文本分词排序
文本分词
在这个代码的基础上
把英语单词作为一类汉语,作为一类然后列出选项
1. 大小排序
2. 小大排序
3. 不排序打印保存
代码
import jieba# 输入文本,让我陪你聊天吧~
lines = []
print("请输入多行文本,以\"2333.3\"结束:")
while True:line = input()if line == "2333.3":breaklines.append(line)# 对每行文本进行分词和去重,将文字拆拆拆~
words = []
for line in lines:seg_list = jieba.cut(line) # 分词,把文字切得精精致致~for word in seg_list:words.append(word) # 把词拼起来,组成一个个小秘密~# 将英文单词作为一类,给中英文都一个舞台~
new_words = []
for word in words:if word.isalpha():new_words.append(word.lower()) # 英文小写,不分大小~else:new_words.append(word) # 中文就这样保留~# 选项控制排序:1. 大小排序 2. 小大排序 3. 不排序,看你喜欢哪种节奏~
option = input("请选择排序方式(输入对应数字1/2/3):")
if option == "1":new_words.sort(key=lambda w: (not w.isalpha(), w)) # 选了1,大小排序,这个节奏有点嗨~
elif option == "2":new_words.sort(key=lambda w: (not w.isalpha(), w), reverse=True) # 选了2,小大排序,调皮一点~
elif option != "3":print("无效选项!默认不排序。") # 嘘~别乱点哦~# 原文和分词结果打印,让我们揭开神秘的面纱~
print("原文:")
for line in lines:print(line)print("\n分词结果:")
for word in new_words:print(word)# 保存为txt文件,让文字在电子世界里流传~
file_name = input("请输入文件名(不需要加后缀):")
if file_name.strip() == "":file_name = "编号. 第1个分词词语 时间戳"file_path = "/storage/emulated/0/数据中心/txt/" + file_name + ".txt"
with open(file_path, "w", encoding="utf-8") as f:# 写入原文f.write("原文:\n")for line in lines:f.write(line + "\n")# 写入分词结果f.write("\n分词结果:\n")for word in new_words:f.write(word + "\n")print("文件保存成功!路径:%s" % file_path) # 保存完毕,请查收~
新添加的内容是将英语单词作为一类汉语,并进行排序。选项控制排序方式,可选择1. 大小排序 2. 小大排序 3. 不排序,默认选项为3. 不排序。
请注意,英语单词将转换为小写形式,如需保留原始大小写,
# 根据选项决定是否将英文单词转换为小写形式,并保留原始大小写
option = input("请选择选项:\n1. 将所有英文单词转换为小写形式\n2. 保留英文单词的原始大小写\n请选择选项(输入对应数字1/2): ")
if option == "1":new_words = [word.lower() if word.isalpha() else word for word in words] # 选了1,将所有英文单词都转换为小写形式
elif option == "2":new_words = words # 选了2,保留英文单词的原始大小写
else:print("无效选项!默认将所有英文单词转换为小写形式。")new_words = [word.lower() if word.isalpha() else word for word in words] # 嘘,别乱选哦~修改后的代码~
import jieba# 输入文本,让我陪你聊天吧~
lines = []
print("请输入多行文本,以\"2333.3\"结束:")
while True:line = input()if line == "2333.3":breaklines.append(line)# 对每行文本进行分词和去重,将文字拆拆拆~
words = []
for line in lines:seg_list = jieba.cut(line) # 使用jieba库进行分词for word in seg_list:words.append(word) # 添加分词的结果# 根据选项决定是否将英文单词转换为小写形式,并保留原始大小写
option = input("请选择选项:\n1. 将所有英文单词转换为小写形式\n2. 保留英文单词的原始大小写\n请选择选项(输入对应数字1/2): ")
if option == "1":new_words = [word.lower() if word.isalpha() else word for word in words] # 将所有英文单词转换为小写形式
elif option == "2":new_words = words # 保留英文单词的原始大小写
else:print("无效选项!默认将所有英文单词转换为小写形式。")new_words = [word.lower() if word.isalpha() else word for word in words] # 默认将所有英文单词转换为小写形式# 将分词结果排序:1. 大小排序 2. 小大排序 3. 不排序,看你喜欢哪种节奏~
option = input("请选择排序方式(输入对应数字1/2/3):")
if option == "1":new_words.sort(key=lambda w: (not w.isalpha(), w)) # 大小排序
elif option == "2":new_words.sort(key=lambda w: (not w.isalpha(), w), reverse=True) # 小大排序
elif option != "3":print("无效选项!默认不排序。") # 默认不排序# 打印原文和分词结果
print("原文:")
for line in lines:print(line)print("\n分词结果:")
for word in new_words:print(word)# 保存为txt文件
file_name = input("请输入文件名(不需要加后缀):")
if file_name.strip() == "":file_name = "编号. 第1个分词词语 时间戳"file_path = "/storage/emulated/0/数据中心/txt/" + file_name + ".txt"
with open(file_path, "w", encoding="utf-8") as f:# 写入原文f.write("原文:\n")for line in lines:f.write(line + "\n")# 写入分词结果f.write("\n分词结果:\n")for word in new_words:f.write(word + "\n")print("文件保存成功!路径:%s" % file_path) # 文件保存成功提示相关文章:

文本分词排序
文本分词 在这个代码的基础上 把英语单词作为一类汉语,作为一类然后列出选项 1. 大小排序 2. 小大排序 3. 不排序打印保存代码 import jieba# 输入文本,让我陪你聊天吧~ lines [] print("请输入多行文本,以\"2333.3\"结束&am…...

SQL与关系数据库基本操作
SQL与关系数据库基本操作 文章目录 第一节 SQL概述一、SQL的发展二、SQL的特点三、SQL的组成 第二节 MySQL预备知识一、MySQL使用基础二、MySQL中的SQL1、常量(1)字符串常量(2)数值常量(3)十六进制常量&…...
【2023年11月第四版教材】第18章《项目绩效域》(第一部分)
第18章《项目绩效域》(第一部分) 1 章节内容2 干系人绩效域2.1 绩效要点2.2 执行效果检查2.3 与其他绩效域的相互作用 3 团队绩效域3.1 绩效要点3.2 与其他绩效域的相互作用3.3 执行效果检查3.4 开发方法和生命周期绩效域 4 绩效要点4.1 与其他绩效域的相…...
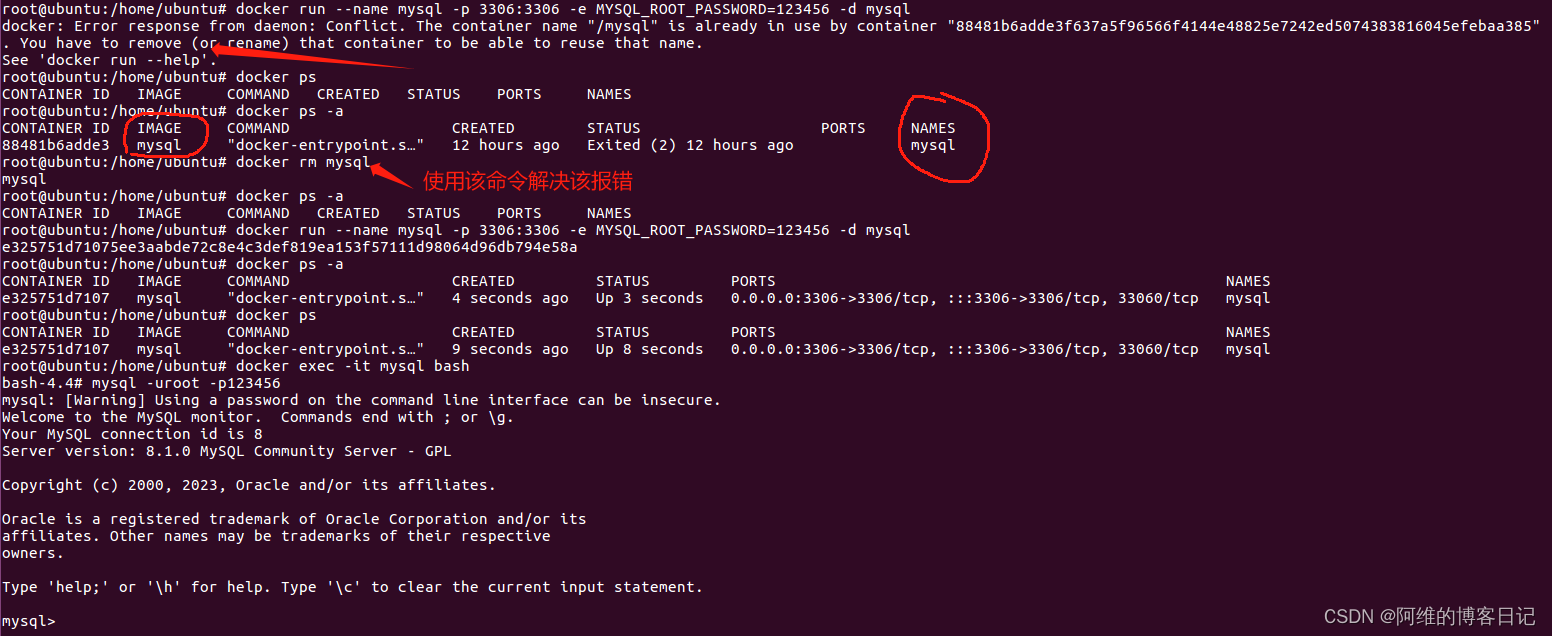
Docker启动Mysql
如果docker里面没有mysql需要先pull一个mysql镜像 docker pull mysql其中123456是mysql的密码 docker run --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD123456 -d mysql可以使用如下命令进入Mysql的命令行界面 docker exec -it mysql bash登录mysql使用如下命令,root是…...

QScrollArea样式
简介 QScrollBar垂直滚动条分为sub-line、add-line、add-page、sub-page、up-arrow、down-arrow和handle几个部分。 QScrollBar水平滚动条分为sub-line、add-line、add-page、sub-page、left-arrow、right-arrow和handle几个部分。 部件如下图所示: 样式详…...
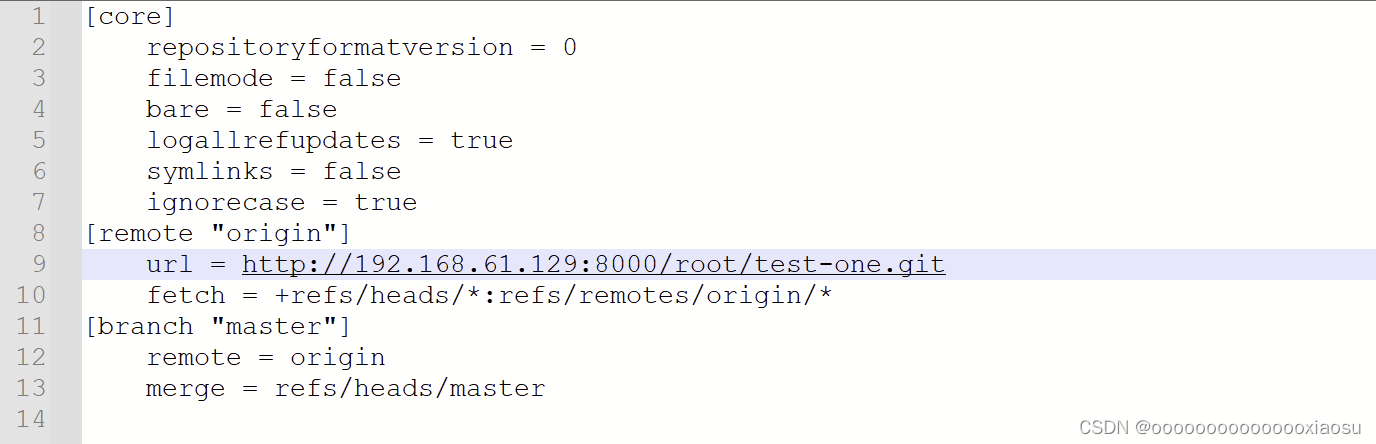
【gitlab】git push -u origin master 报403
问题描述 gitlab版本:14.0.5 虚拟机版本:centos7 项目:renren-fast 原因分析 .git -> config目录下 url配错 但这个url不是手动配置的,还不知道怎么生成。 解决方法 把配置错误的url改成gitlab的project的url 这样&#…...

第二篇:矩阵的翻转JavaScript
一维数组的翻转 // 一维矩阵翻转 // 实例: arr [1,2,3,4,5] > [5,4,3,2,1] let n readline() let arr readline().split( ).map(Number) // console.log(n,arr) let temp 0 for(let i 0; i < n/2;i){temp arr[i]arr[i] arr[n-i-1]arr[n-i-1] temp }…...
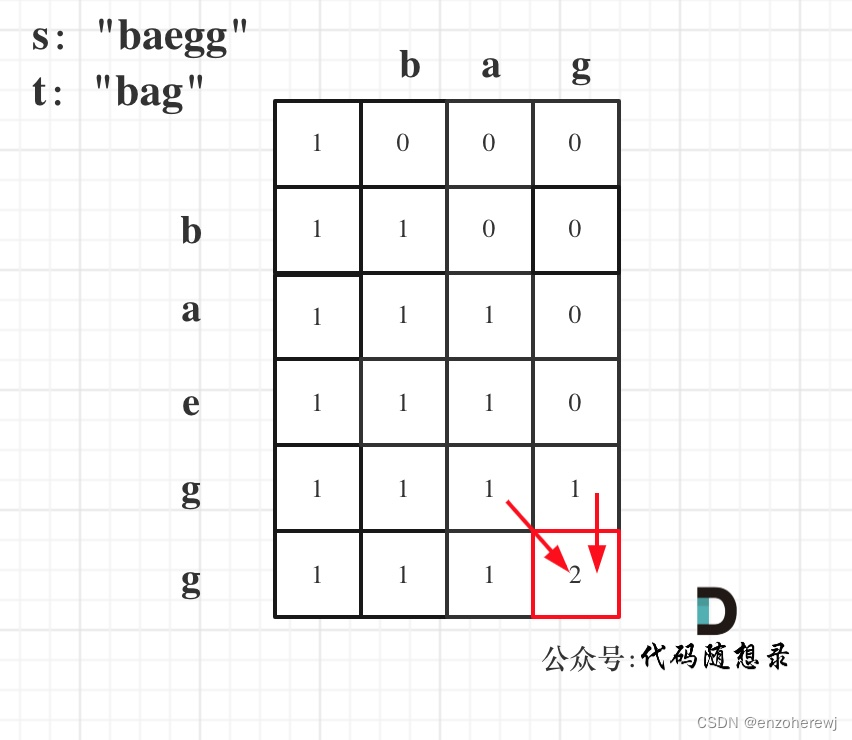
代码随想录算法训练营第五十七天 | 动态规划 part 15 | 392.判断子序列、115.不同的子序列
目录 392.判断子序列思路代码 115.不同的子序列思路代码 392.判断子序列 Leetcode 思路 dp[i][j] 表示以下标i-1为结尾的字符串s,和以下标j-1为结尾的字符串t,相同子序列的长度为dp[i][j]递推公式: 初始化:为0遍历顺序ÿ…...

【国漫逆袭】人气榜,小医仙首次上榜,霍雨浩排名飙升,不良人热度下降
Hello,小伙伴们,我是小郑继续为大家深度解析国漫资讯。 为了提升作品和角色的讨论度,增加平台的用户活跃度,小企鹅推出了动漫角色榜,该榜单以【年】【周】【日】为单位,通过角色的点赞量和互动量进行排名 上周的动漫角…...

国庆中秋特辑(七)Java软件工程师常见20道编程面试题
以下是中高级Java软件工程师常见编程面试题,共有20道。 如何判断一个数组是否为有序数组? 答案:可以通过一次遍历,比较相邻元素的大小。如果发现相邻元素的大小顺序不对,则数组不是有序数组。 public boolean isSort…...
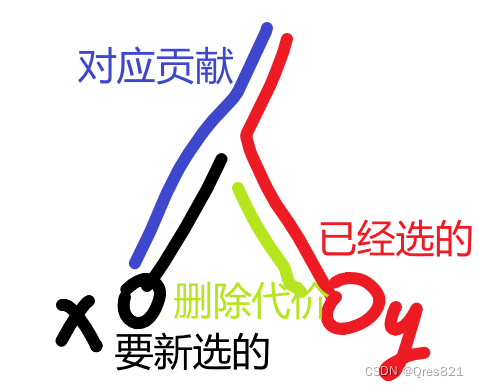
长剖与贪心+树上反悔贪心:1004T4
长剖的本质是一种贪心。(启发式合并本质也是类似哈夫曼树的过程) 在此题中,首先肯定变直径,然后选端点为根。然后选叶子。而每个叶子为了不重复计算,可以只计算其长剖后所在链的贡献。(本题精髓࿰…...

二叉树经典例题
前言: 本文主要讲解了关于二叉树的简单经典的例题。 因为二叉树的特性,所以关于二叉树的大部分题目,需要利用分治的思想去递归解决问题。 分治思想: 把大问题化简成小问题(根节点、左子树、右子树)&…...

什么是指针的指针和指向函数的指针?
理解指针的指针和指向函数的指针对于C语言初学者来说可能会有些挑战,但它们都是非常重要的概念,可以帮助你更好地理解和利用C语言的强大功能。在本文中,我将详细解释这两个概念,包括它们的概念、用途和示例。 指针的指针…...
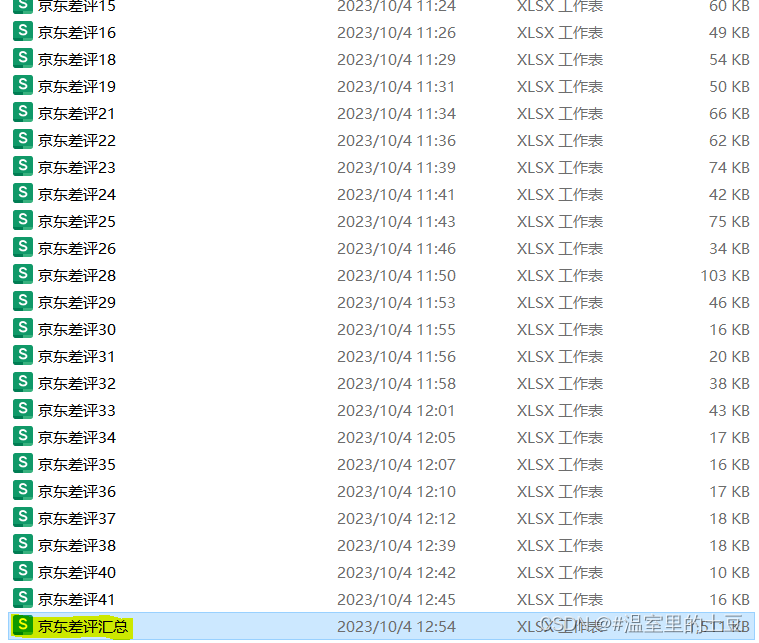
多个excel合并
目的:将同一个文件下的多个 “京东差评.xlsx” 合并为一个:“京东汇总.xlsx" 代码如下: # -*- coding: utf-8 -*- """ Created on Wed Oct 4 12:52:32 2023author: 64884 """import pandas as pd impor…...
Integrity Plus for Mac,保障网站链接无忧之选
在如今数字化的时代,网站链接的完整性对于用户体验和搜索引擎排名至关重要。如果您是一位网站管理员或者经常需要检查网站链接的人,那么Integrity Plus for Mac(Integrity Plus)将成为您最好的伙伴。 Integrity Plus是一款专业的…...

C#,数值计算——Sobol拟随机序列的计算方法与源程序
1 文本格式 using System; using System.Collections.Generic; namespace Legalsoft.Truffer { /// <summary> /// Sobol quasi-random sequence /// </summary> public class Sobol { public Sobol() { } public static void sobseq(int n,…...

以太网协议介绍(ARP、UDP、ICMP、IP)
以太网协议介绍 一、ARP协议 请求: 应答: ARP协议: 0x0001 0x0800 6 4硬件类型:2个字节,arp协议不仅能在以太网上运行还能在其他类型的硬件上运行。以太网用1来表示; 协议类型:两字节。指的是a…...

【C++】STL详解(十)—— 用红黑树封装map和set
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:C学习 🎯长路漫漫浩浩,万事皆有期待 上一篇博客:【C】STL…...

Android学习之路(17) Android Adapter详解
Adapter基础讲解 本节引言 从本节开始我们要讲的UI控件都是跟Adapter(适配器)打交道的,了解并学会使用这个Adapter很重要, Adapter是用来帮助填充数据的中间桥梁,简单点说就是:将各种数据以合适的形式显示到view上,提供 给用户看…...

实验室超声波萃取技术的原理和特点是什么?
梵英超声(fanyingsonic)实验室超声波清洗机 超声波萃取中药材的优越性源于超声波的特殊物理性质。通过压电换能器产生的快速机械振动波,超声波可减少目标萃取物与样品基体之间的作用力,从而实现固液萃取分离。 (1)加速介质质点运…...

紧急通知:v8.1即将关闭旧版审美缓存——72小时内必须完成的3步风格校准清单
更多请点击: https://intelliparadigm.com 第一章:v8.1旧版审美缓存关停的技术动因与全局影响 核心架构演进压力 V8.1 引擎中长期运行的“审美缓存”(Aesthetic Cache)模块,本质上是一套基于 DOM 树节点样式偏好建模…...

Python实时通信实战:Flask-SocketIO深度解析
Python实时通信实战:Flask-SocketIO深度解析 引言 在Python开发中,实时通信是构建现代Web应用的核心技术。作为一名从Rust转向Python的后端开发者,我深刻体会到Flask-SocketIO在实时通信方面的优势。Flask-SocketIO为Flask应用提供了WebSocke…...
从零构建Claude代码:深入Transformer架构与自回归生成实现
1. 项目概述:从零构建你自己的Claude代码最近在开发者社区里,一个名为“woodx9/build-your-claude-code-from-scratch”的项目引起了我的注意。这个标题直译过来就是“从零开始构建你的Claude代码”,它指向了一个非常具体且富有挑战性的目标&…...

【模块化设计-14】深入解析 RT-Thread syswatch 系统监控模块:保障系统稳定的核心卫士
在嵌入式系统开发中,系统的稳定性是重中之重。RT-Thread 提供的 syswatch(系统监控)模块,专为解决线程异常阻塞、保障系统持续运行设计。本文将从模块设计理念、核心功能、配置项、工作流程到实际测试,全方位解析 sysw…...

AI应用开发与AI Agent开发:小白程序员必备技能,收藏学习迎高薪未来!
本文介绍了AI应用开发和AI Agent开发的核心概念和区别,通过传统后端开发、AI应用开发和AI Agent开发三个场景的对比,阐述了AI技术如何赋能产品和服务。AI应用开发是将大模型能力嵌入产品,而AI Agent开发则是让大模型自主完成任务。文章还结合…...

B站成分检测器:3分钟快速安装指南,智能识别评论区用户真实身份
B站成分检测器:3分钟快速安装指南,智能识别评论区用户真实身份 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分,支持动态和关注识别以及手动输入 UID 识别 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-comme…...

Android自动化测试代理droidrun-agent:架构、原理与实战部署
1. 项目概述:一个面向Android应用的自动化测试代理在移动应用开发,尤其是Android生态中,自动化测试是保证应用质量、提升迭代效率的基石。无论是回归测试、兼容性测试还是性能压测,一套稳定、高效的自动化框架都至关重要。然而&am…...

FCOS训练自己的数据?从Labelme标注到VOC格式转换,这份避坑指南请收好
FCOS训练自定义数据集:从Labelme标注到VOC格式的完整避坑指南 当你已经用Labelme完成了图像标注,却卡在数据格式转换这一步时,这篇文章将成为你的救星。FCOS作为一款优秀的全卷积目标检测模型,对输入数据格式有着严格的要求&#…...

Installing the classic Jupyter Notebook interface
简单来说,Jupyter Notebook 是一个基于网页的编程环境,让你可以: 边写代码边运行:可以一次只运行一小段代码,而不是整个程序 混合显示:代码、运行结果(包括图表、图片)、文字说明可…...

模型下载与转换实战:从HuggingFace到GGUF/SafeTensors,格式、量化与校验全解析
系列导读 你现在看到的是《本地大模型私有化部署与优化:从入门到生产级实战》的第 2/10 篇,当前这篇会重点解决:让你不再被模型格式和量化选项搞晕,确保下载和转换过程零失败。 上一篇回顾:第 1 篇《本地大模型部署前夜:硬件选型、环境搭建与框架对比(Ollama/vLLM/Lla…...