pytorch迁移学习训练图像分类
pytorch迁移学习训练图像分类
- 一、环境配置
- 二、迁移学习关键代码
- 三、完整代码
- 四、结果对比
代码和图片等资源均来源于哔哩哔哩up主:同济子豪兄
讲解视频:Pytorch迁移学习训练自己的图像分类模型
一、环境配置
1,安装所需的包
pip install numpy pandas matplotlib seaborn plotly requests tqdm opencv-python pillow wandb -i https://pypi.tuna.tsinghua.edu.cn/simple
2,安装Pytorch
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
3,创建目录
import os
# 存放训练得到的模型权重
os.mkdir('checkpoint')
4,下载数据集压缩包(下载之后需要解压数据集)
wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/fruit30/fruit30_split.zip
二、迁移学习关键代码
以下是迁移学习的三种选择,根据训练的需求选择不同的迁移方法:
- 选择一:只微调训练模型最后一层(全连接分类层)
model = models.resnet18(pretrained=True) # 载入预训练模型
# 修改全连接层,使得全连接层的输出与 当前数据集类别数n_class 对应
model.fc = nn.Linear(model.fc.in_features, n_class)
# 只微调训练最后一层全连接层的参数,其它层冻结
optimizer = optim.Adam(model.fc.parameters())
- 选择二:微调训练所有层。
适用于训练数据集与预训练模型相差大时,可以选择微调训练所有层,此时只使用预训练模型的部分权重和特征,例如原始模型为imageNet,而训练数据为医疗相关
model = models.resnet18(pretrained=True) # 载入预训练模型
model.fc = nn.Linear(model.fc.in_features, n_class)
optimizer = optim.Adam(model.parameters())
- 选择三:随机初始化模型全部权重,从头训练所有层
model = models.resnet18(pretrained=False) # 只载入模型结构,不载入预训练权重参数
model.fc = nn.Linear(model.fc.in_features, n_class)
optimizer = optim.Adam(model.parameters())
三、完整代码
import time
import osimport numpy as np
from tqdm import tqdmimport torch
import torchvision
import torch.nn as nn# 忽略出现的红色提示
import warnings
warnings.filterwarnings("ignore")# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)from torchvision import transforms# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 数据集文件夹路径
dataset_dir = 'fruit30_split'
train_path = os.path.join(dataset_dir, 'train') # 测试集路径
test_path = os.path.join(dataset_dir, 'val') # 测试集路径from torchvision import datasets# 载入训练集
train_dataset = datasets.ImageFolder(train_path, train_transform)# 载入测试集
test_dataset = datasets.ImageFolder(test_path, test_transform)# 各类别名称
class_names = train_dataset.classes
n_class = len(class_names)# 定义数据加载器DataLoader
from torch.utils.data import DataLoaderBATCH_SIZE = 32# 训练集的数据加载器
train_loader = DataLoader(train_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=4)# 测试集的数据加载器
test_loader = DataLoader(test_dataset,batch_size=BATCH_SIZE,shuffle=False,num_workers=4)from torchvision import models
import torch.optim as optim# 选择一:只微调训练模型最后一层(全连接分类层)
model = models.resnet18(pretrained=True) # 载入预训练模型
# 修改全连接层,使得全连接层的输出与当前数据集类别数对应
# 新建的层默认 requires_grad=True,指定张量需要梯度计算
model.fc = nn.Linear(model.fc.in_features, n_class)
model.fc # 查看全连接层
# 只微调训练最后一层全连接层的参数,其它层冻结
optimizer = optim.Adam(model.fc.parameters()) # optim 是 PyTorch 的一个优化器模块,用于实现各种梯度下降算法的优化方法# 选择二:微调训练所有层
# 训练数据集与预训练模型相差大时,可以选择微调训练所有层,只使用预训练模型的部分权重和特征,例如原始模型为imageNet,训练数据为医疗相关
# model = models.resnet18(pretrained=True) # 载入预训练模型
# model.fc = nn.Linear(model.fc.in_features, n_class)
# optimizer = optim.Adam(model.parameters())# 选择三:随机初始化模型全部权重,从头训练所有层
# model = models.resnet18(pretrained=False) # 只载入模型结构,不载入预训练权重参数
# model.fc = nn.Linear(model.fc.in_features, n_class)
# optimizer = optim.Adam(model.parameters())# 训练配置
model = model.to(device)# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 训练轮次 Epoch
EPOCHS = 30# 遍历每个 EPOCH
for epoch in tqdm(range(EPOCHS)):model.train()for images, labels in train_loader: # 获取训练集的一个 batch,包含数据和标注images = images.to(device)labels = labels.to(device)outputs = model(images) # 前向预测,获得当前 batch 的预测结果loss = criterion(outputs, labels) # 比较预测结果和标注,计算当前 batch 的交叉熵损失函数optimizer.zero_grad()loss.backward() # 损失函数对神经网络权重反向传播求梯度optimizer.step() # 优化更新神经网络权重# 测试集上初步测试
model.eval()
with torch.no_grad():correct = 0total = 0for images, labels in tqdm(test_loader): # 获取测试集的一个 batch,包含数据和标注images = images.to(device)labels = labels.to(device)outputs = model(images) # 前向预测,获得当前 batch 的预测置信度_, preds = torch.max(outputs, 1) # 获得最大置信度对应的类别,作为预测结果total += labels.size(0)correct += (preds == labels).sum() # 预测正确样本个数print('测试集上的准确率为 {:.3f} %'.format(100 * correct / total))# 保存模型
torch.save(model, 'checkpoint/fruit30_pytorch_A1.pth') # 选择一:微调全连接层
# torch.save(model, 'checkpoint/fruit30_pytorch_A2.pth') # 选择二:微调所有层
# torch.save(model, 'checkpoint/fruit30_pytorch_A3.pth') # 选择三:随机权重
四、结果对比
调用不同迁移学习得到的模型对比测试集准确率
# 测试集导入和图像预处理等代码和上述完整代码中一致,此处省略……# 调用自己训练的模型
model = torch.load('checkpoint/fruit30_pytorch_A1.pth')# 测试集上进行测试
model.eval()
with torch.no_grad():correct = 0total = 0for images, labels in tqdm(test_loader): # 获取测试集的一个 batch,包含数据和标注images = images.to(device)labels = labels.to(device)outputs = model(images) # 前向预测,获得当前 batch 的预测置信度_, preds = torch.max(outputs, 1) # 获得最大置信度对应的类别,作为预测结果total += labels.size(0)correct += (preds == labels).sum() # 预测正确样本个数print('测试集上的准确率为 {:.3f} %'.format(100 * correct / total))
结果如下:
对于微调全连接层的选择一,测试集准确率为 72.078%

而所有权重随机的选择三测试集准确率为 43.228%

总体而言,迁移学习能够利用已有的知识和经验,加速模型的训练过程,提高模型的性能。
相关文章:
pytorch迁移学习训练图像分类
pytorch迁移学习训练图像分类 一、环境配置二、迁移学习关键代码三、完整代码四、结果对比 代码和图片等资源均来源于哔哩哔哩up主:同济子豪兄 讲解视频:Pytorch迁移学习训练自己的图像分类模型 一、环境配置 1,安装所需的包 pip install …...
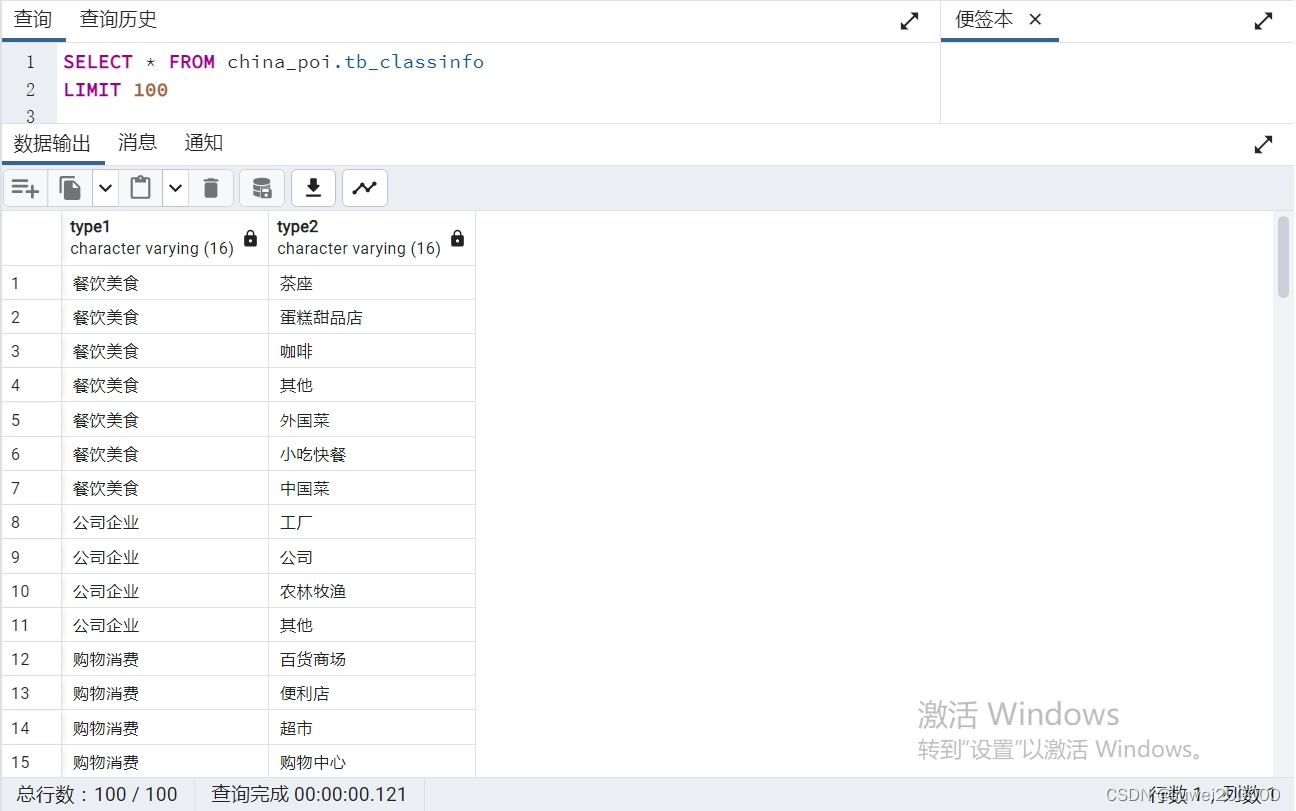
SQL 如何提取多级分类目录
前言 POI数据处理,原始数据为csv格式,整理入库至PostGreSQL,本例使用PostGreSQL13版本。 一、POI POI(一般作为Point of Interest的缩写,也有Point of Information的说法),通常称作兴趣点&am…...
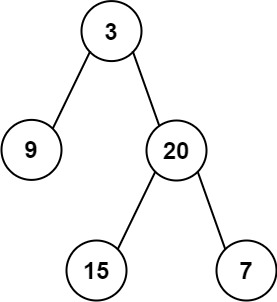
从中序遍历和后序遍历构建二叉树
题目描述 106. 从中序与后序遍历序列构造二叉树 中等 1.1K 相关企业 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入࿱…...

《计算机视觉中的多视图几何》笔记(11)
11 Computation of the Fundamental Matrix F F F 本章讲述如何用数值方法在已知若干对应点的情况下求解基本矩阵 F F F。 文章目录 11 Computation of the Fundamental Matrix F F F11.1 Basic equations11.1.1 The singularity constraint11.1.2 The minimum case – sev…...
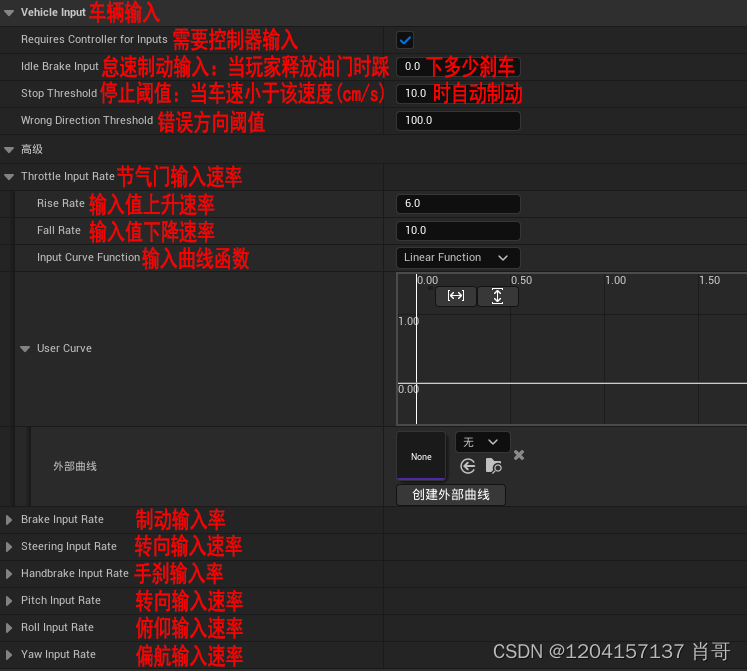
UE5 ChaosVehicles载具研究
一、基本组成 载具Actor类名称:WheeledVehiclePawn Actor最原始的结构 官方增加了两个摇臂相机,可以像驾驶游戏那样切换多机位、旋转观察 选择骨骼网格体、动画蓝图类、开启物理模拟 二、SportsCar_Pawn 角阻尼:物体旋转的阻力。数值越大…...
数据通信——应用层(域名系统)
引言 TCP到此就告一段落,这也意味着传输层结束了,紧随其后的就是TCP/IP五层架构的应用层。操作系统、编程语言、用户的可视化界面等等都要通过应用层来体现。应用层和我们息息相关,我们使用电子设备娱乐或办公时,接触到的就是应用…...

Visual Studio 更新:远程文件管理器
Visual Studio 中的远程文件管理器可以用来访问远程机器上的文件和文件夹,通过 Visual Studio 自带的连接管理器,可以实现不离开开发环境直接访问远程系统,这确实十分方便。 自从此功能发布以来,VS 开发团队努力工作,…...
ChatGPT追祖寻宗:GPT-3技术报告要点解读
论文地址:Language Models are Few-Shot Learners 往期相关文章: ChatGPT追祖寻宗:GPT-1论文要点解读_五点钟科技的博客-CSDN博客ChatGPT追祖寻宗:GPT-2论文要点解读_五点钟科技的博客-CSDN博客 本文的标题之所以取名技术报告而不…...

java easyexcel 导出多级表头
maven <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>${easyexcel.version}</version> </dependency> 导出行的对象 import com.alibaba.excel.annotation.ExcelIgnore; import …...

rar格式转换zip格式,如何做?
平时大家压缩文件时对压缩包格式可能没有什么要求,但是,可能因为工作需要,我们要将压缩包格式进行转换,那么我们如何将rar格式转换为其他格式呢?方法如下: 工具:WinRAR 打开WinRAR,…...

Java中的构造方法
在Java中,构造方法是类的特殊方法,用于初始化对象的实例变量和执行其他必要的操作,以便使对象能够正确地工作。构造方法与类同名,没有返回类型,并且在创建对象时自动调用。 以下是构造方法的一些基本特性:…...

【Java】fastjson
Fastjson简介 Fastjson是阿里巴巴的团队开发的一款Java语言实现的JSON解析器和生成器,它具有简单易用、高性能、高可用性等优点,适用于Java开发中的数据解析和生成。Fastjson的主要特点包括: 简单易用:Fastjson提供了简单易用的…...
JMeter之脚本录制
【软件测试面试突击班】如何逼自己一周刷完软件测试八股文教程,刷完面试就稳了,你也可以当高薪软件测试工程师(自动化测试) 前言: 对于一些JMeter初学者来说,录制脚本可能是最容易掌握的技能之一。…...

计算机网络的相关知识点总结
1.谈一谈对OSI七层模型和TCP/IP四层模型的理解? 不管是OSI七层模型亦或是TCP/IP四层模型,它们的提出都有一个共同的目的:通过分层来将复杂问题细化,通过各个层级之间的相互配合来更好的解决计算机中出现的问题。 说到分层…...

WPF实现轮播图(图片、视屏)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
【Vue.js】使用Element搭建首页导航左侧菜单
目录 Mock.js 是什么 有什么好处 安装mockjs 编辑 引入mockjs mockjs使用 login-mock Bus事物总线 首页导航栏与左侧菜单搭建 结合总线完成组件通讯 Mock.js 是什么 Mock.js是一个用于生成随机数据的模拟数据生成器。它可以帮助开发人员模拟接口请求,生…...
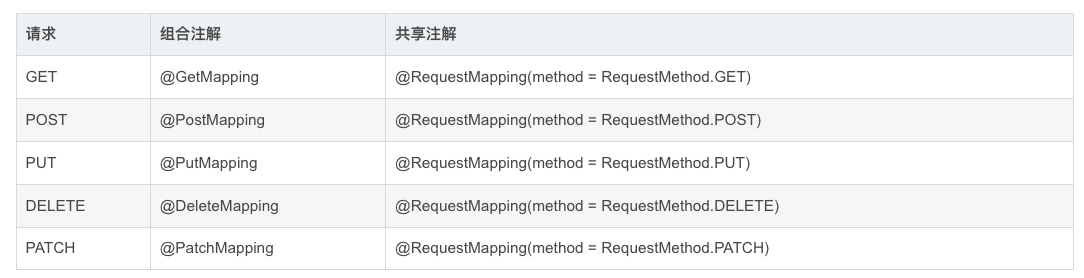
Spring MVC常见面试题
Spring MVC简介 Spring MVC框架是以请求为驱动,围绕Servlet设计,将请求发给控制器,然后通过模型对象,分派器来展示请求结果视图。简单来说,Spring MVC整合了前端请求的处理及响应。 Servlet 是运行在 Web 服务器或应用…...
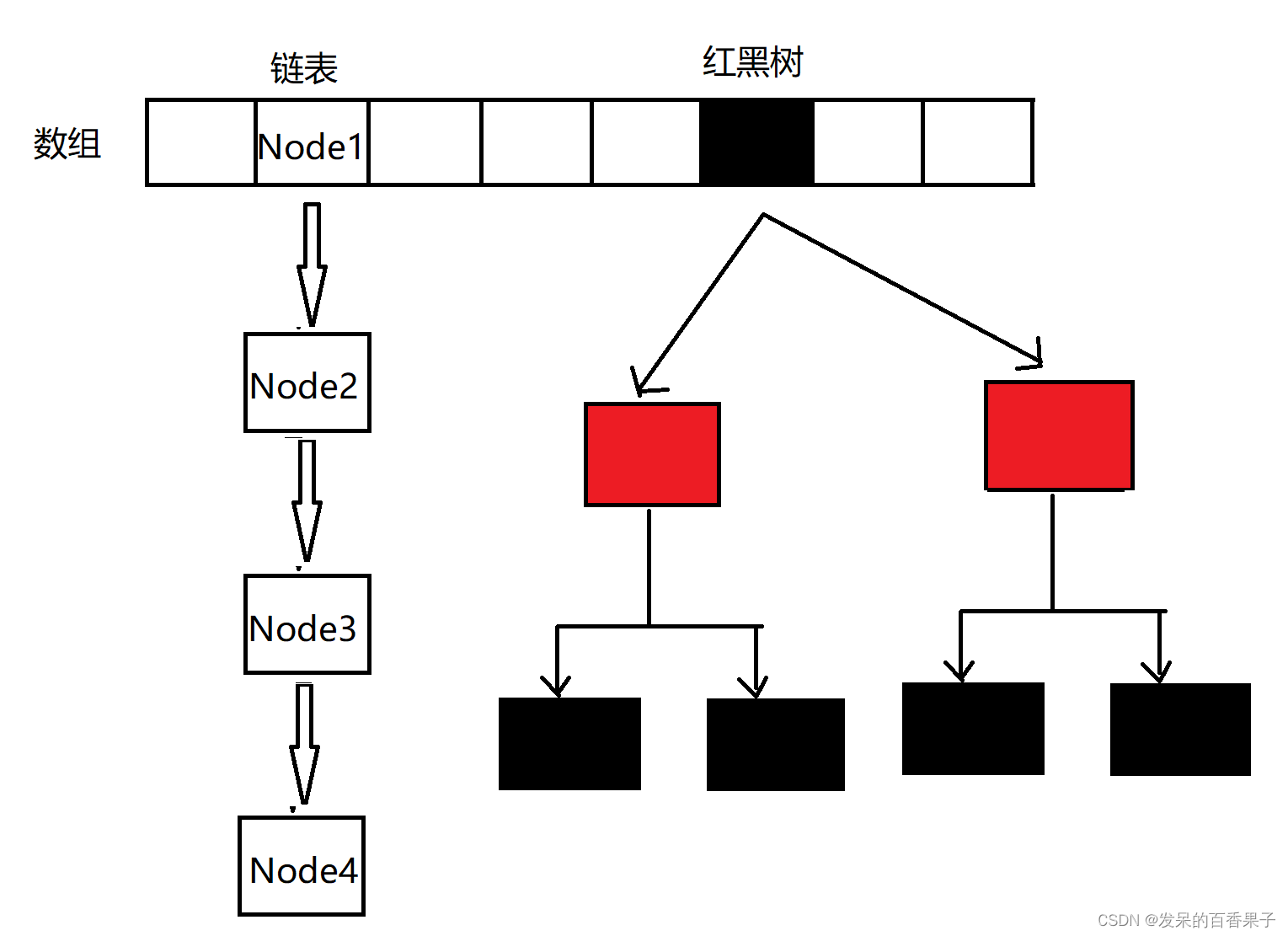
Java基础面试题精选:深入探讨哈希表、链表和接口等
目录 1.ArrayList和LinkedList有什么区别?🔒 2.ArrayList和Vector有什么区别?🔒 3.抽象类和普通类有什么区别?🔒 4.抽象类和接口有什么区别?🔒 5.HashMap和Hashtable有什么区别&…...
Spark计算框架
Spark计算框架 一、Spark概述二、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)1、Spark的安装模式1.1、Spark(单节点)本地安装1.2 Spark的Standalone部署模式的伪分布式安装1.3Spark的YARN部署模式1.4Spark…...

mybatis缓存源码分析
mybatis缓存源码分析 背景 在java程序与数据库交互的过程中永远存在着性能瓶颈,所以需要一直进行优化.而我们大部分会直接将目标放到数据库优化,其实我们应该先从宏观上去解决问题进而再去解决微观上的问题.性能瓶颈体现在什么地方呢?第一网络通信开销,网络数据传输通信.…...

Deepoc 具身智能开发板,解锁更安全高效清扫新体验
在家庭客厅、书房,或是小型商铺、办公室等场景里,地面杂物、低矮家具、墙角缝隙随处可见,布局复杂又不规则。带机械臂的清扫机器人,早已成为不少人解放双手的好帮手,但传统设备在实际使用中,总难避开一些痛…...

get_kline_serial 用法:K 线序列长度、末尾行与新 bar 判定
前言 分钟线、小时线策略里,指标几乎都挂在 get_kline_serial 返回的序列上。我常见三类报错:长度不够就访问 iloc[-20]、把未收盘的 close 当成定稿信号、以及同一根 K 线里重复下单。下面按天勤量化里的订阅方式、长度防护和与 is_changing 的配合写一…...

观察使用Token Plan套餐前后月度AI调用成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Token Plan套餐前后月度AI调用成本的变化趋势 对于频繁调用大模型API的开发者或团队而言,成本的可预测性与可控…...

AArch64虚拟内存系统架构与硬件自动更新机制详解
1. AArch64虚拟内存系统架构概述AArch64是ARMv8及ARMv9架构的64位执行状态,其虚拟内存系统架构(Virtual Memory System Architecture)是现代ARM处理器的核心组成部分。这套系统通过多级页表机制实现虚拟地址到物理地址的转换,为操…...
)
别再只盯着原理图了!FPGA/SoC硬件工程师必看的RGMII接口PCB布线实战指南(含时序约束与等长规则)
RGMII接口PCB设计实战:从时序规范到千兆以太网稳定通信 在FPGA和SoC硬件开发中,RGMII接口设计一直是工程师们又爱又恨的挑战。爱它的简洁高效——相比GMII接口减少了近一半的引脚数量;恨它的时序敏感——一个看似微小的PCB布线失误就可能导致…...

无王无帝定乾坤,来自田间第一人 道统传承兴万民
无王无帝定乾坤 来自田间第一人 华夏千载文脉绵延,万古道统源远流长,自古圣贤立心传道,只为正本清源、润泽苍生。往昔道统多依附王权存续,受朝堂礼制所拘,流传受限,难入寻常百姓之家,普惠世间之…...

普通人如何从零开始搭建自己的AI标题助手?低成本实战指南
就在今天,我刷到了一篇爆文,其标题乃是“用AI制作标题,短短3分钟就能产出100个爆款,而我的阅读量竟翻了5倍之多”,随后我点了进去,看过之后,又将其关掉,此时心里略微有那么点儿不是滋…...

体验Taotoken分钟级接入与标准OpenAI协议的无缝切换
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken分钟级接入与标准OpenAI协议的无缝切换 对于已经熟悉OpenAI API的开发者而言,尝试新的模型服务通常意味着…...

G-Helper:华硕笔记本用户的终极轻量级硬件控制方案
G-Helper:华硕笔记本用户的终极轻量级硬件控制方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

3分钟掌握Typora LaTeX主题:用Markdown写出专业学术论文的终极指南
3分钟掌握Typora LaTeX主题:用Markdown写出专业学术论文的终极指南 【免费下载链接】typora-latex-theme 将Typora伪装成LaTeX的中文样式主题,本科生轻量级课程论文撰写的好帮手。This is a theme disguising Typora into Chinese LaTeX style. 项目地…...