信息检索与数据挖掘 | (二)布尔检索与倒排索引
文章目录
- 📚词项-文档关联矩阵
- 🐇相关名词
- 🐇词项-文档关联矩阵的布尔查询处理
- 📚倒排索引
- 🐇关于索引
- 🐇建立索引
- 🐇基于倒排索引的布尔查询处理
- 🐇查询优化
- 📚字典数据结构
- 🐇哈希表
- 🐇各种树
- 🐇B树 vs B+树
- 📚短语查询及含位置信息的倒排记录
- 🐇二元词索引(Biword indexes)
- 🐇位置信息索引
- 🐇混合索引机制
- 📚基于跳表的倒排记录表快速合并算法
- 线性扫描是一种最简单的计算机文档检索方式,这个过程通常称为
grepping。在使用现代计算机的条件下,对一个规模不大的文档集进行线性扫描非常简单,根本不需要做额外的处理。- 但在(1)大规模文档集(2)更灵活的匹配方式(3)需要对结果进行排序的情况下,就不能再用上边的线性扫描。一种非线性扫描的方式是事先给文档建立索引(index)。
📚词项-文档关联矩阵
🐇相关名词
- 词项(Term):索引的单位,通常用词来表示。
- 文档(Document):检索系统的检索对象,可以是单独的一条记录或者是一本书的各章。
- 文档集/语料库(collection/corpus):所有文档的集合。
- 词项-文档关联矩阵(Term-document incidence matrices)

- 从行看,可以得到每个词项对应的文档向量,表示词项在哪些文档出现或不出现。
- 从列看,可以得到每个文档对应的词项向量,表示文档中哪些词项出现或不出现。
🐇词项-文档关联矩阵的布尔查询处理
- 对于采用
AND、OR及NOT等逻辑操作符连接起来的布尔表达式查询,通过对文档向量间接逻辑操作来得到查询结果。 - 例:响应查询
Brutus AND Caesar AND NOT Calpurnia:结果向量中的第1和第4个元素为1,这表明该查询对应的剧本是Antony and Cleo patra和Hamlet。
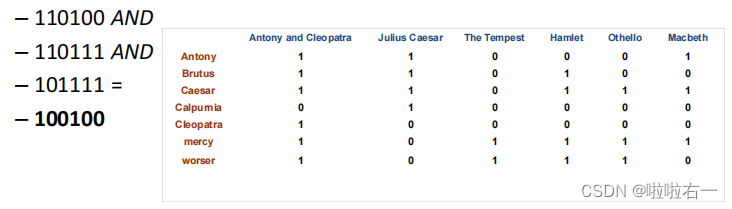
- 假设有50万个词项和100万篇文档,所以其对应的词项-文档矩阵大概有5000亿个取布尔值的元素,这远远大于一台计算机内存的容量。此外,这个庞大的矩阵实际上具有高度的稀疏性,即大部分元素都是0,而只有极少部分元素为1。

- 也就是说对于词项个数和文档规模很大的情况,构造出的关联矩阵是高度稀疏的。这时,只
记录原始矩阵中1的位置的表示方法比词项-文档关联矩阵更好。因此,引出了倒排索引。
📚倒排索引
🐇关于索引
- 索引(Index)由词项词典(Dictionary)和一个全体倒排记录表(Postings)组成。图 1-3 中的词典按照字母顺序进行排序,而倒排记录表则按照文档ID号进行排序。

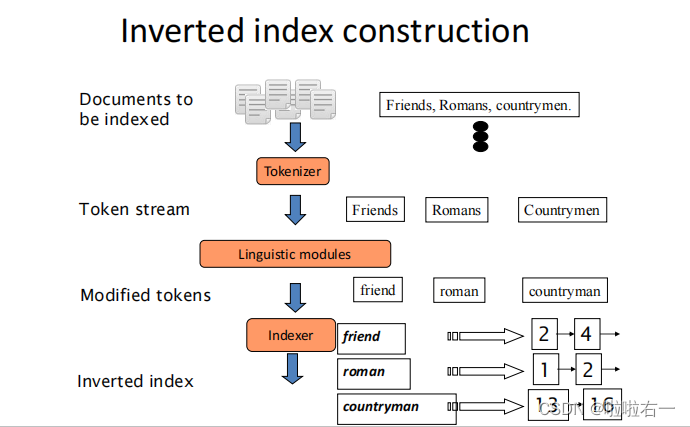
🐇建立索引

-
预处理:
词语切分、词项归一化、词干还原与词形合并、去除停用词

-
构建倒排索引
-
给每篇文章的所有词项加上文档ID。
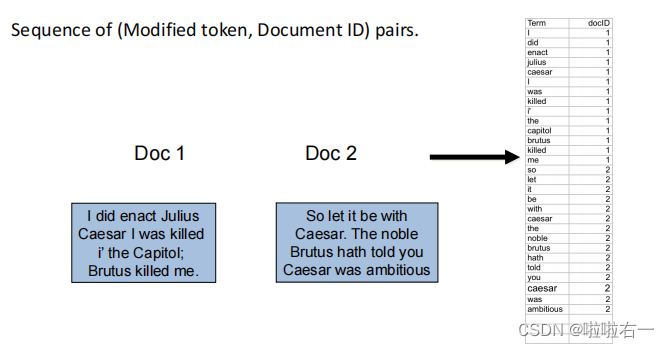
-
按照字母顺序排序。

-
将同一词项合并,并将词项和文档ID分开存储。
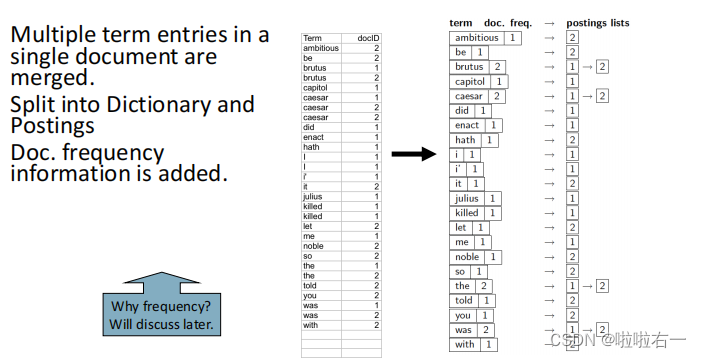
-
-
在字典的每个词项中还可以存储其他信息,如文档频率。
-
每个倒排记录表存储了词项出现的文档列表,还可以存储词项频率、词项在文档中出现的位置。
🐇基于倒排索引的布尔查询处理

求两个倒排记录表交集的合并算法:
- 我们对每个有序列表都维护一个位置指针,并让两个指针同时在两个列表中后移。
- 该算法对于倒排记录表集(即待合并的两个倒排记录表)的大小而言是线性的。每一步我们都比较两个位置指针所指向的文档 ID,如果两者一样,则将该 ID 输出到结果表中,然后同时将两个指针后移一位。
- 如果两个文档 ID不同,则将较小的 ID 所对应的指针后移。
- 假设两个倒排记录表的大小分别是 x 和 y,那么上述求交集的过程需要 O ( x + y ) O(x+y) O(x+y)次操作,也即查询的时间复杂度为 Θ ( N ) Θ(N) Θ(N),其中 N 是文档集合中文档的数目。

- 和线性扫描相比,这种索引方法并没有带来Θ意义上时间复杂度的提高,而最多只是一个常数级别的变化。
- 但是,实际当中这个常数很大。
🐇查询优化
- 对每个词项,我们必须取出其对应的倒排记录表,然后将它们合并。
- 一个启发式的想法是,按照词项的文档频率(也就是倒排记录表的长度)从小到大依次进行处理,如果我们先合并两个最短的倒排记录表,那么所有中间结果的大小都不会超过最短的倒排记录表(这是因为多个集合的交集元素个数肯定不大于其中任何一个集合的元素个数) ,这样处理所需要的工作量很可能最少。
- 布尔查询适合精确查询。
📚字典数据结构
Two main choices——Hashtables、Trees
🐇哈希表
数据结构 | 第十章:散列表 | 字典 | 线性探查 | 链式散列 | LZW编码

🐇各种树
数据结构可视化网站

数据结构 | 第十一章:二叉树和其他树 | 【前序遍历】【中序遍历】【后序遍历】【层次遍历】 | 并查集
数据结构 | 第十二章:优先级队列 | 堆 | 左高树 | 堆排序 | 霍夫曼编码
数据结构 | 第十四章:搜索树 | 二叉搜索树的查找、插入、删除
数据结构 | 第十五章:平衡搜索树——AVL树 | AVL树的搜索、插入、删除
数据结构 | 第十五章:平衡搜索树——B-树 | B-树的搜索、插入、删除
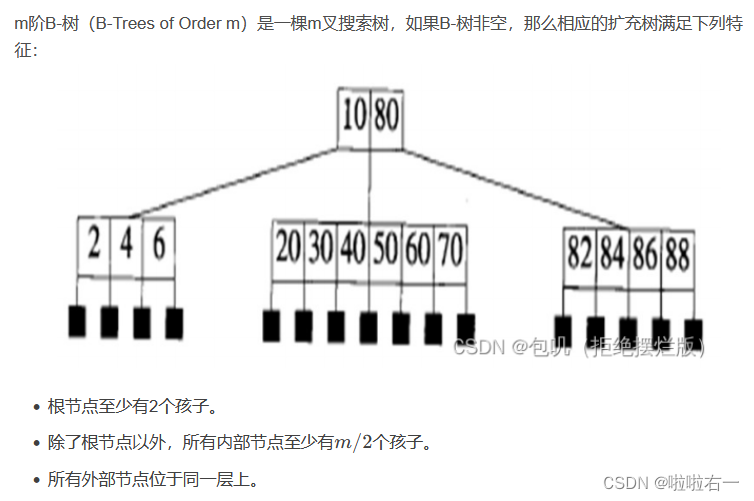
🐇B树 vs B+树
-
B树

-
B+树
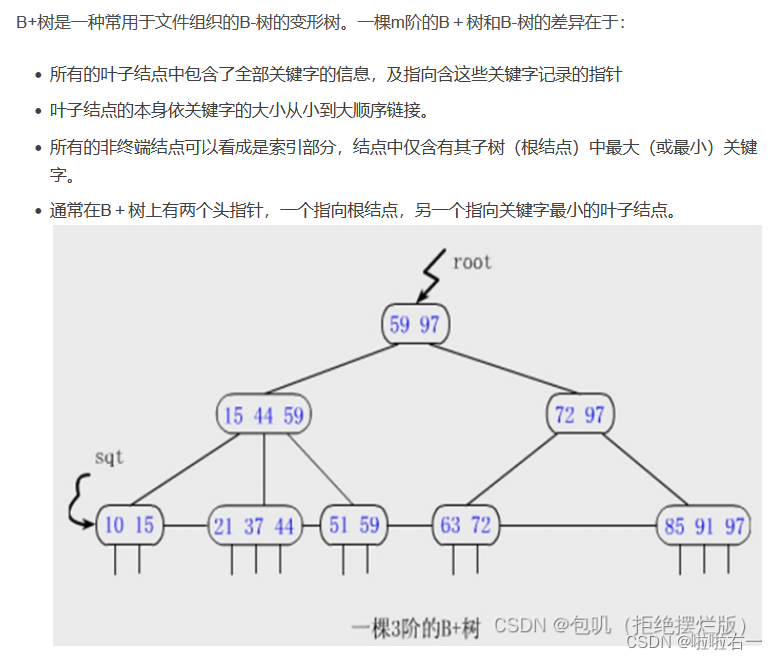

- B+树和B树相比的主要区别:
- B+树所有关键码都在叶子节点
- B+树的叶子节点是带有指针的,且叶节点本身按关键码从小到大顺序连接
- 在搜索过程中,如果查询和内部节点的关键字一致,那么搜索过程不停止,而是继续向下搜索这个分支。因此,在B+树中,不管查找成功与否,每次查找都是走了一条从根到叶子结点的路径。
- B+树在文件系统、数据库系统当中,更有优势,更高效。
- B+树更有利于对数据库的扫描 ,因为所有元素都在叶子节点上。
- B+树的查询效率更加稳定 ,B树最后就是要找到叶子节点,每次查找都是走了一条从根到叶子结点的路径。
- B+树没有像B树一样,把一些关键码每层都放一部分,之间存在互相之间的关系。在考虑指针指向内容上,B+树没有这些要存,反而数据量大的情况的,占的空间要比B树小。
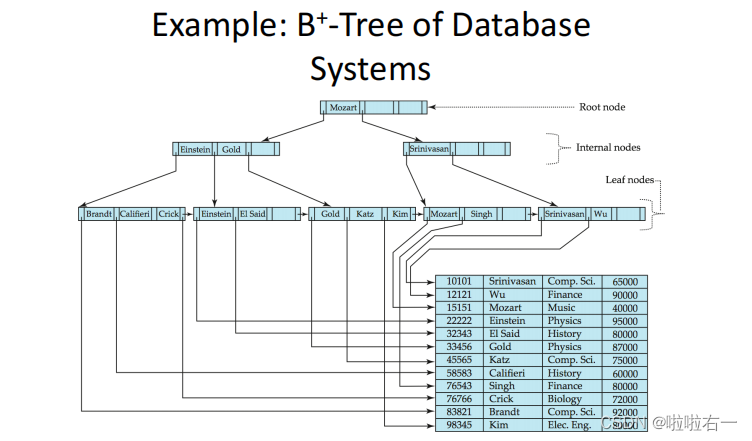
📚短语查询及含位置信息的倒排记录
🐇二元词索引(Biword indexes)
- 对文档中每个接续词对(Biword)看成词项,这样马上就能处理两个词构成的短语查询。
- 更长的查询可以分成多个短查询来处理。
- 比如,按照上面的方法可以将查询
stanford university palo alto分成如下的布尔查询:“stanford university” AND “university palo” AND “palo alto”。 - 可以期望该查询在实际中效果会不错,但是偶尔也会有错误的返回例子。对于该布尔查询返回的文档,我们并不知道其是否真正包含最原始的四词短语。

🐇位置信息索引
- 在位置信息索引(positional index)中,对于每个词项,以如下方式存储倒排记录:


- 短语查询处理


- 同样,类似的方法可以用于 k 词近邻搜索当中:
employment /3 place,这里,/k意味着“ 从左边或右边相距在 k 个词之内” 。很显然,位置索引能够用于邻近搜索,而二元词索引则不能。

🐇混合索引机制
- 二元词索引和位置索引这两种策略可以进行有效的合并。
- 假如用户通常只查询特定的短语,如Michael Jackson,那么基于位置索引的倒排记录表合并方式效率很低。
- 一个混合策略是:对某些查询使用短语索引或只使用二元词索引,而对其他短语查询则采用位置索引。
- 短语索引所收录的那些较好的查询可以根据用户最近的访问行为日志统计得到,也就是说,它们往往是那些高频常见的查询。
📚基于跳表的倒排记录表快速合并算法
- 跳表(skip list):在构建索引的同时在倒排记录表上建立跳表。跳表指针能够提供捷径来跳过那些不可能出现在检索结果中的记录项。

- 在什么位置上放置跳表指针?
- 跳表指针越多意味着跳跃的步长越短,那么在合并过程中跳跃的可能性也更大,但同时这也意味着需要更多的指针比较次数和更多的存储空间。跳表指针越少意味着更少的指针比较次数,但同时也意味着更长的跳跃步长,也就是说意味着更少的跳跃机会。
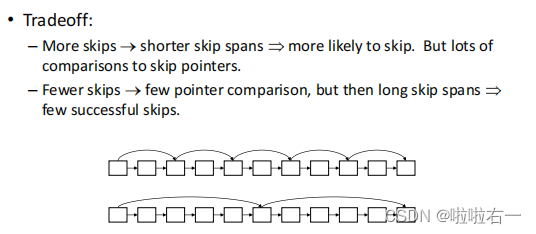
- 放置跳表指针位置的一个简单的启发式策略:在每个 P \sqrt{P} P 处均匀放置跳表指针,其中 P P P 是倒排记录表的长度。
- 这个策略在实际中效果不错,但是仍然有提高的余地,因为它并没有考虑查询词项的任何分布细节。
- 如果索引相对固定的话,建立有效的跳表指针则比较容易。但是如果倒排记录表由于经常更新而发生变化,那么跳表指针的建立就比较困难。恶意的删除策略可能会使跳表完全失效。
- 跳表指针越多意味着跳跃的步长越短,那么在合并过程中跳跃的可能性也更大,但同时这也意味着需要更多的指针比较次数和更多的存储空间。跳表指针越少意味着更少的指针比较次数,但同时也意味着更长的跳跃步长,也就是说意味着更少的跳跃机会。
参考博客:
- B树和B+树的区别
相关文章:
信息检索与数据挖掘 | (二)布尔检索与倒排索引
文章目录 📚词项-文档关联矩阵🐇相关名词🐇词项-文档关联矩阵的布尔查询处理 📚倒排索引🐇关于索引🐇建立索引🐇基于倒排索引的布尔查询处理🐇查询优化 📚字典数据结构&a…...

【学习笔记】EC-Final 2022 K. Magic
最近的题都只会抄题解😅 首先,操作顺序会影响答案,因此不能直接贪心。其次,因为是求贡献最大,所以可以考虑枚举最终哪些位置对答案产生了贡献,进而转化为全局贡献。 1.1 1.1 1.1 如果 [ l 1 , r 1 ) ⊆ [ …...
MySQL数据库笔记
文章目录 一、初识MySQL1.1、什么是数据库1.2、数据库分类1.3、MySQL简介 二、操作数据库2.1、操作数据库(了解)2.2、数据库的列类型2.3、数据库的字段属性(重点)2.4、创建数据库表(重点)2.5、数据表的类型…...
)
大数据之Hive(三)
分区表 概念和常用操作 将一个大表的数据按照业务需要分散存储到多个目录,每个目录称为该表的一个分区。一般来说是按照日期来作为分区的标准。在查询时可以通过where子句来选择查询所需要的分区,这样查询效率会提高很多。 ①创建分区表 hive (defau…...

让高分辨率的相机芯片输出低分辨率的图片对于像素级的值有什么影响?
很多图像传感器可以输出多个分辨率的图像,如果选择低分辨率格式的图像输出,对于图像本身会有什么影响呢? 传感器本身还是使用全部像素区域进行感光,但是在像素数据输出时会进行所谓的降采样(down-sampling)…...
FastGPT 接入飞书(不用写一行代码)
FastGPT V4 版本已经发布,可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景,例如联网谷歌搜索,操作数据库等等,功能非常强大,还没用过的同学赶紧去试试吧。 飞书相比同类产品算是体验非常好的办…...
蓝桥杯 题库 简单 每日十题 day6
01 删除字符 题目描述 给定一个单词,请问在单词中删除t个字母后,能得到的字典序最小的单词是什么? 输入描述 输入的第一行包含一个单词,由大写英文字母组成。 第二行包含一个正整数t。 其中,单词长度不超过100&#x…...

使用Arduino简单测试HC-08蓝牙模块
目录 模块简介模块测试接线代码测试现象 总结 模块简介 HC-08 蓝牙串口通信模块是新一代的基于 Bluetooth Specification V4.0 BLE 蓝牙协议的数传模块。无线工作频段为 2.4GHz ISM,调制方式是 GFSK。模块最大发射功率为4dBm,接收灵度-93dBm,…...

如何在 CentOS 8 上安装 OpenCV?
OpenCV( 开源计算机视觉库)是一个开放源代码计算机视觉库,支持所有主要操作系统。它可以利用多核处理的优势,并具有 GPU 加速功能以实现实时操作。 OpenCV 的用途非常广泛,包括医学图像分析,拼接街景图像,监视视频&am…...

一台主机外接两台显示器
一台主机外接两台显示器 写在最前面双屏配置软件双屏跳转 写在最前面 在使用电脑时需要运行多个程序,时不时就要频繁的切换,很麻烦 但就能用双屏显示来解决这个问题,用一台主机控制,同时外接两台显示器并显示不同画面。 参考&a…...

笔记-搭建和使用docker-registry私有镜像仓库
笔记-搭建和使用docker-registry私有镜像仓库 拉取/安装registry镜像 和 对应的ui镜像 如果有网络可以直接拉取镜像 docker pull registry docker pull hyper/docker-registry-web没有网络可以使用我导出好的离线镜像tar包, 下载地址https://wwzt.lanzoul.com/i3im1194z12d …...
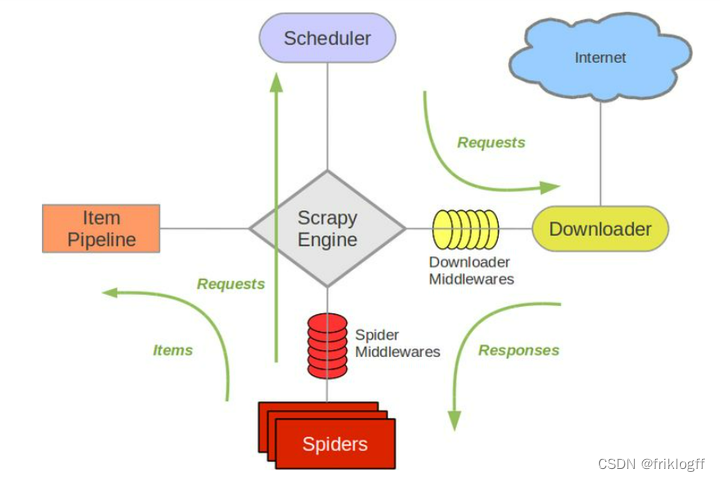
爬虫框架Scrapy学习笔记-2
前言 Scrapy是一个功能强大的Python爬虫框架,它被广泛用于抓取和处理互联网上的数据。本文将介绍Scrapy框架的架构概览、工作流程、安装步骤以及一个示例爬虫的详细说明,旨在帮助初学者了解如何使用Scrapy来构建和运行自己的网络爬虫。 爬虫框架Scrapy学…...
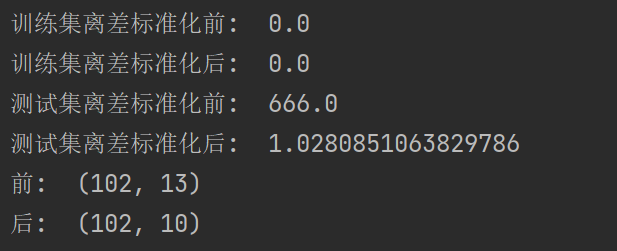
6.1 使用scikit-learn构建模型
6.1 使用scikit-learn构建模型 6.1.1 使用sklearn转换器处理数据6.1.2 将数据集划分为训练集和测试集6.1.3 使用sklearn转换器进行数据预处理与降维1、数据预处理2、PCA降维算法 代码 scikit-learn(简称sklearn)库整合了多种机器学习算法,可以…...
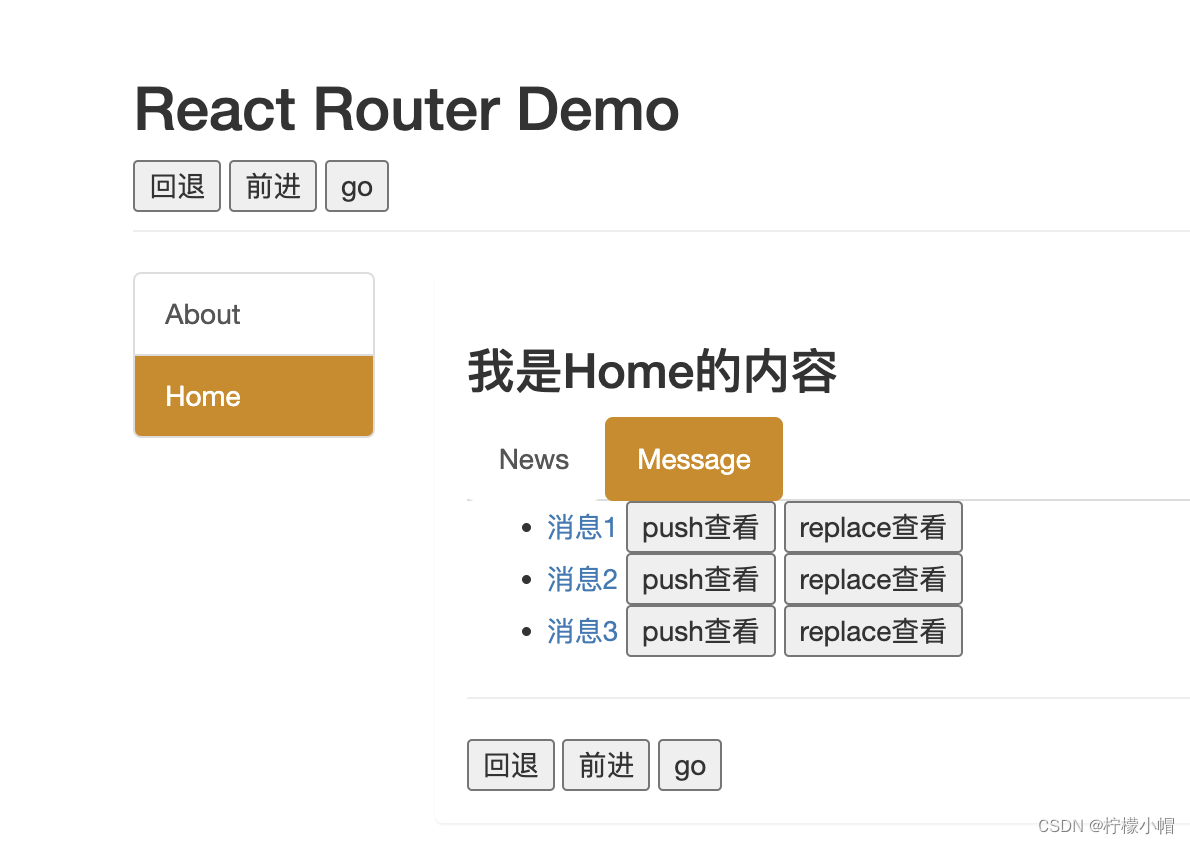
React 全栈体系(十一)
第五章 React 路由 五、向路由组件传递参数数据 1. 效果 2. 代码 - 传递 params 参数 2.1 Message /* src/pages/Home/Message/index.jsx */ import React, { Component } from "react"; import {Link, Route} from react-router-dom import Detail from ./Detai…...
AI 时代的向量数据库、关系型数据库与 Serverless 技术丨TiDB Hackathon 2023 随想
TiDB Hackathon 2023 刚刚结束,我仔细地审阅了所有的项目。 在并未强调项目必须使用人工智能(AI)相关技术的情况下,引人注目的项目几乎一致地都使用了 AI 来构建自己的应用。 大规模语言模型(LLM)的问世使得…...

Vue的路由使用,Node.js下载安装及环境配置教程 (超级详细)
前言: 今天我们来讲解关于Vue的路由使用,Node.js下载安装及环境配置教程 一,Vue的路由使用 首先我们Vue的路由使用,必须要导入官方的依赖的。 BootCDN - Bootstrap 中文网开源项目免费 CDN 加速服务https://www.bootcdn.cn/ <…...

vue修改node_modules打补丁步骤和注意事项
当我们使用 npm 上的第三方依赖包,如果发现 bug 时,怎么办呢? 想想我们在使用第三方依赖包时如果遇到了bug,通常解决的方式都是绕过这个问题,使用其他方式解决,较为麻烦。或者给作者提个issue,然…...

CSS 响应式设计:媒体查询
文章目录 媒体查询添加断点为移动端优先设计其他断点方向:横屏/竖屏 媒体查询 CSS中的媒体查询是一种用于根据不同设备的屏幕尺寸和分辨率来定义样式表的方法。在CSS中,我们可以使用媒体查询来根据不同的设备类型和屏幕尺寸来应用不同的样式,…...
Qt开发 - Qt基础类型
1.基础类型 因为Qt是一个C 框架, 因此C中所有的语法和数据类型在Qt中都是被支持的, 但是Qt中也定义了一些属于自己的数据类型, 下边给大家介绍一下这些基础的数类型。 QT基本数据类型定义在#include <QtGlobal> 中,QT基本数据类型有: 虽然在Qt中…...
Docker-如何获取docker官网x86、ARM、AMD等不同架构下的镜像资源
文章目录 一、概要二、资源准备三、环境准备1、环境安装2、服务器设置代理3、注册docker账号4、配置docker源 四、查找资源1、服务器设置代理2、配置拉取账号3、查找对应的镜像4、查找不同版本镜像拉取 小结 一、概要 开发过程中经常会使用到一些开源的资源,比如经…...

【Sora 2 × Gaussian Splatting融合实战指南】:20年CV专家亲授3大跨模态生成瓶颈突破法
更多请点击: https://intelliparadigm.com 第一章:Sora 2 Gaussian Splatting融合的技术演进与范式跃迁 Sora 2 与 Gaussian Splatting 的深度耦合,标志着生成式视频建模从隐式神经表征迈向显式可微几何渲染的关键转折。二者并非简单串联&a…...

从原理到实践:液压与气压传动核心概念与应用场景解析
1. 液压与气压传动的核心原理 液压与气压传动是现代工业中广泛应用的动力传输方式,它们虽然介质不同,但都遵循着相似的物理原理。液压系统使用不可压缩的液体(通常是液压油)作为工作介质,而气压系统则使用可压缩的空气…...

知网AI率80%降到15%教程,比话降AI知网算法专精+售后保障!
知网AI率80%降到15%教程,比话降AI知网算法专精售后保障! 如果你是硕博毕业生、学校送知网检测、答辩前查出 AI 率 80%——这篇文章直接给你完整操作教程。从「拿到 80% 报告」到「学校送审通过」的完整路径,每一步该做什么、花多少时间、花多…...

Notero:终极Zotero与Notion同步插件,简单快速实现文献管理一体化
Notero:终极Zotero与Notion同步插件,简单快速实现文献管理一体化 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 你是否正在为文献管理与笔记整理之间的…...

电子设备散热风扇控制技术详解与应用
1. 电子设备散热风扇控制技术概述现代电子设备正朝着小型化、高性能方向发展,随之而来的散热问题日益突出。以笔记本电脑为例,其厚度从十年前的30mm缩减到如今的15mm以下,但CPU功耗却从15W提升到45W甚至更高。这种"体积缩小、功耗增加&q…...

从‘能用’到‘好用’:给你的Vue+Element后台管理系统布局加点儿‘细节’
从‘能用’到‘好用’:VueElement后台管理系统的细节打磨指南 后台管理系统作为企业级应用的核心枢纽,其用户体验直接影响着运营效率和操作愉悦度。许多开发者在完成基础功能搭建后,常常陷入"能用但不好用"的困境——系统虽然跑得通…...

从仿真波形到板卡调试:一次搞定Xilinx UltraScale+ FPGA DDR4读写测试全流程
从仿真波形到板卡调试:Xilinx UltraScale FPGA DDR4读写测试全流程实战指南 在FPGA系统设计中,DDR4内存接口的稳定性和性能往往是决定整个系统成败的关键因素。对于使用Xilinx UltraScale系列FPGA的工程师而言,从仿真验证到板卡调试的全流程掌…...

边缘计算中的AI优先设计:从芯片选型到模型部署的实战指南
1. 项目概述:为什么“AI优先”是边缘计算的必然选择 最近和几个做硬件和嵌入式开发的老朋友聊天,话题总绕不开一个词:AIoT。大家的感觉很一致,现在的项目要是没沾点“智能”的边,好像都不好意思拿出手。但真做起来&…...

联想电脑开机蓝屏 + 自动修复卡死?官方 4 步救机指南,亲测有效
很多联想笔记本 / 台式机用户都遇到过这种崩溃场景:按下开机键后,屏幕先是亮起 Logo,紧接着弹出自动修复,转几圈就直接蓝屏报错,反复重启也进不去桌面,工作文件、学习资料全卡在里面,越急越慌。…...

Pandas数据合并:concat vs append,选哪个?用真实‘幸福指数’数据集测给你看
Pandas数据合并实战:concat与append深度性能对比 在数据分析工作中,数据合并是最基础也最频繁的操作之一。Pandas提供了多种合并数据的方法,其中concat和append是最常用的两种纵向合并方式。但很多开发者并不清楚它们在实际项目中的性能差异和…...