分类任务评价指标
分类任务评价指标
分类任务中,有以下几个常用指标:
- 混淆矩阵
- 准确率(Accuracy)
- 精确率(查准率,Precision)
- 召回率(查全率,Recall)
- F-score
- PR曲线
- ROC曲线
1. 混淆矩阵
| 真实1 | 真实0 | |
|---|---|---|
| 预测1 | TP | FP |
| 预测0 | FN | TN |
从预测的角度看:
- TP: True Positive。预测为1,实际为1,预测正确。
- FP: False Positive。预测为1,实际为0,预测错误。
- FN: False Negative。预测为0,实际为1,预测错误。
- TN: True Negative。预测为0,实际为0,预测正确。
2.准确率(Accuracy)
在所有预测结果中,正确预测的占比:
$Accuracy = \frac{TP+TN}{TP+FP+FN+TN} $
准确率衡量整体(包括正样本和负样本)的预测准确度,但不适用与样本不均衡的情况。比如有100个样本,其中正样本90个,负样本10个,此时模型将所有样本都预测为正样本就可以取得 90% 的准确率,但实际上这个模型根本就没有分类的能力。
3. 精确率(查准率,Precision)
在所有预测为1的样本中,正确预测的占比:
$ Precision = \frac{TP}{TP+FP}$
衡量正样本的预测准确度。
4. 召回率(查全率,Recall)
在所有真实标签为1的样本中,正确预测的占比:
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP
衡量模型预测正样本的能力。
5. F-score
综合考虑精确率和召回率:
$ F_{score}=(1+\beta2)\frac{PR}{\beta2*P+R} $
- β=1,表示Precision与Recall一样重要(此时也叫F1-score)
- β<1,表示Precision比Recall重要
- β>1,表示Recall比Precision重要
精确率和召回率相互“制约”:精确率高,则召回率就低;召回率高,则精确率就低。因此就需要综合考虑它们,最常见的方法就是 F-score 。F-score越大模型性能越好。
6. PR曲线
6.1 绘制方法
PR曲线以召回率R为横坐标、以精确率P为纵坐标,以下面的数据为例说明一下绘制方法:
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 预测为正类的概率 score | 0.9 | 0.8 | 0.7 | 0.5 | 0.3 |
| 实际类别 class | 1 | 0 | 1 | 1 | 0 |
-
将每个样本的预测结果按照预测为正类的概率排序(上面已排序)
-
依次看每个样本
a) 对于样本1,将它的 score 0.9 作为阈值,即 score >= 0.9时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 1 0 预测0 2 2 b) 对于样本2,将它的 score 0.8 作为阈值,即 score >= 0.8时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 1 1 预测0 2 1 c) ……
d) ……
e) 对于样本5,将它的 score 0.3 作为阈值,即 score >= 0.3时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 3 2 预测0 0 0 -
根据上面的混淆矩阵,依次算出 5 对(R, R),以召回率R为横坐标、以精确率P为纵坐标,将这些点连接起来即得到 PR 曲线。
6.2 模型性能衡量方法
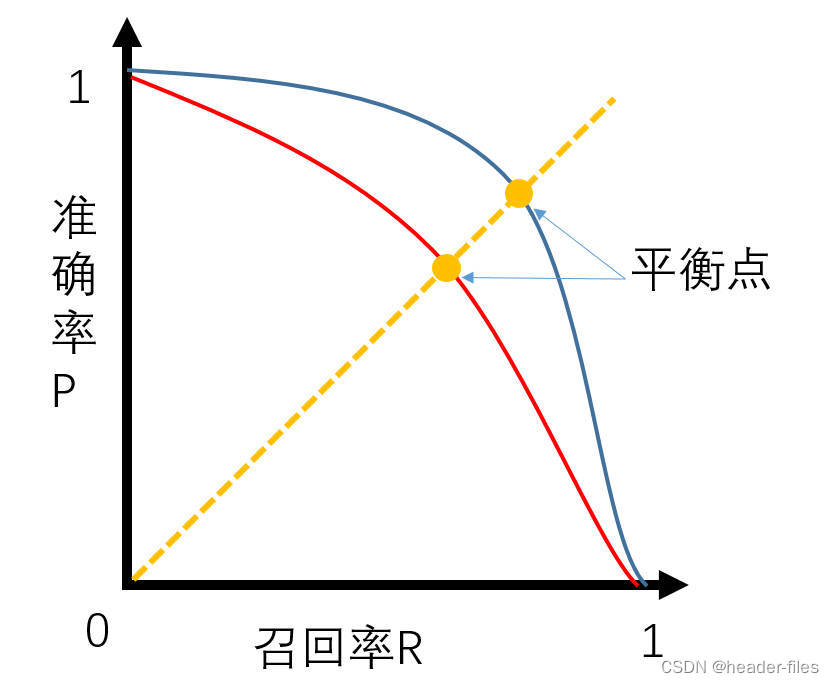
-
如果曲线A完全“包住”曲线B,则A的性能优于B(P和R越高,代表算法分类能力越强);
-
曲线AB发生交叉时:以PR曲线下的面积作为衡量指标(这个指标通常难以计算);
-
使用 “平衡点”(P=R时的取值),值越大代表效果越优(这个点过于简化,更常用的是F1-score)。
7. ROC曲线
真阳性率(真实1里面正确预测为1的概率): T P R = T P T P + F N TPR = \frac{TP}{TP+FN} TPR=TP+FNTP
假阳性率(真实0里面错误预测为1的概率): F P R = F P F P + T N FPR = \frac{FP}{FP+TN} FPR=FP+TNFP
7.1 绘制方法
ROC曲线以假阳性率FPR为横坐标、以真阳性率TPR为纵坐标,以下面的数据为例说明一下绘制方法:
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 预测为正类的概率 score | 0.9 | 0.8 | 0.7 | 0.5 | 0.3 |
| 实际类别 class | 1 | 0 | 1 | 1 | 0 |
-
将每个样本的预测结果按照预测为正类的概率排序(上面已排序)
-
依次看每个样本
a) 对于样本1,将它的 score 0.9 作为阈值,即 score >= 0.9时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 1 0 预测0 2 2 b) 对于样本2,将它的 score 0.8 作为阈值,即 score >= 0.8时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 1 1 预测0 2 1 c) ……
d) ……
e) 对于样本5,将它的 score 0.3 作为阈值,即 score >= 0.3时样本预测为 1 ,反之预测为 0,得到以下混淆矩阵
真实1 真实0 预测1 3 2 预测0 0 0 -
根据上面的混淆矩阵,依次算出 5 对(FPR, TPR),以假阳性率FPR为横坐标、以真阳性率TPR为纵坐标,将这些点连接起来即得到 ROC 曲线。
7.2 模型性能衡量方法
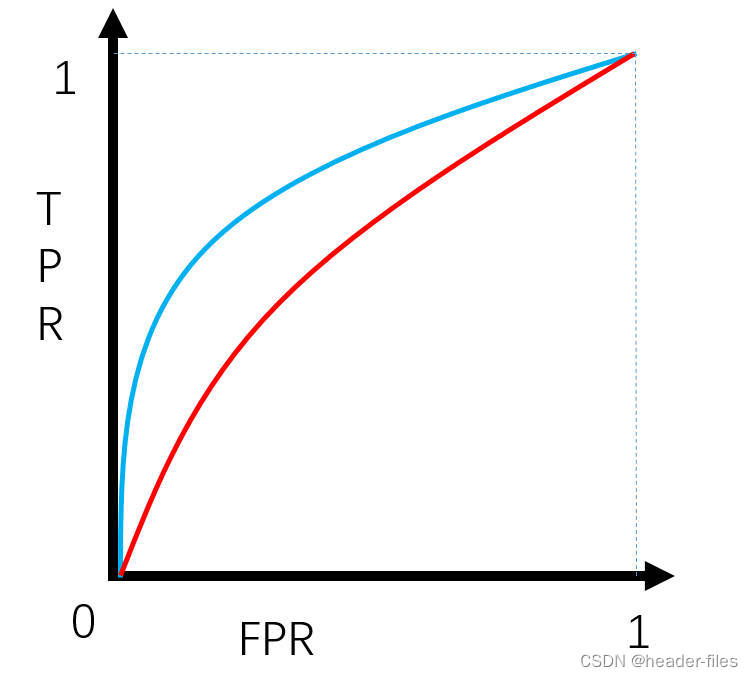
ROC曲线下的面积(AUC)作为衡量指标,面积越大,性能越好。
7.3 AUC的计算
在有M个正样本,N个负样本的数据集里。一共有MN对样本(一对样本即一个正样本与一个负样本)。统计这MN对样本里,正样本的预测概率大于负样本的预测概率的个数:
A U C = ∑ I ( P 正样本 , P 负样本 ) M ∗ N AUC = \frac{\sum I(P_\text{正样本},P_\text{负样本})}{M^*N} AUC=M∗N∑I(P正样本,P负样本)
其中:
I ( P 正样本 , P 负样本 ) = { 1 , P 正样本 > P 正样本 0.5 , P 正样本 = P 负样本 0 , P 正样本 < P 负样本 I(P_\text{正样本},P_\text{负样本})=\begin{cases}1,P_\text{正样本}>P_\text{正样本}\\0.5,P_\text{正样本}=P_\text{负样本}\\0,P_\text{正样本}<P_\text{负样本}\end{cases} I(P正样本,P负样本)=⎩ ⎨ ⎧1,P正样本>P正样本0.5,P正样本=P负样本0,P正样本<P负样本
相关文章:
分类任务评价指标
分类任务评价指标 分类任务中,有以下几个常用指标: 混淆矩阵准确率(Accuracy)精确率(查准率,Precision)召回率(查全率,Recall)F-scorePR曲线ROC曲线 1. 混…...

c++静态成员
目录 静态成员 静态成员变量 静态成员函数 const 静态成员属性 静态成员实现单例模式 静态成员 在类定义中,它的成员(包括成员变量和成员函数),这些成员可以用关键字 static 声明为静态的,称为静态成员。 不管这…...
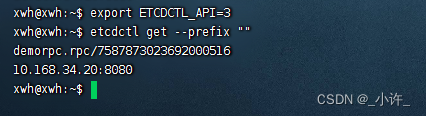
go-zero直连与etcd服务注册中心
go-zero中直连方式 在使用grpc是最重要的就是pb文件了,生成的pb文件,通过pb文件可以生成grpc的客户端和服务端,那么客户端和服务端就可以直连了,再次基础上可以引入etcd实现服务注册。 所有的代码都需要开发者编写,包…...
Kotlin File writeText appendText appendBytes readBytes readText
Kotlin File writeText appendText appendBytes readBytes readText import java.io.Filefun main(args: Array<String>) {val filePath "./myfile.txt"val file File(filePath)file.writeText("hello,") //如果原有文件有内容,将完全覆…...
常见缺少msvcp140.dll问题及解决方法,分享多种方法帮你解决
在日常使用电脑的过程中,我们可能会遇到各种问题,比如电脑提示msvcp140.dll文件丢失。这个问题通常是由于某些程序或游戏需要这个dll文件来正常运行,但是由于某种原因,这个文件被误删或者损坏了。那么,如何解决这个问题…...
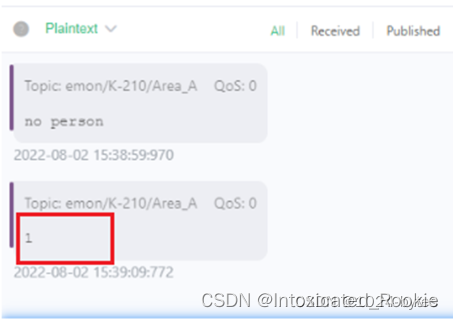
【K210+ESP8266图传上位机开发】TCP server + JPEG图像解析上位机开发
本文章主要记录基于 【K210-ESP8266】 图传和显示的过程,上位机开发过程,系统架构和下位机开发请参考文章: 【K210-ESP8266】开发板上传图像数据到服务器并实时显示 💖 作者简介:大家好,我是喜欢记录零碎知…...

Linux查看当前文件夹的大小
在Linux中,可以使用du(disk usage)命令来查看当前文件夹的大小。以下是一些使用du的方法: 查看当前文件夹的大小: 为了查看当前文件夹的总大小,可以在文件夹中运行: du -sh .这里: -…...

YOLO目标检测——密集人群人头数据集+已标注yolo格式标签下载分享
实际项目应用:城市安防、交通管理、社会研究、商业应用、等多个领域数据集说明:YOLO密集人群人头目标检测数据集,真实场景的高质量图片数据,数据场景丰富,图片格式为jpg,共4300张图片。标注说明:…...

论文精读 —— Gradient Surgery for Multi-Task Learning
文章目录 Multi-task Learning和 PCGrad 方法简介论文信息论文核心图摘要翻译引言翻译2 使用PCGrad进行多任务学习2.1 基本概念:问题和符号表示2.2 三重悲剧:冲突的梯度,主导的梯度,高曲率2.3 PCGrad:解决梯度冲突2.4 …...
【VS Code插件开发】常见自定义命令(七)
🐱 个人主页:不叫猫先生,公众号:前端舵手 🙋♂️ 作者简介:前端领域优质作者、阿里云专家博主,共同学习共同进步,一起加油呀! 📢 资料领取:前端…...

Spring Cloud服务发现与注册的原理与实现
Spring Cloud服务发现与注册的原理与实现 一、简介1 服务发现的定义2 服务发现的意义 二、Spring Cloud服务注册与发现的实现1 Spring Cloud服务注册1.1 服务注册的基本框架1.2 服务注册的实现方式 2 Spring Cloud服务发现2.1 服务发现的基本框架2.2 服务发现的实现方式 三、Sp…...

FFmpeg入门之简单介绍
FFmpeg是什么意思: Fast Forward Moving Picture Experts Group ffmpeg相关文档: Documentation FFmpeg ffmpeg源码下载: https://git.videolan.org/git/ffmpeg.git https://github.com/FFmpeg/FFmpeg.git FFmpeg能做什么? 多种媒体格式的封装与解封装 : 1.多种音…...

新版DBeaver调整编辑窗口字体大小
网上有DBeave字体设置了,但看了下,目前最新版的已经更改了首选项分组,层级发生了变化,这里记录一下2022.08.21版的设置。 默认字体是10,比较小,改为11或更大会好看些。...
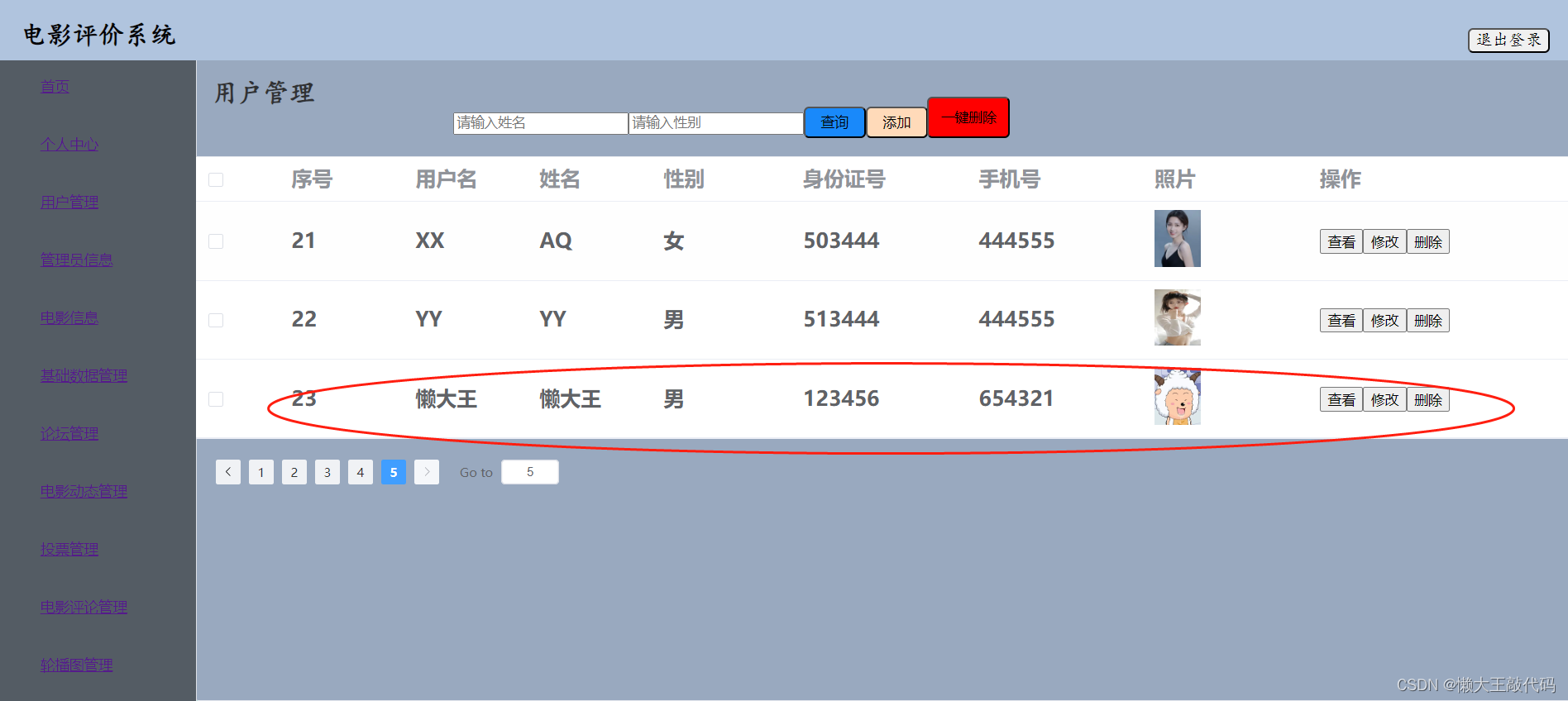
《vue3实战》运用push()方法实现电影评价系统的添加功能
目录 前言 电影评价系统的添加功能是什么? 电影评价系统的添加功能有什么作用? 一、push()方法是什么?它有什么作用? 含义: 作用: 二、功能实现 这段是添加开始时点击按钮使…...
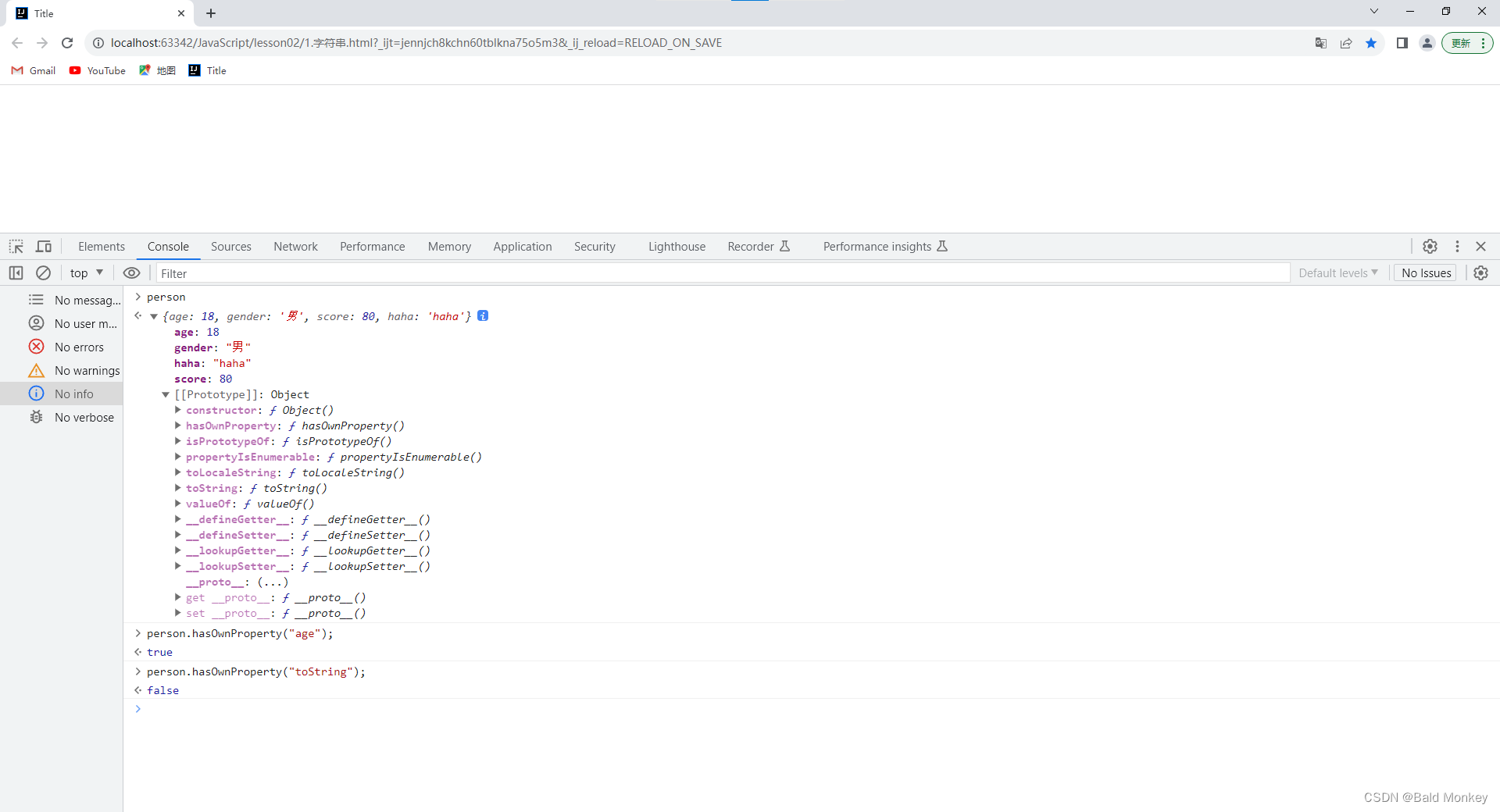
JavaScript学习笔记02
JavaScript笔记02 数据类型详解 字符串 在 JavaScript 中正常的字符串都使用单引号 或者双引号" "包裹:例: 转义字符 在 JavaScript 字符串中也可用使用转义字符(参考:详解转义字符):例&…...
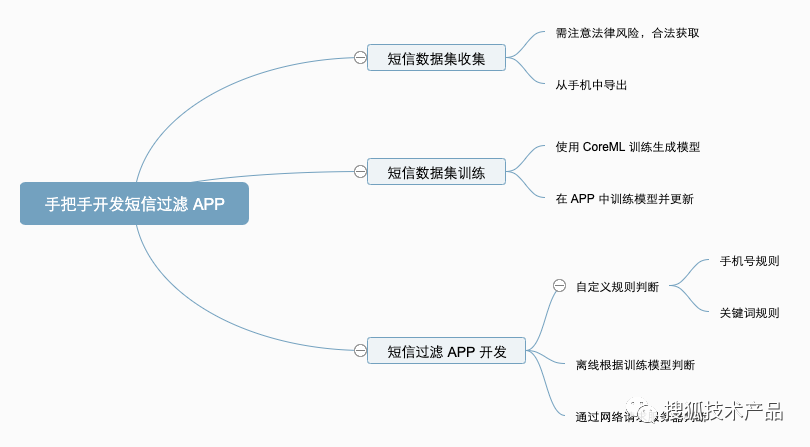
短信过滤 APP 开发
本文字数:7033字 预计阅读时间:42分钟 一直想开发一个自己的短信过滤 APP,但是一直没有具体实施,现在终于静下心来,边开发边记录下整体的开发过程。 01 垃圾短信样本 遇到的第一个问题是,既然要过滤垃圾短信…...

【计算机基础知识7】垃圾回收机制与内存泄漏
目录 前言 一、垃圾回收机制的工作原理 1. 标记-清除算法的基本原理 2. 垃圾回收器的类型及其工作方式 3. 垃圾回收的回收策略和触发机制 三、内存泄漏的定义和原因 1. 内存泄漏的概念和影响 2. 常见的内存泄漏情况及其原因 四、如何避免和处理内存泄漏 1. 使用合适…...

[学习笔记]CS224W
资料: 课程网址 斯坦福CS224W图机器学习、图神经网络、知识图谱【同济子豪兄】 斯坦福大学CS224W图机器学习公开课-同济子豪兄中文精讲 图的基本表示 图是描述各种关联现象的通用语言。与传统数据分析中的样本服从独立同分布假设不一样,图数据自带关联…...
华为云API对话机器人CBS的魅力—实现简单的对话操作
云服务、API、SDK,调试,查看,我都行 阅读短文您可以学习到:人工智能AI智能的问答管理、全面的对话管理、高效训练部署 1.IntelliJ IDEA 之API插件介绍 API插件支持 VS Code IDE、IntelliJ IDEA等平台、以及华为云自研 CodeArts …...

精益制造、质量管控,盛虹百世慧共同启动MOM(制造运营管理)
百世慧科技依托在电池智能制造行业中的丰富经验,与盛虹动能达成合作,为其提供MOM制造运营管理平台,并以此为起点,全面提升盛虹动能的制造管理水平与运营体系。 行业困境 中国动力电池已然发展为全球最大的电池产业,但…...
)
别再只用GitHub了!手把手教你用GitLab搭建团队专属代码仓库(从群组到项目实战)
别再只用GitHub了!手把手教你用GitLab搭建团队专属代码仓库(从群组到项目实战) 在开源生态中,GitHub无疑是代码托管平台的代名词。但对于需要私有化部署和精细权限控制的团队而言,GitLab提供了更完整的DevOps解决方案。…...
ImageTrans插件生态:用Python扩展图片OCR与翻译工作流
1. 项目概述:一个为ImageTrans量身定制的插件生态如果你经常需要处理图像中的文字,比如翻译漫画、本地化游戏截图或者处理带文字的UI设计稿,那你很可能听说过或者用过ImageTrans这款工具。它是一款专注于图片文字识别(OCR…...

5分钟掌握视频号批量下载:res-downloader高效操作指南
5分钟掌握视频号批量下载:res-downloader高效操作指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在数字内容…...

麻省理工博士生弃博投身数字人类研究:10年、100亿美元、5万台H100或可实现
【导语:麻省理工学院博士生Isaak Freeman放弃攻读博士学位,投身数字人类研究。他认为人类若保持碳基形态将在智力竞争中被AI淘汰,而将意识迁移到数字基质上是出路,并给出实现数字人类的粗略计算和路线图。】数字人类:从…...

基于Web Audio与Three.js的VR音乐可视化系统开发实践
1. 项目概述:当音乐可视化遇上VR,一次沉浸式体验的探索最近在折腾一个挺有意思的项目,叫“VersaYT/JellyVR”。乍一看这个名字,可能有点摸不着头脑,它其实是一个将YouTube音乐视频的音频频谱,实时转化为虚拟…...

BioClaw:基于自然语言对话的生物信息学智能分析平台
1. 项目概述:BioClaw,一个能聊天的生物信息学工具箱 如果你是一名生物医学领域的研究者,我猜你对下面这个场景一定不陌生:你刚拿到一批测序数据,需要先跑个FastQC看看质量;同时,实验室的师弟在…...

在Node.js后端服务中集成Taotoken调用多模型API实战
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用多模型API实战 构建需要AI能力的Web服务时,后端开发者常面临模型选型、API接入复…...

CMS三十年:从“手工建站”到“智能基座”
一个从业者的观察与思考不知不觉,跟CMS打交道已经十几年了。从早期的织梦、帝国,到后来的WordPress,再到现在的各类无头CMS和低代码平台,这个领域的变化比想象中要快得多。写这篇文章,算是对CMS发展历程的一次梳理&…...

企业级长文档AI落地避坑指南,从PDF解析失真到语义断裂修复——Claude 2026六大隐性能力详解
更多请点击: https://intelliparadigm.com 第一章:PDF解析失真问题的根源与本质诊断 PDF 文件虽为“便携式文档格式”,但其内部结构高度异构——文本可能嵌入在图形路径中、字体被子集化或完全缺失、字符编码映射断裂,甚至存在跨…...

从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置
从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32开发者来说,掌握高级定时器的互补PWM输出和死区时间配置,意味着可以解锁从电机控制到LE…...