入门ElasticSearch :为什么选择ES作为搜索引擎?
介绍
随着数据量的不断增长,搜索和分析大规模数据集变得越来越重要。传统数据库在面对这种需求时往往表现不佳,这时候就需要一种专门用于搜索和分析的引擎。ElasticSearch (简称ES)就是这样一款强大的搜索引擎,它具有许多优势,使得它成为许多企业和开发者的首选。
简单的说:ElasticSearch 是一个实时的分布式存储、搜索、分析的引擎
在我看来ES最强的其实是它的模糊搜索功能。
那有的人就会问了:我数据库一样可以实现模糊搜索啊?
select * from student where name like '%宁正%'
例如这个sql就可以查出姓名中带有宁正两字的学生
的确,这这样做是可以模糊搜索的,但是name like '%宁正%'这种写法它是不走索引的,所以就意味着:如果你的数据量很大比如上千万,上亿条,那你不管如果去优化代码,你的查询也肯定是秒级的
并且还有一个情况,我们大部分搜索的时候,输入的信息其实并不是很准确,例如我想搜索ElasticSearch 有关的信息,但我一不小心打成了ElesticSearch ,如果按sql语句去进行模糊搜索你就无法找到和es有关的信息
所以在这种情况就可以使用ElasticSearch ,它就是为了搜索而生的。
因此,我这边就把es的优点罗列出来,并进行浅显的分析:
ES对于全文的模糊搜索非常擅长
原因:ES是基于倒排索引,使得ES能够快速匹配关键字并返回相关结果,而不需要像传统数据库那样进行全表扫描。倒排索引在存储和查询大规模文本数据时具有较高的效率。
那有些小伙伴看了可能就会问了:倒排索引是什么?倒排索引和正排索引有什么区别?我们日常使用的数据库可以使用倒排索引吗?
那接下来就一个一个回答:
倒排索引是什么?
倒排索引是一种基于关键词的索引结构,常用于全文搜索引擎和信息检索系统中。它是一种将文档中的关键词映射到对应的文档ID的数据结构。
具体来说,倒排索引将文档中的每个关键词与包含该关键词的文档ID建立映射。对于每个关键词,倒排索引记录了出现该关键词的文档列表,包括它们的词频、位置等信息。这使得在给定关键词的情况下,可以快速找到包含该关键词的相关文档。
倒排索引和正排索引有什么区别?
正排索引是一种文档ID进行排序的索引结构,它存储了文档和文档中的每个词条的详细信息。
我有一个通俗易懂的方法来表达:
正排索引就想我们看书时的目录,可以直接通过页码找到对应页码的内容
而倒排索引就是将整本书中的词汇提取出来,并记录改词汇存在于哪些页码中,形成映射关系,当我想要查找一个词汇出现在哪些页中时,便只要根据这个映射表就可以快速找到想要的页数
这么一解释,大家应该就清楚了。
我们日常使用的数据库可以使用倒排索引吗?
实际上,数据库是可以支持倒排索引的,但是与传统的正排索引相比,数据库倒排索引的实现相对有些复杂,而且数据库的主要设计目标是支持高效的数据管理和事务处理,而不是专注于全文搜索等复杂的查询需求
ES的查询语法更灵活,可以精确控制查询条件和权重,以及进行更复杂的模糊搜索
Elasticsearch的查询语法相当灵活,可以根据需要控制查询条件和权重,以及执行诸如布尔查询、范围查询、模糊查询,地理位置等复杂查询。通过使用查询语法,可以实现更精确的搜索。
我这边写一个基于自身地理位置查询的一个demo
geoDistanceQuery是一种地理位置查询,用于查询距离某个地理坐标点一定距离范围内的文档。只需要提供一个地理点的经纬度坐标和一个距离,以及一个单位:
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
GeoDistanceQueryBuilder geoQuery = QueryBuilders.geoDistanceQuery("local").point(lat, lon) // 地理位置坐标.distance(distance, DistanceUnit.KILOMETERS); // 查询距离sourceBuilder.query(geoQuery);
SearchRequest searchRequest = new SearchRequest("indexName");
searchRequest.source(sourceBuilder);// 执行查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
在上面的demo中,我们创建了一个geoDistanceQuery来查询location字段在给定地理位置坐标的一定距离范围内的文档。这里使用的是公里作为单位。
ES提供了丰富的聚合和分析功能
ES原生的提供了丰富的聚合和分析功能,可以对结果进行聚合、分组、排序等多种操作,并且ES还提供了许多其他的分析功能,如词频统计、日期直方图等。这些功能可以帮助用户更深入地理解数据,生成仪表板和可视化图表。
我在这边也写一个较为简单的demo,看一看就好,详细的之后的博客会讲解
假设我们有一个索引存储了电影信息,包含字段:title(电影标题)、genre(电影类型)和rating(电影评分)。
现在,我们希望对不同类型的电影进行聚合,并计算每个类型的平均评分。
首先,我们需要构建一个聚合查询,指定按genre字段进行分组,并计算每个分组的平均值。
GET movies/_search
{"size": 0,//指定聚合操作的容器"aggs": { //聚合操作起的一个名字"genres": { //指定分组字段的聚合操作类型"terms": { // 指定要分组的字段"field": "genre"},"aggs": {//平均值聚合操作起的一个名字"avg_rating": {//计算均值的聚合操作类型"avg": {//操作的字段"field": "rating"}}}}}
}
在上面的查询中,我们使用terms聚合将电影按照genre字段进行分组,并使用avg聚合计算每个分组的rating字段的平均值。
就会得到以下类似的结果:
"aggregations" : {"genres" : {"buckets" : [{"key" : "Action","doc_count" : 100,"avg_rating" : {"value" : 4.2}},{"key" : "Drama","doc_count" : 80,"avg_rating" : {"value" : 3.8}},...]}
}
Action类的电影有100部平均评分4.2, Drama类的电影有80部平均评分3.8
这只是聚合和分析功能的一个简单示例,实际上ES提供了更多丰富的聚合操作和分析功能,可以根据具体需求进行更复杂的操作
ES使用分布式架构,能够更好地处理大规模数据和高并发查询
ES分布式架构在水平扩展上的表现出色,通过将数据分片存储在多个节点上,ES可以处理大规模数据,并且能够通过并行化查询和分布式计算来提高查询性能。
这个在这就不细讲了,之后具体介绍的是会讲述。
那我们是无脑上ES吗,还是说要在一个特定的情况下呢?
第一个问题的回答,显而易见的当然是不能无脑上ES!
- ES虽然功能强大,但也很复杂。使用它需要一定的学习和理解。如果没有适当的培训或经验,可能会遇到配置错误、性能问题、索引和查询错误等
- ES是一个分布式系统,需要适当的硬件和资源支持才能正常运行。如果部署不当就会导致性能问题或资源浪费。
- ES需要进行适当的管理和维护,包括监控集群健康状况、备份和恢复数据、更新和升级等。如果没有正确进行管理和维护,可能会遇到数据丢失、性能下降或安全风险
- 成本!成本!还是成本!
第二个问题,那我们什么时候才要用ES呢?
在我看来可以从以下几个方法来考虑:
- 数据规模,如果你要处理的数据高到百万甚至上亿,那你完全可以使用ES来处理大量的数据集
- 搜索复杂度,如果你需要经常的对全文数据进行复杂的文本查询和顾虑,那ES是一个比较好的选择
- 实时性,如果你需要快速地分析实时数据,那ES是一个合适的选择,它支持实时数据索引和查询,可以在数据到达时即时进行分析和可视化
- 分布式和高可用性需求,如果你需要一个可扩展的,具有高可用性和容错性的数据存储和分析解决方案,那ES是一个合适的选择
所以不要因为这个技术比较厉害就无脑的去使用该技术,在使用技术的时候也要考虑到它所带来的风险
相关文章:

入门ElasticSearch :为什么选择ES作为搜索引擎?
介绍 随着数据量的不断增长,搜索和分析大规模数据集变得越来越重要。传统数据库在面对这种需求时往往表现不佳,这时候就需要一种专门用于搜索和分析的引擎。ElasticSearch (简称ES)就是这样一款强大的搜索引擎,它具有许…...

汽车安全及标准
汽车安全及标准 我们的测试系统如何处理整个标准? 您是否需要处理汽车行业的一系列标准? 不同的标准侧重于驱动逆变器的安全性和功能性: 功能安全(ISO 26262)信号和低压车载网络(LV 124、LV 148 和 VDA …...
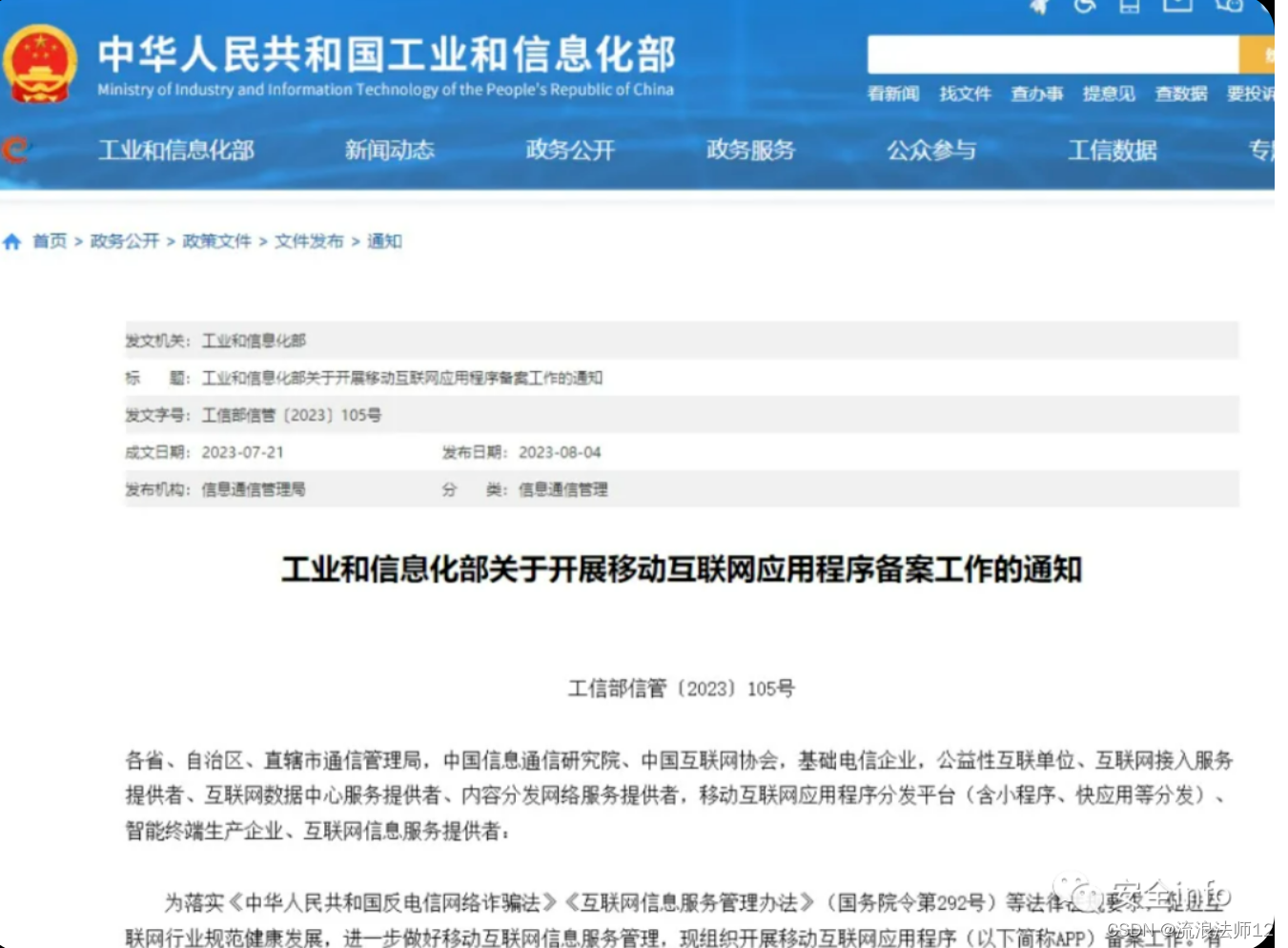
APP备案流程详细解读
背景介绍 2023年8月4日,工信部发布《工业和信息化部关于开展移动互联网应用程序备案工作的通知》。 在中华人民共和国境内从事互联网信息服务的APP主办者,应当依照《中华人民共和国反电信网络诈骗法》《互联网信息服务管理办法》(国务院令第…...
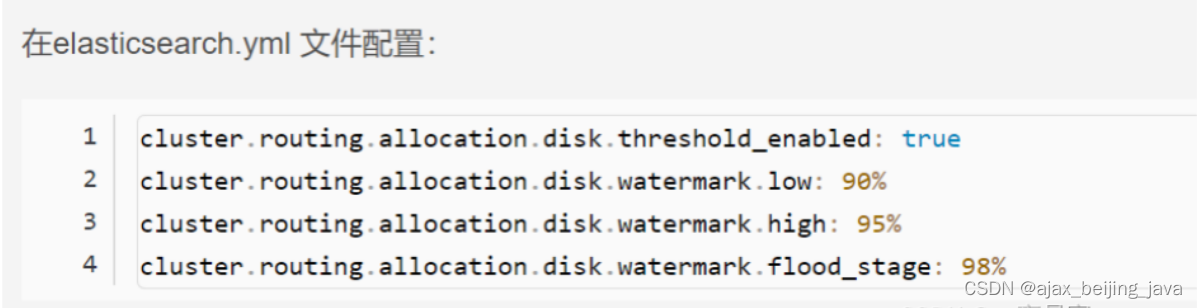
ES 集群常用排查命令
说明:集群使用非默认端口9200,使用的是7116端口举例 一、常用命令 #1.集群健康状态 [wlsadminelastic-01~]$ curl -XGET "http://10.219.27.00:7116/_cluster/health?pretty" { cluster name":"cluster" "status"…...

Nougat 深度剖析
Nougat 深度剖析 项目地址:https://github.com/facebookresearch/nougat 论文地址:Nougat: Neural Optical Understanding for Academic Documents 0 背景 近日,MetaAI又放了大招,他们提出了一种全新的端到端的OCR模型&#x…...

ffmpeg的使用
本文章记录ffmpeg 源码下载,编译,及使用。 一、FFMPEG 源码下载解压 源码官网地址:http://ffmpeg.org/download.html#releases 下载最新版本ffmpeg6.0。 使用命令tar xvJf ffmpeg-6.0.tar.xz 解压。 二、了解FFMPEG源码 (一&am…...

深度强化学习算法的参数更新时机
深度强化学习算法的参数更新时机 深度强化学习中往往涉及到多个神经网络来拟合策略函数、值函数等,什么时候更新参数因算法而异,与具体算法架构/算法思想紧密相关。 算法参数更新时机架构DQN先收集一定经验,然后每步更新Off Policy Value-B…...
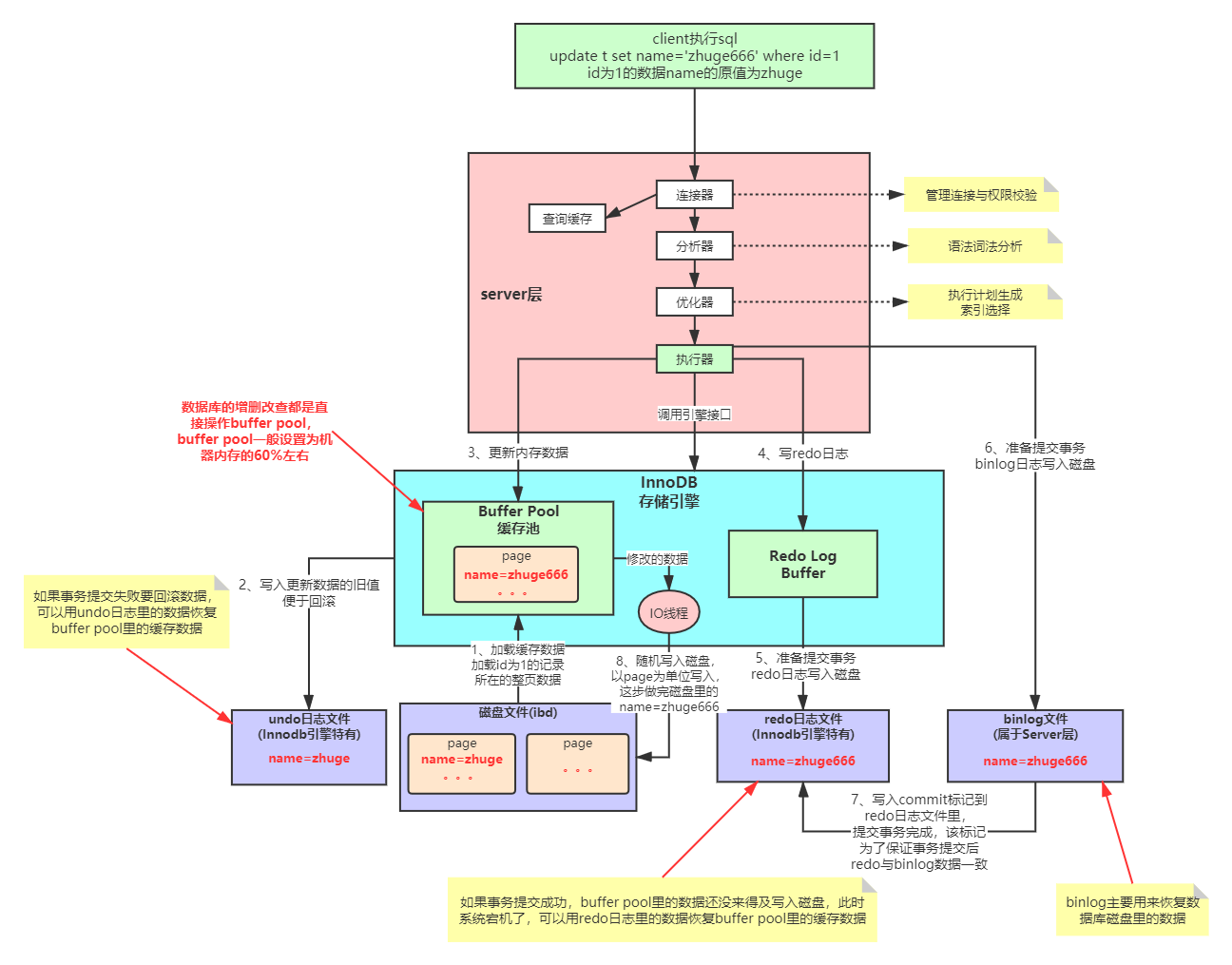
【进阶篇】MySQL的MVCC实现机制详解
文章目录 0.前言1.基础介绍1.1. 什么是MVCC?1.1. 什么是当前读和快照读?1.1. 当前读,快照读和MVCC的关系1.1. MVCC能解决什么问题,好处是?1.1.1. 提高并发性能1.1.2. 避免死锁1.1.3. 解决脏读、不可重复读和幻读等问题1.1.4. 实现…...

Git 命令行查看仓库信息
目录 查看系统config 编辑查看当前用户(global)配置 查看当前仓库配置信息 查看系统config git config --system --list 1 查看当前用户(global)配置 git config --global --list 1 查到的是email , name 等ssl签名信息&a…...

【爬虫】8.1. 深度使用tesseract-OCR技术识别图形验证码
深度使用tesseract-OCR技术识别图形验证码 文章目录 深度使用tesseract-OCR技术识别图形验证码1. OCR技术2. 准备工作3. 简单作用了解3.1. 验证码图片爬取-screenshot_as_png3.2. 识别测试-image_to_string3.2.1. 正确识别3.2.2. 错误识别3.2.3. 灰度调节 3.3. 识别实战-使用im…...

【PythonRS】基于GDAL修改栅格数据的DN值
遥感工作者离不开栅格数据,有时候我们可能需要修改栅格数据的值,但ENVI和ArcGIS中并没有直接修改DN值的工具,只有栅格计算器、Band math这些工具去计算整个波段的值,或者Edit Classification Image工具可以修改ENVI分类后的像元值…...

mysql课堂笔记 mac
目录 启动mac上的mysql 进入mysql mac windows 创建数据库 创建表 修改字段数据类型 修改字段名 增加字段 删除字段 启动mac上的mysql sudo /usr/local/mysql/support-files/mysql.server start 直接输入你的开机密码即可。 编辑 进入mysql mac sudo /usr/local…...

2023年数学建模国赛A 定日镜场的优化设计思路分析
构建以新能源为主体的新型电力系统,是我国实现“碳达峰”“碳中和”目标的一项重要措施。塔式太阳能光热发电是一种低碳环保的新型清洁能源技术[1]。定日镜是塔式太阳能光热发电站(以下简称塔式电站)收集太阳能的基本组件,其底座由…...

【QT】QMessageBox消息框的使用(16)
在实际项目中,弹出消息框是一个很常见的操作,包含错误信息提示、警告信息提示、关于信息提示、还包括判断信息选择等操作,那么今天通过这一节来好好了解下消息框的使用方法。 一.环境配置 1.python 3.7.8 可直接进入官网下载安装…...
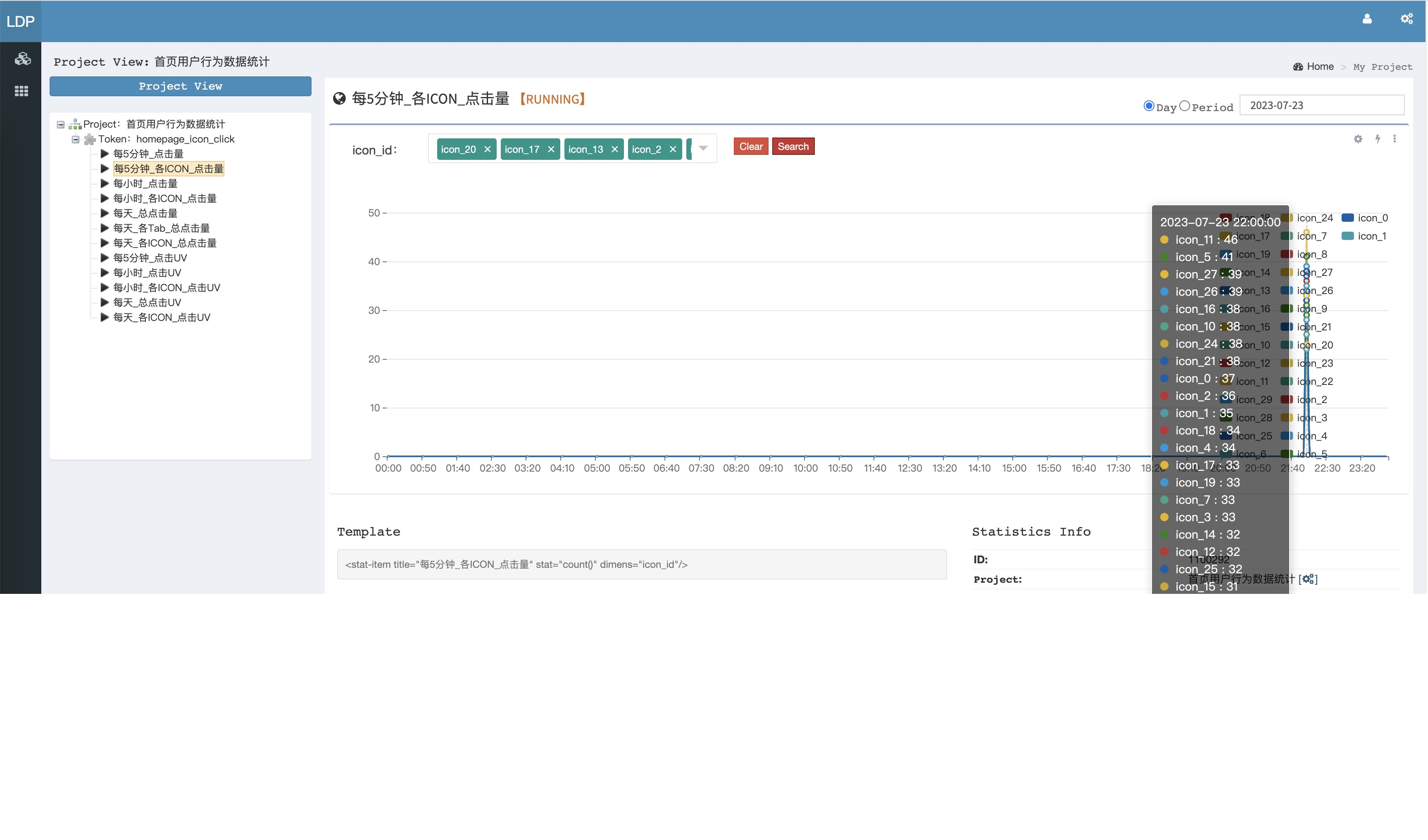
XL-LightHouse 与 Flink 和 ClickHouse 流式大数据统计系统
一个Flink任务只能并行处理一个或少数几个数据流,而XL-LightHouse一个任务可以并行处理数万个、几十万个数据流; 一个Flink任务只能实现一个或少数几个数据指标,而XL-LightHouse单个任务就能支撑大批量、数以万计的数据指标。 1、XL-LightHo…...

【postgresql 基础入门】创建数据库的方法,存储位置,决定自己的数据的访问用户和范围
创建数据库 专栏内容: postgresql内核源码分析手写数据库toadb并发编程 开源贡献: toadb开源库 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地势坤,君…...

科技云报道:AI时代,对构建云安全提出了哪些新要求?
科技云报道原创。 随着企业上云的提速,一系列云安全问题也逐渐暴露出来,云安全问题得到重视,市场不断扩大。 Gartner 发布“2022 年中国 ICT 技术成熟度曲线”显示,云安全已处于技术萌芽期高点,预期在2-5年内有望达到…...

如何让 Llama2、通义千问开源大语言模型快速跑在函数计算上?
:::info 本文是“在Serverless平台上构建AIGC应用”系列文章的第一篇文章。 ::: 前言 随着ChatGPT 以及 Stable Diffusion,Midjourney 这些新生代 AIGC 应用的兴起,围绕AIGC应用的相关开发变得越来越广泛,有呈井喷之势,从长远看这波应用的爆…...
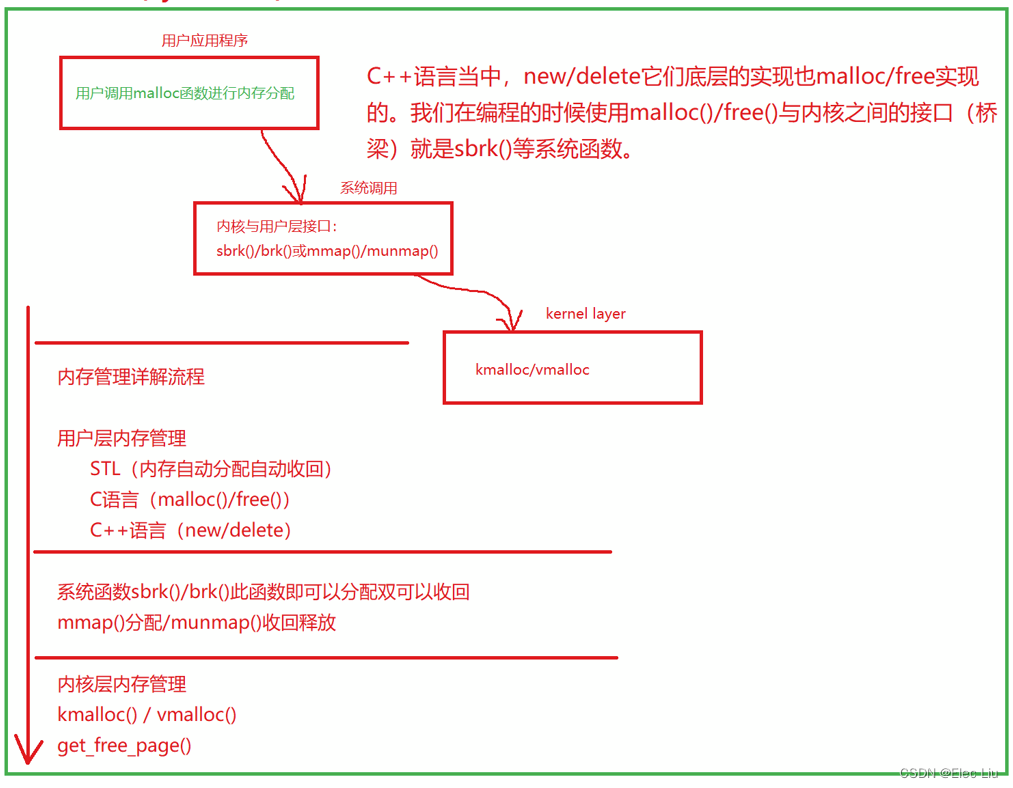
Linux内核源码分析 (B.2)虚拟地址空间布局架构
Linux内核源码分析 (B.2)虚拟地址空间布局架构 文章目录 Linux内核源码分析 (B.2)虚拟地址空间布局架构一、Linux内核整体架构及子系统二、Linux内核内存管理架构 一、Linux内核整体架构及子系统 Linux内核只是操作系统当中的一部分,对下管理系统所有硬件设备&…...
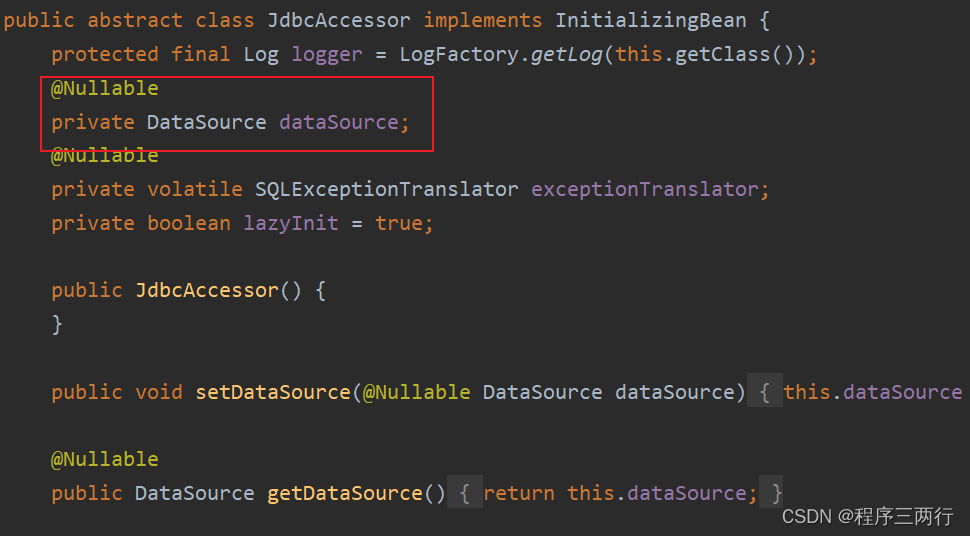
Spring系列文章:Spring使用JdbcTemplate
一、简介 JdbcTemplate是Spring提供的⼀个JDBC模板类,是对JDBC的封装,简化JDBC代码。 当然,你也可以不⽤,可以让Spring集成其它的ORM框架,例如:MyBatis、Hibernate等。 第一步:引入依赖 <d…...

妙趣AI:开源Agent工具链与AI导航平台的工程实践
1. 妙趣AI:一个AI工具导航与开源Agent生态的实践如果你和我一样,每天被各种新冒出来的AI工具、模型和概念搞得眼花缭乱,同时又对“AI Agent”这个听起来很酷但落地很虚的东西充满好奇,那么“妙趣AI”这个项目可能正是你需要的。它…...
轻量级车联网音视频集群)
基于 JTT1078MediaServer 的集群方案实践(Nginx + 溯源模式)轻量级车联网音视频集群
基于JTT1078MediaServer的集群方案实践(Nginx溯源模式)轻量级车联网音视频集群 在车联网JT/T1078音视频平台开发与部署中,单机JTT1078MediaServer在设备量少、并发低时可稳定运行,但随着接入设备增多、多路视频同时播放࿰…...

C# 从零开发 MCP 工具基础教程
在C#编程领域,MCP(Managed Code Programming,托管代码编程)工具能极大提升开发效率与代码管理能力。无论是代码分析、自动化构建,还是调试辅助,一款实用的MCP工具都能成为开发者的得力助手。本教程将带你从…...

外科医生AI认知变迁:从技术好奇到价值驱动的全球调查
1. 项目概述:一场关于外科医生与AI认知变迁的全球对话作为一名长期关注技术与医疗交叉领域的从业者,我始终对一个问题抱有浓厚兴趣:当一项颠覆性技术从实验室走向临床,真正使用它的医生们究竟在想什么?他们的期待、困惑…...

如何高效使用炉石传说脚本:终极完整指南解决你的自动化难题
如何高效使用炉石传说脚本:终极完整指南解决你的自动化难题 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 你是否厌倦了炉石传说中重复性的…...

英特尔转型芯片代工:从IDM巨头到服务商的六大挑战与机遇
1. 英特尔代工之路:从IDM巨头到服务提供商的六大挑战在半导体行业,英特尔这个名字几乎就是高性能微处理器的代名词。这家公司凭借其垂直整合制造模式,在过去几十年里构筑了难以撼动的技术护城河。然而,当行业的目光从单纯的制程竞…...

扩散模型如何重塑建筑设计流程:从概念生成到性能优化的AI协作
1. 项目概述:当AI成为建筑师的“副驾驶”几年前,当我在设计院通宵达旦地对着屏幕调整一个曲面屋顶的参数时,我就在想,有没有一种工具,能让我把脑子里那个模糊的意象,瞬间变成可供推敲的视觉草稿?…...

Steam SDK上传游戏包体避坑指南:路径、验证码与BuildID那些事儿
Steam SDK上传游戏包体避坑指南:路径、验证码与BuildID那些事儿 第一次通过Steam SDK上传游戏包体时,开发者往往会遇到各种意料之外的"坑"。这些看似小问题却可能导致数小时的无效排查。本文将从实战角度,分享那些官方文档没细说但…...

从图文到视频:用 Python 打造公众号文章自动化转视频号的爆款流水线
摘要:本文详解一套完全基于开源工具(Python + edge-tts + ffmpeg)的自动化系统,可将任意微信公众号文章一键转换为横屏/竖屏视频,直接用于视频号分发。全程无需剪辑软件、无需出镜、无需复杂配置,5 分钟部署,1 条命令生成专业级视频。 🔥 为什么你需要这个? 在 AIGC…...

3步终极指南:用开源TCC-G15彻底解决Dell G15散热难题
3步终极指南:用开源TCC-G15彻底解决Dell G15散热难题 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否正在为Dell G15笔记本的过热问题而烦恼…...