LLM-TAP随笔——大语言模型基础【深度学习】【PyTorch】【LLM】
文章目录
- 2.大语言模型基础
- 2.1、编码器和解码器架构
- 2.2、注意力机制
- 2.2.1、注意力机制(`Attention`)
- 2.2.2、自注意力机制(`Self-attention`)
- 2.2.3、多头自注意力(`Multi-headed Self-attention`)
- 2.3、transformer
- 2.4、BERT
- 2.5、GPT
- 2.6、LLaMA
2.大语言模型基础
2.1、编码器和解码器架构

这个架构常用于编码器-解码器架构是一种常用于序列到序列(Seq2Seq)任务的深度学习架构。序列到序列的问题举例:NLP问题(机器翻译、问答系统和文本摘要)。
编码器(Encoder)
将输入形式编码成中间表达形式。
中间表示被称为“编码”或“特征”。
解码器(Decoder)
将中间表示解码成输出形式。
也会有额外的输入。为啥?
输入一些额外的信息来帮助解码器生成正确的输出序列。这些额外的信息可以是一些上下文信息,例如输入序列的长度、标点符号和语法结构等。
2.2、注意力机制
2.2.1、注意力机制(Attention)
注意力机制允许模型在处理信息时更加灵活和智能地选择性地关注输入的不同部分,从而提高了模型的性能和表现力。
相比于全连接层、汇聚层,注意力机制就多了个自主提示。
self-attention 是复杂化的CNN,因此也可以退化成CNN。

组件
- query(自主提示):人为引导控制。
- key(非自主提示/不由自主):被物体的突出易见特征 吸引。
- value:与key配对。
- 注意力权重
- 注意力分数(Attention Scores):α(x, x i x_i xi)
- 注意力输出(Attention Output)

注意力计算规则
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n s o f t m a x ( − 1 2 ( x − x i ) 2 ) y i f(x) = \sum_{i=1}^nα(x,x_i)y_i = \sum_{i=1}^{n} softmax(-\frac{1}{2}(x-x_i)^2)y_i f(x)=i=1∑nα(x,xi)yi=i=1∑nsoftmax(−21(x−xi)2)yi
其中, x = q u e r y , x i = k e y , y i = v a l u e x = query,x_i= key,y_i = value x=query,xi=key,yi=value

2.2.2、自注意力机制(Self-attention)
自注意力(Self-Attention)是一种注意力机制的特殊情况,其中 Query、Key 和 Value 都来自相同的输入序列。
考虑到整个句子的资讯,FC 受到参数体量限制,提出self-attention,来考虑整个句子中哪些是与当前输入 a x a_x ax相关的讯息,通过计算输入之间的相关性α来得出。
计算关联程度α的模组
所有的α计算模组(query要计算自相关)
解释q,k,v的来源
q 1 = W q a 1 q_1 = W_qa_1 q1=Wqa1
k 1 = W k a 1 k_1 = W_ka_1 k1=Wka1
v 1 = W v a 1 v_1 = W_va_1 v1=Wva1
再往前,a的来源
最底层的输入(x1, x2, x3) 表示输入的序列数据,通过嵌入层(可选)将它们进行初步的embedding得到的a1,a2,a3


2.2.3、多头自注意力(Multi-headed Self-attention)
概括:注意力机制组合使用查询、键和值。

对于特定的 x i x_i xi来说,与多组 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV与之相乘,得到多组的 q i , k i , v i q_i,k_i,v_i qi,ki,vi。
2.3、transformer
基于transformer的EncoderDecoder模型结构图

嵌入层 任务
- 为文本序列每个单词创建一个相应的向量表示;
- 与位置编码相加送入下一层。
Feed-Forward Network层任务
考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力。
掩码(mask)作用
解码端则负责生成目标语言序列,这一生成过程是自回归的,即对于每一个单词的生成过程,仅有当前单词之前的目标语言序列是可以被观测的,因此这一额外增加的掩码是用来掩盖后续的文本信息,以防模型在训练阶段直接看到后续的文本序列进而无法得到有效地训练。
token
词元。嵌入层输入词元序列(tokens),输出 vector。
原始输入词序列通过词元分析后,词被切分或保留作为token,这些token序列表示原始词序列。
输出层
softmax通常是在解码器的最后一层或输出层上应用一次,用于将整个目标序列的分布概率计算出来,而不是在每个时间步都应用softmax。这种方式有助于生成整个序列的概率分布,然后可以根据这个分布来选择最终的目标序列。
其它参考:https://zhuanlan.zhihu.com/p/396221959
计算过程
注意力计算。
class Transformer(nn.Module):def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):super().__init__()self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)self.out = nn.Linear(d_model, trg_vocab)def forward(self, src, trg, src_mask, trg_mask):e_outputs = self.encoder(src, src_mask)d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)output = self.out(d_output)return output
其中,
d_output = self.decoder(trg, e_outputs, src_mask, trg_mask),d_output是自回归得到的,需要src_mask与e_outputs一起确保编码器输出的正确使用,src编码时也用到了src_mask,而trg_mask与trg一起确保解码器生成目标序列的合适性。trg包含了模型要生成的目标语言文本序列。解码器的主要目标是逐步生成trg中的每个词汇或标记,直到整个目标序列生成完毕。trg就是答案,一个一个对答案用到了trg_mask。
2.4、BERT
预训练模型:在大规模数据事先训练,然后在特定任务上微调。
只有编码器的 transformer
base版本:#blocks = 12, hidden size = 768, #heads = 12, #parameters = 110M
Large版本:#blocks = 24, hidden size =1024, #heads = 16, #parameters = 340M
模型结构图

计算过程
BERT分词器:WordPiece,源词序列——>词元。
WordPiece词元分析算法(
BERT)
- 先评分
- 再合并,合并使得训练数据似然概率增加最高的词元对。
HuggingFace 提供的评分公式:
s c o r e = 词元对出现的频率 第一个词元出现的频率 × 第二个词元出现的频率 score = \frac{词元对出现的频率}{第一个词元出现的频率 × 第二个词元出现的频率} score=第一个词元出现的频率×第二个词元出现的频率词元对出现的频率
预训练任务1:语言模型每次随机(15%)将一些词元换成(mask:带掩码)。
预训练任务2:下一句子预测,预测一个句子对中两个句子是不是相邻。
句子对<cls> this movie is great <sep> I like it <sep>
- <cls>标记通常用于表示序列(例如句子)的开始或整体表示
- <sep>标记通常用于表示序列的边界或分隔不同的句子或段落
- <eos> end of sequences,结束划分。
预训练bert
预训练阶段包括了编码器和解码器的部分,用于学习通用表示,而下游任务通常涉及到对编码器和解码器的微调,以适应具体任务。在某些情况下,下游任务可能只需要编码器或解码器的一部分,具体取决于任务的性质。
微调bert
微调流程图(instruct tuning)

第二种微调方式Performance会更好,但实际在做的能做的是第一种。拿到预训练好的模型为底座,按照上述流程图去进行特定任务的微调。
2.5、GPT
模型结构图

计算过程
h ( L ) = T r a n s f o r m e r − B l o c k ( L ) ( h ( 0 ) ) h (L) = Transformer-Block(L) (h(0)) h(L)=Transformer−Block(L)(h(0))
微调公式
L P T ( w ) = − ∑ i = 1 n l o g P ( w i ∣ w 0... w i − 1 ; θ ) L^{PT}(w) = -\sum_{i=1}^n logP(w_i|w0...w_{i-1};θ) LPT(w)=−i=1∑nlogP(wi∣w0...wi−1;θ)
L F T ( D ) = − ∑ ( x , y ) l o g P ( y ∣ x 1 . . x n ) L^{FT}(D) =-\sum_{(x,y)}log P(y|x_1..x_n) LFT(D)=−(x,y)∑logP(y∣x1..xn)
L = L F T ( D ) + λ L P T ( D ) L = L^{FT}(D) + \lambda L^{PT}(D) L=LFT(D)+λLPT(D)
L:loss
PT:pre-training
FT:fine-tuning
w:文本序列w = w1w2…wn
D:下游任务标注数据集
2.6、LLaMA
模型结构图

- 前置层归一化(Pre-normalization)
- 整体 Transformer 架构与 GPT-2 类似
RMSNorm归一化函数 (Normalizing Function)
- R M S ( a ) = 1 n ∑ i = 1 n a i 2 RMS(a) = \sqrt{\frac{1}{n}\sum_{i=1}^n a_i^2} RMS(a)=n1i=1∑nai2
- a i ˉ = a i R M S ( a ) \bar{a_i} = \frac{a_i}{RMS(a)} aiˉ=RMS(a)ai
- 可进一步引入偏移系数 g i g_i gi,偏移参数 $ b i b_i bi:
- a i ˉ = a i R M S ( a ) g i + b i \bar{a_i} = \frac{a_i}{RMS(a)}g_i + b_i aiˉ=RMS(a)aigi+bi
Feed-Forword Network激活函数更换为SwiGLU
- 旋转位置嵌入(
RoPE)
- 相对位置编码代替绝对位置编码
- q ~ m = f ( q , m ) k ~ n = f ( k , n ) \tilde{q}_m = f(q,m) \tilde{k}_n = f(k,n) q~m=f(q,m)k~n=f(k,n)
- f(m-n)表示绝对位置m、绝对位置n的相对位置,第m个token与第n个token的位置关系,和第n个token与第m个token的位置关系一定要有区分度,f(m-n) ≠ f (n-m)。矩阵不满足交换律
相关文章:
LLM-TAP随笔——大语言模型基础【深度学习】【PyTorch】【LLM】
文章目录 2.大语言模型基础2.1、编码器和解码器架构2.2、注意力机制2.2.1、注意力机制(Attention)2.2.2、自注意力机制(Self-attention)2.2.3、多头自注意力(Multi-headed Self-attention) 2.3、transforme…...
蓝桥杯备赛-上学迟到
上学迟到 P5707 【深基2.例12】上学迟到 - 洛谷 |https://www.luogu.com.cn/problem/P5707 题目介绍 题目描述 学校和 yyy 的家之间的距离为 s 米,而 yyy 以v 米每分钟的速度匀速走向学校。 在上学的路上,yyy 还要额外花费 1010 分钟的时间进行垃圾分…...

基于 MATLAB 的电力系统动态分析研究【IEEE9、IEEE68系节点】
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

2023百度之星 题目详解 公园+糖果促销
2023百度之星题目详解 文章目录 2023百度之星题目详解前言公园问题题目详解 夏日漫步问题问题详情题目详解 前言 这里为大家带来最新的2023百度之星的题目详解,后续还会继续更新,喜欢的小伙伴可以点个关注啦! 公园问题 今天是六一节&#…...
)
C++ 2019-2022 CSP_J 复赛试题横向维度分析(中)
上文讲解了2019~2022年第一题和第二题。第一题偏数学认知,算法较简单,第二题考查基本数据结构,如队列、栈……和基础算法,如排序、模拟……。 本文继续讲解第三题和第四题。 1. 第三题 1.1 2022 题目: 逻辑表达式…...
基于Spring Boot的IT技术交流和分享平台的设计与实现
目录 前言 一、技术栈 二、系统功能介绍 三、核心代码 1、登录模块 2、文件上传模块 3、代码封装 前言 我国科学技术的不断发展,计算机的应用日渐成熟,其强大的功能给人们留下深刻的印象,它已经应用到了人类社会的各个层次的领域&#x…...

智算引领·创新未来 | 2023紫光展锐泛物联网终端生态论坛成功举办
9月21日,紫光展锐在深圳成功举办2023泛物联网终端生态论坛。论坛以“智算引领创新未来”为主题,吸引了来自信通院、中国联通、中国移动、中国电信、金融机构、终端厂商、模组厂商等行业各领域三百多位精英翘楚汇聚一堂,探讨在连接、算力驱动下…...

网络安全技术指南 103.91.209.X
网络安全技术指的是一系列防范网络攻击、保护网络安全的技术手段和措施,旨在保护网络的机密性、完整性和可用性。常见的网络安全技术包括: 防火墙:用于监控网络流量,过滤掉可能包括恶意软件的数据包。 加密技术:用于保…...
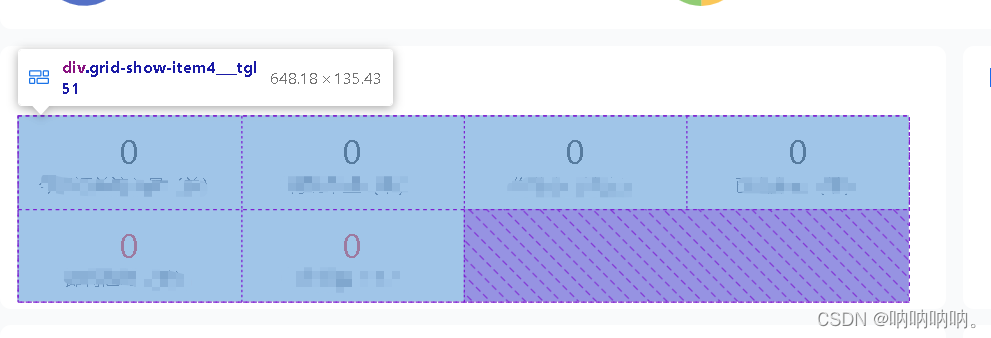
用flex实现grid布局
1. css代码 .flexColumn(columns, gutterSize) {display: flex;flex-flow: row wrap;margin: calc(gutterSize / -2);> div {flex: 0 0 calc(100% / columns);padding: calc(gutterSize / 2);box-sizing: border-box;} }2.用法 .grid-show-item3 {width: 100%;display: fl…...

东郊到家app小程序公众号软件开发预约同城服务系统成品源码部署
东郊到家app系统开发,东郊到家软件定制开发,东郊到家小程序APP开发,东郊到家源码定制开发,东郊到家模式系统定制开发 一、上门软件介绍 1、上门app是一家以推拿为主项,个人定制型的o2o平台,上门app平台提…...

kotlin的集合使用maxBy函数报NoSuchElementException
kotlin设定函数 fun test() {listOf<Int>().maxBy { it } } 查看java实现...
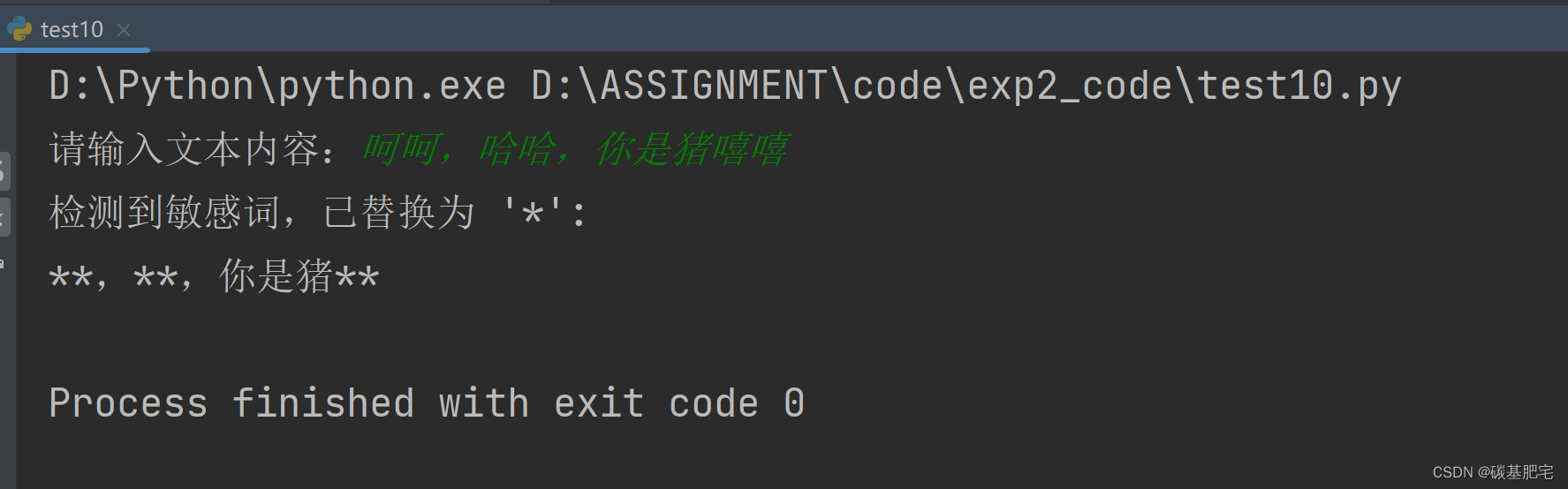
Python开发与应用实验2 | Python基础语法应用
*本文是博主对学校专业课Python各种实验的再整理与详解,除了代码部分和解析部分,一些题目还增加了拓展部分(⭐)。拓展部分不是实验报告中原有的内容,而是博主本人自己的补充,以方便大家额外学习、参考。 &a…...
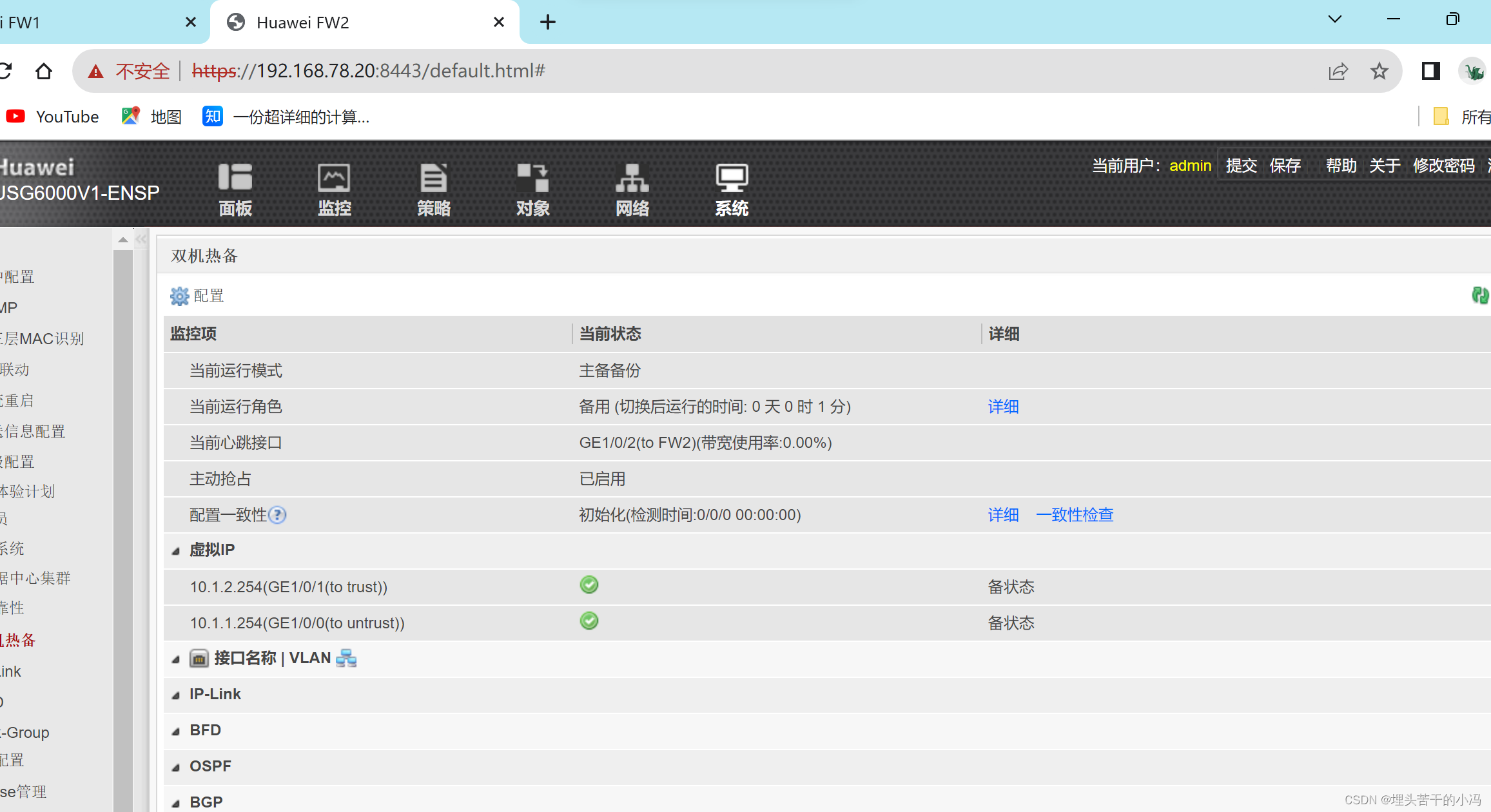
网络安全--防火墙旁挂部署方式和高可靠性技术
目录 一、防火墙 二、防火墙旁挂部署方式 使用策略路由实现 第一步、IP地址配置 第二步、配置路由 第三步、在防火墙上做策略 第四步、在R2上使用策略路由引流 三、防火墙高可靠性技术--HRP 拓扑图 第一步、配置SW1、SW2、FW1、FW2 第二步、进入防火墙Web页面进行配…...
)
c++最小步数模型(魔板)
C 最小步数模型通常用于寻找两个点之间的最短路径或最少步数。以下是一个基本的 C 最小步数模型的示例代码: #include<bits/stdc.h> using namespace std; const int N 1e5 5; vector<int> G[N]; int d[N]; bool vis[N];void bfs(int s) {queue<i…...

【每日一题Day337】LC460LFU 缓存 | 双链表+哈希表
LFU 缓存【LC460】 请你为 最不经常使用(LFU)缓存算法设计并实现数据结构。 实现 LFUCache 类: LFUCache(int capacity) - 用数据结构的容量 capacity 初始化对象int get(int key) - 如果键 key 存在于缓存中,则获取键的值&#x…...
解决老版本Oracle VirtualBox 此应用无法在此设备上运行问题
问题现象 安装华为eNSP模拟器的时候,对应的Oracle VirtualBox-5.2.26安装的时候提示兼容性问题,无法进行安装,具体版本信息如下: 软件对应版本备注Windows 11专业工作站版22H222621eNSP1.3.00.100 V100R003C00 SPC100终结正式版…...

法规标准-UN R48标准解读
UN R48是做什么的? UN R48全名为关于安装照明和灯光标志装置的车辆认证的统一规定,主要描述了对各类灯具的布置要求及性能要求;其中涉及自动驾驶功能的仅有6.25章节【后方碰撞预警信号】,因此本文仅对此章节进行解读 功能要求 …...

自动化和数字化在 ERP 系统中意味着什么?
毋庸置疑,ERP系统的作用是让工作更轻松。它可以集成流程,提供关键分析,确保你的企业高效运营。这些信息可以提高你的运营效率,并将有限的人力资本重新部署到更有效、更重要的需求上。事实上,自动化和数字化是ERP系统最…...

python nvidia 显卡信息 格式数据
python nvidia 显卡信息 格式数据. def get_gpu_memory():result subprocess.check_output([nvidia-smi, --query-gpupci.bus_id,memory.used,memory.total,memory.free, --formatcsv])# 返回 GPU 的显存使用情况,单位为 Minfo []for t in csv.DictReader(result…...
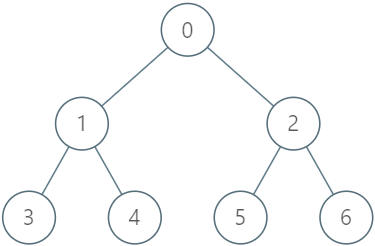
LeetCode每日一题:1993. 树上的操作(2023.9.23 C++)
目录 1993. 树上的操作 题目描述: 实现代码与解析: 模拟 dfs 原理思路: 1993. 树上的操作 题目描述: 给你一棵 n 个节点的树,编号从 0 到 n - 1 ,以父节点数组 parent 的形式给出,其中 p…...

DwarfStar 4:Redis 之父打造 DeepSeek V4 Flash 本地推理引擎,MacBook 上跑出 26 tok/s
DwarfStar 4:Redis 之父打造 DeepSeek V4 Flash 本地推理引擎,MacBook 上跑出 26 tok/s 一、背景:本地运行 284B 大模型成为现实 2026 年 5 月,一个开源项目在 GitHub 上迅速获得 10k 星标——DwarfStar 4 (ds4),由 …...

STM32 FSMC/FMC接口配置与调试:从时序参数到实战应用
1. 项目概述:为什么FSMC/FMC是STM32开发者绕不开的“硬骨头”?在STM32的众多外设中,FSMC(Flexible Static Memory Controller,灵活静态存储器控制器)及其升级版FMC(Flexible Memory Controller&…...

【亲测免费】 普冉PY32F002A移植FreeRTOS资源文件
普冉PY32F002A移植FreeRTOS资源文件 【下载地址】普冉PY32F002A移植FreeRTOS资源文件 本资源文件提供了将FreeRTOS V9.0移植到普冉M0芯片PY32F002A的完整示例。开发环境基于KEIL,并使用了LL库进行移植。该示例展示了如何在PY32F002A芯片上运行四个任务,并…...

别再只用DS18B20了!用51单片机和ADC0804做个PT100温度计,从硬件接线到代码调试全流程
从DS18B20到PT100:用51单片机打造工业级温度监测系统 在嵌入式开发领域,温度测量是一个永恒的话题。当大多数初学者还停留在使用DS18B20这类数字温度传感器时,工业领域早已广泛采用PT100铂电阻作为温度测量的主力军。本文将带你跨越数字传感器…...

Animockup代码实现分析:深入理解Canvas录制和视频转换技术
Animockup代码实现分析:深入理解Canvas录制和视频转换技术 【免费下载链接】animockup Create animated mockups in the browser 🔥 项目地址: https://gitcode.com/gh_mirrors/an/animockup Animockup是一个强大的开源项目,它允许用户…...

初创团队如何利用 Taotoken 模型广场快速进行 AI 技术选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken 模型广场快速进行 AI 技术选型 对于资源有限的初创团队而言,在产品原型阶段快速验证想法是…...

pycharm接入AI大模型测试脚本费用说明
费用说明 阿里云通义千问提供: 新用户免费额度:注册即送一定额度的免费 tokens 按量付费:用多少付多少,无最低消费 价格透明:详见 官方定价 示例成本(以 qwen-plus 为例) 解析-个 100页 PDF≈ 50,000 tokens ≈0.4 生成 100 个问答对≈20,000 tokens ≈0.16 下一步 …...

Linux Idle 调度器的 cpuidle_reflect:Idle 状态统计更新
简介 在 Linux 内核电源管理与调度体系中,CPU Idle(空闲)调度器是实现 CPU 低功耗管理的核心模块,负责在 CPU 无任务可调度时,选择并进入合适的硬件空闲状态(C-state),在性能与功耗…...

C51开发中汇编指令定位与内存优化实战
1. 理解C51开发中的汇编指令定位问题在嵌入式开发领域,尤其是使用Keil C51这类经典工具链时,我们经常需要深入理解编译器如何将高级语言转换为机器指令。最近我在调试一个8051项目时,遇到了一个典型问题:如何准确确定C源代码对应的…...

使用Python开发了CLI爬虫智能体
最近CLI智能体很火,这是一种在命令行工作的AI工具,比如Claude Code、OpenClaw等,非常适合编程、自动化、爬虫等场景。 我花了半天时间,用Python开发了一个CLI爬虫智能体,可以实现自动化采集Tiktok上公开的商品数据信息…...