【排序算法】冒泡排序、插入排序、归并排序、希尔排序、选择排序、堆排序、快速排序
目录
几大排序汇总
1.冒泡排序
性能:
思路和代码:
2.插入排序
性能:
思路和代码:
3.归并排序
性能:
思路和代码:
4.希尔排序
性能:
思路和代码:
5.选择排序
性能:
思路和代码:
6.堆排序
性能:
思路和代码:
topK问题
7.快速排序
性能:
思路和代码:
几大排序汇总
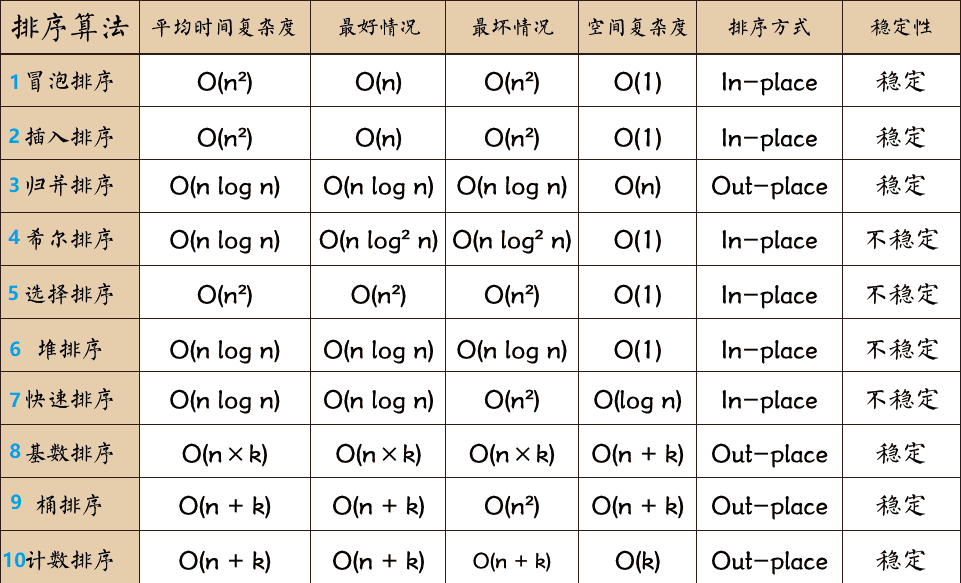
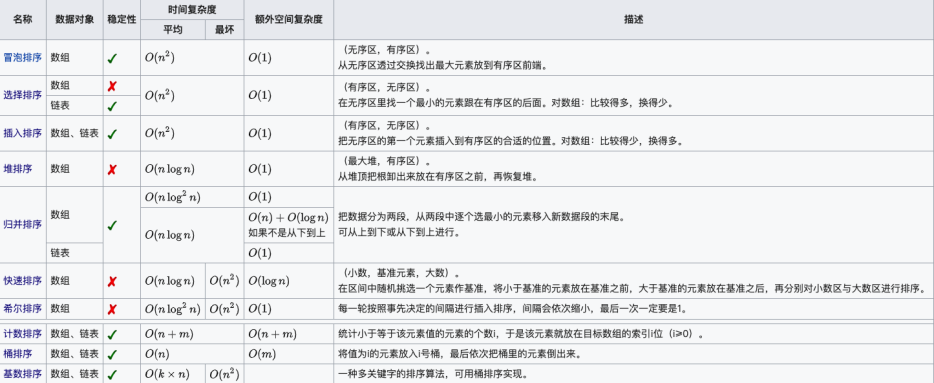
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。用一张图概括
1.冒泡排序
性能:
- 时间复杂度: O(N^2)
- 空间复杂度: O(1)
- 稳定性: 稳定
- 原地排序
时间复杂度:
冒泡排序算法的时间复杂度为O(N^2),其中N是数组的大小。
外层循环需要执行N-1次,表示需要进行N-1趟排序。内层循环在第i趟排序时需要比较的次数为nums.size()-1-i次。因此,总的比较次数为:
(N-1) + (N-2) + ... + 2 + 1 = (N-1) * N / 2 = (N^2 - N) / 2
空间复杂度:
冒泡排序算法是一种原地排序算法,它只需要使用常数级别的额外空间来存储临时变量,例如循环中的索引、交换时的临时变量等。随着输入规模的增加,所需的额外空间大小并不会改变,因此空间复杂度为O(1)。
思路和代码:
有四个数, 排完序需要三趟, 第一趟需要比较三次, 第二趟需要比较二次, 第三趟需要比较一次
把第一个元素与第二个元素比较,如果第一个比第二个大,则交换他们的位置。接着继续比较第二个与第三个元素,如果第二个比第三个大,则交换他们的位置….我们对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样一趟比较交换下来之后,排在最右的元素就会是最大的数。除去最右的元素,我们对剩余的元素做同样的工作,如此重复下去,直到排序完成
优化一下冒泡排序的算法
假如从开始的第一对到结尾的最后一对,相邻的元素之间都没有发生交换的操作,这意味着右边的元素总是大于等于左边的元素,此时的数组已经是有序的了,我们无需再对剩余的元素重复比较下去了。
#include <iostream>
#include <vector>
using namespace std;void bubblesort(vector<int>& nums)
{if (nums.size() < 2) return;for (int i = 0; i < nums.size() - 1; i++) // 一共需要 n-1 趟{bool flag = false;// 随着趟数的增加, 比较的次数随之减小for (int j = 0; j < nums.size() - 1 - i; j++) // 第 i+1 趟时, 一共需要比较多少次 { // 第 i+1 趟时, 需要比较 nums.size()-1-i 次 if (nums[j] > nums[j + 1]){flag = true;myswap(nums, j, j + 1);}}if (flag == false) // 一趟下来没有发生位置交换, 说明这是有序的集合, 因此直接break即可{break;}}
}2.插入排序
性能:
- 时间复杂度: 最坏情况, 逆序O(N^2), 最好情况下O(N)
- 空间复杂度: O(1)
- 稳定的排序
- 什么时候用插排高效? 小规模数据或者基本有序时越高效(移动少)
时间复杂度:
插入排序的时间复杂度取决于待排序数组的初始状态。在最坏情况下,即待排序数组为逆序排列时,插入排序的时间复杂度为O(N^2),其中N是数组的大小。
外部的for循环需要执行N-1次,表示需要对N-1个元素进行插入操作。对于每个待插入的元素,内部的while循环最多需要比较和移动该元素前面的所有元素,最坏情况下为N-1次。因此,总的比较和移动操作次数为:1 + 2 + 3 + ... + (N-1) = (N-1) * N / 2 = (N^2 - N) / 2
需要注意的是,在最好情况下,即待排序数组已经是有序的情况下,插入排序的时间复杂度为O(N),因为每个元素只需要与其前面的一个元素进行比较即可。
综上所述,插入排序的时间复杂度在最坏情况下为O(N^2),在最好情况下为O(N),空间复杂度为O(1)。
空间复杂度:
插入排序的空间复杂度为O(1),即不需要额外的空间与输入规模相关。在插入排序算法中,排序操作是通过原地交换和移动数组元素来实现的,不需要使用额外的数组或数据结构存储临时结果。
无论输入数组的规模大小,插入排序只需要常数级别的额外空间来存储一些辅助变量,如循环变量、待插入元素的副本等。这些额外空间的使用与输入规模无关,因此插入排序的空间复杂度是O(1)。
这是插入排序算法的一个优点,尤其适用于空间有限的环境或对空间复杂度有要求的场景。
思路和代码:
这段代码实现了插入排序算法。插入排序的思路是将数组分为已排序和未排序两部分。初始时,将第一个元素视为已排序部分,从第二个元素开始,逐个将未排序部分的元素插入到已排序部分的正确位置,直到所有元素都被插入到已排序部分。
从数组的第二个元素开始遍历,将当前元素视为待插入的元素。
将待插入元素与已排序部分的元素从后往前进行比较,如果已排序部分的元素大于待插入元素,则将该元素后移一位,直到找到小于等于待插入元素的位置。
将待插入元素插入到找到的位置后面,保持已排序部分的有序性。
重复步骤2和步骤3,直到遍历完所有的待插入元素。
通过不断将待插入元素插入到已排序部分的正确位置,最终实现了整个数组的排序。
#include <iostream>
#include <vector>
using namespace std;void insertsort(vector<int>& nums)
{// 第一个元素认为是有序的, 所以从第二个元素开始遍历for (int i = 1; i < nums.size(); i++){int inserted = nums[i]; // 待插入的元素int j = i - 1;// 插入排序是稳定的排序算法,当遇到相等的元素时,应该停止向后移动,以保持相对顺序不变。for (; j >= 0 && nums[j] > inserted; j--){nums[j + 1] = nums[j]; // 将比 inserted 大的元素向后移}nums[j + 1] = inserted; // 将 inserted 插入到正确位置}
}
/* 插入排序 */
void insertsort(vector<int>& nums)
{if(nums.size() < 2) return;for(int i = 1; i < nums.size(); i++){int inserted = nums[i];int j = i - 1;for(; j >= 0; j--){if(nums[j] > inserted) {nums[j + 1] = nums[j];}else{break;}}nums[j + 1] = inserted;}
}3.归并排序
性能:
- 时间复杂度: O(N*logN), 不管数据是有序的还是无序的, 都是这个时间复杂度
- 空间复杂度: O(N)
- 归并排序是稳定的
- 非原地排序
时间复杂度:
归并排序的时间复杂度是O(nlogn),其中n是待排序数组的长度。
在归并排序中,每一次递归都将数组分为两个大小相等(或相差最多1)的子数组。这个过程的时间复杂度是O(logn),因为每次递归都将数组的规模减半.
在合并操作中,需要比较和合并两个子数组的元素。合并过程的时间复杂度是O(n),其中n是两个子数组的总长度。
因此,总的时间复杂度可以表示为T(n) = 2T(n/2) + O(n),其中T(n/2)表示对两个子数组的递归调用,O(n)表示合并操作的时间复杂度。
根据主定理(Master Theorem)的第三种情况,可以得到归并排序的时间复杂度为O(nlogn)。
空间复杂度:
归并排序的空间复杂度是O(n),其中n是待排序数组的长度。
在归并排序的过程中,需要创建一个临时数组来存储合并操作中的元素。这个临时数组的大小与待排序数组的长度相等,因此需要额外的O(n)的空间来存储临时数组。
除了临时数组外,归并排序的递归调用也会使用一定的栈空间。在每一层递归调用中,需要保存一些变量和返回地址。由于归并排序的递归深度是O(logn),所以递归调用所使用的栈空间也是O(logn)的。
综上所述,归并排序的总空间复杂度是O(n + logn),简化后仍为O(n)。
需要注意的是,在实际实现中,如果原地排序,可以避免创建临时数组,将临时结果存储在原始数组中,这样可以将空间复杂度优化为O(1)。但给定的代码中使用了额外的临时数组来存储合并操作的结果,因此空间复杂度为O(n)。
思路和代码:
- 归并排序使用分治的思想,将待排序的数组分割成较小的子数组,直到子数组的长度为1或为空。
- 通过递归调用归并排序,对左右两个子数组进行排序,直到所有子数组都被排序。
- 将两个已排序的子数组合并成一个有序数组。
- 在合并操作中,创建一个临时数组,比较两个子数组的元素,并将较小的元素放入临时数组中。重复这个过程,直到其中一个子数组的元素都放入了临时数组。
- 如果其中一个子数组还有剩余的元素,将剩余的元素复制到临时数组的末尾。
- 将临时数组中的元素拷贝回原始数组的相应位置。
- 重复以上步骤,直到所有子数组都合并完成,最终得到一个完全有序的数组。
#include <iostream>
#include <vector>
using namespace std;void merge(vector<int>& nums, int begin, int end, int midIndex)
{vector<int> tmpArr(nums.begin() + begin, nums.begin() + end + 1);int k = 0;int b1 = begin;int e1 = midIndex;int b2 = midIndex + 1;int e2 = end;while(b1 <= e1 && b2 <= e2){if(nums[b1] > nums[b2]){tmpArr[k++] = nums[b2++];}else {tmpArr[k++] = nums[b1++];}}while(b1 <= e1){tmpArr[k++] = nums[b1++];}while(b2 <= e2){tmpArr[k++] = nums[b2++];}for(int i = 0; i < tmpArr.size(); i++){nums[i + begin] = tmpArr[i];}
}void process(vector<int>& nums, int left, int right)
{if(left >= right) return;// int mid = (left + right) / 2;int mid = left + (right - left) / 2;process(nums, left, mid);process(nums, mid + 1, right);merge(nums, left, right, mid);
}void mergesort(vector<int>& nums)
{if(nums.size() < 2) return;process(nums, 0, nums.size() - 1);
}4.希尔排序
性能:
- 时间复杂度: O(N^1.3 ~ N^1.5)
- 空间复杂度: O(1)
- 稳定性: 不稳定
- 原地排序
时间复杂度:
希尔排序的时间复杂度并不容易精确确定,它取决于所选择的间隔序列。在最坏情况下,希尔排序的时间复杂度为O(n^2),但在平均情况下,其复杂度通常被认为是小于O(n^2)的。
希尔排序的时间复杂度分析比较复杂,因为它涉及到不同的间隔序列和排序过程中的元素比较次数。最好的情况下,当间隔序列满足特定条件时,希尔排序可以达到接近O(n)的时间复杂度。但是,一般来说,希尔排序的时间复杂度介于O(n log n)和O(n^2)之间。
希尔排序的时间复杂度取决于选择的间隔序列的性质。常见的间隔序列包括希尔序列、Hibbard序列、Sedgewick序列等。不同的间隔序列会对排序过程中的比较次数产生影响,进而影响时间复杂度的上界。
综合来说,希尔排序的时间复杂度是一个开放问题,没有一个确定的公式或界限。它的时间复杂度通常被认为是介于O(n log n)和O(n^2)之间。在实际应用中,希尔排序通常比简单的插入排序具有更好的性能,尤其对于较大规模的数据集。
空间复杂度:
希尔排序的空间复杂度是O(1),即不需要额外的空间来存储数据。希尔排序是一种原地排序算法,它通过在原始数组上进行元素的比较和交换来进行排序,不需要额外的辅助数组或数据结构。
希尔排序的排序过程中只涉及到有限的几个变量,如间隔序列的增量、待插入的元素和临时变量用于交换元素位置。这些变量的空间占用是常数级别的,与输入规模无关。
因此,希尔排序的空间复杂度是O(1),即空间占用是固定的,不随输入规模的增长而增加。这使得希尔排序在空间有限或对空间复杂度要求较高的情况下具有优势。
思路和代码:
这段代码实现了希尔排序算法,它是插入排序的一种改进版本。希尔排序通过将数组分组进行插入排序,并逐步缩小分组的间隔,最终实现整体的排序。
初始化间隔(gap)为数组大小。在每次循环中,将数组按照当前间隔进行分组,对每个分组进行插入排序。逐步缩小间隔,直到间隔为1,完成最后一轮整体的插入排序。
在代码中,shell函数实现了按照给定间隔进行分组的插入排序。它的主要逻辑是:
从第gap个元素开始,将当前元素视为待插入的元素。
将待插入元素与当前分组中的元素进行比较,如果当前分组中的元素大于待插入元素,则将该元素后移gap个位置。
重复步骤2,直到找到小于等于待插入元素的位置。
将待插入元素插入到找到的位置后面。
在ShellSort函数中,通过不断缩小间隔(gap)的值,调用shell函数进行分组插入排序,直到间隔为1,完成最后一轮整体的插入排序。
#include <iostream>
#include <vector>
using namespace std;void shell(vector<int>& nums, int gap)
{// 这里的i需要++for (int i = gap; i < nums.size(); i++){int inserted = nums[i];int j = i - gap;for (; j >= 0; j -= gap){if (nums[j] > inserted){nums[j + gap] = nums[j];}else{break;}}nums[j + gap] = inserted;}
}void shellsort(vector<int>& nums)
{int gap = nums.size();while (gap > 1){shell(nums, gap);gap /= 2;}// 最后整体看成一组进行直接插入排序shell(nums, 1);
}5.选择排序
性能:
- 时间复杂度: O(N^2), 选择排序对数据不敏感, 不管数据是有序还是无序的时间复杂度都是N^2
- 空间复杂度: O(1)
- 稳定性: 不稳定
时间复杂度:
选择排序的时间复杂度为 O(n^2),其中 n 是数组的长度。
在每一轮循环中,需要遍历无序区间来查找最小值的索引,这个遍历的次数是一个等差数列,其长度从 n-1 递减到 1。因此,总的比较次数可以近似为 n-1 + n-2 + ... + 2 + 1,即等差数列的求和公式,结果为 (n-1) * n / 2。这说明比较的次数与 n 的平方级别成正比。
除了比较操作,选择排序还需要进行元素交换的操作,每一轮循环最多进行一次交换。因此,交换的次数也是与 n 成正比的。
综上所述,选择排序的时间复杂度为 O(n^2)。即使在最好情况下,每个元素都已经有序,仍然需要进行 n-1 次比较,因此时间复杂度仍然是 O(n^2)。选择排序的时间复杂度相对较高,在大规模数据排序时不如其他高效的排序算法。
空间复杂度:
选择排序的空间复杂度为 O(1),即不需要额外的空间。
选择排序是在原地进行排序的算法,它只需要使用常数级别的额外空间来存储临时变量和进行元素交换。无论输入数据规模的大小,额外空间的使用量都保持不变,因此空间复杂度是常数级别的 O(1)。这使得选择排序在空间有限的情况下也能有效地进行排序。
思路和代码:
选择排序的思路是在每一轮循环中选择无序区间中的最小值,并将其放到有序区间的末尾,直到所有元素有序。
遍历数组,将数组分为有序区间和无序区间。初始时,有序区间为空,无序区间包含整个数组。
在无序区间中查找最小值的索引,记录为 minIndex。
将找到的最小值与无序区间的第一个元素进行交换。
有序区间扩大一个元素,无序区间缩小一个元素,即有序区间的末尾增加一个元素,无序区间的开头减少一个元素。
重复步骤2到步骤4,直到无序区间为空。
该算法通过不断选择最小值并交换位置,逐步将最小值放到有序区间的末尾,使得有序区间不断扩大,无序区间不断缩小,最终实现整个数组的排序。
#include <iostream>
#include <vector>
using namespace std;// 版本一(一次找一个):
void selectsort(vector<int>& nums)
{// 从无序区间不断挑选出最小值. 挑选 n-1 次(最后一个元素不用挑)for (int i = 0; i < nums.size(); i++){// i 下标左边已经排好序, 右边(包括 i)是无序的区间// 最小值下标默认是无序区间的第一个元素的下标int minIndex = i;for (int j = i + 1; j < nums.size(); j++) // 找出最小值{if (nums[j] < nums[minIndex]){minIndex = j; // 更新最小值的下标}}myswap(nums, i, minIndex); // 交换最小值与无序区间的第一个元素}
}// 版本二(一次找俩个):
void selectsort2(vector<int>& nums)
{int left = 0;int right = nums.size() - 1;while (left < right){int maxIndex = left;int minIndex = left;for (int i = left + 1; i <= right; i++){if (nums[i] > nums[maxIndex]){maxIndex = i;}else if (nums[i] < nums[minIndex]){minIndex = i;}}myswap(nums, minIndex, left);//需要这个 if 判断, 否则存在bug//如果left下标的值就是最大值, 不加这个if, 就会导致找到的最大值下标(maxIndex)被篡改//案例: 18 3 10 2 7if (left == maxIndex){maxIndex = minIndex;}myswap(nums, maxIndex, right);left++;right--;}
}6.堆排序
性能:
- 时间复杂度: O(N*logN)
- 空间复杂度: O(1)
- 堆排序是不稳定的
- 原地排序
时间复杂度:
堆排序的时间复杂度为O(NlogN),其中N是数组的大小。
建立堆的过程需要从最后一个非叶子节点开始,对每个节点调用adjustDown函数,时间复杂度为O(N)。
交换和调整的过程需要将根节点与最后一个节点交换,然后再次调用adjustDown函数,重复执行N-1次。每次调整的时间复杂度为O(logN)。因此,总的时间复杂度为O(NlogN)。
空间复杂度:
堆排序的空间复杂度为O(1),即原地排序。
堆排序算法不需要额外的辅助空间来存储中间结果,所有的操作都是在原始数组上进行的。只需要用到常数级别的额外空间来存储一些临时变量,如父节点、子节点等,而不随数组规模的增加而变化。
思路和代码:
adjustDown函数是向下调整的操作,用于将最大的元素调整到堆顶。它接受一个数组 nums、堆的大小 size 和需要进行调整的父节点索引 parent。在该函数中,首先通过计算获取父节点的左孩子索引 child。然后在循环中,通过比较左右孩子的值,选择较大的孩子节点。如果孩子节点的值大于父节点的值,则交换它们,并更新父节点和孩子节点的索引。最后,如果孩子节点的值小于或等于父节点的值,就跳出循环。这样,就能够将最大的元素调整到堆顶。
heapsort函数是堆排序的主要实现。首先,它检查数组的大小,如果大小小于2,则表示数组已经有序,直接返回。接下来,执行堆排序的两个主要步骤:
建立大堆:从倒数第一个非叶子节点开始,依次对每个父节点调用adjustDown函数,将数组调整为一个大堆。这个过程确保了每个父节点都大于或等于其子节点。
交换和调整:从堆的根节点开始,将根节点(最大元素)与堆的最后一个元素交换,然后通过调用adjustDown函数将交换后的堆重新调整为大堆。然后,继续将根节点与倒数第二个元素交换,并再次调整堆。依此类推,直到将所有元素都交换到适当的位置。
通过以上步骤,堆排序能够按照从小到大的顺序对给定数组进行排序。堆排序具有时间复杂度为O(NlogN),其中N是数组的大小。它是一种原地排序算法,因为只需要对原始数组进行原地交换,而不需要额外的空间。
#include <iostream>
#include <vector>
using namespace std;// 大堆
// 向下调整
// 将最大的元素调整到堆顶
void adjustDown(vector<int>& nums, int size, int parent)
{int child = 2 * parent + 1;// 最起码保证有左孩子while (child < size){// 看看有没有右孩子, 要是有再看看右孩子是不是大于左孩子, 大于就用右孩子和父节点比较if (child + 1 < size && nums[child + 1] > nums[child]){child++; // 选出左右孩子中最小的那个}if (nums[child] > nums[parent]){myswap(nums, child, parent);parent = child;child = 2 * parent + 1;}else{break;}}
}void heapsort(vector<int>& nums)
{if(nums.size() < 2) return;// 1. 建大堆 O(N)// 将元素全部入完, 从 i 开始向下调整int N = nums.size();// i 从倒数第一个非叶子节点开始// N-1 表示最后一个元素的下标, 再 -1 是为了实现由孩子节点找到父亲节点for (int i = (N - 1 - 1) / 2; i >= 0; i--){adjustDown(nums, N, i);}// 2. 和堆顶元素做交换 O(N*logN)int end = N - 1;while (end > 0){myswap(nums, 0, end);adjustDown(nums, end, 0);end--;}
}topK问题
选出最大的第K个, 建立小堆
选出最小的第K个, 建立大堆
#include <iostream>
#include <vector>
using namespace std;// 选出最大的前K个元素, 需要建小堆
// 这种方法只需要建立大小为K的堆即可, 节省空间
void myswap(vector<int>& nums, int a, int b)
{int tmp = nums[a];nums[a] = nums[b];nums[b] = tmp;
}
// 向下调整
// 建小堆
void adjustDown(vector<int>& a, int size, int parent)
{int child = 2 * parent + 1;while (child < size){if (child + 1 < size && a[child + 1] < a[child]) // a[child + 1] > a[child]{ // 选出左右孩子中小的那个child++;}if (a[child] < a[parent]) // a[child] > a[parent]{myswap(a, child, parent);parent = child;child = 2 * parent + 1;}else{break;}}
}// Top-K问题(最大的前K个)
// 这是最优的topK, 空间复杂度很低
void topK(vector<int>& a, int k)
{// 1. 建堆 -- 用a中前k个元素建堆vector<int> KMinHeap;for (int i = 0; i < k; i++) // 将元素存入到数组中{KMinHeap.push_back(a[i]);}for (int i = (k - 1 - 1) / 2; i >= 0; i--) // 建堆{adjustDown(KMinHeap, k, i);}// 2. 将剩余的n-k个元素和堆顶元素进行比较, 大于堆顶元素的就交换int N = a.size();for (int i = k; i < N; i++){if (a[i] > KMinHeap[0]) // a[i] < KMinHeap[0]{KMinHeap[0] = a[i];adjustDown(KMinHeap, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", KMinHeap[i]);}
}7.快速排序
性能:
- 时间复杂度: O(N*logN)(平均情况), 最坏情况下O(N^2)
- 空间复杂度: O(logN)(平均情况), 最坏情况下O(N)
- 快排没有稳定性
- 原地排序
时间复杂度:
快速排序的平均时间复杂度为 O(nlogn),其中 n 是待排序数组的长度。
在每一次快速排序的划分过程中,数组被分为两个部分,左侧部分的元素小于等于基准元素,右侧部分的元素大于等于基准元素。这个过程的时间复杂度是 O(n),其中 n 是当前待排序数组的长度。
在平均情况下,每次划分都将数组分成大致相等的两部分,即左右子数组的规模大致为 n/2。这样,如果我们假设每次划分花费的时间是常数,那么在进行完 O(logn) 次划分后,数组就会完全有序。因此,平均情况下的时间复杂度为 O(nlogn)。
需要注意的是,最坏情况下,即每次划分后都使得数组中的一个子数组为空,此时快速排序的时间复杂度为 O(n^2)。这种情况通常发生在输入数据已经有序或接近有序的情况下,并且基准元素的选择不合适(如选择的始终是最大或最小元素)。为了避免最坏情况的发生,可以采用随机化的方式选择基准元素。
综上所述,快速排序的平均时间复杂度为 O(nlogn),最坏情况下的时间复杂度为 O(n^2)。在实践中,快速排序通常具有较好的性能,尤其对于大规模数据的排序。
空间复杂度:
快速排序的空间复杂度主要取决于递归调用的栈空间和基准元素的选择方式。
在最坏情况下,即每次选择的基准元素都是当前子数组中的最大或最小值时,快速排序的递归树将达到最大深度,此时空间复杂度为 O(n)。每次递归调用都会在栈上创建一个新的帧,直到递归结束后栈帧逐个弹出。
在平均情况下,快速排序的递归树的平均深度为 O(logn),因此空间复杂度也为 O(logn)。这是因为每次递归调用时,数组被分割成两个子数组,每个子数组的规模大约是原数组的一半,递归树的高度大约为 logn。
除了递归调用的栈空间外,快速排序通常不需要额外的辅助空间。它是一种原地排序算法,通过交换元素来进行排序,不需要额外的数组或数据结构来存储中间结果。
需要注意的是,如果使用随机化的方式选择基准元素,即在每次排序时随机选择一个元素作为基准,可以平衡地分割数组,降低最坏情况出现的概率,从而进一步减少空间复杂度的期望值。
综上所述,快速排序的空间复杂度为 O(logn)(平均情况)和 O(n)(最坏情况),其中 n 是待排序数组的长度。
思路和代码:
快速排序核心思想是通过选择一个基准元素,将数组分割成左右两个子数组,其中左边的子数组元素都小于等于基准元素,右边的子数组元素都大于等于基准元素,然后对左右子数组递归地进行排序。
递归调用。对左右子数组分别进行递归调用快速排序,直到子数组的长度小于等于1时终止递归。
合并结果。当递归调用结束后,子数组都已经有序,此时整个数组也就有序了。
荷兰国旗问题是快速排序算法的一种优化,旨在处理数组中存在重复元素的情况。它的目标是将数组中的元素按照某个特定值进行分区,使得分区后的数组满足以下条件:
- 左边的子数组中的元素都小于特定值。
- 中间的子数组中的元素都等于特定值。
- 右边的子数组中的元素都大于特定值。
#include <iostream>
#include <vector>
#include <cstdlib> // 包含 rand 函数
using namespace std;vector<int> netherlandsFlag(vector<int>& nums, int left, int right)
{if(left > right) return { -1, -1 };if(left == right) return { left, right };int less = left - 1; // 左边界的前一个位置int more = right; // 右边界int index = left;while(index < more){if(nums[index] < nums[right]){myswap(nums, index++, ++less);}else if(nums[index] > nums[right]){myswap(nums, index, --more);}else{index++;}}// 将基准元素放到等于区域的最后一个位置上,将等于区域的边界返回作为分区点。myswap(nums, index, right);return { less + 1, more};
}void process(vector<int>& nums, int left, int right)
{if(left >= right) return;int index = left + (int)(rand() % (right - left + 1));myswap(nums, index, right);vector<int> equalsArea = netherlandsFlag(nums, left, right);process(nums, left, equalsArea[0] - 1);process(nums, equalsArea[1] + 1, right);
}void quicksort(vector<int>& nums)
{if(nums.size() < 2) return;process(nums, 0, nums.size() - 1);
}#include <iostream>
#include <vector>
#include <stack>
#include <cstdlib> // 包含 rand 函数
#include <algorithm> // 包含 swap 函数
using namespace std;/* 快排-非递归 */
vector<int> netherlandsFlag(vector<int>& nums, int left, int right)
{if (left > right) return { -1, -1 };if (left == right) return { left, right };int less = left - 1;int more = right;int index = left;while (index < more){if(nums[index] < nums[right]){myswap(nums, index++, ++less);}else if(nums[index] > nums[right]){myswap(nums, index, --more);}else{index++;}}// 将基准元素放到等于区域的最后一个位置上,将等于区域的边界返回作为分区点。myswap(nums, index, right);return { less + 1, more };
}void quicksort(vector<int>& nums)
{if (nums.size() < 2) return;stack<pair<int, int>> st;st.push(make_pair(0, nums.size() - 1));while (!st.empty()){int left = st.top().first;int right = st.top().second;/*当我们处理完一个子数组时,该子数组已经被完全排序,不再需要进一步的处理。因此,我们需要将其从栈中移除,以便下一轮循环时可以取出下一个待处理的子数组。*/st.pop();if (left >= right) continue;int index = left + rand() % (right - left + 1);myswap(nums, index, right);vector<int> equalsArea = netherlandsFlag(nums, left, right);st.push(make_pair(left, equalsArea[0] - 1));st.push(make_pair(equalsArea[1] + 1, right));}
}相关文章:
【排序算法】冒泡排序、插入排序、归并排序、希尔排序、选择排序、堆排序、快速排序
目录 几大排序汇总 1.冒泡排序 性能: 思路和代码: 2.插入排序 性能: 思路和代码: 3.归并排序 性能: 思路和代码: 4.希尔排序 性能: 思路和代码: 5.选择排序 性能: 思路和代码: 6.堆排序 性能: 思路和代码: topK问题 7.快速排序 性能: 思路和代码: 几大排…...

Linux学习笔记-应用层篇
1、Linux进程、线程概念/区别 Linux进程和线程是计算机系统中两种不同的资源分配和调度单位。 进程是计算机系统进行资源分配和调度的基本单位,也被认为是正在运行的程序。在面向线程的计算机结构中,进程是线程的容器。进程拥有独立的内存和系统资源&am…...

MySQL数据库的存储引擎
目录 一、存储引擎概念 二、存储引擎 2.1MyISAM 2.11MyISAM的特点 2.12MyISAM表支持3种不同的存储格式: 2.2 InnoDB 2.21InnoDB特点介绍 三、InnoDB与MyISAM 区别 四、怎么样选择存储引擎 五、查看存储引擎 六、查看表使用的存储引擎 七、修改存储引擎 …...
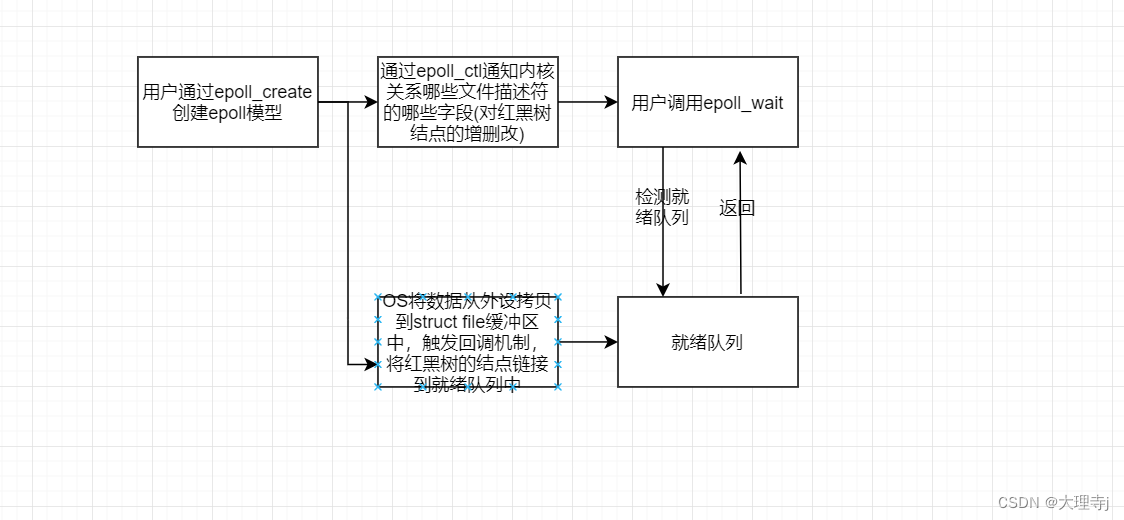
Linux-多路转接-epoll
epoll 接口认识epoll_createepoll_ctlepoll_wait epoll工作原理在内核中创建的数据结构epoll模型的一个完整工作流程 epoll工作模式LT-水平触发ET-边缘触发两种方式的对比 epoll的使用场景对于poll的改进惊群效应什么是惊群效应如何解决惊群效应原子操作/mutex/spinlock如何选择…...
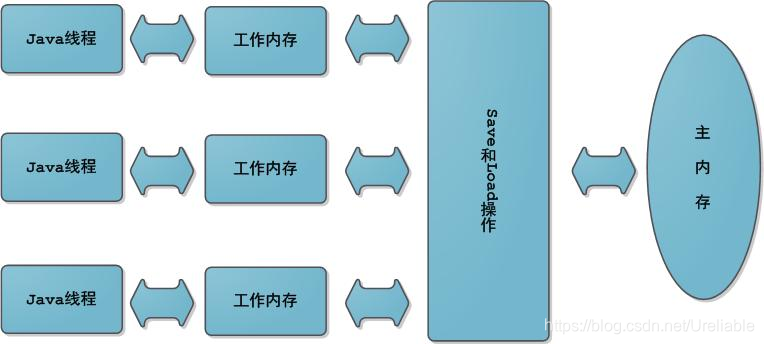
Java面试被问了几个简单的问题,却回答的不是很好
作者:逍遥Sean 简介:一个主修Java的Web网站\游戏服务器后端开发者 主页:https://blog.csdn.net/Ureliable 觉得博主文章不错的话,可以三连支持一下~ 如有需要我的支持,请私信或评论留言! 前言 前几天参加了…...

概率论几种易混淆的形式
正态分布标准型 x − μ σ \frac{x - \mu}{\sigma} σx−μ 大数定律形式 P { X ≤ ∑ i 1 n x i − n μ n σ 2 } ∫ − ∞ X 1 2 π e − x 2 2 d x P\{X \le \frac{\sum_{i 1}^{n}x_i -n\mu}{\sqrt{n\sigma^2}} \} \int _{-\infty}^{X}\frac{1}{\sqrt{2\pi}}e^{-\fr…...

PyTorch数据增强后的结果展示
from PIL import Image import torch from torchvision import transformstrans transforms.Compose([transforms.ToTensor(), transforms.RandomErasing(p0.9, value 120, inplaceTrue)]) # 这里Compose是所做的变换img_path 02-56-45-060-1454-camra1.bmp img Image.open…...

指定程序在哪个GPU上运行
摘要: 当本地(或服务器)有个多个GPU时,需要指定程序在指定GPU上运行,需要做以下设置。 目录 一、在终端上指定GPU二、在程序中指定GPU三、系统变量指定GPU四、pytorch中指定GPU 一、在终端上指定GPU 在终端运行程序时…...

Linux CentOS7 vim多文件编辑
使用vim编辑多个文件,十分常用的操作。本文从打开、显示、切换文件到退出,进行简单讨论。 一、打开文件 1.一次打开多个文件 vim还没有启动的时候,在终端里输入vim file1 file2 … filen便可以打开所有想要打开的文件。 执行命令 vim fil…...

PAT甲级真题1153: 解码PAT准考证
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...

linux信号
title: linux信号 createTime: 2020-10-29 18:05:52 updateTime: 2020-10-29 18:05:52 categories: linux tags: SIGHUP 终止进程 终端线路挂断[喝小酒的网摘]http://blog.hehehehehe.cn/a/16999.htm SIGINT 终止进程 中断进程 SIGQUIT 建立CORE文件终止进程,并且生…...

JavaWeb开发-05-SpringBootWeb请求响应
一.请求 1.Postman 2.简单参数 package com.wjh.controller;import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController;import javax.servlet.http.HttpServletRequest;/** 测试请求参数接受*/ R…...

Ubuntu下载
参考文档: 镜像文件:VMware下安装ubuntu 16.04(全步骤)_vmwaubuntu-16.04.4-desktop-amd64.iso_ST0new的博客-CSDN博客 vmware tools使用安装:VMware——VMware Tools的介绍及安装方法_William.csj的博客-CSDN博客 …...

Vue 的组件加载顺序和渲染顺序
1、结论先行 组件的加载顺序是自上而下的,也就是先加载父组件,再递归地加载其所有的子组件。 而组件渲染顺序是按照深度优先遍历的方式,也就是先渲染最深层的子组件,再依次向上渲染其父组件。 2、案例 下面是一个简单的示例代…...
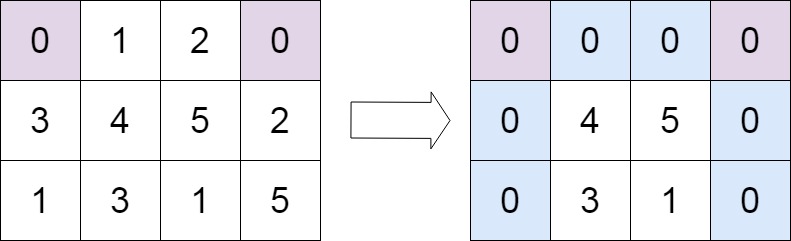
leetcode Top100(17)矩阵置零
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:matrix [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]]示例 2: 输入&…...
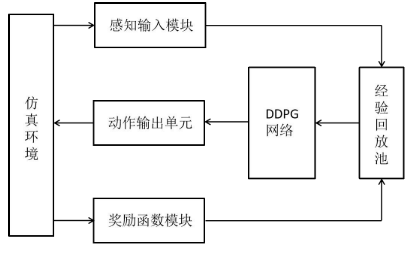
论文精读(2)—基于稀疏奖励强化学习的机械臂运动规划算法设计与实现(内含实现机器人控制的方法)
目录 1.作者提出的问题及解决方向 2.延深-用如何用强化学习对机器人进行控制 2.1思路 2.2DQN和DDPG在机器人控制中的应用 3.解决方案 3.1思路 3.2实验 3.3创新点 4.展望 1.作者提出的问题及解决方向 目的:使机械臂在非结构化环境下实现端到端的自主学习控制…...

快速安装keepalive
快速安装keepalive #安装 yum install keepalived -y# 查看版本: rpm -q -a keepalived#修改配置文件 vim /etc/keepalived.conf虚拟 ip :随意选一个,不被占用的ip即可。...
nginx实现反向代理实例
1 前言 1.1 演示内容 在服务器上访问nginx端口然后跳转到tomcat服务器 1.2 前提条件 前提条件:利用docker安装好nginx、tomcat、jdk8(tomcat运行需要jdk环境) 只演示docker安装tomcat: 默认拉取最新版tomcat docker pull t…...

使用Freemarker填充模板导出复杂Excel,其实很简单哒!
文章目录 1. 需求分析2. 对象生成3. 列表插值4. 另存xml格式化5. ftl修改6. 程序转化7. 犯的错误8. 总结 1. 需求分析 类似这样的一个表格 我们需要从数据库中查询对应的数据,将其汇总进该表格,并且可能还需要复制表格项,我这个案例中没有&a…...

windows环境下安装logstash同步数据,注册系统服务
windows环境下安装logstash同步数据,注册系统服务 此方法适用于Windows环境,同一个配置文件配置多个管道,并且配置系统服务,防止程序被杀进程 一、安装logstash (1)下载压缩包,解压后修改con…...

新手友好:借助快马平台从零复刻w777.7cc经典小游戏
作为一个刚接触编程的新手,最近在InsCode(快马)平台尝试复刻w777.7cc经典小游戏时,发现整个过程比想象中简单许多。这种翻牌匹配类游戏规则明确、交互直观,特别适合用来理解前端三件套(HTML/CSS/JavaScript)的协作逻辑…...

3步解决会议记录难题:给职场人士的离线语音转文字工具
3步解决会议记录难题:给职场人士的离线语音转文字工具 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 发现问题:为什么会议记录总是让人头疼? 你是否经历过这样的场景࿱…...
)
紧急预警:C++27 std::filesystem::copy_options::recursive_nowait 已被证实引发静默截断!附官方补丁+3行兼容封装方案(2025 Q2前必读)
第一章:C27 文件系统库扩展应用C27 标准对 <filesystem> 库进行了实质性增强,新增了异步路径遍历、符号链接元数据深度解析、跨设备硬链接原子创建以及基于策略的路径规范化接口。这些特性显著提升了在复杂存储拓扑(如容器挂载点、分布…...

从相位差到厘米级精度:深入解析蓝牙6.0 CS中PBR公式的推导与验证
1. 蓝牙6.0 CS技术中的相位测距原理 蓝牙6.0引入的信道探测(CS)功能将定位精度提升到了厘米级,这主要得益于其采用的相位测距法(PBR)。想象一下,这就像用无线电波玩"激光测距",只不过我们用的是相位差而不是光脉冲。在实际操作中&a…...

G-Helper终极解决方案:华硕笔记本风扇与性能问题完全指南
G-Helper终极解决方案:华硕笔记本风扇与性能问题完全指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix,…...

YOLOFuse效果惊艳:红外热成像+可见光,极端环境下的检测利器
YOLOFuse效果惊艳:红外热成像可见光,极端环境下的检测利器 1. 多模态检测的技术突破 在智能安防、自动驾驶和工业检测等关键领域,视觉系统常常面临极端环境的挑战:漆黑的夜晚、弥漫的烟雾、刺眼的强光...传统基于RGB图像的目标检…...

小米笔记本Hackintosh无线网卡终极解决方案:Intel Wi-Fi驱动 vs 更换模块
小米笔记本Hackintosh无线网卡终极解决方案:Intel Wi-Fi驱动 vs 更换模块 【免费下载链接】XiaoMi-Pro-Hackintosh XiaoMi NoteBook Pro Hackintosh 项目地址: https://gitcode.com/gh_mirrors/xia/XiaoMi-Pro-Hackintosh 想要在小米笔记本上完美运行macOS系…...

终极Fuel测试指南:使用MockWebServer编写可靠的Kotlin网络测试
终极Fuel测试指南:使用MockWebServer编写可靠的Kotlin网络测试 【免费下载链接】fuel The easiest HTTP networking library for Kotlin/Android 项目地址: https://gitcode.com/gh_mirrors/fu/fuel Fuel是Kotlin平台最简单易用的HTTP网络库,专为…...

seo泛站群的合法性问题如何避免_seo泛站群的运营团队应该怎样组建
SEO泛站群的合法性问题如何避免 在当前的互联网市场中,SEO(搜索引擎优化)是一个重要的营销手段,其中泛站群(SEO泛站群)作为一种策略被广泛使用。泛站群的合法性问题和操作风险也随之而来。本文将深入探讨如…...

AI伦理测试:当算法可能产生偏见时
随着人工智能技术从实验室走向规模化应用,算法决策已深度渗透至招聘、信贷、医疗、司法、内容推荐等关乎社会公平与个人福祉的关键领域。对软件测试从业者而言,一个全新的、紧迫的挑战正摆在面前:传统的功能、性能、安全测试已不足以确保AI产…...