《动手学深度学习 Pytorch版》 4.5 权重衰减
4.5.1 范数与权重衰减
整节理论,详见书本。
4.5.2 高维线性回归
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
# 生成一些数据,为了使过拟合效果更明显,将维数增加到 200 并使用一个只包含 20 个样本的小训练集。
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05 # 设置真实参数
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
4.5.3 从零开始实现
- 初始化模型参数
def init_params():w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)b = torch.zeros(1, requires_grad=True)return [w, b]
- 定义 L 2 L_2 L2 范数惩罚
def l2_penalty(w):return torch.sum(w.pow(2)) / 2
-
定义训练代码实现
损失函数直接通过 d2l 包导入,损失包含了惩罚项。
def train(lambd):w, b = init_params()net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_lossnum_epochs, lr = 100, 0.003animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',xlim=[5, num_epochs], legend=['train', 'test'])for epoch in range(num_epochs):for X, y in train_iter:# 增加了L2范数惩罚项,# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量l = loss(net(X), y) + lambd * l2_penalty(w)l.sum().backward()d2l.sgd([w, b], lr, batch_size)if (epoch + 1) % 5 == 0:animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),d2l.evaluate_loss(net, test_iter, loss)))print('w的L2范数是:', torch.norm(w).item())
- 忽略正则化直接训练
train(lambd=0)
w的L2范数是: 14.042692184448242

- 使用权重衰减
train(lambd=3)
w的L2范数是: 0.35160931944847107

4.5.4 简洁实现
def train_concise(wd):net = nn.Sequential(nn.Linear(num_inputs, 1))for param in net.parameters():param.data.normal_()loss = nn.MSELoss(reduction='none')num_epochs, lr = 100, 0.003trainer = torch.optim.SGD([{"params":net[0].weight,'weight_decay': wd}, # PyTorch默认同时衰减权重和偏置,此处使用 weight_decay指定仅权重衰减{"params":net[0].bias}], lr=lr)animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',xlim=[5, num_epochs], legend=['train', 'test'])for epoch in range(num_epochs):for X, y in train_iter:trainer.zero_grad()l = loss(net(X), y)l.mean().backward()trainer.step()if (epoch + 1) % 5 == 0:animator.add(epoch + 1,(d2l.evaluate_loss(net, train_iter, loss),d2l.evaluate_loss(net, test_iter, loss)))print('w的L2范数:', net[0].weight.norm().item())
train_concise(0)
w的L2范数: 12.836501121520996

train_concise(3)
w的L2范数: 0.3978956639766693

练习
(1)在本节的估计问题中使用 λ \lambda λ 的值进行实验。绘制训练精度和测试精度有关 λ \lambda λ 的函数图,可以观察到什么?
随着 λ \lambda λ 的增大可以改善过拟合的现象,但是 λ \lambda λ 过大也会影响收敛。
for i in (0, 2, 8, 32, 128, 256):train_concise(i)
w的L2范数: 0.008308843709528446






(2)使用验证集来找最优值 λ \lambda λ。它真的是最优值吗?
不至于说是最优的,毕竟再怎么样验证集也和训练集分布有些许区别,只能说是比较接近最优值。
(3)如果我们使用 ∑ i ∣ w i ∣ \sum_i|w_i| ∑i∣wi∣ 作为我们选择的惩罚( L 1 L_1 L1正则化),那么更新的公式会是什么样子?
如果使用 L 1 L_1 L1 正则化则最小化预测损失和惩罚项之和为:
L R ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w T x ( i ) + b − y ( i ) ) 2 + λ ∑ i = 1 n ∣ w i ∣ LR(\boldsymbol{w},b)=\frac{1}{n}\sum_{i=1}^n\frac{1}{2}(\boldsymbol{w}^T\boldsymbol{x}^{(i)}+b-y^{(i)})^2+\lambda\sum^n_{i=1}|w_i| LR(w,b)=n1i=1∑n21(wTx(i)+b−y(i))2+λi=1∑n∣wi∣
L 1 L_1 L1 范数有求导问题,在此,规定在不可导点 x = 0 x=0 x=0 的导数为 0,则:
w ← w − η ∂ L R ( w , b ) ∂ w = w − η ∣ B ∣ ∑ i ∈ B x ( i ) ( w T x ( i ) + b − y ( i ) ) − λ η sign ( w ) \boldsymbol{w}\gets\boldsymbol{w}-\eta\ \frac{\partial LR(\boldsymbol{w},b)}{\partial\boldsymbol{w}}=\boldsymbol{w}-\frac{\eta}{|B|}\sum_{i\in B}\boldsymbol{x}^{(i)}(\boldsymbol{w}^T\boldsymbol{x}^{(i)}+b-y^{(i)})-\lambda\ \eta\ \text{sign}(\boldsymbol{w}) w←w−η ∂w∂LR(w,b)=w−∣B∣ηi∈B∑x(i)(wTx(i)+b−y(i))−λ η sign(w)
(4)我们知道 ∣ ∣ w ∣ ∣ 2 = w T w ||\boldsymbol{w}||^2=\boldsymbol{w}^T\boldsymbol{w} ∣∣w∣∣2=wTw。能找到类似的矩阵方程吗?(见 2.3.10 节中的弗罗贝尼乌斯范数)
弗罗贝尼乌斯范数时矩阵元素平方和的平方根:
∣ ∣ X ∣ ∣ F = ∑ i = 1 m ∑ j = 1 n x i j 2 ||\boldsymbol{X}||_F=\sqrt{\sum^m_{i=1}\sum^n_{j=1}x^2_{ij}} ∣∣X∣∣F=i=1∑mj=1∑nxij2
和L2范数的平方相似,弗罗贝尼乌斯范数的平方:
∣ ∣ X ∣ ∣ F 2 = X T X ||\boldsymbol{X}||_F^2=\boldsymbol{X}^T\boldsymbol{X} ∣∣X∣∣F2=XTX
(5)回顾训练误差和泛化误差之间的关系。除了权重衰减、增加训练数据、使用适当复杂度的模型,还有其他方法来处理过拟合吗?
Dropout暂退法、多种模型组合等
(6)在贝叶斯统计中,我们使用先验和似然的乘积,通过公式 P ( w ∣ x ) ∝ P ( x ∣ w ) P ( w ) P(w|x)\propto P(x|w)P(w) P(w∣x)∝P(x∣w)P(w) 得到后验。如何得到正则化的 P ( w ) P(w) P(w)?
以下参见王木头大佬的视频《贝叶斯解释“L1和L2正则化”,本质上是最大后验估计。如何深入理解贝叶斯公式?》
使用最大后验估计,令:
w = arg max w P ( w ∣ x ) = arg max w P ( x ∣ w ) P ( x ) ⋅ P ( w ) = arg max w P ( x ∣ w ) ⋅ P ( w ) = arg max w log ( P ( x ∣ w ) ⋅ P ( w ) ) = arg max w ( log P ( x ∣ w ) + log P ( w ) ) \begin{align} w&=\mathop{\arg\max}\limits_{w}P(w|x)\\ &=\mathop{\arg\max}\limits_{w}\frac{P(x|w)}{P(x)}\cdot P(w)\\ &=\mathop{\arg\max}\limits_{w}P(x|w)\cdot P(w)\\ &=\mathop{\arg\max}\limits_{w}\log(P(x|w)\cdot P(w))\\ &=\mathop{\arg\max}\limits_{w}(\log P(x|w)+\log P(w))\\ \end{align} w=wargmaxP(w∣x)=wargmaxP(x)P(x∣w)⋅P(w)=wargmaxP(x∣w)⋅P(w)=wargmaxlog(P(x∣w)⋅P(w))=wargmax(logP(x∣w)+logP(w))
其中:
- ( 2 ) ⇒ ( 3 ) (2)\Rightarrow(3) (2)⇒(3) 是由于分母 P ( x ) P(x) P(x) 是与 w w w 无关的常数,故可以忽略。
- ( 3 ) ⇒ ( 4 ) (3)\Rightarrow(4) (3)⇒(4) 是由于习惯上添加 log \log log 运算。
P ( w ) P(w) P(w) 作为先验概率可以任取
- 如果取高斯分布 w ∼ N ( 0 , σ 2 ) w\sim\mathrm{N}(0,\sigma^2) w∼N(0,σ2),则出现 L 2 L_2 L2 正则化:
log P ( w ) = log ∏ i 1 σ 2 π e − ( w i − 0 ) 2 2 σ 2 = − 1 2 σ 2 ∑ i w i 2 + C \begin{align} \log P(w)&=\log\prod_i\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(w_i-0)^2}{2\sigma^2}}\\ &=-\frac{1}{2\sigma^2}\sum_iw_i^2+C \end{align} logP(w)=logi∏σ2π1e−2σ2(wi−0)2=−2σ21i∑wi2+C
- 如果取拉普拉斯分布 w ∼ L a p l a c e ( 0 , b ) w\sim\mathrm{Laplace}(0,b) w∼Laplace(0,b),则出现 L 1 L_1 L1 正则化:
log P ( w ) = log ∏ i 1 2 b e − ∣ w i − 0 ∣ b = − 1 b ∑ i ∣ w i ∣ + C \begin{align} \log P(w)&=\log\prod_i\frac{1}{2b}e^{-\frac{|w_i-0|}{b}}\\ &=-\frac{1}{b}\sum_i|w_i|+C \end{align} logP(w)=logi∏2b1e−b∣wi−0∣=−b1i∑∣wi∣+C
太奇妙了!
相关文章:
《动手学深度学习 Pytorch版》 4.5 权重衰减
4.5.1 范数与权重衰减 整节理论,详见书本。 4.5.2 高维线性回归 %matplotlib inline import torch from torch import nn from d2l import torch as d2l# 生成一些数据,为了使过拟合效果更明显,将维数增加到 200 并使用一个只包含 20 个样…...

数据脱敏的风险量化评估介绍
1、背景介绍 当前社会信息化高速发展,网络信息共享加速互通,数据呈现出规模大、流传快、类型多以及价值密度低的特点。人们可以很容易地对各类数据实现采集、发布、存储与分析,然而一旦带有敏感信息的数据被攻击者获取将会造成个人隐私的严重…...
)
SpringCloudGateway网关实战(三)
SpringCloudGateway网关实战(三) 上一章节我们讲了gateway的内置过滤器Filter,本章节我们来讲讲全局过滤器。 自带全局过滤器 在实现自定义全局过滤器前, spring-cloud-starter-gateway依赖本身就自带一些全局过滤器࿰…...

08在MyBatis-Plus中配置多数据源
配置多数据源 模拟多库场景 适用于多种场景: 多库(操作的表分布在不同数据库当中),读写分离(有的数据库负责查询的功能,有的数据库负责增删该的功能),一主多从,混合模式等 第一步: 模拟多库,在mybatis_plus数据库中创建user表,在mybatis_plus_1数据库中创建product表 --创建…...
Centos8安装docker并配置Kali Linux图形化界面
鉴于目前网上没有完整的好用的docker安装kali桌面连接的教程,所以我想做一个。 准备工作 麻了,这服务器供应商提供的镜像是真的纯净,纯净到啥都没有。 问题一:Centos8源有问题 Error: Failed to download metadata for repo ap…...
游戏开发初等数学基础
凑数图() 立体图形面积体积 1. 立方体(Cube): 表面积公式: 6 a 2 6a^2 6a2 (其中 a a a 是边长)。体积公式: a 3 a^3 a3 (其中 a a a 是边长)。 2. 球体(Sphere): 表面积公…...

svg图片代码data:image/svg+xml转png图片方法
把代码保存为html格式的文件中,用浏览器访问,即可右键保存 从AI软件或其它网站得到svg图片代码后,把他复制到下面源码上 注意:src""图片地址中,一些参数的含义 d‘这里是图片代码数据’ viewBox是图片显示区域,宽,高等 fill%23000000’这里表示颜色 ,后面6位0表示黑色…...

解决问题:Replace `‘vue‘;⏎` with `“vue“;`
使用vscode写vue文件的问题: Replace vue;⏎ with "vue"; error Replace v-model:value"xxx"placeholder"inputsearch prettier/prettier 7:38 error Insert ⏎ potentially fixable with the --fix option 原因:格式问题&a…...
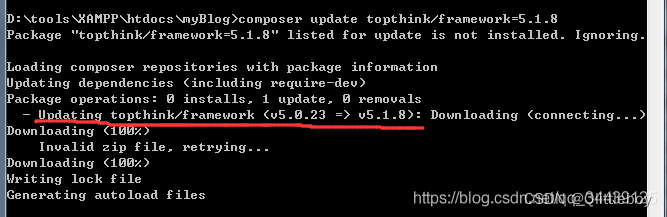
ThinkPHP 5.0通过composer升级到5.1,超级简单
事情是这样的,我实现一个验证码登录的功能,但是这个验证码的包提示tp5的版本可以是5.1.1、5.1.2、5.1.3。但我使用的是5.0,既然这样,那就升个级呗,百度了一下,结果发现大部分都是讲先备份application和修改…...
计算机竞赛 多目标跟踪算法 实时检测 - opencv 深度学习 机器视觉
文章目录 0 前言2 先上成果3 多目标跟踪的两种方法3.1 方法13.2 方法2 4 Tracking By Detecting的跟踪过程4.1 存在的问题4.2 基于轨迹预测的跟踪方式 5 训练代码6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习多目标跟踪 …...

一文了解大模型工作原理——以ChatGPT为例
文章目录 写在前面1.Tansformer架构模型2.ChatGPT原理3.提示学习与大模型能力的涌现3.1 提示学习3.2 上下文学习3.3 思维链 4.行业参考建议4.1 拥抱变化4.2 定位清晰4.3 合规可控4.4 经验沉淀 写在前面 2022年11月30日,ChatGPT模型问世后,立刻在全球范围…...

CPP-Templates-2nd--第十九章 萃取的实现 19.7---
目录 19.7 其它的萃取技术 19.7.1 If-Then-Else 19.7.2 探测不抛出异常的操作 19.7.3 萃取的便捷性(Traits Convenience) 别名模板和萃取(Alias Templates And Traits) 变量模板和萃取(Variable Templates and Traits&…...
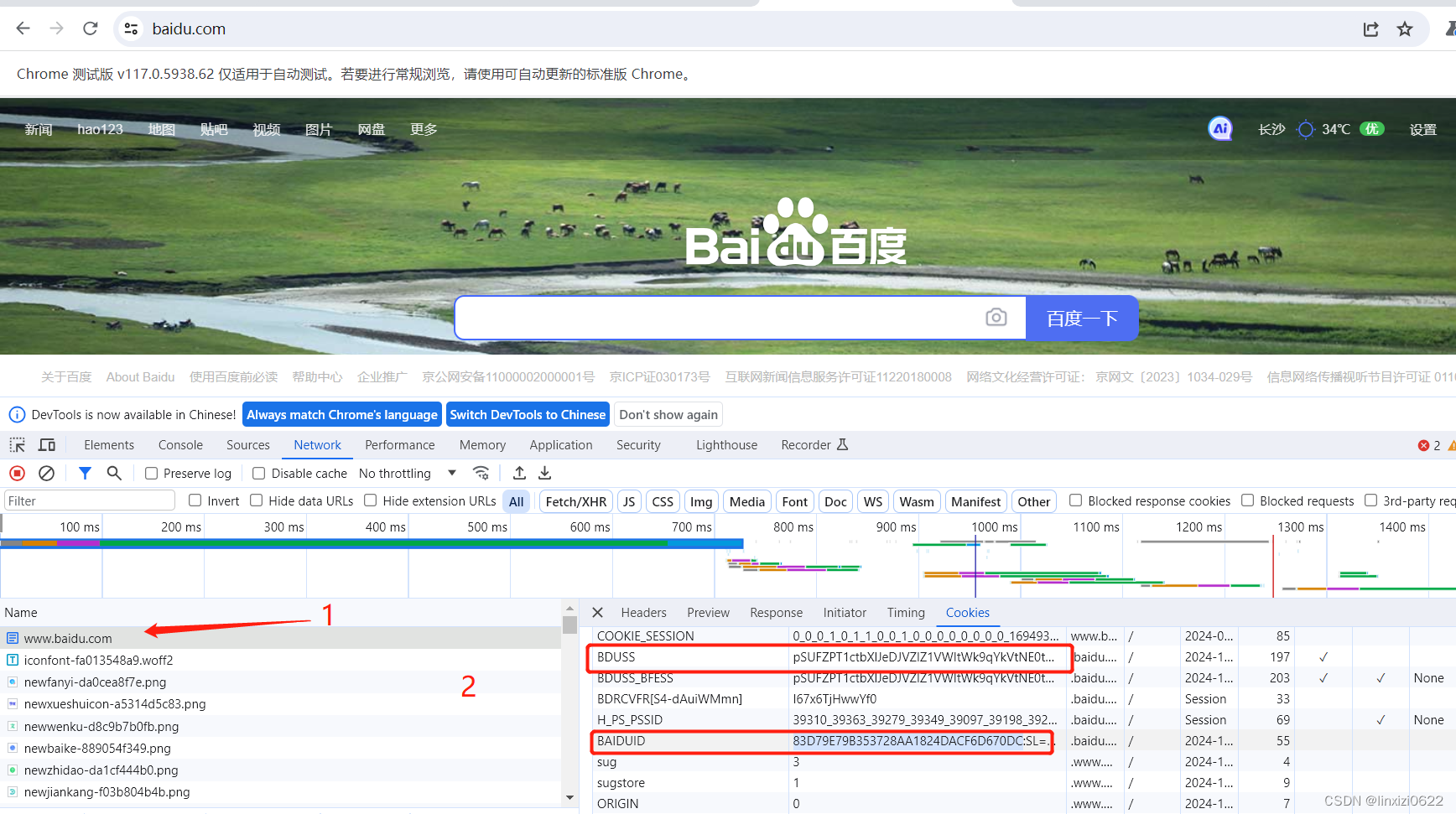
python 采用selenium+cookies 获取登录后的网页
百度网页由于需要登陆手机短信验证。比较麻烦 这里我采用先人工登录百度账号,然后将百度账号的相关cookies保存下来 然后采用selenium动态登录网页 整体代码如下 from selenium import webdriverimport timeoptions webdriver.ChromeOptions()options.add_argu…...

【测试开发】答疑篇 · 什么是软件测试
【测试开发】答疑篇 文章目录 【测试开发】答疑篇1. 生活中的测试2. 什么是软件测试3. 为什么要有测试/没有测试行不行4. 软件测试和软件开发的区别5. 软件测试和软件调试之间的区别6. 软件测试的岗位7. 优秀测试人员具备的素质 【测试开发】答疑篇 软件不一定是桌面应用&#…...
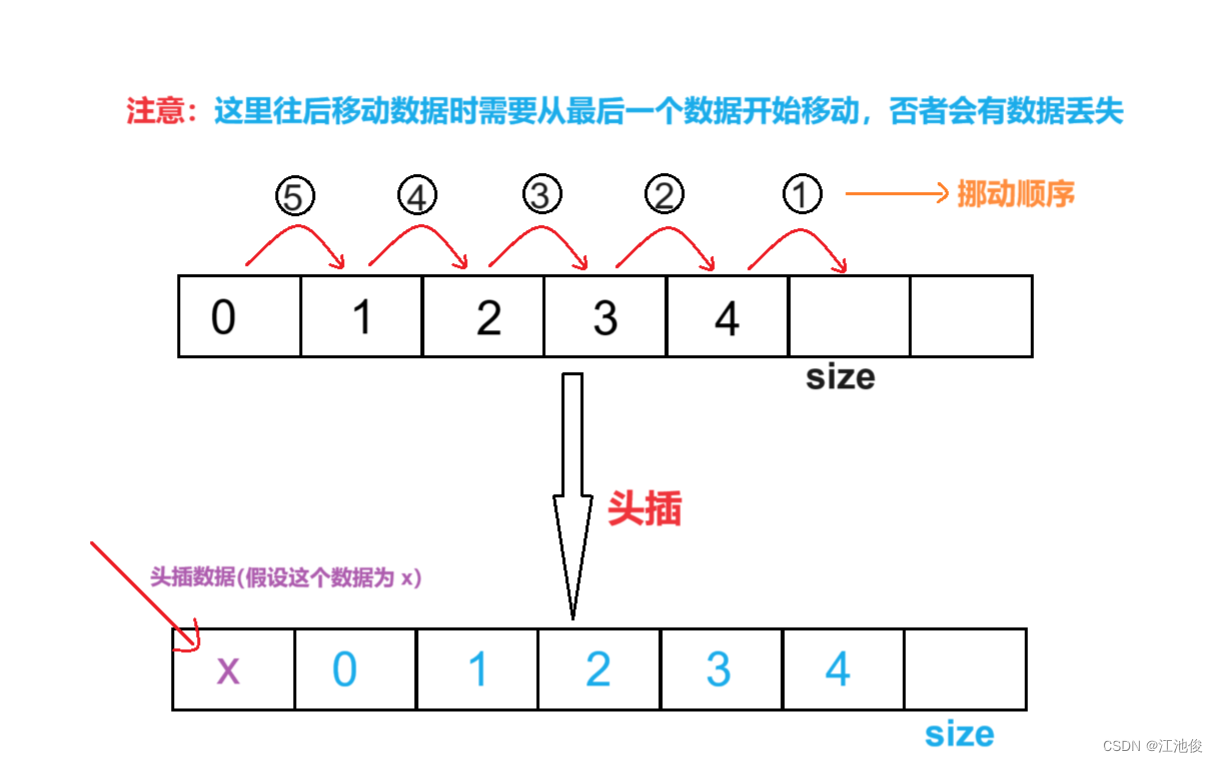
深入解析顺序表:揭开数据结构的奥秘,掌握顺序表的精髓
💓 博客主页:江池俊的博客⏩ 收录专栏:数据结构探索👉专栏推荐:✅C语言初阶之路 ✅C语言进阶之路💻代码仓库:江池俊的代码仓库🔥编译环境:Visual Studio 2022Ἰ…...

数据风险量化评估方案
一、企业面临数据安全的痛点 1、企业缺少清晰的数据安全意识 各部门重视度不够,缺少主动数据安全管控意识。数据安全管控架构不清晰,职责划分不明确。对数据安全管控认识不全面、不深刻。工作人员对于所持有的数据缺乏概念,导致数据的价值无…...

EasyAVFilter代码示例之将视频点播文件转码成HLS(m3u8+ts)视频点播格式
以下是一套完整的视频点播功能开发源码,就简简单单几行代码,就可以完成原来ffmpeg很复杂的视频点播转码调用流程,而且还可以集成在自己的应用程序中调用,例如java、php、cgo、c、nodejs,不需要再单独一个ffmpeg的进程来…...
动态规划 part 11)
day-50 代码随想录算法训练营(19)动态规划 part 11
123.买卖股票的最佳时机||| 分析:只能买卖两次,就是说有五个状态: 没有买过第一次买入第一次卖出第二次买入第二次卖出 思路:二维数组,记录五个状态 1.dp存储:dp[i][1] 第一次买入 dp[i][2] 第一次卖…...

自定义权限指令与防止连点指令
1.权限指令 // 注册一个全局自定义权限指令 v-permission Vue.directive(permission, {inserted: function(el, binding, vnode) {const {value} binding; // 指令传的值// user:edit:phone,sysData:sampleconst permissions [user:edit:address, sysData:entrust, sysData:…...
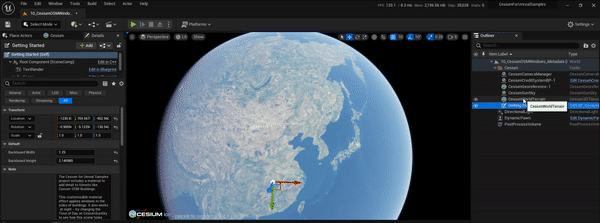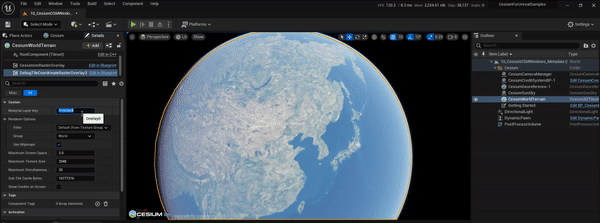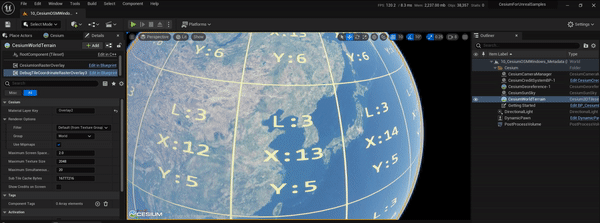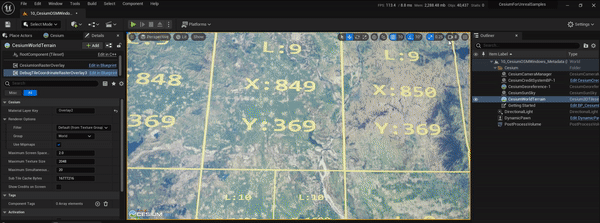
UE5、CesiumForUnreal实现瓦片坐标信息图层效果
文章目录 1.实现目标2.实现过程2.1 原理简介2.2 cesium-native改造2.3 CesiumForUnreal改造2.4 运行测试3.参考资料1.实现目标 参考CesiumJs的TileCoordinatesImageryProvider,在CesiumForUnreal中也实现瓦片坐标信息图层的效果,便于后面在调试地形和影像瓦片的加载调度等过…...

RISC-V DSP开发板实战:从环境搭建到BLDC电机控制全解析
1. 项目概述:一次难得的RISC-V DSP开发板深度体验机会 作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我见证了ARM架构从崭露头角到一统江湖的全过程。然而,近几年开源指令集架构RISC-V的异军突起,让我这个“老顽固”也感受到了…...

告别第三方工具:手把手教你打造微软官方WinPE系统维护盘
1. 为什么你需要一个官方WinPE维护盘? 每次电脑系统崩溃时,你是不是也在各大论坛疯狂搜索"如何重装系统"?市面上确实有很多第三方PE工具,比如老毛桃、微PE之类的,用起来确实方便。但作为一个在IT行业摸爬滚…...

如何精准下载GitHub项目中的特定文件或文件夹
如何精准下载GitHub项目中的特定文件或文件夹 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 在GitHub上查找开源资源时,开发者常常面临一个现实问题:如何仅获取项目中的特定模块而非整…...

中文大语言模型智能路由:统一接口调度多模型,实现降本增效
1. 项目概述:一个中文大语言模型路由器的诞生最近在折腾大语言模型应用开发的朋友,估计都遇到过这个头疼的问题:手头有好几个模型,比如智谱的GLM、百度的文心、阿里的通义,还有一堆开源的,每个模型都有自己…...

BetterNCM插件管理器实战指南:网易云音乐扩展架构深度解析
BetterNCM插件管理器实战指南:网易云音乐扩展架构深度解析 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer BetterNCM Installer是一款基于Rust语言开发的网易云音乐插件管理…...

模拟IC设计避坑指南:从gm/id曲线看懂增益、带宽与噪声的三角博弈
模拟IC设计中的gm/id方法论:增益、带宽与噪声的三角平衡艺术 在模拟集成电路设计的精密世界里,每个参数选择都如同走钢丝,需要设计师在相互制约的性能指标间找到完美平衡点。gm/id设计方法正是为这种复杂决策而生的一套系统化工具,…...

魔兽争霸3性能优化与界面修复:三步实现流畅游戏体验
魔兽争霸3性能优化与界面修复:三步实现流畅游戏体验 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3的卡顿、界面异常和功…...

Zig语言构建工具zcc详解:依赖管理与项目构建实践
1. 项目概述:一个为Zig语言量身打造的构建系统最近在折腾Zig语言项目时,发现了一个挺有意思的工具:git-on-my-level/zcc。乍一看这个名字,可能会让人联想到经典的C编译器gcc,或者猜测它是一个Zig语言的C编译器前端。但…...

自动驾驶汽车保险七大议题:从技术视角看责任转移与系统设计
1. 自动驾驶汽车保险的七个核心议题:从工程师视角看技术与责任的碰撞作为一名在汽车电子和嵌入式系统领域摸爬滚打了十几年的工程师,我亲眼见证了从ABS到自适应巡航,再到今天各种L2辅助驾驶的演进。每当和圈内朋友聊起全自动驾驶,…...

开源首发:DocCenter — 本地 HTML 工作台,治好 AI 时代的文档散落病
Tags:Python aiohttp 开源项目 AI工具 前端工程 全栈 工具分享 一、痛点:AI 时代的文档散落病 (对比传统文档管理 vs AI 生成文档的区别,说明为什么 VSCode/Notion 都不合适) 二、技术选型:为什么是单 Pyth…...