【八大经典排序算法】快速排序
【八大经典排序算法】快速排序
- 一、概述
- 二、思路实现
- 2.1 hoare版本
- 2.2 挖坑法
- 2.3 前后指针版本
- 三、优化
- 3.1 三数取中
- 3.1.1 最终代码
- 3.1.2 快速排序的特性总结
- 四、非递归实现快排

一、概述
说到快速排序就不得不提到它的创始人 hoare了。在20世纪50年代,计算机科学家们开始研究如何对数据进行排序,以提高计算机程序的效率。当时,常用的排序算法包括冒泡排序、插入排序和选择排序等。
然而,这些算法的效率都相对较低,特别是在处理大量数据时。于是,人们开始寻找更快速的排序算法。Tony Hoare 在研究中发现了一种基于分治思想的排序方法,即快速排序。
二、思路实现
快速排序的思想是任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
代码如下:
// 假设按照升序对array数组中[left, right]区间中的元素进行排序
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;// 按照基准值对数组的 [left, right)区间中的元素进行划分int keyi = PartSort(a, begin, end);//分成[begin,keyi-1] keyi [keyi+1,end]// 递归排[left, div)QuickSort(a, begin, keyi - 1);// 递归排[div+1, right)QuickSort(a, keyi + 1, end);
}
上述为快速排序递归实现的主框架,发现与二叉树前序遍历规则非常像,接下来只需分析如何按照基准值来对区间中数据进行划分的方式即可。
待排序集合分割时,将区间按照基准值划分为左右两半部分的常见方式有以下3种。
2.1 hoare版本
思路:
- 选择一个基准元素(key),可以是最左边也可以是最右边。
- 定义两个指针,一个指向数组的第一个元素(左指针),一个指向数组的最后一个元素(右指针)。(需要注意的是:若选择最左边的数据作为key,则需要right先走;若选择最右边的数据作为key,则需要left先走)
- 移动左指针,直到找到一个大于等于基准元素(key)的元素;移动右指针,直到找到一个小于等于基准元素(key)的元素。之后交换交换左右指针所指向的元素。然后不断重复上述步骤直到左指针大于右指针
- 最后将基准元素与右指针所指向的元素交换位置,此时基准元素位于正确的位置。此时左边元素>=key,右边元素<=key。
Tips:博主在这里解释一下为什么“若选择最左边的数据作为key,则需要right先走;若选择最右边的数据作为key,则需要left先走”,后续其他方法同理。
① :左边作key,右边先走,保证了相遇位置的值小于key或就是key的位置。
②:右边作key,左边先走,保证了相遇位置的值大于key或就是key的位置。
以①为例,L和R相遇无非就两种情况:L遇R,R遇L。
情况一:L遇R。在R停下来后,L还在走。由于R先走,R停下来的位置一定小于Key。相遇位置为R停下来的位置,一定比key小。
情况二:R遇L。再相遇的这一轮,L就不动了,R在移动。相遇位置即为L的位置。而L的位置就是key的位置 or 已经交换过一些轮次了,此时相遇位置一定比key小。
【动画演示】:

代码如下:
//[left, right]--采用左闭右闭
int PartSort(int* a, int left, int right)
{int keyi = left;while (left < right){//找到右边比key小的数while (left < right && a[right] <= a[keyi]){right--;}//找到左边比key大的数while (left < right && a[left] >= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);return left;
}void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
2.2 挖坑法
思路:
- .选出一个数据(一般是最左边或是最右边的)存放在key变量中,同时该数据位置形成一个坑。
- 还是左右指针left和right,left从左向右走,right从右向左走。(若在最左边挖坑,则需要R先走;若在最右边挖坑,则需要L先走)
- 移动右指针找到第一个比key小的数并填到坑位,此时右指针所在位置变成新的坑。然后移动左指针找到第一个比key大的数并填到坑位,此时左指针所在位置变成新的坑。然后和hoare版本一样,不断重复上述步骤即可
【动画演示】:

代码如下:
//挖坑法
int PartSort(int* a, int left, int right)
{int key = a[left];int hole = left;while (left < right){//找到右边比key小的值while (left < right && a[right] >= key){right--;}a[hole] = a[right];hole = right;//左边比key大的值while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
2.3 前后指针版本
思路:
- 选出一个key,一般是最左边或是最右边的。
- 起始时,prev指针指向序列开头,cur指针指向prev+1。
- 若cur指向的内容小于key,则prev先向后移动一位,然后交换prev和cur指针指向的内容,然后cur指针++;若cur指向的内容大于key,则cur指针直接++。如此进行下去,直到cur到达end位置,此时将key和++prev指针指向的内容交换即可。
【动画演示】:

代码如下:
//前后指针法
int PartSort(int* a, int left, int right)
{int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
三、优化
虽然已经可以解决问题了,但还有一个问题:
当选取的key每次都是中位数时,效率最好,时间复杂度为O(N*logN);但当数组有序时变成最坏,时间复杂度变为O(N^2)!
对于上述情况,这里有两种优化方式:
- 三数取中法选key
- 递归到小的子区间时,可以考虑使用插入排序
3.1 三数取中
这里博主给出一直最简单的方法:
int GetMidIndix(int* a, int left, int right)
{int mid = left + (right - left) / 2;if (a[left] < a[mid]){if (a[mid] < a[right])return mid;else if (a[mid] > a[right])return right;elsereturn left;}else//a[left]>=a[mid]{if (a[mid] > a[right])return mid;else if (a[mid] < a[right])return right;elsereturn left;}
}
3.1.1 最终代码
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}int GetMidIndix(int* a, int left, int right)
{int mid = left + (right - left) / 2;if (a[left] < a[mid]){if (a[mid] < a[right])return mid;else if (a[mid] > a[right])return right;elsereturn left;}else//a[left]>=a[mid]{if (a[mid] > a[right])return mid;else if (a[mid] < a[right])return right;elsereturn left;}
}// hoare
// [left, right]
//int PartSort(int* a, int left, int right)
//{
// int midi = GetMidIndix(a, left, right);
// Swap(&a[left], &a[midi]);
//
// int keyi = left;
// while (left < right)
// {
// //找到右边比key小的数
// while (left < right && a[right] <= a[keyi])
// {
// right--;
// }
//
// //找到左边比key大的数
// while (left < right && a[left] >= a[keyi])
// {
// left++;
// }
// Swap(&a[left], &a[right]);
// }
// Swap(&a[keyi], &a[left]);
// return left;
//}//挖坑法
//int PartSort(int* a, int left, int right)
//{
// int midi = GetMidIndix(a, left, right);
// Swap(&a[left], &a[midi]);
//
// int key = a[left];
// int hole = left;
// while (left < right)
// {
// //找到右边比key小的值
// while (left < right && a[right] >= key)
// {
// right--;
// }
// a[hole] = a[right];
// hole = right;
//
// //左边比key大的值
// while (left < right && a[left] <= key)
// {
// left++;
// }
// a[hole] = a[left];
// hole = left;
// }
// a[hole] = key;
// return hole;
//}//前后指针法
int PartSort(int* a, int left, int right)
{int midi = GetMidIndix(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;int keyi = PartSort(a, begin, end);//分成[begin,keyi-1] keyi [keyi+1,end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}
3.1.2 快速排序的特性总结
- 时间复杂度:O(N*logN)

- 空间复杂度:O(logN)
- 稳定性:不稳定
四、非递归实现快排
思路:
- 定义一个栈,然后将待排序的数组的起始索引和结束索引入栈。
- 通过前面将的三种分割区间的方法将数组的起始索引和结束索引之间的元素分成两部分,左边部分小于等于基准元素,右边部分大于等于基准元素。
- 由于非递归实现时,我们是通过从栈中两两取出维护待排序数组的下标,所以接下来就是如果左边部分的长度大于1,则将左边部分的起始索引和结束索引入栈;如果右边部分的长度大于1,则将右边部分的起始索引和结束索引入栈。最后循环此操作,直到栈为空。
代码如下:
//前后指针法
int PartSort(int* a, int left, int right)
{int midi = GetMidIndix(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}//快排非递归
void QuickSortNonR(int* a, int begin, int end)
{ST st;STInit(&st);STPush(&st, end);STPush(&st, begin);while (!STEmpty(&st)){int left = STTop(&st);STPop(&st);int right = STTop(&st);STPop(&st);int keyi = PartSort(a, left, right);//[left,keyi-1] keyi [keyi+1,right]if (keyi + 1 < right){STPush(&st, right);STPush(&st, keyi + 1);}if (keyi - 1 > left){STPush(&st, keyi - 1);STPush(&st, left);}}STDestroy(&st);
}


相关文章:
【八大经典排序算法】快速排序
【八大经典排序算法】快速排序 一、概述二、思路实现2.1 hoare版本2.2 挖坑法2.3 前后指针版本 三、优化3.1 三数取中3.1.1 最终代码3.1.2 快速排序的特性总结 四、非递归实现快排 一、概述 说到快速排序就不得不提到它的创始人 hoare了。在20世纪50年代,计算机科学…...

vue 父组件给子组件传递一个函数,子组件调用父组件中的方法
vue 中父子组件通信,props的数据类型可以是 props: {title: String,likes: Number,isPublished: Boolean,commentIds: Array,author: Object,callback: Function,contactsPromise: Promise // or any other constructor }在父组件中,我们在子组件中给他…...
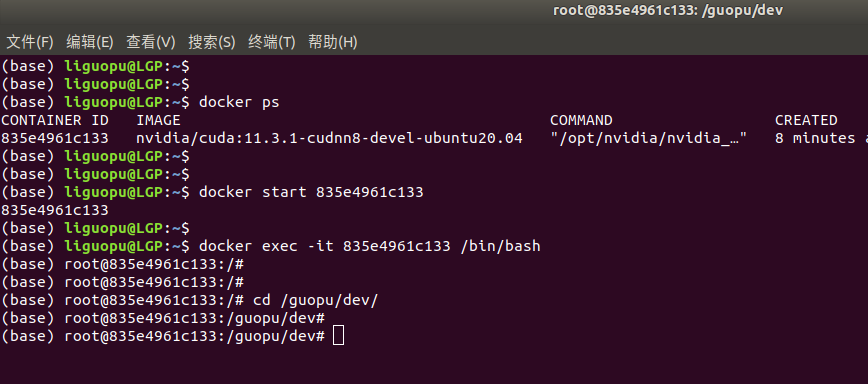
docker 获取Nvidia 镜像 | cuda |cudnn
本文分享如何使用docker获取Nvidia 镜像,包括cuda10、cuda11等不同版本,cudnn7、cudnn8等,快速搭建深度学习环境。 1、来到docker hub官网,查看有那些Nvidia 镜像 https://hub.docker.com/r/nvidia/cuda/tags?page2&name11.…...
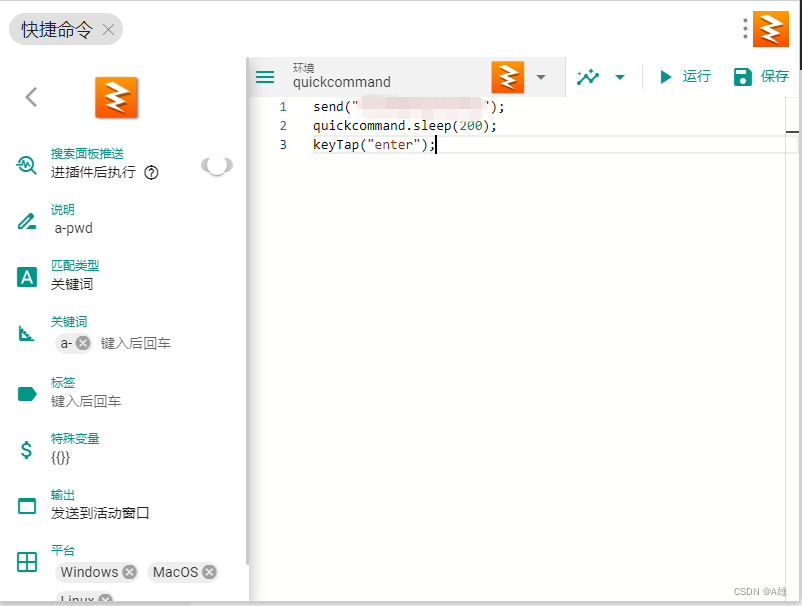
uTool快捷指令
send("************"); quickcommand.sleep(200); keyTap("enter");...

R reason ‘拒绝访问‘的解决方案
Win11系统 安装rms的时候报错: Error in loadNamespace(j <- i[[1L]], c(lib.loc, .libPaths()), versionCheck vI[[j]]) : namespace Matrix 1.5-4.1 is already loaded, but > 1.6.0 is required## 安装rms的时候报错,显示Matrix的版本太低…...

许战海战略文库|品类缩量时代:制造型企业如何跨品类打造份额产品?
所有商业战略的本质是围绕着竞争优势与竞争效率展开的。早期,所有品牌立足于从局部竞争优势出发。因此,品牌创建初期大多立足于单个品类。后期增长受限,就要跨品类持续扩大竞争优势,将局部竞争优势转化为长期竞争优势,如果固化不前很难获得增…...
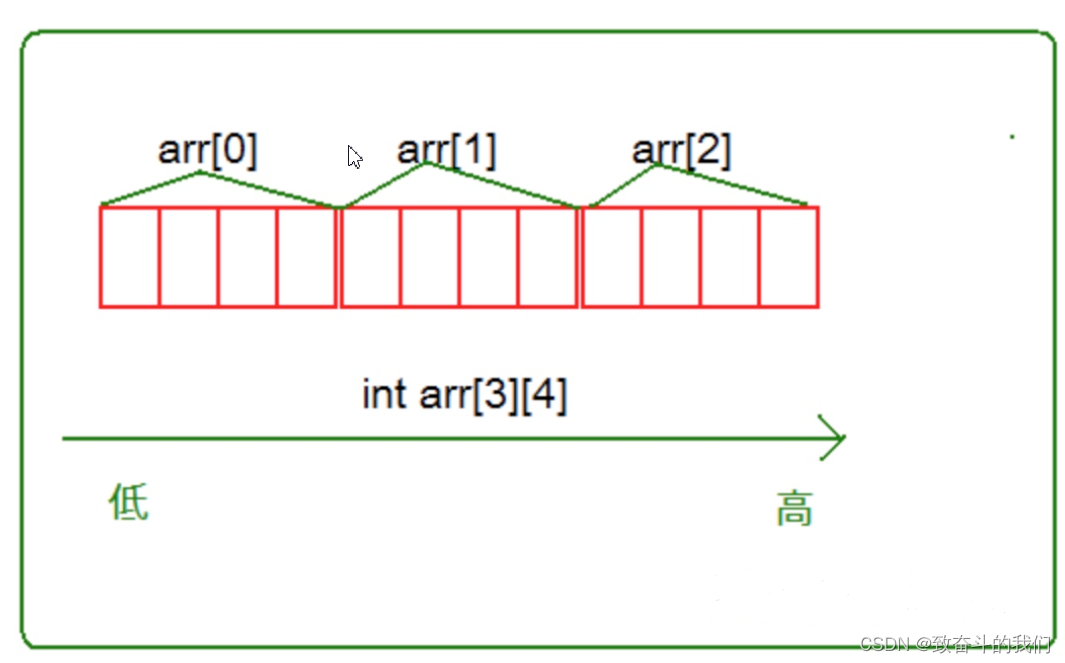
BIT-4-数组
一维数组的创建和初始化一维数组的使用 一维数组在内存中的存储 二维数组的创建和初始化二维数组的使用二维数组在内存中的存储 数组越界数组作为函数参数数组的应用实例1:三子棋 数组的应用实例2:扫雷游戏 1. 一维数组的创建和初始化 1.1 数组的创建 …...
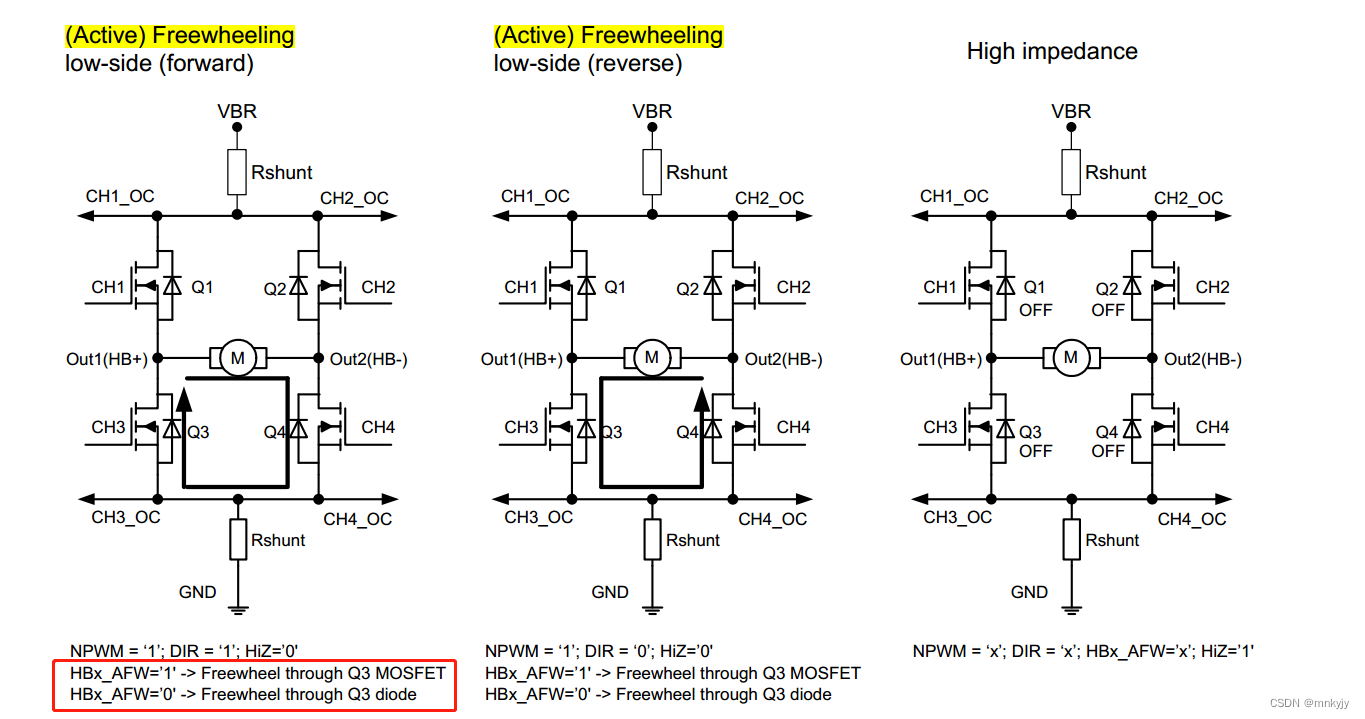
L9945的H桥续流模式
在H桥的配置中,包括两种续流模式:主动续流和被动续流。 一个L9945可输出两个H桥驱动。HB1在CMD3中配置,HB2在CMD7中配置。 主动续流:通过Q3的MOS的二极管来续流 被动续流:通过Q3外部的二极管来续流...
Ubuntu20.04安装Nvidia显卡驱动、CUDA11.3、CUDNN、TensorRT、Anaconda、ROS/ROS2
1.更换国内源 打开终端,输入指令: wget http://fishros.com/install -O fishros && . fishros 选择【5】更换系统源,后面还有一个要输入的选项,选择【0】退出,就会自动换源。 2.安装NVIDIA驱动 这一步最痛心…...

linux下使用crontab定时器,并且设置定时不执行的情况,附:项目启动遇到的一些问题和命令
打开终端,以root用户身份登录。 运行以下命令打开cron任务编辑器: crontab -e 如果首次编辑cron任务,会提示选择编辑器。选择你熟悉的编辑器,比如nano或vi,并打开相应的配置文件。 在编辑器中,添加一行类…...

linux下二进制安装docker最新版docker-24.0.6
一.基础环境 本次实操是公司技术培训下基于centos7.9操作系统安装docker最新版docker-24.0.6,下载地址是:https://download.docker.com/linux/static/stable/x86_64/docker-24.0.6.tgz 二. 下载Docker压缩包 mkdir -p /opt/docker-soft cd /opt/docker…...

计算机视觉 01(介绍)
一、深度学习 1.1 人工智能 1.2 人工智能,机器学习和深度学习的关系 机器学习是实现人工智能的一种途径,深度学习是机器学习的一个子集,也就是说深度学习是实现机器学习的一种方法。与机器学习算法的主要区别如下图所示[参考:黑…...

Java下部笔记
目录 一.双列集合 1.Map 2.Map的遍历方式 3.可变参数 4.Collection中的默认方法 5.不可变集合(map不会) 二.Stream流 1.获取stream流 2.中间方法 3.stream流的收集操作 4.方法引用 1.引用静态方法 2.引用成员方法 3.引用构造方法 4.使用类…...
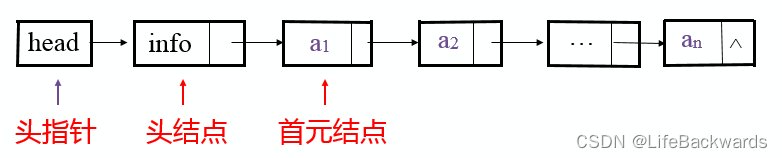
链表基本操作
单链表简介 单链表结构 头指针是指向链表中第一个结点的指针 首元结点是指链表中存储第一个数据元素a1的结点 头结点是在链表的首元结点之前附设的一个结点;数据域内只放空表标志和表长等信息 单链表存储结构定义: typedef struct Lnode { ElemTyp…...

Linux学习笔记-Ubuntu系统下配置用户ssh只能访问git仓库
目录 一、基本信息1.1 系统信息1.2 git版本[^1]1.2.1 服务器端git版本1.2.2 客户端TortoiseGit版本1.2.3 客户端Git for windows版本 二、创建git用户和群组[^2]2.1 使用groupadd创建群组2.2 创建git用户2.2.1 使用useradd创建git用户2.2.2 配置新建的git用户ssh免密访问 2.3 创…...

央媒发稿不能改?媒体发布新闻稿有哪些注意点
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 “央媒发稿不能改”是媒体行业和新闻传播领域的普遍理解。央媒,即中央主要媒体,是权威性的新闻源,当这些媒体发布新闻稿或报道时,其他省、…...
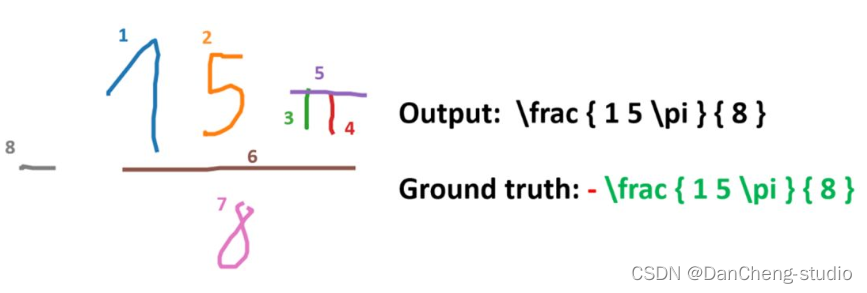
计算机竞赛 深度学习 opencv python 公式识别(图像识别 机器视觉)
文章目录 0 前言1 课题说明2 效果展示3 具体实现4 关键代码实现5 算法综合效果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于深度学习的数学公式识别算法实现 该项目较为新颖,适合作为竞赛课题方向,学…...

KPM算法
概念 KMP(Knuth–Morris–Pratt)算法是一种字符串匹配算法,用于在一个主文本字符串中查找一个模式字符串的出现位置。KMP算法通过利用模式字符串中的重复性,避免无意义的字符比较,从而提高效率。 KMP算法的核心思想是…...
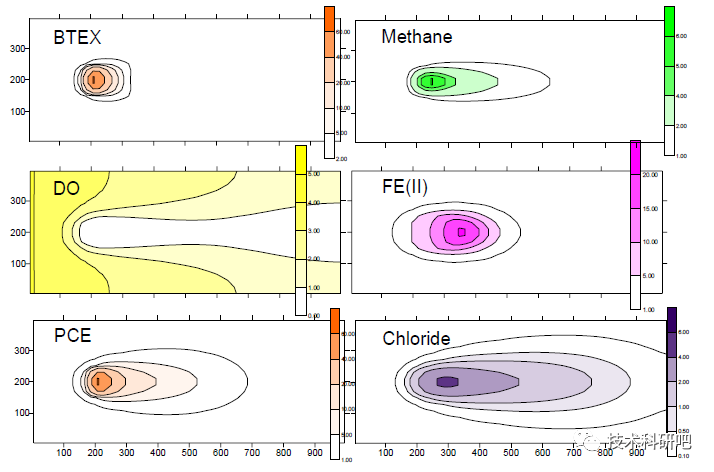
全流程GMS地下水数值模拟及溶质(包含反应性溶质)运移模拟技术教程
详情点击公众号链接:全流程GMS地下水数值模拟及溶质(包含反应性溶质)运移模拟技术教程 前言 GMS三维地质结构建模 GMS地下水流数值模拟 GMS溶质运移数值模拟与反应性溶质运移模 详情 1.GMS的建模数据的收集、数据预处理以及格式等ÿ…...

GE D20 EME 10BASE-T电源模块产品特点
GE D20 EME 10BASE-T 电源模块通常是工业自动化和控制系统中的一个关键组件,用于为系统中的各种设备和模块提供电源。以下是可能包括在 GE D20 EME 10BASE-T 电源模块中的一些产品特点: 电源输出:D20 EME 模块通常提供一个或多个电源输出通道…...
迁移笔记一)
oracle 大表(1亿以上)迁移笔记一
作者:蓝鸟 1974 CSDN:https://blog.csdn.net/weixin_42767242 关键字 大表迁移、存储过程批量归档、定时 JOB、索引维护、统计信息收集、NOLOGGING、BULK COLLECT、FORALL 一、场景概述 在医院 HIS/EMR 系统中,业务流水表、病历明细表数据增长极快,单表数据量轻松突破…...

2026届必备的六大降重复率工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要落实信息输出的精简规范,就得设定维度清晰的降效调整规则,核心规则…...

BilibiliDown:一键下载B站音频的跨平台神器
BilibiliDown:一键下载B站音频的跨平台神器 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili…...

TaotokenAPI密钥管理与访问控制功能的实际使用体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API 密钥管理与访问控制功能的实际使用体验 在团队协作开发中,如何安全、高效地管理大模型 API 的访问权限&a…...

stm32开发者如何快速接入大模型api实现智能对话功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 STM32开发者如何快速接入大模型API实现智能对话功能 为嵌入式设备增加自然语言交互能力,是许多STM32开发者希望实现的功…...
)
别再盲目缩放PGA了!土木工程师必看的地震动调整实战指南(附Python代码)
土木工程师的地震动调整实战指南:从原理到Python实现 地震动调整是结构抗震分析中的关键环节,却常被简化为机械的PGA缩放操作。这种粗放的处理方式可能导致分析结果严重偏离实际地震响应,给工程安全埋下隐患。本文将带您深入理解地震动调整的…...

告别重复操作:M9A如何用智能自动化重塑《重返未来:1999》游戏体验
告别重复操作:M9A如何用智能自动化重塑《重返未来:1999》游戏体验 【免费下载链接】M9A 重返未来:1999 小助手 | Assistant For Reverse: 1999 项目地址: https://gitcode.com/gh_mirrors/m9/M9A 在当今快节奏的生活中,游戏…...

从赛场到职场:一份高职物联网技能大赛任务书的实战拆解与能力映射
1. 竞赛任务书背后的物联网技术全景 高职物联网技能大赛的任务书就像一份浓缩版的行业项目说明书,里面藏着物联网技术的完整技术栈。我第一次看到这份任务书时,发现它完美地覆盖了物联网的三大层级:感知层、传输层和应用层。 感知层设备选型与…...

如何高效配置编程字体:Maple Mono的进阶优化方案
如何高效配置编程字体:Maple Mono的进阶优化方案 【免费下载链接】maple-font Maple Mono: Open source monospace font with round corner, ligatures and Nerd-Font icons for IDE and terminal, fine-grained customization options. 带连字和控制台图标的圆角等…...

观察Taotoken API Key的访问控制与审计日志功能如何保障企业安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken API Key的访问控制与审计日志功能如何保障企业安全 在企业级应用大模型能力的实践中,安全与合规是技术决…...