大数据之Hive(三)
分区表
概念和常用操作
将一个大表的数据按照业务需要分散存储到多个目录,每个目录称为该表的一个分区。一般来说是按照日期来作为分区的标准。在查询时可以通过where子句来选择查询所需要的分区,这样查询效率会提高很多。
①创建分区表
hive (default)>
create table dept_partition
(deptno int, --部门编号dname string, --部门名称loc string --部门位置
)partitioned by (day string, hour string)row format delimited fields terminated by '\t';
查询分区表数据时,可以将分区字段看作表的伪列,可像使用其他字段一样使用分区字段。
| 操作命令 | 作用 |
|---|---|
| desc 表名 | 查看表的信息,分辨是否为分区表 |
| show partition 表名 | 查看所有分区信息 |
| alter 表名 add partition(dt=‘’) | 添加分区,多个分区不用添加分隔符 |
| alter 表名 drop partition(),partiton2 | 删除分区, 多个分区逗号分隔 |
| msck repair table 表名 add/drop/ sync partitions | 没有使用hive load命令上传文件时,用来修复分区,默认是add |
二级分区表
如果一天内的数据量也很大,可以再次将数据按照小时进行分区。适合数据量特别大的时候使用
动态分区表
动态分区是指向分区表insert数据时,被写往的分区不由用户指定,而是由每行数据的最后一个字段的值来动态的决定。使用动态分区,可只用一个insert语句将数据写入多个分区。
- 开启动态分区功能set
hive.exec.dynamic.partition=true; - 设置为动态分区非严格模式set
hive.exec.dynamic.partition.mode=nonstrict - 需要先存在一张大表已经存储好了,然后转换为动态分区表。
- 按照已经存储的表的最后一列作为分区列
insert into table dept_partition_dynamic
partition(loc) -- 动态分区就是指这个值没有写死
select deptno, dname, loc
from dept;
分桶表
分区提供一个隔离数据和优化查询的便利方式。底层是将数据放到不同目录,但是并非所有数据都可形成合理的分区。分桶是指将同一个文件的数据按照分桶数再划分为更细粒度的不同文件。数据内容是按照对应字段的哈希值对桶数取模来分配的。只在特定情况下效率会更高。
分区和分桶结合使用
create table stu_buck_sort_part(id int,name string
)
partitioned by (day string) -- 分区
clustered by (id) sorted by (id)
into 4 buckets -- 分桶
row format delimited fields terminated by '\t';
分区和分桶的区别:
- 分区是分的是目录,分桶分的是文件
- 分区的字段不能是表中字段,分桶的字段必须是表中的字段
自定义函数
用户自定义函数分类
(1)UDF:一进一出
(2)UDAF:多进一出
(3)UDTF:一进多出
自定义步骤
- 模仿length函数
- 导入jar包
- 编写MyUDF类,继承GenericUDF类,重写方法
- initialize(检查器数组),返回值为检查器。检查器类内部封装了所有可以处理的类对象。初始化用来:
- 检查参数个数,不正确时抛UDFArgumentLengthException()
- 检查参数类型, 不正确时抛UDFArgumentTypeException()
- 约定函数的返回值类型, 可以选择java的序列化对象或者hadoop的writable对象。使用工厂类(帮你把各种类的单例已经new好了)来获取返回对应的对象。
- evaluate(函数值对象 o) ,返回值是Object
- 如果为null,返回0或-1
- 不为null, 返回 o.toString().length();
- 使用Maven打包,在target中复制到hadoop中,建议放到data目录下, 复制路径pwd。
- 在hadoop中使用add jar 路径
- 进入jdbc中创建永久函数
create function my_len as "方法的全类名";如果想创建临时方法,在function前面加上temporary。临时函数可以跨库使用,永久函数需要加上前缀库名后才能跨库使用。 - 由于add jar本身也是临时生效的,需要将jar包上传到HDFS中才能真正变成永久函数。然后在创建函数时添加
using "HDFS路径"
Hadoop压缩
存储时选择压缩比的最好的bzip2,计算时选择速度快点压缩算法,目前天选加唯一的就是snappy。
- 打开参数, 这两个参数默认都为false
Hadoop: mapreduce.map.output.compress=true
Hive:hive.exec.compress.output=true - 设置压缩方式
- 使用hadoop103:8088中的yarn来查看压缩算法是否被使用。
- 实际使用过程中并不能提升程序的运行效率,只是减少了IO,但需要额外的配置,只有在特殊场景才会配置。
Hive文件格式
| 文件名 | 特点 |
|---|---|
| textfile | 行式存储 |
| orc | 列式存储, 比较适合列式的查询,符合公司业务需求 |
| Parquet | 列式存储 |
ORC文件结构
- Stripe0:大小等于物理块,128M
- Index索引
- column a
- column b
- column c
- Footer编码信息
- Stripe1:和上面一样
- …
- File Footer:
- stripe的起始位置,索引的长度,数据的长度,Stripe footer的长度
使用orc列式存储时可以将原文件大小缩小到原先的40%,parquet大概是原先的70%。在数据量较大时,orc和parquet进行按列查询时查询速度会比textfile速度更快。
企业优化
计算资源配置
- 调整yarn内存和容器内存
- 调整map和reduce的内存和CPU核心数
Explain查看执行计划
语法:explain query-SQL
分组聚合优化
map-side聚合
将聚合操作从reduce阶段提前到map阶段。
set hive.map.aggr = true. 开启预聚合combiner
可以将该参数关闭,比较两次查询过程的执行时间。该优化对于有数据倾斜的数据有很好的优化效果。
join优化
- common join
- 没有开启自动转map join
- map join
- 文件大小小于25M时被称为小表
- 配置参数开启hive.auto.convert.join
- 配置参数开启无条件转map join,不考虑数据是否是小表,出错时直接OOM内存溢出。
- bucket map join
- 将大表进行分桶,分桶是根据字段来分的,分桶时必须按照
连接键来分。 - 左右两边分桶的个数必须是相等或倍数关系。
- 将大表进行分桶,分桶是根据字段来分的,分桶时必须按照
- sort merge bucket join
- 在分桶的基础上,将桶内数据进行排序后再进行Join操作,将全量IO转换为部分IO。
- 设置参数为true:
- sortedmerge
- sortmerge.join
数据倾斜
reducer倾斜
- map-side聚合:默认是开启的
- Skew-GroupBy优化:将数据打散,不按照原先的逻辑进行分组,随机平均分散到不同的reducer中。适合倾斜量级很大时,否则优化效果不是很明显。
join数据倾斜
- 桶表join
- map join
相关文章:
)
大数据之Hive(三)
分区表 概念和常用操作 将一个大表的数据按照业务需要分散存储到多个目录,每个目录称为该表的一个分区。一般来说是按照日期来作为分区的标准。在查询时可以通过where子句来选择查询所需要的分区,这样查询效率会提高很多。 ①创建分区表 hive (defau…...

让高分辨率的相机芯片输出低分辨率的图片对于像素级的值有什么影响?
很多图像传感器可以输出多个分辨率的图像,如果选择低分辨率格式的图像输出,对于图像本身会有什么影响呢? 传感器本身还是使用全部像素区域进行感光,但是在像素数据输出时会进行所谓的降采样(down-sampling)…...
FastGPT 接入飞书(不用写一行代码)
FastGPT V4 版本已经发布,可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景,例如联网谷歌搜索,操作数据库等等,功能非常强大,还没用过的同学赶紧去试试吧。 飞书相比同类产品算是体验非常好的办…...
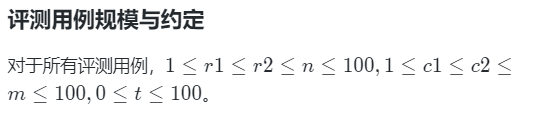
蓝桥杯 题库 简单 每日十题 day6
01 删除字符 题目描述 给定一个单词,请问在单词中删除t个字母后,能得到的字典序最小的单词是什么? 输入描述 输入的第一行包含一个单词,由大写英文字母组成。 第二行包含一个正整数t。 其中,单词长度不超过100&#x…...

使用Arduino简单测试HC-08蓝牙模块
目录 模块简介模块测试接线代码测试现象 总结 模块简介 HC-08 蓝牙串口通信模块是新一代的基于 Bluetooth Specification V4.0 BLE 蓝牙协议的数传模块。无线工作频段为 2.4GHz ISM,调制方式是 GFSK。模块最大发射功率为4dBm,接收灵度-93dBm,…...

如何在 CentOS 8 上安装 OpenCV?
OpenCV( 开源计算机视觉库)是一个开放源代码计算机视觉库,支持所有主要操作系统。它可以利用多核处理的优势,并具有 GPU 加速功能以实现实时操作。 OpenCV 的用途非常广泛,包括医学图像分析,拼接街景图像,监视视频&am…...

一台主机外接两台显示器
一台主机外接两台显示器 写在最前面双屏配置软件双屏跳转 写在最前面 在使用电脑时需要运行多个程序,时不时就要频繁的切换,很麻烦 但就能用双屏显示来解决这个问题,用一台主机控制,同时外接两台显示器并显示不同画面。 参考&a…...

笔记-搭建和使用docker-registry私有镜像仓库
笔记-搭建和使用docker-registry私有镜像仓库 拉取/安装registry镜像 和 对应的ui镜像 如果有网络可以直接拉取镜像 docker pull registry docker pull hyper/docker-registry-web没有网络可以使用我导出好的离线镜像tar包, 下载地址https://wwzt.lanzoul.com/i3im1194z12d …...
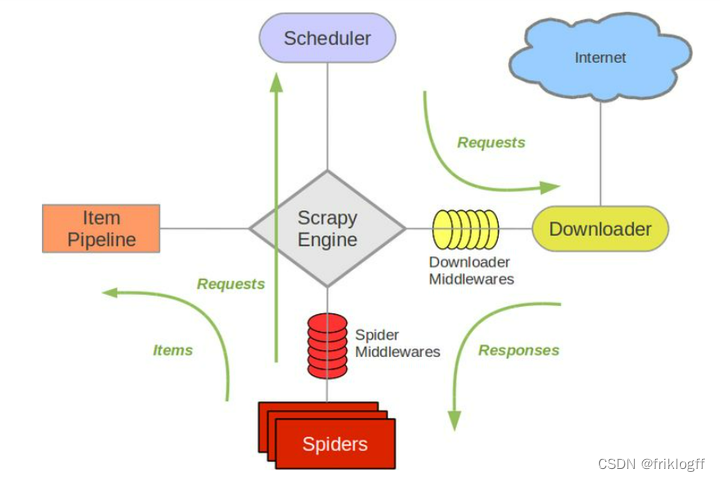
爬虫框架Scrapy学习笔记-2
前言 Scrapy是一个功能强大的Python爬虫框架,它被广泛用于抓取和处理互联网上的数据。本文将介绍Scrapy框架的架构概览、工作流程、安装步骤以及一个示例爬虫的详细说明,旨在帮助初学者了解如何使用Scrapy来构建和运行自己的网络爬虫。 爬虫框架Scrapy学…...
6.1 使用scikit-learn构建模型
6.1 使用scikit-learn构建模型 6.1.1 使用sklearn转换器处理数据6.1.2 将数据集划分为训练集和测试集6.1.3 使用sklearn转换器进行数据预处理与降维1、数据预处理2、PCA降维算法 代码 scikit-learn(简称sklearn)库整合了多种机器学习算法,可以…...
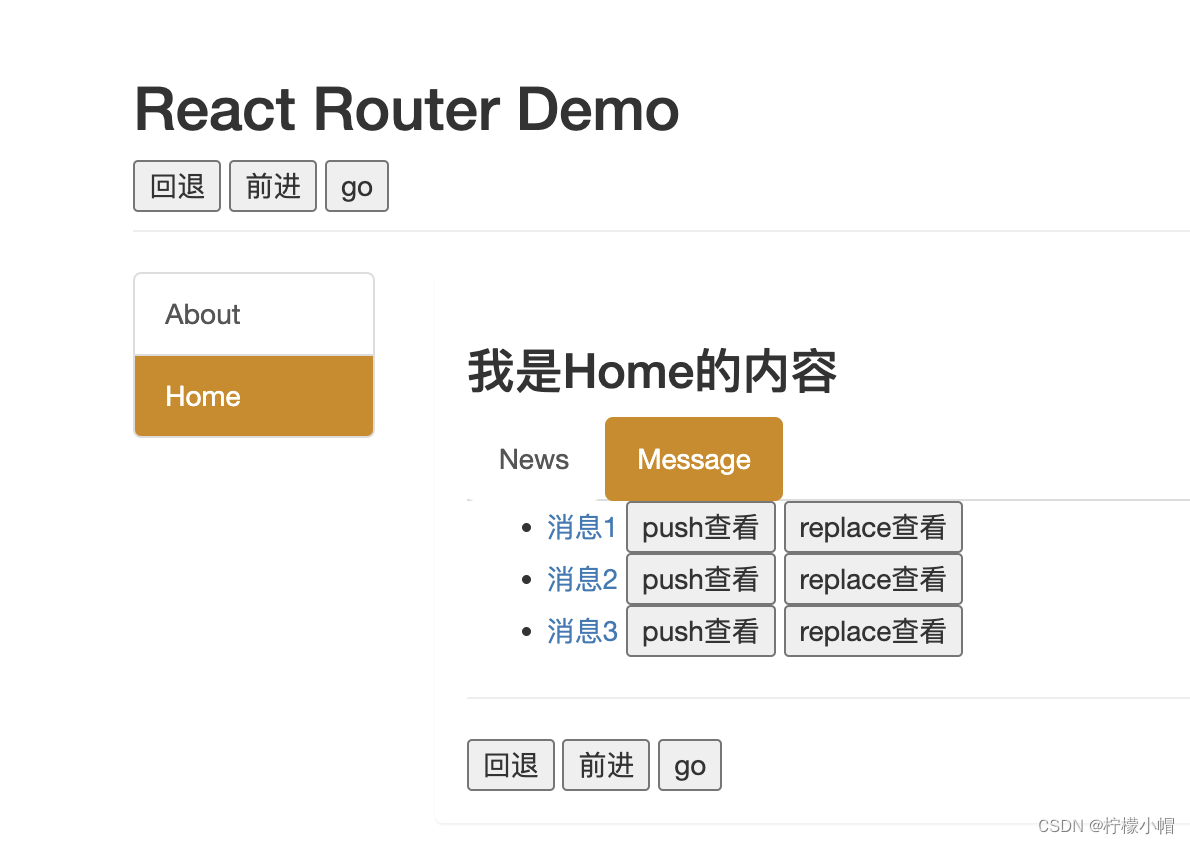
React 全栈体系(十一)
第五章 React 路由 五、向路由组件传递参数数据 1. 效果 2. 代码 - 传递 params 参数 2.1 Message /* src/pages/Home/Message/index.jsx */ import React, { Component } from "react"; import {Link, Route} from react-router-dom import Detail from ./Detai…...
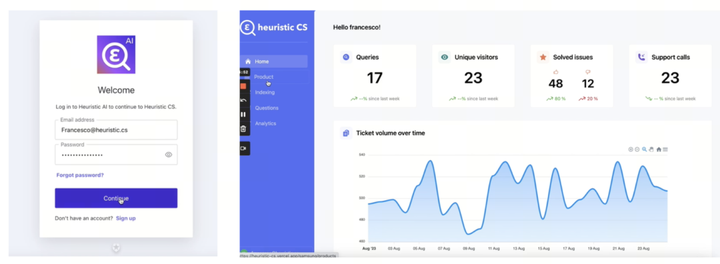
AI 时代的向量数据库、关系型数据库与 Serverless 技术丨TiDB Hackathon 2023 随想
TiDB Hackathon 2023 刚刚结束,我仔细地审阅了所有的项目。 在并未强调项目必须使用人工智能(AI)相关技术的情况下,引人注目的项目几乎一致地都使用了 AI 来构建自己的应用。 大规模语言模型(LLM)的问世使得…...

Vue的路由使用,Node.js下载安装及环境配置教程 (超级详细)
前言: 今天我们来讲解关于Vue的路由使用,Node.js下载安装及环境配置教程 一,Vue的路由使用 首先我们Vue的路由使用,必须要导入官方的依赖的。 BootCDN - Bootstrap 中文网开源项目免费 CDN 加速服务https://www.bootcdn.cn/ <…...

vue修改node_modules打补丁步骤和注意事项
当我们使用 npm 上的第三方依赖包,如果发现 bug 时,怎么办呢? 想想我们在使用第三方依赖包时如果遇到了bug,通常解决的方式都是绕过这个问题,使用其他方式解决,较为麻烦。或者给作者提个issue,然…...

CSS 响应式设计:媒体查询
文章目录 媒体查询添加断点为移动端优先设计其他断点方向:横屏/竖屏 媒体查询 CSS中的媒体查询是一种用于根据不同设备的屏幕尺寸和分辨率来定义样式表的方法。在CSS中,我们可以使用媒体查询来根据不同的设备类型和屏幕尺寸来应用不同的样式,…...
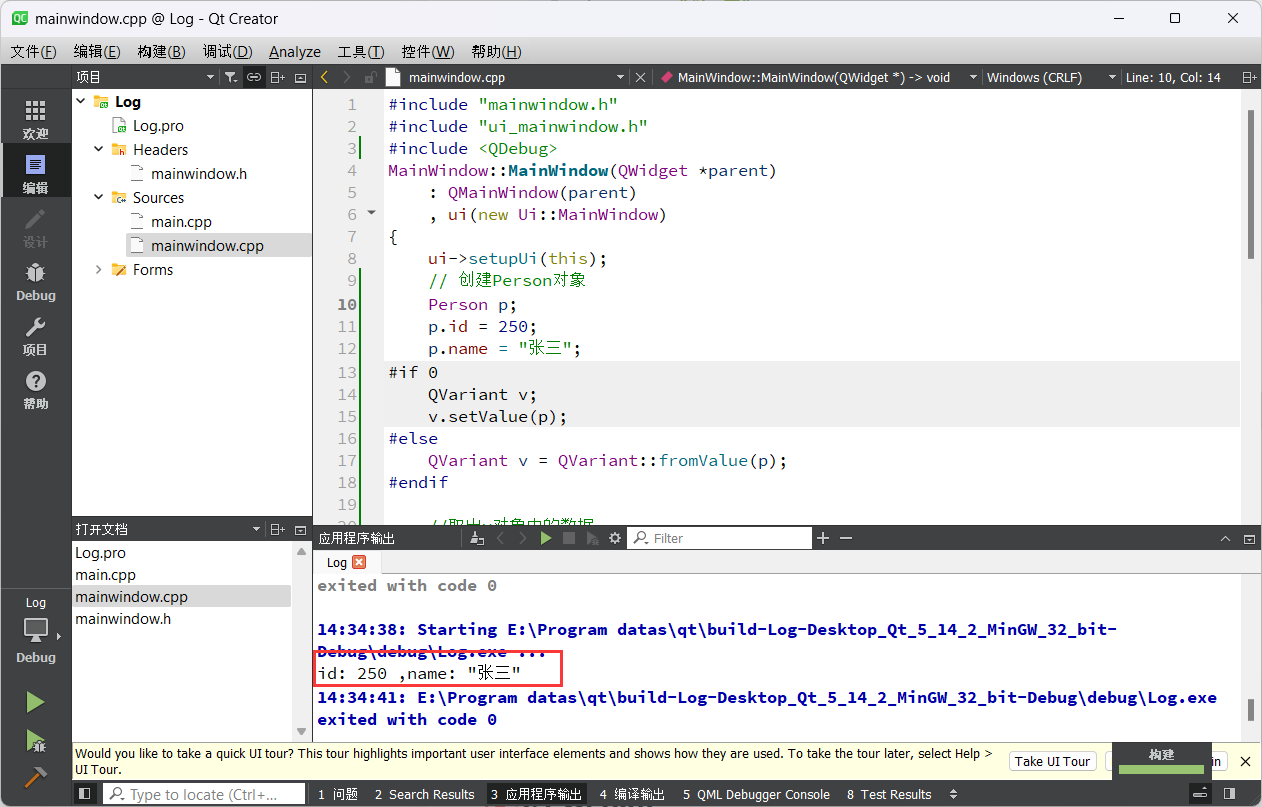
Qt开发 - Qt基础类型
1.基础类型 因为Qt是一个C 框架, 因此C中所有的语法和数据类型在Qt中都是被支持的, 但是Qt中也定义了一些属于自己的数据类型, 下边给大家介绍一下这些基础的数类型。 QT基本数据类型定义在#include <QtGlobal> 中,QT基本数据类型有: 虽然在Qt中…...
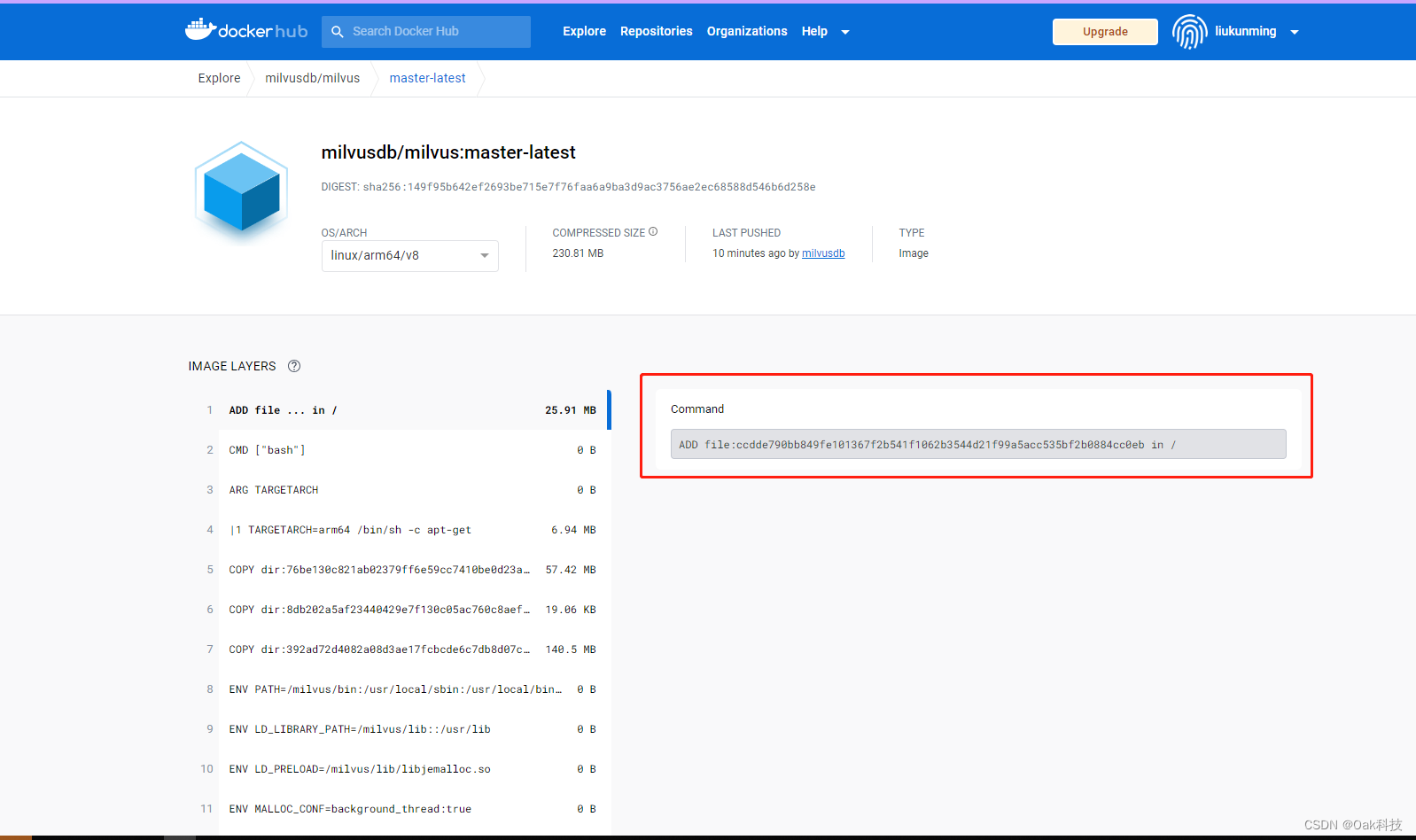
Docker-如何获取docker官网x86、ARM、AMD等不同架构下的镜像资源
文章目录 一、概要二、资源准备三、环境准备1、环境安装2、服务器设置代理3、注册docker账号4、配置docker源 四、查找资源1、服务器设置代理2、配置拉取账号3、查找对应的镜像4、查找不同版本镜像拉取 小结 一、概要 开发过程中经常会使用到一些开源的资源,比如经…...

Vuex状态管理最佳实践
文章目录 单一状态树使用模块使用常量定义Mutation类型使用Actions处理异步操作使用Getters计算属性严格模式分模块管理Getter、Mutation和Action:注释和文档:Vue Devtools ✍创作者:全栈弄潮儿 🏡 个人主页: 全栈弄潮…...

platform和led中断项目
设备树根节点下添加 myledIrqPlatform{compatible"hqyj,myledIrqPlatform";reg<0x22334455 59>;interrupt-parent<&gpiof>;interrupts<9 0>;led1-gpio<&gpioe 10 0>;//10表示使用的gpioe第几个管脚 0,表示gpio默认属性…...
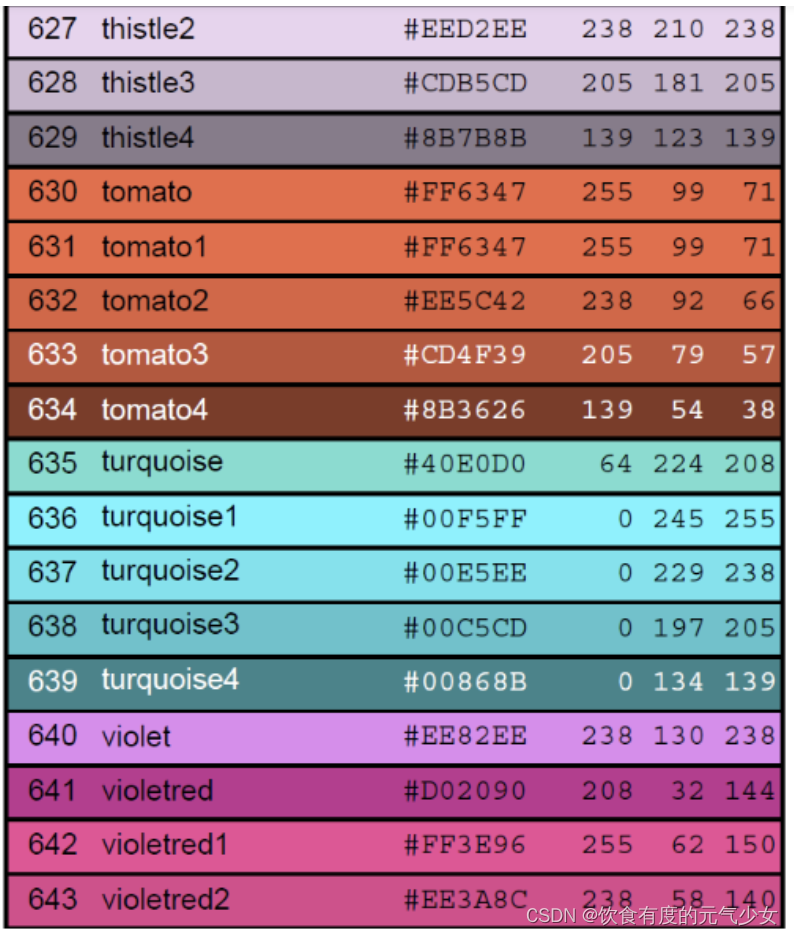
R语言-关于颜色
目录 颜色 示例 R 颜色板 参考: 颜色 什么场景会用到颜色?比如在绘图过程中,为了让图更好看,有的时候,需要选择使用不同的颜色进行绘制或者填充。本文提供了R颜色的相关参数。 在R中,可以通过颜色下标…...

搜搜果:一种面向AI生成内容验真与品牌可见度监测的实现方案
1. 问题定义 随着大语言模型(LLM)广泛集成到搜索、问答、推荐等场景中,出现两个可观测的问题: 内容可信性问题:模型会以高置信度输出事实上不存在的实体、事件或引用(幻觉,hallucination&#…...

用PTA题库学C语言:手把手教你拆解‘选择与循环’的嵌套逻辑
用PTA题库学C语言:手把手教你拆解‘选择与循环’的嵌套逻辑 学习C语言时,最让初学者头疼的莫过于那些层层嵌套的选择结构和循环结构。面对一堆if-else和for/while语句,很多人会感到无从下手。本文将通过PTA题库中的典型题目,教你一…...

SteamAutoCrack:3步自动化破解Steam游戏的终极解决方案
SteamAutoCrack:3步自动化破解Steam游戏的终极解决方案 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack 你是否厌倦了每次想离线玩游戏时都要手动破解的繁琐过程?…...

保姆级教程:小白也能轻松上手 AI 硬件
大家好,我是siuser小伟如果你是一个小白,又想玩一下硬件的话,那我一定推荐你去接触 AI 小智。因为他们的生态非常好,教程非常详细,你也可以跑一个专属于你自己的 AI 硬件。这篇文章专门写给第一次部署小智 Go 后端的人…...

Shinkai Node:无代码AI智能体平台架构解析与实战部署
1. 项目概述:Shinkai Node,一个无需代码的AI智能体构建平台 最近在折腾AI智能体(AI Agent)的时候,发现了一个挺有意思的开源项目—— Shinkai Node 。它来自dcSpark团队,核心目标非常明确: …...
)
别再只盯着原理图了!用Python+OpenCV动手模拟激光三角测距(斜射/直射对比)
用PythonOpenCV模拟激光三角测距:斜射与直射的实战对比 激光三角测距技术听起来高大上,但真正理解它的精髓往往需要跳出公式推导的泥潭。作为一名长期在工业检测领域摸爬滚打的技术人员,我发现用代码模拟物理过程是最有效的学习方式。本文将…...

挖掘MCU硬件加速潜力:以R80515的Double DPTR和MDU为例,在Keil C51中开启性能外挂
挖掘MCU硬件加速潜力:R80515双DPTR与MDU在Keil C51中的实战优化 当你在Keil C51环境下为资源受限的8051架构编写代码时,是否曾为缓慢的数据搬运和复杂的数学运算而头疼?现代增强型8051内核如R80515通过硬件加速单元提供了突破性能瓶颈的可能…...

ArcGIS符号库“隐身”之谜:从DAO组件缺失到完整恢复的实战指南
1. 当符号选择器突然"罢工":一个GISer的崩溃瞬间 那天早上我正赶着完成客户的地图项目,准备给水系图层换个漂亮的蓝色符号。像往常一样双击图层打开属性窗口,点击Symbol Selector准备挑选样式时,整个人瞬间僵住了——本…...

从入门到精通:摄影测量学核心概念与应用全景解析
1. 摄影测量学入门指南:从零开始理解核心概念 第一次接触摄影测量学时,我被那些专业术语搞得晕头转向。直到有一次在公园用手机拍摄了一组树木照片,尝试用免费软件生成3D模型后,才真正理解了这门技术的魅力。摄影测量学本质上就是…...

AC鸭的温度墙
题目描述AC鸭在实验室里看到了一面很长的温度墙,这面墙从左到右一共有 n 个位置。一开始,每个位置的温度都是 0。接下来 AC鸭会进行 m 次加热操作。每次操作给出 l,r,v表示把第l个位置到第r个位置的温度都加上上v。所有操作结束后,AC鸭想知道…...