Spark【Spark SQL(三)DataSet】
DataSet
DataFrame 的出现,让 Spark 可以更好地处理结构化数据的计算,但存在一个问题:编译时的类型安全问题,为了解决它,Spark 引入了 DataSet API(DataFrame API 的扩展)。DataSet 是分布式的数据集合,它提供了强类型支持,也就是给 RDD 的每行数据都添加了类型约束。
在 Spark 2.0 中,DataFrame 和 DataSet 被合并为 DataSet 。DataSet包含 DataFrame 的功能,DataFrame 表示为 DataSet[Row] ,即DataSet 的子集。
三种 API 的选择
RDD 是DataFrame 和 DataSet 的底层,如果需要更多的控制功能(比如精确控制Spark 怎么执行一条查询),尽量使用 RDD。
如果希望在编译时获得更高的类型安全,建议使用 DataSet。
如果想统一简化 Spark 的API ,则使用 DataFrame 和 DataSet。
基于 DataFrame API 和 DataSet API 开发的程序会被自动优化,开发人员不需要操作底层的RDD API 来手动优化,大大提高了开发效率。但是RDD API 对于非结构化数据的处理有独特的优势(比如文本数据流),而且更方便我们做底层的操作。
DataSet 的创建
1、使用createDataset()方法创建
def main(args: Array[String]): Unit = {//local代表本地单线程模式 local[*]代表本地多线程模式val spark = SparkSession.builder().appName("create dataset").master("local[*]").getOrCreate()//一定要导入它 不然无法创建DataSet对象import spark.implicits._val ds1 = spark.createDataset(1 to 5)ds1.show()val ds2 = spark.createDataset(spark.sparkContext.textFile("data/sql/people.txt"))ds2.show()spark.stop()}运行结果:
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
| 5|
+-----++--------+
| value|
+--------+
| Tom, 21|
|Mike, 25|
|Andy, 18|
+--------+2、通过 toDS 方法生成
import org.apache.spark.sql.{Dataset, SparkSession}object DataSetCreate {//case类一定要写到main方法之外case class Person(name:String,age:Int)def main(args: Array[String]): Unit = {//local代表本地单线程模式 local[*]代表本地多线程模式val spark = SparkSession.builder().appName("create dataset").master("local[*]").getOrCreate()//一定要导入 SparkSession对象下的implicitsimport spark.implicits._val data = List(Person("Tom",21),Person("Andy",22))val ds: Dataset[Person] = data.toDS()ds.show()spark.stop()}
}
运行结果:
+----+---+
|name|age|
+----+---+
| Tom| 21|
|Andy| 22|
+----+---+3、通过DataFrame 转换生成
object DataSetCreate{case class Person(name:String,age:Long,sex:String)
def main(args: Array[String]): Unit = {//local代表本地单线程模式 local[*]代表本地多线程模式val spark = SparkSession.builder().appName("create dataset").master("local[*]").getOrCreate()import spark.implicits._val df = spark.read.json("data/sql/people.json")val ds = df.as[Person]ds.show()spark.stop()}
}RDD、DataFrame 和 DataSet 之间的相互转换
RDD <=> DataFrame
- RDD 转 DataFrame ,也就是上一篇博客中介绍的两种方法:
- 能创建case类,就直接映射出一个RDD[Person],然后调用toDF方法利用反射机制推断RDD模式。
- 无法创建case类,就使用编程方式定义RDD模式,使用 createDataFrame(rowRDD,schema) 指定rowRDD:RDD[Row]和schema:StructType。
- DataFrame 转 RDD,直接使用 rdd() 方法。
package com.study.spark.core.sqlimport org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}object TransForm {case class Person(name:String,age:Int) //txt文件age字段可以用Int,但json文件尽量用Longdef main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("transform").master("local[*]").getOrCreate()import spark.implicits._//1.RDD和DataFrame之间互相转换//1.1 创建RDD对象val rdd: RDD[Person] = spark.sparkContext.textFile("data/sql/people.txt").map(_.split(",")).map(attr => Person(attr(0), attr(1).trim.toInt))rdd.foreach(println)/*Person(Andy,18)Person(Tom,21)Person(Mike,25)*///1.2 RDD转DataFrameval df = rdd.toDF()df.show()/*+----+---+|name|age|+----+---+| Tom| 21||Mike| 25||Andy| 18|+----+---+*///1.3 DataFrame转RDDval res: RDD[Row] = df.rdd/*[Andy,18][Tom,21][Mike,25]*/res.foreach(println)spark.stop()}
}
可以看到,RDD[Person]转为DataFrame后,再从DataFrame转回RDD就变成了RDD[Row] 类型了。
RDD <=> DataSet
RDD 和 DataSet 之间的转换比较简单:
- RDD 转 DataSet 直接使用case 类(比如Person),然后映射出 RDD[Person] ,直接调用 toDS方法。
- DataSet 转 RDD 直接调用 rdd方法即可。
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}object TransForm {case class Person(name:String,age:Int) //txt文件age字段可以用Int,但json文件尽量用Longdef main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("transform").master("local[*]").getOrCreate()import spark.implicits._//1.RDD和DataSet之间互相转换//1.1 创建RDD对象val rdd: RDD[Person] = spark.sparkContext.textFile("data/sql/people.txt").map(_.split(",")).map(attr => Person(attr(0), attr(1).trim.toInt))rdd.foreach(println)/*Person(Andy,18)Person(Tom,21)Person(Mike,25)*///1.2 RDD转DataSetval ds = rdd.toDS()ds.show()/*+----+---+|name|age|+----+---+| Tom| 21||Mike| 25||Andy| 18|+----+---+*///1.3 DataFrame转RDDval res: RDD[Person] = ds.rddres.foreach(println)/*Person(Andy,18)Person(Tom,21)Person(Mike,25)*/spark.stop()}
}
可以看到,相比RDD和DataFrame互相转换,RDD和DataSet转换的过程中,不会有数据类型的变化,而DataFrame转RDD的过程就会把我们定义的case类转为Row对象。
DataFrame <=> DataSet
- DataFrame 转 DataSet 先使用case类,然后直接使用 as[case 类] 方法。
- DataSet 转 DataFrame 直接使用 toDF 方法。
import org.apache.spark.sql.{DataFrame, Row, SparkSession}object TransForm {case class Person(name:String,age:Long,sex:String) //txt文件age字段可以用Int,但json文件尽量用Longdef main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("transform").master("local[*]").getOrCreate()import spark.implicits._//1.DataFrame和DataSet之间互相转换//1.1 创建DataFrame对象val df = spark.read.json("data/sql/people.json")df.show()/*+---+----------+---+|age| name|sex|+---+----------+---+| 30| Michael| 男|| 19| Andy| 女|| 19| Justin| 男|| 20|Bernadette| 女|| 23| Gretchen| 女|| 27| David| 男|| 33| Joseph| 女|| 27| Trish| 女|| 33| Alex| 女|| 25| Ben| 男|+---+----------+---+*///1.2 DataFrame转DataSetval ds = df.as[Person]ds.show()/*+---+----------+---+|age| name|sex|+---+----------+---+| 30| Michael| 男|| 19| Andy| 女|| 19| Justin| 男|| 20|Bernadette| 女|| 23| Gretchen| 女|| 27| David| 男|| 33| Joseph| 女|| 27| Trish| 女|| 33| Alex| 女|| 25| Ben| 男|+---+----------+---+*///1.3 DataSet转DataFrameval res: DataFrame = ds.toDF()res.show()/*+---+----------+---+|age| name|sex|+---+----------+---+| 30| Michael| 男|| 19| Andy| 女|| 19| Justin| 男|| 20|Bernadette| 女|| 23| Gretchen| 女|| 27| David| 男|| 33| Joseph| 女|| 27| Trish| 女|| 33| Alex| 女|| 25| Ben| 男|+---+----------+---+*/spark.stop()}
}
DataSet 实现 WordCount
def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("create dataset").master("local[*]").getOrCreate()import spark.implicits._val res: Dataset[(String, Long)] = spark.read.text("data/word.txt").as[String].flatMap(_.split(" ")).groupByKey(_.toLowerCase).count()res.show()spark.stop()}运行结果:
| key|count(1)|
+------+--------+
| fast| 1|
| is| 3|
| spark| 2|
|better| 1|
| good| 1|
|hadoop| 1|
+------+--------+总结
剩下来就是不断练习各种DataFrame和DataSet的操作、熟悉各种转换和行动操作。
相关文章:
DataSet】)
Spark【Spark SQL(三)DataSet】
DataSet DataFrame 的出现,让 Spark 可以更好地处理结构化数据的计算,但存在一个问题:编译时的类型安全问题,为了解决它,Spark 引入了 DataSet API(DataFrame API 的扩展)。DataSet 是分布式的数…...

制作立体图像实用软件:3DMasterKit 10.7 Crack
3DMasterKit 软件专为创建具有逼真 3D 和运动效果的光栅图片而设计:翻转、动画、变形和缩放。 打印机、广告工作室、摄影工作室和摄影师将发现 3DMasterKit 是一种有用且经济高效的解决方案,可将其业务扩展到新的维度,提高生成的 3D 图像和光…...

高校 Web 站点网络安全面临的主要的威胁
校园网 Web 站点的主要安全威胁来源于计算机病毒、内部用户恶意攻击和 破坏、内部用户非恶意的错误操作和网络黑客入侵等。 2.1 计算机病毒 计算机病毒是指编制者在计算机程序中插入的破坏计算机功能或者数据, 影响计算机使用并且能够自我复制的一组计算机指令或…...

vue前端解决跨域
1,首先 axios请求,看后端接口路径,http://122.226.146.110:25002/api/xx/ResxxList,所以baseURL地址改成 ‘/api’ let setAxios originAxios.create({baseURL: /api, //这里要改掉timeout: 20000 // request timeout}); export default s…...

【Cicadaplayer】解码线程及队列实现
4.4分支https://github.com/alibaba/CicadaPlayer/blob/release/0.4.4/framework/codec/ActiveDecoder.h对外:送入多个包,获取一个帧 int send_packet(std::unique_ptr<IAFPacket> &packet, uint64_t timeOut) override;int getFrame(std::u...
把文件上传到Gitee的详细步骤
目录 第一步:创建一个空仓库 第二步:找到你想上传的文件所在的地址,打开命令窗口,git init 第三步:git add 想上传的文件 ,git commit -m "给这次提交取个名字" 第四步:和咱们在第…...

基于keras中Lenet对于mnist的处理
文章目录 MNIST导入必要的包加载数据可视化数据集查看数据集的分布开始训练画出loss图画出accuracy图 使用数据外的图来测试图片可视化转化灰度图的可视化可视化卷积层的特征图第一层卷积 conv1 和 pool1第二层卷积 conv2 和 pool2 MNIST MNIST(Modified National …...

Python爬虫 教程:IP池的使用
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 一、简介 爬虫中为什么需要使用代理 一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率…...

Ansible之playbook剧本
一、playbook概述1.1 playbook 介绍1.2 playbook 组成部分 二、playbook 示例2.1 playbook 启动及检测2.2 实例一2.3 vars 定义、引用变量2.4 指定远程主机sudo切换用户2.5 when条件判断2.6 迭代2.7 Templates 模块1.先准备一个以 .j2 为后缀的 template 模板文件,设…...
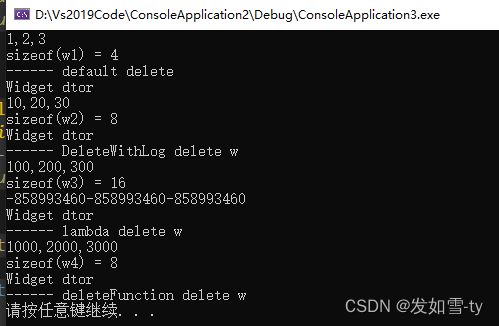
unique_ptr的大小探讨
unique_ptr大小和删除器有很大关系,具体区别看如下代码的分析。不要让unique_ptr占用的空间太大,否则不会达到裸指针同样的效果。 #include <iostream> #include <memory> using namespace std;class Widget {int m_x;int m_y;int m_z;publ…...

人工智能TensorFlow PyTorch物体分类和目标检测合集【持续更新】
1. 基于TensorFlow2.3.0的花卉识别 基于TensorFlow2.3.0的花卉识别Android APP设计_基于安卓的花卉识别_lilihewo的博客-CSDN博客 2. 基于TensorFlow2.3.0的垃圾分类 基于TensorFlow2.3.0的垃圾分类Android APP设计_def model_load(img_shape(224, 224, 3)_lilihewo的博客-CS…...

ElementPlus·面包屑导航实现
面包屑导航 使用vue3中的UI框架elementPlus的 <el-breadcrumb> 实现面包屑导航 <template><!-- 面包屑 --><div class"bread-container" ><el-breadcrumb separator">"><el-breadcrumb-item :to"{ path:/ }&quo…...

【项目管理】PM vs PMO 18点区别
导读:项目经理跟PMO主要有哪些区别?首先从定义上了解,然后根据其他维度进行对比分析,基本可以了解这二者的区别,文中罗列18点区别供各位参考。 目录 1、定义 1.1 PMO 1.2 PM 2、两者区别 2.1 ROI 2.2 项目成功率…...

13 Python使用Json
概述 在上一节,我们介绍了如何在Python中使用xml,包括:SAX、DOM、ElementTree等内容。在这一节,我们将介绍如何在Python中使用Json。Json的英文全称为JavaScript Object Notation,中文为JavaScript对象表示法ÿ…...

PDFBOX和ASPOSE.PDF
一、aspose.pdf 文档 https://docs.aspose.com/pdf/java/ 1、按段落分段 /*** docx文本按段分段*/ public static void main(String[] args) {int i 1;try {// 打开文件流FileInputStream file new FileInputStream("I:\\范文.docx");// 创建 Word 文档对象XWPFDo…...

第51节:cesium 范围查询(含源码+视频)
结果示例: 完整源码: <template><div class="viewer"><el-button-group class="top_item"><el-button type=...

YOLOv5改进算法之添加CA注意力机制模块
目录 1.CA注意力机制 2.YOLOv5添加注意力机制 送书活动 1.CA注意力机制 CA(Coordinate Attention)注意力机制是一种用于加强深度学习模型对输入数据的空间结构理解的注意力机制。CA 注意力机制的核心思想是引入坐标信息,以便模型可以更好地…...
Jmeter系列-阶梯加压线程组Stepping Thread Group详解(6)
前言 tepping Thread Group是第一个自定义线程组但,随着版本的迭代,已经有更好的线程组代替Stepping Thread Group了【Concurrency Thread Group】,所以说Stepping Thread Group已经是过去式了,但还是介绍一下 Stepping Thread …...

图像的几何变换(缩放、平移、旋转)
图像的几何变换 学习目标 掌握图像的缩放、平移、旋转等了解数字图像的仿射变换和透射变换 1 图像的缩放 缩放是对图像的大小进行调整,即 使图像放大或缩小 cv2.resize(src,dsize,fx0,fy0,interpolationcv2.INTER_LINEAR) 参数: src :输入图像dsize…...

计算机网络第四章——网络层(上)
提示:朝碧海而暮苍梧,睹青天而攀白日 文章目录 网络层是路由器的最高层次,通过网络层就可以将各个设备连接到一起,从而实现这两个主机的数据通信和资源共享,之前学的数据链路层和物理层也是将两端连接起来,但是却没有网…...

傅里叶变换加速视觉模型:频域卷积与FiT架构实战
1. 项目概述:用傅里叶变换为视觉模型“减负”在计算机视觉的模型炼金术里,我们总在追求一个看似矛盾的平衡:既要模型“看得更清”(更高的精度和更强的特征提取能力),又要它“跑得更快”(更低的计…...

Wireshark解密不止于IPSec:一份TLS/SSL、HTTPS、SSH等常见加密协议的解密指南
Wireshark解密不止于IPSec:一份TLS/SSL、HTTPS、SSH等常见加密协议的解密指南 当你面对一个加密的网络流量时,是否曾感到无从下手?无论是调试HTTPS API调用、分析SSH连接问题,还是研究QUIC协议的行为,加密流量总是像一…...

华为eNSP Cloud网卡异常排查指南:从WinPcap兼容性到虚拟网卡同步
1. 华为eNSP Cloud网卡异常排查指南 最近在帮朋友调试华为eNSP Cloud时遇到了网卡异常的问题,折腾了大半天才解决。这个问题其实挺常见的,特别是对于刚接触eNSP Cloud的新手来说。今天我就把完整的排查流程和解决方法分享给大家,希望能帮到遇…...

如何快速构建Python量化分析系统:5步掌握通达信数据接口
如何快速构建Python量化分析系统:5步掌握通达信数据接口 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个基于Python的高效通达信数据接口封装,专为量化投资和数…...

机电一体化系统设计的核心挑战与跨学科协同
1. 机电一体化系统设计的核心挑战与机遇十年前我第一次参与工业机器人控制系统开发时,机械团队和电气团队还在用纸质图纸传递设计变更。某个周五下午的机械结构改动,直到下周一才通知到电气组,导致整个控制柜布局需要返工。这种割裂的开发模式…...

高压隔离技术:原理、应用与AMC130x设计解析
1. 高压隔离技术的基础原理与行业需求在工业自动化、新能源发电和电力电子系统中,高压隔离技术如同电路系统的"安全气囊",它能在数千伏的电位差下确保信号和能量的无损传输,同时阻断危险电流的流通。德州仪器(TI&#x…...

技能包管理器:开发者工具链标准化与版本隔离解决方案
1. 项目概述:一个为开发者赋能的技能包管理器在软件开发的世界里,我们每天都在与各种工具、库和依赖项打交道。从构建工具到代码格式化器,从静态分析器到部署脚本,一个现代项目的开发环境往往由数十个、甚至上百个独立的命令行工具…...

AI代理治理零风险上线:asqav观察模式与渐进式集成实践
1. 项目概述:在AI代理上线后,如何安全地引入治理机制你花了好几周时间,终于把那个AI代理流水线给搭起来了。从LangChain的链式调用,到精心设计的工具函数,再到与外部API的集成,每一个环节都调试得服服帖帖。…...

ARM GICv5 IRS寄存器架构与缓存控制机制详解
1. ARM GICv5 IRS寄存器架构解析中断控制器(GIC)是现代SoC设计中不可或缺的核心组件,负责高效管理和分发系统中各类中断请求。GICv5版本引入的中断路由服务(IRS)模块代表了ARM架构在中断处理领域的重大革新。IRS通过精心设计的寄存器组实现了前所未有的中断管理灵活…...

深度解析VinXiangQi:基于深度学习的中国象棋AI连线工具终极指南
深度解析VinXiangQi:基于深度学习的中国象棋AI连线工具终极指南 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi VinXiangQi是一款基于YOLOv5深…...