Hadoop命令大全
HDFS分布式文件系统 , 将一个大的文件拆分成多个小文件存储在多台服务器中
文件系统: 目录结构(树状结构) "/" 树根, 目录结构在namenode中维护
目录
1.查看当前目录
2.创建多级目录
3.上传文件
4.查看文件
4.hdfs中移动文件
编辑 5.下载文件
6.删除文件
7.查看文件大小
8.删除目录
9.常用命令
9.1. hdfs文件系统命令
9.2. 运维命令
9.3. mapreduce命令
9.4. hdfs系统检查工具fsck
9.5. 运行pipies作业
1.查看当前目录
# hdfs dfs -ls /
Found 2 items
drwxr-xr-x - yunwei supergroup 0 2023-02-24 14:39 /hbase
drwxr-xr-x - yunwei supergroup 0 2023-02-24 14:55 /usr2.创建多级目录
hdfs dfs -mkdir /hadoop
hdfs dfs -mkdir -p /test/a
hdfs dfs -ls /test 查看文件,ls 。没有cd命令, 需要指绝对路径
# hdfs dfs -mkdir -p /test/a
# hdfs dfs -ls /
Found 2 items
drwxr-xr-x - yunwei supergroup 0 2023-02-24 14:39 /hbase
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test
# hdfs dfs -ls /test
Found 1 items
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test/a3.上传文件
就已经能看出来了
-copyFromLocal 将本地的文件复制到hdfs的分布式系统中
-put 将本地文件复制到hdfs系统中,可以给文件重命名,本地原文件还存在
-moveFromLocal 将文件复制到hdfs中,本地文件已不存在
# hdfs dfs -copyFromLocal hello-hadoop.txt /test/
# hdfs dfs -lsr /test
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test/a
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:21 /test/hello-hadoop.txt# hdfs dfs -put hello-hadoop.txt /test/a.txt
# hdfs dfs -lsr /test
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test/a
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:23 /test/a.txt
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:21 /test/hello-hadoop.txt# hdfs dfs -moveFromLocal hello-hadoop.txt /test/b.txt
# hdfs dfs -lsr /test
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test/a
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:23 /test/a.txt
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:25 /test/b.txt
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:21 /test/hello-hadoop.txt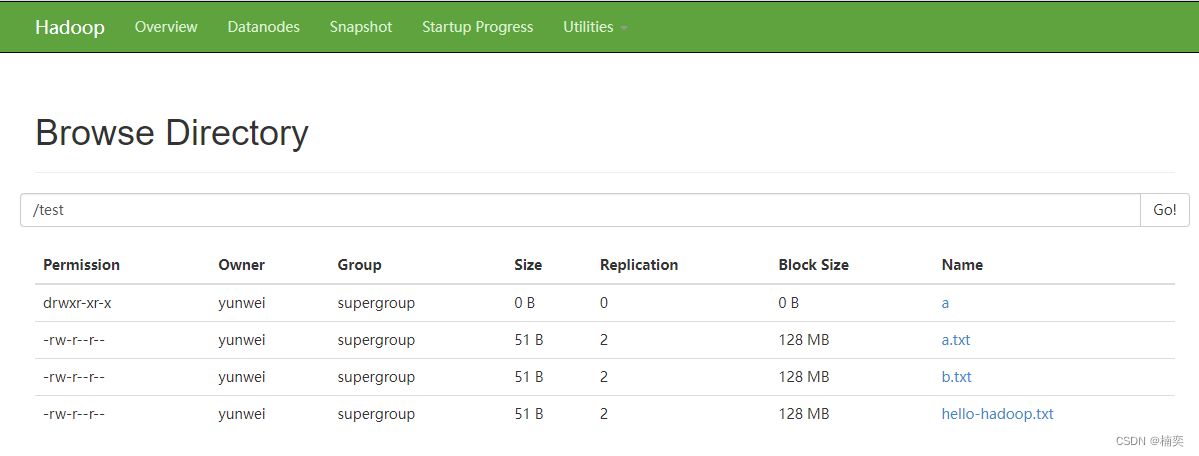
4.查看文件
当知道文件内容小的时候,可以用-cat,
文件内容很大时,可以用-tail -f,文件就会一直在文件末尾,有信息时,随时展示
# hdfs dfs -cat /test/a.txt
name:china
local:beijing
time:now
say:hello hadoop
#
# hdfs dfs -tail -f /test/a.txt
name:china
local:beijing
time:now
say:hello hadoop4.hdfs中移动文件
# hdfs dfs -mv /test/a.txt /test/aa.txt
# hdfs dfs -lsr /test
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test/a
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:23 /test/aa.txt
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:25 /test/b.txt
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:21 /test/hello-hadoop.txt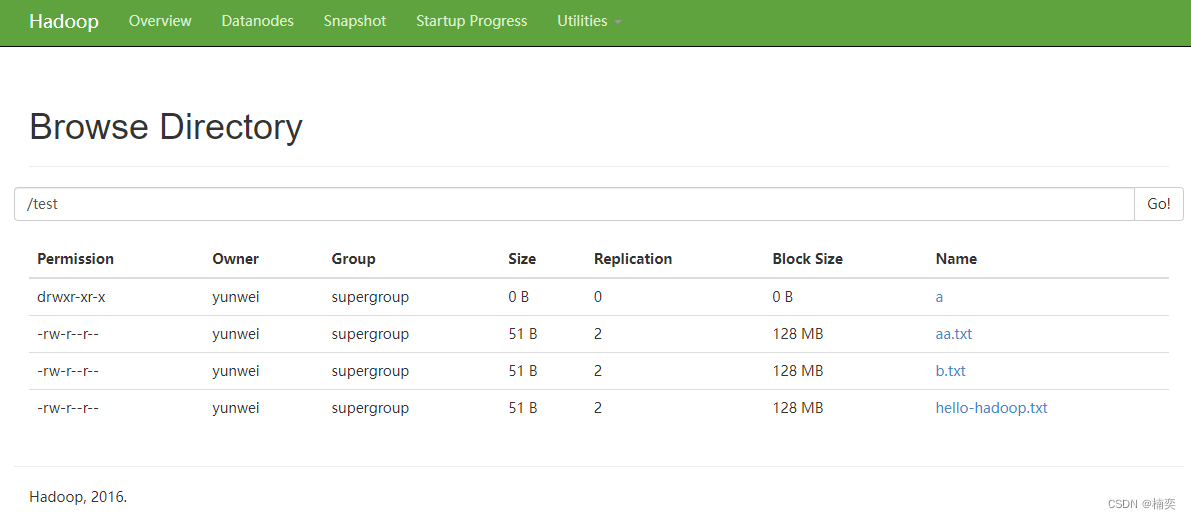 5.下载文件
5.下载文件
# hdfs dfs -get /test/b.txt
# ll
total 4
-rw-r--r-- 1 yunwei yunwei 51 Feb 24 17:34 b.txt6.删除文件
# hdfs dfs -rm r /test/aa.txt
rm: `r': No such file or directory
23/02/24 17:41:19 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /test/aa.txt
#
# hdfs dfs -lsr /test
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - yunwei supergroup 0 2023-02-24 17:14 /test/a
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:25 /test/b.txt
-rw-r--r-- 2 yunwei supergroup 51 2023-02-24 17:21 /test/hello-hadoop.txt7.查看文件大小
# hdfs dfs -du -h /test
0 /test/a
51 /test/b.txt
51 /test/hello-hadoop.txt8.删除目录
# hdfs dfs -rmr /usr
rmr: DEPRECATED: Please use 'rm -r' instead.
23/02/24 16:39:51 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /usr# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - yunwei supergroup 0 2023-02-24 14:39 /hbase
9.常用命令
9.1. hdfs文件系统命令
hdfs dfs -mkdir dir 创建文件夹
hdfs dfs -rmr dir 删除文件夹dir
hdfs dfs -ls 查看目录文件信息
hdfs dfs -lsr 递归查看文件目录信息
hdfs dfs -stat path 返回指定路径的信息
9.1.2 空间大小查看系列命令:
hdfs dfs -du -h dir 按照适合阅读的形式人性化显示文件大小
hdfs dfs -dus uri 递归显示目标文件的大小
hdfs dfs -du path/file显示目标文件file的大小
9.1.3 权限管理类:
hdfs dfs -chgrp group path 改变文件所属组
hdfs dfs -chgrp -R /dir 递归更改dir目录的所属组
hdfs dfs -chmod [-R] 权限 -path 改变文件的权限
hdfs dfs -chown owner[-group] /dir 改变文件的所有者
hdfs dfs -chown -R owner[-group] /dir 递归更改dir目录的所属用户
9.1.4 文件操作(上传下载复制)系列:
hdfs dfs -touchz a.txt 创建长度为0的空文件a.txt
hdfs dfs -rm file 删除文件file
hdfs dfs -put file dir 向dir文件上传file文件
hdfs dfs -put filea dir/fileb 向dir上传文件filea并且把filea改名为fileb
hdfs dfs -get file dir 下载file到本地文件夹
hdfs dfs -getmerge hdfs://Master:9000/data/SogouResult.txt CombinedResult 把hdfs里面的多个文件合并成一个文件,合并后文件位于本地系统
hdfs dfs -cat file 查看文件file
hdfs fs -text /dir/a.txt 如果文件是文本格式,相当于cat,如果文件是压缩格式,则会先解压,再查看
hdfs fs -tail /dir/a.txt查看dir目录下面a.txt文件的最后1000字节
hdfs dfs -copyFromLocal localsrc path 从本地复制文件
hdfs dfs -copyToLocal /hdfs/a.txt /local/a.txt 从hdfs拷贝到本地
hdfs dfs -copyFromLocal /dir/source /dir/target 把文件从原路径拷贝到目标路径
hdfs dfs -mv /path/a.txt /path/b.txt 把文件从a目录移动到b目录,可用于回收站恢复文件
9.1.5 判断系列:
hdfs fs -test -e /dir/a.txt 判断文件是否存在,正0负1
hdfs fs -test -d /dir 判断dir是否为目录,正0负1
hdfs fs -test -z /dir/a.txt 判断文件是否为空,正0负1
9.1.6 系统功能管理类:
hdfs dfs -expunge 清空回收站
hdfs dfsadmin -safemode enter 进入安全模式
hdfs dfsadmin -sfaemode leave 离开安全模式
hdfs dfsadmin -decommission datanodename 关闭某个datanode节点
hdfs dfsadmin -finalizeUpgrade 终结升级操作
hdfs dfsadmin -upgradeProcess status 查看升级操作状态
hdfs version 查看hdfs版本
hdfs daemonlog -getlevel host:port 打印运行在host:port的守护进程的日志级别
hdfs daemonlog -setlevel host:port 设置运行在host:port的守护进程的日志级别
hdfs dfs -setrep -w 副本数 -R path 设置文件的副本数
9.2. 运维命令
start-dfs.sh 启动namenode,datanode,启动文件系统
stop-dfs.sh 关闭文件系统
start-yarn.sh 启动resourcemanager,nodemanager
stop-yarn.sh 关闭resourcemanager,nodemanager
start-all.sh 启动hdfs,yarn
stop-all.sh 关闭hdfs,yarn
hdfs-daemon.sh start datanode 单独启动datanode
start-balancer.sh -t 10% 启动负载均衡,尽量不要在namenode节点使用
hdfs namenode -format 格式化文件系统
hdfs namenode -upgrade 分发新的hdfs版本之后,namenode应以upgrade选项启动
hdfs namenode -rollback 将namenode回滚到前一版本,这个选项要在停止集群,分发老的hdfs版本之后执行
hdfs namenode -finalize finalize会删除文件系统的前一状态。最近的升级会被持久化,rollback选项将再不可用,升级终结操作之后,它会停掉namenode,分发老的hdfs版本后使用
hdfs namenode importCheckpoint 从检查点目录装载镜像并保存到当前检查点目录,检查点目录由fs.checkpoint.dir指定
9.3. mapreduce命令
hdfs jar file.jar 执行jar包程序
hdfs job -kill job_201005310937_0053 杀死正在执行的jar包程序
hdfs job -submit 提交作业
hdfs job -status 打印map和reduce完成百分比和所有计数器。
hdfs job -counter 打印计数器的值。
hdfs job -kill 杀死指定作业。
hdfs job -events <from-event-#> <#-of-events> 打印给定范围内jobtracker接收到的事件细节。
hdfs job -history [all]
hdfs job -history 打印作业的细节、失败及被杀死原因的细节。更多的关于一个作业的细节比如成功的任务,做过的任务尝试等信息可以通过指定[all]选项查看。
hdfs job -list [all] 显示所有作业。-list只显示将要完成的作业。
hdfs job -kill -task 杀死任务。被杀死的任务不会不利于失败尝试。
hdfs job -fail -task 使任务失败。被失败的任务会对失败尝试不利。
9.4. hdfs系统检查工具fsck
hdfs fsck -move 移动受损文件到/lost+found
hdfs fsck -delete 删除受损文件。
hdfs fsck -openforwrite 打印出写打开的文件。
hdfs fsck -files 打印出正被检查的文件。
hdfs fsck -blocks 打印出块信息报告。
hdfs fsck -locations 打印出每个块的位置信息。
hdfs fsck -racks 打印出data-node的网络拓扑结构。
9.5. 运行pipies作业
hdfs pipes -conf 作业的配置
hdfs pipes -jobconf <key=value>, <key=value>, … 增加/覆盖作业的配置项
hdfs pipes -input 输入目录
hdfs pipes -output 输出目录
hdfs pipes -jar Jar文件名
hdfs pipes -inputformat InputFormat类
hdfs pipes -map Java Map类
hdfs pipes -partitioner Java Partitioner
hdfs pipes -reduce Java Reduce类
hdfs pipes -writer Java RecordWriter
hdfs pipes -program 可执行程序的URI
hdfs pipes -reduces reduce个数
相关文章:
Hadoop命令大全
HDFS分布式文件系统 , 将一个大的文件拆分成多个小文件存储在多台服务器中 文件系统: 目录结构(树状结构) "/" 树根, 目录结构在namenode中维护 目录 1.查看当前目录 2.创建多级目录 3.上传文件 4.查…...
一文带你快速初步了解云计算与大数据
目录 🔍一、云计算基础 1、云计算的概念、特点、关键技术 2、云计算的分类 3、云计算的部署模式 4、云计算的服务模式:IaaS、PaaS、SaaS分别是什么,具体含义要清楚 5、物联网的概念 6、物联网和云计算、大数据的关系 7、了解云计算的…...
STM32 OTA应用开发——通过USB实现OTA升级
STM32 OTA应用开发——通过USB实现OTA升级 目录STM32 OTA应用开发——通过USB实现OTA升级前言1 环境搭建2 功能描述3 BootLoader的制作4 APP的制作5 烧录下载配置6 运行测试结束语前言 什么是OTA? 百度百科:空中下载技术(Over-the-Air Techn…...

JavaScript高级程序设计读书分享之6章——6.2Array
JavaScript高级程序设计(第4版)读书分享笔记记录 适用于刚入门前端的同志 除了 Object,Array 应该就是 ECMAScript 中最常用的类型了。 创建数组 使用 Array 构造函数 在使用 Array 构造函数时,也可以省略 new 操作符。 let colors new Array() let …...
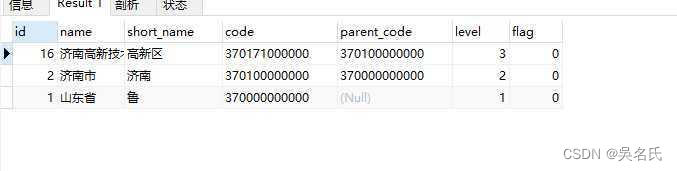
MySQL递归查询 三种实现方式
1 建表脚本1.1 建表DROP TABLE IF EXISTS sys_region; CREATE TABLE sys_region (id int(50) NOT NULL AUTO_INCREMENT COMMENT 地区主键编号,name varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT 地区名称,short_name varchar(50) CHARA…...
:过滤器)
Servle笔记(7):过滤器
1、过滤器的作用与目的 过滤器的目的 在客户端的请求访问后端资源之前,拦截请求在服务器的响应发送回客户端之前,处理响应 2、过滤器的类型 身份验证过滤器(Authentication Filters)数据压缩过滤器(Data compressio…...

2023年:我成了半个外包
边线业务与主线角色被困外包; 012022年,最后一个工作日,裁员的小刀再次挥下; 商务区楼下又多了几个落寞的身影,办公室内又多了几头暴躁的灵魂; 随着裁员的结束,部门的人员结构简化到了极致&am…...

HTTP中GET与POST方法的区别
1. HTTP HTTP即超文本传输协议(Hyper Text Transfer Protocol),是因特网上应用最广的一种协议。 设计目的:保证客户端与服务器之间的通信(发布和接受HTML页面);工作方式:客户端-服务器端的请求-应答协议 …...
使用ChatGPT需要避免的8个错误
如果ChatGPT是未来世界为每个登上新大陆人发放的一把AK47, 那么现在大多数人做的事,就是突突突一阵扫射, 不管也不知道有没有扫射到自己想要的目标。每个人都在使用 ChatGPT。但几乎每个人都停留在新手模式。 避免下面常见的8个ChatGPT的错…...
ELK日志分析--Kibana
Kibana 概述 部署安装浏览页面并使用 1.Kibana 概述 Kibana-是进入Elastic的窗口使用Kibana,可以 1 搜索,观察和保护。 从发现文档到分析日志再到发现安全漏洞,Kibana是您访问这些功能及其他功能的门户。 2 可视化和分析您的数据。 搜索隐藏的…...
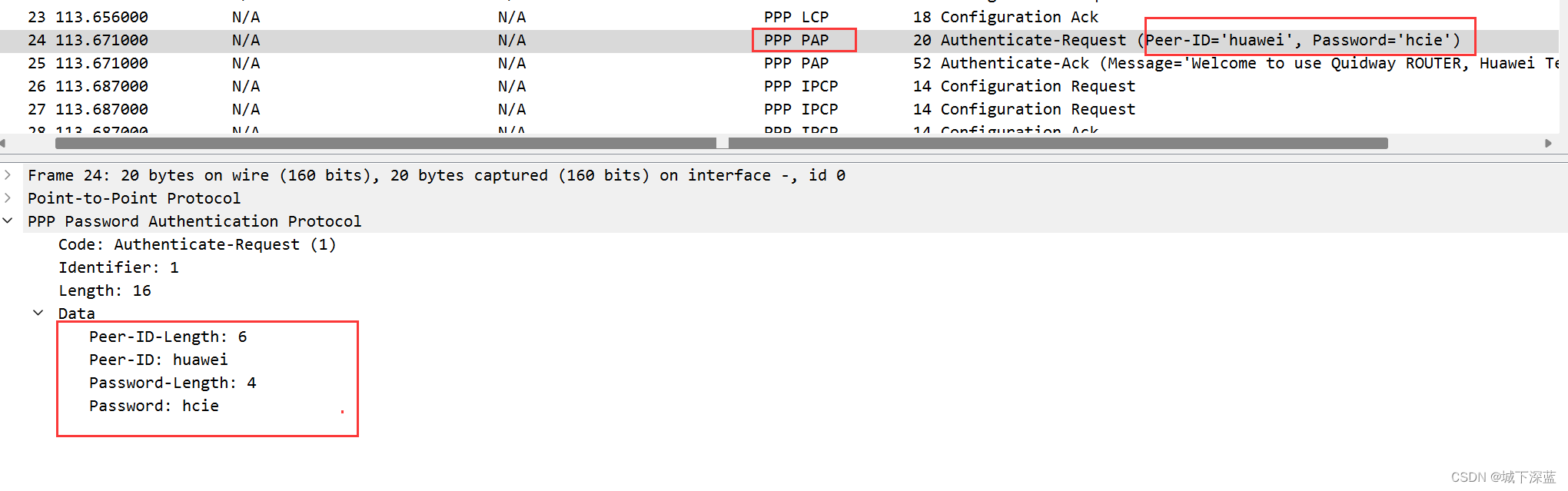
PPP点到点协议认证之PAP认证
PPP点到点协议认证之PAP认证 需求 如图配置接口的IP地址将R1配置为认证端,用户名和密码是 huawei/hcie ,使用的认证方式是pap确保R1和R2之间可以互相ping通 拓扑图 配置思路 确保接口使用协议是PPP确保接口的IP地址配置正确在R1 的端口上,…...
设计模式之建造者模式(C++)
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 一、建造者模式是什么? 建造者模式是一种创建型的软件设计模式,用于构造相对复杂的对象。 建造者模式可以…...

linux常见的系统日志
我们了解一下常见的系统日志,知道哪些需要收集 1. /var/log/boot.log linux中/var/log/boot.log是系统启动时的日志,其包括自启动服务。 2. /var/log/btmp linux中/var/log/btmp是记录登录失败信息的日志,是一种非文本文件,可以使…...

支付系统中的设计模式09:组合模式
现在就剩下怎么能够实现运营部提出的「打印出平台顾客购买的商品小票」这个需求了。 我们去超市买完东西之后,都会收到收银员打印出来的小票,就是商品清单、价格、数量和汇总的信息。下面这个我想应该99%的人都见过吧。 图三十七:超市购物小票 线上也是一样,也会有这种购物…...

Linux 文件权限之umask
目录一、文件默认创建权限二、文件默认创建权限掩码三、文件权限的修改本文主要讲解Linux中的文件默认创建权限相关的内容,涉及到的内容有:文件默认创建权限、文件默认创建权限掩码、文件访问权限的修改。 文件访问者共三类:文件所有者、文件…...
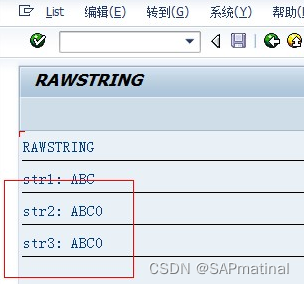
SAP ABAP 理解RAWSTRING(XSTRING) 类型
用F1查看的时候,这里是这样说的: The types RAWSTRING and STRING have a variable length. A maximum length for these types can be specified, but has no upper limit. The type SSTRING is available as of release 6.10 and it has a variable …...

Linux核心技能:2023主流监控Prometheus详解,附官方可复制中文文档教程
Prometheus既是一个时序数据库,又是一个监控系统,更是一套完备的监控生态解决方案。作为时序数据库,目前Prometheus已超越了老牌的时序数据库OpenTSDB、Graphite、RRDtool、KairosDB等,如图所示。 (来源网络࿰…...

金山文档这样玩,效率「狂飙」
1985年,微软发布了第一代的Excel。现在,Excel成为了许多打工人的必备工具,却也在很多人的日常工作中,带来了海量跨表同步、大批数据对齐的日常繁琐工作,逐渐沦为“表哥”“表妹”。多维表,是新一代数据效率…...

【类与对象】封装对象的初始化及清理
C面向对象的三大特性:封装、继承、多态。具有相同性质的对象,抽象为类。 文章目录1 封装1.1 封装的意义(一)1.2 封装的意义(二)1.3 struct 和 class区别1.4 成员属性设置为私有练习案例:1 设计…...

【算法】——并查集
作者:指针不指南吗 专栏:算法篇 🐾或许会很慢,但是不可以停下🐾 文章目录1.思想2.模板3.应用3.1 合并集合3.2 连通块中点的数量1.思想 并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题…...

AutoCut视频剪辑神器:像编辑Word一样剪视频,3步完成专业剪辑
AutoCut视频剪辑神器:像编辑Word一样剪视频,3步完成专业剪辑 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为复杂的视频剪辑软件头疼吗?想象一下,如果能像…...

5个简单技巧让明日方舟桌宠Ark-Pets运行更流畅:性能优化完全指南
5个简单技巧让明日方舟桌宠Ark-Pets运行更流畅:性能优化完全指南 【免费下载链接】Ark-Pets Arknights Desktop Pets | 明日方舟桌宠 (ArkPets) 项目地址: https://gitcode.com/gh_mirrors/ar/Ark-Pets Ark-Pets是一款让《明日方舟》角色在桌面上活动的开源桌…...
)
Linux系统服务“窃听”与“喊话”:dbus-monitor/dbus-send实战指南(以systemd-logind为例)
Linux系统服务的“窃听”与“喊话”:dbus-monitor/dbus-send高阶实战指南当你坐在咖啡馆里,周围此起彼伏的对话声中,偶尔会捕捉到一些有趣的片段——这正是dbus-monitor在Linux系统中的角色。而当你需要主动与某人交流时,清晰明确…...

NLP文本预处理全流程实战:从数据清洗到向量化的工程实践指南
1. 项目概述:从文本到智能的桥梁在人工智能的众多分支中,自然语言处理(NLP)一直是最具挑战性也最引人入胜的领域之一。它的核心目标直白而宏大:让机器能像人一样理解、运用和生成语言。这听起来像是科幻小说的情节&…...

机器学习与韦尔势零检验:挑战宇宙学标准模型的新方法
1. 项目概述:当机器学习遇见宇宙学检验在宇宙学这个探索宇宙起源与演化的宏大领域里,ΛCDM模型(宇宙学常数Λ与冷暗物质模型)已经稳坐了二十多年的“标准模型”宝座。它就像一个精密的宇宙蓝图,用几个关键参数…...

5分钟快速上手:AMD Ryzen处理器硬件调试完整指南
5分钟快速上手:AMD Ryzen处理器硬件调试完整指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode…...

Camoufox反检测浏览器:深度伪造Canvas/WebGL/Audio指纹
1. 这不是浏览器,而是一套“数字伪装系统”:Camoufox的本质定位很多人第一次看到“Camoufox反检测浏览器”时,下意识会把它当成一个“长得像Firefox的爬虫工具”,甚至有人直接把它和普通无头浏览器、SeleniumUser-Agent轮换方案划…...

【AI Agent招聘效能跃迁计划】:为什么92%的HR团队在第3周就放弃?——附可立即上线的MVP验证模板
更多请点击: https://intelliparadigm.com 第一章:AI Agent招聘效能跃迁计划的战略定位与行业悖论 在人才竞争白热化的当下,AI Agent并非招聘流程的“自动化补丁”,而是重构人岗匹配底层逻辑的战略支点。其核心价值不在于替代HR执…...

昇腾CANN ops-blas Batched GEMM:多头注意力的小矩阵乘批处理实战
Transformer 的 Multi-Head Attention 有 H 个注意力头——每个头独立做矩阵乘(QhKh^T、AttnVh)。H32 时,一个 BatchNorm 后面紧跟着 32 个小矩阵乘(每个头独立)。单独启动 32 次 GEMM 会有 32 次 launch 开销…...

AI Agent Harness Engineering:大模型之后的下一个技术爆发点
AI Agent Harness Engineering:大模型之后的下一个技术爆发点一、引言 1.1 钩子:从“大模型的局限性”到“人类解放双手的终极形态” 你是否有过这样的经历? 上周为了赶一份季度数据分析报告,你打开了GPT-4:先让它帮你…...