深入理解强化学习——强化学习和有监督学习
分类目录:《深入理解强化学习》总目录
通过前文的介绍,我们现在应该已经对强化学习的基本数学概念有了一定的了解。这里我们回过头来再看看一般的有监督学习和强化学习的区别。以图片分类为例,有监督学习(Supervised Learning)假设我们有大量被标注的数据且通常假设样本空间中全体样本服从一个未知分布,我们获得的每个样本都是独立地从这个分布上采样获得的,即独立同分布(Independent and Identically Distributed,IID),比如汽车、飞机、椅子这些被标注的图片,这些图片都要满足独立同分布,即它们之间是没有关联关系的。假设我们训练一个分类器,比如神经网络。为了分辨输入的图片中是汽车还是飞机,在训练过程中,需要把正确的标签信息传递给神经网络。 当神经网络做出错误的预测时,比如输入汽车的图片,它预测出来是飞机,我们就会直接告诉它,该预测是错误的,正确的标签应该是汽车。最后我们根据类似错误写出一个损失函数(Loss Function),通过反向传播(Back Propagation)来训练神经网络。所以在监督学习过程中,有两个假设:
- 输入的数据(标注的数据)都应是没有关联的。因为如果输入的数据有关联,学习器是不好学习的
- 需要告诉学习器正确的标签是什么,这样它可以通过正确的标签来修正自己的预测
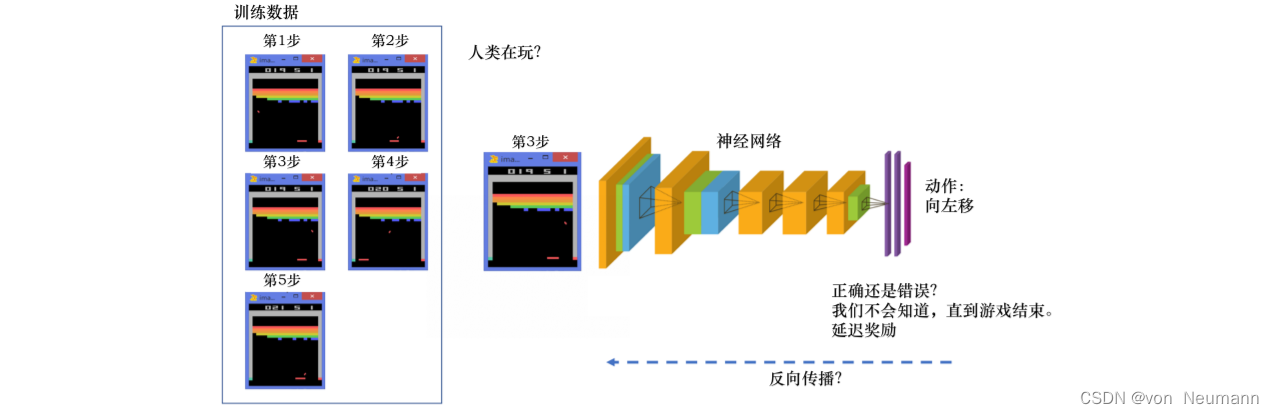
在强化学习中,有监督学习的两个假设其实都不能得到满足。以雅达利(Atari) 游戏Breakout为例,如下图所示,这是一个打砖块的游戏,控制木板左右移动从而把球反弹到上面来消除砖块。在玩游戏的过程中,我们可以发现智能体得到的观测(Observation)不是独立同分布的,上一帧与下一帧间其实有非常强的连续性。我们得到的数据是相关的时间序列数据,不满足独立同分布。另外,我们并没有立刻获得反馈,游戏没有告诉我们哪个动作是正确动作。比如现在把木板往右移,这只会使得球往上或者往左一点儿,我们并不会得到即时的反馈。因此,强化学习之所以困难,是因为智能体不能得到即时的反馈,然而我们依然希望智能体在这个环境中学习。

如下图所示,强化学习的训练数据就是一个玩游戏的过程。我们从第1步开始,采取一个动作,比如我们把木板往右移,接到球。第2步我们又做出动作,得到的训练数据是一个玩游戏的序列。比如现在是在第3步,我们把这个序列放进网络,希望网络可以输出一个动作,即在当前的状态应该输出往右移或者往左移。这里有个问题,我们没有标签来说明现在这个动作是正确还是错误的,必须等到游戏结束才可能知道,这个游戏可能10s后才结束。现在这个动作到底对最后游戏是否能赢有无帮助,我们其实是不清楚的。这里我们就面临延迟奖励(Delayed Reward)的问题,延迟奖励使得训练网络非常困难。
对于一般的有监督学习任务,我们的目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数。在训练数据独立同分布的假设下,这个优化目标表示最小化模型在整个数据分布上的泛化误差(Generalization Error),用简要的公式可以概括为:
最优模型 = arg min 模型 E ( 特征 , 标签 ) ∼ 数据分布 [ 损失函数 ( 标签 , 模型 ( 特征 ) ) ] \text{最优模型}=\arg\min_{\text{模型}} E_{(\text{特征}, \text{标签})\sim \text{数据分布}}[\text{损失函数}(\text{标签}, \text{模型}(\text{特征}))] 最优模型=arg模型minE(特征,标签)∼数据分布[损失函数(标签,模型(特征))]
相比之下,强化学习任务的最终优化目标是最大化智能体策略在和动态环境交互过程中的价值。根据上面的分析,策略的价值可以等价转换成奖励函数在策略的占用度量上的期望:
最优策略 = arg max 策略 E ( 状态 , 动作 ) ∼ 策略占用度量 [ 奖励函数 ( 状态 , 动作 ) ] \text{最优策略}=\arg\max_{\text{策略}} E_{(\text{状态}, \text{动作})\sim \text{策略占用度量}}[\text{奖励函数}(\text{状态}, \text{动作})] 最优策略=arg策略maxE(状态,动作)∼策略占用度量[奖励函数(状态,动作)]
观察以上两个优化公式,我们可以总结出两者的相似点和不同点:
- 有监督学习和强化学习的优化目标相似,即都是在优化某个数据分布下的一个分数值的期望。
- 二者优化的途径是不同的,有监督学习直接通过优化模型对于数据特征的输出来优化目标,即修改目标函数而数据分布不变;强化学习则通过改变策略来调整智能体和环境交互数据的分布,进而优化目标,即修改数据分布而目标函数不变。
综上所述,一般有监督学习和强化学习的范式之间的区别为:
- 有监督学习关注寻找一个模型,使其在给定数据分布下得到的损失函数的期望最小。而强化学习关注寻找一个智能体策略,使其在与动态环境交互的过程中产生最优的数据分布,即最大化该分布下一个给定奖励函数的期望。
- 强化学习输入的样本是序列数据,而不像监督学习里面样本都是独立的。
- 学习器并没有告诉我们每一步正确的动作应该是什么,学习器需要自己去发现哪些动作可以带来最多的奖励,只能通过不停地尝试来发现最有利的动作。
- 智能体获得自己能力的过程,其实是不断地试错探索(Trial-and-error Exploration)的过程。探索 (Exploration)和利用(Exploitation)是强化学习里面非常核心的问题。其中,探索指尝试一些新的动作, 这些新的动作有可能会使我们得到更多的奖励,也有可能使我们“一无所有”,而利用指采取已知的可以获得最多奖励的动作,重复执行这个动作,因为我们知道这样做可以获得一定的奖励。因此,我们需要在探索和利用之间进行权衡,这也是在监督学习里面没有的情况。
- 在强化学习过程中,没有非常强的监督者(Supervisor),只有奖励信号(Reward Signal),并且奖励信号是延迟的,即环境会在很久以后告诉我们之前我们采取的动作到底是不是有效的。因为我们没有得到即时反馈,所以智能体使用强化学习来学习就非常困难。当我们采取一个动作后,如果我们使用监督学习,我们就可以立刻获得一个指导,比如,我们现在采取了一个错误的动作,正确的动作应该是什么。而在强化学习里面,环境可能会告诉我们这个动作是错误的,但是它并没有告诉我们正确的动作是什么。而且更困难的是,它可能是在一两分钟过后告诉我们这个动作是错误的。所以这也是强化学习和监督学习不同的地方。
通过与监督学习的比较,我们可以总结出强化学习的一些特征:
- 强化学习会试错探索,它通过探索环境来获取对环境的理解。
- 强化学习智能体会从环境里面获得延迟的奖励。
- 在强化学习的训练过程中,时间非常重要,因为我们得到的是有时间关联的数据(Sequential Data), 而不是独立同分布的数据。在机器学习中,如果观测数据有非常强的关联,会使得训练非常不稳定。这也是为什么在监督学习中,我们希望数据尽量满足独立同分布,这样就可以消除数据之间的相关性。
- 智能体的动作会影响它随后得到的数据,这一点是非常重要的。在训练智能体的过程中,很多时 候我们也是通过正在学习的智能体与环境交互来得到数据的。所以如果在训练过程中,智能体不能保持稳定,就会使我们采集到的数据非常糟糕。我们通过数据来训练智能体,如果数据有问题,整个训练过程就会失败。所以在强化学习里面一个非常重要的问题就是,怎么让智能体的动作一直稳定地提升。
本文梳理了强化学习和有监督学习在范式以及思维方式上的相似点和不同点。在大多数情况下,强化学习任务往往比一般的有监督学习任务更难,因为一旦策略有所改变,其交互产生的数据分布也会随之改变,并且这样的改变是高度复杂、不可追踪的,往往不能用显式的数学公式刻画。这就好像一个混沌系统,我们无法得到其中一个初始设置对应的最终状态分布,而一般的有监督学习任务并没有这样的混沌效应。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022
相关文章:
深入理解强化学习——强化学习和有监督学习
分类目录:《深入理解强化学习》总目录 通过前文的介绍,我们现在应该已经对强化学习的基本数学概念有了一定的了解。这里我们回过头来再看看一般的有监督学习和强化学习的区别。以图片分类为例,有监督学习(Supervised Learning&…...

设计模式 - 结构型模式考点篇:装饰者模式(概念 | 案例实现 | 优缺点 | 使用场景)
目录 一、结构型模式 1.1、装饰者模式 1.1.1、概念 1.1.2、案例实现 1.1.3、优缺点 1.1.4、使用场景 一、结构型模式 1.1、装饰者模式 1.1.1、概念 装饰者模式就是指在不改变现有对象结构的情况下,动态的给该对象增加一些职责(增加额外功能&#…...

计算机竞赛 题目:基于深度学习的手势识别实现
文章目录 1 前言2 项目背景3 任务描述4 环境搭配5 项目实现5.1 准备数据5.2 构建网络5.3 开始训练5.4 模型评估 6 识别效果7 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的手势识别实现 该项目较为新颖,适合作为竞赛课题…...

手撕各种排序
> 作者简介:დ旧言~,目前大一,现在学习Java,c,c,Python等 > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:掌握每种排序的方法,理解每种排序利弊…...
视频号的链接在哪,视频号视频链接地址获取办法!
不少人问视频号的链接在哪里可以获取,本质的在腾讯微信中目前视频号的链接是无法获取的,但好事多磨今天就分享一个第三方的视频号视频链接地址获取办法,希望对你有所帮助! 1:在微信客户端中,我们可以通过搜…...

深度学习笔记之优化算法(六)RMSprop算法的简单认识
深度学习笔记之优化算法——RMSProp算法的简单认识 引言回顾:AdaGrad算法AdaGrad算法与动量法的优化方式区别AdaGrad算法的缺陷 RMProp算法关于AdaGrad问题的优化方式RMSProp的算法过程描述 RMSProp示例代码 引言 上一节对 AdaGrad \text{AdaGrad} AdaGrad算法进行…...

10架构管理之公司整体技术架构
一句话导读 公司的整体技术架构一般是公司的架构组、架构管理部、技术委员会等部门负责,需要对公司整体的技术架构进行把控和管理,确保信息系统的稳定性和可靠性,避免因技术架构不合理而导致的系统崩溃和数据丢失等问题,为公司的业…...

联邦学习综述
《Advances and Open Problems in Federated Learning》 选题:Published 10 December 2019-Computer Science-Found. Trends Mach. Learn. 联邦学习定义 联邦学习是一种机器学习设置,其中多个客户端在中央服务器或服务提供商的协调下协作解决机器学习…...

几行cmd命令,轻松将java文件打包成jar文件
1. 在任意目录下建立一个.java文件 2. 在当前目录下使用cmd命令: javac filename编译 如果报错则使用此命令javac -encoding UTF-8 filename 3.此时已成功生成.class文件 4. 可以手动添加MANIFEST.MF文件 Manifest-Version: 1.0 Main-Class: fileName 5.直接一…...

BuyVM 卢森堡 VPS 测评
description: 发布于 2023-07-05 BuyVM 卢森堡 VPS 测评 产品链接:https://my.frantech.ca/cart.php?gid39 1G口不限流量,续约3个月后升级为10G口突发。抗DMCA版权投诉。抗一般投诉。 大陆连通性还可以,延迟略高,不绕美。 CP…...
JavaScript 编写一个 数值转换函数 万以后简化 例如1000000 展示为 100万 万以下原来数值返回
很多时候 我们看一些系统 能够比较只能的展示过大的数值 例如 到万了 他就能展示出 多少 多少万 看着很奇妙 但实现确实非常的基础 我们只需要一个这样的函数 //数值转换函数 convertNumberToString(num) {//如果传入的数值 不是数字 且也无法转为数字 直接扔0回去if (!parse…...
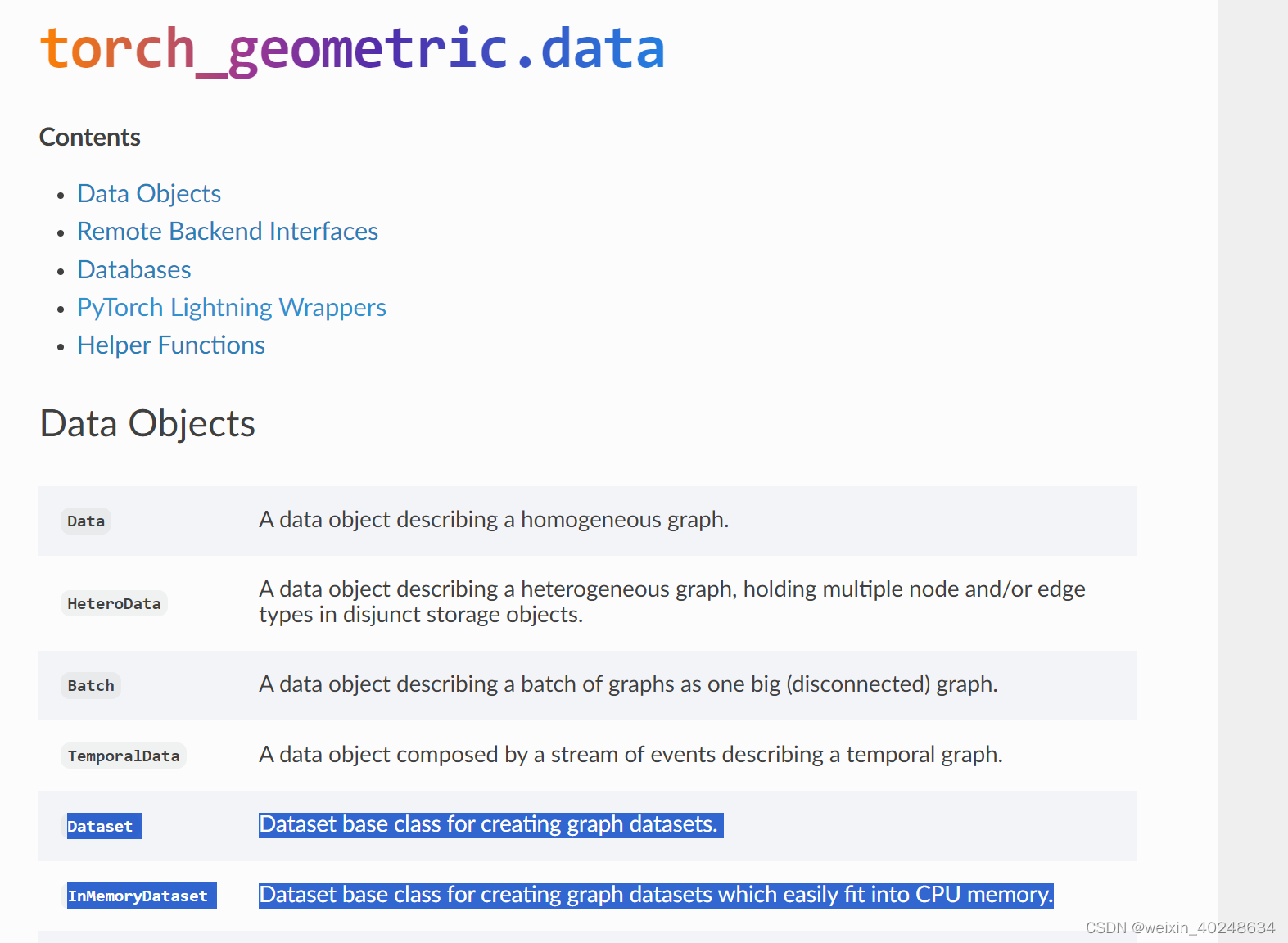
PyG两个data Datsaset v.s. InMemoryDataset
可以看到InMemoryDataset 对CPU更加友好 https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#pytorch-lightning-wrappers...

ArcGIS Engine:视图菜单的创建和鹰眼图的实现
目录 01 创建项目 1.1 通过ArcGIS-ExtendingArcObjects创建窗体应用 1.2 通过C#-Windows窗体应用创建窗体应用 1.2.1 创建基础项目 1.2.2 搭建界面 02 创建视图菜单 03 鹰眼图的实现 3.1 OnMapReplaced事件的触发 3.2 OnExtentUpdated事件的触发 04 稍作演示 01 创建项目…...
POI 和 EasyExcel 操作 Excel
一、概述 目前操作 Excel 比较流行的就是 Apache POI 和阿里巴巴的 easyExcel。 1.1 POI 简介 Apache POI 是用 Java 编写的免费开源的跨平台的 Java API,Apache POI 提供 API 给 Java 程序对 Microsoft Office 格式文档读和写的常用功能。POI 为 “Poor Obfuscati…...

pytorch算力与有效性分析
pytorch Windows中安装深度学习环境参考文档机器环境说明3080机器 Windows11qt_env 满足遥感CS软件分割、目标检测、变化检测的需要gtrs 主要是为了满足遥感监测管理平台(BS)系统使用的,无深度学习环境内容swin_env 与 qt_env 基本一致od 用于…...

Sublime text启用vim模式
官方教程:https://www.sublimetext.com/docs/vintage.html vintage的github:https://github.com/sublimehq/Vintage...
)
爬虫进阶-反爬破解6(Nodejs+Puppeteer实现登陆官网+实现滑动验证码全自动识别)
一、NodejsPuppeteer实现登陆官网 1.环境说明 Nodejs——直接从官网下载最新版本,并安装 使用npm安装puppeteer:npm install puppeteer npm install xxx -registry https://registry.npm.taobao.org Chromium会自动下载,前提是网络通畅 2.实践操作…...
【Unity】RenderFeature笔记
【Unity】RenderFeature笔记 RenderFeature是在urp中添加的额外渲染pass,并可以将这个pass插入到渲染列队中的任意位置。内置渲染管线中Graphics 的功能需要在RenderFeature里实现,常见的如DrawMesh和Blit 可以实现的效果包括但不限于 后处理,可以编写…...
golang gin——controller 模型绑定与参数校验
controller 模型绑定与参数校验 gin框架提供了多种方法可以将请求体的内容绑定到对应struct上,并且提供了一些预置的参数校验 绑定方法 根据数据源和类型的不同,gin提供了不同的绑定方法 Bind, shouldBind: 从form表单中去绑定对象BindJSON, shouldB…...

办公技巧:Excel日常高频使用技巧
目录 1. 快速求和?用 “Alt ” 2. 快速选定不连续的单元格 3. 改变数字格式 4. 一键展现所有公式 “CTRL ” 5. 双击实现快速应用函数 6. 快速增加或删除一列 7. 快速调整列宽 8. 双击格式刷 9. 在不同的工作表之间快速切换 10. 用F4锁定单元格 1. 快速求…...

通过curl命令直接测试Taotoken聊天补全接口的简易方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的简易方法 在开发或调试过程中,有时我们希望在无需引入完整SDK的轻量级环境…...

Cursor智能体学习工具:构建专属AI编程知识库的完整指南
1. 项目概述:一个为开发者量身定制的Cursor智能体学习工具如果你是一名开发者,并且最近正在尝试使用Cursor这款AI编程工具,那么你很可能和我一样,经历过一个既兴奋又有点迷茫的阶段。Cursor的强大毋庸置疑,它能理解上下…...

基于全志T527开发板的手势识别:OpenCV部署与轮廓匹配实战
1. 项目概述与硬件平台选择最近在做一个嵌入式视觉项目,需要在一块开发板上实现实时的手势识别功能。选型时,我重点考察了算力、接口丰富度和社区支持。最终,米尔电子的MYD-LT527开发板进入了我的视线。这块板子核心是全志T527处理器…...

C++二叉树控制台可视化:从递归布局到层序遍历的图形化实现
1. 项目概述:为什么我们需要“看见”二叉树?在C的学习和数据结构实践中,二叉树是一个绕不开的核心概念。我们经常需要实现它的插入、删除、遍历等操作。然而,无论是调试一个复杂的平衡算法,还是向他人展示你的数据结构…...

Windows驱动签名实战:从证书获取到安装包封装的完整指南
1. 项目概述:为什么驱动签名是硬件开发者的“必修课” 如果你做过硬件开发,尤其是涉及USB、串口这类需要与Windows系统深度交互的设备,那你一定对那个黄色的“Windows安全”警告弹窗不陌生。用户插上你的设备,系统提示“正在安装…...

除了 Docker 还能用什么?一文看懂容器技术的“四大门派”
除了 Docker 还能用什么?一文看懂容器技术的“四大门派” 在云原生时代,Docker 几乎成了容器的代名词。但实际上,容器技术是一片茂密的森林,除了 Docker,还有许多针对特定痛点(如安全、性能、隔离性&#x…...

保姆级教程:将LabelImg标注的VOC数据一键转为Ultralytics RT-DETR训练格式
从VOC到RT-DETR:零基础完成目标检测数据格式转换实战 当你第一次尝试用Ultralytics框架训练RT-DETR模型时,最令人头疼的往往不是模型调参,而是数据准备阶段——特别是当你的标注数据还停留在LabelImg生成的VOC格式(XML文件&#x…...

解锁B站高清与会员视频:基于you-get与EditThisCookie的自动化下载方案
1. 为什么需要you-get与EditThisCookie组合方案 每次在B站看到喜欢的视频想保存下来,你是不是也遇到过这样的烦恼?用普通下载工具要么画质模糊得像打了马赛克,要么遇到会员专属内容直接提示"无权限"。作为常年混迹技术社区的老司机…...

忘记压缩包密码怎么办?5分钟学会用ArchivePasswordTestTool找回密码
忘记压缩包密码怎么办?5分钟学会用ArchivePasswordTestTool找回密码 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经…...

3分钟掌握网页视频下载:Chrome扩展VideoDownloadHelper完全指南
3分钟掌握网页视频下载:Chrome扩展VideoDownloadHelper完全指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾经遇到想…...