Python3数据科学包系列(三):数据分析实战

Python3中类的高级语法及实战
Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案
Python3数据科学包系列(一):数据分析实战
Python3数据科学包系列(二):数据分析实战
Python3数据科学包系列(三):数据分析实战
国庆中秋宅家自省: Python在Excel中绘图尝鲜
一: 数据分析与挖掘认知升维
我们知道在数据分析与数据挖掘中,数据处理是一项复杂且繁琐的工作,同时也是整个数据分析过程中的最为重要的环节;数据处理一方面能提供数据的质量;另一方面能让数据更好的使用数据分析工具;
数据处理的主要内容包括:
(1) 数据清洗
1.1 重复值处理
1.2 缺少值处理
(2) 数据的抽取
2.1 字段抽取
2.2 字段拆分
2.3 重置索引
2.4 记录抽取
2.5 随机抽样
2.6 通过索引抽取数据
2.7 字典数据抽取
2.8 插入数据
2.9 修改数据记录
(3) 数据交换
3.1 交换行与列
3.2 排名索引
3.3 数据合并
(4) 数据计算
4.1 简单计算 (加,减,乘,除的计算)
4.2 数据标准化
4.3 数据分组
4.4 日期处理
....................
(5) 数据可视化
5.1 图表化
5.2 Excel|Word|PPT化
二:数据处理
数据清洗认知升级:在数据分析时,海量的原始数据中存在大量不完整,不一致,有异常的数据,严重影响到数据分析的结果;索引进行数据清洗很重要,数据清洗是数据价值链中最关键的步骤。垃圾数据,即使是通过最好的分析,也将产生错误的结果,并误导业务本身.因此在数据分析过程中.数据清洗占据很大的工作量数据清洗就是处理缺失的数据以及清除无意义的信息,如删除原始数据集中的无关数据,重复数据,平滑噪声数据,筛选掉与分析主题无关的数据,处理缺失值,异常值等
数据清洗:一: 重复值的处理二: 缺失的处理
实例一:重复数据处理
# -*- coding:utf-8 -*-import pandas as pd from pandas import Series"""数据清洗认知升级:在数据分析时,海量的原始数据中存在大量不完整,不一致,有异常的数据,严重影响到数据分析的结果;索引进行数据清洗很重要,数据清洗是数据价值链中最关键的步骤。垃圾数据,即使是通过最好的分析,也将产生错误的结果,并误导业务本身.因此在数据分析过程中.数据清洗占据很大的工作量数据清洗就是处理缺失的数据以及清除无意义的信息,如删除原始数据集中的无关数据,重复数据,平滑噪声数据,筛选掉与分析主题无关的数据,处理缺失值,异常值等数据清洗:一: 重复值的处理二: 缺失的处理 """print("""(1)重复值的处理利用DataFrame中的duplicated方法返回一个布尔型的Series,展示是否有重复行,没有重复的行显示FALSE;有重复的则从第二行起均显示为TRUE(2)使用drop_duplicates方法用于把数据结构中行相同的数据去除(只保留一行),该方法返回一个DataFrame的数据框 """) dataFrame = pd.DataFrame({'age': Series([26, 85, 64, 85, 85]),'name': Series(['Ben', 'John', 'Jerry', 'John', 'John']) }) print(dataFrame) # 显示那些行有重复 repeatableDataFrame = dataFrame.duplicated() print() print(repeatableDataFrame) print("""去掉重复的行 """) print("查看name列重复行") print(dataFrame.duplicated('name')) print() print("查看age列重复行") print(dataFrame.duplicated('age')) print() print("根据age列去掉重复的行数") print(dataFrame.drop_duplicates('age'))print() print("根据name列去掉重复的行数") print(dataFrame.drop_duplicates('name'))
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\dataanalysis\DataAnalysisDataCleaning.py
(1)重复值的处理
利用DataFrame中的duplicated方法返回一个布尔型的Series,展示是否有重复行,没有重复的行显示FALSE;
有重复的则从第二行起均显示为TRUE
(2)使用drop_duplicates方法用于把数据结构中行相同的数据去除(只保留一行),该方法返回一个DataFrame的数据框age name
0 26 Ben
1 85 John
2 64 Jerry
3 85 John
4 85 John0 False
1 False
2 False
3 True
4 True
dtype: bool去掉重复的行
查看name列重复行
0 False
1 False
2 False
3 True
4 True
dtype: bool查看age列重复行
0 False
1 False
2 False
3 True
4 True
dtype: bool根据age列去掉重复的行数
age name
0 26 Ben
1 85 John
2 64 Jerry根据name列去掉重复的行数
age name
0 26 Ben
1 85 John
2 64 JerryProcess finished with exit code 0
三: 缺失值处理
认知升维从统计上说,缺失的数据可能会产生有偏估计,从而导致样本数据不能很好地代表总体,而现实中绝大部分数据都包含缺失值,因此如何处理缺失值很重要。一般来说,缺失值的处理包括两个步骤:(1)缺失数据的识别(2)缺失数据的处理
# -*- coding:utf-8 -*-import pandas as pd from pandas import Series"""认知升维从统计上说,缺失的数据可能会产生有偏估计,从而导致样本数据不能很好地代表总体,而现实中绝大部分数据都包含缺失值,因此如何处理缺失值很重要。一般来说,缺失值的处理包括两个步骤:(1)缺失数据的识别(2)缺失数据的处理 """print("读取数据来源: ") dataFrame = pd.read_excel(r'./file/rz.xlsx', sheet_name='Sheet2') print(dataFrame)print("""1)缺失值的识别Pandas使用浮点值NaN表示浮点数和非浮点数组里的缺失数据,并使用.isnull和.notnull函数来判断缺失情况 """) print() print("缺失值判断;True表示缺失,False表示非缺失") print(dataFrame.isnull())print() print("缺失值判断;True表示非缺失,False表示缺失") print(dataFrame.notnull())print("""2)缺失值处理对于缺失数据的处理方式有数据补齐,删除对应行,不处理等方式2.1 dropna()去除数据结构中值为空的数据行2.2 fillna()用其他数替代NaN;有的时候直接删除空数据会影响分析结果,可以对数据进行填补2.3 fillna(method = 'pad')用前一个数据值代替NaN """)print("删除数据为空所对应的行: ") print(dataFrame.dropna()) print() print("使用数值或者任意字符替代缺失值:") print(dataFrame.fillna("$")) print() print("用前一个值替换缺失的值: ") print(dataFrame.fillna(method='pad'))print() print("用后一个值替换缺失的值:") print(dataFrame.fillna(method='bfill'))print() print("用平均数或者其它描述性统计量替代NaN") print(dataFrame.fillna(dataFrame.mean(numeric_only=True)))print() print("""dataFrame.mean()['填补列名':'计算均值的列名']:可以使用选择列的均值进行缺失值的处理 """)print(dataFrame.fillna(dataFrame.mean(numeric_only=True)['高代':'解几'])) print() print("dataFrame.fillna({'列名1':值1,'列名2':值2}): 可以传入一个字典,对不同的列填充不同的值") print(dataFrame.fillna({'数分': 100, '高代': 0}))print("使用strip()清除字符串左,右或首尾指定的字符串,默认为空格,中间不清除") dataFrameStrip = pd.DataFrame({'age': Series([26, 85, 64, 85, 85]),'name': Series(['Ben', 'John ', 'Jerry', 'John ', ' John']) }) print(dataFrameStrip) print() print(dataFrameStrip['name'].str.strip())print() print("只删除右边的字符n,如果不指定删除的字符串,默认删除空格") print(dataFrameStrip['name'].str.rstrip()) print() print(dataFrameStrip['name'].str.rstrip('n'))print() print("只删除左边的字符n,如果不指定删除的字符串,默认删除空格") print(dataFrameStrip['name'].str.lstrip()) print() print(dataFrameStrip['name'].str.lstrip('J'))
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\dataanalysis\DataAnalysisDataMissing.py
读取数据来源:
学号 姓名 英语 数分 高代 解几
0 2308024241 成龙 76 40.0 23.0 60
1 2308024244 周怡 66 47.0 47.0 44
2 2308024251 张波 85 NaN 45.0 60
3 2308024249 朱浩 65 72.0 62.0 71
4 2308024219 封印 73 61.0 47.0 46
5 2308024201 迟培 60 71.0 76.0 71
6 2308024347 李华 67 61.0 65.0 78
7 2308024307 陈田 76 69.0 NaN 69
8 2308024326 余皓 66 65.0 61.0 71
9 2308024219 封印 73 61.0 47.0 461)缺失值的识别
Pandas使用浮点值NaN表示浮点数和非浮点数组里的缺失数据,并使用.isnull和.notnull函数来判断缺失情况
缺失值判断;True表示缺失,False表示非缺失
学号 姓名 英语 数分 高代 解几
0 False False False False False False
1 False False False False False False
2 False False False True False False
3 False False False False False False
4 False False False False False False
5 False False False False False False
6 False False False False False False
7 False False False False True False
8 False False False False False False
9 False False False False False False缺失值判断;True表示非缺失,False表示缺失
学号 姓名 英语 数分 高代 解几
0 True True True True True True
1 True True True True True True
2 True True True False True True
3 True True True True True True
4 True True True True True True
5 True True True True True True
6 True True True True True True
7 True True True True False True
8 True True True True True True
9 True True True True True True2)缺失值处理
对于缺失数据的处理方式有数据补齐,删除对应行,不处理等方式
2.1 dropna()去除数据结构中值为空的数据行
2.2 fillna()用其他数替代NaN;有的时候直接删除空数据会影响分析结果,可以对数据进行填补
2.3 fillna(method = 'pad')用前一个数据值代替NaN删除数据为空所对应的行:
学号 姓名 英语 数分 高代 解几
0 2308024241 成龙 76 40.0 23.0 60
1 2308024244 周怡 66 47.0 47.0 44
3 2308024249 朱浩 65 72.0 62.0 71
4 2308024219 封印 73 61.0 47.0 46
5 2308024201 迟培 60 71.0 76.0 71
6 2308024347 李华 67 61.0 65.0 78
8 2308024326 余皓 66 65.0 61.0 71
9 2308024219 封印 73 61.0 47.0 46使用数值或者任意字符替代缺失值:
学号 姓名 英语 数分 高代 解几
0 2308024241 成龙 76 40.0 23.0 60
1 2308024244 周怡 66 47.0 47.0 44
2 2308024251 张波 85 $ 45.0 60
3 2308024249 朱浩 65 72.0 62.0 71
4 2308024219 封印 73 61.0 47.0 46
5 2308024201 迟培 60 71.0 76.0 71
6 2308024347 李华 67 61.0 65.0 78
7 2308024307 陈田 76 69.0 $ 69
8 2308024326 余皓 66 65.0 61.0 71
9 2308024219 封印 73 61.0 47.0 46用前一个值替换缺失的值:
学号 姓名 英语 数分 高代 解几
0 2308024241 成龙 76 40.0 23.0 60
1 2308024244 周怡 66 47.0 47.0 44
2 2308024251 张波 85 47.0 45.0 60
3 2308024249 朱浩 65 72.0 62.0 71
4 2308024219 封印 73 61.0 47.0 46
5 2308024201 迟培 60 71.0 76.0 71
6 2308024347 李华 67 61.0 65.0 78
7 2308024307 陈田 76 69.0 65.0 69
8 2308024326 余皓 66 65.0 61.0 71
9 2308024219 封印 73 61.0 47.0 46用后一个值替换缺失的值:
学号 姓名 英语 数分 高代 解几
0 2308024241 成龙 76 40.0 23.0 60
1 2308024244 周怡 66 47.0 47.0 44
2 2308024251 张波 85 72.0 45.0 60
3 2308024249 朱浩 65 72.0 62.0 71
4 2308024219 封印 73 61.0 47.0 46
5 2308024201 迟培 60 71.0 76.0 71
6 2308024347 李华 67 61.0 65.0 78
7 2308024307 陈田 76 69.0 61.0 69
8 2308024326 余皓 66 65.0 61.0 71
9 2308024219 封印 73 61.0 47.0 46用平均数或者其它描述性统计量替代NaN
学号 姓名 英语 数分 高代 解几
0 2308024241 成龙 76 40.000000 23.000000 60
1 2308024244 周怡 66 47.000000 47.000000 44
2 2308024251 张波 85 60.777778 45.000000 60
3 2308024249 朱浩 65 72.000000 62.000000 71
4 2308024219 封印 73 61.000000 47.000000 46
5 2308024201 迟培 60 71.000000 76.000000 71
6 2308024347 李华 67 61.000000 65.000000 78
7 2308024307 陈田 76 69.000000 52.555556 69
8 2308024326 余皓 66 65.000000 61.000000 71
9 2308024219 封印 73 61.000000 47.000000 46
dataFrame.mean()['填补列名':'计算均值的列名']:可以使用选择列的均值进行缺失值的处理学号 姓名 英语 数分 高代 解几
0 2308024241 成龙 76 40.0 23.000000 60
1 2308024244 周怡 66 47.0 47.000000 44
2 2308024251 张波 85 NaN 45.000000 60
3 2308024249 朱浩 65 72.0 62.000000 71
4 2308024219 封印 73 61.0 47.000000 46
5 2308024201 迟培 60 71.0 76.000000 71
6 2308024347 李华 67 61.0 65.000000 78
7 2308024307 陈田 76 69.0 52.555556 69
8 2308024326 余皓 66 65.0 61.000000 71
9 2308024219 封印 73 61.0 47.000000 46dataFrame.fillna({'列名1':值1,'列名2':值2}): 可以传入一个字典,对不同的列填充不同的值
学号 姓名 英语 数分 高代 解几
0 2308024241 成龙 76 40.0 23.0 60
1 2308024244 周怡 66 47.0 47.0 44
2 2308024251 张波 85 100.0 45.0 60
3 2308024249 朱浩 65 72.0 62.0 71
4 2308024219 封印 73 61.0 47.0 46
5 2308024201 迟培 60 71.0 76.0 71
6 2308024347 李华 67 61.0 65.0 78
7 2308024307 陈田 76 69.0 0.0 69
8 2308024326 余皓 66 65.0 61.0 71
9 2308024219 封印 73 61.0 47.0 46
使用strip()清除字符串左,右或首尾指定的字符串,默认为空格,中间不清除
age name
0 26 Ben
1 85 John
2 64 Jerry
3 85 John
4 85 John0 Ben
1 John
2 Jerry
3 John
4 John
Name: name, dtype: object只删除右边的字符n,如果不指定删除的字符串,默认删除空格
0 Ben
1 John
2 Jerry
3 John
4 John
Name: name, dtype: object0 Be
1 John
2 Jerry
3 John
4 Joh
Name: name, dtype: object只删除左边的字符n,如果不指定删除的字符串,默认删除空格
0 Ben
1 John
2 Jerry
3 John
4 John
Name: name, dtype: object0 Ben
1 ohn
2 erry
3 ohn
4 John
Name: name, dtype: objectProcess finished with exit code 0
四: 数据抽取
# -*- coding:utf-8 -*-import pandas as pd from pandas import Seriesimport warningsprint("数据抽取:") extractDataFrame = pd.read_excel(r'./file/i_nuc.xls', sheet_name='Sheet4') print(extractDataFrame.head()) print("""字段抽取是抽取出某列上指定位置的数据做成新的列:slice(start,stop)start表示开始位置stop表示结束 """) print() # 把’电话‘列转换为字符串: astype(str)转换类型 及修改extractDataFrame的列为字符串类型 extractDataFrame['电话'] = extractDataFrame['电话'].astype(str) print(extractDataFrame) print("抽取电话号码的前三位,便于判断号码的品牌:") bands = extractDataFrame['电话'].str.slice(0, 3) print(bands) print() print("抽取手机号码的中间4位,以判断手机号码的区域:") print(extractDataFrame['电话'].str.slice(3, 7)) print() print("抽取手机号的后四位:") print(extractDataFrame['电话'].str.slice(7, 11))print() print("""字符串拆分:字符串拆分是指指定的字符sep,拆分已有的字符串。split(sep,n,expand=False)sep:表示用于分隔字符串的分隔符n表示分割后新增的列数expand表示是否展开为数据库,默认为False返回值: expand是否展开为数据框,默认为False """)dataFrameSeries = pd.read_excel(r'./file/i_nuc.xls', sheet_name='Sheet4') print(dataFrameSeries)print() print("现将IP列转换为字符串str,在删除首尾空格") print(dataFrameSeries['IP'].str.strip()) print() print("按第一个'.'分成两列,1表示新增的列数") print("""FutureWarning: In a future version of pandas all arguments of StringMethods.split except for the argument 'pat' will be keyword-only.splitDataFrameSeries = dataFrameSeries['IP'].str.split('.', 1, True)忽略警告 """) warnings.filterwarnings('ignore', category=FutureWarning) # 忽略警告 splitDataFrameSeries = dataFrameSeries['IP'].str.split('.', 1, True) print(splitDataFrameSeries)print("给第一列和第二类指定列名称") splitDataFrameSeries.columns = ['IPOne', 'IPTwo'] print(splitDataFrameSeries)print("") print("重置索引") print("""重置索引是指指定某列为索引,以便于对其他数据进行操作:dataFrame.set_index('列名') """) df = pd.DataFrame({'age': Series([26, 85, 64, 85, 85]),'name': Series(['Ben', 'John', 'Jerry', 'John', 'John'])} ) print(df) # 指定name为索引 dataFrameReIndex = df.set_index('name') print("重置索引后数据结构") print(dataFrameReIndex)
运行效果:
D:\program_file_worker\anaconda\python.exe D:\program_file_worker\python_source_work\SSO\grammar\dataanalysis\DataAnalysisDataExtractData.py
数据抽取:
学号 电话 IP
0 2308024241 1.892225e+10 221.205.98.55
1 2308024244 1.352226e+10 183.184.226.205
2 2308024251 1.342226e+10 221.205.98.55
3 2308024249 1.882226e+10 222.31.51.200
4 2308024219 1.892225e+10 120.207.64.3字段抽取是抽取出某列上指定位置的数据做成新的列:
slice(start,stop)
start表示开始位置
stop表示结束
学号 电话 IP
0 2308024241 18922254812.0 221.205.98.55
1 2308024244 13522255003.0 183.184.226.205
2 2308024251 13422259938.0 221.205.98.55
3 2308024249 18822256753.0 222.31.51.200
4 2308024219 18922253721.0 120.207.64.3
5 2308024201 nan 222.31.51.200
6 2308024347 13822254373.0 222.31.59.220
7 2308024307 13322252452.0 221.205.98.55
8 2308024326 18922257681.0 183.184.230.38
9 2308024320 13322252452.0 221.205.98.55
10 2308024342 18922257681.0 183.184.230.38
11 2308024310 19934210999.0 183.184.230.39
12 2308024435 19934210911.0 185.184.230.40
13 2308024432 19934210912.0 183.154.230.41
14 2308024446 19934210913.0 183.184.231.42
15 2308024421 19934210914.0 183.154.230.43
16 2308024433 19934210915.0 173.184.230.44
17 2308024428 19934210916.0 NaN
18 2308024402 19934210917.0 183.184.230.4
19 2308024422 19934210918.0 153.144.230.7
抽取电话号码的前三位,便于判断号码的品牌:
0 189
1 135
2 134
3 188
4 189
5 nan
6 138
7 133
8 189
9 133
10 189
11 199
12 199
13 199
14 199
15 199
16 199
17 199
18 199
19 199
Name: 电话, dtype: object抽取手机号码的中间4位,以判断手机号码的区域:
0 2225
1 2225
2 2225
3 2225
4 2225
5
6 2225
7 2225
8 2225
9 2225
10 2225
11 3421
12 3421
13 3421
14 3421
15 3421
16 3421
17 3421
18 3421
19 3421
Name: 电话, dtype: object抽取手机号的后四位:
0 4812
1 5003
2 9938
3 6753
4 3721
5
6 4373
7 2452
8 7681
9 2452
10 7681
11 0999
12 0911
13 0912
14 0913
15 0914
16 0915
17 0916
18 0917
19 0918
Name: 电话, dtype: object
字符串拆分:
字符串拆分是指指定的字符sep,拆分已有的字符串。
split(sep,n,expand=False)
sep:表示用于分隔字符串的分隔符
n表示分割后新增的列数
expand表示是否展开为数据库,默认为False
返回值: expand是否展开为数据框,默认为False学号 电话 IP
0 2308024241 1.892225e+10 221.205.98.55
1 2308024244 1.352226e+10 183.184.226.205
2 2308024251 1.342226e+10 221.205.98.55
3 2308024249 1.882226e+10 222.31.51.200
4 2308024219 1.892225e+10 120.207.64.3
5 2308024201 NaN 222.31.51.200
6 2308024347 1.382225e+10 222.31.59.220
7 2308024307 1.332225e+10 221.205.98.55
8 2308024326 1.892226e+10 183.184.230.38
9 2308024320 1.332225e+10 221.205.98.55
10 2308024342 1.892226e+10 183.184.230.38
11 2308024310 1.993421e+10 183.184.230.39
12 2308024435 1.993421e+10 185.184.230.40
13 2308024432 1.993421e+10 183.154.230.41
14 2308024446 1.993421e+10 183.184.231.42
15 2308024421 1.993421e+10 183.154.230.43
16 2308024433 1.993421e+10 173.184.230.44
17 2308024428 1.993421e+10 NaN
18 2308024402 1.993421e+10 183.184.230.4
19 2308024422 1.993421e+10 153.144.230.7现将IP列转换为字符串str,在删除首尾空格
0 221.205.98.55
1 183.184.226.205
2 221.205.98.55
3 222.31.51.200
4 120.207.64.3
5 222.31.51.200
6 222.31.59.220
7 221.205.98.55
8 183.184.230.38
9 221.205.98.55
10 183.184.230.38
11 183.184.230.39
12 185.184.230.40
13 183.154.230.41
14 183.184.231.42
15 183.154.230.43
16 173.184.230.44
17 NaN
18 183.184.230.4
19 153.144.230.7
Name: IP, dtype: object按第一个'.'分成两列,1表示新增的列数
FutureWarning: In a future version of pandas all arguments of StringMethods.split
except for the argument 'pat' will be keyword-only.
splitDataFrameSeries = dataFrameSeries['IP'].str.split('.', 1, True)
忽略警告0 1
0 221 205.98.55
1 183 184.226.205
2 221 205.98.55
3 222 31.51.200
4 120 207.64.3
5 222 31.51.200
6 222 31.59.220
7 221 205.98.55
8 183 184.230.38
9 221 205.98.55
10 183 184.230.38
11 183 184.230.39
12 185 184.230.40
13 183 154.230.41
14 183 184.231.42
15 183 154.230.43
16 173 184.230.44
17 NaN NaN
18 183 184.230.4
19 153 144.230.7
给第一列和第二类指定列名称
IPOne IPTwo
0 221 205.98.55
1 183 184.226.205
2 221 205.98.55
3 222 31.51.200
4 120 207.64.3
5 222 31.51.200
6 222 31.59.220
7 221 205.98.55
8 183 184.230.38
9 221 205.98.55
10 183 184.230.38
11 183 184.230.39
12 185 184.230.40
13 183 154.230.41
14 183 184.231.42
15 183 154.230.43
16 173 184.230.44
17 NaN NaN
18 183 184.230.4
19 153 144.230.7重置索引
重置索引是指指定某列为索引,以便于对其他数据进行操作:
dataFrame.set_index('列名')age name
0 26 Ben
1 85 John
2 64 Jerry
3 85 John
4 85 John
重置索引后数据结构
age
name
Ben 26
John 85
Jerry 64
John 85
John 85Process finished with exit code 0
相关文章:
Python3数据科学包系列(三):数据分析实战
Python3中类的高级语法及实战 Python3(基础|高级)语法实战(|多线程|多进程|线程池|进程池技术)|多线程安全问题解决方案 Python3数据科学包系列(一):数据分析实战 Python3数据科学包系列(二):数据分析实战 Python3数据科学包系列(三):数据分析实战 国庆中秋宅家自省: Pyth…...

UE4.27.2 自定义 PrimitiveComponent 出现的问题
目录 CreatePrimitiveUniformBufferImmediateFLocalVertexFactory 默认构造函数GetTypeHashENQUEUE_RENDER_COMMANDnull resource entry in uniform buffer parameters FLocalVertexFactory 在看大象无形,其中关于静态物体网络绘制的代码出错的 bug 我也搞了一会………...

【docker】数据卷和数据卷容器
一、如何管理docker容器中的数据? 二、数据卷 1、数据卷原理 将容器内部的配置文件目录,挂载到宿主机指定目录下 数据卷默认会一直存在,即使容器被删除 宿主机和容器是两个不同的名称空间,如果想进行连接需要用ssh,…...
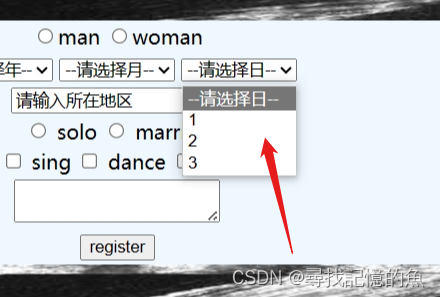
HTML——列表,表格,表单内容的讲解
文章目录 一、列表1.1无序(unorder)列表1.2 有序(order)列表1.3 定义列表 二、表格**2.1 基本的表格标签2.2 演示 三、表单3.1 form元素3.2 input元素3.2.1 单选按钮 3.3 selcet元素 基础部分点击: web基础 一、列表 …...
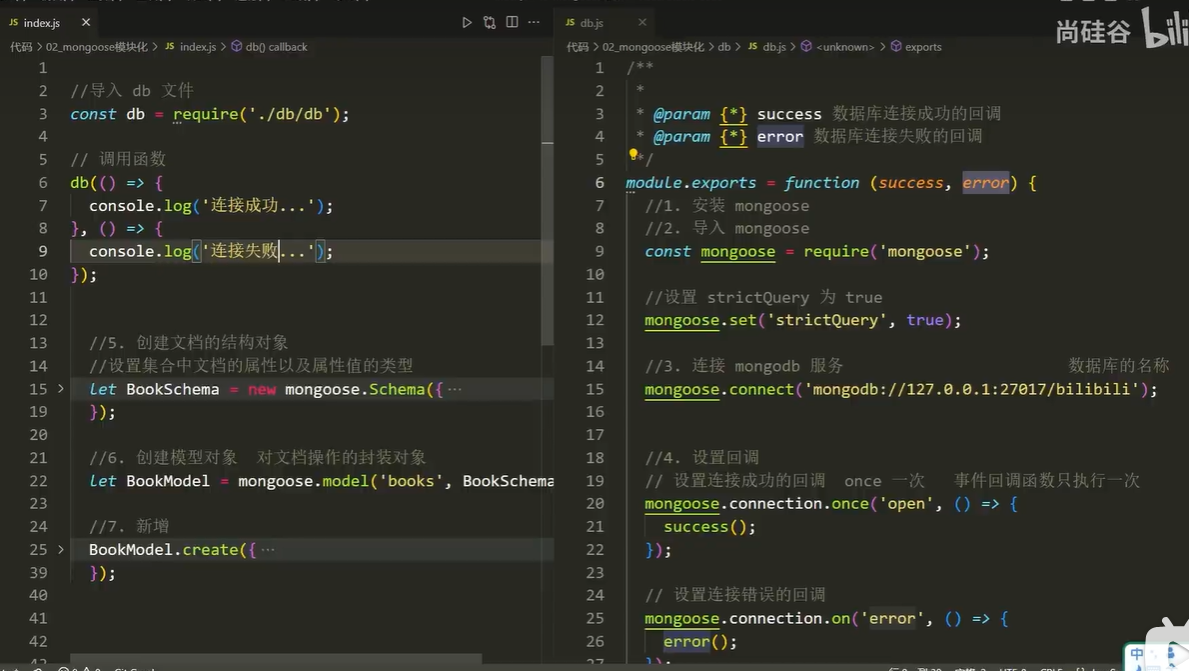
Mongodb学习
一、初步了解 1.1 Mongodb 是什么 MongoDB 是一个基于分布式文件存储的数据库,官方地址 https://www.mongodb.com/ 1.2 数据库是什么 数据库(DataBase)是按照数据结构来组织、存储和管理数据的 应用程序 1.3 数据库的作用 数据库的主要…...

2024届计算机毕业生福利来啦!Python毕业设计选题分享Django毕设选题大全Flask毕设选题最易过题目
💕💕作者:计算机源码社 💕💕个人简介:本人七年开发经验,擅长Java、Python、PHP、.NET、微信小程序、爬虫、大数据等,大家有这一块的问题可以一起交流! 💕&…...
网络爬虫指南
一、定义 网络爬虫,是按照一定规则,自动抓取网页信息。爬虫的本质是模拟浏览器打开网页,从网页中获取我们想要的那部分数据。 二、Python为什么适合爬虫 Python相比与其他编程语言,如java,c#,Cÿ…...

9、媒体元素标签
9、媒体元素标签 一、视频元素 video标签 二、音频元素 audio标签 <!--音频和视频 video:视频标签 audio:音频标签 controls:控制选项,可以显示进度条 autoplay:自动播放 -->示例 <!DOCTYPE html> &…...
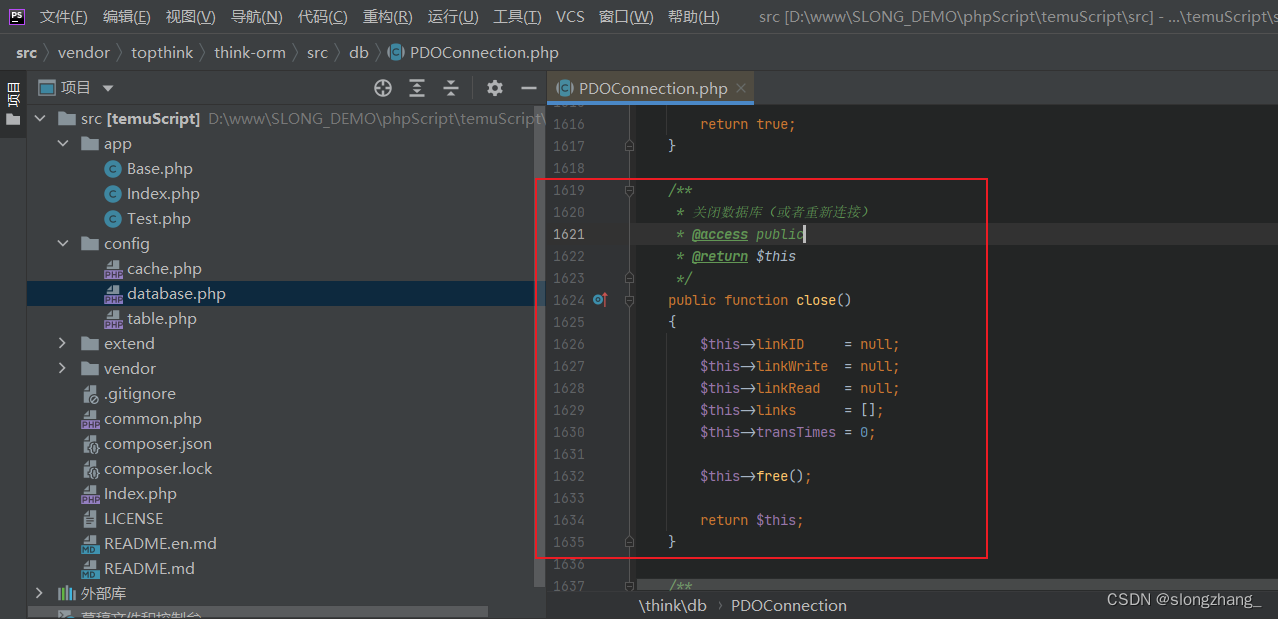
php单独使用think-rom数据库 | thinkphp手动关闭数据库连接
背景(think-orm2.0.61) 由于需要长时间运行一个php脚本,而运行过程并不是需要一直与数据库交互,但thinkphp主要是为web站点开发的框架,而站点一般都是数据获取完则进程结束,所以thinkphp没提供手动关闭数据…...

337. 打家劫舍 III
题目描述 小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。 除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两…...
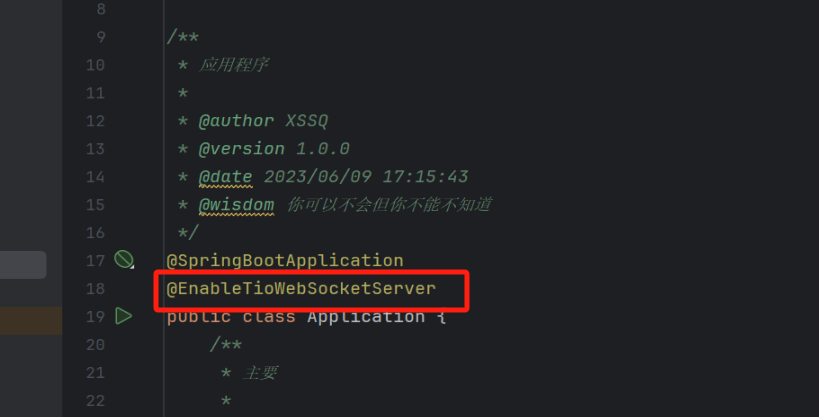
tio-websocket-spring-boot-starter的最简单实例,看完你一定有所收获
前言 我最近一个月一直在寻找能够快速开发实时通讯的简单好用的模块,所以我就去寻找了一下相关的内容.在此之前我使用的是Spring原生的webSocket,她有个弊端就是设置组不容易设置,而且配置上也稍微复杂一点,需要配置拦截器和处理器,还需要把它放入到Springboot的启动容器里面,也…...

列出连通集
输入样例: 8 6 0 7 0 1 2 0 4 1 2 4 3 5 输出样例: { 0 1 4 2 7 } { 3 5 } { 6 } { 0 1 2 7 4 } { 3 5 } { 6 } solution #include <stdio.h> #include <string.h> int arcs[10][10]; int visited[10] {0}; void DFS(int n, int v); void BFS(int n , int i)…...

前端 富文本编辑器原理——从javascript、html、css开始入门
文章目录 ⭐前言⭐html的contenteditable属性💖 输入的光标位置(浏览器获取selection)⭐使用Selection.toString () 返回指定的文本⭐getRangeAt 获取指定索引范围 💖 修改光标位置💖 设置选取range ⭐总结⭐结束 ⭐前…...

堆--数据流中第K大元素
如果对于堆不是太认识,请点击:堆的初步认识-CSDN博客 数据流与上述堆--数组中第K大元素-CSDN博客的数组区别: 数据流的数据是动态变化的,数组是写死的 堆--数组中第K大元素-CSDN博客题的小顶堆加一个方法: class MinH…...
【算法|动态规划No.12】leetcode152. 乘积最大子数组
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【手撕算法系列专栏】【LeetCode】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程,希望…...
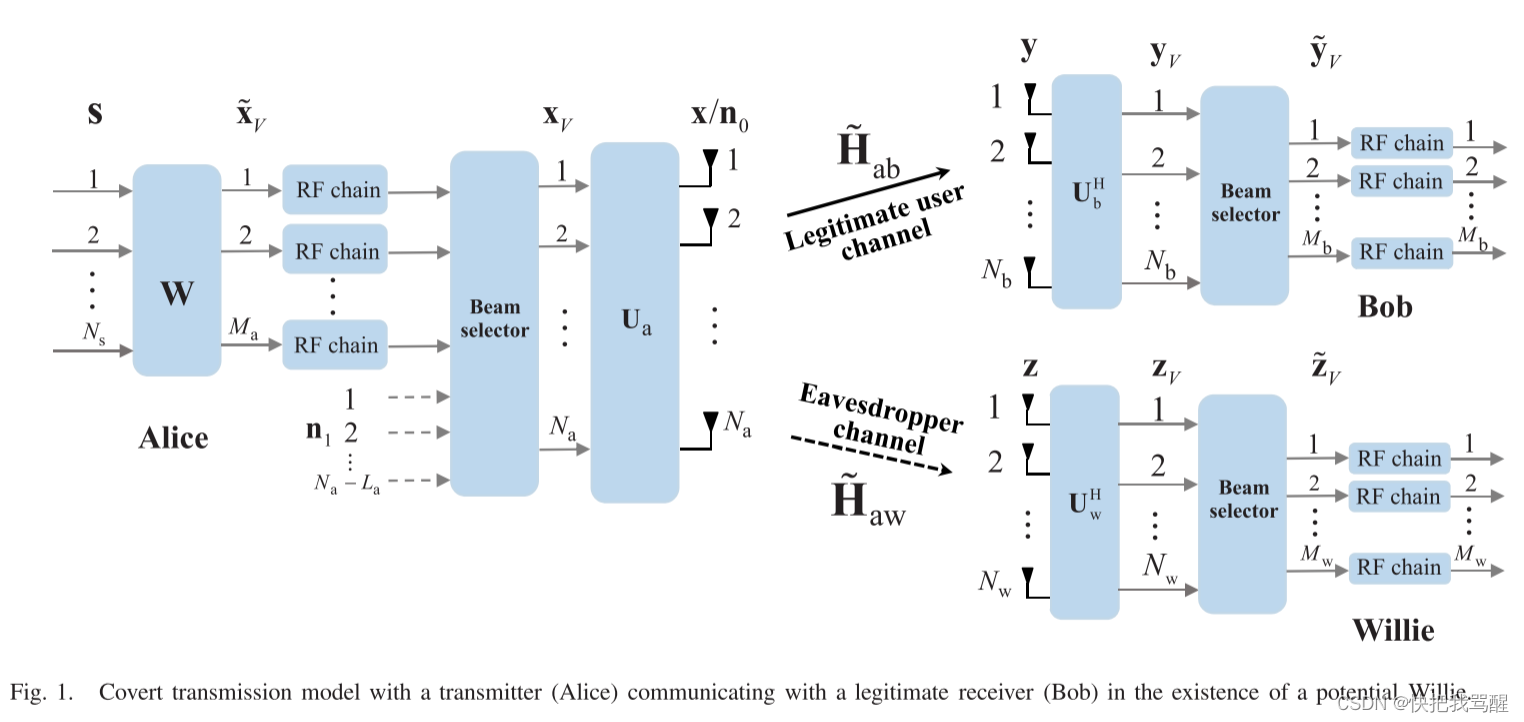
Covert Communication 与选择波束(毫米波,大规模MIMO,可重构全息表面)
Covert Communication for Spatially Sparse mmWave Massive MIMO Channels 2023 TOC abstract 隐蔽通信,也称为低检测概率通信,旨在为合法用户提供可靠的通信,并防止任何其他用户检测到合法通信的发生。出于下一代通信系统安全链路的强烈…...

计算机毕业设计 基于协调过滤算法的绿色食品推荐系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
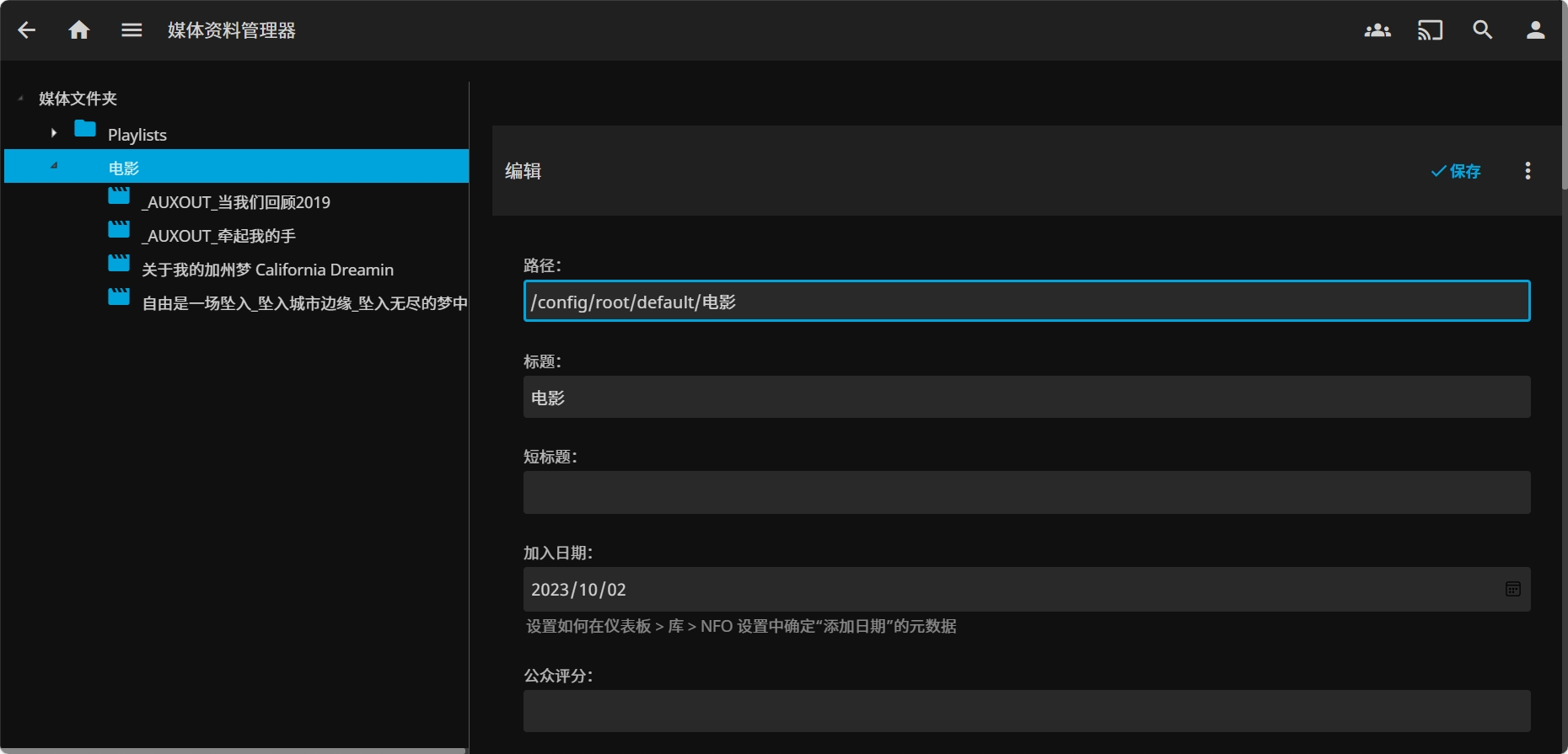
华为云云耀云服务器L实例评测|部署在线影音媒体系统 Jellyfin
华为云云耀云服务器L实例评测|部署在线影音媒体系统 Jellyfin 一、云耀云服务器L实例介绍1.1 云服务器介绍1.2 产品规格1.3 应用场景1.4 支持镜像 二、云耀云服务器L实例配置2.1 重置密码2.2 服务器连接2.3 安全组配置 三、部署 Jellyfin3.1 Jellyfin 介绍3.2 Docke…...
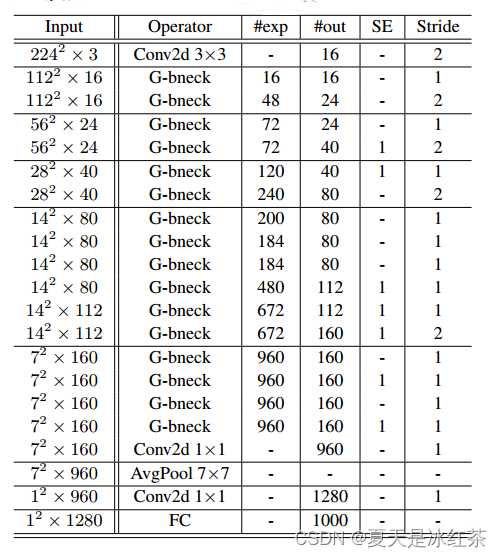
GhostNet原理解析及pytorch实现
论文:https://arxiv.org/abs/1911.11907 源码:https://github.com/huawei-noah/ghostnet 简要论述GhostNet的核心内容。 Ghost Net 1、Introduction 在训练良好的深度神经网络的特征图中,丰富甚至冗余的信息通常保证了对输入数据的全面理…...
视频二维码的制作方法,支持内容修改编辑
现在学生经常会需要使用音视频二维码,比如外出打开、才艺展示、课文背诵等等。那么如何制作一个可以长期使用的二维码呢?下面来给大家分享一个二维码制作(免费在线二维码生成器-二维码在线制作-音视频二维码在线生成工具-机智熊二维码&#x…...

Blitz.js全栈开发框架:基于Next.js的Zero-API数据层实践
1. 项目概述:Blitz.js,一个被低估的全栈开发框架如果你和我一样,在过去几年里一直在用 Next.js 构建全栈应用,那你肯定经历过这种场景:前端页面写得飞快,但一到后端 API 路由、数据库操作、身份验证这些环节…...

GroundTruth-MCP:为AI生成代码构建实时事实核查防火墙
1. 项目概述:当AI助手自信地写出过时代码时你的AI助手刚刚又“自信满满”地给你生成了一堆过时的代码。它告诉你React 19里forwardRef用得没问题,Next.js 15的cookies()还是同步函数,或者用字符串模板拼接SQL查询“既简洁又高效”。更糟的是&…...

基于Kubernetes Operator的企业级区块链网络自动化部署实践
1. 项目概述:企业级区块链的云原生部署方案如果你正在寻找一个能够将企业级区块链网络快速、稳定地部署到Kubernetes集群上的成熟方案,那么ConsenSys开源的quorum-kubernetes项目绝对值得你花时间深入研究。这个项目不是一个简单的概念验证,而…...

PS4游戏存档管理终极指南:如何使用Apollo工具轻松备份和修改游戏进度
PS4游戏存档管理终极指南:如何使用Apollo工具轻松备份和修改游戏进度 【免费下载链接】apollo-ps4 Apollo Save Tool (PS4) 项目地址: https://gitcode.com/gh_mirrors/ap/apollo-ps4 在PlayStation 4游戏体验中,游戏存档管理一直是个让玩家头疼的…...

基于DGX OpenClaw Stack构建本地AI智能体:从硬件调优到生产部署
1. 项目概述:一站式本地AI智能体栈如果你和我一样,对把大语言模型(LLM)真正“养”在自己的硬件上,构建一个功能完整、数据私有的智能助手有执念,那么你很可能已经踩过不少坑了。从选模型、搭服务、配工具链…...

开源数字白板the-board:基于React+Fabric.js的实时协作技术解析
1. 项目概述:一个开源的“数字白板”能做什么?最近在GitHub上看到一个挺有意思的项目,叫the-board。乍一看名字,可能觉得平平无奇,但点进去你会发现,它其实是一个功能相当完整的在线白板应用。简单来说&…...

量子机器学习在网络安全中的应用与性能分析
1. 量子机器学习在网络安全中的应用现状量子机器学习(Quantum Machine Learning, QML)近年来在网络安全领域引起了广泛关注。作为一名长期从事网络安全与量子计算交叉研究的从业者,我见证了这项技术从理论探讨到实际验证的发展历程。量子计算…...

Gemini自动生成PPT实战手册:从零输入到专业演示文稿,3步完成95%的幻灯片工作流
更多请点击: https://intelliparadigm.com 第一章:Gemini自动生成PPT的核心原理与能力边界 Gemini 生成 PPT 的本质并非传统模板填充,而是基于多模态理解与结构化内容重构的端到端推理过程。其核心依赖于对用户输入(文本、大纲、…...

微信视频下载器wx_channels_download
微信视频下载器ltaoo/wx_channels_download(跨平台轻量首选) 特点:体积小、使用简单,在微信PC端视频下方添加“下载”按钮;支持 macOS 和 Windows。优点:集成式(无需单独监听)&…...

从怀疑到真香!2026年我亲测十多款语音识别转文字app只留这一个
开完2小时讨论会,你要花3小时逐句整理纪要?采访了3个受访者,你戴耳机听一天录音,还漏了一半核心观点?做方言访谈,转出来的文字驴唇不对马嘴,你还要返工重听? 这些磨人的痛点…...