Lostash同步Mysql数据到Elasticsearch(三)Elasticsearch模板与索引设置
logstash数据同步ES相关
同步数据时,Elasticsearch配合脚本的相关处理设置
1.模板创建更新
在kibana中执行,或者直接给ES发送请求,你懂得,不懂得百度下ES创建template
PUT /_template/test-xxx{"template": "idx_znyw_data_gkb_logstash","order": 1,"settings": {"number_of_shards": 1},"mappings": {"dynamic": "true","dynamic_date_formats": ["yyyy-MM-dd'T'HH:mm:ss.SSS'Z'","yyyy-MM-dd'T'HH:mm:ss.SSS+0800","yyyy-MM-dd'T'HH:mm:ss'Z'","yyyy-MM-dd'T'HH:mm:ss+0800","yyyy-MM-dd'T'HH:mm:ss","yyyy-MM-dd HH:mm:ss","yyyy-MM-dd"],"properties": {"@timestamp": {"type": "date"},"@version": {"type": "integer"},"_class": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"id": {"type": "long"},"location": {"properties": {"lat": {"type": "double"},"lon": {"type": "double"}}},"latitude": {"type": "double"},"longitude": {"type": "double"},"ipAddr": {"type": "ip","index": true,"store": false},"setupTime": {"type": "date","index": true,"store": false,"format": "date","ignore_malformed": false},"updateDate": {"type": "date","index": true,"store": false,"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd'T'HH:mm:ss||yyyy-MM-dd'T'HH:mm:ss+0800||yyyy-MM-dd'T'HH:mm:ss'Z'||yyyy-MM-dd'T'HH:mm:ss.SSS+0800||yyyy-MM-dd'T'HH:mm:ss.SSS'Z'||yyyy-MM-dd||epoch_millis","ignore_malformed": false},"delFlag": {"type": "integer"}}}
}2.特殊版本类型logstash脚本处理
上面红色部分的需要特殊处理,下面给出特殊操作的logstash脚本处理方法,在filter中特殊处理,这里是直接上干货,其他的概念性的问题,百度一下。
filter {#坐标 mutate {add_field => ["[location][lon]", "%{[longitude]}"]add_field => ["[location][lat]", "%{[latitude]}"]}#时间
ruby {code => "date_person = event.get('setupTime').time.localtime + 0*60*60event.set('setupTime', date_person.strftime('%Y-%m-%d'))"}
ruby {code => "
event.set('createDate', event.get('createDate').time.localtime + 0*60*60)"}}3.索引更新设置
#在kibana中执行,执行前要关闭索引,但是注意,这里不能修改分片数,分片数只能在索引创建时指定,那数据量超量时,分片数不够用怎么整呢,看标题4
//先把索引关掉
POST /idx_xxx_sysinfo/_close
POST /idx_xxx_sysinfo/_open
//更新索引
PUT /idx_xxx_sysinfo/_settings{"index":{"number_of_replicas": 2,"max_result_window": 65536,"max_inner_result_window": 10000,"translog.durability": "request","translog.sync_interval": "3s","auto_expand_replicas": false,"analysis.analyzer.default.type": "ik_max_word","analysis.search_analyzer.default.type": "ik_smart","shard.check_on_startup": false,"codec": "default","store.type": "niofs"}
}
4.分片数量不够时(ES内部内部数据迁移策略)
ES内部内部数据迁移策略
使用场景:
1、当你的数据量过大,而你的索引最初创建的分片数量不足,导致数据入库较慢的情况,此时需要扩大分片的数量,此时可以尝试使用Reindex。
2、当数据的mapping需要修改,但是大量的数据已经导入到索引中了,重新导入数据到新的索引太耗时;但是在ES中,一个字段的mapping在定义并且导入数据之后是不能再修改的,
所以这种情况下也可以考虑尝试使用Reindex。
POST _reindex?slices=5&refresh
{"source": {"index": "idx_znyg_datanbqseries_new","size": 10000 //批量执行数},"dest": {"index": "idx_znyg_datanbqseries",//version_type"version_type": "internal"或者不设置,则Elasticsearch强制性的将文档转储到目标中,覆盖具有相同类型和ID的任何内容:"version_type": "internal"}
}slices大小设置注意事项:
1)slices大小的设置可以手动指定,或者设置slices设置为auto,auto的含义是:针对单索引,slices大小=分片数;针对多索引,slices=分片的最小值。
2)当slices的数量等于索引中的分片数量时,查询性能最高效。slices大小大于分片数,非但不会提升效率,反而会增加开销。
3)如果这个slices数字很大(例如500),建议选择一个较低的数字,因为过大的slices 会影响性能。
效果
实践证明,比默认设置reindex速度能提升10倍+。
创建索引
PUT /idx_znyg_datanbqseries_new?pretty
{"settings": {"index.number_of_shards": 12,"index.number_of_replicas": 1,"index.max_result_window": 65536,"index.max_inner_result_window": 10000,"index.translog.durability": "request","index.translog.sync_interval": "3s","index.auto_expand_replicas": false,"index.analysis.analyzer.default.type": "ik_smart","index.analysis.search_analyzer.default.type": "ik_smart","index.shard.check_on_startup": false,"index.codec": "default","index.store.type": "niofs"}, "mappings": {}}5.logstash大数据量脚本加速
脚本执行SQL分析,人为加速处理设置。
如下SQL为logstash数据同步执行脚本,分析设置后,做如下处理,OFFSET -500获取上次执行完数据,拿最小ID保存至ID文件内,关闭服务重启启动,此时速度飞起,当OFFSET 数量过500万时,每次查询30S+,所以速度就下降了。
SELECT * FROM (select del_flag as delFlag from znyw_data_nbq_series WHERE id>= 1347422522840252418) AS `t1` LIMIT 500 OFFSET 500
6.logstash特性(重要)
有时候发现数据库数量和索引数量不匹配,需要重新同步,请按照如下操作处理:
1.停止服务
2.删除索引更新数据文件
3.重启启动服务查看日志
这样操作是因为,增量id更新,没有读文件,这样操作最保险,还有就是数据不一致不要慌,查看任务执行日志,有些脚本过滤插件有问题的也不会更新。
相关文章:
Elasticsearch模板与索引设置)
Lostash同步Mysql数据到Elasticsearch(三)Elasticsearch模板与索引设置
logstash数据同步ES相关 同步数据时,Elasticsearch配合脚本的相关处理设置 1.模板创建更新 在kibana中执行,或者直接给ES发送请求,你懂得,不懂得百度下ES创建template PUT /_template/test-xxx {"template": "…...
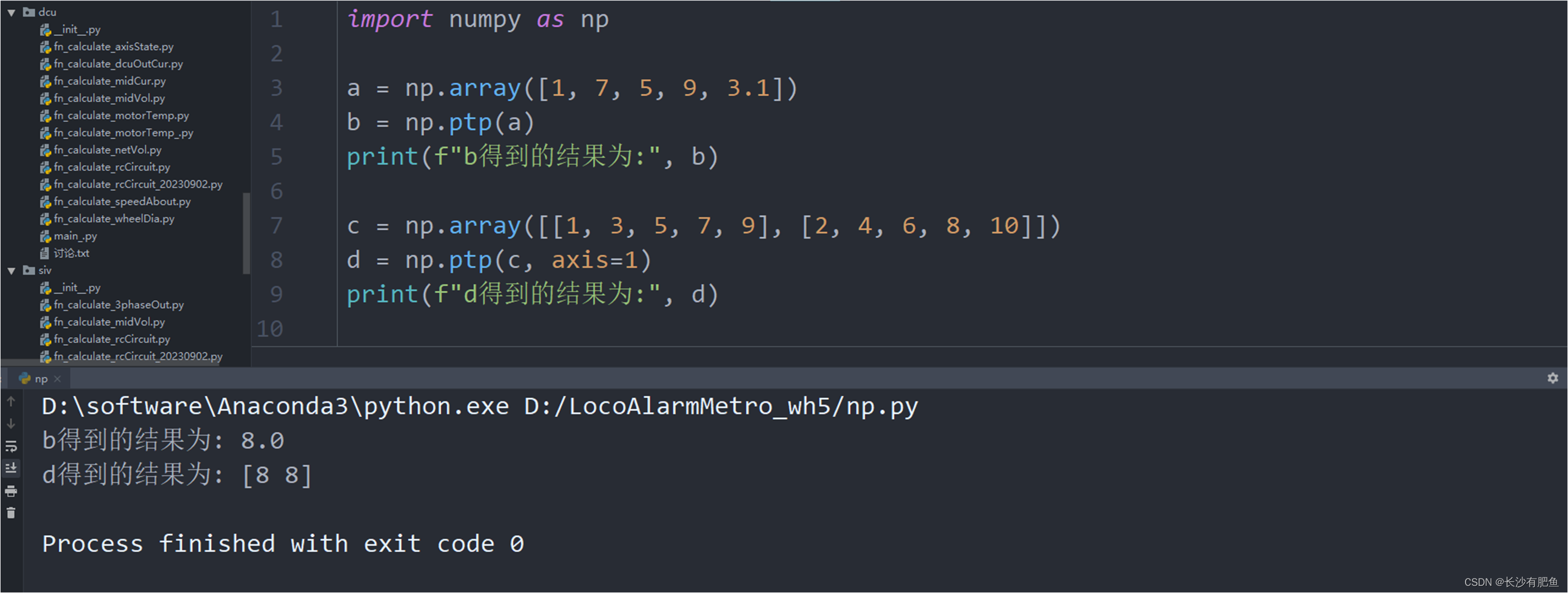
python——ptp()函数
函数功能:求最大值和最小值的差值 def ptp(a, axisNone, outNone):"""沿轴的值范围(最大值-最小值)。该函数的名称来自“peak-to-peak”的首字母缩写。参数----------a:array_like输入值。axis:int,可选找到山峰的…...
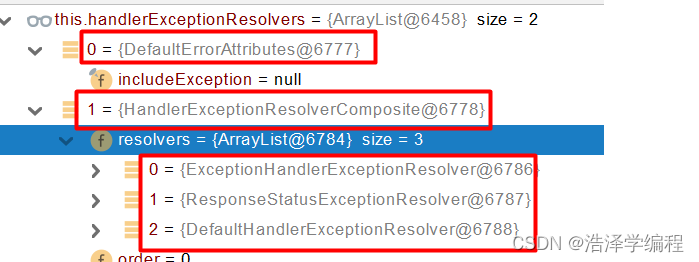
SpringBoot之异常处理
文章目录 前言一、默认规则二、定制异常处理处理自定义错误页面ControllerAdviceExceptionHandler处理全局异常ResponseStatus自定义异常自定义实现 HandlerExceptionResolver 处理异常 三、异常处理自动配置原理四、异常处理流程总结 前言 包含SpringBoot默认处理规则、如何定…...
: flask-socketio文档学习)
Flask-[实现websocket]-(2): flask-socketio文档学习
一、简单项目的构建 flask_websocket |---static |---js |---jquery-3.7.0.min.js |---socket.io_4.3.1.js |---templates |---home |---group_chat.html |---index.html |---app.py 1.1、python环境 python3.9.0 1.2、依赖包 Flask2.1.0 eventlet0.33.3 #使用这个性能会…...

网页中使用的图片格式
网页中使用的图片格式有以下几种,各有优缺点: JPEG:适用于照片或彩色图像,支持16.7万种颜色,有损压缩,可以调节压缩比和质量,文件较小,加载较快PNG:适用于图标或透明图像…...

【android】如何设置LD_LIBRARY_PATH?
目录 一 配置方法 1 进入Android shell 2 使用export命令 3 使用echo命令查看变量是否设置成功 二 扩展 1 LD_LIBRARY_PATH设置多个路径 2 push文件 一 配置方法 android中配置LD_LIBRARY_PATH的方法具体为: 1 进入Android shell adb shell 2 使用export…...
【hadoop3.x】一 搭建集群调优
一、基础环境安装 https://blog.csdn.net/fen_dou_shao_nian/article/details/120945221 二、hadoop运行环境搭建 2.1 模板虚拟机环境准备 0)安装模板虚拟机,IP 地址 192.168.10.100、主机名称 hadoop100、内存 4G、硬盘 50G 1)hadoop100…...
linux使用操作[2]
文章目录 版权声明网络传输ping命令wget命令curl命令端口linux端口端口命令和工具 进程管理查看进程关闭进程 主机状态top命令内容详解磁盘信息监控 版权声明 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相…...
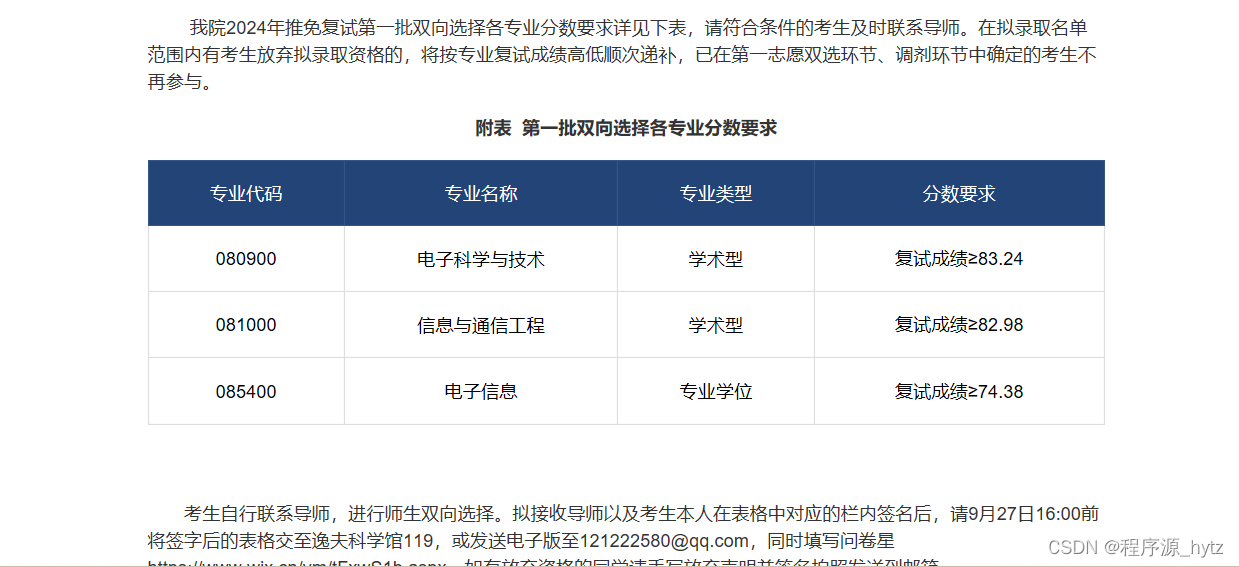
华南理工大学电子与信息学院23年预推免复试面试经验贴
运气较好,复试分数90.24,电科学硕分数线84、信通83、专硕电子与信息74. 面试流程: 1:5min ppt的介绍。其中前2min用英语简要介绍基本信息,后3min可用英语也可用中文 介绍具体项目信息如大创、科研、竞赛等(…...

Linux网络编程- ether_header iphdr tcphdr
struct ether_header struct ether_header 是一个数据结构,用于表示以太网(Ethernet)帧的头部。这个结构体在 <netinet/if_ether.h> 头文件中定义。当你处理或分析以太网帧时,可以使用这个结构体来访问和解读 Ethernet 头部…...

wpf中的StaticResource和DynamicResource
不同点一:StaticResource是程序载入时对资源的一次性使用,之后就不在访问了 DynamicResouce则是程序运行过程中回去访问资源 样例:在xaml中定义好的资源 <Window.Resources><SolidColorBrush x:Key"borderRed" Color"…...

数据结构与算法基础-(3)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...
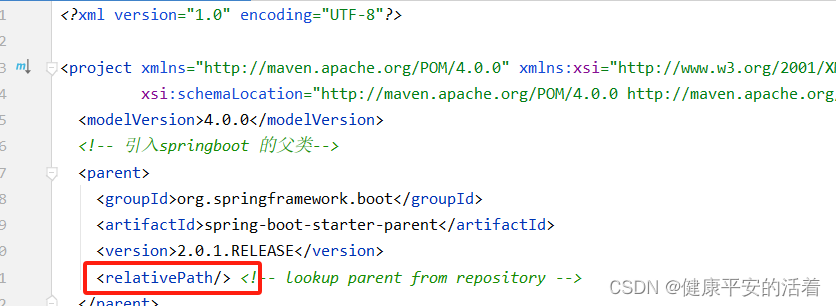
maven中relativepath标签的含义
一 relative标签的含义 1.1 作用 这个<parent>下面的<relativePath>属性:parent的pom文件的路径。 relativePath 的作用是为了找到父级工程的pom.xml;因为子工程需要继承父工程的pom.xml文件中的内容。然后relativePath 标签内的值使用相对路径定位…...

Greenplum 对比 Hadoop
Greenplum属于MPP架构,和Hadoop一样都是为了解决大规模数据的并行计算而出现的技术,两者的相似点在于: 分布式存储,数据分布在多个节点服务器上分布式并行计算框架支持横向扩展来提高整体的计算能力和存储容量都支持X86开放集群架…...

OJ练习第182题——字典树(前缀树)
字典树(前缀树) 208. 实现 Trie (前缀树)题目描述示例知识补充官解代码 211. 添加与搜索单词 - 数据结构设计题目描述示例思路Java代码 208. 实现 Trie (前缀树) 力扣链接:208. 实现 Trie (前缀树) 题目描述 示例 知识补充 插入字符串 我…...

前端知识总结
在前端开发中,y x是一种常见的自增运算符的使用方式。它表示将变量x的值自增1,并将自增后的值赋给变量y。 具体来说,x是一种后缀自增运算符,表示将变量x的值自增1。而y x则是将自增前的值赋给变量y。这意味着在执行y x之后&am…...
)
中国JP-10燃料行业市场研究与预测报告(2023版)
内容简介: 高密度燃料是指以石油基、煤基和生物质基烃类为原料,通过聚合、加氢、异构等工艺合成的密度大于0.85 gcm-3的饱和多环碳氢化合物,广泛应用于航空航天领域。由于高密度燃料密度大和体积热值高等特点,飞行器在油箱体积一…...

护眼灯显色指数应达多少?眼科医生推荐灯光显色指数多少合适
台灯的显色指数是其非常重要的指标,它可以表示灯光照射到物体身上,物体颜色的真实程度,一般用平均显色指数Ra来表示,Ra值越高,灯光显色能力越强。常见的台灯显色指数最低要求一般是在Ra80以上即可,比较好的…...

AI 大模型
随着人工智能技术的迅猛发展,AI 大模型逐渐成为推动人工智能领域提升的关键因素,大模型已成为了引领技术浪潮研究和应用方向。大模型即大规模预训练模型,通常是指那些在大规模数据上进行了预训练的具有庞大规模和复杂结构的人工智能模型&…...

一个案例熟悉使用pytorch
文章目录 1. 完整模型的训练套路1.2 导入必要的包1.3 准备数据集1.3.1 使用公开数据集:1.3.2 获取训练集、测试集长度:1.3.3 利用 DataLoader来加载数据集 1.4 搭建神经网络1.4.1 测试搭建的模型1.4.2 创建用于训练的模型 1.5 定义损失函数和优化器1.6 使…...

终极ModEngine2指南:从零开始掌握魂类游戏模组引擎
终极ModEngine2指南:从零开始掌握魂类游戏模组引擎 【免费下载链接】ModEngine2 Runtime injection library for modding Souls games. WIP 项目地址: https://gitcode.com/gh_mirrors/mo/ModEngine2 想要为《黑暗之魂3》或《艾尔登法环》添加自定义内容却苦…...

利用 Taotoken 统一 API 为内部低代码平台集成 AI 能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 统一 API 为内部低代码平台集成 AI 能力 为内部低代码平台引入 AI 能力,正成为提升平台自动化和智能化水…...

Taotoken用量看板与账单追溯功能在项目复盘中的实际价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与账单追溯功能在项目复盘中的实际价值 1. 复盘场景与数据需求 在项目月度复盘会议上,技术团队经常面…...

基于STM32的太阳能热水器智能控制系统设计与实现
1. 项目概述:为什么用STM32做太阳能热水器?几年前,我接手了一个老家的太阳能热水器改造项目。那台老式设备,除了一个机械式的水温水位显示仪,几乎没有任何智能控制。夏天水温能飙到七八十度,烫得没法直接用…...

当ChIP-seq遇见单细胞:技术原理、应用场景与未来展望,一次给你讲清楚
当单细胞分辨率重塑表观遗传学:scChIP-seq的技术突破与应用全景 表观遗传学研究正经历一场分辨率革命。过去十年间,科学家们不得不依赖数百万细胞才能绘制组蛋白修饰或转录因子结合的全局图谱,这种"群体平均"的视角掩盖了细胞间异…...

3分钟告别Armoury Crate:华硕笔记本轻量化控制终极指南
3分钟告别Armoury Crate:华硕笔记本轻量化控制终极指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, E…...

【ArcGIS实战指南】利用属性连接与符号化,一键生成柱状图与饼状图
1. 从零开始:理解ArcGIS图表制作的核心逻辑 第一次接触ArcGIS的图表功能时,我也被各种专业术语搞得晕头转向。直到在西北农业干旱评估项目中,我才真正搞明白属性连接和符号化的配合使用逻辑。简单来说,这就像给地图数据"穿衣…...

3分钟完成B站缓存视频转换:m4s-converter完整使用指南
3分钟完成B站缓存视频转换:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站视频下架后&…...

别再只盯着效率了!DCDC降压芯片选型,这5个‘隐形’参数才是关键
别再只盯着效率了!DCDC降压芯片选型,这5个‘隐形’参数才是关键 在电源设计领域,工程师们往往过于关注DCDC降压芯片的效率、输入输出电压范围等基础参数,却忽略了那些真正影响系统长期稳定性和用户体验的"隐形"特性。这…...

SAP ABAP文件处理避坑指南:从FILE事务码到OPEN DATASET的完整配置流程
SAP ABAP服务器端文件处理实战:从逻辑路径配置到OPEN DATASET高阶应用 在SAP系统集成与数据交换场景中,文件处理能力直接影响着接口稳定性与运维效率。不同于常规编程语言的文件操作,ABAP环境下的服务器端文件处理涉及逻辑路径映射、平台适配…...