发:烧录过程
进入rk3568这款芯片的烧录模式共有3种方式,先讲需要准备的环境要求。 一、软硬件环境 1、配套sdk版本的驱动DriverAssitant_vx.x.x和RKDevTool_Release_vx.x,版本不对应可能无法烧录,建议直接在sdk压缩包里获取; 2、如果正确安…...

【数据结构】——树和二叉树的概念
目录 1.树概念及结构 1.1树的概念 1.2 树的相关性质 1.3 树的表示 1.4 树在实际中的运用(表示文件系统的目录树结构) 2.二叉树概念及结构 2.1二叉树概念 2.2 特殊的二叉树 2.3 二叉树的性质 1.树概念及结构 1.1树的概念 树是一种非线性的数据结构…...

Meta分析在生态环境领域里的应用
Meta分析(Meta Analysis)是当今比较流行的综合具有同一主题的多个独立研究的统计学方法,是较高一级逻辑形式上的定量文献综述。20世纪90年代后,Meta分析被引入生态环境领域的研究,并得到高度的重视和长足的发展&#x…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...
)
Claude服务治理架构升级(生产环境零停机迁移实录)
更多请点击: https://codechina.net 第一章:Claude服务治理架构升级(生产环境零停机迁移实录) 为应对日益增长的推理请求量与多租户策略精细化需求,我们对Claude服务治理层实施了从单体API网关向云原生服务网格的平滑…...

Balena Etcher:跨平台系统镜像安全写入的技术实现
Balena Etcher:跨平台系统镜像安全写入的技术实现 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 当你需要在不同操作系统之间部署系统镜像时&#x…...

终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签
终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 还在为满屏混乱的Chrome书…...

机器学习进化算法与新奇性搜索在暗物质模型参数空间扫描中的应用
1. 项目概述与核心挑战在粒子物理和宇宙学的前沿,寻找暗物质候选者是一场旷日持久的“寻宝”游戏。我们面对的“藏宝图”是各种理论模型,比如二重希格斯模型(2HDM)及其扩展,而“宝藏”则是那些能让模型预言与所有实验观…...