Scala集合详解(第七章:集合、数组、列表、set集合、map集合、元组、队列、并行)(尚硅谷笔记)
集合
- 第七章:集合
- 7.1 集合简介
- 7.1.1 不可变集合继承图
- 7.1.2 可变集合继承图
- 7.2 数组
- 7.2.1 不可变数组
- 7.2.2 可变数组
- 7.2.3 不可变数组与可变数组的转换
- 7.2.4 多维数组
- 7.3 列表 List
- 7.3.1 不可变 List
- 7.3.2 可变 ListBuffer
- 7.4 Set 集合
- 7.4.1 不可变 Set
- 7.4.2 可变 mutable.Set
- 7.5 Map 集合
- 7.5.1 不可变 Map
- 7.5.2 可变 Map
- 7.6 元组
- 7.7 集合常用函数
- 7.7.1 基本属性和常用操作
- 7.7.2 衍生集合
- 7.7.3 集合计算简单函数
- 7.7.4 集合计算高级函数
- 7.7.5 普通 WordCount 案例
- 7.7.6 复杂 WordCount 案例
- 7.8 队列
- 7.9 并行集合
第七章:集合
7.1 集合简介
1)Scala 的集合有三大类:序列 Seq、集 Set、映射 Map,所有的集合都扩展自 Iterable
特质。
2)对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两
个包
- 不可变集合:scala.collection.immutable
- 可变集合: scala.collection.mutable
3)Scala 不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而
不会对原对象进行修改。类似于 java 中的 String 对象
4)可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。类似
于 java 中 StringBuilder 对象
建议:在操作集合的时候,不可变用符号,可变用方法
7.1.1 不可变集合继承图
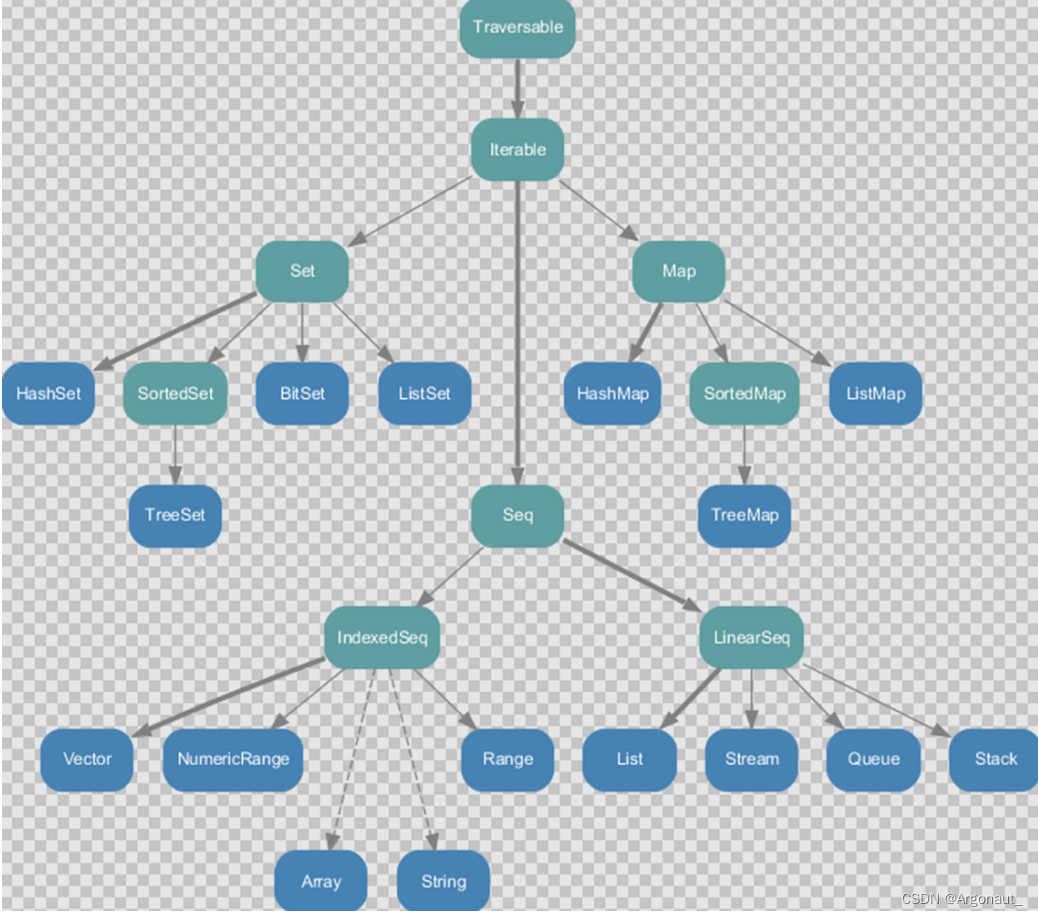
1)Set、Map 是 Java 中也有的集合
2)Seq 是 Java 没有的,我们发现 List 归属到 Seq 了,因此这里的 List 就和 Java 不是同一个
概念了
3)我们前面的 for 循环有一个 1 to 3,就是 IndexedSeq 下的 Range
4)String 也是属于 IndexedSeq
5)我们发现经典的数据结构比如 Queue 和 Stack 被归属到 LinearSeq(线性序列)
6)大家注意 Scala 中的 Map 体系有一个 SortedMap,说明 Scala 的 Map 可以支持排序
7)IndexedSeq 和 LinearSeq 的区别:
- (1)IndexedSeq 是通过索引来查找和定位,因此速度快,比如 String 就是一个索引集合,通过索引即可定位
- (2)LinearSeq 是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找
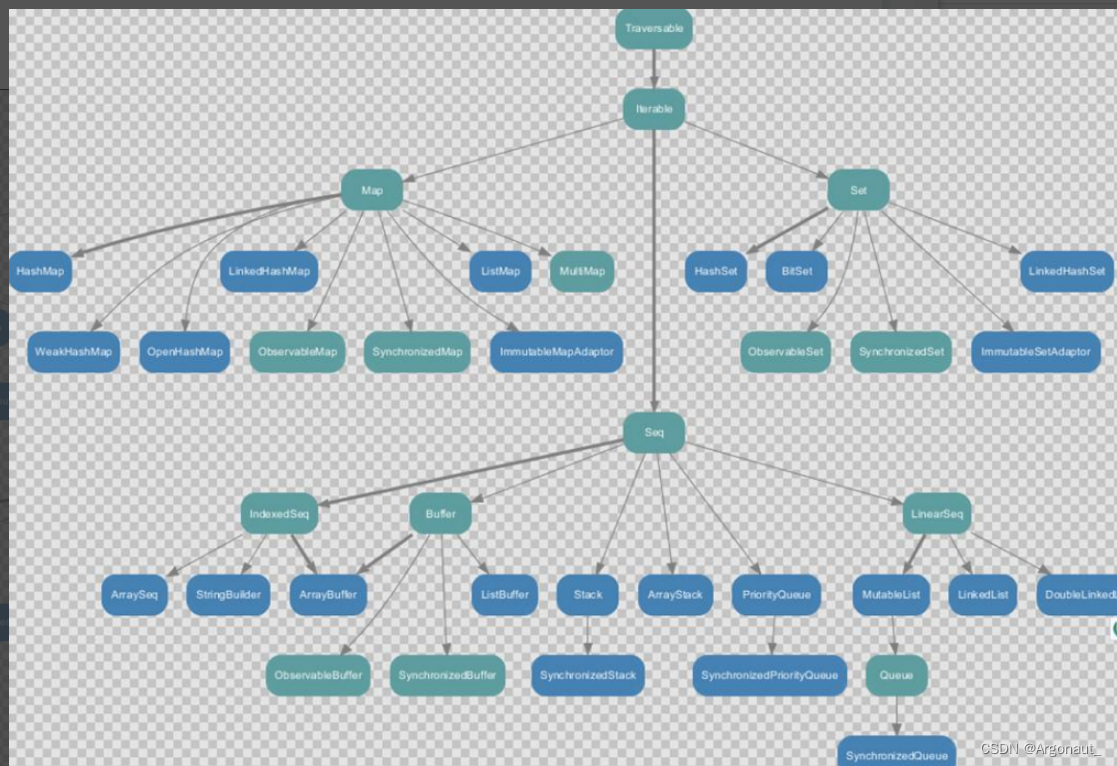
7.1.2 可变集合继承图
7.2 数组
7.2.1 不可变数组
加粗样式1)第一种方式定义数组
定义:val arr1 = new ArrayInt
- (1)new 是关键字
- (2)[Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定 Any
- (3)(10),表示数组的大小,确定后就不可以变化
2)案例实操
object TestArray{def main(args: Array[String]): Unit = {//(1)数组定义val arr01 = new Array[Int](4)println(arr01.length) // 4//(2)数组赋值//(2.1)修改某个元素的值arr01(3) = 10//(2.2)采用方法的形式给数组赋值arr01.update(0,1)//(3)遍历数组//(3.1)查看数组println(arr01.mkString(","))//(3.2)普通遍历for (i <- arr01) {println(i)}//(3.3)简化遍历def printx(elem:Int): Unit = {println(elem)}arr01.foreach(printx)// arr01.foreach((x)=>{println(x)})// arr01.foreach(println(_))arr01.foreach(println)//(4)增加元素(由于创建的是不可变数组,增加元素,其实是产生新的数
组)println(arr01)val ints: Array[Int] = arr01 :+ 5println(ints)}
}
3)第二种方式定义数组
val arr1 = Array(1, 2)
- (1)在定义数组时,直接赋初始值
- (2)使用 apply 方法创建数组对象
4)案例实操
object TestArray{def main(args: Array[String]): Unit = {var arr02 = Array(1, 3, "bobo")println(arr02.length)for (i <- arr02) {println(i)}}
}
7.2.2 可变数组
1)定义变长数组
val arr01 = ArrayBuffer[Any](3, 2, 5)
- (1)[Any]存放任意数据类型
- (2)(3, 2, 5)初始化好的三个元素
- (3)ArrayBuffer 需要引入 scala.collection.mutable.ArrayBuffer
2)案例实操
- (1)ArrayBuffer 是有序的集合
- (2)增加元素使用的是 append 方法(),支持可变参数
import scala.collection.mutable.ArrayBuffer
object TestArrayBuffer {def main(args: Array[String]): Unit = {//(1)创建并初始赋值可变数组val arr01 = ArrayBuffer[Any](1, 2, 3)//(2)遍历数组for (i <- arr01) {println(i)}println(arr01.length) // 3println("arr01.hash=" + arr01.hashCode())//(3)增加元素//(3.1)追加数据arr01.+=(4)//(3.2)向数组最后追加数据arr01.append(5,6)//(3.3)向指定的位置插入数据arr01.insert(0,7,8)println("arr01.hash=" + arr01.hashCode())//(4)修改元素arr01(1) = 9 //修改第 2 个元素的值println("--------------------------")for (i <- arr01) {println(i)}println(arr01.length) // 5}
}
7.2.3 不可变数组与可变数组的转换
1)说明
arr1.toBuffer //不可变数组转可变数组
arr2.toArray //可变数组转不可变数组
- (1)arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化
- (2)arr1.toBuffer 返回结果才是一个可变数组,arr1 本身没有变化
2)案例实操
object TestArrayBuffer {def main(args: Array[String]): Unit = {//(1)创建一个空的可变数组val arr2 = ArrayBuffer[Int]()//(2)追加值arr2.append(1, 2, 3)println(arr2) // 1,2,3//(3)ArrayBuffer ==> Array//(3.1)arr2.toArray 返回的结果是一个新的定长数组集合//(3.2)arr2 它没有变化val newArr = arr2.toArrayprintln(newArr)//(4)Array ===> ArrayBuffer//(4.1)newArr.toBuffer 返回一个变长数组 newArr2//(4.2)newArr 没有任何变化,依然是定长数组val newArr2 = newArr.toBuffernewArr2.append(123)println(newArr2)}}
7.2.4 多维数组
1)多维数组定义
val arr = Array.ofDimDouble
说明:二维数组中有三个一维数组,每个一维数组中有四个元素
2)案例实操
object DimArray {def main(args: Array[String]): Unit = {//(1)创建了一个二维数组, 有三个元素,每个元素是,含有 4 个元素一维
数组()val arr = Array.ofDim[Int](3, 4)arr(1)(2) = 88//(2)遍历二维数组for (i <- arr) { //i 就是一维数组for (j <- i) {print(j + " ")}println()}}
}
7.3 列表 List
7.3.1 不可变 List
1)说明
- (1)List 默认为不可变集合
- (2)创建一个 List(数据有顺序,可重复)
- (3)遍历 List
- (4)List 增加数据
- (5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化
- (6)取指定数据
- (7)空集合 Nil
2)案例实操
object TestList {def main(args: Array[String]): Unit = {//(1)List 默认为不可变集合//(2)创建一个 List(数据有顺序,可重复)val list: List[Int] = List(1,2,3,4,3)//(7)空集合 Nilval list5 = 1::2::3::4::Nil//(4)List 增加数据//(4.1)::的运算规则从右向左//val list1 = 5::listval list1 = 7::6::5::list//(4.2)添加到第一个元素位置val list2 = list.+:(5)//(5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化val list3 = List(8,9)//val list4 = list3::list1val list4 = list3:::list1//(6)取指定数据println(list(0))//(3)遍历 List//list.foreach(println)//list1.foreach(println)//list3.foreach(println)//list4.foreach(println)list5.foreach(println)}
}
7.3.2 可变 ListBuffer
1)说明
- (1)创建一个可变集合 ListBuffer
- (2)向集合中添加数据
- (3)打印集合数据
2)案例实操
import scala.collection.mutable.ListBuffer
object TestList {def main(args: Array[String]): Unit = {//(1)创建一个可变集合val buffer = ListBuffer(1,2,3,4)//(2)向集合中添加数据buffer.+=(5)
buffer.append(6)
buffer.insert(1,2)//(3)打印集合数据buffer.foreach(println)
//(4)修改数据
buffer(1) = 6
buffer.update(1,7)
//(5)删除数据
buffer.-(5)
buffer.-=(5)
buffer.remove(5)}
}
7.4 Set 集合
默认情况下,Scala 使用的是不可变集合,如果你想使用可变集合,需要引用
scala.collection.mutable.Set 包
7.4.1 不可变 Set
1)说明
- (1)Set 默认是不可变集合,数据无序
- (2)数据不可重复
- (3)遍历集合
2)案例实操
object TestSet {def main(args: Array[String]): Unit = {//(1)Set 默认是不可变集合,数据无序val set = Set(1,2,3,4,5,6)//(2)数据不可重复val set1 = Set(1,2,3,4,5,6,3)//(3)遍历集合for(x<-set1){println(x)}}
}
7.4.2 可变 mutable.Set
1)说明
- (1)创建可变集合 mutable.Set
- (2)打印集合
- (3)集合添加元素
- (4)向集合中添加元素,返回一个新的 Set
- (5)删除数据
2)案例实操
object TestSet {def main(args: Array[String]): Unit = {//(1)创建可变集合val set = mutable.Set(1,2,3,4,5,6)//(3)集合添加元素set += 8//(4)向集合中添加元素,返回一个新的 Setval ints = set.+(9)println(ints)println("set2=" + set)//(5)删除数据set-=(5)//(2)打印集合set.foreach(println)println(set.mkString(","))}
}
7.5 Map 集合
Scala 中的 Map 和 Java 类似,也是一个散列表,它存储的内容也是键值对(key-value)
映射
7.5.1 不可变 Map
1)说明
- (1)创建不可变集合 Map
- (2)循环打印
- (3)访问数据
- (4)如果 key 不存在,返回 0
2)案例实操
object TestMap {def main(args: Array[String]): Unit = {// Map//(1)创建不可变集合 Mapval map = Map( "a"->1, "b"->2, "c"->3 )//(3)访问数据for (elem <- map.keys) {// 使用 get 访问 map 集合的数据,会返回特殊类型 Option(选项):
有值(Some),无值(None)println(elem + "=" + map.get(elem).get)}//(4)如果 key 不存在,返回 0println(map.get("d").getOrElse(0))println(map.getOrElse("d", 0))//(2)循环打印map.foreach((kv)=>{println(kv)})}
}
7.5.2 可变 Map
1)说明
- (1)创建可变集合
- (2)打印集合
- (3)向集合增加数据
- (4)删除数据
- (5)修改数据
2)案例实操
object TestSet {def main(args: Array[String]): Unit = {//(1)创建可变集合val map = mutable.Map( "a"->1, "b"->2, "c"->3 )//(3)向集合增加数据map.+=("d"->4)// 将数值 4 添加到集合,并把集合中原值 1 返回val maybeInt: Option[Int] = map.put("a", 4)println(maybeInt.getOrElse(0))//(4)删除数据map.-=("b", "c")//(5)修改数据map.update("d",5)
map("d") = 5//(2)打印集合map.foreach((kv)=>{println(kv)})}
}
7.6 元组
1)说明
元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。说的简单点,就是将多个无关的数据封装为一个整体,称为元组。
注意:元组中最大只能有 22 个元素。
2)案例实操
- (1)声明元组的方式:(元素 1,元素 2,元素 3)
- (2)访问元组
- (3)Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为对偶
object TestTuple {def main(args: Array[String]): Unit = {//(1)声明元组的方式:(元素 1,元素 2,元素 3)val tuple: (Int, String, Boolean) = (40,"bobo",true)//(2)访问元组//(2.1)通过元素的顺序进行访问,调用方式:_顺序号println(tuple._1)println(tuple._2)println(tuple._3)//(2.2)通过索引访问数据println(tuple.productElement(0))//(2.3)通过迭代器访问数据for (elem <- tuple.productIterator) {println(elem)}//(3)Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为
对偶val map = Map("a"->1, "b"->2, "c"->3)val map1 = Map(("a",1), ("b",2), ("c",3))map.foreach(tuple=>{println(tuple._1 + "=" + tuple._2)})}
}
7.7 集合常用函数
7.7.1 基本属性和常用操作
1)说明
- (1)获取集合长度
- (2)获取集合大小
- (3)循环遍历
- (4)迭代器
- (5)生成字符串
- (6)是否包含
2)案例实操
object TestList {def main(args: Array[String]): Unit = {val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7)//(1)获取集合长度println(list.length)//(2)获取集合大小,等同于 lengthprintln(list.size)//(3)循环遍历list.foreach(println)//(4)迭代器for (elem <- list.itera tor) {println(elem)}//(5)生成字符串println(list.mkString(","))//(6)是否包含println(list.contains(3))}
}
7.7.2 衍生集合
1)说明
- (1)获取集合的头
- (2)获取集合的尾(不是头的就是尾)
- (3)集合最后一个数据
- (4)集合初始数据(不包含最后一个)
- (5)反转
- (6)取前(后)n 个元素
- (7)去掉前(后)n 个元素
- (8)并集
- (9)交集
- (10)差集
- (11)拉链
- (12)滑窗
2)案例实操
object TestList {def main(args: Array[String]): Unit = {val list1: List[Int] = List(1, 2, 3, 4, 5, 6, 7)val list2: List[Int] = List(4, 5, 6, 7, 8, 9, 10)//(1)获取集合的头println(list1.head)//(2)获取集合的尾(不是头的就是尾)println(list1.tail)//(3)集合最后一个数据println(list1.last)//(4)集合初始数据(不包含最后一个)println(list1.init)//(5)反转println(list1.reverse)//(6)取前(后)n 个元素println(list1.take(3))println(list1.takeRight(3))//(7)去掉前(后)n 个元素println(list1.drop(3))println(list1.dropRight(3))//(8)并集println(list1.union(list2))//(9)交集println(list1.intersect(list2))//(10)差集println(list1.diff(list2))//(11)拉链 注:如果两个集合的元素个数不相等,那么会将同等数量的数据进
行拉链,多余的数据省略不用println(list1.zip(list2))//(12)滑窗list1.sliding(2, 5).foreach(println)}
}
7.7.3 集合计算简单函数
1)说明
- (1)求和
- (2)求乘积
- (3)最大值
- (4)最小值
- (5)排序
2)实操
object TestList {def main(args: Array[String]): Unit = {val list: List[Int] = List(1, 5, -3, 4, 2, -7, 6)//(1)求和println(list.sum)//(2)求乘积println(list.product)//(3)最大值println(list.max)//(4)最小值println(list.min)//(5)排序// (5.1)按照元素大小排序println(list.sortBy(x => x))// (5.2)按照元素的绝对值大小排序println(list.sortBy(x => x.abs))// (5.3)按元素大小升序排序
println(list.sortWith((x, y) => x < y))
// (5.4)按元素大小降序排序println(list.sortWith((x, y) => x > y))}
}
- (1)sorted 对一个集合进行自然排序,通过传递隐式的 Ordering
- (2)sortBy 对一个属性或多个属性进行排序,通过它的类型。
- (3)sortWith 基于函数的排序,通过一个 comparator 函数,实现自定义排序的逻辑。
7.7.4 集合计算高级函数
1)说明
- (1)过滤 遍历一个集合并从中获取满足指定条件的元素组成一个新的集合
- (2)转化/映射(map)将集合中的每一个元素映射到某一个函数
- (3)扁平化
- (4)扁平化+映射 注:flatMap 相当于先进行 map 操作,在进行 flatten 操作
集合中的每个元素的子元素映射到某个函数并返回新集合 - (5)分组(group) 按照指定的规则对集合的元素进行分组
- (6)简化(归约)
- (7)折叠
2)实操
object TestList {def main(args: Array[String]): Unit = {val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)val nestedList: List[List[Int]] = List(List(1, 2, 3), List(4,
5, 6), List(7, 8, 9))val wordList: List[String] = List("hello world", "hello
atguigu", "hello scala")//(1)过滤println(list.filter(x => x % 2 == 0))//(2)转化/映射println(list.map(x => x + 1))//(3)扁平化println(nestedList.flatten)//(4)扁平化+映射 注:flatMap 相当于先进行 map 操作,在进行 flatten
操作println(wordList.flatMap(x => x.split(" ")))//(5)分组println(list.groupBy(x => x % 2))}
}
3)Reduce 方法
Reduce 简化(归约) :通过指定的逻辑将集合中的数据进行聚合,从而减少数据,最
终获取结果。案例实操
object TestReduce {def main(args: Array[String]): Unit = {val list = List(1,2,3,4)// 将数据两两结合,实现运算规则val i: Int = list.reduce( (x,y) => x-y )println("i = " + i)// 从源码的角度,reduce 底层调用的其实就是 reduceLeft//val i1 = list.reduceLeft((x,y) => x-y)// ((4-3)-2-1) = -2val i2 = list.reduceRight((x,y) => x-y)println(i2)}
}
4)Fold 方法
Fold 折叠:化简的一种特殊情况。
- (1)案例实操:fold 基本使用
object TestFold {def main(args: Array[String]): Unit = {val list = List(1,2,3,4)// fold 方法使用了函数柯里化,存在两个参数列表// 第一个参数列表为 : 零值(初始值)// 第二个参数列表为: 简化规则// fold 底层其实为 foldLeftval i = list.foldLeft(1)((x,y)=>x-y)val i1 = list.foldRight(10)((x,y)=>x-y)println(i)println(i1)}
}
- (2)案例实操:两个集合合并
object TestFold {def main(args: Array[String]): Unit = {// 两个 Map 的数据合并val map1 = mutable.Map("a"->1, "b"->2, "c"->3)val map2 = mutable.Map("a"->4, "b"->5, "d"->6)val map3: mutable.Map[String, Int] = map2.foldLeft(map1)
{(map, kv) => {val k = kv._1val v = kv._2map(k) = map.getOrElse(k, 0) + vmap}}println(map3)}
}
7.7.5 普通 WordCount 案例
1)需求
单词计数:将集合中出现的相同的单词,进行计数,取计数排名前三的结果
2)需求分析
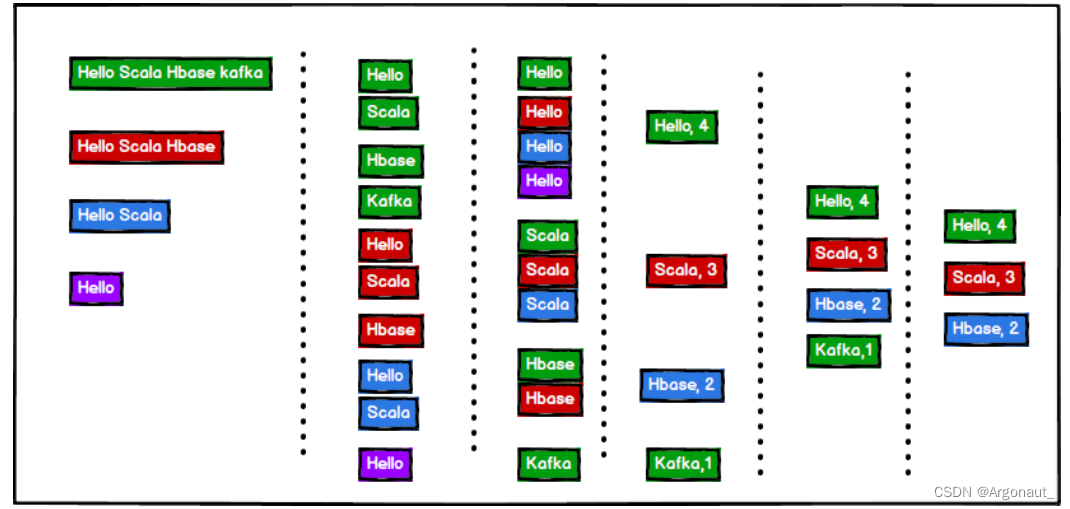
3)案例实操
object TestWordCount {def main(args: Array[String]): Unit = {// 单词计数:将集合中出现的相同的单词,进行计数,取计数排名前三的结
果val stringList = List("Hello Scala Hbase kafka", "Hello
Scala Hbase", "Hello Scala", "Hello")// 1) 将每一个字符串转换成一个一个单词val wordList: List[String] =
stringList.flatMap(str=>str.split(" "))//println(wordList)// 2) 将相同的单词放置在一起val wordToWordsMap: Map[String, List[String]] =
wordList.groupBy(word=>word)//println(wordToWordsMap)// 3) 对相同的单词进行计数// (word, list) => (word, count)val wordToCountMap: Map[String, Int] =
wordToWordsMap.map(tuple=>(tuple._1, tuple._2.size))// 4) 对计数完成后的结果进行排序(降序)val sortList: List[(String, Int)] =
wordToCountMap.toList.sortWith {(left, right) => {left._2 > right._2}}// 5) 对排序后的结果取前 3 名val resultList: List[(String, Int)] = sortList.take(3)println(resultList)}
}
7.7.6 复杂 WordCount 案例
1)方式一
object TestWordCount {def main(args: Array[String]): Unit = {// 第一种方式(不通用)val tupleList = List(("Hello Scala Spark World ", 4), ("Hello
Scala Spark", 3), ("Hello Scala", 2), ("Hello", 1))val stringList: List[String] = tupleList.map(t=>(t._1 + "
") * t._2)//val words: List[String] =
stringList.flatMap(s=>s.split(" "))val words: List[String] = stringList.flatMap(_.split(" "))//在 map 中,如果传进来什么就返回什么,不要用_省略val groupMap: Map[String, List[String]] =
words.groupBy(word=>word)//val groupMap: Map[String, List[String]] =
words.groupBy(_)// (word, list) => (word, count)val wordToCount: Map[String, Int] = groupMap.map(t=>(t._1,
t._2.size))val wordCountList: List[(String, Int)] =
wordToCount.toList.sortWith {(left, right) => {left._2 > right._2}}.take(3)//tupleList.map(t=>(t._1 + " ") * t._2).flatMap(_.split("
")).groupBy(word=>word).map(t=>(t._1, t._2.size))println(wordCountList)}
}
2)方式二
object TestWordCount {def main(args: Array[String]): Unit = {val tuples = List(("Hello Scala Spark World", 4), ("Hello
Scala Spark", 3), ("Hello Scala", 2), ("Hello", 1))// (Hello,4),(Scala,4),(Spark,4),(World,4)// (Hello,3),(Scala,3),(Spark,3)// (Hello,2),(Scala,2)// (Hello,1)val wordToCountList: List[(String, Int)] = tuples.flatMap
{t => {val strings: Array[String] = t._1.split(" ")strings.map(word => (word, t._2))}}// Hello, List((Hello,4), (Hello,3), (Hello,2), (Hello,1))// Scala, List((Scala,4), (Scala,3), (Scala,2)// Spark, List((Spark,4), (Spark,3)// Word, List((Word,4))val wordToTupleMap: Map[String, List[(String, Int)]] =
wordToCountList.groupBy(t=>t._1)val stringToInts: Map[String, List[Int]] =
wordToTupleMap.mapValues {datas => datas.map(t => t._2)}stringToInts/*val wordToCountMap: Map[String, List[Int]] =
wordToTupleMap.map {t => {(t._1, t._2.map(t1 => t1._2))}}val wordToTotalCountMap: Map[String, Int] =
wordToCountMap.map(t=>(t._1, t._2.sum))println(wordToTotalCountMap)*/}
}
7.8 队列
1)说明
Scala 也提供了队列(Queue)的数据结构,队列的特点就是先进先出。进队和出队的方
法分别为 enqueue 和 dequeue。
2)案例实操
object TestQueue {def main(args: Array[String]): Unit = {val que = new mutable.Queue[String]()que.enqueue("a", "b", "c")println(que.dequeue())println(que.dequeue())println(que.dequeue())}
}
7.9 并行集合
1)说明
Scala 为了充分使用多核 CPU,提供了并行集合(有别于前面的串行集合),用于多核
环境的并行计算。
2)案例实操
object TestPar {def main(args: Array[String]): Unit = {val result1 = (0 to 100).map{case _ =>
Thread.currentThread.getName}val result2 = (0 to 100).par.map{case _ =>
Thread.currentThread.getName}println(result1)println(result2)}
}
相关文章:
Scala集合详解(第七章:集合、数组、列表、set集合、map集合、元组、队列、并行)(尚硅谷笔记)
集合第七章:集合7.1 集合简介7.1.1 不可变集合继承图7.1.2 可变集合继承图7.2 数组7.2.1 不可变数组7.2.2 可变数组7.2.3 不可变数组与可变数组的转换7.2.4 多维数组7.3 列表 List7.3.1 不可变 List7.3.2 可变 ListBuffer7.4 Set 集合7.4.1 不可变 Set7.4.2 可变 mutable.Set7.…...
定了:Python3.7,今年停止更新~
大家好,这里是程序员晚枫。 今天给大家分享一个来自Python官网的重要消息:Python3.7马上就要停止维护了,请不要使用了! 官网链接:https://devguide.python.org/versions/ 停更的后果是什么? 周末翻阅Py…...
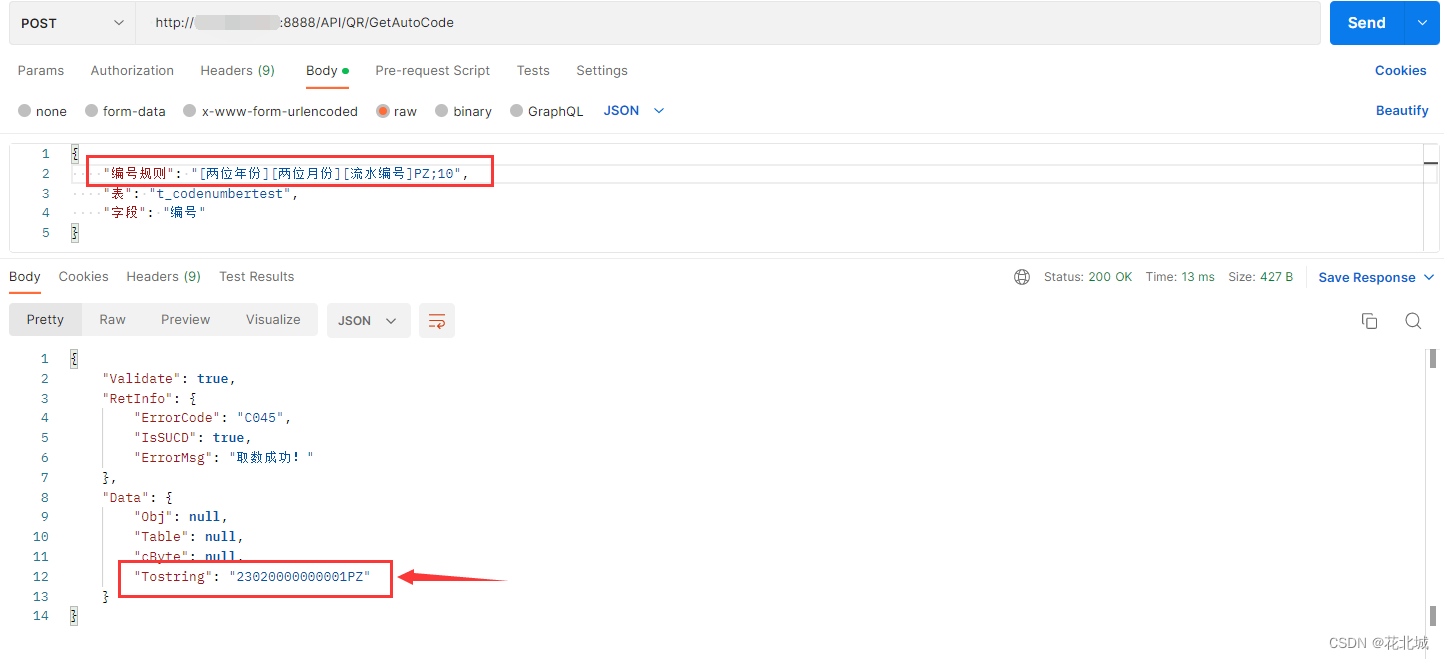
C# 业务单据号生成器(定义规则、获取编号、流水号)
系列文章 C#底层库–数据库访问帮助类(MySQL版) 本文链接:https://blog.csdn.net/youcheng_ge/article/details/126886379 C#底层库–JSON帮助类_详细(序列化、反序列化、list、datatable) 本文链接:htt…...
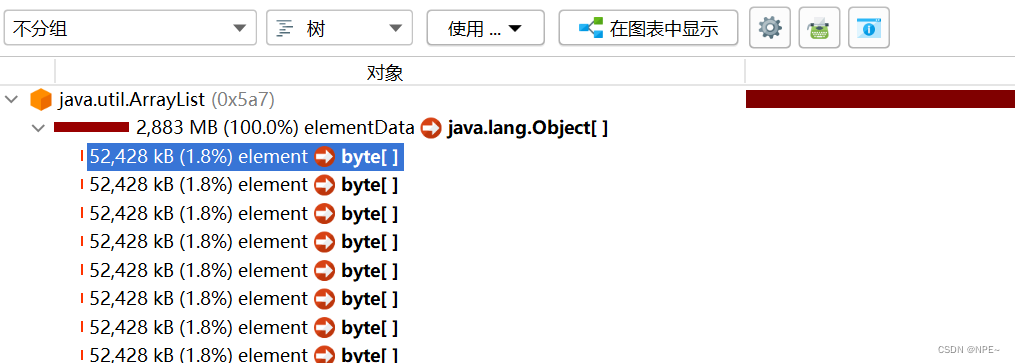
Java的dump文件分析及JProfiler使用
Java的dump文件分析及JProfiler使用 1 dump文件介绍 从软件开发的角度上,dump文件就是当程序产生异常时,用来记录当时的程序状态信息(例如堆栈的状态),用于程序开发定位问题。 idea配置发生OOM的时候指定路径生成dump文件 # 指定…...
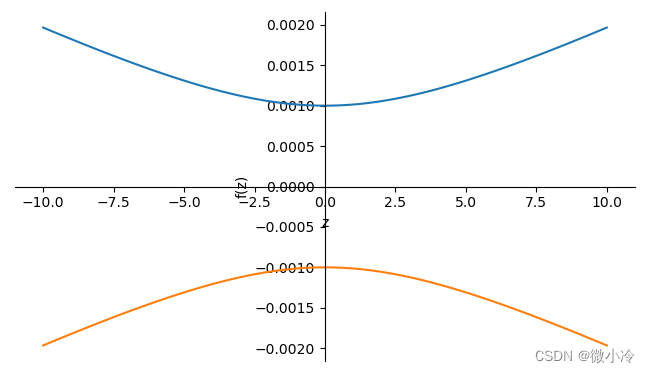
sympy高斯光束模型
文章目录Gauss模型sympy封装实战sympy.phisics.optics.gaussopt集成了高斯光学中的常见对象,包括光线和光学元件等,有了这些东西,就可以制作一个光学仿真系统。Gauss模型 高斯光束的基本模型为 E(r,z)E0ω0ω(z)exp[−r2ω2(z)]exp[−ik…...
Cloudflared 内网穿透 使用记录
Cloudflared 内网穿透前提创建cloudflared tunnel我使用的服务前提 你必须要有一个域名,并且可以改域名的dns解析服务商到cloudflare 1.登录到cloudflare后台,点击添加站点 2.输入自己的域名,下一步选择免费套餐 3.他会搜索这个域名下已有…...

柴油发电机组的调压板
1 概述 柴油发电机组的调压板是一种用于控制发电机输出电压的装置。它通常由一块电子电路板和一个电子电路板上的电位器组成。 当发电机运行时,它会产生电压,然后通过调压板中的电路进行控制。调压板中的电路会检测输出电压的大小,并通过电…...

【MySQL】表操作和库操作
文章目录概念库操作1.创建数据库2.删除数据库3.选择数据库4.显示数据库列表表操作1.创建数据表CREATE2.删除数据表DROP3.插入数据INSERT4.更新数据UPDATE5.修改数据ALTER6.查询数据SELECT7.WHERE子句8.ORDER BY子句9.LIMIT子句10.GROUP BY子句11.HAVING子句使用注意事项概念 M…...

拓扑排序的思想?用代码怎么实现
目录 一、拓扑排序的思想 二、代码实现(C) 代码思想 核心代码 完整代码 一、拓扑排序的思想 以西红柿炒鸡蛋这道菜为例,其中的做饭流程为: 中间2 6 3 7 4的顺序都可以任意调换,但1和5必须在最前面,这是…...
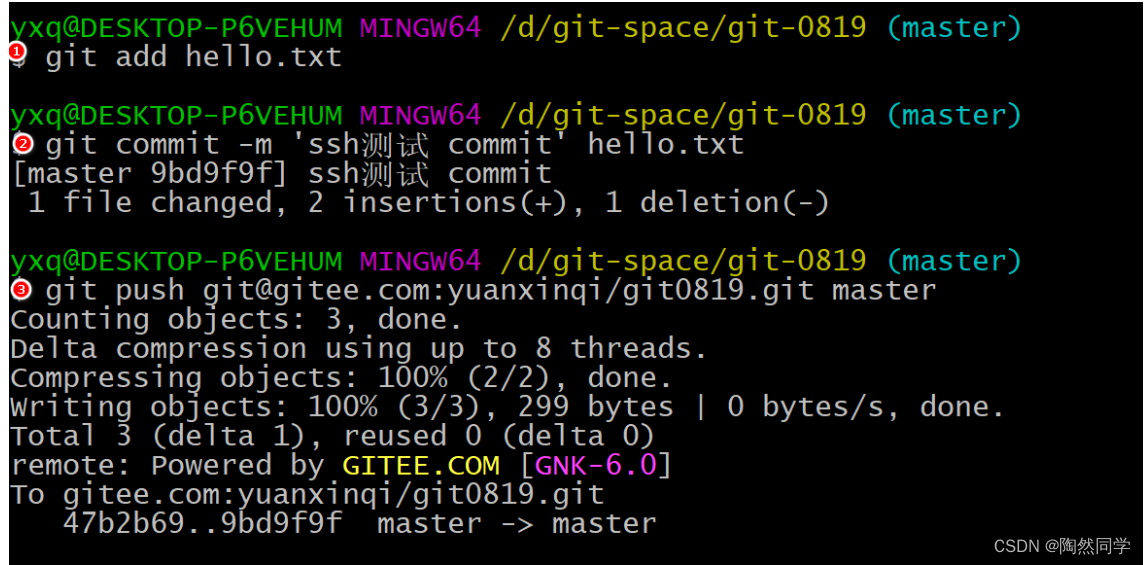
【Git】码云
目录 5、 Git 团队协作机制 5.1 团队内协作 5.2 跨团队协作 6、 Gitee码云 操作 6.1 创建远程仓库 6.2 远程仓库操作 6.3 SSH 免密登录 5、 Git 团队协作机制 5.1 团队内协作 5.2 跨团队协作 6、 Gitee码云 操作 码云网址: https://githee.com/ 账号验证…...
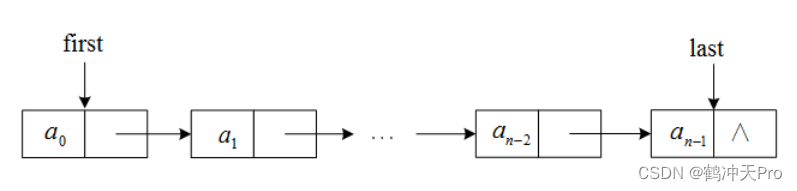
数据结构与算法(三):栈与队列
上一篇《数据结构与算法(二):线性表》中介绍了数据结构中线性表的两种不同实现——顺序表与链表。这一篇主要介绍线性表中比较特殊的两种数据结构——栈与队列。首先必须明确一点,栈和队列都是线性表,它们中的元素都具…...

Spring架构篇--2.5.2 远程通信基础Select 源码篇--window--sokcet.register
前言:通过Selector.open() 获取到Selector 的选择器后,服务端和客户的socket 都可以通过register 进行socker 的注册; 服务端 ServerSocketChannel 的注册: ServerSocketChannel serverSocketChannel ServerSocketChannel.open(…...
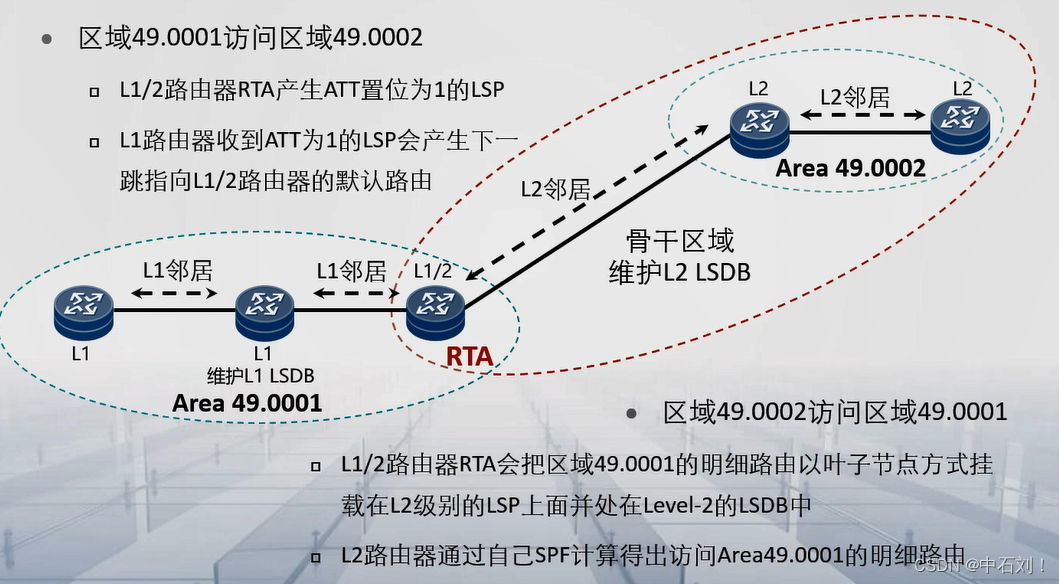
ISIS协议
ISIS协议基础简介应用场景路由计算过程地址结构路由器分类邻居Hello报文邻居关系建立DIS及DIS与DR的类比链路状态信息的载体链路状态信息的交互路由算法网络分层路由域区域间路由简介…...

CRM系统哪种品牌的好?这五款简单好用!
CRM系统哪种品牌的好?这五款简单好用! CRM系统是指利用软件、硬件和网络技术,为企业建立一个客户信息收集、管理、分析和利用的信息系统。CRM系统的基础功能主要包括营销自动化、客户管理、销售管理、客服管理、报表分析等,选择合…...
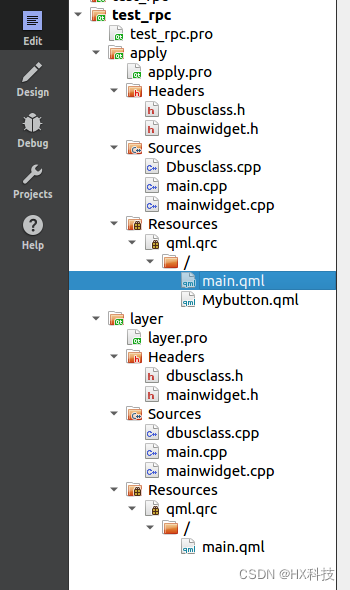
QT_dbus(ipc进程间通讯)
QT_dbus(ipc进程间通讯) 前言: 参考链接: https://www.cnblogs.com/brt3/p/9614899.html https://blog.csdn.net/weixin_43246170/article/details/120994311 https://blog.csdn.net/kchmmd/article/details/118605315 一个大型项目可能需要多个子程序同…...

华为OD机试 - 数组排序(C++) | 附带编码思路 【2023】
刷算法题之前必看 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 OD 清单查看地址:https://blog.csdn.net/hihell/category_12199283.html 华为OD详细说明:https://dream.blog.csdn.net/article/details/128980730 华为OD机试题…...
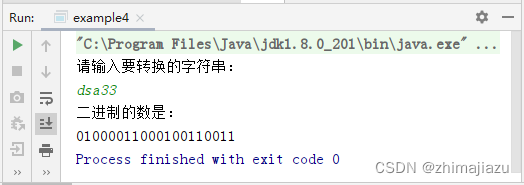
字符串转换为二进制-课后程序(JAVA基础案例教程-黑马程序员编著-第五章-课后作业)
【案例5-4】 字符串转换为二进制 【案例介绍】 1.任务描述 本例要求编写一个程序,从键盘录入一个字符串,将字符串转换为二进制数。在转换时,将字符串中的每个字符单独转换为一个二进制数,将所有二进制数连接起来进行输出。 案…...
SpringIOC
一、为什么要使用Spring? Spring 是个java企业级应用的开源开发框架。Spring主要用来开发Java应用,但是有些扩展是针对构建J2EE平台的web应用。Spring 框架目标是简化Java企业级应用开发,并通过POJO为基础的编程模型促进良好的编程习惯。 为…...

Debezium系列之:基于数据库信号表和Kafka信号Topic两种技术方案实现增量快照incremental技术的详细步骤
Debezium系列之:基于数据库信号表和Kafka信号Topic两种技术方案实现增量快照incremental技术的详细步骤 一、需求背景二、增量快照技术实现的两种方案三、基于数据库信号表实现增量快照技术的原理1.基于水印的快照2.信令表3.增量快照4.连接起重启四、基于数据库信号表实现增量…...
 | 机试题+算法思路+考点+代码解析 【2023】)
华为OD机试 - 第 K 个最小码值的字母(Python) | 机试题+算法思路+考点+代码解析 【2023】
第 K 个最小码值的字母 题目 输入一个由n个大小写字母组成的字符串 按照 ASCII 码值从小到大进行排序 查找字符串中第k个最小 ASCII 码值的字母(k>=1) 输出该字母所在字符串中的位置索引(字符串的第一个位置索引为 0) k如果大于字符串长度则输出最大 ASCII 码值的字母所在…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...

D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析
D2DX如何让暗黑破坏神2在4K显示器上流畅运行:5个关键技术解析 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 当…...

从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置
从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置当你第一次面对Ubuntu Server时,最迫切的需求可能就是如何安全地远程管理它。作为运维新手或开发者,掌握SSH连接和防火墙配置是进入Linux世界的第一道门槛。本文将带你…...

3PEAK思瑞浦 TPA6532-VS1R MSOP8 运算放大器
特性 供电电压:1.75伏至5.5伏 偏移电压:土1.5mV(最大) 通用峰值电压:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1Hz至10Hz电压噪声:1Vpp 开机和关机电流期间无明显输出抖动 低功耗:每通道最大25安培工作温度范围:-40C至125C...

医用超声图像干扰伪像算法:原理、识别与抑制技术综述
引言 医用超声成像因其无创、实时、低成本等优点,已成为临床诊断不可或缺的工具。然而,超声图像质量极易受到各种物理因素和系统限制的影响,从而产生干扰伪像。这些伪像并非真实的解剖结构,而是由声波传播特性、设备硬件、操作手法等因素导致的虚假或失真的图像信息。准确…...

终极镜像烧录指南:3分钟掌握Balena Etcher安全烧录技巧
终极镜像烧录指南:3分钟掌握Balena Etcher安全烧录技巧 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher Balena Etcher是一款专为安全烧录操作系统镜像…...

城通网盘直连解析完整指南:三步获取高速下载链接的免费方案
城通网盘直连解析完整指南:三步获取高速下载链接的免费方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载速度慢而烦恼吗?ctfileGet是一款专为城通网盘用户…...