50个 Pandas 高频操作技巧,建议收藏
在数据分析和数据建模的过程中需要对数据进行清洗和整理等工作,有时需要对数据增删字段。
下面为大家介绍Pandas对数据的复杂查询、数据类型转换、数据排序、数据的修改、数据迭代以及函数的使用
文章目录
- 技术交流
- 01、复杂查询
- 1、逻辑运算
- 2、逻辑筛选数据
- 3、函数筛选
- 4、比较函数
- 5、查询df.query()
- 6、筛选df.filter()
- 02、数据类型转换
- 1、推断类型
- 2、指定类型
- 3、类型转换astype()
- 4、转为时间类型
- 03、数据排序
- 1、索引排序df.sort\_index()
- 2、数值排序sort\_values()
- 3、混合排序
- 4、按值大小排序nsmallest()和nlargest()
- 04、添加修改
- 1、修改数值
- 2、替换数据
- 3、填充空值
- 4、修改索引名
- 5、增加列
- 6、插入列df.insert()
- 7、指定列df.assign()
- 8、执行表达式df.eval()
- 9、增加行
- 10、追加合并
- 11、删除
- 12、删除空值
- 05、高级过滤
- 1、df.where()
- 2、np.where()
- 3、df.mask()
- 4、df.lookup()
- 06、数据迭代
- 1、迭代Series
- 2、df.iterrows()
- 3、df.itertuples()
- 4、df.items()
- 5、按列迭代
- 07、函数应用
- 1、pipe()
- 2、apply()
- 3、applymap()
- 4、map()
- 5、agg()
- 6、transform()
- 7、copy()
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
本文来自技术群粉丝分享整理,资料资料、数据、技术交流,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自CSDN +备注来意
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
01、复杂查询
实际业务需求往往需要按照一定的条件甚至复杂的组合条件来查询数据,接下来为大家介绍如何发挥Pandas数据筛选的无限可能,随心所欲地取用数据。
1、逻辑运算
# Q1成绩大于36
df.Q1> 36
# Q1成绩不小于60分,并且是C组成员
~(df.Q1< 60) & (df['team'] == 'C')
2、逻辑筛选数据
切片([ ])、.loc[ ]和.iloc[ ]均支持上文所介绍的逻辑表达式。
以下是切片([ ])的逻辑筛选示例:
df[df['Q1']== 8] # Q1等于8
df[~(df['Q1']== 8)] # 不等于8
df[df.name== 'Ben'] # 姓名为Ben
df[df.Q1> df.Q2]
以下是.loc[ ]和.lic[ ]示例:
# 表达式与切片一致
df.loc[df['Q1']> 90, 'Q1':] # Q1大于90,只显示Q1
df.loc[(df.Q1> 80) & (df.Q2 < 15)] # and关系
df.loc[(df.Q1> 90) | (df.Q2 < 90)] # or关系
df.loc[df['Q1']== 8] # 等于8
df.loc[df.Q1== 8] # 等于8
df.loc[df['Q1']> 90, 'Q1':] # Q1大于90,显示Q1及其后所有列
3、函数筛选
# 查询最大索引的值
df.Q1[lambdas: max(s.index)] # 值为21
# 计算最大值
max(df.Q1.index)
# 99
df.Q1[df.index==99]
4、比较函数
# 以下相当于 df[df.Q1 == 60]
df[df.Q1.eq(60)]
df.ne() # 不等于 !=
df.le() # 小于等于 <=
df.lt() # 小于 <
df.ge() # 大于等于 >=
df.gt() # 大于 > 5、查询df.query()
df.query('Q1 > Q2 > 90') # 直接写类型SQL where语句
还支持使用@符引入变量
# 支持传入变量,如大于平均分40分的
a = df.Q1.mean()
df.query('Q1 > @a+40')
df.query('Q1 > `Q2`+@a') df.eval()与df.query()类似,也可以用于表达式筛选。
# df.eval()用法与df.query类似
df[df.eval("Q1 > 90 > Q3 >10")]
df[df.eval("Q1 > `Q2`+@a")]
6、筛选df.filter()
df.filter(items=['Q1', 'Q2']) # 选择两列
df.filter(regex='Q', axis=1) # 列名包含Q的列
df.filter(regex='e$', axis=1) # 以e结尾的列
df.filter(regex='1$', axis=0) # 正则,索引名以1结尾
df.filter(like='2', axis=0) # 索引中有2的
# 索引中以2开头、列名有Q的
df.filter(regex='^2',axis=0).filter(like='Q', axis=1)
7、按数据类型查询
df.select_dtypes(include=['float64']) # 选择float64型数据
df.select_dtypes(include='bool')
df.select_dtypes(include=['number']) # 只取数字型
df.select_dtypes(exclude=['int']) # 排除int类型
df.select_dtypes(exclude=['datetime64'])
02、数据类型转换
在开始数据分析前,我们需要为数据分配好合适的类型,这样才能够高效地处理数据。不同的数据类型适用于不同的处理方法。
# 对所有字段指定统一类型
df = pd.DataFrame(data, dtype='float32')
# 对每个字段分别指定
df = pd.read_excel(data, dtype={'team':'string', 'Q1': 'int32'})
1、推断类型
# 自动转换合适的数据类型
df.infer_objects() # 推断后的DataFrame
df.infer_objects().dtypes
2、指定类型
# 按大体类型推定
m = ['1', 2, 3]
s = pd.to_numeric(s) # 转成数字
pd.to_datetime(m) # 转成时间
pd.to_timedelta(m) # 转成时间差
pd.to_datetime(m, errors='coerce') # 错误处理
pd.to_numeric(m, errors='ignore')
pd.to_numeric(m errors='coerce').fillna(0) # 兜底填充
pd.to_datetime(df[['year', 'month', 'day']])
# 组合成日期
3、类型转换astype()
df.Q1.astype('int32').dtypes
# dtype('int32')
df.astype({'Q1': 'int32','Q2':'int32'}).dtypes
4、转为时间类型
t = pd.Series(['20200801', '20200802'])
03、数据排序
数据排序是指按一定的顺序将数据重新排列,帮助使用者发现数据的变化趋势,同时提供一定的业务线索,还具有对数据纠错、分类等作用。
1、索引排序df.sort_index()
s.sort_index() # 升序排列
df.sort_index() # df也是按索引进行排序
df.team.sort_index()s.sort_index(ascending=False)# 降序排列
s.sort_index(inplace=True) # 排序后生效,改变原数据
# 索引重新0-(n-1)排,很有用,可以得到它的排序号
s.sort_index(ignore_index=True)
s.sort_index(na_position='first') # 空值在前,另'last'表示空值在后
s.sort_index(level=1) # 如果多层,排一级
s.sort_index(level=1, sort_remaining=False) #这层不排
# 行索引排序,表头排序
df.sort_index(axis=1) # 会把列按列名顺序排列
2、数值排序sort_values()
df.Q1.sort_values()
df.sort_values('Q4')
df.sort_values(by=['team', 'name'],ascending=[True, False])
其他方法:
s.sort_values(ascending=False) # 降序
s.sort_values(inplace=True) # 修改生效
s.sort_values(na_position='first') # 空值在前
# df按指定字段排列
df.sort_values(by=['team'])
df.sort_values('Q1')
# 按多个字段,先排team,在同team内再看Q1
df.sort_values(by=['team', 'Q1'])
# 全降序
df.sort_values(by=['team', 'Q1'], ascending=False)
# 对应指定team升Q1降
df.sort_values(by=['team', 'Q1'],ascending=[True, False])
# 索引重新0-(n-1)排
df.sort_values('team', ignore_index=True)
3、混合排序
df.set_index('name', inplace=True) # 设置name为索引
df.index.names = ['s_name'] # 给索引起名
df.sort_values(by=['s_name', 'team']) # 排序
4、按值大小排序nsmallest()和nlargest()
s.nsmallest(3) # 最小的3个
s.nlargest(3) # 最大的3个
# 指定列
df.nlargest(3, 'Q1')
df.nlargest(5, ['Q1', 'Q2'])
df.nsmallest(5, ['Q1', 'Q2'])
04、添加修改
数据的修改、增加和删除在数据整理过程中时常发生。修改的情况一般是修改错误、格式转换,数据的类型修改等。
1、修改数值
df.iloc[0,0] # 查询值
# 'Liver'
df.iloc[0,0] = 'Lily' # 修改值
df.iloc[0,0] # 查看结果
# 'Lily' # 将小于60分的成绩修改为60
df[df.Q1 < 60] = 60
# 查看
df.Q1 # 生成一个长度为100的列表
v = [1, 3, 5, 7, 9] * 20
2、替换数据
s.replace(0, 5) # 将列数据中的0换为5
df.replace(0, 5) # 将数据中的所有0换为5
df.replace([0, 1, 2, 3], 4) # 将0~3全换成4
df.replace([0, 1, 2, 3], [4, 3, 2, 1]) # 对应修改
s.replace([1, 2], method='bfill') # 向下填充
df.replace({0: 10, 1: 100}) # 字典对应修改
df.replace({'Q1': 0, 'Q2': 5}, 100) # 将指定字段的指定值修改为100
df.replace({'Q1': {0: 100, 4: 400}}) # 将指定列里的指定值替换为另一个指定的值
3、填充空值
df.fillna(0) # 将空值全修改为0
# {'backfill', 'bfill', 'pad', 'ffill',None}, 默认为None
df.fillna(method='ffill') # 将空值都修改为其前一个值
values = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
df.fillna(value=values) # 为各列填充不同的值
df.fillna(value=values, limit=1) # 只替换第一个
4、修改索引名
df.rename(columns={'team':'class'})
常用方法如下:
df.rename(columns={"Q1":"a", "Q2": "b"}) # 对表头进行修改
df.rename(index={0: "x", 1:"y", 2: "z"}) # 对索引进行修改
df.rename(index=str) # 对类型进行修改
df.rename(str.lower, axis='columns') # 传索引类型
df.rename({1: 2, 2: 4}, axis='index') # 对索引名进行修改
s.rename_axis("animal")
df.rename_axis("animal") # 默认是列索引
df.rename_axis("limbs",axis="columns") # 指定行索引 # 索引为多层索引时可以将type修改为class
df.rename_axis(index={'type': 'class'}) # 可以用set_axis进行设置修改
s.set_axis(['a', 'b', 'c'], axis=0)
df.set_axis(['I', 'II'], axis='columns')
df.set_axis(['i', 'ii'], axis='columns',inplace=True)
5、增加列
df['foo'] = 100 # 增加一列foo,所有值都是100
df['foo'] = df.Q1 + df.Q2 # 新列为两列相加
df['foo'] = df['Q1'] + df['Q2'] # 同上
# 把所有为数字的值加起来
df['total'] =df.select_dtypes(include=['int']).sum(1)df['total'] =
df.loc[:,'Q1':'Q4'].apply(lambda x: sum(x), axis='columns')
df.loc[:, 'Q10'] = '我是新来的' # 也可以
# 增加一列并赋值,不满足条件的为NaN
df.loc[df.num >= 60, '成绩'] = '合格'
df.loc[df.num < 60, '成绩'] = '不合格'
6、插入列df.insert()
# 在第三列的位置上插入新列total列,值为每行的总成绩
df.insert(2, 'total', df.sum(1))
7、指定列df.assign()
# 增加total列
df.assign(total=df.sum(1))
# 增加两列
df.assign(total=df.sum(1), Q=100)
df.assign(total=df.sum(1)).assign(Q=100)
其他使用示例:
df.assign(Q5=[100]*100) # 新增加一列Q5
df = df.assign(Q5=[100]*100) # 赋值生效
df.assign(Q6=df.Q2/df.Q1) # 计算并增加Q6
df.assign(Q7=lambda d: d.Q1 * 9 / 5 + 32) # 使用lambda# 添加一列,值为表达式结果:True或False
df.assign(tag=df.Q1>df.Q2)
# 比较计算,True为1,False为0
df.assign(tag=(df.Q1>df.Q2).astype(int))
# 映射文案
df.assign(tag=(df.Q1>60).map({True:'及格',False:'不及格'}))
# 增加多个
df.assign(Q8=lambda d: d.Q1*5, Q9=lambda d: d.Q8+1) # Q8没有生效,不能直接用df.Q8
8、执行表达式df.eval()
# 传入求总分表达式
df.eval('total = Q1+Q3+Q3+Q4')
其他方法:
df['C1'] = df.eval('Q2 + Q3')
df.eval('C2 = Q2 + Q3') # 计算
a = df.Q1.mean()df.eval("C3 =`Q3`+@a") # 使用变量
df.eval("C3 = Q2 > (`Q3`+@a)") #加一个布尔值
df.eval('C4 = name + team', inplace=True) # 立即生效
9、增加行
# 新增索引为100的数据
df.loc[100] = ['tom', 'A', 88, 88, 88, 88]
其他方法:
df.loc[101]={'Q1':88,'Q2':99} # 指定列,无数据列值为NaN
df.loc[df.shape[0]+1] = {'Q1':88,'Q2':99} # 自动增加索引
df.loc[len(df)+1] = {'Q1':88,'Q2':99}
# 批量操作,可以使用迭代
rows = [[1,2],[3,4],[5,6]]
for row in rows: df.loc[len(df)] = row
10、追加合并
df = pd.DataFrame([[1, 2], [3, 4]],columns=list('AB'))
df2 = pd.DataFrame([[5, 6], [7, 8]],columns=list('AB'))
df.append(df2)
11、删除
# 删除索引为3的数据
s.pop(3)
# 93s
s
12、删除空值
df.dropna() # 一行中有一个缺失值就删除
df.dropna(axis='columns') # 只保留全有值的列
df.dropna(how='all') # 行或列全没值才删除
df.dropna(thresh=2) # 至少有两个空值时才删除
df.dropna(inplace=True) # 删除并使替换生效
05、高级过滤
介绍几个非常好用的复杂数据处理的数据过滤输出方法。
1、df.where()
# 数值大于70
df.where(df > 70)
2、np.where()
# 小于60分为不及格
np.where(df>=60, '合格', '不合格')
3、df.mask()
# 符合条件的为NaN
df.mask(s > 80)
4、df.lookup()
# 行列相同数量,返回一个array
df.lookup([1,3,4], ['Q1','Q2','Q3']) # array([36, 96, 61])
df.lookup([1], ['Q1']) # array([36])
06、数据迭代
1、迭代Series
# 迭代指定的列
for i in df.name: print(i)
# 迭代索引和指定的两列
for i,n,q in zip(df.index, df.name,df.Q1): print(i, n, q)
2、df.iterrows()
# 迭代,使用name、Q1数据
for index, row in df.iterrows(): print(index, row['name'], row.Q1)
3、df.itertuples()
for row in df.itertuples(): print(row)
4、df.items()
# Series取前三个
for label, ser in df.items(): print(label) print(ser[:3], end='\n\n')
5、按列迭代
# 直接对DataFrame迭代
for column in df: print(column)
07、函数应用
1、pipe()
应用在整个DataFrame或Series上。
# 对df多重应用多个函数
f(g(h(df), arg1=a), arg2=b, arg3=c)
# 用pipe可以把它们连接起来
(df.pipe(h) .pipe(g, arg1=a) .pipe(f, arg2=b, arg3=c)
)
2、apply()
应用在DataFrame的行或列中,默认为列。
# 将name全部变为小写
df.name.apply(lambda x: x.lower())
3、applymap()
应用在DataFrame的每个元素中。
# 计算数据的长度
def mylen(x): return len(str(x))
df.applymap(lambda x:mylen(x)) # 应用函数
df.applymap(mylen) # 效果同上
4、map()
应用在Series或DataFrame的一列的每个元素中。
df.team.map({'A':'一班', 'B':'二班','C':'三班', 'D':'四班',})# 枚举替换
df['name'].map(f)
5、agg()
# 每列的最大值
df.agg('max')
# 将所有列聚合产生sum和min两行
df.agg(['sum', 'min'])
# 序列多个聚合
df.agg({'Q1' : ['sum', 'min'], 'Q2' : ['min','max']})
# 分组后聚合
df.groupby('team').agg('max')
df.Q1.agg(['sum', 'mean'])
6、transform()
df.transform(lambda x: x*2) # 应用匿名函数
df.transform([np.sqrt, np.exp]) # 调用多个函数
7、copy()
s = pd.Series([1, 2], index=["a","b"])
s_1 = s
s_copy = s.copy()
s_1 is s # True
s_copy is s # False
相关文章:

50个 Pandas 高频操作技巧,建议收藏
在数据分析和数据建模的过程中需要对数据进行清洗和整理等工作,有时需要对数据增删字段。 下面为大家介绍Pandas对数据的复杂查询、数据类型转换、数据排序、数据的修改、数据迭代以及函数的使用 文章目录技术交流01、复杂查询1、逻辑运算2、逻辑筛选数据3、函数筛…...

pygraphviz安装教程
0x01. 背景 最近在做casual inference,做实验时候想因果图可视化,遂需要安装pygraphviz,整了一下午,终于捣鼓好了,真头大。 环境: win10操作系统python3.9环境 0x02. 安装Graphviz 传送门:…...
HarmonyOS Connect认证测试
在HarmonyOS Connect生态产品的认证测试过程中,你是否存在这些疑问:认证流程具体包括哪些操作环节?如何根据实际场景选择合适的认证方式?如何选择认证测试标准的版本…… 本期FAQ为大家带来HarmonyOS Connect认证测试的常见问题…...

Datawhale团队第九期录取名单!
Datawhale团队 公示:Datawhale团队成员Datawhale成立四年了,从一开始的12个人,学习互助,到提议成立开源组织,做更多开源的事情,帮助更多学习者,也促使我们更好地成长。于是有了我们的使命&#…...

ChatGPT 的原理与未来研究方向
1、原理: 架构:chatGPT是一种基于转移学习的大型语言模型,它使用GPT-3.2 (Generative PretrainedTransformer2)模型的技术,使用了transformer的架构,并进行了进一步的训练和优化。InstructGPT/…...

基于UIAutomation+Python+Unittest+Beautifulreport的WindowsGUI自动化测试框架主入口main解析
文章目录1 main.py主入口2 testcase目录2.1 实例:test\_test\_mymusic.py2.2 实例:test\_toolbar.py3 page目录3.1 page/mymusic.py3.2 page/toolbar.py注: 1、本文为本站首发,他用请联系作者并注明出处,谢谢ÿ…...
)
华为OD机试真题Python实现【挑选字符串】真题+解题思路+代码(20222023)
挑选字符串 题目 给定a-z,26 个英文字母小写字符串组成的字符串A和B, 其中A可能存在重复字母,B不会存在重复字母, 现从字符串A中按规则挑选一些字母可以组成字符串B 挑选规则如下: 同一个位置的字母只能挑选一次, 被挑选字母的相对先后顺序不能被改变, 求最多可以同时…...

Orcad放置字符标注、文本框、注释及图片方法教程
实际设计当中,经常需要对一些功能进行文字说明,或者对可选线路进行文字标注。这些文字注释可以大大增强线路的可读性,后期也可以让布线工程充分对所关注的线路进行特别处理。1、放置字符标注 字符标注主要针对的是较短的文字说明。 ÿ…...

秒懂算法 | 子集树模型——0-1背包问题的回溯算法及动态规划改进
给定n种物品和一背包。物品i的重量是wi,其价值为vi,背包的容量为W。一种物品要么全部装入背包,要么全部不装入背包,不允许部分装入。装入背包的物品的总重量不超过背包的容量。问应如何选择装入背包的物品,使得装入背包中的物品总价值最大? 01、问题分析——解空间及搜索…...

koc转化效果评估模型是什么?如何根据模型来进行投放
目前小红书有超2亿月活用户,共有4300万的分享,当之无愧的成为众多年轻用户心中的“消费决策”平台。那怎么将如此巨大的流量切实的转化为效果是一个挑战。今天就来简单分享一下这个挑战的答案。其实可以借助模型来帮助,这就是koc转化效果评估…...

vuejs-datepicker|简单易用的Vue.js日期选择组件
vuejs-datepicker是一个简单易用的Vue.js日期选择组件。它使用了Bootstrap 4的样式,支持多种语言,具有直观的界面,易于配置和扩展。👉 效果演示 👉如果您想使用vuejs-datepicker,首先您需要安装它ÿ…...

【c++】类和对象3—初始化列表、类对象作为类成员、静态成员
文章目录初始化列表类对象作为类成员静态成员初始化列表 作用:c提供了初始化 语法:构造函数():属性1(值1),属性2(值2),…{} #include<iostream> using namespace std;class Person { public://1、传统初始化操作/*Person(int a, int b, int c) …...

【基础算法】数的范围
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...

FreeRTOS入门(01):基础说明与使用演示
文章目录目的基础说明系统移植基础使用演示数据类型和命名风格总结碎碎念目的 FreeRTOS是一个现在非常流行的实时操作系统(Real Time Operating System)。本文将介绍FreeRTOS入门使用相关内容,这篇是第一篇,主要介绍基础背景方面…...
)
华为OD机试真题Python实现【交换字符】真题+解题思路+代码(20222023)
交换字符 题目 给定一个字符串S 变化规则: 交换字符串中任意两个不同位置的字符M S都是小写字符组成 1 <= S.length <= 1000 🔥🔥🔥🔥🔥👉👉👉👉👉👉 华为OD机试(Python)真题目录汇总 输入 一串小写字母组成的字符串 输出 按照要求变换得到…...
Word处理控件Aspose.Words功能演示:使用 Java 在 MS Word 文档中进行邮件合并
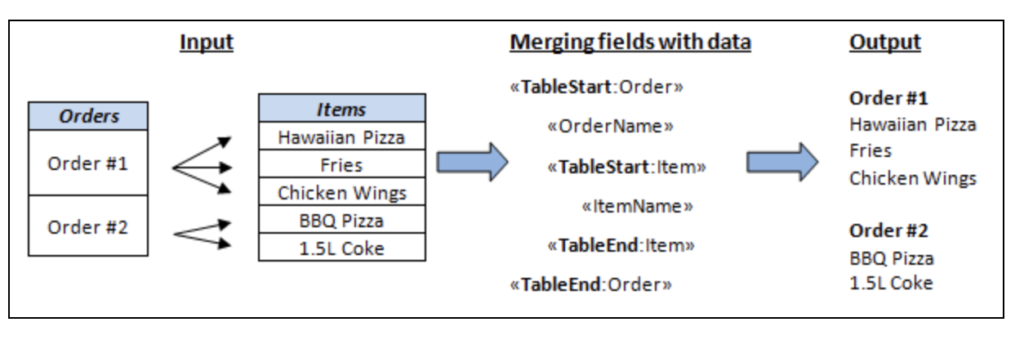
Aspose.Words 是一种高级Word文档处理API,用于执行各种文档管理和操作任务。API支持生成,修改,转换,呈现和打印文档,而无需在跨平台应用程序中直接使用Microsoft Word。此外,Aspose API支持流行文件格式处理…...

产品未出 百度朋友圈“开演”
ChatGPT这股AI龙卷风刮到国内时,人们齐刷刷望向百度,这家在国内对AI投入最高的公司最终出手了,大模型新项目文心一言(ERNIE Bot)将在3月正式亮相,对标微软投资的ChatGPT。 文心一言产品未出,百…...

emacs 中的键盘宏
emacs 中的键盘宏 宏定义是emacs比较强大的功能,自定义宏然后绑定快捷键之后就更加爽了。 vim 当然也有宏功能,而且用法简单,例如录制宏到a寄存器:qa...q, 执行宏a: a 世界就是由循环和递归构成的. 宏定义就是一个执行体,为了以后的循环做准备的 开启宏记录 C-x ( 或…...

TCP/IP网络编程——关于 I/O 流分离的其他内容
完整版文章请参考: TCP/IP网络编程完整版文章 文章目录第 16 章 关于 I/O 流分离的其他内容16.1 分离 I/O 流16.1.1 2次 I/O 流分离16.1.2 分离「流」的好处16.1.3 「流」分离带来的 EOF 问题16.2 文件描述符的的复制和半关闭16.2.1 终止「流」时无法半关闭原因16.2…...

【BCT认证_组播DNS】 DNS SRV RR
每天遇见几个罕为人知的Bug,醉了 定义 关键字“必须”、“不能”、“应该”、“不应该”和“可以”本文档中使用的术语应按照 [BCP 14] 中的规定进行解释。本文档中使用的其他术语在 DNS 中定义规范,RFC 1034。 适用性声明 一般情况下,预计…...

告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境
告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境 对于嵌入式开发者来说,配置开发环境往往是个令人头疼的问题。传统虚拟机方案虽然能提供完整的Linux体验,但资源占用高、启动慢、与宿主系统交互不便等问题一直困扰着开发者。…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...