【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式
前言
Prompt Tuning是一种PEFT方法(Parameter-Efficient FineTune),旨在以高效的方式对LLM模型进行下游任务适配,本文简要介绍Prompt Tuning方法,希望对读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇ \nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用(https://www.zhihu.com/column/c_1265262560611299328)
微信公众号:机器学习杂货铺3号店
众所周知,当前LLM是人工智能界的香饽饽,众多厂商和研究者都希望能够在LLM上进行应用推广和研究,这就难免需要对LLM进行下游任务的适配,最理想的情况当然是可以用私有数据,进行全网络端到端的微调。但是LLM现在参数量巨大,大部分都大于6B,有些甚至达到了100B以上,即便是端到端微调都需要大量的硬件资源。 PEFT(Parameter-Efficient FineTune)旨在最高效地引入参数,探索合适的训练方式,使得LLM适配下游任务的代价最小化,而本文提到的Prompt Tuning [1] 就是这样一个工作。
在介绍这个工作之前,我们得知道什么是prompt,关于prompt的内容之前在博文[2]中曾经介绍过,简单来说,就是用某种固定的模板或者范式,尝试去让LLM去适配下游任务,从在prompt中是否提供例子的角度上看,又可以分为one-shot prompt, few-shot prompt, zero-shot prompt等。但是,在文章[3]中提到过,不同的prompt模板对性能的影响巨大,如Fig 1.所示,我们也把这种prompt称之为硬提示词(hard-prompt)。既然有『硬』的,那么就肯定有『软』的prompt,soft-prompt指的是模型可以通过学习的方式去学习出prompt模板,经典工作包括P-Tuning [3], prefix prompt [4], soft prompt [5],以及本文将会介绍到的prompt tuning [1]。

如Fig 2.所示,在prompt tuning中,在原有hard prompt模板之前拼接了若干个可学习的token,我们用 P ∈ R p × d \mathbf{P} \in \mathbb{R}^{p \times d} P∈Rp×d表示soft prompt部分,其中 p p p为拼接的token数量,用 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d 表示hard prompt部分。那么,完整的prompt可表示为 [ P ; X ] ∈ R ( p + n ) × d [\mathbf{P};\mathbf{X}] \in \mathbb{R}^{(p+n) \times d} [P;X]∈R(p+n)×d,模型的目标既变为了 P ( Y ∣ [ P ; X ] ) P(\mathbf{Y}|[\mathbf{P};\mathbf{X}]) P(Y∣[P;X])。此时,LLM的参数和embedding层的参数都是设置为不可学习的 (❄),整个网络只有soft prompt层是可学习的(🔥),这意味着微调模型需要的内存和计算代价都大大减小了 1。

只需要设置不同的soft prompt就可以适配不同的下游任务了,如Fig 3. 所示,在模型参数量足够大( ≥ 10 B \ge 10B ≥10B)的时候,采用prompt tuning的效果足以比肩全参数微调,而且所需参数量只有后者的万分之一,是名副其实的参数高效(Parameter-Efficient)方法。而不管在什么尺度的模型下,prompt tuning的结果都要远远优于hard prompt design的结果,人工设计的prompt模板确实很难与模型自己学习出来的竞争。

此外,作者在论文中还进行了更多实验去验证prompt tuning的有效性和其他特性。第一个就是soft prompt所需要的长度,如Fig 4. (a)所示,在10B模型下,20-100个soft token是一个比较合适的数量,20个token能提供最大的性价比。如何初始化这些新增的soft token embedding也是一个指的思考的问题,作者尝试了随机均匀初始化,从词表的embedding中采样,以及对于分类任务而言,用label的类别embedding进行初始化,如Fig 4. (b) 所示,随机初始化在模型参数量不够的时候(< 10B)表现,不如从词表采样和label初始化的方法,但当模型参数量足够大时,随机初始化的效果能够达到最好,优于从词表中采样的方法。考虑到本文采用的LLM是T5,而T5是一个encoder-decoder的结构,在设计预训练任务的时候采用的是span corruption + 哨兵token的形式,如:
Origin: Thank you for inviting me to your party last week
Corrupted: Thank you for [X] me to your party [Y] week
Target: [X] inviting [Y] last [Z]
这样设计预训练任务能实现encoder-decoder架构的T5高效预训练,但是这意味着模型没有见过自然语言的输入(因为输入总是有哨兵token,比如[X]/[Y]等),为了实现T5到LM的适配,在本文中作者尝试对T5进行了LM Adaptation的后训练:继续T5的少量预训练,给定自然文本作为输入,尝试预测自然语言的输出,而不是带有哨兵token的文本。 此外,作者还尝试了所谓的Span Corruption + 哨兵的方法,指的是在原T5模型基础上,在应用到下游任务预测时候,都给拼接上哨兵token,以减少下游任务和预训练任务的gap。如Fig 4. (C)所示,无论采用多大尺度的模型,采用了LM Adaptation能带来持续的增益,而Span Corruption或者Span Corruption+Sentinel的方法,则只在10B模型的尺度上能有比较好的效果(然而仍然无法超越前者)。那么LM Adaptation需要进行多少step的训练合适呢?在Fig 4. (d)中,作者进行了若干尝试,结果表明越多step将会带来越多的收益,最终作者选定在100k step。

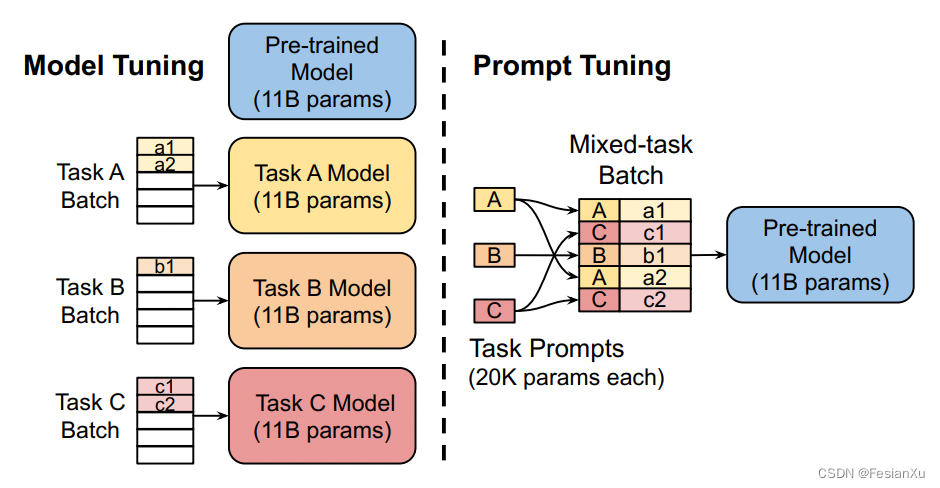
采用prompt tuning还有一个好处就是可以让多个下游任务复用同一个LLM模型。在模型微调中,对于每个下游任务都需要维护一套独立的模型,如Fig 5. 左图所示,而在prompt tuning中,则只需要维护一套静态的LLM模型,不同任务通过不同的soft prompt进行区分即可激发LLM的不同下游任务能力,如Fig 5. 右图所示,因为可以节省很多资源,这对于部署来说很友好。
Reference
[1]. Lester, Brian, Rami Al-Rfou, and Noah Constant. “The power of scale for parameter-efficient prompt tuning.” arXiv preprint arXiv:2104.08691 (2021). aka Prompt Tuning.
[2]. https://blog.csdn.net/LoseInVain/article/details/130500648, 《增强型语言模型——走向通用智能的道路?!?》
[3]. Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021. Gpt understands, too. arXiv:2103.10385. aka p-tuning
[4]. Li, Xiang Lisa, and Percy Liang. “Prefix-tuning: Optimizing continuous prompts for generation.” arXiv preprint arXiv:2101.00190 (2021). aka prefix tuning
[5]. Qin, Guanghui, and Jason Eisner. “Learning how to ask: Querying LMs with mixtures of soft prompts.” arXiv preprint arXiv:2104.06599 (2021). aka soft prompt
[6].
由于将LLM的参数设置成为了不可学习,因此在反向过程中很多参数并不需要在显存中维护。假设模型的参数量为X,那么常用的Adam优化器的两个动量就不需要维护了(减少2X),激活值通过重计算技术,已经缩减了绝大部分,并且梯度只需要传递到soft prompt部分,而不需要进行参数更新,因此梯度也可以不维护(减少X),因此所需显存减少了3X,并且减少了对参数更新的计算量。 ↩︎
相关文章:
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式
【论文极速读】Prompt Tuning——一种高效的LLM模型下游任务适配方式 FesianXu 20230928 at Baidu Search Team 前言 Prompt Tuning是一种PEFT方法(Parameter-Efficient FineTune),旨在以高效的方式对LLM模型进行下游任务适配,本…...
如何在 Elasticsearch 中使用 Openai Embedding 进行语义搜索
随着强大的 GPT 模型的出现,文本的语义提取得到了改进。 在本文中,我们将使用嵌入向量在文档中进行搜索,而不是使用关键字进行老式搜索。 什么是嵌入 - embedding? 在深度学习术语中,嵌入是文本或图像等内容的数字表示…...

世界第一ERP厂商SAP,推出类ChatGPT产品—Joule
9月27日,世界排名第一ERP厂商SAP在官网宣布,推出生成式AI助手Joule,并将其集成在采购、供应链、销售、人力资源、营销、数据分析等产品矩阵中,帮助客户实现降本增效。 据悉,Joule是一款功能类似ChatGPT的产品…...
嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理③
嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理③ 第十八章 Linux系统对中断的处理 ③18.5 编写使用中断的按键驱动程序 ③18.5.1 编程思路18.5.1.1 设备树相关18.5.1.2 驱动代码相关 18.5.2 先编写驱动程序18.5.2.1 从设备树获得 GPIO18.5.2.2 从 GPIO获得中断号18.5…...

【Python】返回指定时间对应的时间戳
使用模块datetime,附赠一个没啥用的“时间推算”功能(获取n天后对应的时间 代码: import datetimedef GetTimestamp(year,month,day,hour,minute,second,*,relativeNone,timezoneNone):#返回指定时间戳。指定relative时进行时间推算"""根…...
微服务moleculer03
1. Moleculer 目前支持SQLite,MySQL,MariaDB,PostgreSQL,MSSQL等数据库,这里以mysql为例 2. package.json 增加mysql依赖 "mysql2": "^2.3.3", "sequelize": "^6.21.3", &q…...

[React] react-router-dom的v5和v6
v5 版本既兼容了类组件(react v16.8前),又兼容了函数组件(react v16.8及以后,即hook)。v6 文档把路由组件默认接受的三个属性给移除了,若仍然使用 this.props.history.push(),此时pr…...
之mv)
Linux命令(91)之mv
linux命令之mv 1.mv介绍 linux命令mv是用来移动文件或目录,并且也可以用来更改文件或目录的名字 2.mv用法 mv [参数] src dest mv常用参数 参数说明-f强制移动,不提示 3.实例 3.1.重命名文件1.txt为ztj.txt 命令: mv 1.txt ztj.txt …...
C++ 强制类型转换(int double)、查看数据类型、自动决定类型、三元表达式、取反、
强制类型转换( int 与 double) #include <iostream> using namespace std;int main() {// 数据类型转换char c1;short s1;int n 1;long l 1;float f 1;double d 1;int p 0;int cc (int)c;// 注意:字符 转 整形时 是有问题的// “…...
Android自动化测试之MonkeyRunner--从环境构建、参数讲解、脚本制作到实战技巧
monkeyrunner 概述、环境搭建 monkeyrunner环境搭建 (1) JDK的安装不配置 http://www.oracle.com/technetwork/java/javase/downloads/index.html (2) 安装Python编译器 https://www.python.org/download/ (3) 设置环境变量(配置Monkeyrunner工具至path目彔下也可丌配置) (4) …...
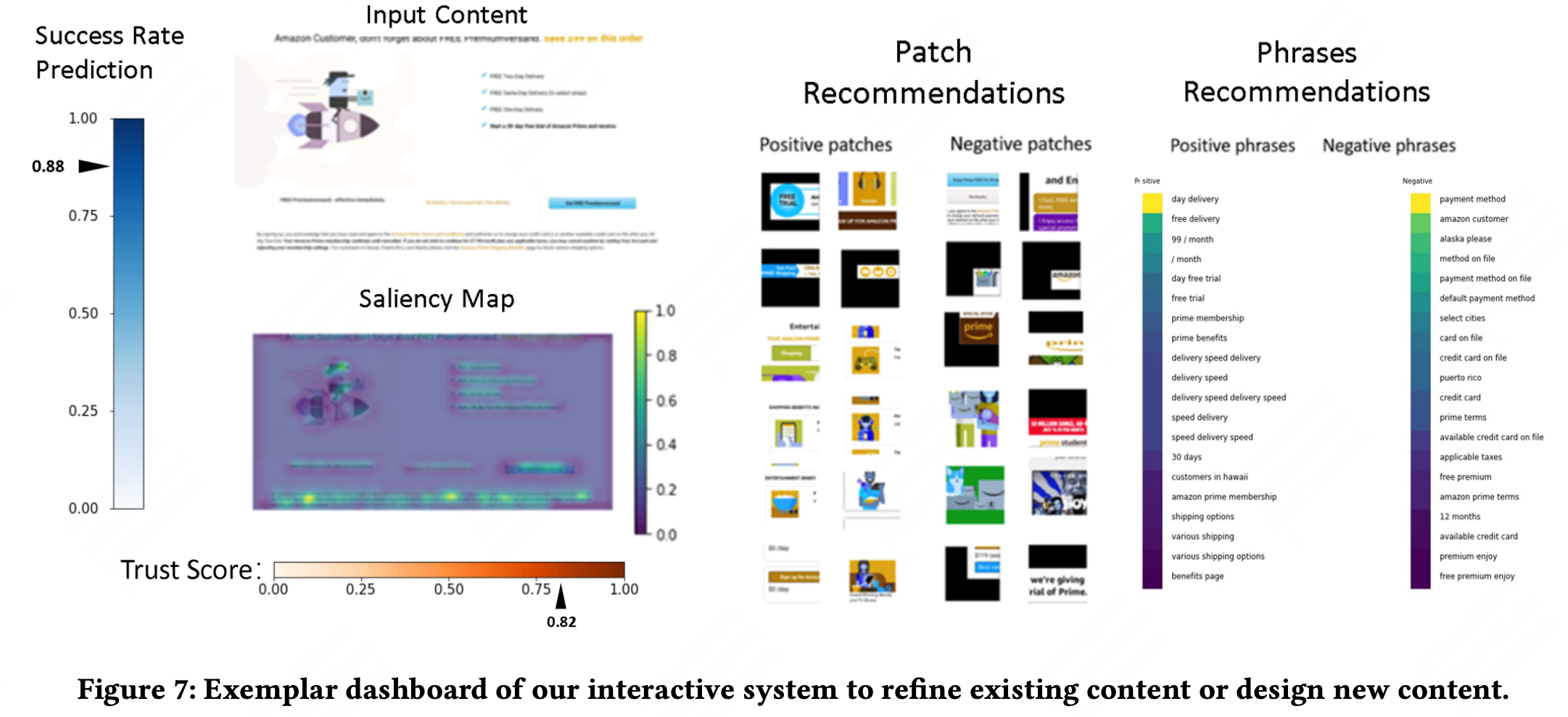
Neural Insights for Digital Marketing Content Design 阅读笔记
KDD-2023 很值得读的文章! 1 摘要 电商里,营销内容的实验,很重要。 然而,创作营销内容是一个手动和耗时的过程,缺乏明确的指导原则。 本文通过 基于历史数据的AI驱动的可行性洞察,来弥补 营销内容创作 和…...

BI神器Power Query(26)-- 使用PQ实现表格多列转换(2/3)
实例需求:原始表格包含多列属性数据,现在需要将不同属性分列展示在不同的行中,att1、att3、att5为一组,att2、att3、att6为另一组,数据如下所示。 更新表格数据 原始数据表: Col1Col2Att1Att2Att3Att4Att5Att6AAADD…...

中间件中使用到的设计模式
本文记录阅读源码的过程中,了解/学习到中间件使用到的设计模式及具体运用的组件/功能点 1. 策略模式 1. Nacos2.x中grpc处理时通过请求type来进行具体Handler映射,找到对应处理器。 2. 模板模式 1. Nacos配置数据读取,内部数据源、外部数据…...

运用动态内存实现通讯录(增删查改+排序)
目录 前言: 实现通讯录: 1.创建和调用菜单: 2.创建联系人信息和通讯录: 3.初始化通讯录: 4.增加联系人: 5.显示联系人: 6.删除联系人: 编辑 7.查找联系人: …...
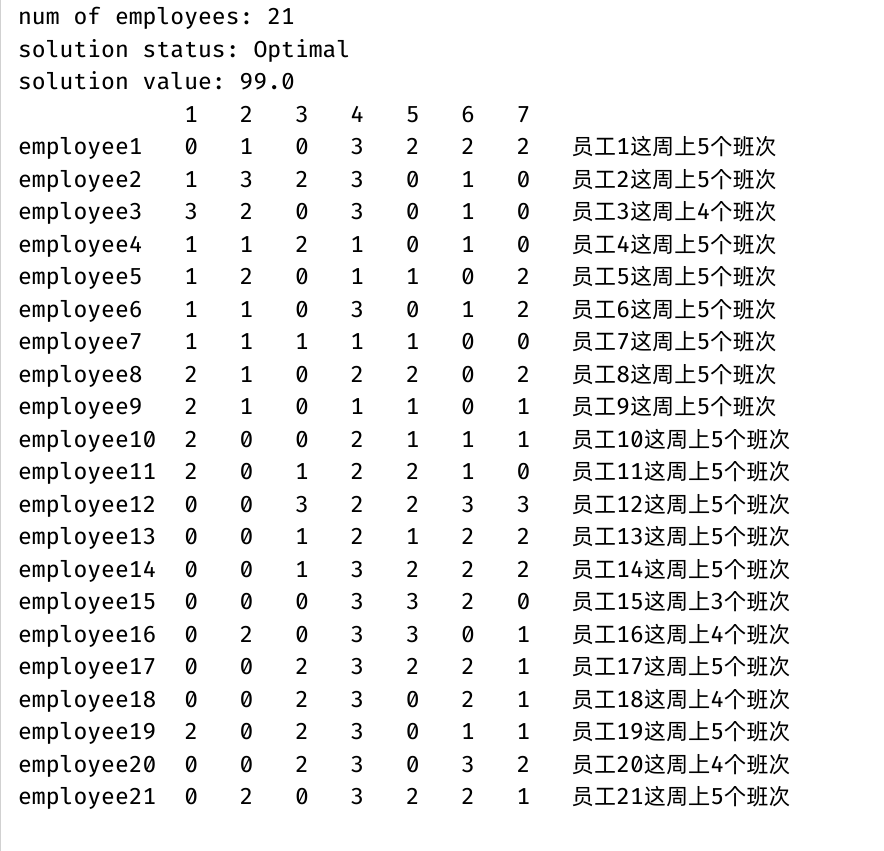
基于Cplex的人员排班问题建模求解(JavaAPI)
使用Java调用Cplex实现了阿里mindopt求解器的案例(https://opt.aliyun.com/platform/case)人员排班问题。 这里写目录标题 人员排班问题问题描述数学建模编程求解(CplexJavaAPI)求解结果 人员排班问题 随着现在产业的发展&#…...

理解Go中的数据类型
引言 数据类型指定了编写程序时特定变量存储的值的类型。数据类型还决定了可以对数据执行哪些操作。 在本文中,我们将介绍Go的重要数据类型。这不是对数据类型的详尽研究,但将帮助您熟悉Go中可用的选项。理解一些基本的数据类型能让你写出更清晰、性能…...
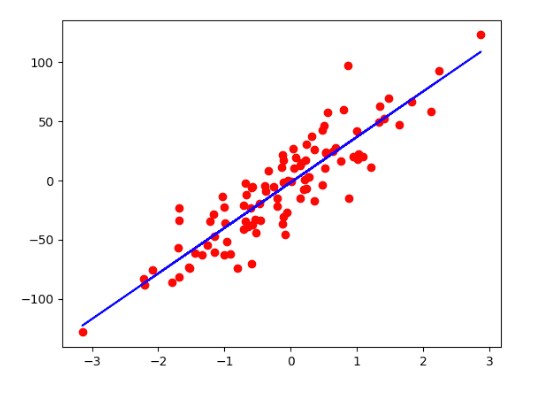
【人工智能导论】线性回归模型
一、线性回归模型概述 线性回归是利用函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。简单来说,就是试图找到自变量与因变量之间的关系。 二、线性回归案例:房价预测 1、案例分析 问题:现在要预测140平方的房屋的价格&…...
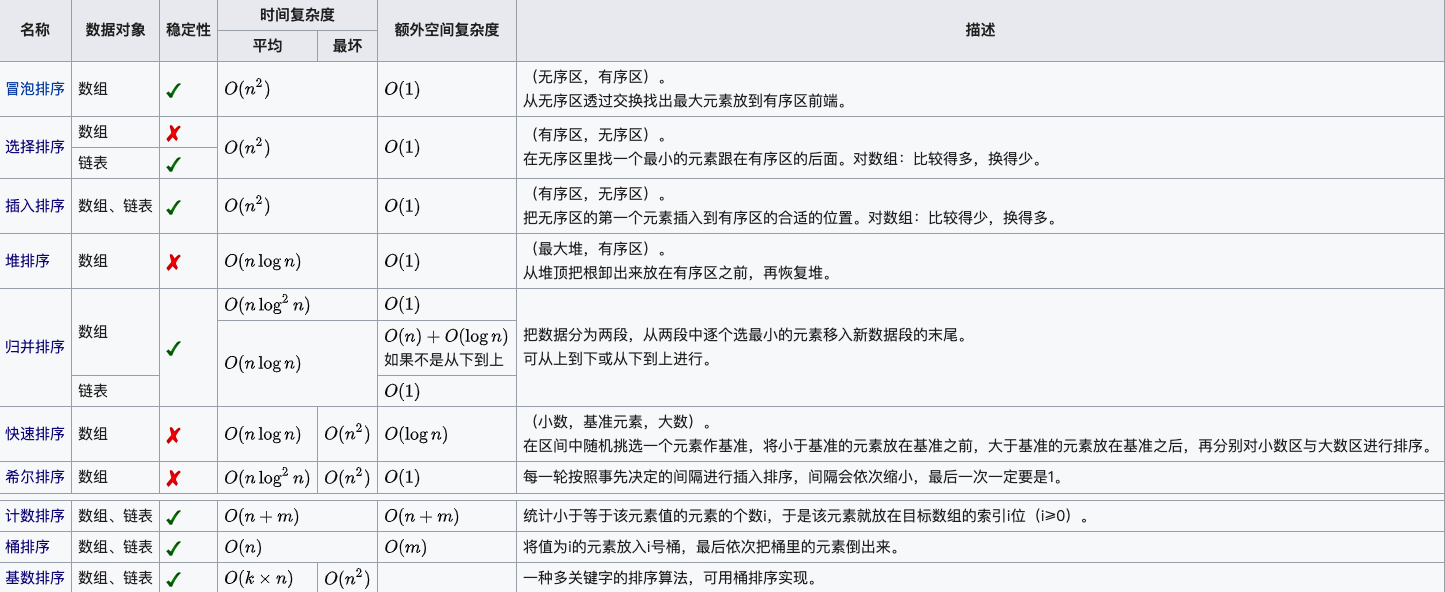
十大常见排序算法详解(附Java代码实现和代码解析)
文章目录 十大排序算法⛅前言🌱1、排序概述🌴2、排序的实现🌵2.1 插入排序🐳2.1.1 直接插入排序算法介绍算法实现 🐳2.1.2 希尔排序算法介绍算法实现 🌵2.2 选择排序🐳2.2.1 选择排序算法介绍算…...
在Ubuntu上通过Portainer部署微服务项目
这篇文章主要记录自己在ubuntu上部署自己的微服务应用的过程,文章中使用了docker、docker-compose和portainer,在部署过程中遇到了不少问题,因为博主也是初学docker-compose,通过这次部署实战确实有所收获,在这篇文章一…...
软件测试基础学习
注意: 各位同学们,今年本人求职目前遇到的情况大体是这样了,开发太卷,学历高的话优势非常的大,公司会根据实际情况考虑是否值得培养(哪怕技术差一点);学历稍微低一些但是技术熟练的…...

LeetCode 2946. 循环移位后的矩阵相似检查【数学周期性+原地比较】简单
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...

从“连连看”到DFA最小化:一个游戏化思路帮你彻底理解状态等价
从“连连看”到DFA最小化:用游戏化思维破解编译原理难题 编译原理作为计算机科学的核心课程之一,常常让初学者望而生畏。特别是当教材开始讨论"确定性有限自动机(DFA)最小化"这类概念时,那些抽象的状态转换图…...

动态规划详解:从入门到精通,这四个案例让你彻底掌握DP思想
面试必考、算法进阶的核心,一篇文章帮你打通任督二脉在算法学习的过程中,动态规划(Dynamic Programming,简称DP)绝对是让很多人头疼的一个难点。很多初学者看到DP问题就发怵,其实只要掌握了核心思想&#x…...

Hunyuan-MT-7B实战教程:OpenWebUI插件开发——添加术语库与记忆功能
Hunyuan-MT-7B实战教程:OpenWebUI插件开发——添加术语库与记忆功能 1. 项目背景与目标 Hunyuan-MT-7B作为腾讯混元开源的70亿参数多语翻译模型,在WMT2025竞赛中斩获30项第一,支持33种语言双向互译,包括5种中国少数民族语言。这…...

开源视觉模型推荐:GLM-4v-9B,高分辨率输入,中文OCR领先
开源视觉模型推荐:GLM-4v-9B,高分辨率输入,中文OCR领先 1. 引言 在当今多模态AI快速发展的时代,视觉-语言模型正成为技术前沿的热点。GLM-4v-9B作为智谱AI最新开源的90亿参数视觉-语言多模态模型,凭借其11201120高分…...
)
基于三菱PLC与MCGS组态的农田智能灌溉系统说明(两万字)
基于三菱PLC农田灌溉 包含说明一万 和MCGS组态农田智能灌溉系统说明一万前阵子回豫东老家帮我叔打理那三亩秋月梨果园,那浇地给我整得怀疑人生——三伏天顶着三十七八度的太阳,扛着铁锹跑遍地头开电磁阀,中午热得头晕就算了,晚上还…...

Hunyuan-HY-MT1.8B性能报告解读:380ms处理500token实测
Hunyuan-HY-MT1.8B性能报告解读:380ms处理500token实测 1. 测试背景与模型简介 腾讯混元团队最新发布的HY-MT1.5-1.8B翻译模型,以其轻量级架构和卓越性能引起了广泛关注。这个仅有18亿参数的模型,在保持高质量翻译效果的同时,实…...

Docker 部署 Vaultwarden:轻量级自托管密码管理解决方案
1. 为什么选择Vaultwarden作为自托管密码管理方案 在这个数字时代,我们每个人平均要管理超过100个在线账户的密码。传统的密码管理方式——用同一个简单密码注册所有网站,或者把密码写在记事本上——已经远远不能满足安全需求。这就是为什么像Bitwarden这…...

OpenClaw大模型API怎么选?Kimi与DeepSeek实测指南
最适配 OpenClaw 的大模型 API 是哪个?四款模型实测对比与选型指南(2026年3月) OpenClaw 内置 ReAct Agent 架构,通过工具调用(Tool Use)驱动 Shell 执行、文件操作、浏览器控制、截图等自动化任务。模型的…...

Clawdbot网关配置教程:实现Qwen3-VL:30B与飞书的无缝对接
Clawdbot网关配置教程:实现Qwen3-VL:30B与飞书的无缝对接 1. 准备工作与环境概述 在开始配置前,请确保已完成以下准备工作: 已在CSDN星图AI云平台完成Qwen3-VL:30B的私有化部署(参考上篇教程)拥有飞书开放平台的企业…...