归并排序含非递归版
目录
1.归并排序的原理
2.实现归并排序
2.1框架
2.2区间问题和后序遍历
2.3归并并拷贝
2.4归并排序代码
2.5测试
3.非递归实现归并排序
3.1初次实现
3.2测试
3.3修改
3.4修改测试
1.归并排序的原理
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;
即先使每个子序列有序,再使子序列段间有序 若将两个有序表合并成一个有序表,称为二路归并。
可以将数组内容想象成一颗二叉树,通过递归的方式将数组的内容分为左子树和右子树,分出来的左子树和右子树又分别有它们的左子树和右子树。不断地向下进行拆分,直到拆分到没有对应区间和区间只有一个元素(有序)的时候便递归返回。然后使用归并的方式将左子树和右子树归并成有序数组,再将其拷贝会原数组,这样对应的子树便会有序,再递归返回,不断地递归。直到根左子树和根右子树有序,再归并和拷贝,整个数组就会变得有序。
如图所示: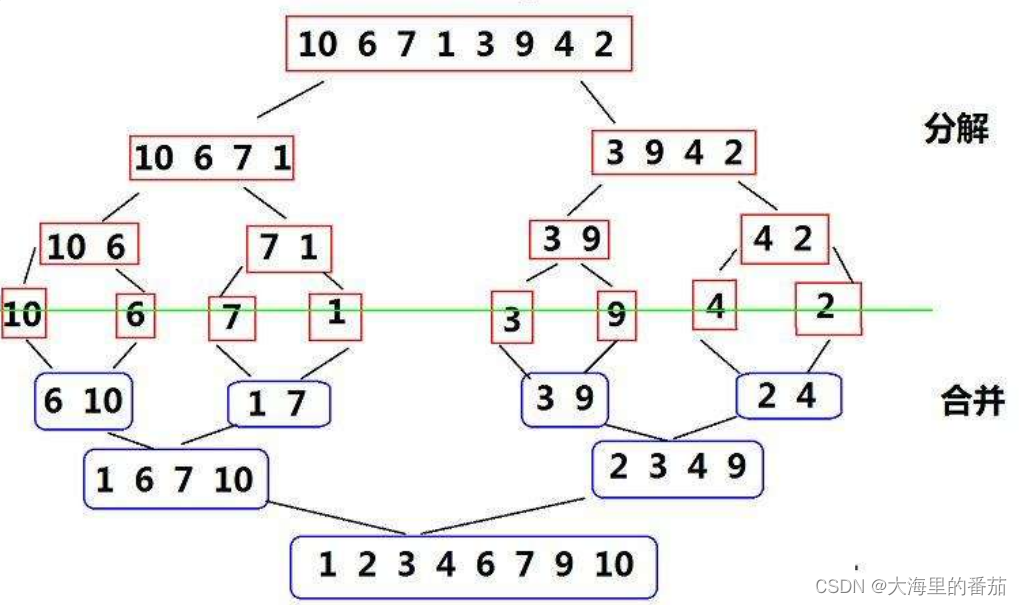
2.实现归并排序
归并排序需要开额外的空间来辅助实现 之所以不在原数组实现,是因为如果你使用交换的方式来进行排序,可能会将原数组已经排好序的部分又一次变回无序,而使用令数组向后移动的方式进行对应的排序,时间复杂度便会大大增加,因此归并排序可以理解成一种以空间换时间的排序方法。
归并排序需要开额外的空间,但每次递归都要开空间显然是不合理的,因此我们使用一个函数来完成递归的部分。思考一下,新创建的函数的参数应该有哪些,首先得有原数组,其次得有我们开辟好的数组,而我们要如二叉树一般形成对应的递归,显然需要区间,而区间的形成需要两个数来辅助,因此可以传递两个代表区间的数进来,可以取名为begin,end(left,right),这样理解起来轻松一些。
2.1框架

2.2区间问题和后序遍历
如二叉树一般实现后序遍历注意: 当begin>=end时代表着区间不存在或者只有一个元素(有序)的时候返回。因为是后序遍历,需要先将区间的分界给计算出来之后才能使用。
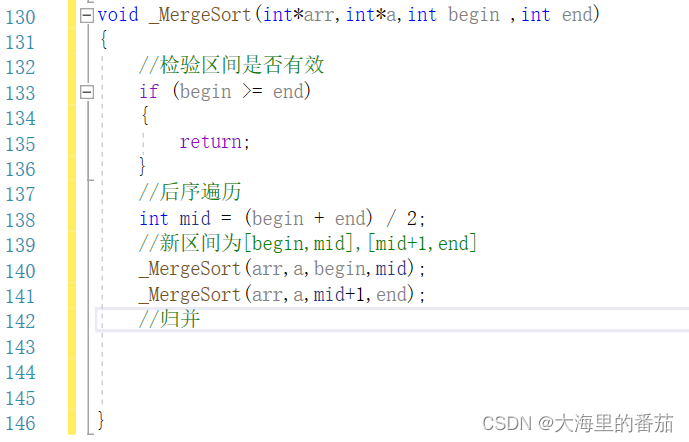
2.3归并并拷贝
可以看出,每次递归都会有两个区间的生成[begin,mid]和[mid+1,end]我们的目标就是将这两个区间归并在一起,这个很简单,循环便可以搞定。注意:两个区间不知道是哪个区间先完成循环,因此在外面需要将未完成循环的区间,补充回辅助数组中。
搞定完归并后,使用memcpy将辅助数组中的内容拷贝回原数组,排序便结束了。注意:我们传递的是闭区间,因此拷贝的长度为,end-begin+1
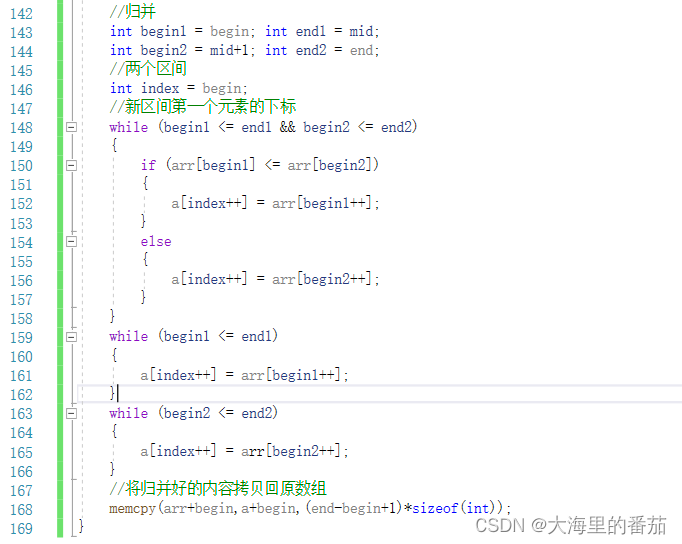
2.4归并排序代码
void MergeSort(int*arr,int n)
//将数组和数组的元素个数传递过来
{int* a = (int*)malloc(sizeof(int)*n);//创建辅助数组if (a == NULL){perror("malloc fail");return;}_MergeSort(arr,a,0,n-1);free(a);
}
void _MergeSort(int*arr,int*a,int begin ,int end)
{//检验区间是否有效if (begin >= end){return;}//后序遍历int mid = (begin + end) / 2;//新区间为[begin,mid],[mid+1,end]_MergeSort(arr,a,begin,mid);_MergeSort(arr,a,mid+1,end);//归并int begin1 = begin; int end1 = mid;int begin2 = mid+1; int end2 = end;//两个区间int index = begin;//新区间第一个元素的下标while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] <= arr[begin2]){a[index++] = arr[begin1++];}else{a[index++] = arr[begin2++];}}while (begin1 <= end1){a[index++] = arr[begin1++];}while (begin2 <= end2){a[index++] = arr[begin2++];}//将归并好的内容拷贝回原数组memcpy(arr+begin,a+begin,(end-begin+1)*sizeof(int));
}2.5测试
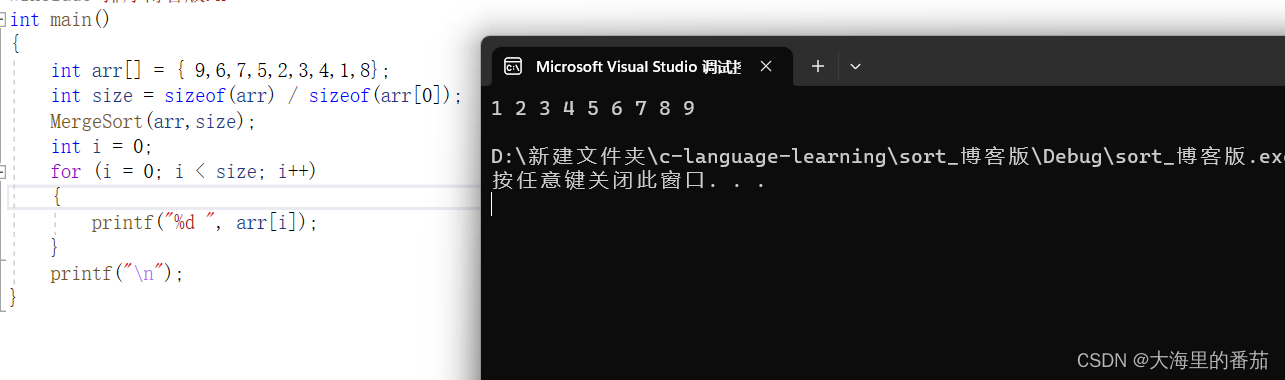
3.非递归实现归并排序
根据我们之前的排序我们可以看到它的本质是和预排序差不多的形态,因此我们可以通过一个整型如gap来区分一个元素和一个元素排序,两个元素和两个元素排序.......
3.1初次实现
void MergeSortNonR(int* arr, int n)
{int* a = (int*)malloc(sizeof(int) * n);//创建辅助数组int gap = 1;//gap=1便是1个元素和1个元素归并while (gap < n){int i = 0;for (i = 0; i < n; i += 2 * gap)//i+=2*gap跳过一整个区间{//两个区间int begin1 = i; int end1 = i + gap - 1;int begin2 = i + gap; int end2 = i + 2 * gap - 1;int index = i; //新区间第一个元素的下标//归并while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] <= arr[begin2]){a[index++] = arr[begin1++];}else{a[index++] = arr[begin2++];}}while (begin1 <= end1){a[index++] = arr[begin1++];}while (begin2 <= end2){a[index++] = arr[begin2++];}memcpy(arr + i, a + i, sizeof(int) * (2 * gap));}gap *= 2;}free(a);
}3.2测试
出现了越界问题
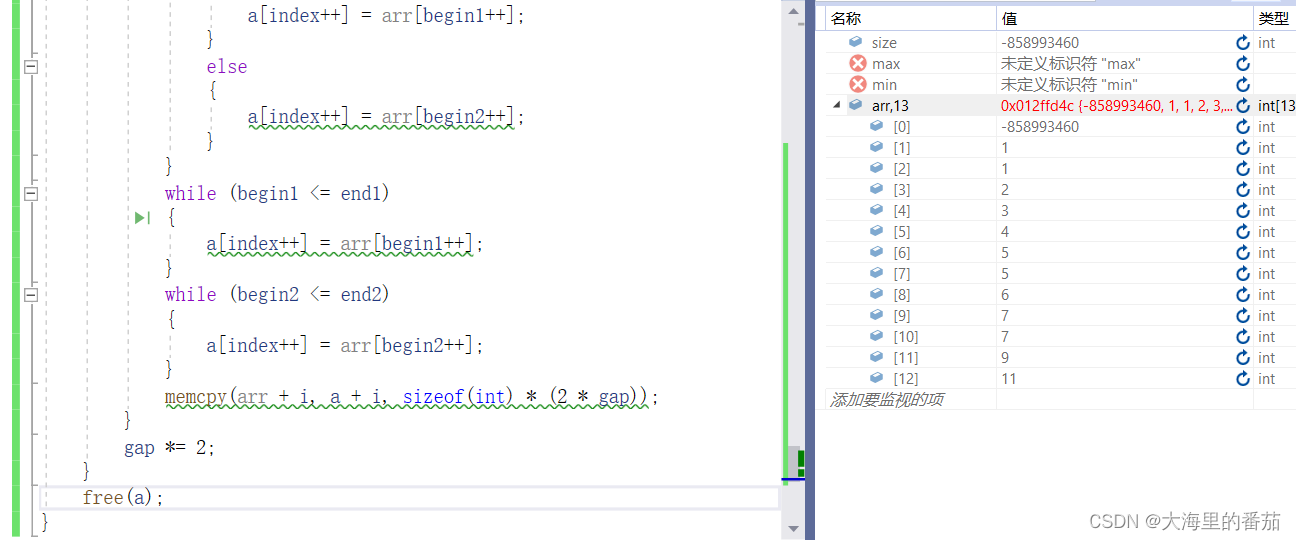
程序在打印之前就被迫中止了

3.3修改
观察可以发现,第一个区间的为[begin1,end1],第二个区间为[begin2,end2],那么begin1必然不会越界,而end1和更后面的begin2,end2都可能会越界。而其中end1和begin2越界的话都在说明已经排好序了,而end2越界,begin2没越界,则在说明还有数据未被排序。
再想一想细节,end1越界了,begin2一定越界,而begin2越界,end1不一定越界,所以无需考虑end1越界,只要begin2越界就说明排序已完成直接break 而只有end2越界,便将end2修正成数组的最大下标即可。
注意:我们之前使用拷贝函数均是拷贝2*gap个过去,在这里显然不合适,总区间长度应修正 为end2-begin1,这个修正不应该放在最后,因为在进行归并的期间,begin1会++至end1 也不应该放在判断begin2,end2越界之前,因为可能会对end2进行修正。综上所述,得出的代码为
void MergeSortNonR(int* arr, int n)
{int* a = (int*)malloc(sizeof(int) * n);//创建辅助数组int gap = 1;//gap=1便是1个元素和1个元素归并while (gap < n){int i = 0;for (i = 0; i < n; i += 2 * gap)//i+=2*gap跳过一整个区间{//两个区间int begin1 = i; int end1 = i + gap - 1;int begin2 = i + gap; int end2 = i + 2 * gap - 1;if (begin2 >= n){break;}if (end2 >= n)end2 = n - 1;//修正区间长度int order = end2 - begin1+1;//修正要拷贝的长度int index = i; //新区间第一个元素的下标//归并while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] <= arr[begin2]){a[index++] = arr[begin1++];}else{a[index++] = arr[begin2++];}}while (begin1 <= end1){a[index++] = arr[begin1++];}while (begin2 <= end2){a[index++] = arr[begin2++];}/*int order = 2 * gap;if (2 * gap >= n){order = n;}*/memcpy(arr + i, a + i, sizeof(int) * order);}gap *= 2;}free(a);
}3.4修改测试

至此,归并排序的递归版和非递归版讲解完成,感谢各位友友的来访,祝各位友友前程似锦O(∩_∩)O
相关文章:
归并排序含非递归版
目录 1.归并排序的原理 2.实现归并排序 2.1框架 2.2区间问题和后序遍历 2.3归并并拷贝 2.4归并排序代码 2.5测试 3.非递归实现归并排序 3.1初次实现 3.2测试 3.3修改 3.4修改测试 1.归并排序的原理 归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治…...

项目进展(八)-编写代码,驱动ADS1285
一、代码 根据芯片的数据手册编写部分驱动,首先看部分引脚的波形: DRDY: CS: 首先在代码初始化时连续写入三个寄存器: void WriteReg(uint8_t startAddr, uint8_t *regData, uint8_t number) {uint8_t i0;// 循环写number1次…...
【MyBatis-Plus】快速精通Mybatis-plus框架—快速入门
大家在日常开发中应该能发现,单表的CRUD功能代码重复度很高,也没有什么难度。而这部分代码量往往比较大,开发起来比较费时。 因此,目前企业中都会使用一些组件来简化或省略单表的CRUD开发工作。目前在国内使用较多的一个组件就是…...

docker 安装kafka
运行容器 zookeeper: [rootk8s-master ~]# docker run -d --restartalways --log-driver json-file --log-opt max-size100m --log-opt max-file2 --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper c603f292813cfd6e2b16fff88a9767cc86fc9bba34d82…...

容器内获得apiserver地址
1.容器的Env的KUBENETES_SERVICE_HOST字段 roottomcat01-69fc8f859b-w9btn:/tmp# env | grep KUBERNETES_SERVICE_HOST10.96.0.1 KUBERNETES_SERVICE_HOST10.96.0.12.通过域名查询 nslookup getent hosts roottomcat01-69fc8f859b-w9btn:/tmp# getent hosts kubernetes.def…...
)
linux服务端c++开发工具介绍(vscode版)
本文适合于有一定c开发经验,但是还不明确如何到linux服务端开发程序的同学。 一、vscode 几年前用的是ssh到云服务上,再用vim在云上开发的形式 ssh dongbeijing.dbj11.158.142.176 vim hello.c 现今,由于vscode比较好用,这几年…...

Linux常用命令大全
Linux常用命令大全 一、文件&目录管理1. 文件和目录操作命令2. 查看文件及内容处理命令3. 文件压缩及解压缩命令4. 搜索文件命令5. 其他 二、Linux 软件包管理三、用户管理1. 用户管理2. 查看系统用户登陆信息的命令 四、进程管理五、网络通信1. 基础网络操作命令2. 深入网…...

Python中取2023, 9, 1——2023, 10, 31的全部时间
使用datetime.date()函数定义了开始和结束日期。然后,我们使用datetime.timedelta()类创建了一个时间范围,其中n表示从开始日期到结束日期之间的天数。最后,我们使用一个for循环迭代时间范围内的日期,并打印每个日期。示例代码演示…...

创建django文件
1、在指定目录里打开终端,输入D:\Softwares\Anaconda3\envs\pytorch\Scripts\django-admin .exe startproject 名称 ,即可在对应目录里创建django文件。...
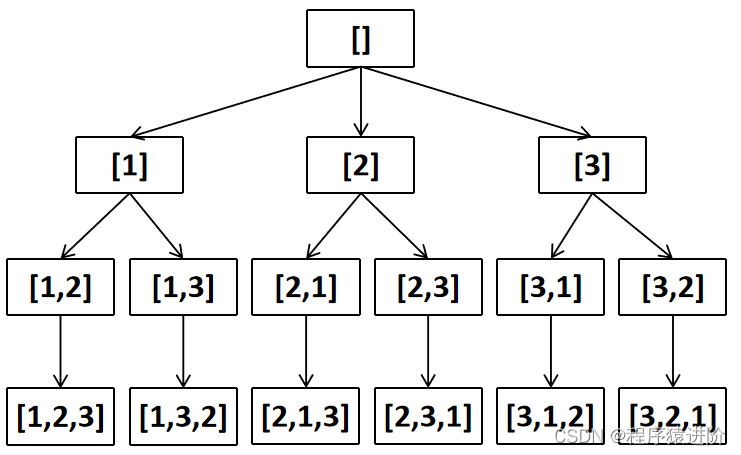
全排列[中等]
优质博文:IT-BLOG-CN 一、题目 给定一个不含重复数字的数组nums,返回其所有可能的全排列。你可以按任意顺序返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 示例…...
mybatise-plus的id过长问题
一、问题情景 笔者在做mp插入数据库(id已设置为自增)操作时,发现新增数据的id过长,结果导致前端JS拿到的数据出现了精度丢失问题,原因是后端id的类型是Long。在网上查了一下,只要在该属性上加上如下注解就可以 TableId(value &q…...
图示矩阵分解
特征值与特征向量 设 A A A 是 n 阶矩阵,如果存在数 λ \lambda λ 和 n 维非零列向量 x x x,满足关系式: A x λ x ( 1 ) Ax \lambda x\quad\quad(1) Axλx(1) 则数 λ \lambda λ 称为矩阵 A A A 的特征值,非零向量 x…...
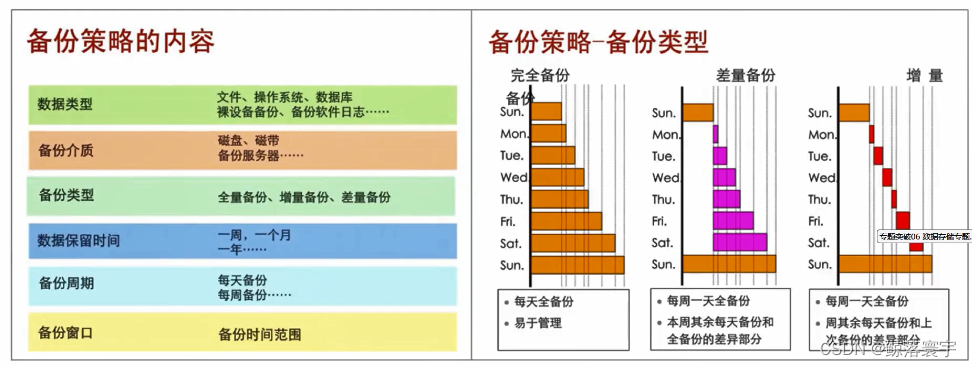
六、互联网技术——数据存储
文章目录 一、存储系统层次结构二、按照重要性分类三、磁盘阵列RAID三、RAID基础四、磁盘阵列分级五、数据备份与恢复六、容灾与灾难恢复 一、存储系统层次结构 常见的三层存储体系结构如下图所示,分为高速缓冲存储器、主存储器和外存储器。 二、按照重要性分类 …...

六、vpp 流表+负载均衡
草稿!!! vpp node其实就是三个部分 1、plugin init 2、set command 3、function 实现功能,比如这里的流表 今天我们再用VPP实现一个流表的功能 一、流表 1.1流表----plugin init VLIB_REGISTER_NODE 注册流表节点 // 注册流…...
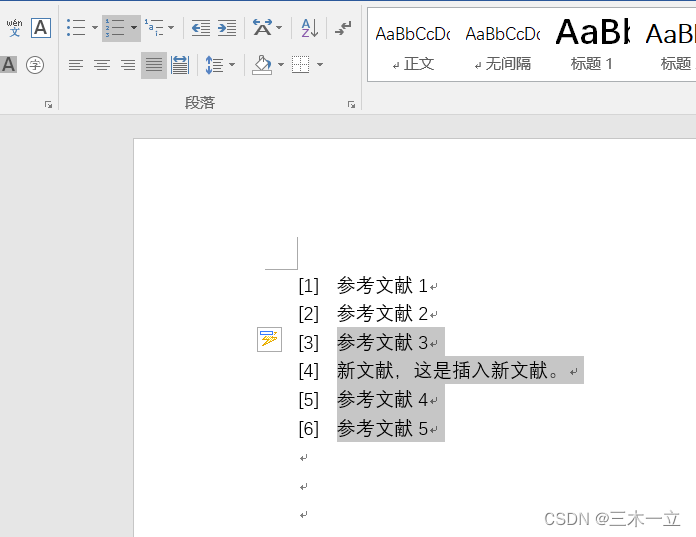
word已排序好的参考文献,插入新的参考文献,序号更新
原排序好的文献序号。 现在在3号后面插入一个新文献。4,5号应该成为5,6 这时在3号后面,回车,就会自动的增长。如下图: 但是如果手滑,把[4]删除了如何排序?? 如下图: …...
二叉树的顺序存储——堆——初识堆排序
前面我们学过可以把完全二叉树存入到顺序表中,然后利用完全二叉树的情缘关系,就可以通过数组下标来联系。 但是并不是把二叉树存入到数组中就是堆了,要看原原来的二叉树是否满足:所有的父都小于等于子,或者所有的父都…...

CYEZ 模拟赛 9
A a ⊥ b ⇒ a − b ⊥ a b (1) a \perp b \Rightarrow a-b \perp ab \tag {1} a⊥b⇒a−b⊥ab(1) 证明: gcd ( a , b ) gcd ( b , a − b ) \gcd(a,b) \gcd(b, a-b) gcd(a,b)gcd(b,a−b),故 a − b ⊥ b a - b \perp b a−b⊥b,同…...
typescript: Builder Pattern
/*** file: CarBuilderts.ts* TypeScript 实体类 Model* Builder Pattern* 生成器是一种创建型设计模式, 使你能够分步骤创建复杂对象。* https://stackoverflow.com/questions/12827266/get-and-set-in-typescript* https://github.com/Microsoft/TypeScript/wiki/…...
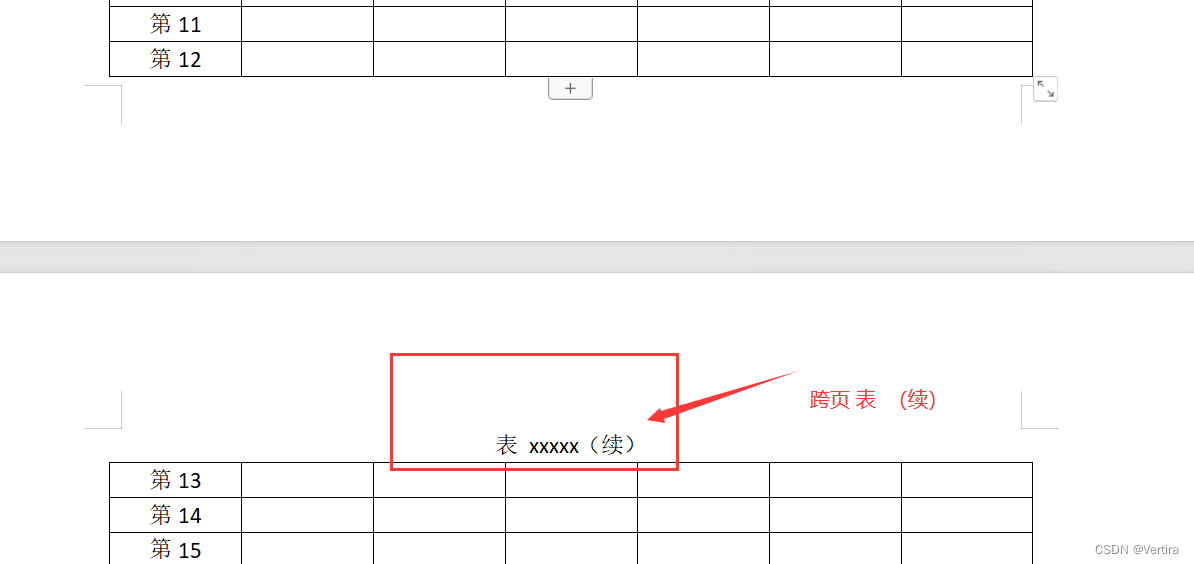
WPS/word 表格跨行如何续表、和表的名称
1:具体操作: 将光标定位在跨页部分的第一行任意位置,按下快捷键ctrlshiftenter,就可以在跨页的表格上方插入空行(在空行可以写,表1-3 xxxx(续)) 在空行中输入…...
Python的NumPy库(一)基础用法
NumPy库并不是Python的标准库,但其在机器学习、大数据等很多领域有非常广泛的应用,NumPy本身就有比较多的内容,全部的学习可能涉及许多的内容,但我们在这里仅学习常见的使用,这些内容对于我们日常使用NumPy是足够的。 …...

League Akari:英雄联盟玩家的终极智能助手,5大核心功能全面解析
League Akari:英雄联盟玩家的终极智能助手,5大核心功能全面解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为…...

Apache Airflow 系列教程 | 第34课:实战项目 — 机器学习管道编排
导读(Introduction) 欢迎来到 Apache Airflow 源码深度解析系列的第34课。 在上一课中,我们构建了一个完整的企业级 ETL 平台,涵盖了多层数据仓库、多团队协作和监控告警。本课将目光转向另一个高价值场景——机器学习管道编排(ML Pipeline Orchestration)。 机器学习…...

告别驱动开发:手把手教你用himm工具在用户空间玩转Hi3516的GPIO
用户空间高效操控Hi3516 GPIO:himm工具实战指南 在嵌入式开发领域,传统的内核驱动开发往往需要经历漫长的编译、加载和调试周期。对于快速硬件验证和原型开发而言,这种开发模式显得过于笨重。海思Hi3516平台提供的himm工具,为开发…...

uni-app iOS后台运行 uni-app App如何实现后台定位或音乐播放
iOS上uni.startBackgroundTask基本无效,仅音频播放、定位更新、后台数据刷新三类能力合规;后台定位需manifest声明原生权限地理围栏事件;无声音频保活须onLaunch配置AudioSession并延迟播放。uni.startBackgroundTask 在 iOS 上基本无效&…...

3步搭建你的英雄联盟智能助手:LeagueAkari完整操作指南
3步搭建你的英雄联盟智能助手:LeagueAkari完整操作指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 想象一下,当你正…...

HTML5 教程
HTML5 教程 引言 HTML5,作为现代网页开发的核心技术之一,自从推出以来就受到了广泛的关注和认可。它不仅改进了原有的HTML特性,还引入了新的元素和API,使得网页设计和开发更加高效、强大。本教程旨在为您提供一个全面的HTML5学习路径,帮助您快速掌握HTML5的基础知识和高…...

坐北朝南教育集团
在教育行业不断发展的当下,家长和学生在选择教育机构时常常面临诸多困扰,寻找一家口碑好、教学质量高的教育集团成为了关键。坐北朝南教育集团作为辽沈地区知名的综合教育航母,在解决教育领域痛点方面表现出色,成为众多家长和学生…...

AI工具搭建自动化视频生成NVENC
最近在折腾视频生成这块,发现AI工具搭配NVENC(NVIDIA的硬件编码器)做自动化视频生成,其实是个挺有意思的组合。很多人以为写个脚本调用FFmpeg就能搞定,但真正要把NVENC用透,背后的门道还是挺多的。不如从几…...

FanControl深度解析:Windows上最强大的风扇控制软件终极指南
FanControl深度解析:Windows上最强大的风扇控制软件终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trend…...

Windows Defender Remover终极指南:高效移除Windows安全防护的完整解决方案
Windows Defender Remover终极指南:高效移除Windows安全防护的完整解决方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcod…...