深度学习Week16-yolo.py文件解读(YOLOv5)
目录
简介
需要的基础包和配置
二、主要组件介绍
2.1 parse_model
2.2Detect类
2.3DetectionModel类
三、实验
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有)
🍖 作者:[K同学啊]
这周接着详细解析小白YOLOv5全流程-训练+实现数字识别_牛大了2022的博客-CSDN博客_yolov5识别数字,之前入门教大家下载配置环境,如果没有的话请参考这篇的文章深度学习Week11-调用官方权重进行检测(YOLOv5)_yolov5权重_牛大了2022的博客-CSDN博客
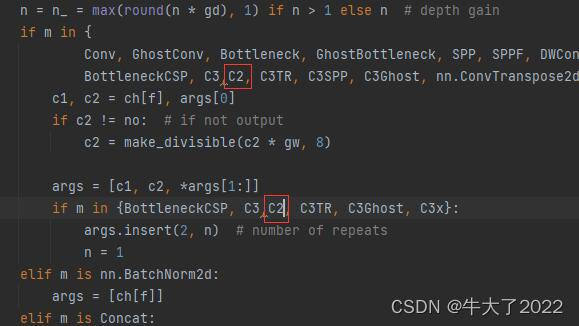
📌 本周任务:将YOLOv5s网络模型中的C3模块按照下图方式修改形成C2模块,并将C2模块插入第2层与第3层之间,且跑通YOLOv5s。
●💫 任务提示:
○提示1:需要修改common.yaml、yolo.py、yolov5s.yaml文件。
○提示2:C2模块与C3模块是非常相似的两个模块,我们要插入C2到模型当中,只需要找到哪里有C3模块,然后在其附近加上C2即可。
简介
common.py文件位置在./models/yolo.py

需要的基础包和配置
import argparse
import contextlib
import os
import platform
import sys
from copy import deepcopy
from pathlib import PathFILE = Path(__file__).resolve()
ROOT = FILE.parents[1] # YOLOv5 root directory
if str(ROOT) not in sys.path:sys.path.append(str(ROOT)) # add ROOT to PATH
if platform.system() != 'Windows':ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relativefrom models.common import *
from models.experimental import *
from utils.autoanchor import check_anchor_order
from utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
from utils.plots import feature_visualization
from utils.torch_utils import (fuse_conv_and_bn, initialize_weights, model_info, profile, scale_img, select_device,time_sync)try:import thop # for FLOPs computation
except ImportError:thop = None二、主要组件介绍
2.1 parse_model
用于将模型的模块拼接起来,搭建完成的网络模型。不是固定的,改框架也要改这个函数。
def parse_model(d, ch): # model_dict, input_channels(3)# Parse a YOLOv5 model.yaml dictionaryLOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()LOGGER.info(f"{colorstr('activation:')} {act}") # printna = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)layers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argsm = eval(m) if isinstance(m, str) else m # eval stringsfor j, a in enumerate(args):with contextlib.suppress(NameError):args[j] = eval(a) if isinstance(a, str) else a # eval stringsn = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2else:c2 = ch[f]m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []ch.append(c2)return nn.Sequential(*layers), sorted(save)2.2Detect类
构建Detect层的,将输入feature map 通过一个卷积操作和公式计算到我们想要的shape,为后面的计算损失或者NMS作准备。
class Detect(nn.Module):# YOLOv5 Detect head for detection modelsstride = None # strides computed during builddynamic = False # force grid reconstructionexport = False # export modedef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.empty(0) for _ in range(self.nl)] # init gridself.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use inplace ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)if isinstance(self, Segment): # (boxes + masks)xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xywh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf.sigmoid(), mask), 4)else: # Detect (boxes only)xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)xy = (xy * 2 + self.grid[i]) * self.stride[i] # xywh = (wh * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf), 4)z.append(y.view(bs, self.na * nx * ny, self.no))return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')):d = self.anchors[i].devicet = self.anchors[i].dtypeshape = 1, self.na, ny, nx, 2 # grid shapey, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)yv, xv = torch.meshgrid(y, x, indexing='ij') if torch_1_10 else torch.meshgrid(y, x) # torch>=0.7 compatibilitygrid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)return grid, anchor_grid2.3DetectionModel类
模型的构建工场,指定模型的yaml文件,以及一系列的训练参数
class DetectionModel(BaseModel):# YOLOv5 detection modeldef __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classessuper().__init__()if isinstance(cfg, dict):self.yaml = cfg # model dictelse: # is *.yamlimport yaml # for torch hubself.yaml_file = Path(cfg).namewith open(cfg, encoding='ascii', errors='ignore') as f:self.yaml = yaml.safe_load(f) # model dict# Define modelch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channelsif nc and nc != self.yaml['nc']:LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")self.yaml['nc'] = nc # override yaml valueif anchors:LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')self.yaml['anchors'] = round(anchors) # override yaml valueself.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelistself.names = [str(i) for i in range(self.yaml['nc'])] # default namesself.inplace = self.yaml.get('inplace', True)# Build strides, anchorsm = self.model[-1] # Detect()if isinstance(m, (Detect, Segment)):s = 256 # 2x min stridem.inplace = self.inplaceforward = lambda x: self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forwardcheck_anchor_order(m)m.anchors /= m.stride.view(-1, 1, 1)self.stride = m.strideself._initialize_biases() # only run once# Init weights, biasesinitialize_weights(self)self.info()LOGGER.info('')def forward(self, x, augment=False, profile=False, visualize=False):if augment:return self._forward_augment(x) # augmented inference, Nonereturn self._forward_once(x, profile, visualize) # single-scale inference, traindef _forward_augment(self, x):img_size = x.shape[-2:] # height, widths = [1, 0.83, 0.67] # scalesf = [None, 3, None] # flips (2-ud, 3-lr)y = [] # outputsfor si, fi in zip(s, f):xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))yi = self._forward_once(xi)[0] # forward# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # saveyi = self._descale_pred(yi, fi, si, img_size)y.append(yi)y = self._clip_augmented(y) # clip augmented tailsreturn torch.cat(y, 1), None # augmented inference, traindef _descale_pred(self, p, flips, scale, img_size):# de-scale predictions following augmented inference (inverse operation)if self.inplace:p[..., :4] /= scale # de-scaleif flips == 2:p[..., 1] = img_size[0] - p[..., 1] # de-flip udelif flips == 3:p[..., 0] = img_size[1] - p[..., 0] # de-flip lrelse:x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scaleif flips == 2:y = img_size[0] - y # de-flip udelif flips == 3:x = img_size[1] - x # de-flip lrp = torch.cat((x, y, wh, p[..., 4:]), -1)return pdef _clip_augmented(self, y):# Clip YOLOv5 augmented inference tailsnl = self.model[-1].nl # number of detection layers (P3-P5)g = sum(4 ** x for x in range(nl)) # grid pointse = 1 # exclude layer counti = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indicesy[0] = y[0][:, :-i] # largei = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indicesy[-1] = y[-1][:, i:] # smallreturn ydef _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency# https://arxiv.org/abs/1708.02002 section 3.3# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.m = self.model[-1] # Detect() modulefor mi, s in zip(m.m, m.stride): # fromb = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)b.data[:, 5:5 + m.nc] += math.log(0.6 / (m.nc - 0.99999)) if cf is None else torch.log(cf / cf.sum()) # clsmi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)三、实验

任务:如图所示,将C3模块改为C2模块,并将C2模块插入到第二层与第三层之间,并跑通代码。
common.py中

yolov5s.yaml

yolo.py
注意添加修改会涉及多处地方。
相关文章:
深度学习Week16-yolo.py文件解读(YOLOv5)
目录 简介 需要的基础包和配置 二、主要组件介绍 2.1 parse_model 2.2Detect类 2.3DetectionModel类 三、实验 🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有) 🍖 作者:[K同学啊…...
富文本编辑组件封装,tinymce、tinymce-vue
依赖:package.json yarn add tinymce tinymce/tinymce-vue {"dependencies": {"tinymce/tinymce-vue": "5.0.0","tinymce": "6.3.1","vue": "3.2.45",}, } 本地依赖: 在publ…...

电子作业指导书系统能树立良好的生产形象
“制造”就是以规定的成本、规定的工时、生产出品质均匀、符合规格的产品。从全球新能源汽车的发展来看,其动力电源主要包括锂离子电池、镍氢电池、铅酸电池、超级电容器,其中超级电容器大多以辅助动力源的形式出现。那么,电子作业指导书系统…...
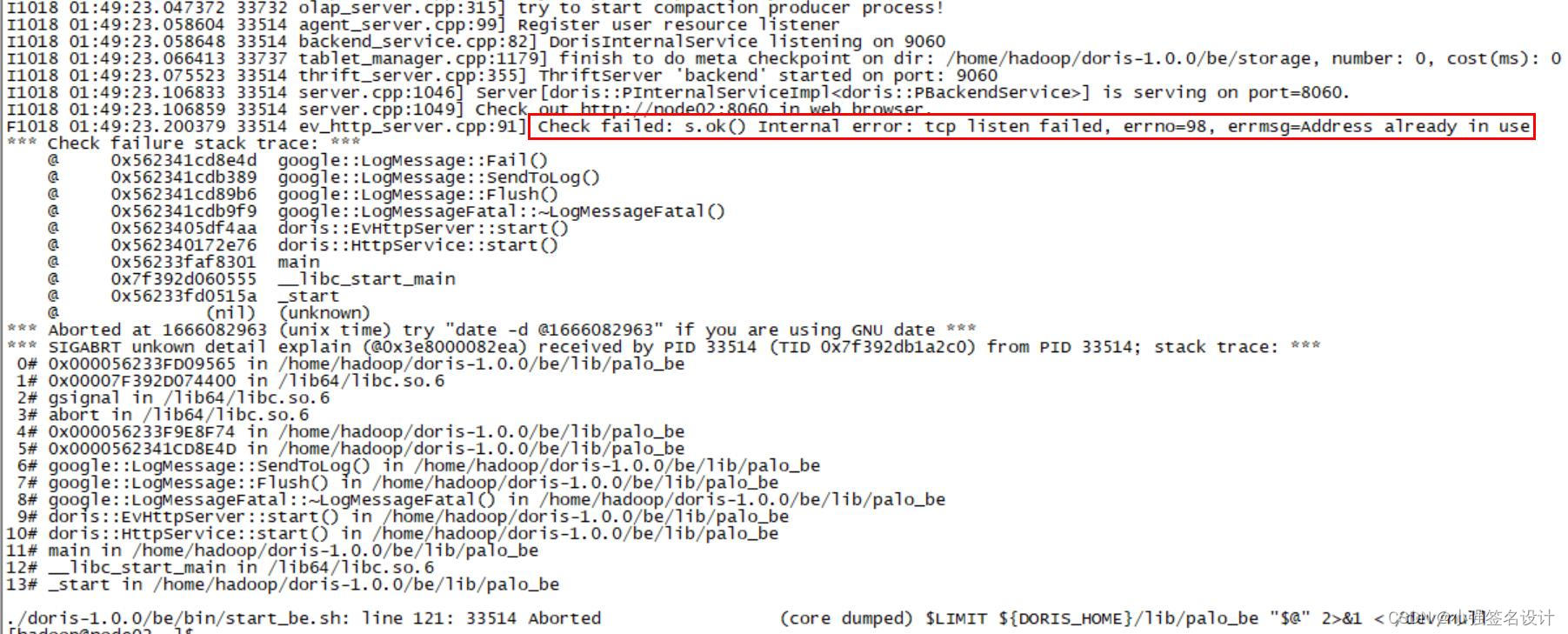
Doris单机部署
文章目录1. 前言2. 安装3. 启动4. 使用1. 前言 Apache Doris 是一款现代 MPP (Massively Parallel Processing大规模并行处理) 的分布式 SQL 分析数据库,所谓分析数据库就是将其数据集分布在许多机器或节点上,以处理大量数据,采用 Apache 2.0…...

利用身份证号获取生日信息
1 问题如何利用Java程序从身份证号中获取生日信息。2 方法采用“截图文字代码”的方式描述。//调用函数获取当前日期以及截取身份证号码中的数字import java.util.Calendar;import java.util.Scanner;public class nain { static Scanner sc new Scanner(System.in); st…...
c++模板的简单认识
文章目录 前言一.泛型编程 函数模板 模板参数的匹配原则 类模板总结前言 ADD函数很好写,但是如果我们要有int类型的,double类型的,char类型的等等各种类型,难道要写这么多不同的ADD函数吗,这么写简直太麻…...
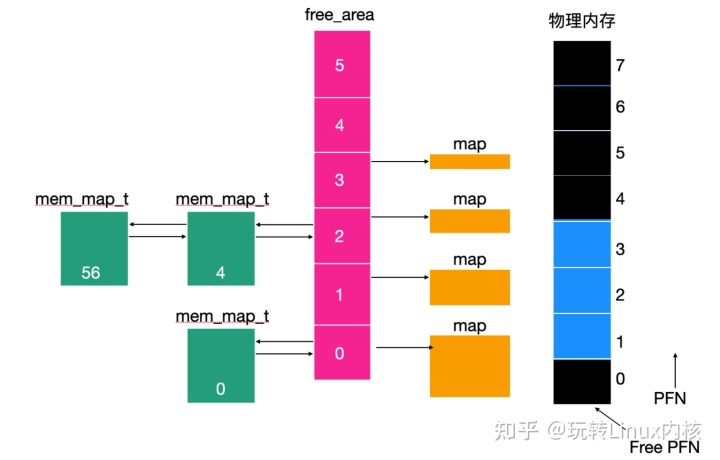
真香!Linux 原来是这么管理内存的
Linux 内存管理模型非常直接明了,因为 Linux 的这种机制使其具有可移植性并且能够在内存管理单元相差不大的机器下实现 Linux,下面我们就来认识一下 Linux 内存管理是如何实现的。 一,基本概念 每个 Linux 进程都会有地址空间,这…...
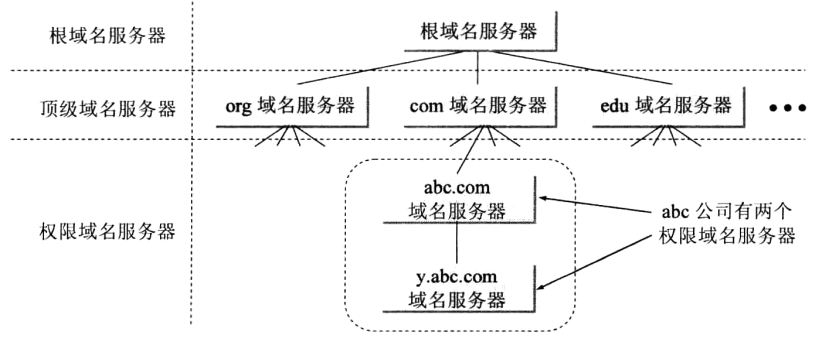
计网之IP协议和以太网
文章目录一. IP协议1. IPv4报头介绍2. 解决IPv4地址不够用的问题3. IP地址管理4. 路由选择二. 以太网三. 浅谈DNS域名解析系统一. IP协议 IP协议是位于OSI模型中第三层(网络层)的协议, 在这层上工作的不止这一个协议, 但IP协议是网络层传输所使用的最主流的一种协议, 有IPv4和…...
 | 机试题+算法思路+考点+代码解析 【2023】)
华为OD机试 - 关联子串(Python) | 机试题+算法思路+考点+代码解析 【2023】
关联子串 题目 给定两个字符串str1和str2 如果字符串str1中的字符,经过排列组合后的字符串中 只要有一个是str2的子串 则认为str1是str2的关联子串 若不是关联子串则返回-1 示例一: 输入: str1="abc",str2="efghicaibii" 输出: -1 预制条件: 输入的…...
)
SpringBoot学习笔记(二)
配置文件分类 SpringBoot中4级配置文件 1级:file:config/application.yaml 【最高】 2级:file:application.yml 3级:classpath:config/application.yml 4级:classpath:application.…...

亚马逊云科技SageMaker:实现自动、可视化管理迭代
现如今,AI正在成为跨时代的技术,在数字经济发展中登上舞台,发挥关键作用。在Gartner发布的《2022年新兴技术成熟度曲线》*报告中,AIGC(即AI Generated Content,人工智能自动生成内容)被列为2022…...

汽车 Automotive > CAN Transceivers收发器选择
参考:https://www.nxp.com/products/interfaces/can-transceivers/3-3-v-5-v-io-can-transceivers:33VIO-CAN3.3 V / 5V IO CAN收发器组合TJA1042高速CAN收发器,具有待机模式,适用于所有类型的高速CAN网络,在需要低功耗模式的节点…...

AI将如何影响程序员的未来,以及如何不被AI所替代。
随着人工智能技术的不断发展,越来越多的工作被自动化和智能化所取代,其中程序员这个职业也不例外。然而,我们需要客观地分析AI在未来对程序员的影响,并且给出建议,以便程序员能够保持竞争力,不被AI所取代。…...

nginx 常用配置之 pass_proxy
大家好,我是 17。 今天和大家聊聊 pass_proxy 代理。 pass_proxy 代理 在前端代理主要是为了跨域。虽然前端跨域有多种方法,各有利弊,但用代理来跨域对开发是最友好的。用代理可以不用修改产品代码切换线上线下,非常安全。pass…...

Linux中驱动模块加载方法分析
如何管理驱动模块 由于Linux驱动模块众多,系统对模块加载顺序有要求,一些基础模块在系统启动时需要很早就被加载;开发者加入自己的模块时,需要维护一个模块初始化列表,上面两方面的做起来很困难,为了科学地…...

yarn 通过 resolutions,指定子孙依赖包版本号,解决froala-editor 版本问题
前端开发项目过程中会使用到各种依赖包。但是这些依赖包虽然好用,但是一味使用最新版本可能会出现各种奇葩问题,因此我们经常会针对一些依赖包指定一个稳定版本。 常用版本 版本号注释“1.0.2”必须切到1.0.2版“>1.0.2”必须大于1.0.2版“>1.0.…...
Elasticsearch7.8.0版本进阶——多文档操作流程
目录一、多文档操作1.1、多文档操作的概述1.2、多文档操作与单文档模式区别二、用单个 mget 请求取回多个文档2.1、用单个 mget 请求取回多个文档的图解2.2、用单个 mget 请求取回多个文档的步骤三、bulk API 的模式请求取回多个文档3.1、bulk API 的模式请求取回多个文档的图解…...
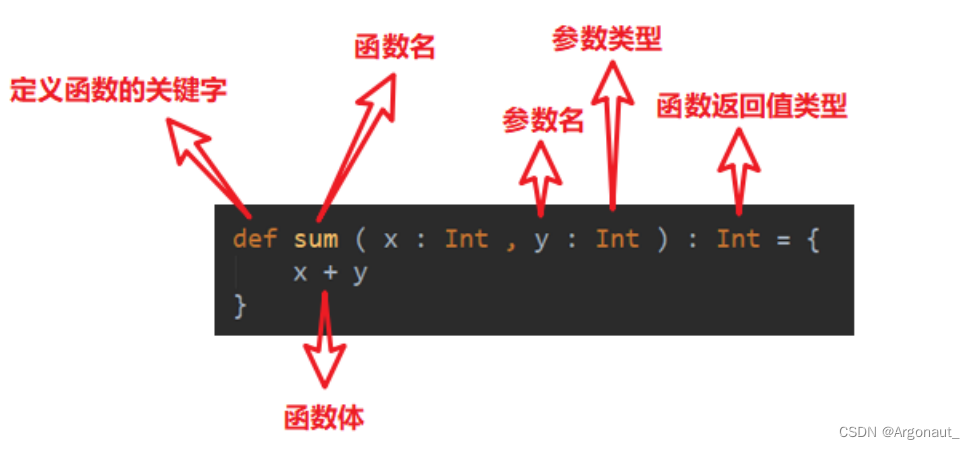
Scala函数式编程(第五章:函数基础、函数高级详解)
文章目录第 5 章 函数式编程5.1 函数基础5.1.1 函数基本语法5.1.2 函数和方法的区别5.1.3 函数定义5.1.4 函数参数5.1.5 函数至简原则(重点)5.2 函数高级5.2.1 高阶函数5.2.2 匿名函数5.2.3 高阶函数案例5.2.4 函数柯里化&闭包5.2.5 递归5.2.6 控制抽…...

ZED相机快速使用指南
1、安装SDK ZED SDK 3.8 - Download | Stereolabs 2、安装ros GitHub - stereolabs/zed-ros-wrapper: ROS wrapper for the ZED SDK 其他教程:ZED2相机SDK安装使用及ROS下使用_可即的博客-CSDN博客 3、官方文档 Get Started with ZED | Stereolabs 4、标定参…...
树莓派4b配置OpenWrt联网
文章目录前言一、下载固件二、配置wan口三、简单介绍1、修改无线名称、设置密码2、下载软件包总结前言 树莓派4b内置wifi模块,加一个千兆网口 好像有一种办法,通过无线wifi链接其他wifi通网,然后把这个网口作为lan口,连接电脑使…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...
)
保姆级教程:手把手教你搞定ESXi 6.7安装前的BIOS设置(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7安装前的BIOS设置终极指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我记得自己第一次在Dell PowerEdge服务器上安装ESXi时,光是搞清楚BIOS里那些晦涩的选项就花了整整一…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

机器学习加速分子晶体偏振拉曼光谱模拟:非谐效应与准谐效应的分离
1. 项目概述:当机器学习遇见偏振拉曼光谱 偏振-取向拉曼光谱(PO-Raman)一直是我在材料光谱分析领域里觉得既迷人又头疼的技术。它就像给材料的“分子指纹”加上了方向滤镜,能揭示出振动模式在空间中的对称性和各向异性,…...