指针进阶(3)
9. 模拟实现排序函数
这里我们使用冒泡排序算法,模拟实现一个排序函数,可以排序任意类型的数据。
这段代码可以排序整型数据,我们需要在这段代码的基础上进行改进,使得它可以排序任意类型的数据。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
void bubble_sort(int arr[], int sz)
{//冒泡排序趟数int i = 0;for (i = 0; i < sz - 1; i++){int j = 0;for ( j = 0; j < sz - 1 - i; j++){if (arr[j] < arr[j + 1]){int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}
}
void print(int arr[], int sz)
{int i = 0;for (i = 0; i < sz; i++){printf("%d ", arr[i]);}printf("\n");
}
void test1()
{int arr[] = { 1,2,3,4,5,6,7,8,9,10 };//升序int sz = sizeof(arr) / sizeof(arr[0]);print(arr, sz);//排序前打印bubble_sort(arr,sz);//排序成降序print(arr, sz);//排序后打印}
int main()
{test1();//排序整型数据
}那么我们要做的就是将bubble_arr里的int arr[]改为指针的形式,并且是void*类型,这样就可以接收任意类型的数据,再将int sz改为size_t类型,仅仅有元素个数还不够,我们还需要知道一个元素的大小,这样可以方便我们访问,所以我们加一个size_t size,最后我们再加一个比较函数int (*cmp)(const void* e1,const void* e2),这是一个函数指针,所以我们需要根据自己的需求写一个比较函数。
e1是一个指针,存放了一个要比较的元素的地址
e2是一个指针,存放了一个要比较的元素的地址
e1指向的元素>e2指向的元素,返回>0的数字
e1指向的元素==e2指向的元素,返回0
e1指向的元素<e2指向的元素,返回<0的数字
1.如果我们要比较整型数据,我们就写一个cmp_int,将const void*强转成(int*)再解引用,然后两个元素进行相减,结果作为这个函数的返回值。由于base的类型是void*,所以不能进行+1,-1,所以我们再将base的类型强转成char*,然后加上j*size,就可以进行每个元素的访问了。我们在进行排序的时候需要将元素交换,所以写一个交换函数swap,将元素的地址和大小传过去就行了。
2.如果我们要比较结构体数据的首字母,我们写一个cmp_stu_by_name作为比较函数,字符串的比较我们用strcmp,返回值是>0,<0或者0。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
void swap(char* buf1, char* buf2, size_t size)
{int i = 0;for (i = 0; i < size; i++){char tmp = *buf1;*buf1 = *buf2;*buf2 = tmp;buf1++;buf2++;}
}
void bubble_sort(void* base, size_t num, size_t size, int (*cmp)(const void* e1, const void*e2))
{//冒泡排序的趟数int i = 0;for (i = 0; i < num - 1; i++){//一趟冒泡排序int j = 0;for (j = 0; j < num - 1 - i; j++){//if (arr[j] > arr[j + 1])if(cmp((char*)base + j * size, (char*)base + (j + 1) * size)>0){//交换swap((char*)base + j * size, (char*)base + (j + 1) * size, size);}}}
}
int cmp_int(const void*e1, const void*e2)
{return *(int*)e1 - *(int*)e2;
}
void test1()
{int arr[] = { 0,1,2,3,4,5,6,7,8,9 };//升序//排序为降序int sz = sizeof(arr) / sizeof(arr[0]);print_arr(arr, sz);bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);print_arr(arr, sz);
}
struct Stu
{char name[20];//20int age;//4
};
int cmp_stu_by_age(const void* e1, const void*e2)
{return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
int cmp_stu_by_name(const void* e1, const void* e2)
{return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
void test2()
{struct Stu arr[] = { {"zhangsan", 20}, {"lisi", 30}, {"wangwu", 15}};int sz = sizeof(arr) / sizeof(arr[0]);//3bubble_sort(arr, sz, sizeof(arr[0]), cmp_stu_by_name);
}
int main()
{//整型数据/字符数据/结构体数据...//可以使用qsort函数对数据进行排序//测试bubble_sort,排序整型数据test1();//测试bubble_sort,排序结构体的数据//test2();return 0;
}10. 指针和数组笔试题解析
一维数组:
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a));数组名的理解:
数组名是数组首元素的地址
但是有2个例外:
1. sizeof(数组名),这里的数组名表示整个数组,sizeof(数组名)计算的是整个数组的大小,单位是字节
2. &数组名,这里的数组名表示整个数组,&数组名取出的是数组的地址
所以答案是4*4=16。
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a+0));a并非单独放在sizeof内部,也没有&,所以数组名a是数组首元素的地址,a+0还是首元素的地址。
只要是地址,大小就是4/8,单位是byte。
int a[] = {1,2,3,4};
printf("%d\n",sizeof(*a));a并非单独放在sizeof内部,也没有&,所以数组名a是数组首元素的地址.*a == *(a+0) == a[0]。
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a+1));a并非单独放在sizeof内部,也没有&,所以数组名a是数组首元素的地址,a+1就是第二个元素的地址。a+1 == &a[1] 是第2个元素的地址,是地址就是4/8个字节。
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a[1]));a[1]就是数组的第二个元素,这里计算的就是第二个元素的大小,单位是字节 - 4
int a[] = {1,2,3,4};
printf("%d\n", sizeof(&a));&a - 是取出数组的地址,但是数组的地址也是地址,是地址就是4/8个Byte。
数组的地址 和 数组首元素的地址 的本质区别是类型的区别,并非大小的区别
a -- int* int * p = a;
&a -- int (*)[4] int (*p)[4] = &a;
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(*&a));
对数组指针解引用访问一个数组的大小,单位是字节。
sizeof(*&a) --- sizeof(a) //16
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(&a + 1));&a数组的地址,&a+1还是地址,是地址就是4/8个字节。
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(&a[0]));
&a[0]是首元素的地址, 计算的是地址的大小 4/8 个字节。
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(&a[0] + 1));/&a[0]是首元素的地址,&a[0]+1就是第二个元素的地址,大小4/8个字节。
字符数组
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr));
随机值,arr是首元素的地址.
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr + 0));随机值,arr是首元素的地址, arr+0还是首元素的地址。
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(*arr));err(发生错误),arr是首元素的地址, *arr就是首元素 - 'a' - 97。
站在strlen的角度,认为传参进去的'a'-97就是地址,97作为地址,直接进行访问,就是非法访问。
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr[1]));err, 'b' - 98。
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(&arr));随机值
&arr -- char (*)[6]
const char*。
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(&arr + 1));随机值。
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(&arr[0] + 1));随机值。
char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(arr));6,数组名arr单独放在sizeof内部,计算的是整个数组的大小,单位是字节。
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", sizeof(arr + 0));arr是首元素的地址==&arr[0],是地址就是4/8个字节。
char*
指针变量的大小和类型无关,不管什么类型的指针变量,大小都是4/8个字节。
指针变量是用来存放地址的,地址存放需要多大空间,指针变量的大小就是几个字节。
32位环境下,地址是32个二进制位,需要4个字节,所以指针变量的大小就是4个字节。
64位环境下,地址是64个二进制位,需要8个字节,所以指针变量的大小就是8个字节。
不要在门缝里看指针,把指针给看扁了。
char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(*arr));arr是首元素的地址,*arr就是首元素,大小就是1Byte。
char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(arr[1]));1.
char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(&arr));&arr是数组的地址,sizeof(&arr)就是4/8个字节。
char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(&arr + 1));&arr+1 是跳过数组后的地址,是地址就是4/8个字节。
char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(&arr[0] + 1));第二个元素的地址,是地址就是4/8Byte。
char arr[] = "abcdef";printf("%d\n", sizeof(arr));这个字符串创建的时候末尾必定有一个\0,所以答案是7.
char arr[] = "abcdef";printf("%d\n", sizeof(arr + 0));arr+0就是第一个元素地址,就是4/8。
char arr[] = "abcdef";printf("%d\n", sizeof(*arr));arr既没有单独放到sizeof内部,也没有&,所以是首元素地址,就是a的地址,*arr就是取出a的地址,大小就是一个字节。
char arr[] = "abcdef";printf("%d\n", sizeof(arr[1]));
arr[1]就是第二个元素的地址,所以是1.
char arr[] = "abcdef";printf("%d\n", sizeof(&arr));&arr就是取出数组的地址,是地址就是4/8个字节。
char arr[] = "abcdef";printf("%d\n", sizeof(&arr + 1));&arr+1,就是跳过整个数组,但也是地址,就是4/8个字节。
char arr[] = "abcdef";printf("%d\n", sizeof(&arr[0] + 1));&arr[0]就是取出第一个元素的地址,+1就是第二个元素的地址,就是4/8个字节。
char arr[] = "abcdef";printf("%d\n", strlen(arr));这个数组名虽然是单独放在strlen内部,但是和sizeof是有区别的,所以代表的是首元素地址,就是a的地址,统计的是\0之前的字符,就是6.
char arr[] = "abcdef";printf("%d\n", strlen(arr + 0));arr+0代表的是首元素的地址,也是6.
char arr[] = "abcdef";printf("%d\n", strlen(*arr));对首元素的地址进行解引用,就是a,ASCLL值是97,所以会报错。
char arr[] = "abcdef";printf("%d\n", strlen(arr[1]));arr[1]是第二个元素,也会报错。
char arr[] = "abcdef";printf("%d\n", strlen(&arr));取出的是arr的地址,所以是6.
char arr[] = "abcdef";printf("%d\n", strlen(&arr + 1));
跳过整个数组,把\0也跳过了,因为不知道啥时候遇到\0,所以是随机值。
char arr[] = "abcdef";printf("%d\n", strlen(&arr[0] + 1));取出的是第二个元素的地址,所以是5.
char* p = "abcdef";printf("%d\n", sizeof(p));
把a的地址交给了p,p是一个指针变量,所以sizeof(p)就是4/8.
char* p = "abcdef";printf("%d\n", sizeof(p + 1));char*指针加1就向后跳过一个字节,所以p指向了b,也是地址,所以是4/8.
char* p = "abcdef";printf("%d\n", sizeof(*p));p是char*的指针,所以解引用访问一个字节,就是1.
char* p = "abcdef";printf("%d\n", sizeof(p[0]));p[0]是第一个元素,所以也是1.
char* p = "abcdef";printf("%d\n", sizeof(&p));&p也是地址,地址就是4/8个字节。
char* p = "abcdef";printf("%d\n", sizeof(&p + 1));&p+1也是地址,所以也是4/8个字节。
char* p = "abcdef";printf("%d\n", sizeof(&p[0] + 1));
&p[0]+1就是第二个元素的地址,地址就是4/8个字节。
char* p = "abcdef";printf("%d\n", strlen(p));遇到\0就停止,所以是6.
char* p = "abcdef";printf("%d\n", strlen(p + 1));从第二个元素开始,所以是5.
char* p = "abcdef";printf("%d\n", strlen(*p));*p就是a,97,所以会出错。
char* p = "abcdef";printf("%d\n", strlen(p[0]));p[0]就是第一个元素,也是97,会出错。
char* p = "abcdef";printf("%d\n", strlen(&p));&p拿到的是随机值。
char* p = "abcdef";printf("%d\n", strlen(&p + 1));&p+1也是随机值。
char* p = "abcdef";printf("%d\n", strlen(&p[0] + 1));&p[0]+1,就是第二个元素的地址,所以是5.
今天的分享到这里就结束啦!谢谢老铁们的阅读,让我们下期再见。
相关文章:
)
指针进阶(3)
9. 模拟实现排序函数 这里我们使用冒泡排序算法,模拟实现一个排序函数,可以排序任意类型的数据。 这段代码可以排序整型数据,我们需要在这段代码的基础上进行改进,使得它可以排序任意类型的数据。 #define _CRT_SECURE_NO_WARN…...
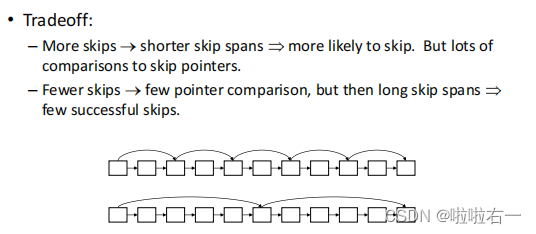
信息检索与数据挖掘 | (二)布尔检索与倒排索引
文章目录 📚词项-文档关联矩阵🐇相关名词🐇词项-文档关联矩阵的布尔查询处理 📚倒排索引🐇关于索引🐇建立索引🐇基于倒排索引的布尔查询处理🐇查询优化 📚字典数据结构&a…...

【学习笔记】EC-Final 2022 K. Magic
最近的题都只会抄题解😅 首先,操作顺序会影响答案,因此不能直接贪心。其次,因为是求贡献最大,所以可以考虑枚举最终哪些位置对答案产生了贡献,进而转化为全局贡献。 1.1 1.1 1.1 如果 [ l 1 , r 1 ) ⊆ [ …...
MySQL数据库笔记
文章目录 一、初识MySQL1.1、什么是数据库1.2、数据库分类1.3、MySQL简介 二、操作数据库2.1、操作数据库(了解)2.2、数据库的列类型2.3、数据库的字段属性(重点)2.4、创建数据库表(重点)2.5、数据表的类型…...
)
大数据之Hive(三)
分区表 概念和常用操作 将一个大表的数据按照业务需要分散存储到多个目录,每个目录称为该表的一个分区。一般来说是按照日期来作为分区的标准。在查询时可以通过where子句来选择查询所需要的分区,这样查询效率会提高很多。 ①创建分区表 hive (defau…...

让高分辨率的相机芯片输出低分辨率的图片对于像素级的值有什么影响?
很多图像传感器可以输出多个分辨率的图像,如果选择低分辨率格式的图像输出,对于图像本身会有什么影响呢? 传感器本身还是使用全部像素区域进行感光,但是在像素数据输出时会进行所谓的降采样(down-sampling)…...
FastGPT 接入飞书(不用写一行代码)
FastGPT V4 版本已经发布,可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景,例如联网谷歌搜索,操作数据库等等,功能非常强大,还没用过的同学赶紧去试试吧。 飞书相比同类产品算是体验非常好的办…...
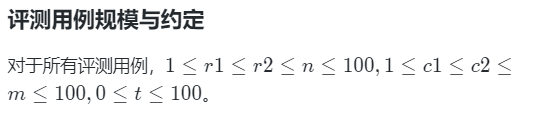
蓝桥杯 题库 简单 每日十题 day6
01 删除字符 题目描述 给定一个单词,请问在单词中删除t个字母后,能得到的字典序最小的单词是什么? 输入描述 输入的第一行包含一个单词,由大写英文字母组成。 第二行包含一个正整数t。 其中,单词长度不超过100&#x…...

使用Arduino简单测试HC-08蓝牙模块
目录 模块简介模块测试接线代码测试现象 总结 模块简介 HC-08 蓝牙串口通信模块是新一代的基于 Bluetooth Specification V4.0 BLE 蓝牙协议的数传模块。无线工作频段为 2.4GHz ISM,调制方式是 GFSK。模块最大发射功率为4dBm,接收灵度-93dBm,…...

如何在 CentOS 8 上安装 OpenCV?
OpenCV( 开源计算机视觉库)是一个开放源代码计算机视觉库,支持所有主要操作系统。它可以利用多核处理的优势,并具有 GPU 加速功能以实现实时操作。 OpenCV 的用途非常广泛,包括医学图像分析,拼接街景图像,监视视频&am…...

一台主机外接两台显示器
一台主机外接两台显示器 写在最前面双屏配置软件双屏跳转 写在最前面 在使用电脑时需要运行多个程序,时不时就要频繁的切换,很麻烦 但就能用双屏显示来解决这个问题,用一台主机控制,同时外接两台显示器并显示不同画面。 参考&a…...

笔记-搭建和使用docker-registry私有镜像仓库
笔记-搭建和使用docker-registry私有镜像仓库 拉取/安装registry镜像 和 对应的ui镜像 如果有网络可以直接拉取镜像 docker pull registry docker pull hyper/docker-registry-web没有网络可以使用我导出好的离线镜像tar包, 下载地址https://wwzt.lanzoul.com/i3im1194z12d …...
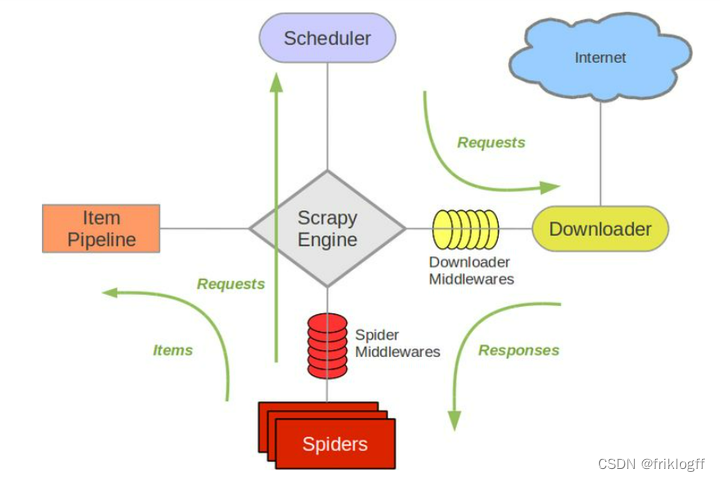
爬虫框架Scrapy学习笔记-2
前言 Scrapy是一个功能强大的Python爬虫框架,它被广泛用于抓取和处理互联网上的数据。本文将介绍Scrapy框架的架构概览、工作流程、安装步骤以及一个示例爬虫的详细说明,旨在帮助初学者了解如何使用Scrapy来构建和运行自己的网络爬虫。 爬虫框架Scrapy学…...
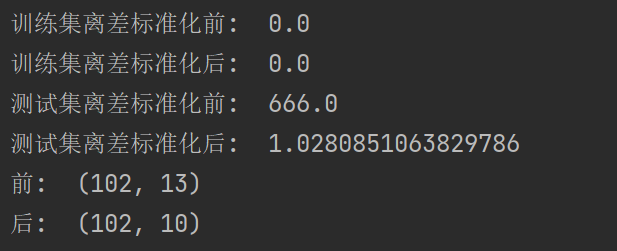
6.1 使用scikit-learn构建模型
6.1 使用scikit-learn构建模型 6.1.1 使用sklearn转换器处理数据6.1.2 将数据集划分为训练集和测试集6.1.3 使用sklearn转换器进行数据预处理与降维1、数据预处理2、PCA降维算法 代码 scikit-learn(简称sklearn)库整合了多种机器学习算法,可以…...
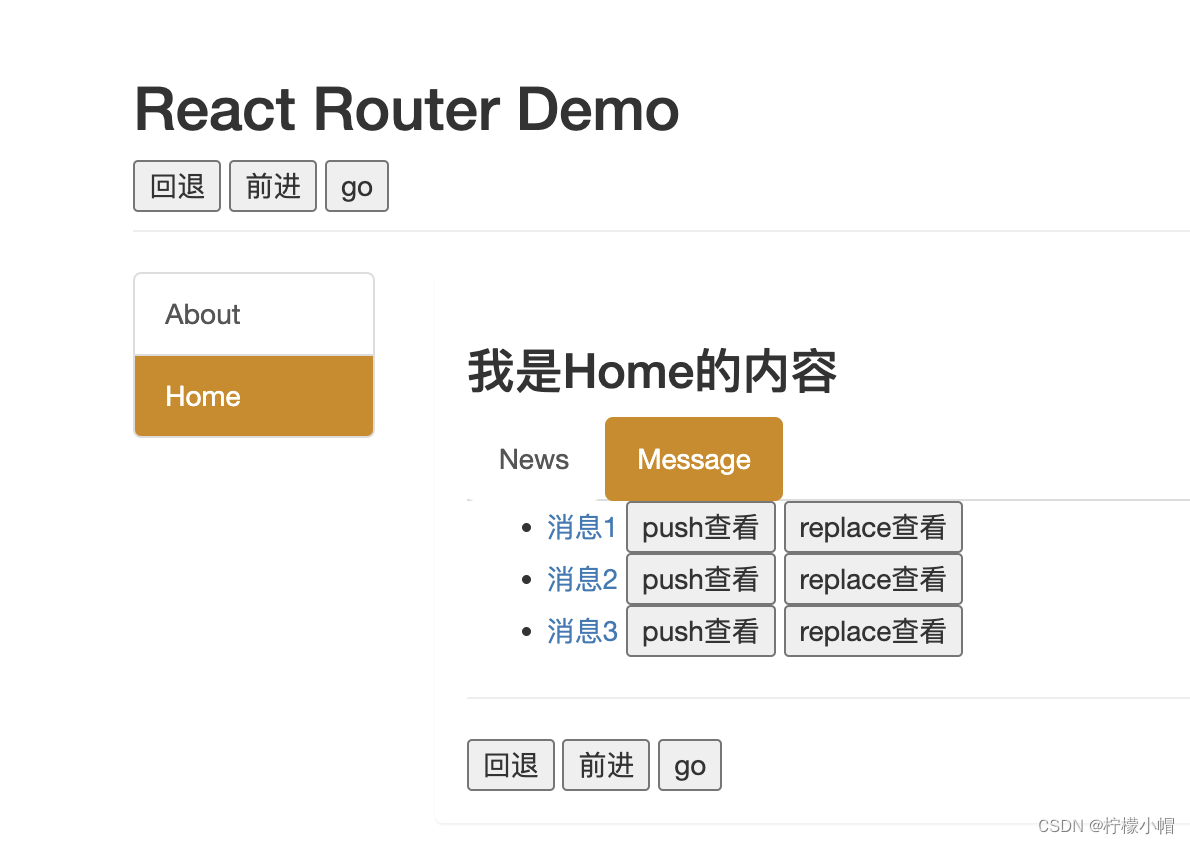
React 全栈体系(十一)
第五章 React 路由 五、向路由组件传递参数数据 1. 效果 2. 代码 - 传递 params 参数 2.1 Message /* src/pages/Home/Message/index.jsx */ import React, { Component } from "react"; import {Link, Route} from react-router-dom import Detail from ./Detai…...
AI 时代的向量数据库、关系型数据库与 Serverless 技术丨TiDB Hackathon 2023 随想
TiDB Hackathon 2023 刚刚结束,我仔细地审阅了所有的项目。 在并未强调项目必须使用人工智能(AI)相关技术的情况下,引人注目的项目几乎一致地都使用了 AI 来构建自己的应用。 大规模语言模型(LLM)的问世使得…...

Vue的路由使用,Node.js下载安装及环境配置教程 (超级详细)
前言: 今天我们来讲解关于Vue的路由使用,Node.js下载安装及环境配置教程 一,Vue的路由使用 首先我们Vue的路由使用,必须要导入官方的依赖的。 BootCDN - Bootstrap 中文网开源项目免费 CDN 加速服务https://www.bootcdn.cn/ <…...

vue修改node_modules打补丁步骤和注意事项
当我们使用 npm 上的第三方依赖包,如果发现 bug 时,怎么办呢? 想想我们在使用第三方依赖包时如果遇到了bug,通常解决的方式都是绕过这个问题,使用其他方式解决,较为麻烦。或者给作者提个issue,然…...

CSS 响应式设计:媒体查询
文章目录 媒体查询添加断点为移动端优先设计其他断点方向:横屏/竖屏 媒体查询 CSS中的媒体查询是一种用于根据不同设备的屏幕尺寸和分辨率来定义样式表的方法。在CSS中,我们可以使用媒体查询来根据不同的设备类型和屏幕尺寸来应用不同的样式,…...
Qt开发 - Qt基础类型
1.基础类型 因为Qt是一个C 框架, 因此C中所有的语法和数据类型在Qt中都是被支持的, 但是Qt中也定义了一些属于自己的数据类型, 下边给大家介绍一下这些基础的数类型。 QT基本数据类型定义在#include <QtGlobal> 中,QT基本数据类型有: 虽然在Qt中…...

福特技术复兴:用户体验整合如何重塑汽车行业竞争格局
1. 福特的技术复兴之路:一次深度拆解十年前,当大多数传统汽车制造商还在为金融危机后的生存而挣扎时,福特汽车做出了一个在当时看来颇具前瞻性的决定:将技术,而非仅仅是马力或造型,作为品牌复兴的核心驱动力…...
)
拒绝纸上谈兵!深度拆解 hello-agents:从零开始构建你的第一个智能体 (AI Agent)
发布日期: 2026-02-10标签: #AIAgent #智能体 #Datawhale #大模型 #Python #人工智能入门一、 引言如果说 2024 年是大模型的元年,那么 2026 年则是 AI Agent(智能体) 的应用爆发年。单纯的对话已经无法满足需求&#…...

告别枯燥理论:用51单片机和DAC0832做个迷你音乐合成器,汇编语言实现《小星星》
用51单片机和DAC0832打造迷你音乐合成器:汇编语言实现《小星星》全解析 在嵌入式系统学习的道路上,很多初学者都会遇到一个共同的问题:如何将枯燥的理论知识转化为有趣的实际应用?今天,我们就来打破常规,用…...

如何在iOS设备上快速安装TrollStore:TrollInstallerX完整使用指南
如何在iOS设备上快速安装TrollStore:TrollInstallerX完整使用指南 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS 14.0到16.6…...

Illustrator脚本自动化终极指南:如何节省设计师90%重复工作时间
Illustrator脚本自动化终极指南:如何节省设计师90%重复工作时间 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts Adobe Illustrator脚本自动化是每个设计师都应该掌握的生…...

【高频电子线路】从抽头到变压器:解锁谐振功率放大器的阻抗变换实战
1. 高频电路中的阻抗匹配为什么重要 我第一次调试射频功放时,烧掉了三个末级晶体管才明白一个道理:高频电路里,阻抗不匹配就像让卡车走自行车道。那个周末实验室里飘着的焦糊味,至今让我对阻抗变换保持敬畏。 在高频环境下&#x…...

Fillinger智能填充算法深度解析:从三角剖分到工程化实现
Fillinger智能填充算法深度解析:从三角剖分到工程化实现 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在矢量图形设计领域,复杂形状内的元素填充是一个常见…...

ROS2机械臂实战:ros2_control、moveit2与move_group核心问题排查与解决
1. ROS2机械臂开发中的常见问题与调试思路 最近在做一个ROS2机械臂项目,用到了ros2_control、moveit2和move_group这几个核心组件。说实话,从零开始搭建这套系统踩了不少坑,特别是硬件接口初始化、控制器配置这些环节。今天就把我遇到的一些典…...

【仿真实战】AnyLogic地铁站客流仿真:从零搭建带安检与限流的多层车站模型
1. 从零开始搭建地铁站仿真模型 第一次接触AnyLogic做地铁站客流仿真时,我完全被各种模块和参数搞晕了。后来在几个实际项目中摸爬滚打,终于总结出一套小白也能快速上手的方法。这次我们就来搭建一个包含安检区和限流措施的多层地铁站模型,整…...

AI智能体技能超市:用SKILL.md标准打破AI能力壁垒
1. 项目概述:一个为AI智能体准备的“技能超市” 如果你和我一样,每天都在和各种AI编程助手打交道——Cursor、Claude Code、GitHub Copilot,那你肯定也遇到过这样的场景:想让AI帮你生成一张产品原型图,结果它告诉你“我…...