thinkphp中使用Elasticsearch 7.0进行多表的搜索
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、thinkphp中使用Elasticsearch 7.0进行多表的搜索
- 二、使用步骤
- 1.引入库
- 2.读入数据
- 总结
前言
提示:thinkphp中使用Elasticsearch 7.0进行多表的搜索:
thinkphp数据库配置文件
// Elasticsearch数据库配置信息'elasticsearch' => ['scheme' =>'http','host' => '127.0.0.1','port' => '9200','user' => '','pass' => '','timeout' => 2,],
提示:以下是本篇文章正文内容,下面案例可供参考
一、thinkphp中使用Elasticsearch 7.0进行多表的搜索
示例:thinkphp中使用Elasticsearch 7.0进行多表的搜索
二、使用步骤
1.引入库
直接上代码如下(示例):
composer require "elasticsearch/elasticsearch": "7.0.*"
2.读入数据
代码如下(示例):
namespace app\common\model;
use think\facade\Db;
use think\Model;
use Elasticsearch\ClientBuilder;
class Article extends Model
{protected $client;public function __construct($data = []){parent::__construct($data);try { $this->client = ClientBuilder::create()->setHosts([config('database.connections.elasticsearch.host') . ':' . config('database.connections.elasticsearch.port')])->build();} catch (\Exception $e) {// 输出连接错误信息echo $e->getMessage();exit;}}// 添加文档到Elasticsearchpublic function addDocument(){$articles = Db::name('article')->select();foreach ($articles as $article) {$data = ['id' => $article['id'], // 文章表的 ID'title' => $article['title'],'content' => $article['content'],'category_id' => $article['category_id'], // 文章表的 ID];$params = ['index' => 'articles', // 索引名称'id' => $data['id'], // 文章 ID 作为文档的唯一标识'body' => $data,];$response = $this->client->index($params);}return $response;}// 搜索文档public function searchDocuments($index,$query){$params = ['index' => $index,'body' => ['query' => ['multi_match' => ['query' => $query,'fields' => ['title', 'content'],],],],];$response = $this->client->search($params);return $response;}
}
<?php
/*** Created by PhpStorm.* User: wangkxin@foxmail.com* Date: 2023/9/2* Time: 17:55*/namespace app\common\model;
use think\facade\Db;
use think\Model;
use Elasticsearch\ClientBuilder;class Book extends Model
{protected $client;public function __construct($data = []){parent::__construct($data);try {// $host = config('database.connections.elasticsearch.host');// $port = config('database.connections.elasticsearch.port');$this->client = ClientBuilder::create()->setHosts([config('database.connections.elasticsearch.host') . ':' . config('database.connections.elasticsearch.port')])->build();} catch (\Exception $e) {// 输出连接错误信息echo $e->getMessage();exit;}}// 添加文档到Elasticsearchpublic function addDocument(){$books = Db::name('book')->select();foreach ($books as $book) {$data = ['id' => $book['id'], // 书籍表的 ID'user_id' => $book['user_id'], // 书籍表作者ID'book' => $book['book'],];$params = ['index' => 'books', // 索引名称'id' => $data['id'], // 文章 ID 作为文档的唯一标识'body' => $data,];$response = $this->client->index($params);}return $response;}// 搜索文档public function searchDocuments($index,$query){$params = ['index' => $index,'body' => ['query' => ['multi_match' => ['query' => $query,'fields' => ['book'],],],],];$response = $this->client->search($params);return $response;}
}
<?php
/*** Created by PhpStorm.* User: wangkxin@foxmail.com* Date: 2023/9/2* Time: 15:27* 全局搜素模型*/namespace app\common\model;use think\Model;
use Elasticsearch\ClientBuilder;class ElasticsearchModel extends Model
{protected $client;public function __construct($data = []){parent::__construct($data);try {$this->client = ClientBuilder::create()->setHosts([config('database.connections.elasticsearch.host') . ':' . config('database.connections.elasticsearch.port')])->build();} catch (\Exception $e) {// 输出连接错误信息echo $e->getMessage();exit;}}public function globalSearch($keyword){// 搜索articles索引$articles = $this->searchIndex('articles', $keyword);// 搜索books索引$books = $this->searchIndex('books', $keyword);// 合并搜索结果$result = array_merge($articles, $books);return $result;}protected function searchIndex($index, $keyword){$params = ['index' => $index,'body' => ['query' => ['multi_match' => ['query' => $keyword,'fields' => ['title', 'content','book'],],],],];// 执行搜索请求$response = $this->client->search($params);// 解析结果$result = [];if (isset($response['hits']['hits'])) {foreach ($response['hits']['hits'] as $hit) {$result[] = $hit['_source'];$result['index'] = $index;}}return $result;}}
<?php
/*** Created by PhpStorm.* User: wangkxin@foxmail.com* Date: 2023/9/2* Time: 18:53*/namespace app\index\controller;use app\common\model\ElasticsearchModel;class SearchController
{//全局搜索个表间的数据public function search($keyword){$searchModel = new ElasticsearchModel();$result = $searchModel->globalSearch($keyword);return json($result);}
}
namespace app\index\controller;
use app\BaseController;
use app\common\model\Article as ElasticArticle;
use app\common\model\Book as ElasticBook;
use app\Request;
use Elasticsearch\ClientBuilder;class Demo1 extends BaseController
{
//新增索引,建议在模型中新增 ,删除, 修改 或者使用观察者模式更新ES索引public function addDocument(){$elasticsearchArticle = new ElasticArticle();$response = $elasticsearchArticle->addDocument();$elasticsearchBook = new ElasticBook();$response1 = $elasticsearchBook->addDocument();return json($response);// print_r(json($response));// print_r(json($response1));}/*** 单独搜索文章表例子*/public function search(Request $request){$keyword = $request->param('keyword');$elasticsearchModel = new ElasticArticle();$index = 'articles';$query = '你';$response = $elasticsearchModel->searchDocuments($index, $query);return json($response);}//单独搜搜书籍表public function searchBook(Request $request){$keyword = $request->param('keyword');$elasticsearchModel = new ElasticBook();$index = 'books';$query = '巴黎';$response = $elasticsearchModel->searchDocuments($index, $query);return json($response);}public function deleteIndex(){$client = ClientBuilder::create()->build();$params = ['index' => 'my_index', // 索引名称];$response = $client->indices()->delete($params);if ($response['acknowledged']) {return '索引删除成功';} else {return '索引删除失败';}}}
使用的表
CREATE TABLE `article` (`id` int(11) NOT NULL AUTO_INCREMENT,`category_id` int(11) DEFAULT NULL,`title` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,`content` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=107 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;CREATE TABLE `book` (`id` int(11) NOT NULL AUTO_INCREMENT,`user_id` int(11) DEFAULT NULL,`book` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=21 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;CREATE TABLE `elasticsearch_model` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`model_name` varchar(255) NOT NULL DEFAULT '' COMMENT '模型名称',`index_name` varchar(255) NOT NULL DEFAULT '' COMMENT '索引名称',`created_time` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',`updated_time` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',PRIMARY KEY (`id`),UNIQUE KEY `index_name_unique` (`index_name`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COMMENT='Elasticsearch 模型配置表';结果


windwos 上记住 安装 Elasticsearch 7.0 库, 和 kibana-7.0.0-windows-x86_64 图像管理工具



总结
提示:这是简单例子, 注意’fields’ => [‘title’, ‘content’], 尝试使用搜索number型字段,索引报错, 貌似只支持txt类型字段搜索
例如:以上就是今天要讲的内容,本文仅仅简单介绍了Elasticsearch的使用
相关文章:
thinkphp中使用Elasticsearch 7.0进行多表的搜索
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、thinkphp中使用Elasticsearch 7.0进行多表的搜索二、使用步骤1.引入库2.读入数据 总结 前言 提示:thinkphp中使用Elasticsearch 7.0进行多表的…...

说说 TCP的粘包、拆包
分析&回答 拆包和粘包是在socket编程中经常出现的情况, 在socket通讯过程中,如果通讯的一端一次性连续发送多条数据包,tcp协议会将多个数据包打包成一个tcp报文发送出去,这就是所谓的粘包。如果通讯的一端发送的数据包超过一…...

PowerToys安装
PowerToys 是微软开发者开发的免费实用工具集,可以用于高级用户调整和简化 Windows 操作,以提高效率。 官网安装方法: https://learn.microsoft.com/zh-cn/windows/powertoys/install 目前安装文件路径: https://github.com/m…...
Unity——LitJSON的安装
一、LitJSON介绍 特点 LitJSON是一个轻量级的C# JSON库,用于在Unity游戏开发中进行JSON数据的序列化和反序列化操作。它提供了简单而高效的接口,帮助开发者处理JSON数据。 以下是LitJSON库的一些主要特点和功能: 1. 高性能:Lit…...

YOLOv5:对yolov5n模型进一步剪枝压缩
YOLOv5:对yolov5n模型进一步剪枝压缩 前言前提条件相关介绍具体步骤修改yolov5n.yaml配置文件单通道数据(黑白图片)修改models/yolo.py文件修改train.py文件 剪枝后模型大小 参考 前言 由于本人水平有限,难免出现错漏,…...
:Pandas的基础应用详解(五))
大数据(八):Pandas的基础应用详解(五)
专栏介绍 结合自身经验和内部资料总结的Python教程,每天3-5章,最短1个月就能全方位的完成Python的学习并进行实战开发,学完了定能成为大佬!加油吧!卷起来! 全部文章请访问专栏:《Python全栈教程(0基础)》 再推荐一下最近热更的:《大厂测试高频面试题详解》 该专栏对…...
【算法】归并排序 详解
归并排序 详解 归并排序代码实现1. 递归版本2. 非递归版本 排序: 排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性: 假定在待排序的记录序列中,存在多个具有相…...

linux 进程隔离Namespace 学习
一、linux namespace 介绍 1.1、概念 Linux Namespace是Linux内核提供的一种机制,它用于隔离不同进程的资源视图,使得每个进程都拥有独立的资源空间,从而实现进程之间的隔离和资源管理。 Linux Namespace的设计目标是为了解决多个进程之间…...
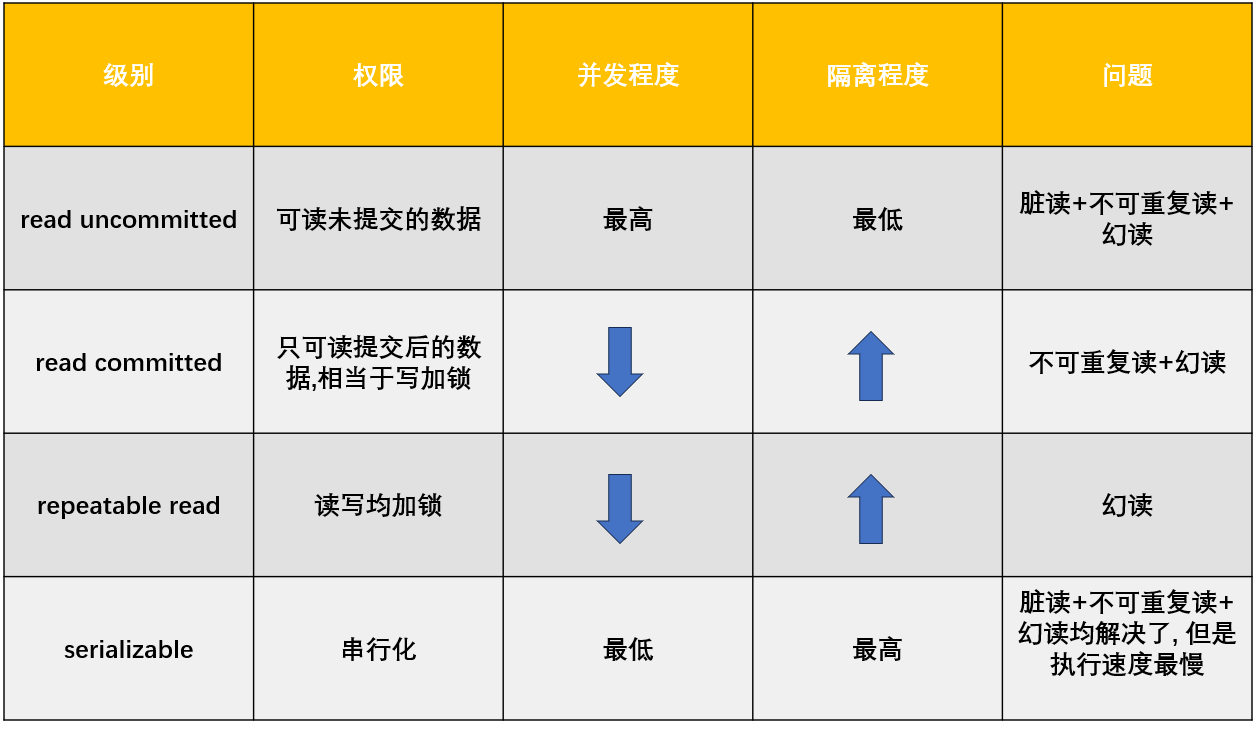
【MySQL】事务 详解
事务 详解 一. 为什么使用事务二. 事务的概念三. 使用四. 事务的特性原子性(Atomicity)一致性(Consistency)隔离性(Isolation)持久性(Durability) 五. 事务并发所带来的问题脏读问题…...

爬虫到底难在哪里?
目录 爬虫到底难在哪里 怎么学习爬虫 注意事项 爬虫工具 总结 学习Python爬虫的难易程度因人而异,对于具备编程基础的人来说,学习Python爬虫并不困难。Python语言本身比较简单易学,适合初学者使用。 爬虫到底难在哪里 爬虫的难点主要包…...

linux常用命令行整理
1、linux的以及目录 bin 二进制可执行文件sbin 二进制可执行文件(root用户权限)etc 系统管理和配置文件,例如常见host文件home 用户文件的根目录usr 用户存放系统应用程序(共享系统资源)opt 可选的应用程序proc 虚拟文件系统root 超级用户dev 存放设备文件mnt 系统管理员安装临…...

python字符串相关
python字符串相关 一、reverse() 函数 只能反转 列表二、reversed() 反转元组字符串等等 返回迭代器三、join和reversed反转字符串四、join串联字符串(join连接对象仅限字符串、储存字符串的元组、列表、字典)数字对象可通过str()转化为字符串⭐对象为字…...

JavaScript学习笔记01
JavaScript笔记01 什么是 JavaScript JavaScript 是一门世界上最流行的脚本语言,它是一种弱类型的脚本语言,其代码不需要经过编译,而是由浏览器解释运行,用于控制网页的行为。 发展历史 参考:JavaScript的起源故事…...
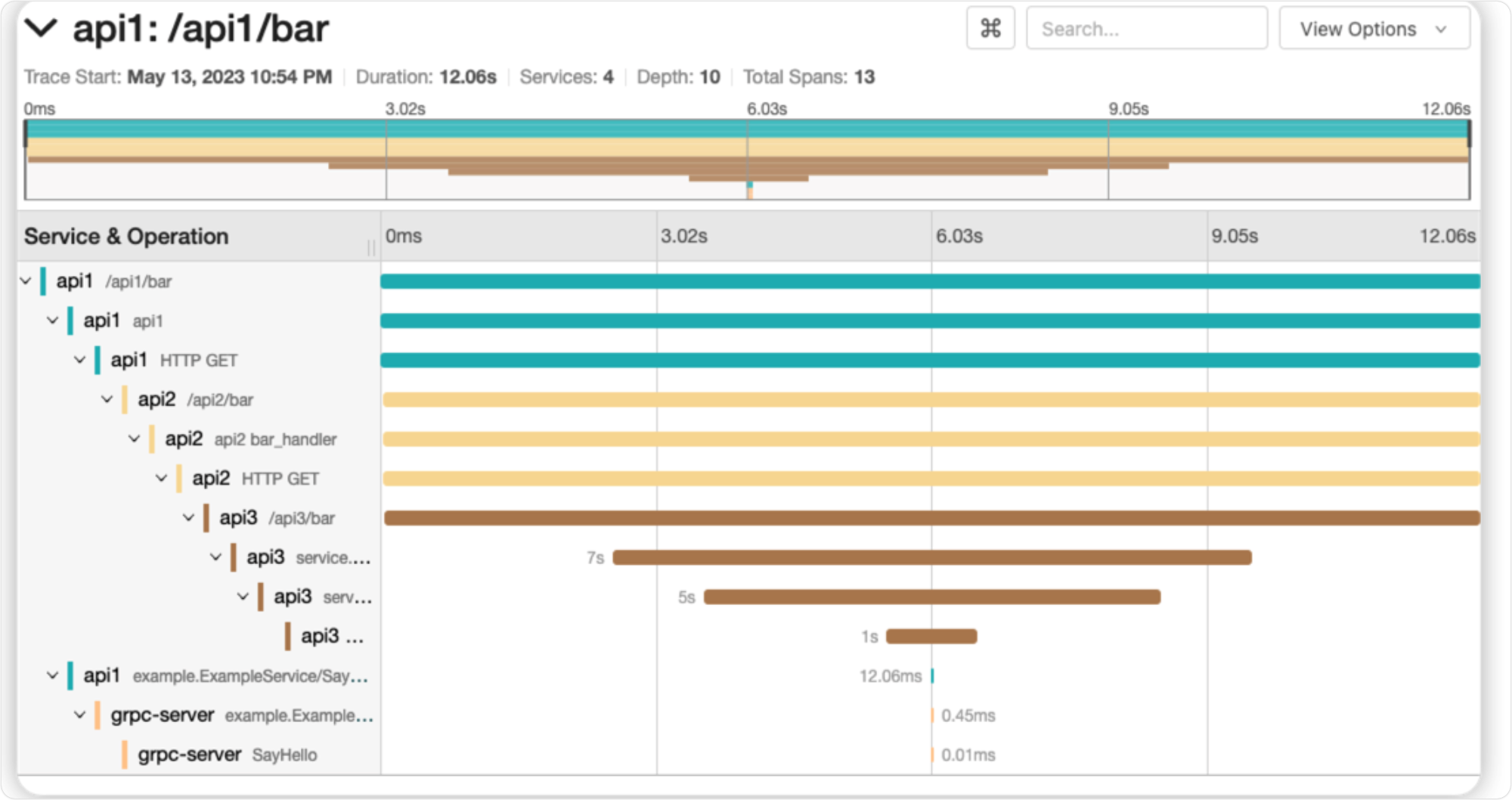
golang 通用的 grpc http 基础开发框架
go-moda golang 通用的 grpc http 基础开发框架仓库地址: https://github.com/webws/go-moda仓库一直在更新,欢迎大家吐槽和指点 特性 transport: 集成 http(echo、gin)和 grpc。tracing: openTelemetry 实现微务链路追踪pprof: 分析性能config: 通用…...
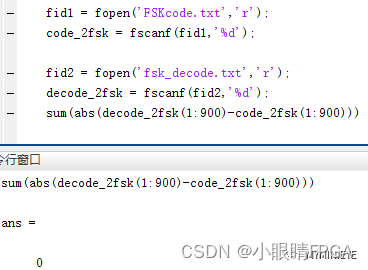
FSK解调技术的FPGA实现
本原创文章由深圳市小眼睛科技有限公司创作,版权归本公司所有,如需转载,需授权并注明出处 一、FSK信号的解调原理 FSK信号的解调也有非相干和相干两种,FSK信号可以看作是用两个频率源交替传输得到的,所以FSK的接收机由…...
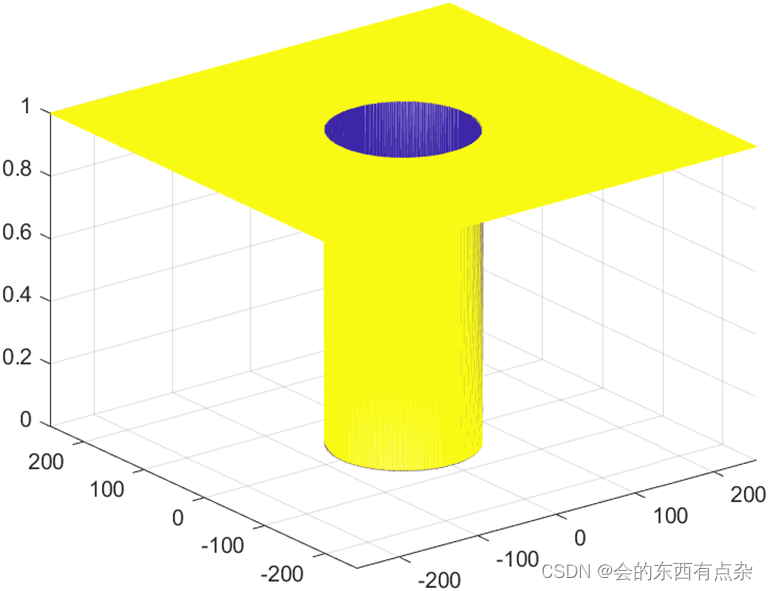
Matlab图像处理-高斯低通滤波器
高通滤波 图像的边缘、细节主要位于高频部分,而图像的模糊是由于高频成分比较弱产生的。高通滤波就是为了高消除模糊,突出边缘。因此采用高通滤波器让高频成分通过,消除低频噪声成分削弱,再经傅里叶逆变换得到边缘锐化的图像。 …...
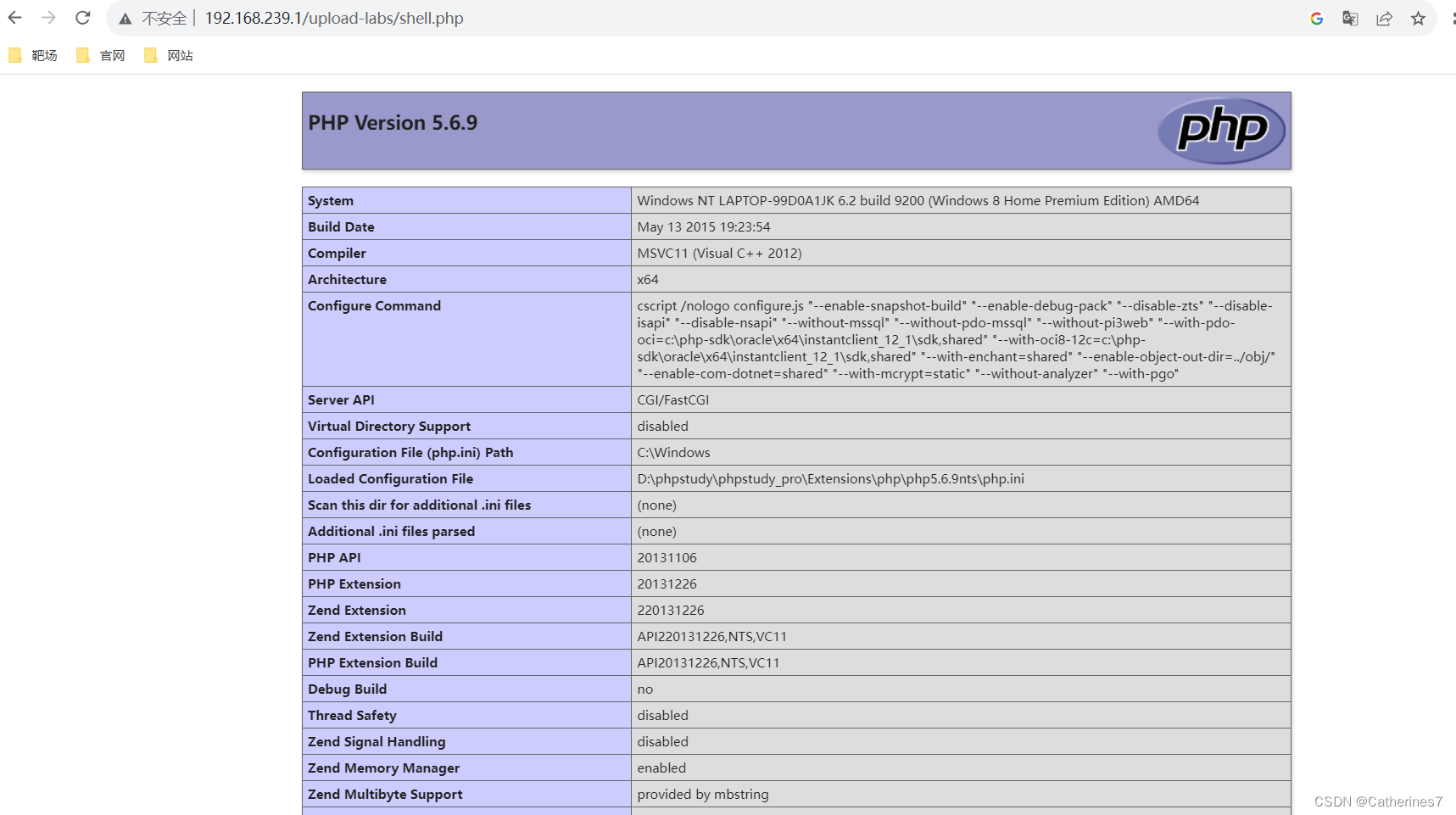
文件上传之图片马混淆绕过与条件竞争
一、图片马混淆绕过 1.上传gif imagecreatefromxxxx函数把图片内容打散,,但是不会影响图片正常显示 $is_upload false; $msg null; if (isset($_POST[submit])){// 获得上传文件的基本信息,文件名,类型,大小&…...

代码随想录二刷day16
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣104. 二叉树的最大深度二、力扣559. N 叉树的最大深度三、力扣111. 二叉树的最小深度三、力扣力扣222. 完全二叉树的节点个数 前言 一、力扣104. 二叉树…...

【开发】安防监控/视频存储/视频汇聚平台EasyCVR优化播放体验的小tips
视频云存储/安防监控EasyCVR视频汇聚平台基于云边端智能协同,可实现视频监控直播、视频轮播、视频录像、云存储、回放与检索、智能告警、服务器集群、语音对讲、云台控制、电子地图、H.265自动转码H.264、平台级联等。为了便于用户二次开发、调用与集成,…...
算法_C++—— 只出现一次的数字)
力扣(LeetCode)算法_C++—— 只出现一次的数字
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。 示例 1 : 输入࿱…...

Speechless:三步完成微博PDF备份的终极免费Chrome扩展
Speechless:三步完成微博PDF备份的终极免费Chrome扩展 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 在数字时代,我们的社交…...
:Agentic RAG——让 Agent 主导检索过程)
RAG 系列(十七):Agentic RAG——让 Agent 主导检索过程
Pipeline RAG 的沉默失败 前面十几篇一直在优化一件事:怎么让检索结果更好。更好的分块、更精准的排序、更聪明的问法、CRAG 纠偏、Graph RAG 关系遍历…… 但有一件事始终没变:无论检索结果好不好,都会被传给 LLM 生成答案。 Pipeline RAG 的流程是线性的、固定的: 问…...

从零到一:Android Studio集成Uniapp离线SDK打包实战
1. 环境准备:工具选择与版本匹配 第一次接触Uniapp离线打包时,最让我头疼的就是工具版本匹配问题。记得去年接手一个混合开发项目时,因为HBuilderX和SDK版本不兼容,整整浪费了两天时间排查问题。为了避免大家重蹈覆辙,…...

如何用nmrpflash拯救你的Netgear路由器:从“变砖“到重生的完整指南
如何用nmrpflash拯救你的Netgear路由器:从"变砖"到重生的完整指南 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器固件升级失败、意外断电或系统崩溃后无法启动…...

Hitboxer终极指南:专业级游戏键盘重映射与SOCD清理工具完全教程
Hitboxer终极指南:专业级游戏键盘重映射与SOCD清理工具完全教程 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd Hitboxer是一款专为竞技游戏玩家设计的专业级键盘按键重映射和SOCD清理工具ÿ…...

利用OCI免费套餐构建高可用Kubernetes集群实战指南
1. 项目概述:在免费云上构建企业级K8s集群最近在技术社区里,一个名为“nce/oci-free-cloud-k8s”的项目引起了我的注意。这个标题乍一看有点“黑话”的味道,但拆解开来,它指向了一个非常具体且极具吸引力的场景:利用Or…...

从零构建情感大语言模型:基于EmoLLM的实践指南
1. 项目概述:当大语言模型学会“察言观色”最近在折腾一个挺有意思的开源项目,叫SmartFlowAI/EmoLLM。光看名字你可能就猜到了,这玩意儿跟“情绪”和“大语言模型”有关。没错,它的核心目标就是让冷冰冰的LLM(Large La…...

LLVM开发实战指南:从入门到精通编译器与程序分析
1. 项目概述:为什么你需要一份LLVM指南?如果你是一名C开发者,或者对编译器、程序分析、代码优化这些底层技术感兴趣,那么“LLVM”这个名字对你来说一定不陌生。它早已不是象牙塔里的学术玩具,而是驱动着从iOS、macOS到…...

终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效
终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经因为ThinkPad风扇的"直升机起…...

AXI Crossbar设计解析:从总线互联原理到SoC集成实战
1. 项目概述:AXI Crossbar,不仅仅是“总线交叉开关”在复杂的数字系统设计,尤其是SoC(片上系统)和FPGA应用中,我们常常面临一个核心问题:多个主设备(Master,如CPU、DMA控…...