《动手学深度学习 Pytorch版》 7.1 深度卷积神经网络(AlexNet)
7.1.1 学习表征
深度卷积神经网络的突破出现在2012年。突破可归因于以下两个关键因素:
- 缺少的成分:数据
数据集紧缺的情况在 2010 年前后兴起的大数据浪潮中得到改善。ImageNet 挑战赛中,ImageNet数据集由斯坦福大学教授李飞飞小组的研究人员开发,利用谷歌图像搜索对分类图片进行预筛选,并利用亚马逊众包标注每张图片的类别。这种数据规模是前所未有的。 - 缺少的成分:硬件
2012年,Alex Krizhevsky和Ilya Sutskever使用两个显存为3GB的NVIDIA GTX580 GPU实现了快速卷积运算,推动了深度学习热潮。
7.1.2 AlexNet
2012年横空出世的 AlexNet 首次证明了学习到的特征可以超越手动设计的特征。
AlexNet 和 LeNet 的架构非常相似(此书对模型稍微精简了一下,取出来需要两个小GPU同时运算的设计特点):
| 全连接层(1000) |
|---|
↑ \uparrow ↑
| 全连接层(4096) |
|---|
↑ \uparrow ↑
| 全连接层(4096) |
|---|
↑ \uparrow ↑
| 3 × 3 3\times3 3×3最大汇聚层,步幅2 |
|---|
↑ \uparrow ↑
| 3 × 3 3\times3 3×3卷积层(384),填充1 |
|---|
↑ \uparrow ↑
| 3 × 3 3\times3 3×3卷积层(384),填充1 |
|---|
↑ \uparrow ↑
| 3 × 3 3\times3 3×3卷积层(384),填充1 |
|---|
↑ \uparrow ↑
| 3 × 3 3\times3 3×3最大汇聚层,步幅2 |
|---|
↑ \uparrow ↑
| 5 × 5 5\times5 5×5卷积层(256),填充2 |
|---|
↑ \uparrow ↑
| 3 × 3 3\times3 3×3最大汇聚层,步幅2 |
|---|
↑ \uparrow ↑
| 11 × 11 11\times11 11×11卷积层(96),步幅4 |
|---|
↑ \uparrow ↑
| 输入图像( 3 × 224 × 224 3\times224\times224 3×224×224) |
|---|
AlexNet 和 LeNet 的差异:
- AlexNet 比 LeNet 深的多
- AlexNet 使用 ReLU 而非 sigmoid 作为激活函数
以下为 AlexNet 的细节。
-
模型设计
由于 ImageNet 中的图像大多较大,因此第一层采用了 11 × 11 11\times11 11×11 的超大卷积核。后续再一步一步缩减到 3 × 3 3\times3 3×3。而且 AlexNet 的卷积通道数是 LeNet 的十倍。
最后两个巨大的全连接层分别各有4096个输出,近 1G 的模型参数。因早期 GPU 显存有限,原始的 AlexNet 采取了双数据流设计。
-
激活函数
ReLU 激活函数是训练模型更加容易。它在正区间的梯度总为1,而 sigmoid 函数可能在正区间内得到几乎为 0 的梯度。
-
容量控制和预处理
AlexNet 通过暂退法控制全连接层的复杂度。此外,为了扩充数据,AlexNet 在训练时增加了大量的图像增强数据(如翻转、裁切和变色),这也使得模型更健壮,并减少了过拟合。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(# 这里使用一个11*11的更大窗口来捕捉对象。# 同时,步幅为4,以减少输出的高度和宽度。# 另外,输出通道的数目远大于LeNetnn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 使用三个连续的卷积层和较小的卷积窗口。# 除了最后的卷积层,输出通道的数量进一步增加。# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000nn.Linear(4096, 10))
X = torch.randn(1, 1, 224, 224)
for layer in net:X=layer(X)print(layer.__class__.__name__,'output shape:\t',X.shape)
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
7.1.3 读取数据集
如果真用 ImageNet 训练,即使是现在的 GPU 也需要数小时或数天的时间。在此仅作演示,仍使用 Fashion-MNIST 数据集,故在此需要解决图像分辨率的问题。
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
7.1.4 训练 AlexNet
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu()) # 大约需要二十分钟,慎跑
loss 0.330, train acc 0.879, test acc 0.878
592.4 examples/sec on cuda:0

练习
(1)尝试增加轮数。对比 LeNet 的结果有什么不同?为什么?
lr, num_epochs = 0.01, 15
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu()) # 大约需要三十分钟,慎跑
loss 0.284, train acc 0.896, test acc 0.887
589.3 examples/sec on cuda:0

相较于 LeNet 的增加轮次反而导致精度下降,AlexNet 具有更好的抗过拟合能力,增加轮次精度就会上升。
(2) AlexNet 模型对 Fashion-MNIST 可能太复杂了。
a. 尝试简化模型以加快训练速度,同时确保准确性不会显著下降。b. 设计一个更好的模型,可以直接在 $28\times28$ 像素的图像上工作。
net_Better = nn.Sequential(nn.Conv2d(1, 64, kernel_size=5, stride=2, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=1),nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(128, 64, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(64 * 5 * 5, 1024), nn.ReLU(),nn.Dropout(p=0.3), nn.Linear(1024, 512), nn.ReLU(),nn.Dropout(p=0.3),nn.Linear(512, 10)
)X = torch.randn(1, 1, 28, 28)
for layer in net_Better:X=layer(X)print(layer.__class__.__name__,'output shape:\t',X.shape)
Conv2d output shape: torch.Size([1, 64, 14, 14])
ReLU output shape: torch.Size([1, 64, 14, 14])
MaxPool2d output shape: torch.Size([1, 64, 12, 12])
Conv2d output shape: torch.Size([1, 128, 12, 12])
ReLU output shape: torch.Size([1, 128, 12, 12])
Conv2d output shape: torch.Size([1, 128, 12, 12])
ReLU output shape: torch.Size([1, 128, 12, 12])
Conv2d output shape: torch.Size([1, 64, 12, 12])
ReLU output shape: torch.Size([1, 64, 12, 12])
MaxPool2d output shape: torch.Size([1, 64, 5, 5])
Flatten output shape: torch.Size([1, 1600])
Linear output shape: torch.Size([1, 1024])
ReLU output shape: torch.Size([1, 1024])
Dropout output shape: torch.Size([1, 1024])
Linear output shape: torch.Size([1, 512])
ReLU output shape: torch.Size([1, 512])
Dropout output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
batch_size = 128
train_iter28, test_iter28 = d2l.load_data_fashion_mnist(batch_size=batch_size)
lr, num_epochs = 0.01, 10
d2l.train_ch6(net_Better, train_iter28, test_iter28, num_epochs, lr, d2l.try_gpu()) # 快多了
loss 0.429, train acc 0.841, test acc 0.843
6650.9 examples/sec on cuda:0

(3)修改批量大小,并观察模型精度和GPU显存变化。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu()) # 大约需要二十分钟,慎跑
loss 0.407, train acc 0.850, test acc 0.855
587.8 examples/sec on cuda:0

4G 显存基本拉满,精度略微下降,过拟合貌似严重了。
(4)分析 AlexNet 的计算性能。
a. 在 AlexNet 中主要是哪一部分占用显存?b. 在AlexNet中主要是哪部分需要更多的计算?c. 计算结果时显存带宽如何?
a. 第一个全连接层占用显存最多
b. 倒数第二个卷积层需要更多的计算
(5)将dropout和ReLU应用于LeNet-5,效果有提升吗?再试试预处理会怎么样?
net_try = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.ReLU(),nn.Dropout(p=0.2), nn.Linear(120, 84), nn.ReLU(),nn.Dropout(p=0.2), nn.Linear(84, 10))lr, num_epochs = 0.6, 10
d2l.train_ch6(net_try, train_iter28, test_iter28, num_epochs, lr, d2l.try_gpu()) # 浅调一下还挺好
loss 0.306, train acc 0.887, test acc 0.883
26121.2 examples/sec on cuda:0

浅浅调一下,效果挺好,精度有所提升。
相关文章:
《动手学深度学习 Pytorch版》 7.1 深度卷积神经网络(AlexNet)
7.1.1 学习表征 深度卷积神经网络的突破出现在2012年。突破可归因于以下两个关键因素: 缺少的成分:数据 数据集紧缺的情况在 2010 年前后兴起的大数据浪潮中得到改善。ImageNet 挑战赛中,ImageNet数据集由斯坦福大学教授李飞飞小组的研究人…...
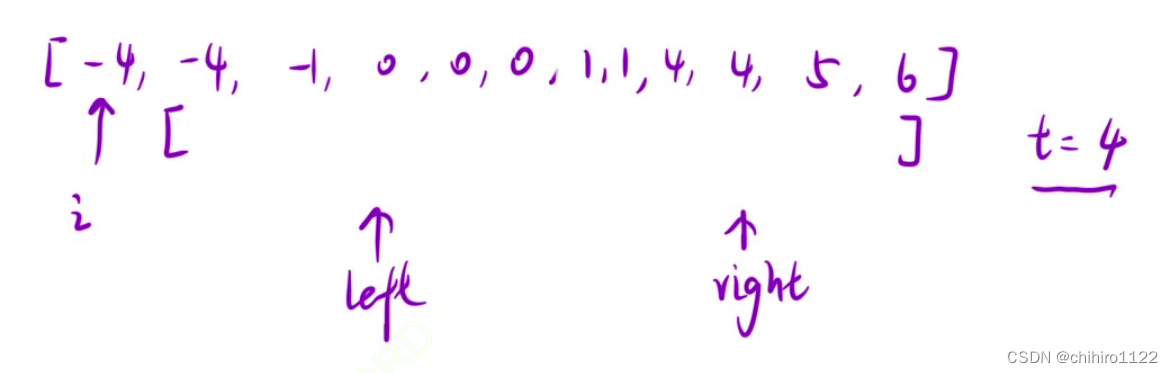
C++ - 双指针_盛水最多的容器
盛水最多的容器 11. 盛最多水的容器 - 力扣(LeetCode) 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的…...

分类预测 | Matlab实现NGO-CNN-SVM北方苍鹰算法优化卷积支持向量机分类预测
分类预测 | Matlab实现NGO-CNN-SVM北方苍鹰算法优化卷积支持向量机分类预测 目录 分类预测 | Matlab实现NGO-CNN-SVM北方苍鹰算法优化卷积支持向量机分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现NGO-CNN-SVM北方苍鹰算法优化卷积支持向量机分类预…...

分享一个java+springboot+vue校园电动车租赁系统(源码、调试、开题、lw)
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! 💕&…...
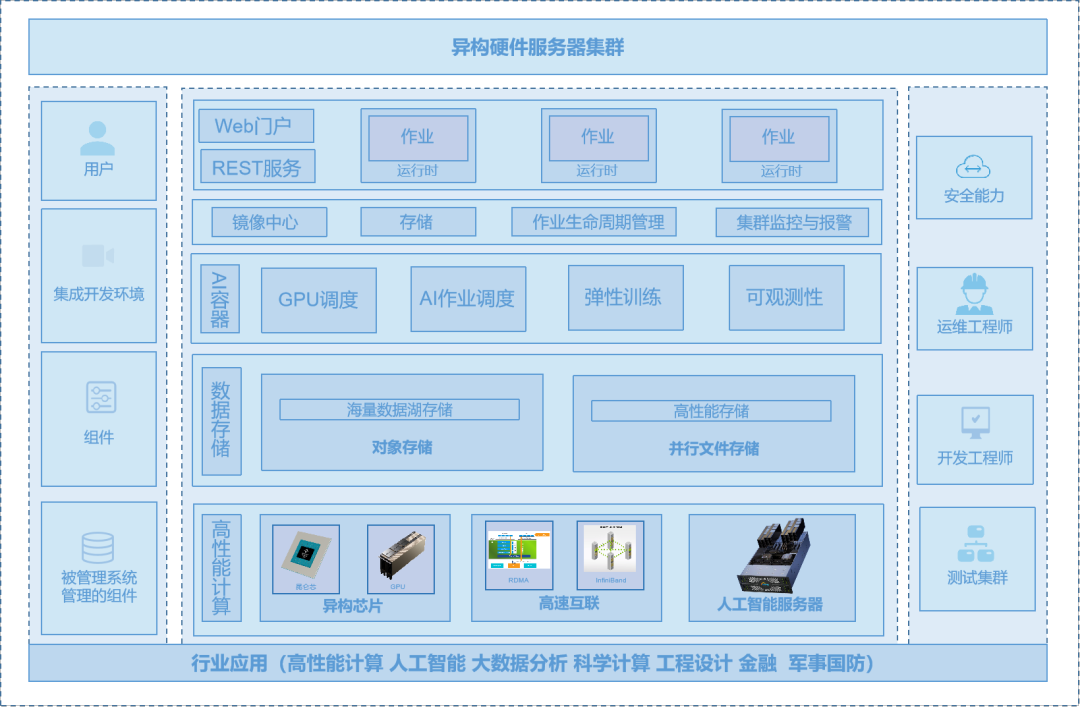
高性能计算环境下的深度学习异构集群建设与优化实践
★深度学习;模式识别;图像处理;人工智能建模;人工智能;深度学习算法;强化学习;神经网络;卷积神经网络;人工神经网络;VIBE算法;控制系统仿真&#…...

Laravel框架 - Facade门面
1 、官方文档给出的定义 “Facades 为应用的 服务容器 提供了一个「静态」 接口。Laravel 自带了很多 Facades,可以访问绝大部分功能。Laravel Facades 实际是服务容器中底层类的 「静态代理」 ,相对于传统静态方法,在使用时能够提供更加灵活…...

算法通关村第16关【青铜】| 滑动窗口思想
1. 滑动窗口的基本思想 一句话概括就是两个快慢指针维护的一个会移动的区间 固定大小窗口:求哪个窗口元素最大、最小、平均值、和最大、和最小 可变大小窗口:求一个序列里最大、最小窗口是什么 2. 两个入门题 (1)子数组最大平…...

CentOS安装openjdk和elasticsearch
CentOS安装openjdk 文章目录 CentOS安装openjdk一、yum1.1search1.2安装openjdk 二、elasticsearch的启动和关闭2.1启动2.2关闭2.3添加服务 一、yum 1.1search yum search java | grep jdk1.2安装openjdk [roottest ~]# yum install java-1.8.0-openjdk -y 查看openjdk版本 …...

【新版】系统架构设计师 - 案例分析 - 信息安全
个人总结,仅供参考,欢迎加好友一起讨论 文章目录 架构 - 案例分析 - 信息安全安全架构安全模型分类BLP模型Biba模型Chinese Wall模型 信息安全整体架构设计WPDRRC模型各模型安全防范功能 网络安全体系架构设计开放系统互联安全体系结构安全服务与安全机制…...
)
数据库设计(火车订票系统)
为一个火车订票系统设计一个数据库是一个好的方法来训练你的数据库技巧。 其中有一些需要考虑到的复杂度。 过一些需求,并且创建表格。 为这个虚构的火车订票系统提出了10个需求。 我们将把其中每个添加到entity relational diagram(实体关系图&…...

qemu+docker在服务器上搭建linux内核调试环境
基于docker和qemu的操作系统实验环境 参考以上文章实现。 其中 docker run -it --name linux_qemu qemu /bin/bash #从qemu镜像启动一个容器linux_qemu,进入shell 要改为 docker run -it --name linux_qemu 3292900173/qemu /bin/bash另外,在vscode运行过程中,ssh远…...

Stable Diffusion 参数介绍及用法
大模型 CheckPoint 介绍 作用:定调了作图风格,可以理解为指挥者 安装路径:models/Stable-diffusion 推荐: AnythingV5Ink_v32Ink.safetensors cuteyukimixAdorable_midchapter2.safetensors manmaruMix_v10.safetensors counterf…...

打印大对象日志导致GC问题的解决
内容: rpc调用外部服务时,需要将req和resp的信息打印出来,以便于排查问题。但是有的rpc服务的resp信息过于庞大,比如resp中有List<>信息,list很大很大时会导致log.info打印信息时,产生GC,…...

【Docker】学习笔记
1. docker基本操作 镜像搜索 // 直接搜索镜像资源 docker search mysql // 搜索过滤 docker search --filter "is-officialtrue" mysql // 官方发布镜像拉取镜像 docker pull mysql查看本地镜像 docker images删除本地镜像 docker rmi mysql // 强制删除镜像 d…...

网易云信4K 8K RTC助力远程医疗的技术实践
// 编者按:随着近年来国家关于缓解医疗资源分配不均的一系列政策出台,远程医疗作为平衡医疗资源分配的有力手段,目前正处于强劲发展阶段。网易云信运用超高清RTC视频技术助力医疗行业实现了远程高清视频病理分析和手术示教等能力。LiveVide…...
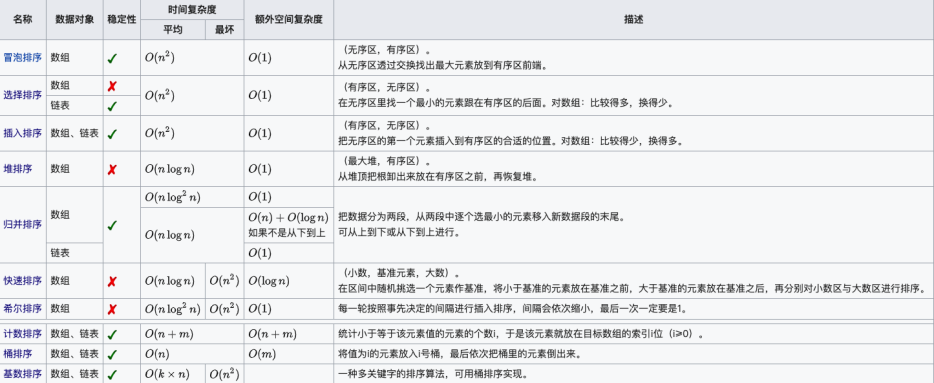
【排序算法】冒泡排序、插入排序、归并排序、希尔排序、选择排序、堆排序、快速排序
目录 几大排序汇总 1.冒泡排序 性能: 思路和代码: 2.插入排序 性能: 思路和代码: 3.归并排序 性能: 思路和代码: 4.希尔排序 性能: 思路和代码: 5.选择排序 性能: 思路和代码: 6.堆排序 性能: 思路和代码: topK问题 7.快速排序 性能: 思路和代码: 几大排…...

Linux学习笔记-应用层篇
1、Linux进程、线程概念/区别 Linux进程和线程是计算机系统中两种不同的资源分配和调度单位。 进程是计算机系统进行资源分配和调度的基本单位,也被认为是正在运行的程序。在面向线程的计算机结构中,进程是线程的容器。进程拥有独立的内存和系统资源&am…...

MySQL数据库的存储引擎
目录 一、存储引擎概念 二、存储引擎 2.1MyISAM 2.11MyISAM的特点 2.12MyISAM表支持3种不同的存储格式: 2.2 InnoDB 2.21InnoDB特点介绍 三、InnoDB与MyISAM 区别 四、怎么样选择存储引擎 五、查看存储引擎 六、查看表使用的存储引擎 七、修改存储引擎 …...
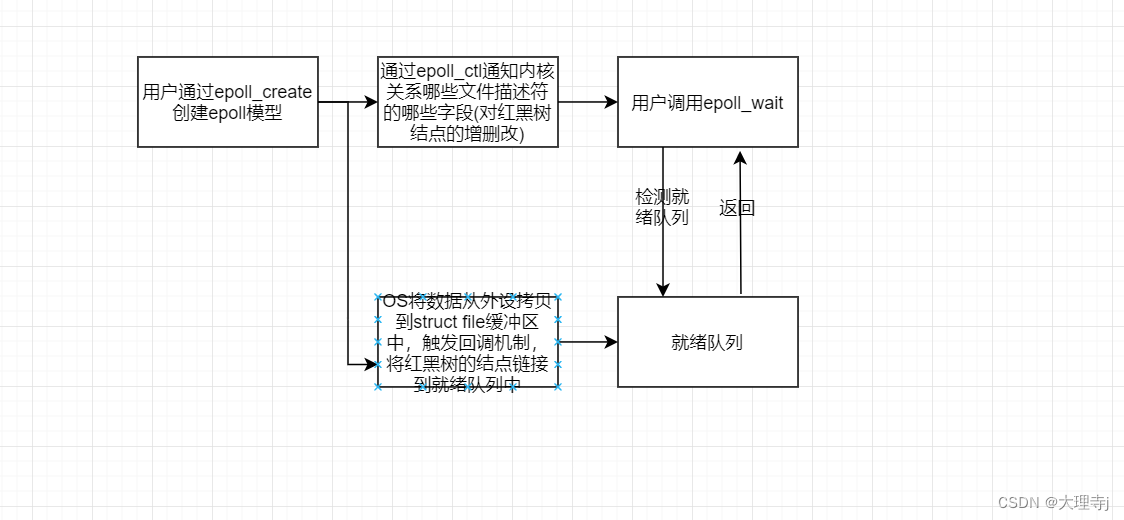
Linux-多路转接-epoll
epoll 接口认识epoll_createepoll_ctlepoll_wait epoll工作原理在内核中创建的数据结构epoll模型的一个完整工作流程 epoll工作模式LT-水平触发ET-边缘触发两种方式的对比 epoll的使用场景对于poll的改进惊群效应什么是惊群效应如何解决惊群效应原子操作/mutex/spinlock如何选择…...
Java面试被问了几个简单的问题,却回答的不是很好
作者:逍遥Sean 简介:一个主修Java的Web网站\游戏服务器后端开发者 主页:https://blog.csdn.net/Ureliable 觉得博主文章不错的话,可以三连支持一下~ 如有需要我的支持,请私信或评论留言! 前言 前几天参加了…...

Cursor AI破解免费VIP 2025终极完整教程:如何绕过试用限制享受Pro功能
Cursor AI破解免费VIP 2025终极完整教程:如何绕过试用限制享受Pro功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve r…...

Stegosuite使用教程
Stegosuite 是一款专注于隐写术的跨平台工具,能够在不改变图像外观的前提下,将秘密数据(文本、文件等)隐藏在图像中。与加密技术不同,隐写术的核心是”隐藏信息的存在”,让第三方难以察觉数据传输的发生。主…...

使用 Dify 快速搭建 Ostrakon-VL 智能应用:无需编码的视觉工作流
使用 Dify 快速搭建 Ostrakon-VL 智能应用:无需编码的视觉工作流 1. 引言:当视觉理解遇上无代码开发 想象一下,你是一家电商公司的运营人员,每天需要处理上千张商品图片——识别商品类别、提取关键属性、整理成表格。传统方式要…...

解密MyBatis拦截器:从插件机制到实战应用
1. MyBatis拦截器基础入门 第一次接触MyBatis拦截器时,我完全被它强大的功能震撼到了。简单来说,拦截器就像是在MyBatis执行SQL过程中的"关卡",可以在特定时机插入自定义逻辑。想象一下,你正在通过一条高速公路…...

SGLang-v0.5.6备份策略详解:零基础学会模型状态保存与恢复
SGLang-v0.5.6备份策略详解:零基础学会模型状态保存与恢复 1. 引言 想象一下,你正在和一个AI助手进行一场长达半小时的深度对话,从技术讨论到方案规划,聊得非常投入。突然,服务器需要重启升级,或者程序意…...

用快马ai快速构建你的第一个endnote式文献管理原型
最近在写论文时,突然意识到需要个简单的文献管理工具。虽然EndNote这类专业软件功能强大,但对于快速记录和引用参考文献来说,有时候只需要一个轻量级的解决方案。于是我在InsCode(快马)平台上尝试用HTML、CSS和JavaScript快速搭建了一个原型&…...

新手友好:借助快马AI生成代码,零基础入门谷歌浏览器扩展开发
最近想尝试开发一个简单的谷歌浏览器扩展,但作为新手完全不知道从何入手。经过一番摸索,我发现用InsCode(快马)平台可以快速生成可运行的示例代码,特别适合零基础学习。下面记录下我的学习过程,希望能帮到同样想入门浏览器扩展开发…...

Wan2.2-TI2V-5B:消费级GPU上的720P视频生成革命
Wan2.2-TI2V-5B:消费级GPU上的720P视频生成革命 【免费下载链接】Wan2.2-TI2V-5B Wan2.2-TI2V-5B是一款开源的先进视频生成模型,基于创新的混合专家架构(MoE)设计,显著提升了视频生成的质量与效率。该模型支持文本生成…...

Python flask django框架的医疗问诊拿药系统
目录同行可拿货,招校园代理 ,本人源头供货商功能分析:基于Flask/Django的医疗问诊拿药系统核心模块划分技术实现要点数据安全与合规扩展性设计项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 …...

PlatformIO+ESP32S3:像素时钟的硬件优化与实战解析
1. 从零开始:像素时钟的硬件架构解析 第一次接触ESP32S3开发像素时钟时,我完全低估了硬件设计的复杂度。这个看似简单的项目实际上涉及电源管理、实时时钟、LED驱动等多个子系统的协同工作。让我用最直白的语言拆解这个硬件拼图:核心就像搭积…...