Scala第二十章节
Scala第二十章节
scala总目录
文档资料下载
章节目标
- 理解Akka并发编程框架简介
- 掌握Akka入门案例
- 掌握Akka定时任务代码实现
- 掌握两个进程间通信的案例
- 掌握简易版spark通信框架案例
1. Akka并发编程框架简介
1.1 Akka概述
Akka是一个用于构建高并发、分布式和可扩展的基于事件驱动的应用工具包。Akka是使用scala开发的库,同时可以使用scala和Java语言来开发基于Akka的应用程序。
1.2 Akka特性
- 提供基于异步非阻塞、高性能的事件驱动编程模型
- 内置容错机制,允许Actor在出错时进行恢复或者重置操作
- 超级轻量级的事件处理(每GB堆内存几百万Actor)
- 使用Akka可以在单机上构建高并发程序,也可以在网络中构建分布式程序。
1.3 Akka通信过程
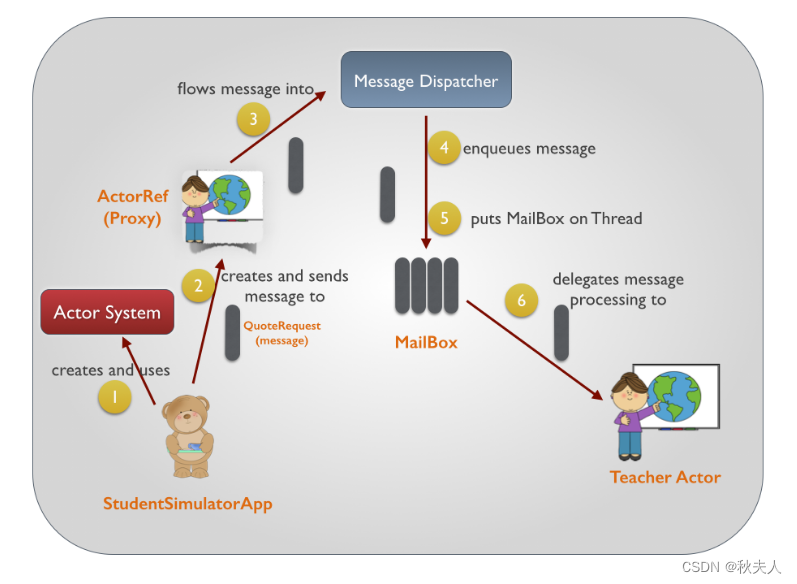
以下图片说明了Akka Actor的并发编程模型的基本流程:
- 学生创建一个ActorSystem
- 通过ActorSystem来创建一个ActorRef(老师的引用),并将消息发送给ActorRef
- ActorRef将消息发送给Message Dispatcher(消息分发器)
- Message Dispatcher将消息按照顺序保存到目标Actor的MailBox中
- Message Dispatcher将MailBox放到一个线程中
- MailBox按照顺序取出消息,最终将它递给TeacherActor接受的方法中
2. 创建Actor
Akka中,也是基于Actor来进行编程的。类似于之前学习过的Actor。但是Akka的Actor的编写、创建方法和之前有一些不一样。
2.1 API介绍
-
ActorSystem: 它负责创建和监督Actor
- 在Akka中,ActorSystem是一个重量级的结构,它需要分配多个线程.
- 在实际应用中, ActorSystem通常是一个单例对象, 可以使用它创建很多Actor.
- 直接使用
context.system就可以获取到管理该Actor的ActorSystem的引用.
-
实现Actor类
- 定义类或者单例对象继承Actor(注意:要导入akka.actor包下的Actor)
- 实现receive方法,receive方法中直接处理消息即可,不需要添加loop和react方法调用. Akka会自动调用receive来接收消息.
- 【可选】还可以实现preStart()方法, 该方法在Actor对象构建后执行,在Actor生命周期中仅执行一次.
-
加载Actor
- 要创建Akka的Actor,必须要先获取创建一个ActorSystem。需要给ActorSystem指定一个名称,并可以去加载一些配置项(后面会使用到)
- 调用ActorSystem.actorOf(Props(Actor对象), “Actor名字”)来加载Actor.
2.2 Actor Path
每一个Actor都有一个Path,这个路径可以被外部引用。路径的格式如下:
| Actor类型 | 路径 | 示例 |
|---|---|---|
| 本地Actor | akka://actorSystem名称/user/Actor名称 | akka://SimpleAkkaDemo/user/senderActor |
| 远程Actor | akka.tcp://my-sys@ip地址:port/user/Actor名称 | akka.tcp://192.168.10.17:5678/user/service-b |
2.3 入门案例
2.3.1 需求
基于Akka创建两个Actor,Actor之间可以互相发送消息。
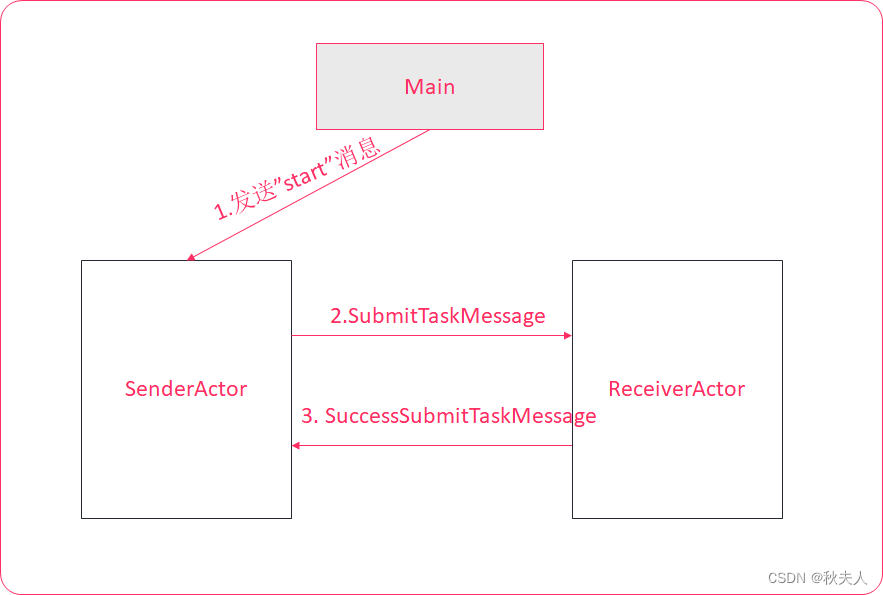
2.3.2 实现步骤
- 创建Maven模块
- 创建并加载Actor
- 发送/接收消息
2.3.3 创建Maven模块
使用Akka需要导入Akka库,这里我们使用Maven来管理项目, 具体步骤如下:
-
创建Maven模块.
选中项目, 右键 -> new -> Module -> Maven -> Next -> GroupId: com.itheimaArtifactId: akka-demo next -> 设置"module name"值为"akka-demo" -> finish -
打开pom.xml文件,导入akka Maven依赖和插件.
//1. 直接把资料的pom.xml文件中的内容贴过来就行了. //2. 源码目录在: src/main/scala下 //3. 测试代码目录在: src/test/scala下. //4. 上述的这两个文件夹默认是不存在的, 需要我们手动创建. //5. 创建出来后, 记得要修改两个文件夹的类型.选中文件夹, 右键 -> Mark Directory as -> Source Roots //存放源代码.Test Source Roots //存放测试代码.
2.3.4 创建并加载Actor
到这, 我们已经把Maven项目创建起来了, 后续我们都会采用Maven来管理我们的项目. 接下来, 我们来实现:
创建并加载Actor, 这里, 我们要创建两个Actor:
- SenderActor:用来发送消息
- ReceiverActor:用来接收,回复消息
具体步骤
-
在src/main/scala文件夹下创建包: com.itheima.akka.demo
-
在该包下创建两个Actor(注意: 用object修饰的单例对象).
-
SenderActor: 表示发送消息的Actor对象.
-
ReceiverActor: 表示接收消息的Actor对象.
-
-
在该包下创建
单例对象Entrance, 并封装main方法, 表示整个程序的入口. -
把程序启动起来, 如果不报错, 说明代码是没有问题的.
参考代码
object SenderActor extends Actor {/*细节: 在Actor并发编程模型中, 需要实现act方法, 想要持续接收消息, 可通过loop + react实现.在Akka编程模型中, 需要实现receive方法, 直接在receive方法中编写偏函数处理消息即可.*///重写receive()方法override def receive: Receive = {case x => println(x)}
} object ReceiverActor extends Actor{//重写receive()方法override def receive: Receive = {case x => println(x)}
}object Entrance { def main(args:Array[String]) = {//1. 实现一个Actor Trait, 其实就是创建两个Actor对象(上述步骤已经实现).//2. 创建ActorSystem//两个参数的意思分别是:ActorSystem的名字, 加载配置文件(此处先不设置)val actorSystem = ActorSystem("actorSystem",ConfigFactory.load())//3. 加载Actor//actorOf方法的两个参数意思是: 1. 具体的Actor对象. 2.该Actor对象的名字val senderActor = actorSystem.actorOf(Props(SenderActor), "senderActor")val receiverActor = actorSystem.actorOf(Props(ReceiverActor), "receiverActor")}
}
2.3.5 发送/接收消息
思路分析
- 使用样例类封装消息
- SubmitTaskMessage——提交任务消息
- SuccessSubmitTaskMessage——任务提交成功消息
- 使用
!发送异步无返回消息.
参考代码
-
MessagePackage.scala文件中的代码
/*** 记录发送消息的 样例类.* @param msg 具体的要发送的信息.*/ case class SubmitTaskMessage(msg:String)/*** 记录 回执信息的 样例类.* @param msg 具体的回执信息.*/ case class SuccessSubmitTaskMessage(msg:String) -
Entrance.scala文件中的代码
//程序主入口. object Entrance {def main(args: Array[String]): Unit = {//1. 创建ActorSystem, 用来管理所有用户自定义的Actor.val actorSystem = ActorSystem("actorSystem", ConfigFactory.load())//2. 通过ActorSystem, 来管理我们自定义的Actor(SenderActor, ReceiverActor)val senderActor = actorSystem.actorOf(Props(SenderActor), "senderActor")val receiverActor = actorSystem.actorOf(Props(ReceiverActor), "receiverActor") //3. 由ActorSystem给 SenderActor发送一句话"start".senderActor ! "start"} } -
SenderActor.scala文件中的代码
object SenderActor extends Actor{override def receive: Receive = {//1. 接收Entrance发送过来的: startcase "start" => {//2. 打印接收到的数据.println("SenderActor接收到: Entrance发送过来的 start 信息.")//3. 获取ReceiverActor的具体路径.//参数: 要获取的Actor的具体路径.//格式: akka://actorSystem的名字/user/要获取的Actor的名字.val receiverActor = context.actorSelection("akka://actorSystem/user/receiverActor")//4. 给ReceiverActor发送消息: 采用样例类SubmitTaskMessagereceiverActor ! SubmitTaskMessage("我是SenderActor, 我在给你发消息!...")}//5. 接收ReceiverActor发送过来的回执信息.case SuccessSubmitTaskMessage(msg) => println(s"SenderActor接收到回执信息: ${msg} ")} } -
ReceiverActor.scala文件中的代码
object ReceiverActor extends Actor {override def receive: Receive = {//1. 接收SenderActor发送过来的消息.case SubmitTaskMessage(msg) => {//2. 打印接收到的消息.println(s"ReceiverActor接收到: ${msg}")//3. 给出回执信息.sender ! SuccessSubmitTaskMessage("接收任务成功!. 我是ReceiverActor")}} }
输出结果
SenderActor接收到: Entrance发送过来的 start 信息.
ReceiverActor接收到: 我是SenderActor, 我在给你发消息!...
SenderActor接收到回执信息: 接收任务成功!. 我是ReceiverActor
3. Akka定时任务
需求: 如果我们想要使用Akka框架定时的执行一些任务,该如何处理呢?
答: 在Akka中,提供了一个scheduler对象来实现定时调度功能。使用ActorSystem.scheduler.schedule()方法,就可以启动一个定时任务。
3.1 schedule()方法的格式
-
方式一: 采用
发送消息的形式实现.def schedule(initialDelay: FiniteDuration, // 延迟多久后启动定时任务interval: FiniteDuration, // 每隔多久执行一次receiver: ActorRef, // 给哪个Actor发送消息message: Any) // 要发送的消息 (implicit executor: ExecutionContext) // 隐式参数:需要手动导入 -
方式二: 采用
自定义方式实现.def schedule(initialDelay: FiniteDuration, // 延迟多久后启动定时任务interval: FiniteDuration // 每隔多久执行一次 )(f: ⇒ Unit) // 定期要执行的函数,可以将逻辑写在这里 (implicit executor: ExecutionContext) // 隐式参数:需要手动导入
注意: 不管使用上述的哪种方式实现定时器, 都需要
导入隐式转换和隐式参数, 具体如下://导入隐式转换, 用来支持 定时器. import actorSystem.dispatcher //导入隐式参数, 用来给定时器设置默认参数. import scala.concurrent.duration._
3.2 案例
需求
- 定义一个ReceiverActor, 用来循环接收消息, 并打印接收到的内容.
- 创建一个ActorSystem, 用来管理所有用户自定义的Actor.
- 关联ActorSystem和ReceiverActor.
- 导入隐式转换和隐式参数.
- 通过定时器, 定时(间隔1秒)给ReceiverActor发送一句话.
- 方式一: 采用发送消息的形式实现.
- 方式二: 采用自定义方式实现.
参考代码
//案例: 演示Akka中的定时器.
object MainActor {//1. 定义一个Actor, 用来循环接收消息, 并打印.object ReceiverActor extends Actor {override def receive: Receive = {case x => println(x) //不管接收到的是什么, 都打印.}}def main(args: Array[String]): Unit = {//2. 创建一个ActorSystem, 用来管理所有用户自定义的Actor.val actorSystem = ActorSystem("actorSystem", ConfigFactory.load())//3. 关联ActorSystem和ReceiverActor.val receiverActor = actorSystem.actorOf(Props(ReceiverActor), "receiverActor")//4. 导入隐式转换和隐式参数.//导入隐式转换, 用来支持 定时器.import actorSystem.dispatcher//导入隐式参数, 用来给定时器设置默认参数.import scala.concurrent.duration._//5. 通过定时器, 定时(间隔1秒)给ReceiverActor发送一句话.//方式一: 通过定时器的第一种方式实现, 传入四个参数.//actorSystem.scheduler.schedule(3.seconds, 2.seconds, receiverActor, "你好, 我是种哥, 我有种子你买吗?...")//方式二: 通过定时器的第二种方式实现, 传入两个时间, 和一个函数.//actorSystem.scheduler.schedule(0 seconds, 2 seconds)(receiverActor ! "新上的种子哟, 你没见过! 嘿嘿嘿...")//实际开发写法actorSystem.scheduler.schedule(0 seconds, 2 seconds){receiverActor ! "新上的种子哟, 你没见过! 嘿嘿嘿..."}}
}
4. 实现两个进程之间的通信
4.1 案例介绍
基于Akka实现在两个进程间发送、接收消息。
- WorkerActor启动后去连接MasterActor,并发送消息给MasterActor.
- MasterActor接收到消息后,再回复消息给WorkerActor。
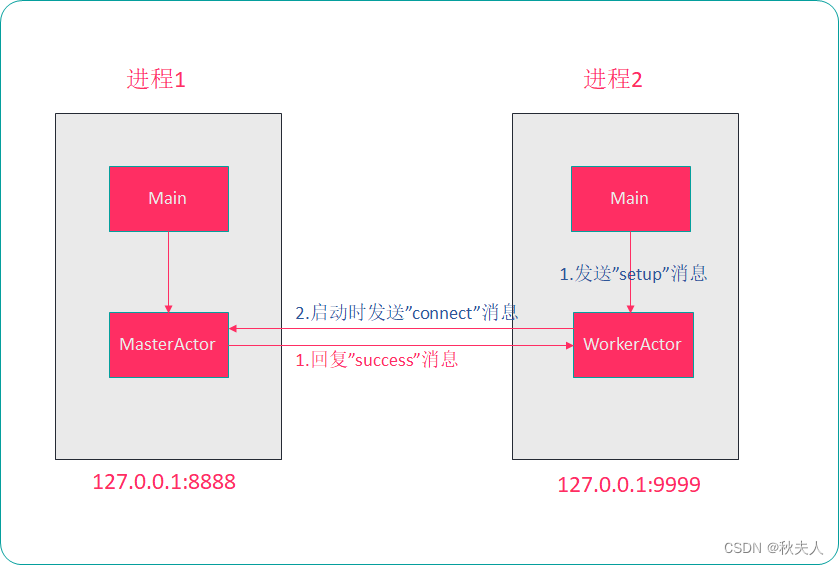
4.2 Worker实现
步骤
-
创建一个Maven模块,导入依赖和配置文件.
-
创建Maven模块.
GroupId: com.itheima
ArtifactID: akka-worker
-
把资料下的pom.xml文件中的内容复制到Maven项目akka-worker的pom.xml文件中
-
把资料下的application.conf复制到 src/main/resources文件夹下.
-
打开 application.conf配置文件, 修改端口号为: 9999
-
-
创建启动WorkerActor.
- 在src/main/scala文件夹下创建包: com.itheima.akka
- 在该包下创建 WorkerActor(单例对象的形式创建).
- 在该包下创建Entrance单例对象, 里边定义main方法
-
发送"setup"消息给WorkerActor,WorkerActor接收打印消息.
-
启动测试.
参考代码
-
WorkerActor.scala文件中的代码
//1. 创建WorkActor, 用来接收和发送消息. object WorkerActor extends Actor{override def receive: Receive = {//2. 接收消息.case x => println(x)} } -
Entrance.scala文件中的代码
//程序入口. //当前ActorSystem对象的路径 akka.tcp://actorSystem@127.0.0.1:9999 object Entrance {def main(args: Array[String]): Unit = {//1. 创建ActorSystem.val actorSystem = ActorSystem("actorSystem", ConfigFactory.load())//2. 通过ActorSystem, 加载自定义的WorkActor.val workerActor = actorSystem.actorOf(Props(WorkerActor), "workerActor")//3. 给WorkActor发送一句话.workerActor ! "setup"} } //启动测试: 右键, 执行, 如果打印结果出现"setup", 说明程序执行没有问题.
4.3 Master实现
步骤
-
创建一个Maven模块,导入依赖和配置文件.
-
创建Maven模块.
GroupId: com.itheima
ArtifactID: akka-master
-
把资料下的pom.xml文件中的内容复制到Maven项目akka-master的pom.xml文件中
-
把资料下的application.conf复制到 src/main/resources文件夹下.
-
打开 application.conf配置文件, 修改端口号为: 8888
-
-
创建启动MasterActor.
- 在src/main/scala文件夹下创建包: com.itheima.akka
- 在该包下创建 MasterActor(单例对象的形式创建).
- 在该包下创建Entrance单例对象, 里边定义main方法
-
WorkerActor发送"connect"消息给MasterActor
-
MasterActor回复"success"消息给WorkerActor
-
WorkerActor接收并打印接收到的消息
-
启动Master、Worker测试
参考代码
-
MasterActor.scala文件中的代码
//MasterActor: 用来接收WorkerActor发送的数据, 并给其返回 回执信息. //负责管理MasterActor的ActorSystem的地址: akka.tcp://actorSystem@127.0.0.1:8888 object MasterActor extends Actor{override def receive: Receive = {//1. 接收WorkerActor发送的数据case "connect" => {println("MasterActor接收到: connect!...")//2. 给WorkerActor回执一句话.sender ! "success"}} } -
Entrance.scala文件中的代码
//Master模块的主入口 object Entrance {def main(args: Array[String]): Unit = {//1. 创建ActorSystem, 用来管理用户所有的自定义Actor.val actorSystem = ActorSystem("actorSystem", ConfigFactory.load())//2. 关联ActorSystem和MasterActor.val masterActor = actorSystem.actorOf(Props(MasterActor), "masterActor")//3. 给masterActor发送一句话: 测试数据, 用来测试.//masterActor ! "测试数据"} } -
WorkerActor.scala文件中的代码(就修改了第3步)
//WorkerActor: 用来接收ActorSystem发送的消息, 并发送消息给MasterActor, 然后接收MasterActor的回执信息. //负责管理WorkerActor的ActorSystem的地址: akka.tcp://actorSystem@127.0.0.1:9999 object WorkerActor extends Actor{override def receive: Receive = {//1. 接收Entrance发送过来的: setup.case "setup" => {println("WorkerActor接收到: Entrance发送过来的指令 setup!.")//2. 获取MasterActor的引用.val masterActor = context.system.actorSelection("akka.tcp://actorSystem@127.0.0.1:8888/user/masterActor")//3. 给MasterActor发送一句话.masterActor ! "connect"}//4. 接收MasterActor的回执信息.case "success" => println("WorkerActor接收到: success!")} }
5. 案例: 简易版spark通信框架
5.1 案例介绍
模拟Spark的Master与Worker通信.
- 一个Master
- 管理多个Worker
- 若干个Worker(Worker可以按需添加)
- 向Master发送注册信息
- 向Master定时发送心跳信息
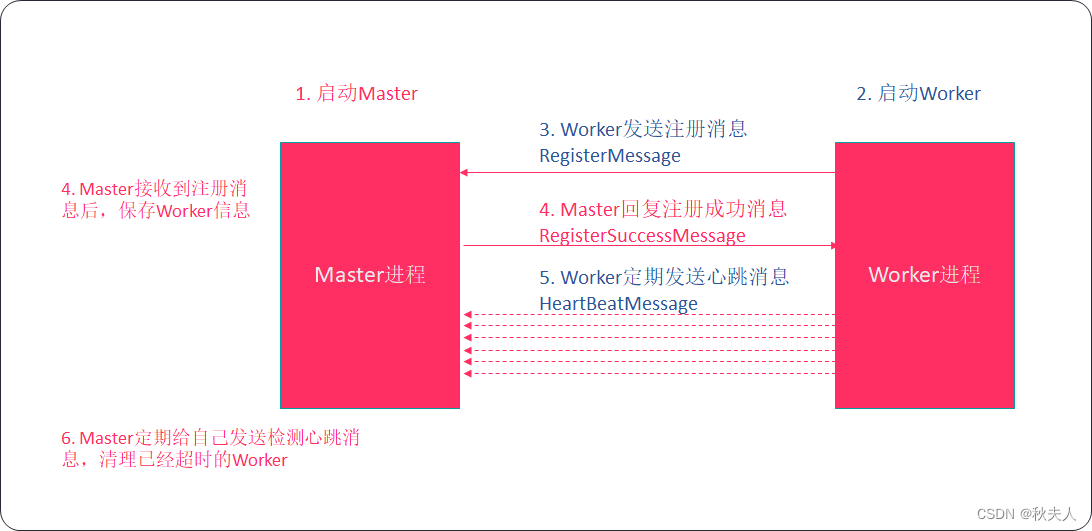
5.2 实现思路
- 构建Master、Worker阶段
- 构建Master ActorSystem、Actor
- 构建Worker ActorSystem、Actor
- Worker注册阶段
- Worker进程向Master注册(将自己的ID、CPU核数、内存大小(M)发送给Master)
- Worker定时发送心跳阶段
- Worker定期向Master发送心跳消息
- Master定时心跳检测阶段
- Master定期检查Worker心跳,将一些超时的Worker移除,并对Worker按照内存进行倒序排序
- 多个Worker测试阶段
- 启动多个Worker,查看是否能够注册成功,并停止某个Worker查看是否能够正确移除
5.3 工程搭建
需求
本项目使用Maven搭建工程.
步骤
- 分别搭建以下几个项目, Group ID统一都为: com.itheima, 具体工程名如下:
| 工程名 | 说明 |
|---|---|
| spark-demo-common | 存放公共的消息、实体类 |
| spark-demo-master | Akka Master节点 |
| spark-demo-worker | Akka Worker节点 |
-
导入依赖(资料包中的pom.xml).
注意: master, worker要添加common依赖, 具体如下:
<!--导入spark-demo-common模块--> <dependency><groupId>com.itheima</groupId><artifactId>spark-demo-common</artifactId><version>1.0-SNAPSHOT</version> </dependency> -
分别在三个项目下的src/main, src/test下, 创建scala目录.
-
导入配置文件(资料包中的application.conf)
- 修改Master的端口为7000
- 修改Worker的端口为8000
5.4 构建Master和Worker
需求
分别构建Master和Worker,并启动测试
步骤
- 创建并加载Master Actor
- 创建并加载Worker Actor
- 测试是否能够启动成功
参考代码
-
完成master模块中的代码, 即: 在src/main/scala下创建包: com.itheima.spark.master, 包中代码如下:
-
MasterActor.scala文件中的代码
//Master: 用来管理多个Worker的. //MasterActor的路径: akka.tcp://actorSystem@127.0.0.1:7000 object MasterActor extends Actor{override def receive: Receive = {case x => println(x)} } -
Master.scala文件中的代码
//程序入口: 相当于我们以前写的MainActor object Master {def main(args: Array[String]): Unit = {//1. 创建ActorSystem.val actorSystem = ActorSystem("actorSystem", ConfigFactory.load())//2. 通过ActorSystem, 关联MasterActor.val masterActor = actorSystem.actorOf(Props(MasterActor), "masterActor")//3. 启动程序, 如果不报错, 说明代码没有问题.} }
-
-
完成worker模块中的代码, 即: 在src/main/scala下创建包: com.itheima.spark.worker, 包中代码如下:
-
WorkerActor.scala文件中的代码
//WorkerActor的地址: akka.tcp://actorSystem@127.0.0.1:7100 object WorkerActor extends Actor{override def receive: Receive = {case x => println(x)} } -
Worker.scala文件中的代码
//程序入口 object Worker {def main(args: Array[String]): Unit = {//1. 创建ActorSystem.val actorSystem = ActorSystem("actorSystem", ConfigFactory.load())//2. 通过ActorSystem, 关联MasterActor.val workerActor = actorSystem.actorOf(Props(WorkerActor), "workerActor")//3. 启动程序, 如果不报错, 说明代码没有问题.workerActor ! "hello"} }
-
5.5 Worker注册阶段实现
需求
在Worker启动时,发送注册消息给Master.
思路分析
- Worker向Master发送注册消息(workerid、cpu核数、内存大小)
- 随机生成CPU核(1、2、3、4、6、8)
- 随机生成内存大小(512、1024、2048、4096)(单位M)
- Master保存Worker信息,并给Worker回复注册成功消息
- 启动测试
具体步骤
-
在spark-demo-common项目的src/main/scala文件夹下创建包: com.itheima.spark.commons
把资料下的MessagePackage.scala和Entities.scala这两个文件拷贝到commons包下.
-
在WorkerActor单例对象中定义一些成员变量, 分别表示:
- masterActorRef: 表示MasterActor的引用.
- workerid: 表示当前WorkerActor对象的id.
- cpu: 表示当前WorkerActor对象的CPU核数.
- mem: 表示当前WorkerActor对象的内存大小.
- cup_list: 表示当前WorkerActor对象的CPU核心数的取值范围.
- mem_list: 表示当前WorkerActor对象的内存大小的取值范围.
-
在WorkerActor的preStart()方法中, 封装注册信息, 并发送给MasterActor.
-
在MasterActor中接收WorkerActor提交的注册信息, 并保存到双列集合中…
-
MasterActor给WorkerActor发送回执信息(注册成功信息.).
-
在WorkerActor中接收MasterActor回复的 注册成功信息.
参考代码
-
WorkerActor.scala文件中的代码
//WorkerActor的地址: akka.tcp://actorSystem@127.0.0.1:7100 object WorkerActor extends Actor {//1 定义成员变量, 记录MasterActor的引用, 以及WorkerActor提交的注册参数信息.private var masterActorRef: ActorSelection = _ //表示MasterActor的引用.private var workerid:String = _ //表示WorkerActor的idprivate var cpu:Int = _ //表示WorkerActor的CPU核数private var mem:Int = _ //表示WorkerActor的内存大小.private val cpu_list = List(1, 2, 3, 4, 6, 8) //CPU核心数的取值范围private val mem_list = List(512, 1024, 2048, 4096) //内存大小取值范围//2. 重写preStart()方法, 里边的内容: 在Actor启动之前就会执行.override def preStart(): Unit = {//3. 获取Master的引用.masterActorRef = context.actorSelection("akka.tcp://actorSystem@127.0.0.1:7000/usre/masterActor")//4. 构建注册消息.workerid = UUID.randomUUID().toString //设置workerActor的idval r = new Random()cpu = cpu_list(r.nextInt(cpu_list.length))mem = mem_list(r.nextInt(mem_list.length))//5. 将WorkerActor的提交信息封装成 WorkerRegisterMessage对象.var registerMessage = WorkerRegisterMessage(workerid, cpu, mem)//6. 发送消息给MasterActor.masterActorRef ! registerMessage}override def receive: Receive = {case x => println(x)} } -
MasterActor.scala文件中的代码
//Master: 用来管理多个Worker的. //MasterActor的路径: akka.tcp://actorSystem@127.0.0.1:7000 object MasterActor extends Actor{//1. 定义一个可变的Map集合, 用来保存注册成功好的Worker信息.private val regWorkerMap = collection.mutable.Map[String, WorkerInfo]()override def receive: Receive = {case WorkerRegisterMessage(workId, cpu, mem) => {//2. 打印接收到的注册信息println(s"MasterActor: 接收到worker注册信息, ${workId}, ${cpu}, ${mem}")//3. 把注册成功后的保存信息保存到: workInfo中.regWorkerMap += workId -> WorkerInfo(workId, cpu, mem)//4. 回复一个注册成功的消息.sender ! RegisterSuccessMessage}} } -
修改WorkerActor.scala文件中receive()方法的代码
override def receive: Receive = {case RegisterSuccessMessage => println("WorkerActor: 注册成功!") }
5.6 Worker定时发送心跳阶段
需求
Worker接收到Master返回的注册成功信息后,定时给Master发送心跳消息。而Master收到Worker发送的心跳消息后,需要更新对应Worker的最后心跳时间。
思路分析
- 编写工具类读取心跳发送时间间隔
- 创建心跳消息
- Worker接收到注册成功后,定时发送心跳消息
- Master收到心跳消息,更新Worker最后心跳时间
- 启动测试
具体步骤
-
在worker的src/main/resources文件夹下的 application.conf文件中添加一个配置.
worker.heartbeat.interval = 5 //配置worker发送心跳的周期(单位是 s)
-
在worker项目的com.itheima.spark.work包下创建一个新的单例对象: ConfigUtils, 用来读取配置文件信息.
-
在WorkerActor的receive()方法中, 定时给MasterActor发送心跳信息.
-
Master接收到心跳消息, 更新Worker最后心跳时间. .
参考代码
-
worker项目的ConfigUtils.scala文件中的代码
object ConfigUtils {//1. 获取配置信息对象.private val config = ConfigFactory.load()//2. 获取worker心跳的具体周期val `worker.heartbeat.interval` = config.getInt("worker.heartbeat.interval") } -
修改WorkerActor.scala文件的receive()方法中的代码
override def receive: Receive = {case RegisterSuccessMessage => {//1. 打印接收到的 注册成功消息println("WorkerActor: 接收到注册成功消息!")//2. 导入时间单位隐式转换 和 隐式参数import scala.concurrent.duration._import context.dispatcher //3. 定时给Master发送心跳消息.context.system.scheduler.schedule(0 seconds, ConfigUtil.`worker.heartbeat.interval` seconds){//3.1 采用自定义的消息的形式发送 心跳信息.masterActorRef ! WorkerHeartBeatMessage(workerId, cpu, mem)}} } -
MasterActor.scala文件中的代码
object MasterActor extends Actor {//1. 定义一个可变的Map集合, 用来保存注册成功好的Worker信息.private val regWorkerMap = collection.mutable.Map[String, WorkerInfo]()override def receive: Receive = {//接收注册信息.case WorkerRegisterMessage(workId, cpu, mem) => {//2. 打印接收到的注册信息println(s"MasterActor: 接收到worker注册信息, ${workId}, ${cpu}, ${mem}")//3. 把注册成功后的保存信息保存到: workInfo中.regWorkerMap += workId -> WorkerInfo(workId, cpu, mem, new Date().getTime)//4. 回复一个注册成功的消息.sender ! RegisterSuccessMessage}//接收心跳消息case WorkerHeartBeatMessage(workId, cpu, mem) => {//1. 打印接收到的心跳消息.println(s"MasterActor: 接收到${workId}的心跳信息")//2. 更新指定Worker的最后一次心跳时间.regWorkerMap += workId -> WorkerInfo(workId, cpu, mem, new Date().getTime)//3. 为了测试代码逻辑是否OK, 我们可以打印下 regWorkerMap的信息println(regWorkerMap)}} }
5.7 Master定时心跳检测阶段
需求
如果某个worker超过一段时间没有发送心跳,Master需要将该worker从当前的Worker集合中移除。可以通过Akka的定时任务,来实现心跳超时检查。
思路分析
- 编写工具类,读取检查心跳间隔时间间隔、超时时间
- 定时检查心跳,过滤出来大于超时时间的Worker
- 移除超时的Worker
- 对现有Worker按照内存进行降序排序,打印可用Worker
具体步骤
-
修改Master的application.conf配置文件, 添加两个配置
#配置检查Worker心跳的时间周期(单位: 秒)
master.check.heartbeat.interval = 6
#配置worker心跳超时的时间(秒)
master.check.heartbeat.timeout = 15 -
在Master项目的com.itheima.spark.master包下创建: ConfigUtils工具类(单例对象), 用来读取配置文件信息.
-
在MasterActor中开始检查心跳(即: 修改MasterActor#preStart中的代码.).
-
开启Master, 然后开启Worker, 进行测试.
参考代码
-
Master项目的ConfigUtils.scala文件中的代码
//针对Master的工具类. object ConfigUtil {//1. 获取到配置文件对象.private val config: Config = ConfigFactory.load()//2. 获取检查Worker心跳的时间周期(单位: 秒)val `master.check.heartbeat.interval` = config.getInt("master.check.heartbeat.interval")//3. 获取worker心跳超时的时间(秒)val `master.check.heartbeat.timeout` = config.getInt("master.check.heartbeat.timeout") } -
MasterActor.scala文件的preStart()方法中的代码
//5. 定时检查worker的心跳信息 override def preStart(): Unit = {//5.1 导入时间转换隐式类型 和 定时任务隐式变量import scala.concurrent.duration._import context.dispatcher//5.2 启动定时任务.context.system.scheduler.schedule(0 seconds, ConfigUtil.`master.check.heartbeat.interval` seconds) {//5.3 过滤大于超时时间的Worker.val timeOutWorkerMap = regWorkerMap.filter {keyval =>//5.3.1 获取最后一次心跳更新时间.val lastHeatBeatTime = keyval._2.lastHeartBeatTime//5.3.2 超时公式: 当前系统时间 - 最后一次心跳时间 > 超时时间(配置文件信息 * 1000)if (new Date().getTime - lastHeatBeatTime > ConfigUtil.`master.check.heartbeat.timeout` * 1000) true else false}//5.4 移除超时的Workerif(!timeOutWorkerMap.isEmpty) {//如果要被移除的Worker集合不为空, 则移除此 timeOutWorkerMap//注意: 双列集合是根据键移除元素的, 所以最后的 _._1是在获取键.regWorkerMap --= timeOutWorkerMap.map(_._1)}//5.5 对worker按照内存大小进行降序排序, 打印Worker//_._2 获取所有的WorkInfo对象.val workerList = regWorkerMap.map(_._2).toList//5.6 按照内存进行降序排序.val sortedWorkerList = workerList.sortBy(_.mem).reverse//5.7 打印结果println("按照内存的大小降序排列的Worker列表: ")println(sortedWorkerList)} }
5.8 多个Worker测试阶段
需求
修改配置文件,启动多个worker进行测试。
大白话: 启动一个Worker, 就修改一次Worker项目下的application.conf文件中记录的端口号, 然后重新开启Worker即可.
步骤
- 测试启动新的Worker是否能够注册成功
- 停止Worker,测试是否能够从现有列表删除
5.8 多个Worker测试阶段
需求
修改配置文件,启动多个worker进行测试。
大白话: 启动一个Worker, 就修改一次Worker项目下的application.conf文件中记录的端口号, 然后重新开启Worker即可.
步骤
- 测试启动新的Worker是否能够注册成功
- 停止Worker,测试是否能够从现有列表删除
相关文章:
Scala第二十章节
Scala第二十章节 scala总目录 文档资料下载 章节目标 理解Akka并发编程框架简介掌握Akka入门案例掌握Akka定时任务代码实现掌握两个进程间通信的案例掌握简易版spark通信框架案例 1. Akka并发编程框架简介 1.1 Akka概述 Akka是一个用于构建高并发、分布式和可扩展的基于事…...
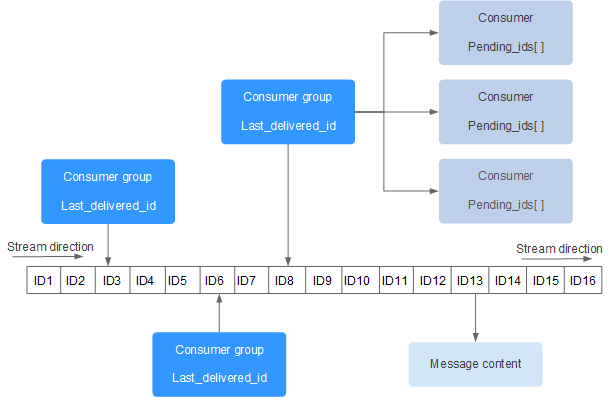
redis的持久化消息队列
Redis Stream Redis Stream 是 Redis 5.0 版本新增加的数据结构。 Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法…...

分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测
分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测 目录 分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测࿰…...

用 Pytorch 自己构建一个Transformer
一、说明 用pytorch自己构建一个transformer并不是难事,本篇使用pytorch随机生成五千个32位数的词向量做为源语言词表,再生成五千个32位数的词向量做为目标语言词表,让它们模拟翻译过程,transformer全部用pytorch实现,具备一定实战意义。 二、论文和概要 …...

Docker安装ActiveMQ
ActiveMQ简介 官网地址:https://activemq.apache.org/ 简介: ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,…...
【二】spring boot-设计思想
spring boot-设计思想 简介:现在越来越多的人开始分析spring boot源码,拿到项目之后就有点无从下手了,这里介绍一下springboot源码的项目结构 一、项目结构 从上图可以看到,源码分为两个模块: spring-boot-project&a…...

系统架构设计:7 论企业集成架构设计及应用
目录 一 企业集成 1 企业集成分类:按照集成点分 (1)界面集成(表示集成)...

【pytorch】多GPU同时训练模型
文章目录 1. 基本原理单机多卡训练教程——DP模式 2. Pytorch进行单机多卡训练步骤1. 指定GPU2. 更改模型训练方式3. 更改权重保存方式 摘要:多GPU同时训练,能够解决单张GPU显存不足问题,同时加快模型训练。 1. 基本原理 单机多卡训练教程—…...
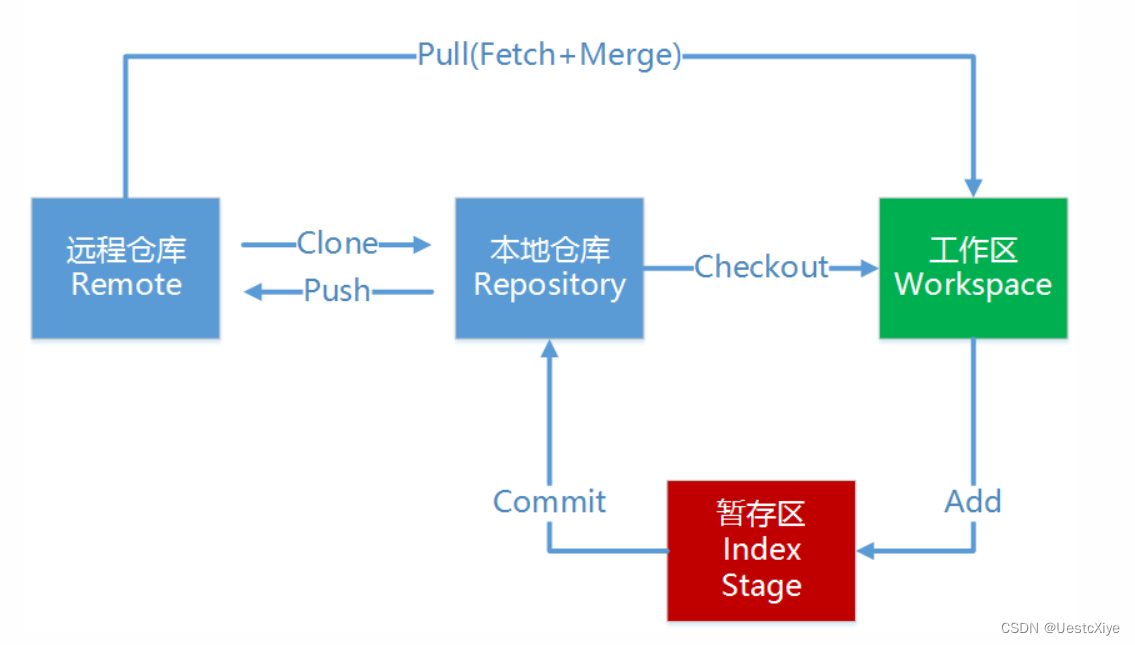
Git 学习笔记 | Git 基本理论
Git 学习笔记 | Git 基本理论 Git 学习笔记 | Git 基本理论Git 工作区域Git 工作流程 Git 学习笔记 | Git 基本理论 在开始使用 Git 创建项目前,我们先学习一下 Git 的基础理论。 Git 工作区域 Git本地有三个工作区域:工作目录(Working Di…...

滚动表格封装
滚动表格封装 我们先设定接收的参数 需要表头内容columns,表格数据data,需要currentSlides来控制当前页展示几行 const props defineProps({// 表头内容columns: {type: Array,default: () > [],required: true,},// 表格数据data: {type: Array,d…...

【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题
文章目录 【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题⛅前言 平均售价🔒题目🔑题解 项目员工I🔒题目🔑题解 各赛事的用户注册率🔒题目🔑题解 查询结果的质量和占比🔒题目&am…...

系统压力测试:保障系统性能与稳定的重要措施
压力测试简介 在当今数字化时代,各种系统和应用程序扮演着重要角色,从企业的核心业务系统到在线服务平台,都需要具备高性能和稳定性,以满足用户的需求。然而,随着用户数量和业务负载的增加,系统可能会面临…...

常用数据结构和算法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、时间复杂度二、使用步骤 1.引入库2.读入数据总结 前言 提示:这里可以添加本文要记录的大概内容: 这里面有10个数据结构࿱…...

C++中使用引用避免内存复制
C中使用引用避免内存复制 引用让您能够访问相应变量所在的内存单元,这使得编写函数时引用很有用。典型的函数声明类似于下面这样: ReturnType DoSomething(Type parameter);调用函数 DoSomething() 的代码类似于下面这样: ReturnType Resu…...
计算机网络(第8版)-第4章 网络层
4.1 网络层的几个重要概念 4.1.1 网络层提供的两种服务 如果主机(即端系统)进程之间需要进行可靠的通信,那么就由主机中的运输层负责(包括差错处理、流量控制等)。 4.1.2 网络层的两个层面 4.2 网际协议 IP 图4-4 网…...
chromadb 0.4.0 后的改动
本文基于一篇上次写的博客:[开源项目推荐]privateGPT使用体验和修改 文章目录 一.上次改好的ingest.py用不了了,折腾了一会儿二.发现privateGPT官方更新了总结下变化效果 三.others 一.上次改好的ingest.py用不了了,折腾了一会儿 pydantic和c…...
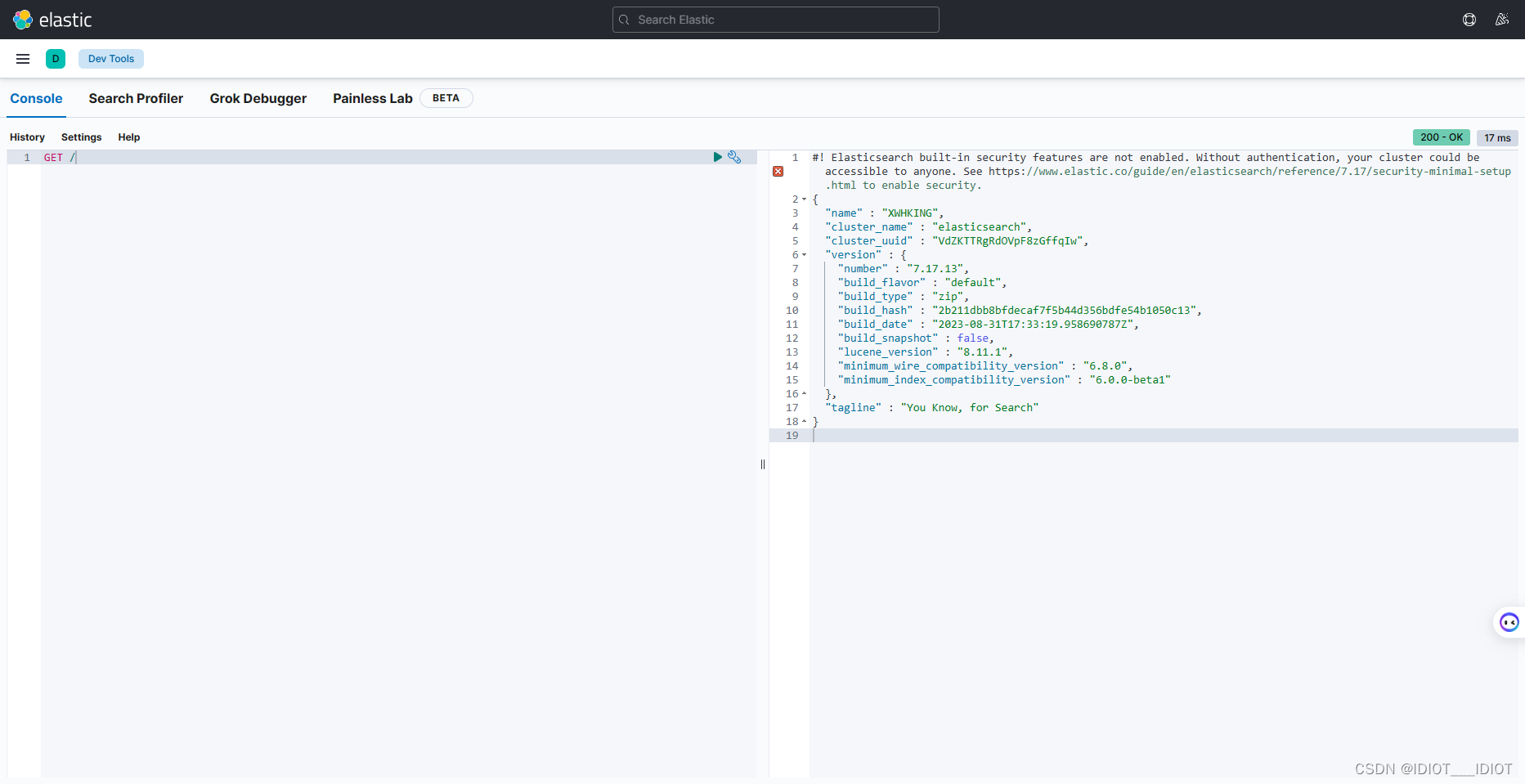
Windows环境下下载安装Elasticsearch和Kibana
Windows环境下下载安装Elasticsearch和Kibana 首先说明这里选择的版本都是7.17 ,为什么不选择新版本,新版本有很多坑,要去踩,就用7就够了。 Elasticsearch下载 Elasticsearch是一个开源的分布式搜索和分析引擎,最初由…...
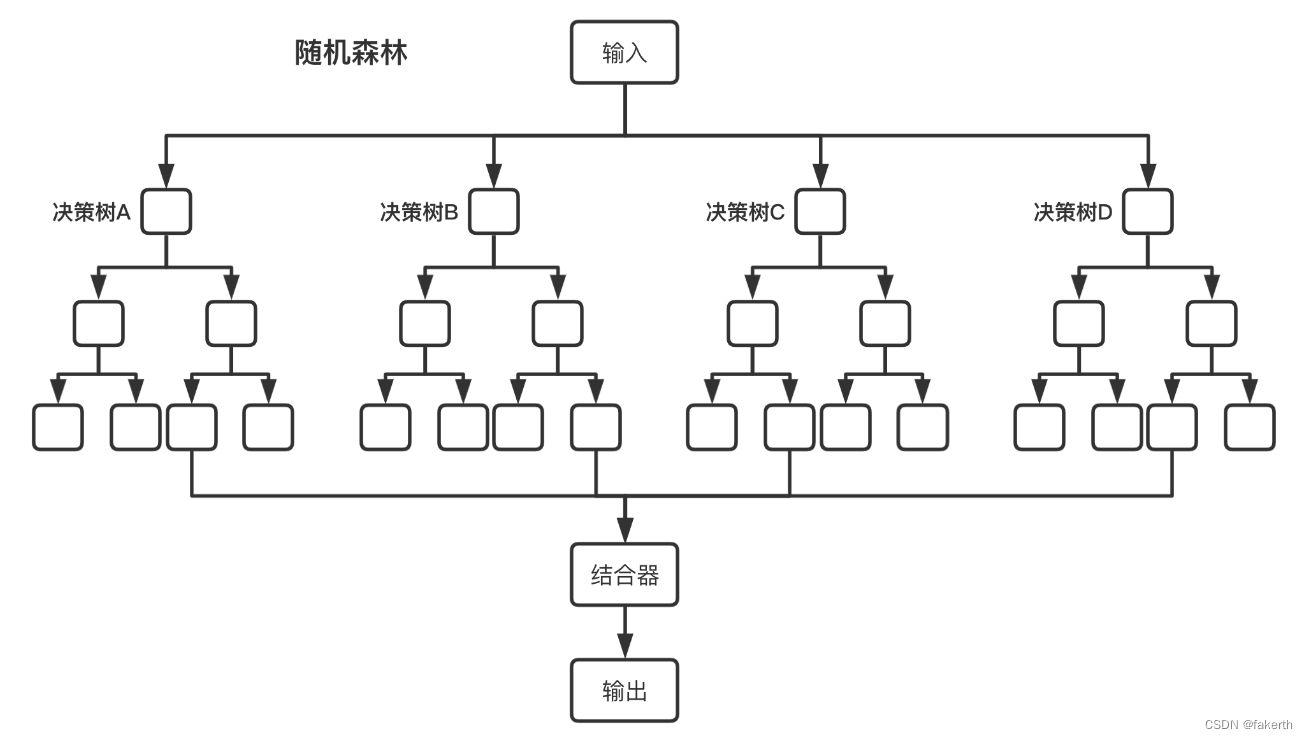
机器学习:随机森林
集成学习 集成学习(Ensemble Learning)是一种机器学习方法,通过将多个基本学习算法的预测结果进行组合,以获得更好的预测性能。集成学习的基本思想是通过结合多个弱分类器或回归器的预测结果,来构建一个更强大的集成模…...
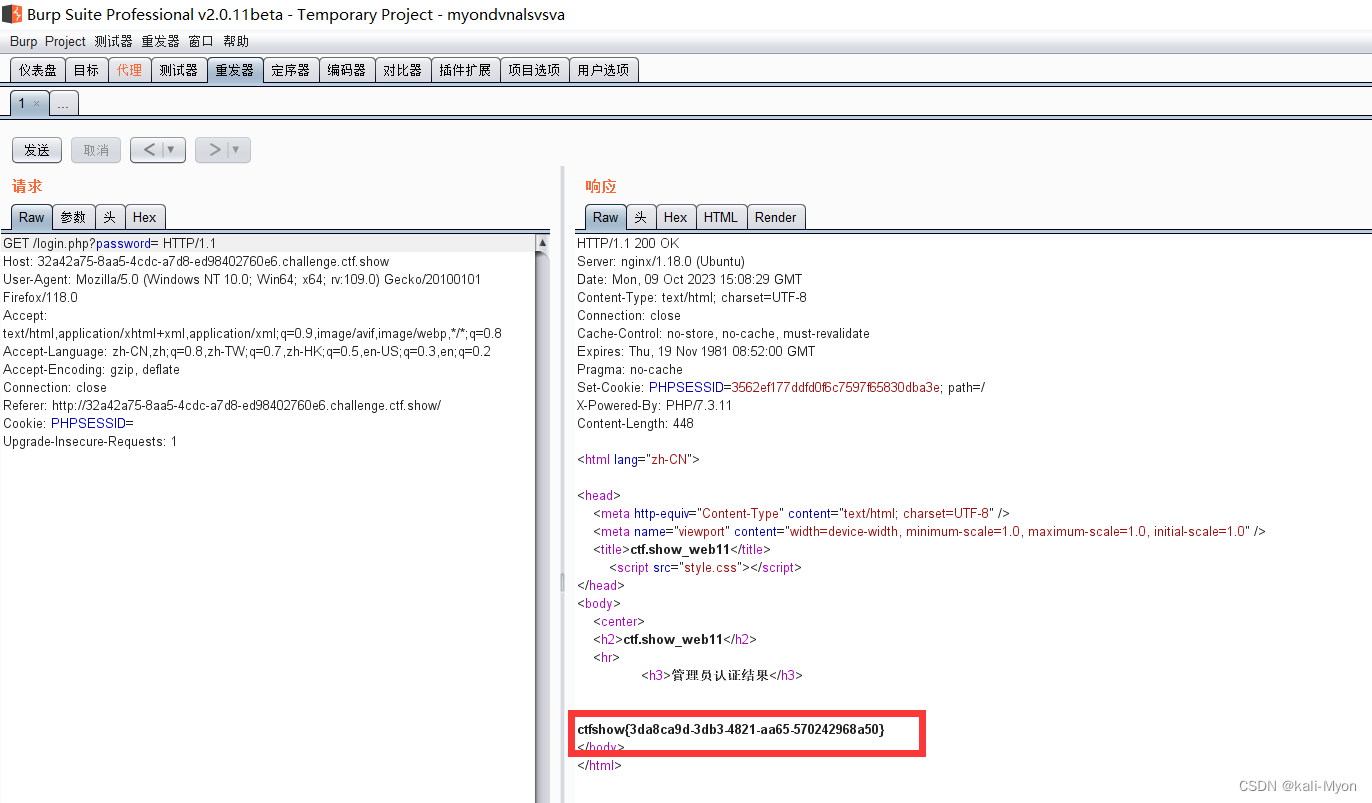
ctfshow-web11(session绕过)
php代码审计: function replaceSpecialChar($strParam){$regex "/(select|from|where|join|sleep|and|\s|union|,)/i";return preg_replace($regex,"",$strParam);} 首先定义了一个函数,主要是使用preg_replace函数对我们提交的内…...

状态模式:对象状态的变化
欢迎来到设计模式系列的第十七篇文章。在本文中,我们将深入探讨状态模式,这是一种行为型设计模式,用于管理对象的状态以及状态之间的变化。 什么是状态模式? 状态模式是一种允许对象在内部状态发生变化时改变其行为的设计模式。…...

proxy-doctor:自动化诊断与修复开发工具代理配置的利器
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的项目时,遇到了一个老生常谈但又极其恼人的问题:代理配置。无论是开发环境里的包管理工具,还是日常使用的命令行工具,一旦涉及到网络请求,代理设置不对ÿ…...

AI智能体编排平台:从任务自动化到生态协作的架构与实践
1. 项目概述:一个面向AI编排与技能提升的生态协作平台最近在和一些做AI应用开发的朋友聊天,大家普遍有个痛点:现在AI工具和模型太多了,从大语言模型到图像生成,再到各种自动化脚本,每个都很强大,…...

GD32F103C8T6烧录方式全解析:串口ISP、ST-Link Utility、Keil在线,哪种最适合你?
GD32F103C8T6烧录方案深度评测:从原型开发到量产部署的全场景指南 在嵌入式开发领域,选择正确的程序烧录方式往往决定着开发效率和生产成本。作为STM32F103的国产替代方案,GD32F103C8T6凭借其出色的性价比赢得了广泛关注。但许多开发者在迁移…...

基于Adafruit FLORA的红外遥控胸针DIY:从嵌入式编程到可穿戴艺术
1. 项目概述:一个藏在时尚配饰里的“电视终结者”几年前,我在一个朋友聚会上,发现大家明明在聊天,眼睛却总是不自觉地瞟向角落里那个正在播放无聊广告的电视。直接走过去关掉显得有点突兀,找遥控器又太麻烦。那一刻我就…...

UEFITool解析指南:三步骤掌握固件逆向分析的核心技术
UEFITool解析指南:三步骤掌握固件逆向分析的核心技术 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款功能强大的UEFI固件分析工具,能够帮助你深入探索计…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...
.name()到可读类型名)
C++运行时类型识别实战:从typeid().name()到可读类型名
1. 为什么我们需要关心运行时类型识别? 在C开发中,我们经常会遇到需要知道某个变量或表达式具体类型的情况。特别是在调试复杂代码、编写泛型程序或进行元编程时,能够准确获取类型信息就显得尤为重要。想象一下,当你看到一个日志输…...

开源婚礼技能库:用项目管理思维破解备婚焦虑,打造个性化高性价比婚礼
1. 项目概述:婚礼技能库的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“awesome-wedding-skills”。光看名字,你可能会觉得这又是一个普通的“awesome”系列资源列表,无非是收集一些婚礼策划、摄影、化妆的链接。但当我点…...

MCP-Commander:让AI助手操作本地文件与命令行的智能接口
1. 项目概述:一个连接思维与执行的智能接口最近在折腾AI工作流的时候,发现了一个挺有意思的项目,叫nmindz/mcp-commander。乍一看这个名字,可能有点摸不着头脑,但如果你正在尝试让大型语言模型(LLM…...

汽车该多久换一代
汽车该多久换一代 买车的人其实不怕四年换代,怕的是刚提车半年就被新款打成旧款。李想这句话能引起讨论,原因也在这里:车企说的是研发验证周期,车主感受到的是价格、配置和二手残值。 汽车确实没法完全照着手机节奏跑。手机坏了可…...