【C/C++】STL——深度剖析vector容器

👻内容专栏: C/C++编程
🐨本文概括:vector的介绍与使用、深度剖析及模拟实现。
🐼本文作者: 阿四啊
🐸发布时间:2023.10.8
一、vector的介绍与使用
1. vector的介绍
像string的学习一样,我们依旧得学会在cplusplus网站中学会查看文档。
关于vector的文档介绍

- vector是表示可变大小数组的序列容器。
- 就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素
进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自
动处理。 - 本质讲,vector使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小
为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是
一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大
小。 - vector分配空间策略:vector会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存
储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是
对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。 - 因此,vector占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增
长。 - 与其它动态序列容器相比(deque, list and forward_list), vector在访问元素的时候更加高效,在末
尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list和forward_list
统一的迭代器和引用更好。
使用STL的三个境界:能用,明理,能扩展 ,那么下面学习vector,我们也是按照这个方法去学习
2. vector的使用
vector在实际中非常的重要,在实际中我们熟悉常见的接口就可以。我们一一介绍学习常见的vector接口。
2.1 vector的定义
| constructor构造函数声明 | 接口说明 |
|---|---|
| vector()(重点) | 无参构造 |
| vector(size_type n, const value_type& val = value_type()) | 构造并初始化n个val |
| vector (const vector& x);(重点) | 拷贝构造 |
| vector (InputIterator first, InputIterator last) | 使用迭代器进行初始化构造 |
//vector的构造
void test_vector1()
{vector<int> v1; // 无参初始化vector<int> v2(10, 1); //带参初始化//利用迭代区间进行初始化vector<int> v3(v1.begin(), v1.end());vector<int> v4(v2); //拷贝构造//也利用string的迭代区间也可以进行初始化string s1("hello world");vector<int> v5(s1.begin(), s1.end());vector<int>::iterator it = v5.begin();while (it != v5.end()){//打印字符所对应的ascii码值cout << *it << " ";it++;}
}
2.2 vector 迭代器的使用
| iterator的使用 | 接口说明 |
|---|---|
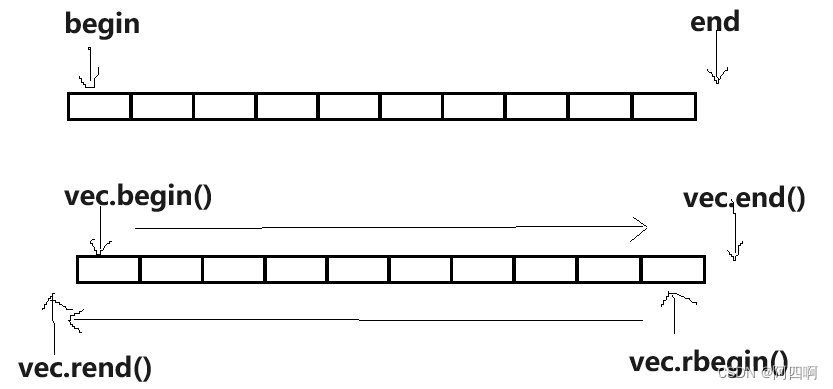
| begin/cbegin + end/cend | 获取第一个数据位置的iterator/const_iterator, 获取最后一个数据的下一个位置的iterator/const_iterator |
| rbegin + rend | 获取最后一个数据位置的reverse_iterator,获取第一个数据前一个位置的reverse_iterator |
void PrintVector(const vector<int>& v)
{// const对象使用const迭代器进行遍历打印vector<int>::const_iterator it = v.begin();while (it != v.end()){cout << *it << " ";++it;}cout << endl;
}void test_vector2()
{vector<int> vec(10,0);vector<int>::iterator it = vec.begin();while (it != vec.end()){cout << *it << " ";it++;}cout << endl;//使用迭代器进行修改it = vec.begin();int i = 1;while (it != vec.end()){*it += i;it++;i++;}//反向迭代器auto rit = vec.rbegin();while (rit != vec.rend()){cout << *rit << " ";rit++;}cout << endl;//迭代器遍历打印vecPrintVector(vec);
}
2.3 空间增长问题
| 容量空间 | 接口说明 |
|---|---|
| size | 获取数据个数 |
| capacity | 获取容量大小 |
| empty | 判断是否为空 |
| resize | 改变vector的size |
| reserve | 改变vector的capacity |
- capacity的代码在vs和g++下分别运行会发现,vs下capacity是按1.5倍增长的,g++是按2倍增长的。这个问题经常会考察,不要固化的认为,vector增容都是2倍,具体增长多少是根据具体的需求定义的。vs是PJ版本STL,g++是SGI版本STL。
- reserve只负责开辟空间,如果预知需要用多少空间,reserve可以缓解vector频繁增容的代价缺陷问题。resize在开空间的同时还会进行初始化,影响size。
// 测试vector的默认扩容机制
void TestVectorExpand()
{size_t sz;vector<int> v;sz = v.capacity();cout << "making v grow:\n";for (int i = 0; i < 100; ++i){v.push_back(i);if (sz != v.capacity()){sz = v.capacity();cout << "capacity changed: " << sz << '\n';}}
}
vs:运行结果:vs下使用的STL基本是按照1.5倍方式扩容
making foo grow:
capacity changed: 1
capacity changed: 2
capacity changed: 3
capacity changed: 4
capacity changed: 6
capacity changed: 9
capacity changed: 13
capacity changed: 19
capacity changed: 28
capacity changed: 42
capacity changed: 63
capacity changed: 94
capacity changed: 141g++运行结果:linux下使用的STL基本是按照2倍方式扩容
making foo grow:
capacity changed: 1
capacity changed: 2
capacity changed: 4
capacity changed: 8
capacity changed: 16
capacity changed: 32
capacity changed: 64
capacity changed: 128
// 如果已经确定vector中要存储元素大概个数,可以提前将空间设置足够
// 就可以避免边插入边扩容导致效率低下的问题了
void TestVectorExpandOP()
{vector<int> v;size_t sz = v.capacity();v.reserve(100); // 提前将容量设置好,可以避免一遍插入一遍扩容cout << "making bar grow:\n";for (int i = 0; i < 100; ++i){v.push_back(i);if (sz != v.capacity()){sz = v.capacity();cout << "capacity changed: " << sz << '\n';}}
}
2.4 vector的增删查改
| vector的增删查改 | 接口说明 |
|---|---|
| push_back | 尾插 |
| pop_back | 尾删 |
| insert | 在position位置之前插入val值 |
| erase | 删除position位置的元素 |
| swap | 交换两个vector的数据空间 |
| operator[ ] | 像数组一样访问 |
| clear | 删除容器的所有元素,将size置为0,但并不改变capacity的大小 |
// 尾插和尾删:push_back/pop_back
void test_vector3()
{vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);auto it = v.begin();while (it != v.end()) {cout << *it << " ";++it;}cout << endl;v.pop_back();v.pop_back();it = v.begin();while (it != v.end()) {cout << *it << " ";++it;}cout << endl;
}// 任意位置插入:insert和erase,以及查找find
// 注意find不是vector自身提供的方法,是STL提供的算法
void test_vector4()
{// 使用列表方式初始化,C++11新语法vector<int> v{ 1, 2, 3, 4 };// 在指定位置前插入值为val的元素,比如:3之前插入30,如果没有则不插入// 1. 先使用find查找3所在位置// 注意:vector没有提供find方法,如果要查找只能使用STL提供的全局findauto pos = find(v.begin(), v.end(), 3);if (pos != v.end()){// 2. 在pos位置之前插入30v.insert(pos, 30);}vector<int>::iterator it = v.begin();while (it != v.end()) {cout << *it << " ";++it;}cout << endl;pos = find(v.begin(), v.end(), 3);// 删除pos位置的数据v.erase(pos);it = v.begin();while (it != v.end()) {cout << *it << " ";++it;}cout << endl;v.clear();//调用clear后,vector的size将变成0,但是它的容量capacity并未发生改变
}
二、vector的底层实现
1.说明和准备工作
创建一个vector的源文件,写一个vector的类模板,放入一个自己的MyVector的命名空间里面,以免与库里面的vector发生冲突。
在模拟vector时,我们并没有和string一样使用动态分配的指针_Ptr、_size、_capacity,在类中我们使用了三个iterator,贴近stl库里面的实现方式,其实本质就是原生指针。
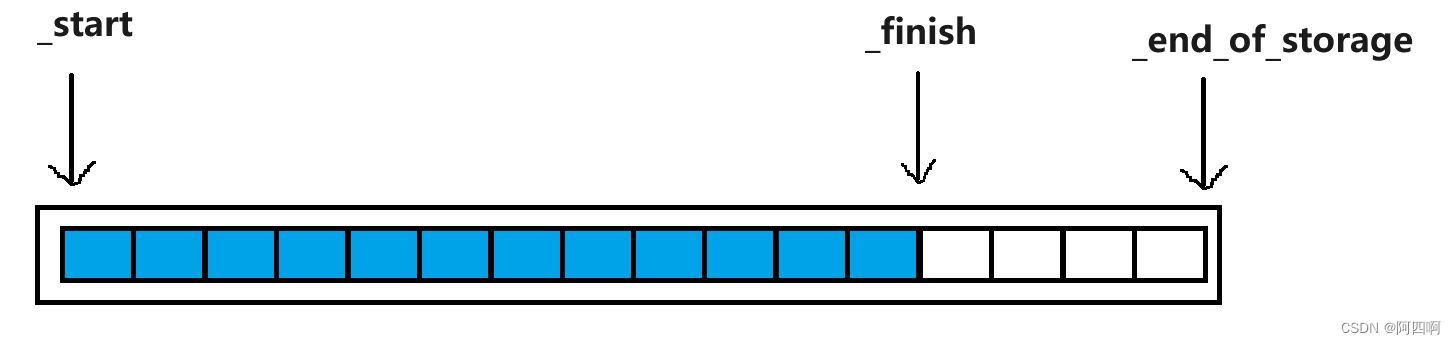
_start: _start指向动态数组或容器的第一个元素的位置。它用于表示容器的起始位置。
_finish: _finish 也是一个指针,指向容器中当前元素的下一个位置。它表示容器中元素的结束位置。通常,_finish 处于有效元素的末尾,但它之后的内存可能已经分配,但未被使用。
_end_of_storage: _end_of_storage 指向容器内存分配的末尾位置。这个位置之后的内存是容器为将来添加更多元素而预留的。当容器的大小接近容量时,它可能需要重新分配内存,并将新的_end_of_storage更新为新的内存末尾。
namespace MyVector
{template<class T>class vector{public:typedef T* iterator;private:iterator _start;iterator _finish;iterator _end_of_storage;};
};
2.push_back操作
首选我们提前需要写好构造函数与析构函数,构造函数在初始化列表将三个iterator置为nullptr即可,析构函数进行释放资源与指针置空操作。
size()接口函数:表示vector的有效数据个数,即:_finish - _start
capacity()接口函数:表示vector的容量大小,即:_end_of_storage - _start
在push_back尾插之前,我们还需要进行判断是否要进行扩容,扩容机制我们在数据结构学习了很多,不作细致讲解,下面直接放代码:
namespace MyVector
{template<class T>class vector{public:typedef T* iterator;vector(): _start(nullptr), _finish(nullptr), _end_of_storage(nullptr){}size_t capacity(){return _end_of_storage - _start;}size_t size(){return _finish - _start;}void push_back(const T& val){//扩容if (_finish == _end_of_storage){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;T* tmp = new T[newcapacity];if (_start){memcpy(tmp, _start, sizeof(T)* size());delete[] _start;}_start = tmp;_finish = _start + size();_end_of_storage = _start + newcapacity;}*_finish = val;_finish++;}//通过[]进行访问vectorT& operator[] (size_t n){assert(n < size());return *(_start + n);}~vector(){delete[] _start;_start = _finish = _end_of_storage = nullptr;}private:iterator _start;iterator _finish;iterator _end_of_storage;};void test_vector1(){vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (size_t i = 0; i < v1.size(); i++){cout << v1[i] << " ";}cout << endl;}
};
在main函数中我们调用MyVector::test_vector1(),将程序运行起来之后程序就出问题了:
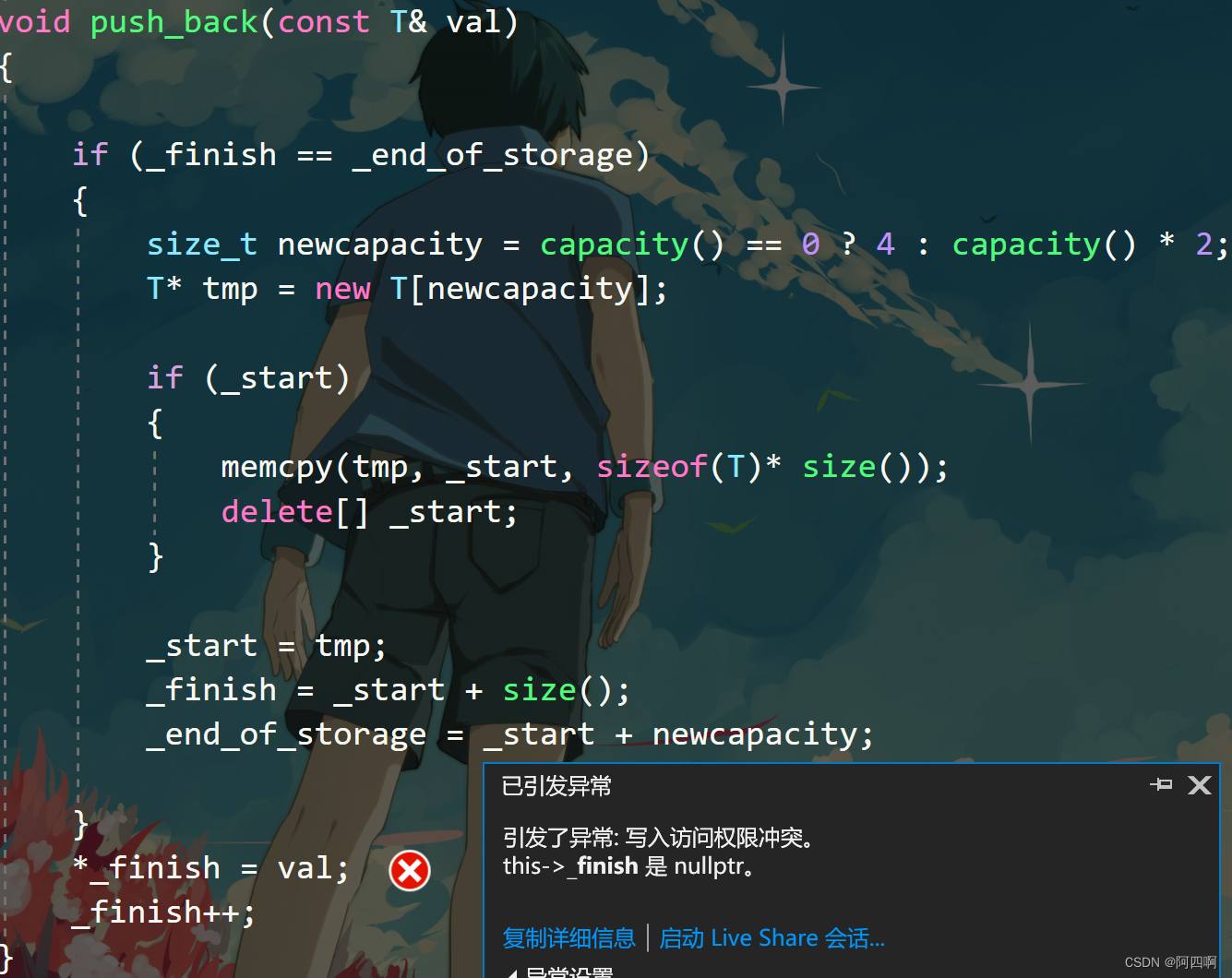
报错说_finish是nullptr,什么原因呢?
我们将程序调试起来,观察发现vector发生了扩容,其_start与_end_of_storage均发生了改变,我们讲他俩相减等于16字节,1个int占4个字节,说明确实刚开始扩容了4个元素,但是我们细心观察发现_finish的值还是为空指针,原因其实就在于_finish = _start + size(),这里更新了_start,而size()里面的_finish还是指向原来的空间,也就是0x00000000,属于迭代器失效问题,解决办法就是在扩容之前,提前用sz变量记录好偏移量。

解决方案:
void push_back(const T& val)
{if (_finish == _end_of_storage){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;size_t sz = size();T* tmp = new T[newcapacity];if (_start){memcpy(tmp, _start, sizeof(T)* sz);delete[] _start;}_start = tmp;_finish = _start + sz;_end_of_storage = _start + newcapacity;}*_finish = val;_finish++;
}
3.vector的访问与遍历
第一种:[]下标访问遍历
第二种:将迭代器_start与_finish用begin与end方法进行封装为成员函数,利用iterator进行遍历。
第三种:一旦有了迭代器,就可以支持范围for语句,因为其底层就是迭代器。
namespace MyVector
{template<class T>class vector{public:typedef T* iterator;vector(): _start(nullptr), _finish(nullptr), _end_of_storage(nullptr){}iterator begin(){return _start;}iterator end(){return _finish;}size_t capacity(){return _end_of_storage - _start;}size_t size(){return _finish - _start;}void push_back(const T& val){if (_finish == _end_of_storage){size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;size_t sz = size();T* tmp = new T[newcapacity];if (_start){memcpy(tmp, _start, sizeof(T)* sz);delete[] _start;}_start = tmp;_finish = _start + sz;_end_of_storage = _start + newcapacity;}*_finish = val;_finish++;}T& operator[] (size_t n){assert(n < size());return *(_start + n);}~vector(){delete[] _start;_start = _finish = _end_of_storage = nullptr;}private:iterator _start;iterator _finish;iterator _end_of_storage;};void test_vector1(){vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);for (size_t i = 0; i < v1.size(); i++){cout << v1[i] << " ";}cout << endl;vector<int> v2;v2.push_back(10);v2.push_back(20);v2.push_back(30);v2.push_back(40);v2.push_back(50);vector<int>::iterator it = v2.begin();while (it != v2.end()){cout << *it << " ";it++;}cout << endl;for(auto e:v2){cout << e << " ";}cout << endl;}
};4.resize与reserve
resize接口函数:改变vector的size,可以增加或减少容器中的元素数量。
当使用 resize 减少size大小时,多余的元素会被移除,当使用 resize 增加size大小时,会发生扩容。
reserve接口函数:改变vector的容量大小,它能够预留足够的空间,使用 reserve 可以减少因为频繁扩容而带来的性能开销。
ps:reserve本身有检查扩容机制的意思,我们直接使用push_back写的扩容机制代码,然后用push_back复用reserve.
void reserve(size_t n)
{if (n > capacity()){T* tmp = new T[n];size_t sz = size();if (_start){memcpy(tmp, _start, sizeof(T) * sz);delete[] _start;}_start = tmp;_finish = _start + sz;_end_of_storage = _start + n;}
}//为什么这里的val要给匿名对象初始化,而不是0,
//因为这里写的是vector类模板,
//传进来的参数类型可能是int,double,也可能是vector<string>,vector<int>……
//C++泛型编程对内置类型也支持构造函数(匿名对象),不然C++模板很难用
//添加const说明匿名对象具有常属性,添加&可以延长匿名对象的生命周期
void resize(size_t n, const T& val = T())
{//分为三种情况//小于等于size =>缩容(多余元素被移除)// 大于size 小于capacity//大小capacity =>扩容if (n <= size()){_finish = _start + n;}else{reserve(n);while (_finish < _start + n){*_finish = val;_finish++;}}
}
void push_back(const T& val)
{if (_finish == _end_of_storage){reserve(capacity() == 0 ? 4 : capacity() * 2);}*_finish = val;_finish++;
}
测试:
void test_vector2()
{vector<int*> v1;v1.resize(5);vector<string> v2;v2.resize(10,"xxx");for (auto e: v1){cout << e << " ";}cout << endl;for (auto e : v2){cout << e << " ";}cout << endl;
}
5.insert和erase
5.1 insert插入操作
void insert(iterator pos,const T& val)
{assert(pos >= _start);assert(pos <= _finish);//判断是否需要扩容if (_finish == _end_of_storage){reserve(capacity() == 0 ? 4 : capacity() * 2);}//挪动数据iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}*pos = val;_finish++;
}
测试:
void test_vector3()
{vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);for (size_t i = 0; i < v1.size(); i++){cout << v1[i] << " ";}cout << endl;//第一次在下标为2的位置插入一个元素30v1.insert(v1.begin() + 2, 30);for (size_t i = 0; i < v1.size(); i++){cout << v1[i] << " ";}cout << endl;//第二次头插一个元素8,此时会发生扩容,导致pos失效v1.insert(v1.begin(), 8);for (size_t i = 0; i < v1.size(); i++){cout << v1[i] << " ";}cout << endl;
}
第一次我们在下标为2的位置插入一个元素30,程序能够正确运行,结果也是对的。
但是我们再次利用insert头插一个元素,此时正好是添加新的元素,需要进行扩容,最后程序发生了崩溃。
为何呢?是因为扩容的原因导致的吗?接下来,我们探究一下
在扩容之前,我们调试观察看到pos接收的地址的确和_start的地址一模一样,都是0x0122da28

一旦经过reseve扩容,我们发生三个iterator地址都发生了变化,唯独pos却纹丝不动,还是原来的地址空间,此时的问题貌似很眼熟,没错,就是在前面部分我们提到的_finish如出一辙,也属于迭代器失效问题,本质就是因为pos使用的是释放之前的空间,空间发生了扩容,pos在对以前已经释放的空间进行操作时,就会引起代码运行崩溃。
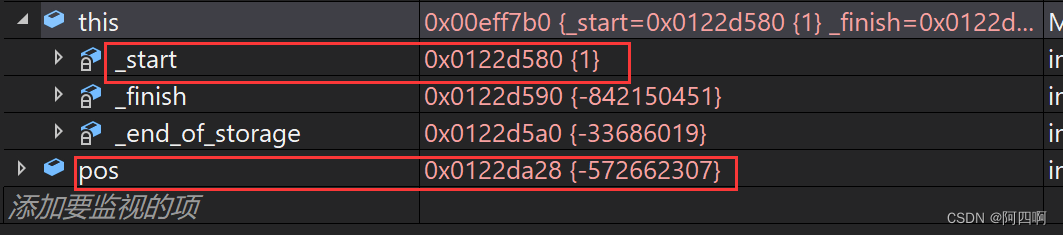
解决方案:在扩容之前,保存pos位置的偏移量,在扩容后更新pos位置。
void insert(iterator pos,const T& val)
{assert(pos >= _start);assert(pos <= _finish);if (_finish == _end_of_storage){size_t len = pos - _start;reserve(capacity() == 0 ? 4 : capacity() * 2);pos = _start + len;}iterator end = _finish - 1;while (end >= pos){*(end + 1) = *end;end--;}*pos = val;_finish++;
}
5.2 erase删除操作
void erase(iterator pos)
{assert(pos >= _start);assert(pos < _finish);iterator begin = pos + 1;while (begin < _finish){*(begin - 1) = *begin;begin++;}_finish--;
}
测试:
void test_vector4()
{vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);v1.push_back(6);v1.push_back(7);for (size_t i = 0; i < v1.size(); i++){cout << v1[i] << " ";}cout << endl;auto it = v1.begin();v1.erase(it);for (auto e:v1){cout << e << " ";}cout << endl;v1.erase(it + 2);for (auto e : v1){cout << e << " ";}cout << endl;}
以上我们对头部和下标为2的元素进行了删除操作,代码的结果也能顺畅地跑出来,结果也是正确的,但是这里的it迭代器不会失效吗?答案并非如此,我们来看下面的场景:
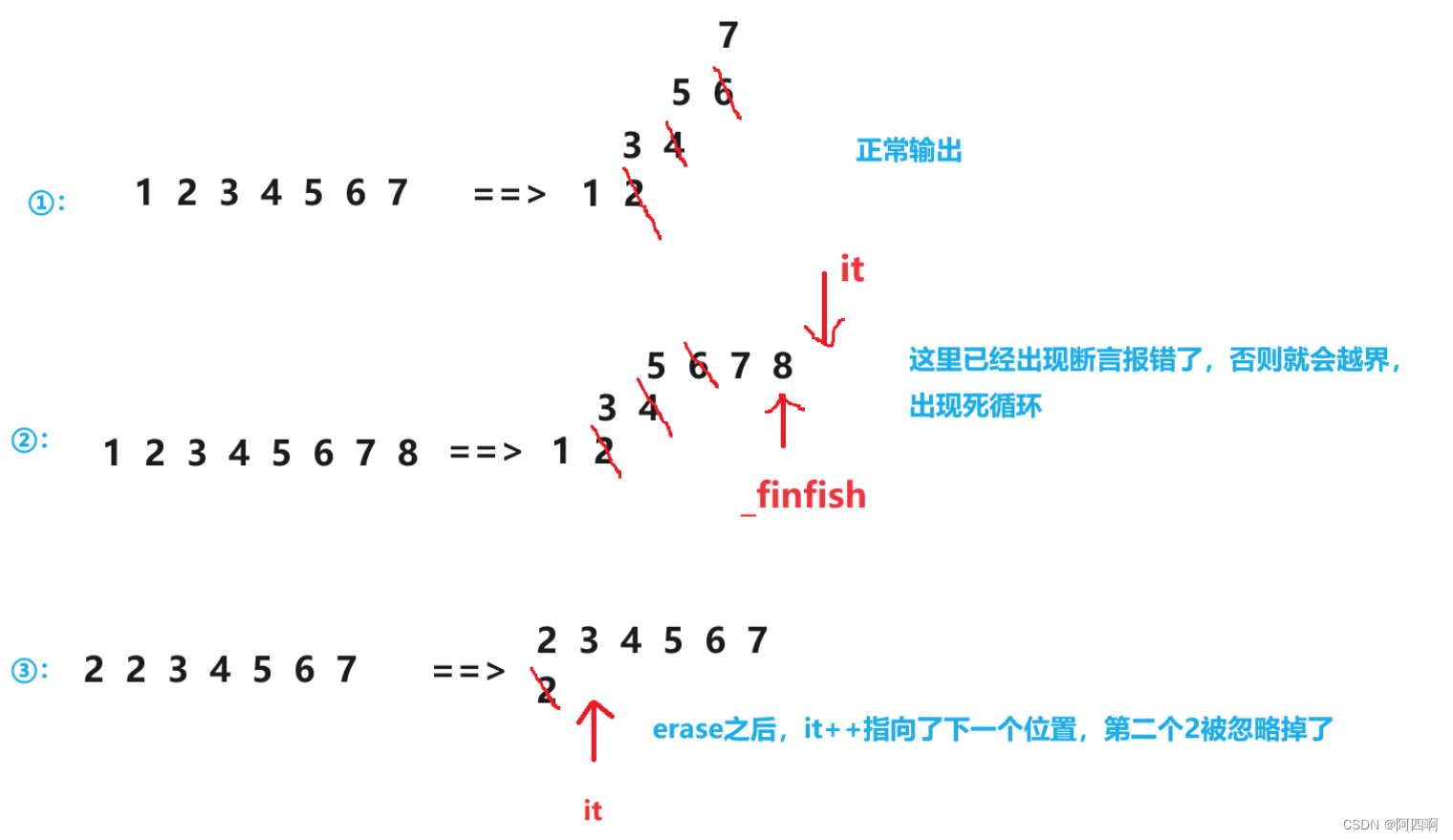
我们给出三组样例数据,分别计算给出的样例中用erase删除偶数元素。
第一组测试数据:1 2 3 4 5 6 7
//第一种情况
void test_vector5()
{vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);v1.push_back(6);v1.push_back(7);cout << "begin:";for (auto e : v1){cout << e << " ";}cout << endl;auto it = v1.begin();while (it != v1.end()){if (*it % 2 == 0){v1.erase(it);}it++;}cout << "after:";for (auto e : v1){cout << e << " ";}cout << endl;
}
运行结果:结果正确
begin:1 2 3 4 5 6 7
after:1 3 5 7
第二种测试数据:1 2 3 4 5 6 7 8
//第二种情况
void test_vector6()
{vector<int> v1;v1.push_back(1);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);v1.push_back(6);v1.push_back(7);v1.push_back(8);cout << "begin:";for (auto e : v1){cout << e << " ";}cout << endl;auto it = v1.begin();while (it != v1.end()){if (*it % 2 == 0){v1.erase(it);}it++;}cout << "after:";for (auto e : v1){cout << e << " ";}cout << endl;
}
运行结果:程序崩溃
begin:1 2 3 4 5 6 7 8
error运行崩溃(触发断言)
第三种测试数据:2 2 3 4 5 6 7
//第三种情况
void test_vector7()
{vector<int> v1;v1.push_back(2);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);v1.push_back(6);v1.push_back(7);cout << "begin:";for (auto e : v1){cout << e << " ";}cout << endl;auto it = v1.begin();while (it != v1.end()){if (*it % 2 == 0){v1.erase(it);}it++;}cout << "after:";for (auto e : v1){cout << e << " ";}cout << endl;
}
打印结果:结果错误
begin:2 2 3 4 5 6 7
after:2 3 5 7
分析:
注⚠️:
以上也是Linux下g++的编译器对迭代器的检测并不严格,处理没有vs编译器果断极端。
以上代码在vs下程序会出现崩溃,vs一些编译器会进行强制检查,认为erase之后it就失效了,访问就会报错。但是在Linux下,虽然可能可以运行,但是输出的结果是不对的。
那么对于以上it等迭代器失效问题,该如何解决呢?
其实erase有具体的返回值,返回的是一个iterator,指向被删除元素的下一个元素的位置。

👇修正erase的代码:
iterator erase(iterator pos)
{assert(pos >= _start);assert(pos < _finish);iterator begin = pos + 1;while (begin < _finish){*(begin - 1) = *begin;begin++;}_finish--;return pos;
} //迭代器失效的解决方案
//在使用前,对迭代器进行重新赋值
void test_vector8()
{vector<int> v1;v1.push_back(2);v1.push_back(2);v1.push_back(3);v1.push_back(4);v1.push_back(5);v1.push_back(6);v1.push_back(7);cout << "begin:";for (auto e : v1){cout << e << " ";}cout << endl;auto it = v1.begin();while (it != v1.end()){if (*it % 2 == 0){//在下次操作it之前,对迭代器进行重新赋值it = v1.erase(it); }else{//不删除++即可it++;}}cout << "after:";for (auto e : v1){cout << e << " ";}cout << endl;
}结论:在使用了 insert 和 erase 之后,迭代器失效了,不能再访问,需要谨慎处理。
6.关于具体迭代器失效问题的分析
关于剖析迭代器失效问题 博客==>关于迭代器失效问题
7.memcpy浅拷贝问题
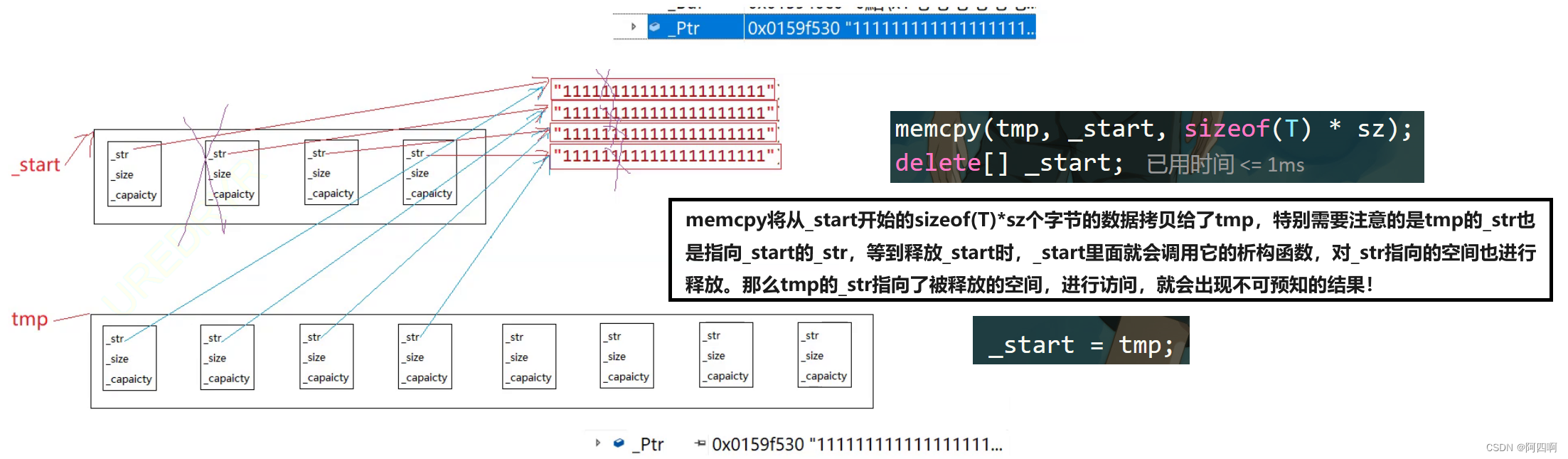
使用memcpy拷贝的是内置类型,那么通常是高效又安全的,但是如果对于自定义类型,涉及动态资源管理,会导致浅拷贝问题,造成内存泄露等不可预知的结果!
//测试对于自定义类型,扩容时使用memcpy会导致浅拷贝问题
void test_vector9()
{vector<string> v1;v1.push_back("11111111111");v1.push_back("11111111111");v1.push_back("11111111111");v1.push_back("11111111111");v1.push_back("11111111111");for (auto e : v1){cout << e << " ";}cout << endl;}
解决方案:
很简单,使用一个for循环,对每个字节进行赋值操作,对于内置类型是赋值,对于自定义类型就会调用自身的赋值重载函数!
void reserve(size_t n)
{if (n > capacity()){T* tmp = new T[n];size_t sz = size();if (_start){//memcpy(tmp, _start, sizeof(T) * sz);for (size_t i = 0; i < sz; i++){tmp[i] = _start[i];}delete[] _start;}_start = tmp;_finish = _start + sz;_end_of_storage = _start + n;}
}
8.vector的拷贝构造与赋值重载
//拷贝构造
//v2(v1)
vector(const vector<T>& x): _start(nullptr), _finish(nullptr), _end_of_storage(nullptr)
{//开辟和x一样大的空间reserve(x.capacity());for (size_t i = 0; i < x.size(); i++){push_back(x[i]);}
}void swap(vector<T>& v)
{std::swap(_start, v._start);std::swap(_finish, v.finish);std::swap(_end_of_storage, v._end_of_storage);
}//赋值重载
//v2 = v1
vector<T>& operator=(vector<T> tmp)
{swap(tmp);return *this;
}
测试赋值重载:
//测试赋值重载void test_vector10(){vector<int> v1;v1.push_back(10);v1.push_back(20);v1.push_back(30);v1.push_back(40);vector<int> v2;v2 = v1;for (auto e : v2){cout << e << " ";}cout << endl;}
9.迭代区间初始化与n个val初始化
类模板里面可以嵌套函数模板,可以传入任意类型的迭代区间初始化,在形参部分用InputIterator进行接收,具体细节可下面的测试用例。
对于n个val初始化,不能直接写成vector(size_t n, const T& val = T()),在编译器认为会优先去调用最匹配的,就会调用迭代区间的初始化,此时编译就会出错,那么我们就需要写一个更匹配的vector(int n, const T& val = T()),此时就能正确编译并执行了。
//利用迭代器区间进行初始化
//函数模板
template <class InputIterator>
vector(InputIterator first, InputIterator last):_start(nullptr), _finish(nullptr), _end_of_storage(nullptr)
{while (first != last){push_back(*first);first++;}
}vector(size_t n, const T& val = T())
{reserve(n);for (size_t i = 0; i < n; i++){push_back(val); }
}vector(int n, const T& val = T())
{reserve(n);for (int i = 0; i < n; i++){push_back(val);}
}
测试迭代器区间初始化与n个val初始化:
//测试迭代器区间初始化与n个val初始化
void test_vector11()
{//n个val初始化vector<int> v1(10, 0);//利用迭代器区间初始化string str("hello world");vector<int> v2(str.begin(), str.end());for (auto e : v2){cout << e << " ";}cout << endl;
}
10.vector模拟实现源代码
vector的深度剖析及模拟实现
相关文章:
【C/C++】STL——深度剖析vector容器
👻内容专栏: C/C编程 🐨本文概括:vector的介绍与使用、深度剖析及模拟实现。 🐼本文作者: 阿四啊 🐸发布时间:2023.10.8 一、vector的介绍与使用 1. vector的介绍 像string的学习…...
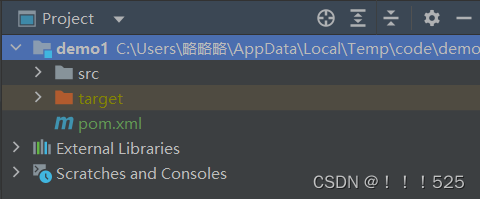
如何在idea中隐藏文件或文件夹
例如我想要隐藏如下文件 只需要点击file->settings editor->file types->ignores Files and Folders-> 然后按照图片点击顺序操作即可 添加完毕点击apply->ok 隐藏成功后效果如下:...
Scala第二十章节
Scala第二十章节 scala总目录 文档资料下载 章节目标 理解Akka并发编程框架简介掌握Akka入门案例掌握Akka定时任务代码实现掌握两个进程间通信的案例掌握简易版spark通信框架案例 1. Akka并发编程框架简介 1.1 Akka概述 Akka是一个用于构建高并发、分布式和可扩展的基于事…...
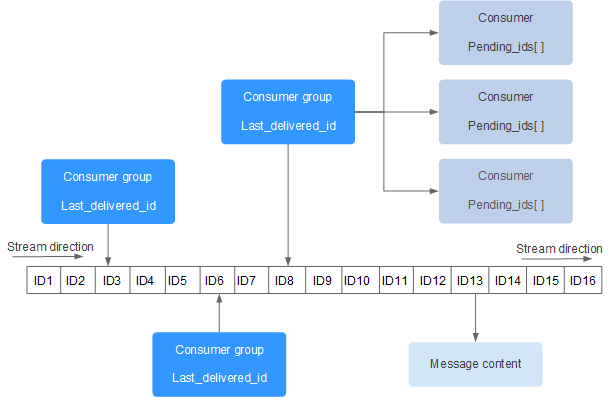
redis的持久化消息队列
Redis Stream Redis Stream 是 Redis 5.0 版本新增加的数据结构。 Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法…...

分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测
分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测 目录 分类预测 | MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现KOA-CNN开普勒算法优化卷积神经网络数据分类预测࿰…...

用 Pytorch 自己构建一个Transformer
一、说明 用pytorch自己构建一个transformer并不是难事,本篇使用pytorch随机生成五千个32位数的词向量做为源语言词表,再生成五千个32位数的词向量做为目标语言词表,让它们模拟翻译过程,transformer全部用pytorch实现,具备一定实战意义。 二、论文和概要 …...

Docker安装ActiveMQ
ActiveMQ简介 官网地址:https://activemq.apache.org/ 简介: ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,尽管JMS规范出台已经是很久的事情了,…...
【二】spring boot-设计思想
spring boot-设计思想 简介:现在越来越多的人开始分析spring boot源码,拿到项目之后就有点无从下手了,这里介绍一下springboot源码的项目结构 一、项目结构 从上图可以看到,源码分为两个模块: spring-boot-project&a…...

系统架构设计:7 论企业集成架构设计及应用
目录 一 企业集成 1 企业集成分类:按照集成点分 (1)界面集成(表示集成)...

【pytorch】多GPU同时训练模型
文章目录 1. 基本原理单机多卡训练教程——DP模式 2. Pytorch进行单机多卡训练步骤1. 指定GPU2. 更改模型训练方式3. 更改权重保存方式 摘要:多GPU同时训练,能够解决单张GPU显存不足问题,同时加快模型训练。 1. 基本原理 单机多卡训练教程—…...
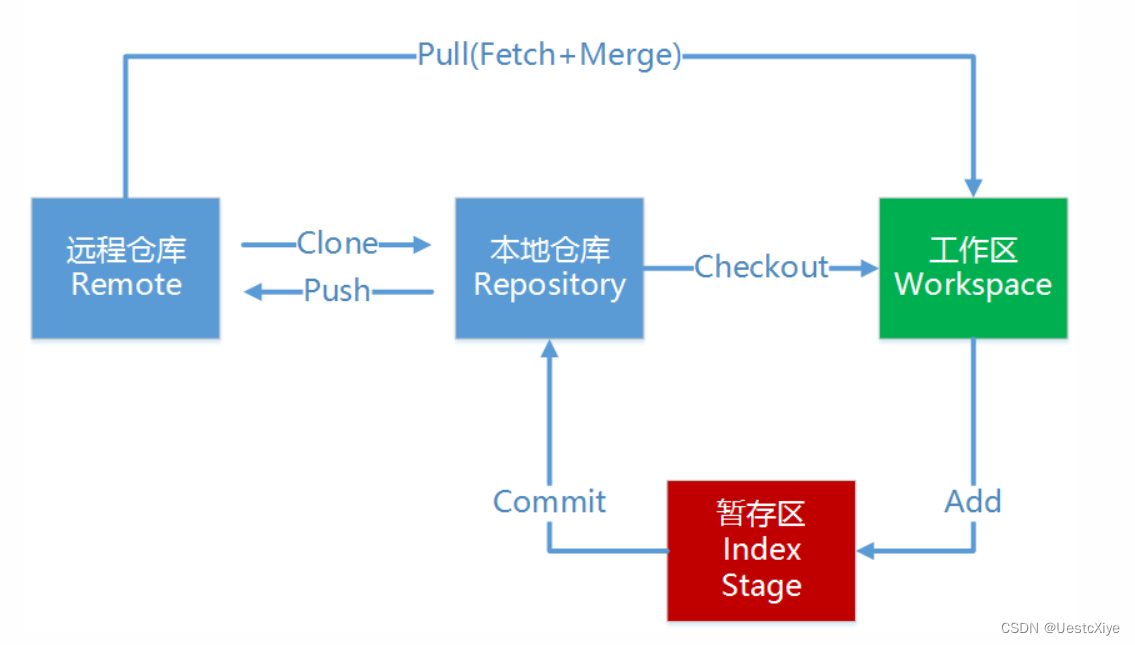
Git 学习笔记 | Git 基本理论
Git 学习笔记 | Git 基本理论 Git 学习笔记 | Git 基本理论Git 工作区域Git 工作流程 Git 学习笔记 | Git 基本理论 在开始使用 Git 创建项目前,我们先学习一下 Git 的基础理论。 Git 工作区域 Git本地有三个工作区域:工作目录(Working Di…...

滚动表格封装
滚动表格封装 我们先设定接收的参数 需要表头内容columns,表格数据data,需要currentSlides来控制当前页展示几行 const props defineProps({// 表头内容columns: {type: Array,default: () > [],required: true,},// 表格数据data: {type: Array,d…...

【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题
文章目录 【LeetCode高频SQL50题-基础版】打卡第3天:第16~20题⛅前言 平均售价🔒题目🔑题解 项目员工I🔒题目🔑题解 各赛事的用户注册率🔒题目🔑题解 查询结果的质量和占比🔒题目&am…...

系统压力测试:保障系统性能与稳定的重要措施
压力测试简介 在当今数字化时代,各种系统和应用程序扮演着重要角色,从企业的核心业务系统到在线服务平台,都需要具备高性能和稳定性,以满足用户的需求。然而,随着用户数量和业务负载的增加,系统可能会面临…...

常用数据结构和算法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、时间复杂度二、使用步骤 1.引入库2.读入数据总结 前言 提示:这里可以添加本文要记录的大概内容: 这里面有10个数据结构࿱…...

C++中使用引用避免内存复制
C中使用引用避免内存复制 引用让您能够访问相应变量所在的内存单元,这使得编写函数时引用很有用。典型的函数声明类似于下面这样: ReturnType DoSomething(Type parameter);调用函数 DoSomething() 的代码类似于下面这样: ReturnType Resu…...
计算机网络(第8版)-第4章 网络层
4.1 网络层的几个重要概念 4.1.1 网络层提供的两种服务 如果主机(即端系统)进程之间需要进行可靠的通信,那么就由主机中的运输层负责(包括差错处理、流量控制等)。 4.1.2 网络层的两个层面 4.2 网际协议 IP 图4-4 网…...
chromadb 0.4.0 后的改动
本文基于一篇上次写的博客:[开源项目推荐]privateGPT使用体验和修改 文章目录 一.上次改好的ingest.py用不了了,折腾了一会儿二.发现privateGPT官方更新了总结下变化效果 三.others 一.上次改好的ingest.py用不了了,折腾了一会儿 pydantic和c…...
Windows环境下下载安装Elasticsearch和Kibana
Windows环境下下载安装Elasticsearch和Kibana 首先说明这里选择的版本都是7.17 ,为什么不选择新版本,新版本有很多坑,要去踩,就用7就够了。 Elasticsearch下载 Elasticsearch是一个开源的分布式搜索和分析引擎,最初由…...
机器学习:随机森林
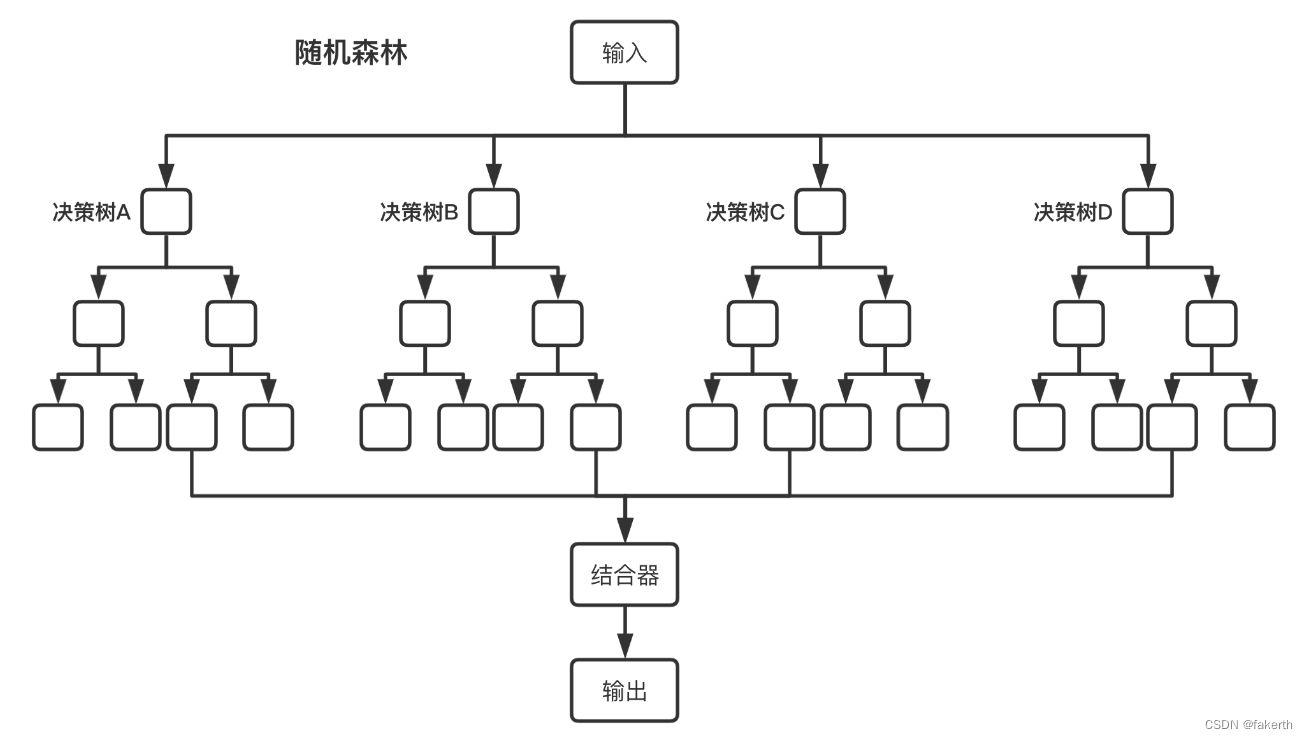
集成学习 集成学习(Ensemble Learning)是一种机器学习方法,通过将多个基本学习算法的预测结果进行组合,以获得更好的预测性能。集成学习的基本思想是通过结合多个弱分类器或回归器的预测结果,来构建一个更强大的集成模…...

GEO优化实操框架:GEO优化的正确姿势是“带着答案去找客户”
如果你是B2B企业的老板或市场负责人,你一定听过这句话: “我们网上曝光是不少,但来的询盘都不对——问价格的比问方案的还多,还有不少是学生做调研的。” 这不是你一个人遇到的问题。这是传统SEO和竞价广告的天然缺陷——你只能“…...
)
告别迷茫!在嵌入式Linux上用libwebsockets v4.0实现WebSocket客户端(含SSL配置避坑)
嵌入式Linux实战:libwebsockets v4.0客户端开发与SSL避坑指南 当树莓派的GPIO引脚需要与云端实时同步数据时,WebSocket往往是嵌入式开发者的首选协议。但面对内存仅512MB的ARMv7开发板,选用一个既支持SSL加密又能兼容C99标准的轻量级库&#…...

百度网盘直链解析工具:3分钟突破限速实现满速下载
百度网盘直链解析工具:3分钟突破限速实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾为百度网盘的下载速度而烦恼?非会员用户经常…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

【最新v2.7.1 版本安装包】OpenClaw 小白入门必看,零基础无需命令零代码保姆级教学
OpenClaw v2.7.1 一键安装部署教程|可视化傻瓜式搭建 ✨适配系统:Windows10/11 64 位 ✨当前版本:v2.7.1 版本(虾壳云版) ✨安装包大小:58.7MB 【点击下载最新安装包】https://xiake.yun/api/download/…...

017、Docker在TinyML开发中的应用
017 Docker在TinyML开发中的应用 从一次“环境地狱”说起 上个月帮团队调一个STM32上的TinyML推理延迟问题,模型是MobileNetV2量化版,在开发板上跑得好好的,换到同事的Ubuntu 20.04机器上编译,死活链接不上CMSIS-NN库。折腾半天发现他系统里默认的arm-none-eabi-gcc版本是…...

AI团队协作镜像:Docker容器化实现环境一致性与高效复现
1. 项目概述:从开源镜像到AI协作平台的深度解构最近在GitHub上看到一个名为“team9ai/team9”的仓库,这个看似简单的镜像名背后,其实隐藏着一个非常典型的现代AI项目协作范式。它不是某个单一的算法模型,也不是一个孤立的工具&…...

FastAPI快速入门:环境搭建+第一个接口
FastAPI快速入门:环境搭建第一个接口文章信息 标题:FastAPI快速入门:环境搭建第一个接口字数:4200字预估阅读时间:18分钟难度:⭐☆☆☆☆一、为什么选择FastAPI? 在2026年的Python Web框架生态中…...