Python入门教程36:urllib网页请求模块的用法
urllib是Python中的一个模块,它提供了一些函数和类,用于发送HTTP请求、处理URL编码、解析URL等操作。无需安装即可使用,包含了4个模块:
#我的Python教程
#官方微信公众号:wdPython
request:它是最基本的http请求模块,用来模拟发送请求。
error:异常处理模块,如果出现错误可以捕获这些异常。
parse:一个工具模块,提供了许多URL处理方法,如:拆分、解析、合并等。
robotparser:主要用来识别网站的robots.txt文件,然后判断哪些网站可以爬。
1. request模块
1.1 urllib.request.urlopen:用于打开和读取URL网址,并返回一个响应对象。
import urllib.requestresponse=urllib.request.urlopen('https://www.baidu.com') #请求站点获得一个HTTPResponse对象
print(response.read().decode('utf-8')) #返回网页内容
#print(response.getheader('server')) #返回响应头中的server值
#print(response.getheaders()) #以列表元组对的形式返回响应头信息
#print(response.fileno()) #返回文件描述符
#print(response.version) #返回版本信息
print(response.status) #成功返回状态码200,404代表网页未找到
#print(response.debuglevel) #返回调试等级
#print(response.closed) #返回对象是否关闭布尔值
#print(response.geturl()) #返回检索的URL
#print(response.info()) #返回网页的头信息
#print(response.getcode()) #返回响应的HTTP状态码
#print(response.msg) #访问成功则返回ok
#print(response.reason) #返回状态信息
1.2 urllib.request.Request:你可以使用它来定制请求的 URL、请求方法(GET、POST 等)、请求头、请求数据等。
url:请求的URL,必传参数,其他都是可选参数。
data:上传的数据,必须传bytes字节流类型的数据,如果它是字典,可以先用urllib.parse模块里的urlencode()编码。
headers:它是一个字典,传递的是请求头数据,可以通过它构造请求头,也可以通过调用请求实例的方法add_header()来添加。
method:是一个字符串,用来指示请求使用的方法,如:GET,POST,PUT等。
以下是一个Request对象使用的例子:
from urllib.request import Request, urlopen url = 'http://www.example.com/'
headers = {'User-Agent': 'Mozilla/5.0'}
data = None # POST 数据,如果是 GET 请求则为 None
req = Request(url, data=data, headers=headers) response = urlopen(req)
html_data = response.read()
print(html_data)
1.3 urllib.request.urlretrieve:将网页文件( 图片,音频等等),保存在本地电脑。urlretrieve(音频网址, f’保存到电脑上的路径.m4a’)
1.4 urllib.request.urlcleanup:用于清理由 urlretrieve 函数下载的临时文件。当使用 urlretrieve 函数下载文件时,它会将文件保存在一个临时位置,然后在文件下载完成后,可以使用 urlcleanup 函数来清理这些临时文件。
2.error模块:urllib的error模块定义了由request模块产生的异常,如果出现问题,request模块便会抛出error模块中定义的异常。
2.1 URLError类来自urllib库的error模块,它继承自OSError类,是error异常模块的基类,由request模块产生的异常都可以通过捕获这个类来处理。它只有一个属性reason,即返回错误的原因。
from urllib import request,error
try:#该url是不存在的,所以会产生异常response = request.urlopen('https://xiaohongniu918918.com/')except error.URLError as e:#由于访问的网页不存在,所以会打印Not Foundprint(e.reason)else:html = response.read()
3.urllib.parse 中常用的函数和类:
3.1 urllib.parse.urlparse(): 解析 URL,返回一个 ParseResult 对象,这个对象包含以下属性:
scheme:URL 的协议部分(例如 ‘http’ 或 ‘https’)。
netloc:网络位置,通常是主机名和端口号(如果有的话)。
path:URL 路径。
params:参数,在 URL 路径中的分号分隔的键值对。
query:查询字符串,在 URL 中的问号之后的部分。
fragment:URL 的片段(也称为锚点),在 URL 中的井号之后的部分。
from urllib.parse import urlparse url = urlparse('http://www.example.com/path?param=value#anchor')
print(url.scheme) # 输出:'http'
print(url.netloc) # 输出:'www.example.com'
print(url.path) # 输出:'/path'
print(url.params) # 输出:'',因为没有参数
print(url.query) # 输出:'param=value'
print(url.fragment)# 输出:'anchor'#你可以使用geturl() 方法来获取完整的 URL 字符串:
print(url.geturl()) # 输出:'http://www.example.com/path?param=value#anchor'
3.2 urllib.parse.urlunparse(): 将 ParseResult 对象转换回 URL 字符串。要求你提供的元组或列表中的元素顺序必须正确,否则结果可能不是你期望的 URL。
from urllib.parse import urlunparseurl_components = ('http', 'www.example.com', '/path', '', 'param=value', 'anchor')
url = urlunparse(url_components)
print(url) # http://www.example.com/path?param=value#anchor
3.3 urllib.parse.urljoin: 接受一个基础 URL 和一个或多个 URL 片段作为参数,并返回一个拼接后的完整 URL。
from urllib.parse import urljoinbase_url = 'http://www.example.com'
url_fragment = '/path/to/resource'full_url = urljoin(base_url, url_fragment)
print(full_url) # http://www.example.com1/path/to/resource
3.4 urllib.parse.urldefrag(url): 接受一个 URL 字符串作为参数,并返回一个包含两个元素的元组:不包含片段标识符的基础 URL 和片段标识符。
from urllib.parse import urldefrag url = 'http://www.example.com/path#fragment'
base_url, fragment = urldefrag(url) print(base_url) # 输出:http://www.example.com/path
print(fragment) # 输出:fragment
3.5 urllib.parse.urlsplit接受一个 URL 字符串作为参数,并返回一个 SplitResult 对象,该对象包含 URL 的各个组成部分。
from urllib.parse import urlsplit url = 'http://www.example.com/path?param=value#anchor'
parts = urlsplit(url) print(parts.scheme) # 输出:'http'
print(parts.netloc) # 输出:'www.example.com'
print(parts.path) # 输出:'/path'
print(parts.query) # 输出:'param=value'
print(parts.fragment) # 输出:'anchor'
3.6 urllib.parse.urlunsplit(parts): 类似于urlunparse,接受一个包含 URL 的各个组成部分的 ParseResult 对象或元组作为参数,并返回一个完整的 URL 字符串。
from urllib.parse import urlunspliturl_components = ('http', 'www.example.com', '/path', 'param=value', 'anchor')
url = urlunsplit(url_components)print(url) # 输出http://www.example.com/path?param=value#anchor
3.7 urllib.parse.parse_qs:接受一个查询字符串作为参数,并返回一个字典,其中包含查询字符串中的参数和对应的值。
from urllib.parse import parse_qsquery_string = 'key1=value1&key2=value2&key3=value3'
print(parse_qs(query_string))
# 输出:{'key1': ['value1'], 'key2': ['value2'], 'key3': ['value3']}
3.8 urllib.parse.parse_qsl: 解析 URL 查询字符串,返回一个元组的列表
from urllib.parse import parse_qslquery_string = 'key1=value1&key2=value2&key3=value3'print(parse_qsl(query_string))
# 输出:[('key1', 'value1'), ('key2', 'value2'), ('key3', 'value3')]
3.9 urllib.parse.quote: 将字符串进行URL编码。
from urllib.parse import quotes = 'Wo, Python教程!'
quoted_s = quote(s)print(quoted_s) # 输出:'Wo%2C%20Python%E6%95%99%E7%A8%8B%21'
3.10 urllib.parse.unquote(s, encoding=‘utf-8’, errors=‘replace’): 将 URL 编码的字符串解码。
from urllib.parse import unquotequoted_s = 'Wo%2C%20Python%E6%95%99%E7%A8%8B%21'
print(unquote(quoted_s))
# 输出:'Wo, Python教程!'
3.11 urllib.parse.quote_plus(s, safe=’ ', encoding=‘utf-8’, errors=‘replace’): 将字符串进行 URL 编码,并将空格转换为加号。
from urllib.parse import quote_pluss = 'Wo, Python 教程!'
print(quote_plus(s))
# 输出:'Wo%2C+Python+%E6%95%99%E7%A8%8B%21'
3.12 urllib.parse.unquote_plus(s, encoding=‘utf-8’, errors=‘replace’): 将 URL 编码的字符串解码,并将加号转换为空格。
from urllib.parse import unquote_plusquoted_s = 'Wo%2C+Python+%E6%95%99%E7%A8%8B%21'
print(unquote_plus(quoted_s))
# 输出:Wo, Python 教程!
相关文章:

Python入门教程36:urllib网页请求模块的用法
urllib是Python中的一个模块,它提供了一些函数和类,用于发送HTTP请求、处理URL编码、解析URL等操作。无需安装即可使用,包含了4个模块: #我的Python教程 #官方微信公众号:wdPythonrequest:它是最基本的htt…...

LeetCode 每日一题 2023/9/4-2023/9/10
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 9/4 449. 序列化和反序列化二叉搜索树9/5 2605. 从两个数字数组里生成最小数字9/6 1123. 最深叶节点的最近公共祖先9/7 2594. 修车的最少时间9/8 2651. 计算列车到站时间9/…...
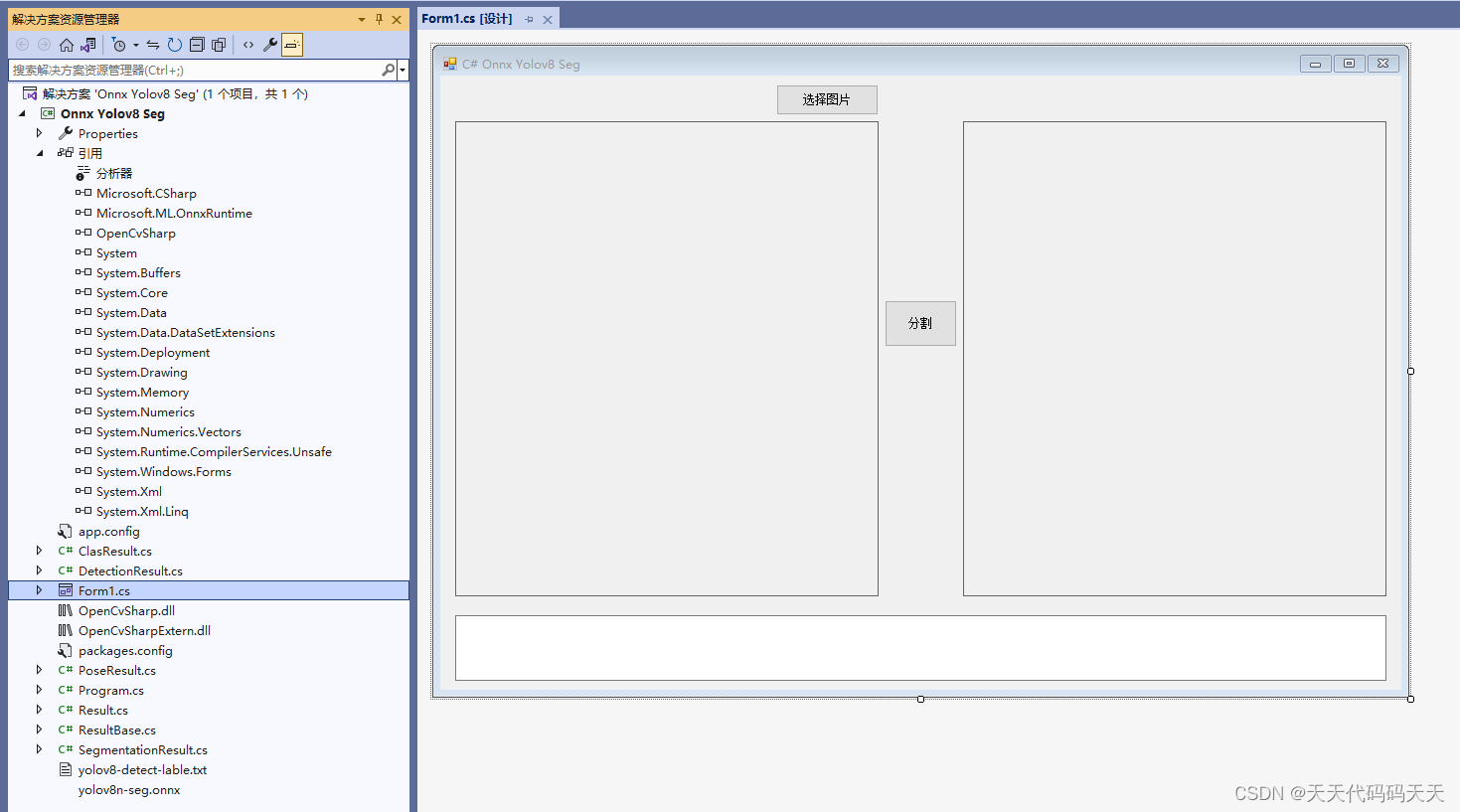
C# Onnx Yolov8 Seg 分割
效果 项目 代码 using Microsoft.ML.OnnxRuntime; using Microsoft.ML.OnnxRuntime.Tensors; using OpenCvSharp; using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System…...

Postman接口测试流程
一、工具安装 ● 安装Postman有中文版和英文版,可以选择自己喜欢的版本即可。安装时重新选择一下安装路径(也可以默认路径),一直下一步安装完成即可。(本文档采用英文版本)安装文件网盘路径链接࿱…...

探索GreatADM:如何快速定义监控
引文 在数据库运维过程中,所使用的运维管理平台是否存在这样的问题: 1、默认监控粒度不够,业务需要更细颗粒度的监控数据。2、平台默认的监控命令不适合,需要调整阈值量身定制监控策略。3、不同类型的实例或组件需要有不同的监控重点,但管理平台监控固…...

C# 参数名加冒号,可以打乱参数顺序
今天看到Python有这种语法,参数名后面跟着等号写参数,联想到前几天用到的Serilog,好像有个参数名加冒号的写法,搜索了一下,果真有这种用法。 函数特别大的时候,用这种方法很直观,而且参数可以打…...
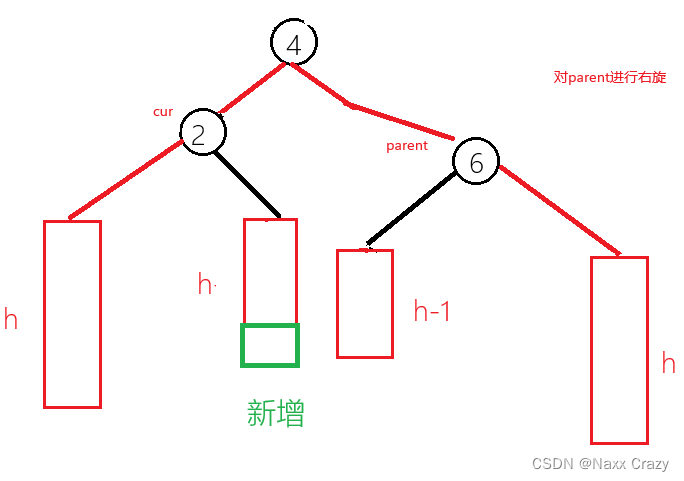
AVL树 模拟实现(插入)
目录 模拟插入节点 左单旋 右单旋 右左双旋 左右双旋 总结 实现 插入实现 左单旋实现 右单旋实现 右左双旋实现 左右双旋实现 AVL树 模拟实现(插入) AVL 树,是高度平衡二叉搜索树,其主要通过旋转来控制其左右子树的高…...
《JavaSE》)
Java面试整理(三)《JavaSE》
反射机制(低) 在我刚开始学Java的时候,大家都很难理解反射这个概念,在实际开发中,虽然都有反射的踪影,但感觉自己又能理解是的。反射机制是指在程序运行时,对任意一个类都能获取其所有属性和方法,并且对任意一个对象都能调用其任意一个方法。 反射的步骤如下: 获取想要…...
LeetCode 1282. Group the People Given the Group Size They Belong To【哈希表】1267
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
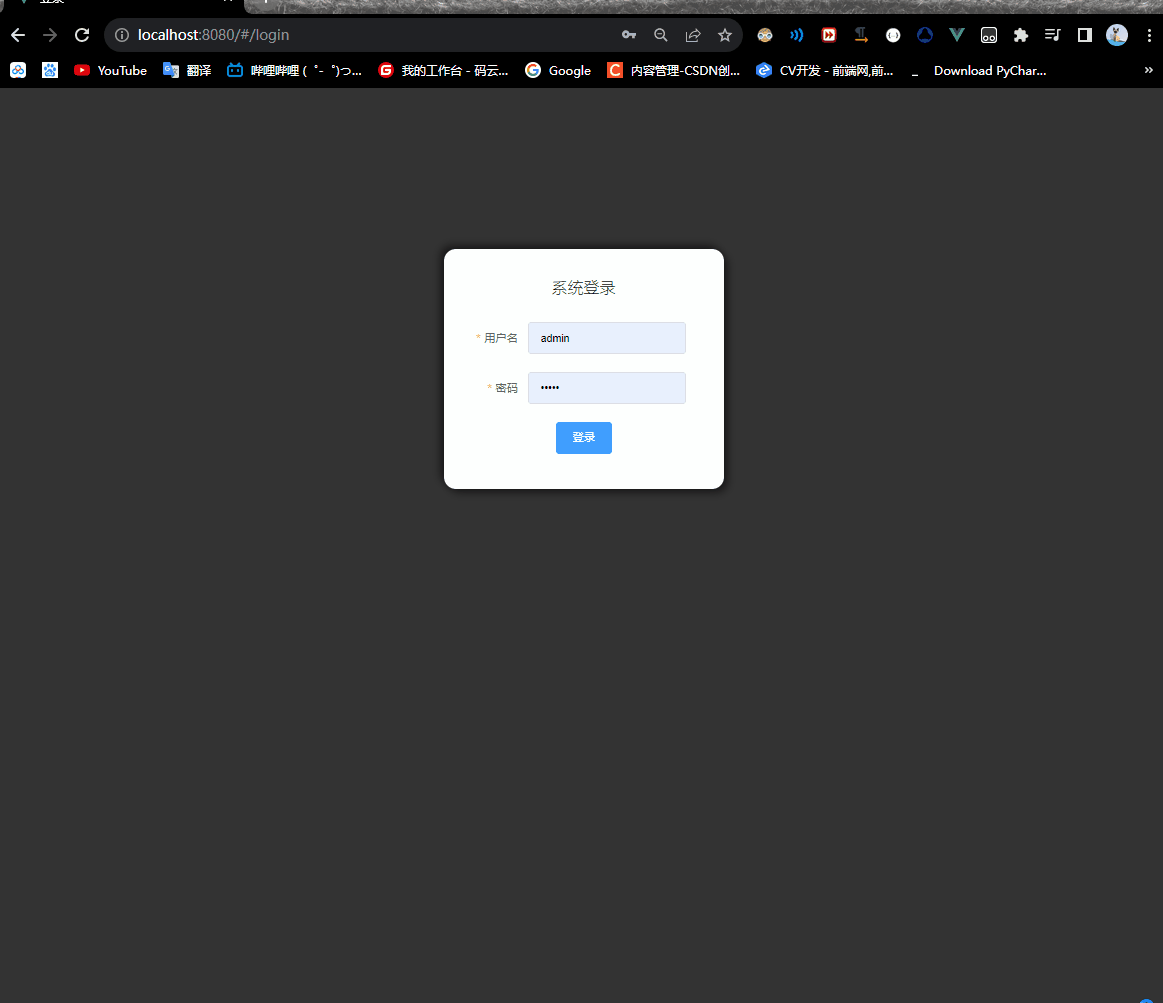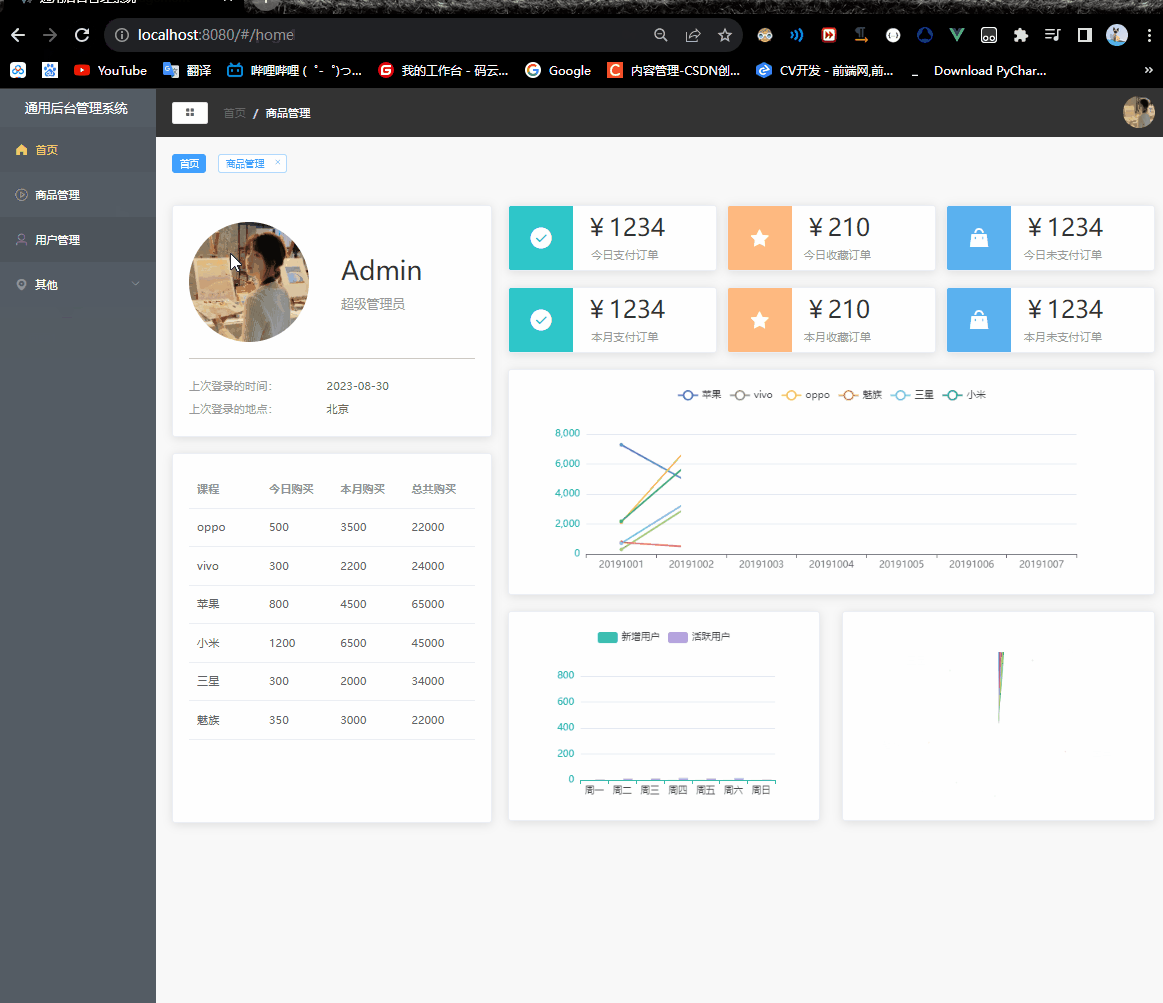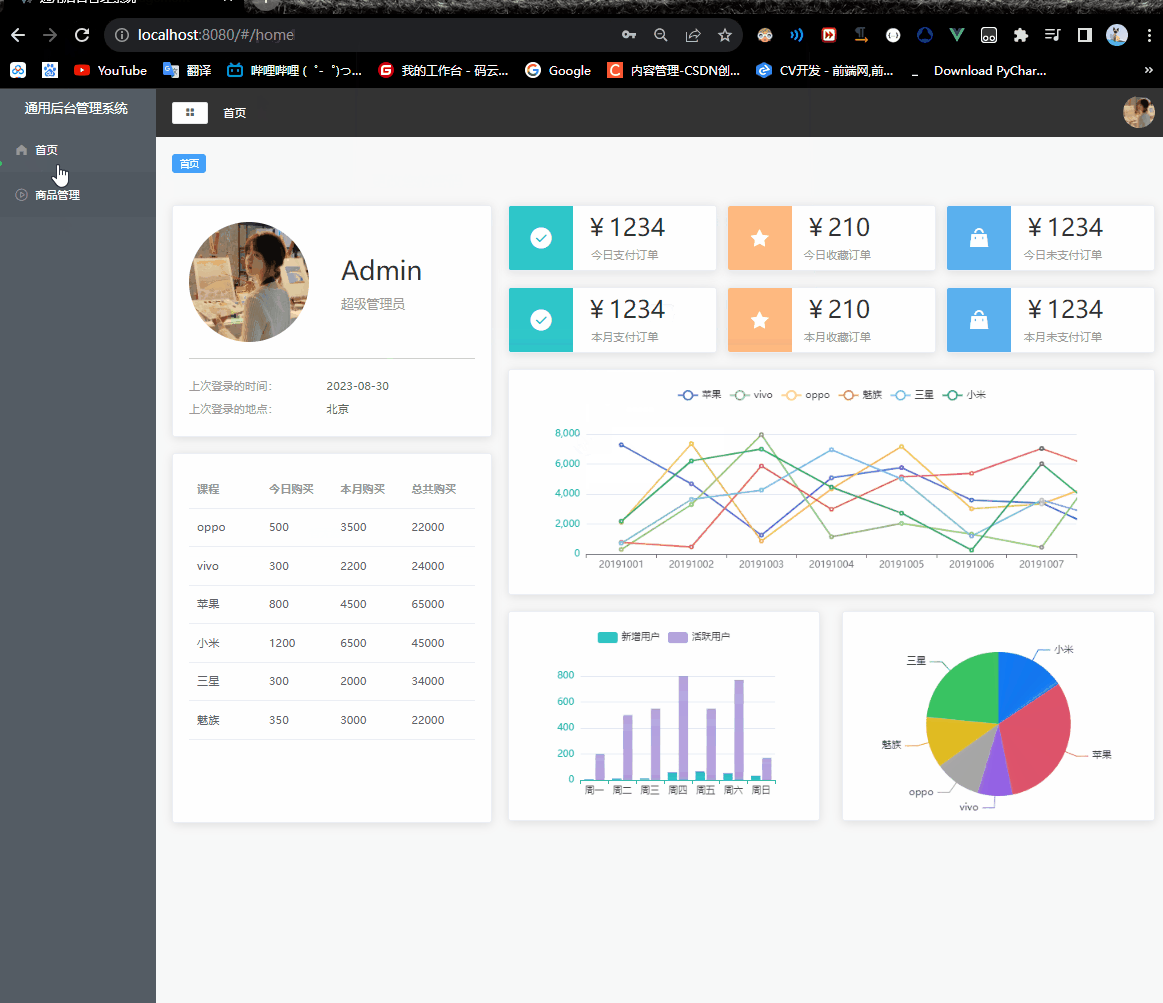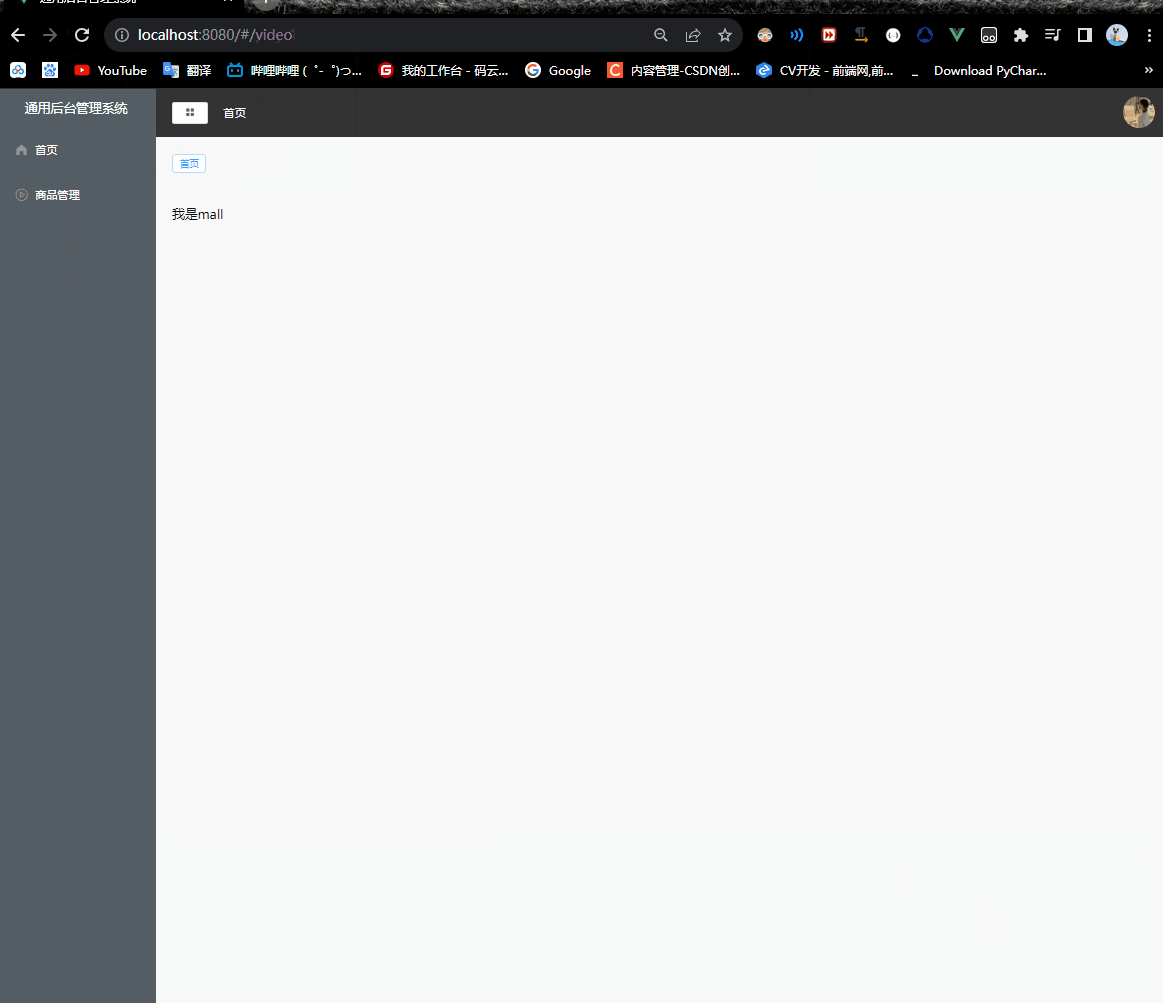
Vue2项目练手——通用后台管理项目第八节
Vue2项目练手——通用后台管理项目 菜单权限功能tab.jsLogin.vueCommonAside.vuerouter/index.js 权限管理问题解决router/tab.jsCommonHeader.vuemain.js 菜单权限功能 不同的账号登录,会有不同的菜单权限通过url输入地址来显示页面对于菜单的数据在不同页面之间的…...

leetcode872. 叶子相似的树(java)
叶子相似的树 题目描述递归 题目描述 难度 - 简单 leetcode - 872. 叶子相似的树 请考虑一棵二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个 叶值序列 。 举个例子,如上图所示,给定一棵叶值序列为 (6, 7, 4, 9, 8) 的树。 如果…...
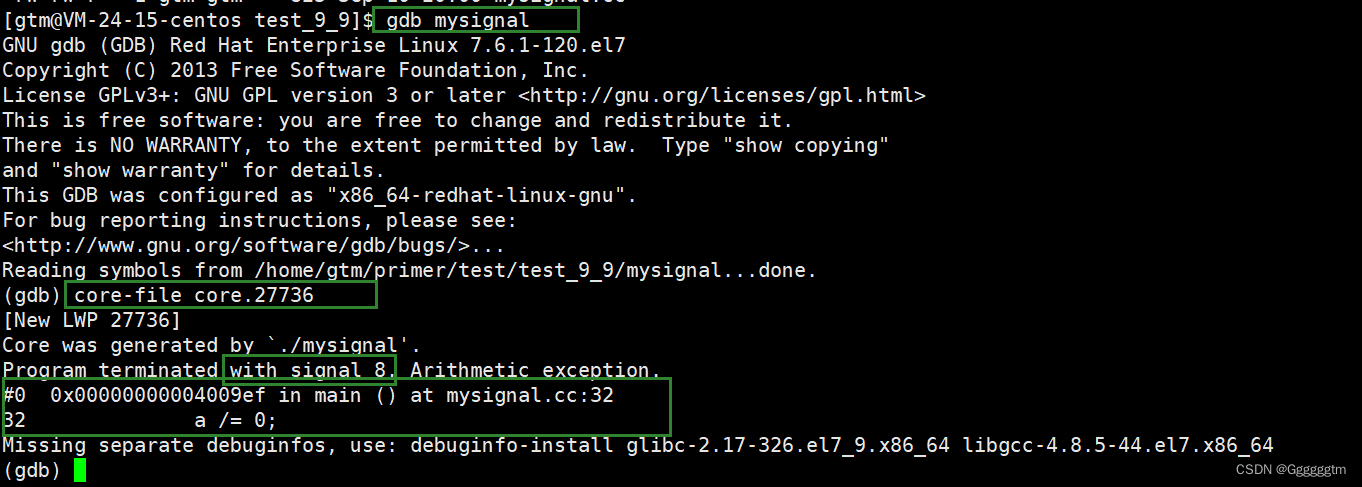
【Linux从入门到精通】信号(初识信号 信号的产生)
本篇文章会对Linux下的信号进行详细解释。主要内容是什么是信号、信号的产生、核心转储等问题。希望本篇文章会对你有所帮助。 文章目录 引入 一、初识信号 1、1 生活中的信号 1、2 Linux 下的信号 1、3 信号进程所得的初识结论 二、信号的产生 2、1 用户通过终端输入产生信号 …...
)
Golang综合项目实战(一)
Golang综合项目实战(一) 01-项目简介02-项目架构、术语、运行结果03-创建并初始化项目04-创建用户模型和错误处理05-创建密码加密工具类06-保存密码之前的hooks07-创建用户名密码验证工具类08-用户数据库操作逻辑09-操作用户service10-创建商品分类模型…...

springmvc 获取项目中的所有请求路径
springboot/springmvc 获取项目中的所有请求路径 1. 编写业务代码 Autowiredprivate WebApplicationContext applicationContext;GetMapping("/getAllURL")public RestfulResult getAllURL() {// 获取springmvc处理器映射器组件对象 RequestMappingHandlerMapping无…...

【React学习】React高级特性
1. 函数式组件和类组件区别 函数式组件 函数式组件是一种简单的组件定义方式,它是一个以JavaScript函数为基础的组件。 可以把函数式组件理解为纯函数,它的输入为props,输出为JSX。函数式组件没有状态,也没有生命周期。 functio…...
如何在Windows系统搭建filebrowser私人网盘并实现在外网访问本地内网
Windows系统搭建网盘神器filebrowser结合内网穿透实现公网访问 文章目录 Windows系统搭建网盘神器filebrowser结合内网穿透实现公网访问前言1.下载安装File Browser2.启动访问File Browser3.安装cpolar内网穿透3.1 注册账号3.2 下载cpolar客户端3.3 登录cpolar web ui管理界面3…...
)
蓝桥杯官网练习题(算式900)
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 小明的作业本上有道思考题: 看下面的算式: (□□□□-□□□□)*□□900其中的小方块代表 0 ~ 9 的数字,这 10 个方块刚好包含了…...
)
【C++从入门到精通】第1篇:C++基础知识(上)
文章目录 1.1 C语句和程序结构1.1.1 本篇介绍1.1.2 语句1.1.3 函数和主函数1.1.4 解析Hello world1.1.5 语法和语法错误1.1.6 练习时间 1.2 注释1.2.1 单行注释1.2.2 多行注释1.2.3 正确使用注释1.2.4 注释掉代码 1.3 对象和变量1.3.1 数据和值1.3.2 对象和变量1.3.3 变量实例化…...

liunx系统无sudo或管理员权限安装rar解压安装包
liunx无sudo权限安装rar解压安装包 (1)正常liunx安装rar(2)无sudo\root(管理员身份)时如何安装rar (1)正常liunx安装rar 1、下载安装包 WinRAR archiver, a powerful tool to process RAR and ZIP files (r…...
浅析目标检测入门算法:YOLOv1,SSD,YOLOv2,YOLOv3,CenterNet,EfficientDet,YOLOv4
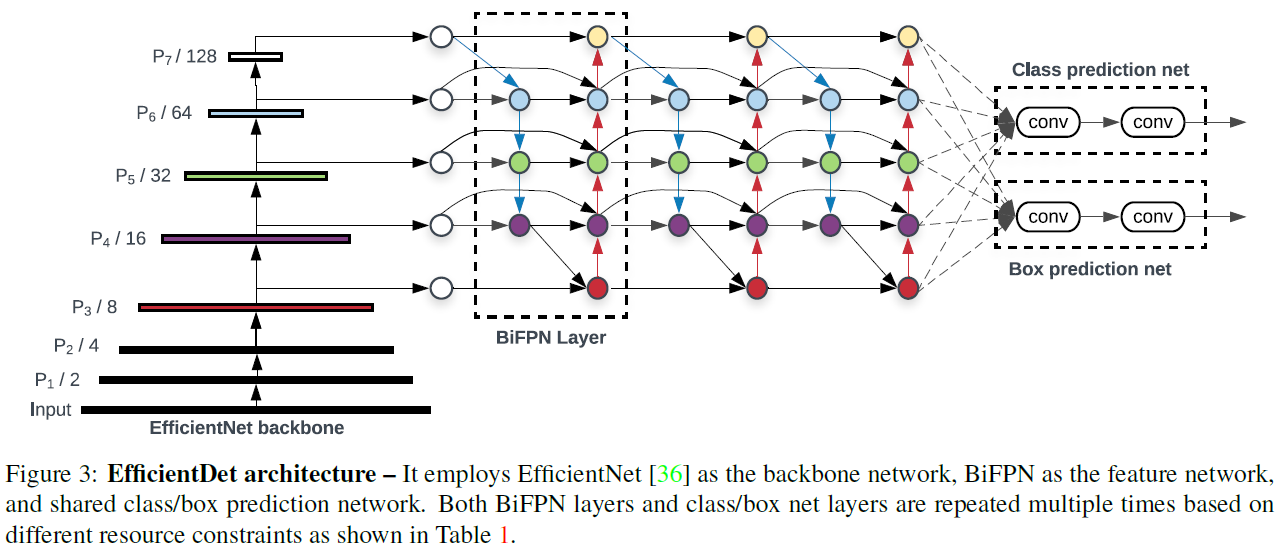
本文致力于让读者对以下这些模型的创新点和设计思想有一个大体的认识,从而知晓YOLOv1到YOLOv4的发展源流和历史演进,进而对目标检测技术有更为宏观和深入的认知。本文讲解的模型包括:YOLOv1,SSD,YOLOv2,YOLOv3,CenterNet,EfficientDet,YOLOv4…...

别再死记硬背了!用MATLAB的`strel`函数玩转形态学:从结构元素选择到开闭运算除噪
别再死记硬背了!用MATLAB的strel函数玩转形态学:从结构元素选择到开闭运算除噪 在数字图像处理的学习过程中,很多初学者都会陷入一个误区:机械地记忆膨胀、腐蚀、开运算、闭运算的定义,却忽略了形态学操作中最关键的一…...

保姆级教程:用命令行搞定npm 2FA配置,告别网页来回跳转
命令行极客指南:npm 2FA全流程自动化实战 每次发布npm包都要掏出手机查验证码?在无头服务器上部署时被2FA卡住?作为命令行重度用户,我们完全可以在终端里完成从启用、日常使用到禁用2FA的全流程。本文将带你用纯CLI方式打通npm双因…...

Qwerty Learner:终极打字练习与单词记忆完全指南
Qwerty Learner:终极打字练习与单词记忆完全指南 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https://gitcode.…...

嵌入式UI开发提速秘籍:用GUI Guider+NXP工具链为LVGL 8.3.2快速设计界面并集成到Keil工程
嵌入式UI开发效率革命:GUI Guider与Keil工程的无缝整合实战 在嵌入式系统开发中,用户界面(UI)的设计与实现往往是最耗时的环节之一。传统的手写代码方式不仅效率低下,而且难以快速迭代和调整。本文将介绍如何利用NXP的GUI Guider工具与Keil开…...
)
NotebookLM深度适配语言学研究全流程(附Linguistic Annotation Pipeline v2.1实测报告)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM语言学研究辅助的范式变革 从静态语料库到动态知识图谱的跃迁 NotebookLM 不再将语言学材料视为孤立文本,而是通过语义锚点(Semantic Anchors)自动识别术…...

Vue绘图画布组件:零基础打造专业级绘图应用
Vue绘图画布组件:零基础打造专业级绘图应用 【免费下载链接】vue-drawing-canvas VueJS Component for drawing on canvas. 项目地址: https://gitcode.com/gh_mirrors/vu/vue-drawing-canvas vue-drawing-canvas 是一个功能强大的Vue.js画布绘图组件&#x…...

颠覆性英雄联盟智能助手:如何用League Akari告别繁琐操作,专注游戏核心
颠覆性英雄联盟智能助手:如何用League Akari告别繁琐操作,专注游戏核心 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit …...

普冉PY32F0系列开发:如何用VSCode+Cortex-Debug插件实现媲美Keil的图形化调试体验?
普冉PY32F0开发实战:VSCodeCortex-Debug打造专业级嵌入式调试环境 在嵌入式开发领域,高效的调试工具往往能决定项目的成败。对于使用普冉PY32F0系列Cortex-M0 MCU的开发者而言,传统商业IDE虽然功能完善,但存在许可成本高、跨平台支…...

Maple Mono 字体配置终极指南:从基础安装到高级定制
Maple Mono 字体配置终极指南:从基础安装到高级定制 【免费下载链接】maple-font Maple Mono: Open source monospace font with round corner, ligatures and Nerd-Font icons for IDE and terminal, fine-grained customization options. 带连字和控制台图标的圆角…...

Buildah:从Dockerfile到OCI镜像的构建原理与生产实践
1. 项目概述:从 Dockerfile 到 OCI 镜像的“幕后推手”如果你用过 Docker,那你一定对docker build命令和Dockerfile不陌生。输入一行命令,等待片刻,一个包含了应用及其所有依赖的、可移植的容器镜像就生成了。这感觉就像魔法&…...