如何设计一个 JVM 语言下的 LLM 应用开发框架?以 Chocolate Factory 为例
本文将介绍 Chocolate Factory 框架背后的一系列想法和思路。在我们探索和设计框架的过程中,受到了:LangChain4j、LangChain、LlamaIndex、Spring AI、Semantic Kernel、PromptFlow 的大量启发。
欢迎一起来探索:https://github.com/unit-mesh/chocolate-factory 。
顺带一提,在我们的参考架构里,框架/SDK 只是整体参考架构的一小部分。
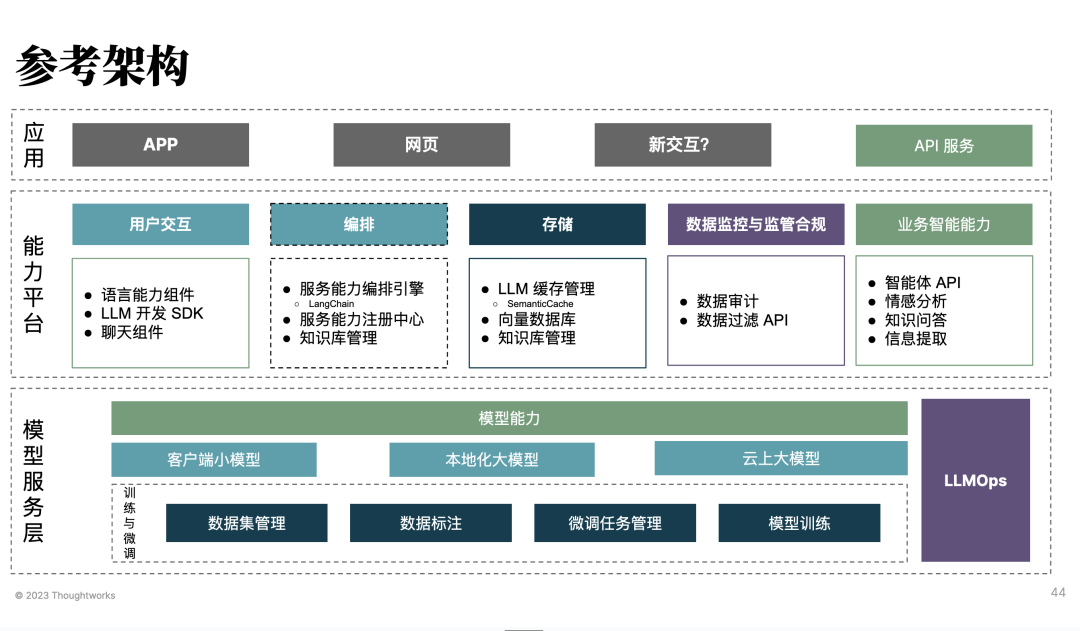
在 SDK 之后,还需要关注于 LLM 应用平台的设计。
为什么开发 JVM 语言的 LLM 开发框架
在过去的几个月里,我们一直在结合已有的 JVM 体系基础设施构建 LLM 应用。诸如于:
在 ArchGuard Co-mate 里,我们探索了架构 Copilot + Agent Tool (架构分析工具)的正确打开方式。
在 AI 辅助编程工具 AutoDev 中,我们给出了市面上最好的开源 IDE 插件的上下文构建模式 —— 构建复杂上下文(语言、框架、规范等)的 Prompt 策略,以及支持不同的大语言模型(除了市面上的大模型,还有内部的 MaaS 平台)。
……
这些尝试是围绕于我们过去的另外一个假设:当大模型成本降低,可靠性上升之后,AIGC 会与业务应用紧密结合。在这时,我们需要致力于:
开发结合 LLM 内部基础设施的 SDK
探索快速构建 RAG (检索增强)相关 PoC (概念证明)的方式
更友好的 prompt 开发与设计工具
简单来说,我们需要一些封装内部基础设施的框架、调试应用,以快速支撑 AI 应用的开发。
诸如于,我们在构建本地化代码搜索时,需要如下的工具:
dependencies {
// 核心库implementation("cc.unitmesh:cocoa-core:0.3.4")
// 代码拆分implementation("cc.unitmesh:code-splitter:0.3.4")
// Elastisearch 向量化存储,普通搜索implementation("cc.unitmesh:store-elasticsearch:0.3.4")
// 本地化的 embedding,用于每次更新代码,重新 embedding => CPUimplementation("cc.unitmesh:sentence-transformers:0.3.4")
}每个模块并不复杂,只是一些基本的 API 与基本的逻辑封装。但是,可以直接与现有的 AI 应用结合,再配套内部的 MaaS(模型即服务平台),就能快速在现有的业务中接入 LLM 能力。
起步:总结 LLM 应用所需要的能力
如先前的文档所说,我们将 LLM 优先的软件架构分为三类:。

通过简单的 prompt 来与大模型进行交互。
结合向量化(Embedding)的方式,来与大模型交互。
自动化规划的方式,基于 workflow 的方式。
在当前,我们优先关注于结合向量化,也就是大部分 RAG 场景下的交互。即基于特定的业务场景,分析用户的意图,自动提供相应的上下文,交由大模型来进行自动化分析。对于这三种类型来说,或者不同场景时,各自的关注度是不一样的。
与大模型的 API 交互。主要会由两部分组成,第一部分是:依赖于 MaaS 平台的标准的 LLM 接口模型封装;第二部分是:支持流式、自定义二次处理结果的交互 API。(第二部分其实是最难的)
文档向量化(Embedding)。主要会由三部分组成,第一部分是:支持不同格式文档的处理,及其拆分模式与策略的代码化设计;第二部分是:不同精度(出于成本考虑)需求的向量化模型接入;第三部分是:支持查询扩展的中间层与多种类型数据库检索,即结合向量数据库和传统数据库。
自动化规划(Flow + Agent)。尽管我们尝试去做更多相关的尝试,但是由于精力有限,并不能给出一个非常精确的结果。所以,在这里就暂时不展开这部分相关的内容。
开发一个框架与过去的东西差别不多。但是,有意思的一点是,由于我们构建的是一个框架,所以当看到新的 RAG 论文,第一反应就是能否交由框架来支持。
抽象:回顾 LLM 的数据处理
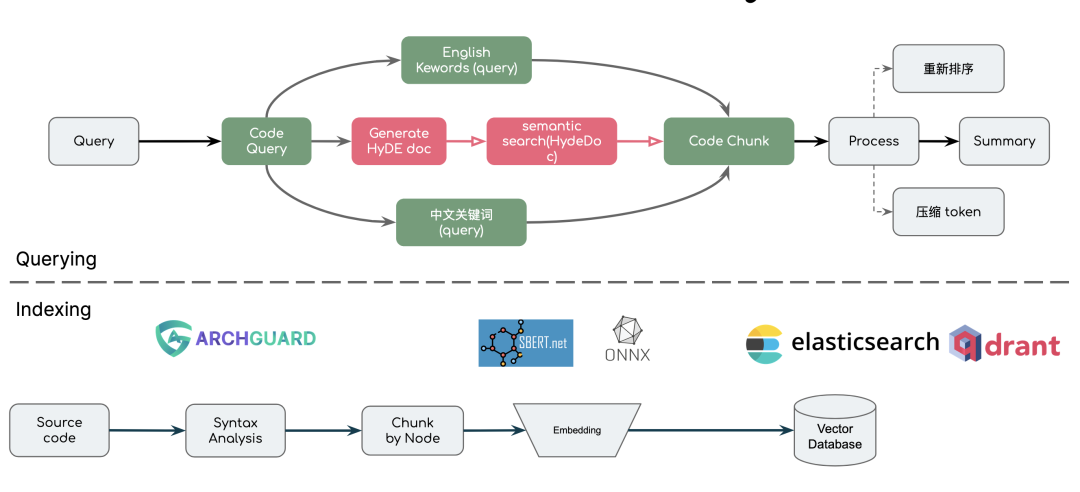
诸如于 LangChain、LlamaIndex 在这方面已经做了非常好的抽象,我们在设计的时候,参考(复制)了大量的相关思想。在 LlamaIndex 的文档上,已经给出了很好的抽象,在这里我们使用我们新开发的 RAGScript (可以直接运行)来表达相关的内容:
rag {indexing {val document = document("filename.text")val chunks = document.split()store.indexing(chunks)}querying {val results = store.findRelevant("Hello World").lowInMiddle()llm.completion {
"// 结合 results 处理 prompt"}}
}上面的代码段非常言简意赅的表达 RAG 的过程。简单来说,一个 RAG 分为 Indexing 和 Querying 两个阶段:
在 Indexing 阶段里,我们关注于如何将数据加工和分解(split),并注入到向量数据库中。
在 querying 阶段里,我们关注于如何加工检索完的数据,再结合 LLM 来处理
而现有的 LangChain、LlamaIndex 已经能提供我们很好的思路。唯一的挑战是,如何结合不同场景去探索合适的应用示例。
原型:从应用 PoC 中迭代抽象接口
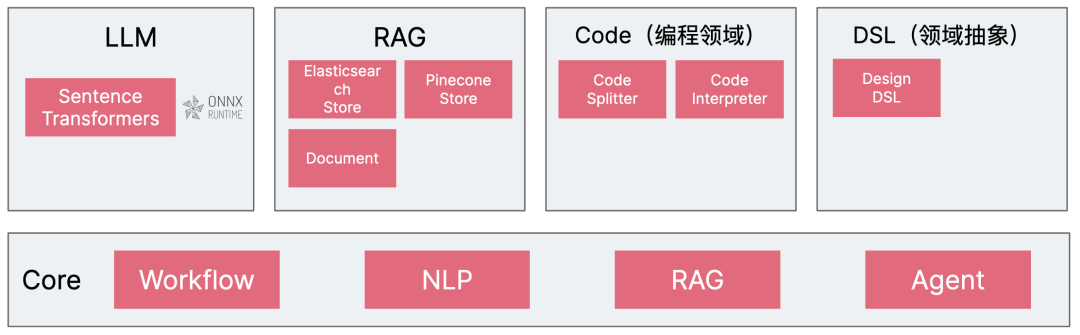
在不同的 LLM 应用开发框架或者 LLM 数据处理引擎里,都有大量的基础设施支持。但是,由于我们的场景往往是多种多样的,所以有时候显得有些不足。诸如于:
本地化向量化(Emdeddbing)模型 SentenceTransformers 的引入,以降低代码向量化的成本。为此,我们需要引入 Onnx Runtime, 以在客户端或者服务端进行向量化操作。
更精准的代码切分。对于框架型代码逻辑解释而言,能提供 interface 等抽象类的拆分,保持类之间的继承关系,以及其它更精准的规则处理,明显会比通用的拆分规则更有实际意义。
同时,为了更好的开发框架,除了结合过往开发 LLM 应用的经验,还得思考一些新的场景作为试验田。诸如于:
交互式的 UI 代码辅助设计场景。
简单场景下的代码解释器。
基于文档的规范查询。
基于自然语言的语义化代码搜索。
长数据场景下的测试用例设计
每种场景之下,对于框架的支持要求是不一样的。对于简单的场景,应该直接由 core 模块来提供所有的能力;对于复杂的场景,需要提供基本的 workflow 支持,以实现快速的应用开发。
除此,在复杂的场景之后,大部分的数据需要经过二次处理,也就是:
实时返回模式。只用于向用户提供快速的反馈。诸如代码生成时,先返回代码;又或者是基于流式的 DSL 来响应数据。
结果二次处理。当模型返回所有的结果时,需要再处理。诸如于,执行用户的代码,以生成的图表。
而在某些场景,我们需要的是长等待时间,即等待所有的用户返回内容。而对于这种不能由框架支持的功能,则稍微显得麻烦一些,我们得考虑通过示例向用户呈现这个过程。
插曲:解释 RAG 实现的 RAGScript
在开发了基本的 Chocolate Factory 功能之后,为了更好的让其他同事参与进来。我们尝试编写一系列的文档和示例,以向其他人解释:如何开发一个基于 LLM 的 RAG 应用?
为此,我们基于已有的 API 能力,构建了 RAGScript,以快速向其他人解释完整的过程。完事的示例代码如下所示:
rag("code") {// 使用 OpenAI 作为 LLM 引擎llm = LlmConnector(LlmType.OpenAI)// 使用 SentenceTransformers 作为 Embedding 引擎embedding = EmbeddingEngine(EngineType.SentenceTransformers)// 使用 Memory 作为 Retrieverstore = Store(StoreType.Memory)indexing {// 从文件中读取文档val document = document("filename.txt")// 将文档切割成 chunkval chunks = document.split()// 建立索引store.indexing(chunks)}querying {// 进行相关性查询val revelant = store.findRelevant("Hello World")// 结合 Lost in the Middle 的长上下文重新排序val results = revelant.lowInMiddle()println(results)}
}当然了,在我们的 RAG 示例中,还提供了代码语义化解释搜索的示例。详细见:https://framework.unitmesh.cc/docs/rag 。
Prompt 调试:LLM 的工程化开发难点
尽管我们开发的是模式二(Co-pilot 型应用)优先的 LLM 应用框架,但是在我们开发示例的过程中,我们依旧会发现对于 Prompt 的调试与编排是最大的挑战。
在 Chocolate Factory 的 DDD 思想的工作流中,我们推荐的实践是:
Apache Velocity Engine 作为模板引擎
构建每个 Workflow 独立的 Context 环境,与变量 resolver。
然而,对于一个大型的组织来说,内部会存在不同的 LLM。对于不同的 LLM 而言,相应的 prompt 编写模式也是有差异的。所以,我们正在思考采用同 PromptFlow 相似的方式,即采用独立的模板文件,结合工作流编排,以适应不同模式的 promtp 差异。如下是 PromptFlow 的模板示例:
system:
You are a helpful assistant.
{% for item in chat_history %}
user:
{{item.inputs.question}}
assistant:
{{item.outputs.answer}}
{% endfor %}
user:
{{question}}再结合 CLI 或者 IDE 可视化的方式进行探索。
总结
总的来说,这篇文章深入探讨了设计 JVM 语言的 LLM 应用开发框架的思考过程,强调了框架的多样性和复杂性,以及如何通过框架和工具来支持各种 LLM 应用场景。我们提供了有用的示例代码和抽象概念,有助于读者更好地理解和开发 LLM 应用。
相关文章:
如何设计一个 JVM 语言下的 LLM 应用开发框架?以 Chocolate Factory 为例
本文将介绍 Chocolate Factory 框架背后的一系列想法和思路。在我们探索和设计框架的过程中,受到了:LangChain4j、LangChain、LlamaIndex、Spring AI、Semantic Kernel、PromptFlow 的大量启发。 欢迎一起来探索:https://github.com/unit-mes…...
基础排序算法
插入排序(insertion sort) 插入排序每次循环将一个元素放置在适当的位置。像抓牌一样。手里的排是有序的,新拿一张牌,与手里的牌进行比较将其放在合适的位置。 插入排序要将待排序的数据分成两部分,一部分有序&#…...
Nginx的反向代理、动静分离、负载均衡
反向代理 反向代理是一种常见的网络技术,它可以将客户端的请求转发到服务器群集中的一个或多个后端服务器上进行处理,并将响应结果返回给客户端。反向代理技术通常用于提高网站的可伸缩性和可用性,并且可以隐藏真实的后端服务器地址。 #user…...

LLM-TAP随笔——大语言模型基础【深度学习】【PyTorch】【LLM】
文章目录 2.大语言模型基础2.1、编码器和解码器架构2.2、注意力机制2.2.1、注意力机制(Attention)2.2.2、自注意力机制(Self-attention)2.2.3、多头自注意力(Multi-headed Self-attention) 2.3、transforme…...
蓝桥杯备赛-上学迟到
上学迟到 P5707 【深基2.例12】上学迟到 - 洛谷 |https://www.luogu.com.cn/problem/P5707 题目介绍 题目描述 学校和 yyy 的家之间的距离为 s 米,而 yyy 以v 米每分钟的速度匀速走向学校。 在上学的路上,yyy 还要额外花费 1010 分钟的时间进行垃圾分…...

基于 MATLAB 的电力系统动态分析研究【IEEE9、IEEE68系节点】
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

2023百度之星 题目详解 公园+糖果促销
2023百度之星题目详解 文章目录 2023百度之星题目详解前言公园问题题目详解 夏日漫步问题问题详情题目详解 前言 这里为大家带来最新的2023百度之星的题目详解,后续还会继续更新,喜欢的小伙伴可以点个关注啦! 公园问题 今天是六一节&#…...
)
C++ 2019-2022 CSP_J 复赛试题横向维度分析(中)
上文讲解了2019~2022年第一题和第二题。第一题偏数学认知,算法较简单,第二题考查基本数据结构,如队列、栈……和基础算法,如排序、模拟……。 本文继续讲解第三题和第四题。 1. 第三题 1.1 2022 题目: 逻辑表达式…...
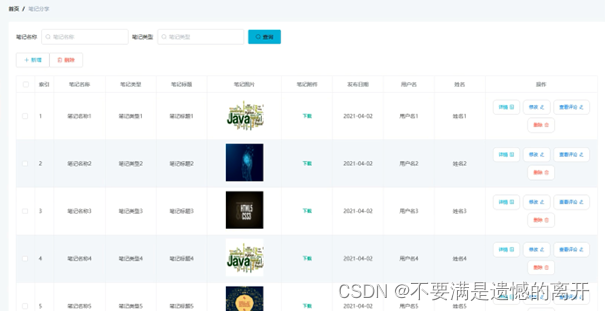
基于Spring Boot的IT技术交流和分享平台的设计与实现
目录 前言 一、技术栈 二、系统功能介绍 三、核心代码 1、登录模块 2、文件上传模块 3、代码封装 前言 我国科学技术的不断发展,计算机的应用日渐成熟,其强大的功能给人们留下深刻的印象,它已经应用到了人类社会的各个层次的领域&#x…...

智算引领·创新未来 | 2023紫光展锐泛物联网终端生态论坛成功举办
9月21日,紫光展锐在深圳成功举办2023泛物联网终端生态论坛。论坛以“智算引领创新未来”为主题,吸引了来自信通院、中国联通、中国移动、中国电信、金融机构、终端厂商、模组厂商等行业各领域三百多位精英翘楚汇聚一堂,探讨在连接、算力驱动下…...

网络安全技术指南 103.91.209.X
网络安全技术指的是一系列防范网络攻击、保护网络安全的技术手段和措施,旨在保护网络的机密性、完整性和可用性。常见的网络安全技术包括: 防火墙:用于监控网络流量,过滤掉可能包括恶意软件的数据包。 加密技术:用于保…...
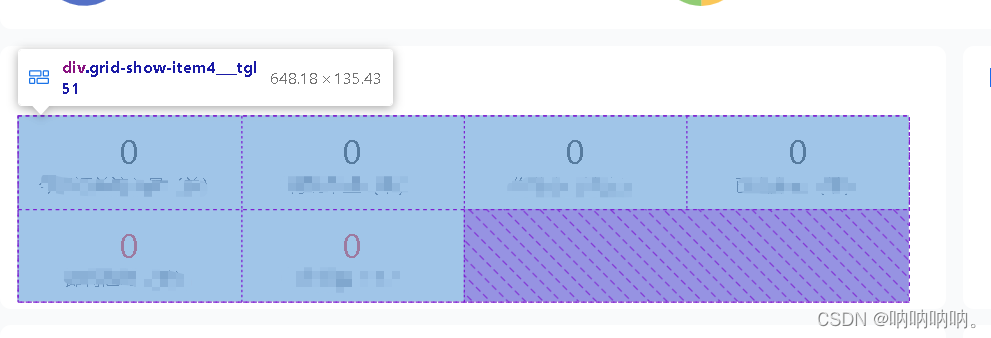
用flex实现grid布局
1. css代码 .flexColumn(columns, gutterSize) {display: flex;flex-flow: row wrap;margin: calc(gutterSize / -2);> div {flex: 0 0 calc(100% / columns);padding: calc(gutterSize / 2);box-sizing: border-box;} }2.用法 .grid-show-item3 {width: 100%;display: fl…...

东郊到家app小程序公众号软件开发预约同城服务系统成品源码部署
东郊到家app系统开发,东郊到家软件定制开发,东郊到家小程序APP开发,东郊到家源码定制开发,东郊到家模式系统定制开发 一、上门软件介绍 1、上门app是一家以推拿为主项,个人定制型的o2o平台,上门app平台提…...

kotlin的集合使用maxBy函数报NoSuchElementException
kotlin设定函数 fun test() {listOf<Int>().maxBy { it } } 查看java实现...
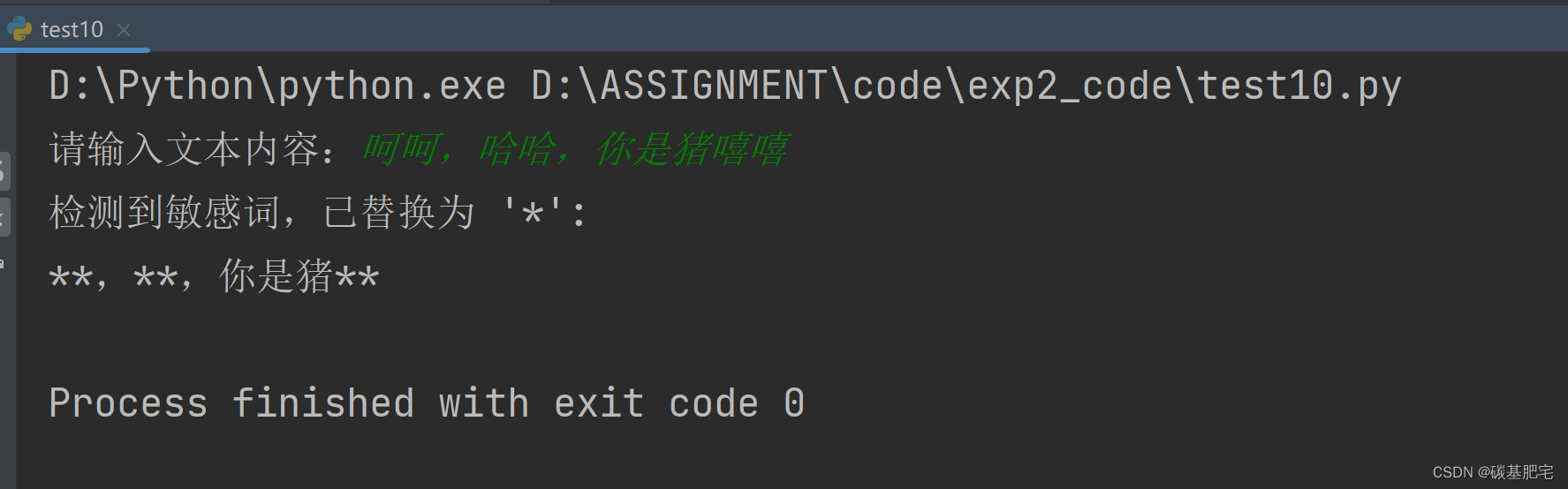
Python开发与应用实验2 | Python基础语法应用
*本文是博主对学校专业课Python各种实验的再整理与详解,除了代码部分和解析部分,一些题目还增加了拓展部分(⭐)。拓展部分不是实验报告中原有的内容,而是博主本人自己的补充,以方便大家额外学习、参考。 &a…...
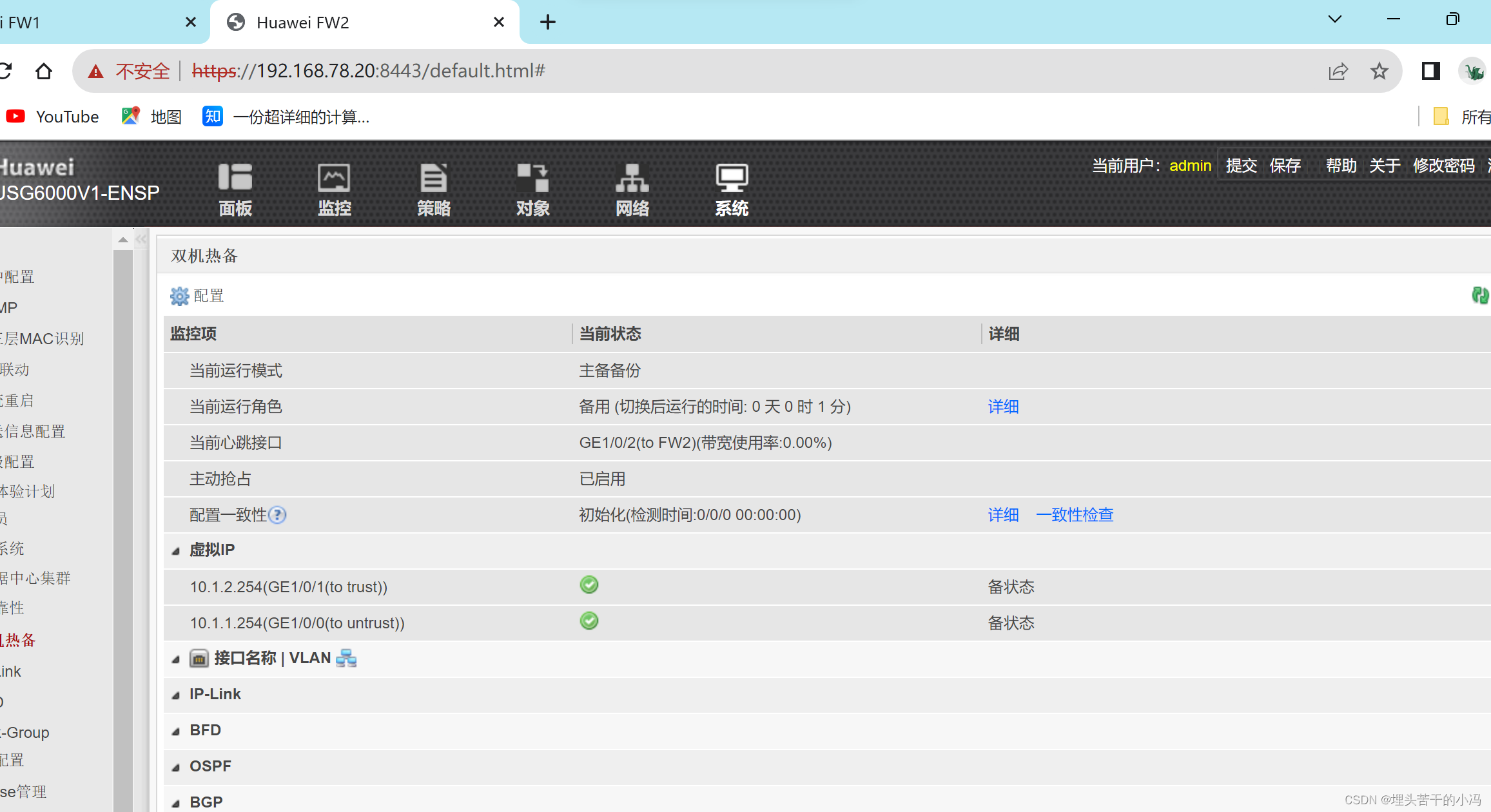
网络安全--防火墙旁挂部署方式和高可靠性技术
目录 一、防火墙 二、防火墙旁挂部署方式 使用策略路由实现 第一步、IP地址配置 第二步、配置路由 第三步、在防火墙上做策略 第四步、在R2上使用策略路由引流 三、防火墙高可靠性技术--HRP 拓扑图 第一步、配置SW1、SW2、FW1、FW2 第二步、进入防火墙Web页面进行配…...
)
c++最小步数模型(魔板)
C 最小步数模型通常用于寻找两个点之间的最短路径或最少步数。以下是一个基本的 C 最小步数模型的示例代码: #include<bits/stdc.h> using namespace std; const int N 1e5 5; vector<int> G[N]; int d[N]; bool vis[N];void bfs(int s) {queue<i…...

【每日一题Day337】LC460LFU 缓存 | 双链表+哈希表
LFU 缓存【LC460】 请你为 最不经常使用(LFU)缓存算法设计并实现数据结构。 实现 LFUCache 类: LFUCache(int capacity) - 用数据结构的容量 capacity 初始化对象int get(int key) - 如果键 key 存在于缓存中,则获取键的值&#x…...
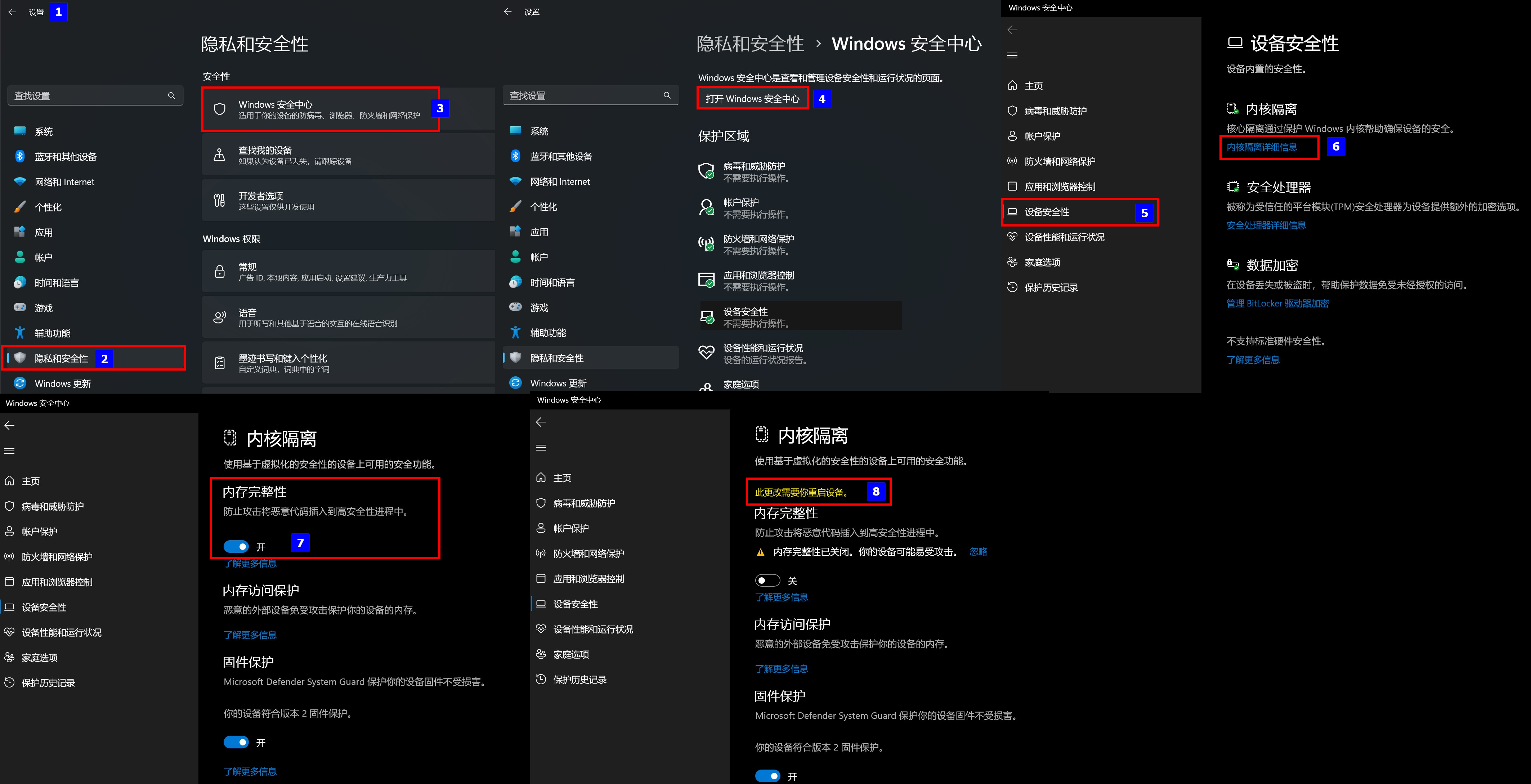
解决老版本Oracle VirtualBox 此应用无法在此设备上运行问题
问题现象 安装华为eNSP模拟器的时候,对应的Oracle VirtualBox-5.2.26安装的时候提示兼容性问题,无法进行安装,具体版本信息如下: 软件对应版本备注Windows 11专业工作站版22H222621eNSP1.3.00.100 V100R003C00 SPC100终结正式版…...

法规标准-UN R48标准解读
UN R48是做什么的? UN R48全名为关于安装照明和灯光标志装置的车辆认证的统一规定,主要描述了对各类灯具的布置要求及性能要求;其中涉及自动驾驶功能的仅有6.25章节【后方碰撞预警信号】,因此本文仅对此章节进行解读 功能要求 …...

完整教程:org-modern的25个核心配置选项详解
完整教程:org-modern的25个核心配置选项详解 【免费下载链接】org-modern :unicorn: Modern Org Style 项目地址: https://gitcode.com/gh_mirrors/or/org-modern org-modern是一款为Emacs Org模式提供现代风格的插件,通过字体锁定和文本属性实现…...

量子优化技术在工业数据生产规划中的应用与实践
1. 量子优化技术在工业数据生产规划中的实践探索在汽车制造领域,生产规划一直是个复杂难题。以冲压车间为例,金属板材需要通过冲压机加工成车身部件,每台冲压机都有不同的工作能力和成本特性,而每个模具组又需要分配到合适的机器上…...

手把手教你写JS逆向通用模板:一键提取加密参数
在JS逆向实战中,你一定遇到过这种情况:同一个网站,换个接口就要重新扣代码、调环境、处理依赖;换个网站,又要从头再来一遍,重复劳动浪费大量时间。 其实90%的JS逆向场景,都可以用一套通用模板搞定。不管是MD5/SHA1签名、AES/RSA加密、还是混淆后的动态加密函数,这套模…...

完全掌握JetBrains IDE试用期重置:从原理到实战的终极解决方案
完全掌握JetBrains IDE试用期重置:从原理到实战的终极解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为JetBrains系列开发工具的试用期限制而困扰吗?IDE Eval Resetter为您提…...

Lenovo Legion Toolkit:拯救者笔记本的终极性能优化指南
Lenovo Legion Toolkit:拯救者笔记本的终极性能优化指南 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 你是否曾…...

3分钟掌握:ncmdumpGUI免费转换网易云音乐ncm文件的完整指南
3分钟掌握:ncmdumpGUI免费转换网易云音乐ncm文件的完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经从网易云音乐下载了心爱的歌…...

Blender 3MF插件终极指南:如何在Blender中实现3D打印文件的完美导入导出
Blender 3MF插件终极指南:如何在Blender中实现3D打印文件的完美导入导出 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 想要在Blender中高效处理3D打印文件吗…...

AI Coding 言出法随,未来什么还会值钱?
本文整理自播客《AI炼金术》任鑫(云九资本)与徐文浩的深度对话,探讨 AI Coding 如何重塑个人开发方式、组织形态,以及在生产力极大释放的时代,究竟什么能力还会持续增值。—本文资料通过Ai好记智能解析获取。一、AI Co…...

别再只盯着大厂光环了:聊聊外包经历对技术人真正的价值与局限
外包经历的技术价值辩证:从职业跳板到能力陷阱的深度思考 当招聘网站上"大厂外包"的职位描述与诱人薪资同时出现时,很多技术人都会面临职业选择的十字路口。我们习惯性地将外包岗位视为"二等公民",却鲜少客观分析这段经历…...
)
从零到部署:用VirtualBox免费搭建你的第一个Linux服务器(CentOS 7 + 静态IP + Xshell连接)
从零到部署:用VirtualBox免费搭建你的第一个Linux服务器(CentOS 7 静态IP Xshell连接) 在技术学习与开发实践中,拥有一个稳定可靠的Linux服务器环境是每个开发者成长的必经之路。对于预算有限的个人开发者、学生群体或刚接触运维…...