计算机竞赛 题目:基于深度学习的手势识别实现
文章目录
- 1 前言
- 2 项目背景
- 3 任务描述
- 4 环境搭配
- 5 项目实现
- 5.1 准备数据
- 5.2 构建网络
- 5.3 开始训练
- 5.4 模型评估
- 6 识别效果
- 7 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的手势识别实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 项目背景
手势识别在深度学习项目是算是比较简单的。这里为了给大家会更好的训练。其中的数据集如下:

3 任务描述
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题。手势识别属于图像分类中的一个细分类问题。虽然与NLP的内容其实没有多大的关系,但是作为深度学习,DNN是一个最为简单的深度学习的算法,它是学习后序CNN、RNN、Lstm以及其他算法深度学习算法的基础。
实践环境:Python3.7,PaddlePaddle1.7.0。
用的仍然是前面多次提到的jupyter notebook,当然我们也可以用本地的pycharm。不过这里需要提醒大家,如果用的是jupyter
notebook作为试验训练,在实验中会占用很大的内存,jupyter
notebook默认路径在c盘,时间久了,我们的c盘会内存爆满,希望我们将其默认路径修改为其他的路径,网上有很多的修改方式,这里限于篇幅就不做说明了。这里需要给大家简要说明:paddlepaddle是百度
AI Studio的一个开源框架,类似于我们以前接触到的tensorflow、keras、caffe、pytorch等深度学习的框架。
4 环境搭配
首先在百度搜索paddle,选择你对应的系统(Windows、macOs、Ubuntu、Centos),然后选择你的安装方式(pip、conda、docker、源码编译),最后选择python的版本(Python2、python3),但是一般选择python3。
左后先则版本(GPU、CPU),但是后期我们用到大量的数据集,因此,我们需要下载GPU版本。,然后将该命令复制到cmd终端,点击安装,这里用到了百度的镜像,可以加快下载安装的速度。
python -m pip install paddlepaddle-gpu==1.8.3.post107 -i https://mirror.baidu.com/pypi/simple
学长电脑是window10系统,用的是pip安装方式,安装的版本是python3,本人的CUDA版本是CUDA10,因此选择的示意图以及安装命令如图所示。这里前提是我们把GPU安装需要的环境配好,网上有很多相关的

环境配好了,接下来就该项目实现。
5 项目实现
5.1 准备数据
首先我们导入必要的第三方库。
import os
import time
import random
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D
from paddle.fluid.dygraph import Linear
该数据集是学长自己收集标注的数据集(目前较小):包含0-9共就种数字手势,共2073张手势图片。
图片一共有3100100张,格式均为RGB格式文件。在本次实验中,我们选择其中的10%作为测试集,90%作为训练集。通过遍历图片,根据文件夹名称,生成label。
我按照1:9比例划分测试集和训练集,生成train_list 和 test_list,具体实现如下:
data_path = '/home/aistudio/data/data23668/Dataset' # 这里填写自己的数据集的路径,windows的默认路径是\,要将其路径改为/。
character_folders = os.listdir(data_path)
print(character_folders)
if (os.path.exists('./train_data.list')):os.remove('./train_data.list')
if (os.path.exists('./test_data.list')):os.remove('./test_data.list')
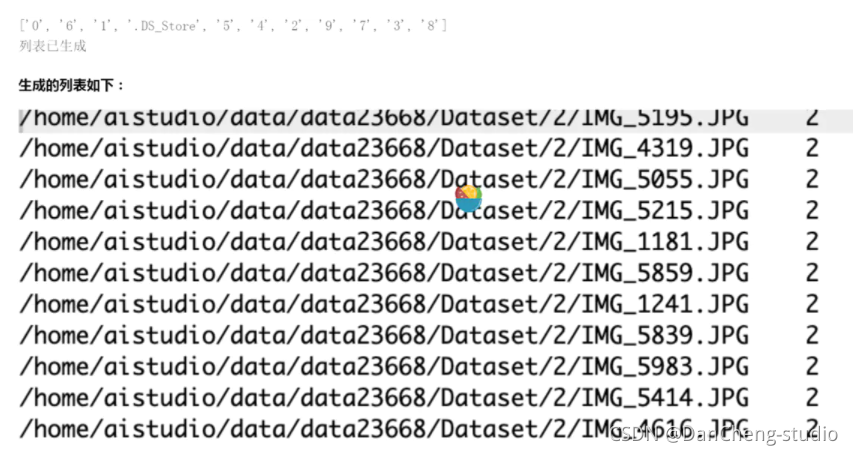
for character_folder in character_folders:with open('./train_data.list', 'a') as f_train:with open('./test_data.list', 'a') as f_test:if character_folder == '.DS_Store':continuecharacter_imgs = os.listdir(os.path.join(data_path, character_folder))count = 0for img in character_imgs:if img == '.DS_Store':continueif count % 10 == 0:f_test.write(os.path.join(data_path, character_folder, img) + '\t' + character_folder + '\n')else:f_train.write(os.path.join(data_path, character_folder, img) + '\t' + character_folder + '\n')count += 1
print('列表已生成')
其效果图如图所示:
这里需要简单的处理图片。需要说明一些函数:
- data_mapper(): 读取图片,对图片进行归一化处理,返回图片和 标签。
- data_reader(): 按照train_list和test_list批量化读取图片。
- train_reader(): 用于训练的数据提供器,乱序、按批次提供数据
- test_reader():用于测试的数据提供器
具体的实现如下:
def data_mapper(sample):img, label = sampleimg = Image.open(img)img = img.resize((32, 32), Image.ANTIALIAS)img = np.array(img).astype('float32')img = img.transpose((2, 0, 1))img = img / 255.0return img, label
def data_reader(data_list_path):def reader():with open(data_list_path, 'r') as f:lines = f.readlines()for line in lines:img, label = line.split('\t')yield img, int(label)return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 512)
5.2 构建网络
在深度学习中有一个关键的环节就是参数的配置,这些参数设置的恰当程度直接影响这我们的模型训练的效果。
因此,也有特别的一个岗位就叫调参岗,专门用来调参的,这里是通过自己积累的经验来调参数,没有一定的理论支撑,因此,这一块是最耗时间的,当然也是深度学习的瓶颈。
接下来进行参数的设置。
train_parameters = {"epoch": 1, #训练轮数"batch_size": 16, #批次大小"lr":0.002, #学习率"skip_steps":10, #每10个批次输出一次结果"save_steps": 30, #每10个批次保存一次结果"checkpoints":"data/"
}train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('./train_data.list'), buf_size=256),batch_size=32)
test_reader = paddle.batch(reader=data_reader('./test_data.list'), batch_size=32)
前面也提到深度神经网络(Deep Neural Networks, 简称DNN)是深度学习的基础。DNN网络图如图所示:

首先定义一个神经网络,具体如下
class MyLeNet(fluid.dygraph.Layer):def __init__(self):super(MyLeNet, self).__init__()self.c1 = Conv2D(3, 6, 5, 1)self.s2 = Pool2D(pool_size=2, pool_type='max', pool_stride=2)self.c3 = Conv2D(6, 16, 5, 1)self.s4 = Pool2D(pool_size=2, pool_type='max', pool_stride=2)self.c5 = Conv2D(16, 120, 5, 1)self.f6 = Linear(120, 84, act='relu')self.f7 = Linear(84, 10, act='softmax')def forward(self, input):# print(input.shape) x = self.c1(input)# print(x.shape)x = self.s2(x)# print(x.shape)x = self.c3(x)# print(x.shape)x = self.s4(x)# print(x.shape)x = self.c5(x)# print(x.shape)x = fluid.layers.reshape(x, shape=[-1, 120])# print(x.shape)x = self.f6(x)y = self.f7(x)return y
这里需要说明的是,在forward方法中,我们在每一步都给出了打印的print()函数,就是为了方便大家如果不理解其中的步骤,可以在实验中进行打印,通过结果来帮助我们进一步理解DNN的每一步网络构成。
5.3 开始训练
接下来就是训练网络。
为了方便我观察实验中训练的结果,学长引入了matplotlib第三方库,直观的通过图来观察我们的训练结果,具体训练网络代码实现如下:
import matplotlib.pyplot as plt
Iter=0
Iters=[]
all_train_loss=[]
all_train_accs=[]
def draw_train_process(iters,train_loss,train_accs):title='training loss/training accs'plt.title(title,fontsize=24)plt.xlabel('iter',fontsize=14)plt.ylabel('loss/acc',fontsize=14)plt.plot(iters,train_loss,color='red',label='training loss')plt.plot(iters,train_accs,color='green',label='training accs')plt.legend()plt.grid()plt.show()with fluid.dygraph.guard():model = MyLeNet() # 模型实例化model.train() # 训练模式opt = fluid.optimizer.SGDOptimizer(learning_rate=0.01,parameter_list=model.parameters()) # 优化器选用SGD随机梯度下降,学习率为0.001.epochs_num = 250 # 迭代次数for pass_num in range(epochs_num):for batch_id, data in enumerate(train_reader()):images = np.array([x[0].reshape(3, 32, 32) for x in data], np.float32)labels = np.array([x[1] for x in data]).astype('int64')labels = labels[:, np.newaxis]# print(images.shape)image = fluid.dygraph.to_variable(images)label = fluid.dygraph.to_variable(labels)predict = model(image) # 预测# print(predict)loss = fluid.layers.cross_entropy(predict, label)avg_loss = fluid.layers.mean(loss) # 获取loss值acc = fluid.layers.accuracy(predict, label) # 计算精度Iter += 32Iters.append(Iter)all_train_loss.append(loss.numpy()[0])all_train_accs.append(acc.numpy()[0])if batch_id != 0 and batch_id % 50 == 0:print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num, batch_id, avg_loss.numpy(), acc.numpy()))avg_loss.backward()opt.minimize(avg_loss)model.clear_gradients()fluid.save_dygraph(model.state_dict(), 'MyLeNet') # 保存模型
draw_train_process(Iters, all_train_loss, all_train_accs)
训练过程以及结果如下:

前面提到强烈建议大家安装gpu版的paddle框架,因为就是在训练过程中,paddle框架会利用英伟达的GP加速,训练的速度会很快的,而CPU则特别的慢。因此,CPU的paddle框架只是在学习的时候还可以,一旦进行训练,根本不行。
可能GPU需要几秒的训练在CPU可能需要十几分钟甚至高达半个小时。其实不只是paddlepaddle框架建议大家安装GPU版本,其他的类似tensorflow、keras、caffe等框架也是建议大家按安装GPU版本。不过安装起来比较麻烦,还需要大家认真安装。
with fluid.dygraph.guard():accs = []model_dict, _ = fluid.load_dygraph('MyLeNet')model = MyLeNet()model.load_dict(model_dict) # 加载模型参数model.eval() # 训练模式for batch_id, data in enumerate(test_reader()): # 测试集images = np.array([x[0].reshape(3, 32, 32) for x in data], np.float32)labels = np.array([x[1] for x in data]).astype('int64')labels = labels[:, np.newaxis]image = fluid.dygraph.to_variable(images)label = fluid.dygraph.to_variable(labels)predict = model(image)acc = fluid.layers.accuracy(predict, label)accs.append(acc.numpy()[0])avg_acc = np.mean(accs)print(avg_acc)
5.4 模型评估
配置好了网络,并且进行了一定的训练,接下来就是对我们训练的模型进行评估,具体实现如下:

结果还可以,这里说明的是,刚开始我们的模型训练评估不可能这么好,可能存在过拟合或者欠拟合的问题,不过更常见的是过拟合,这就需要我们调整我们的epoch、batchsize、激活函数的选择以及优化器、学习率等各种参数,通过不断的调试、训练最好可以得到不错的结果,但是,如果还要更好的模型效果,其实可以将DNN换为更为合适的CNN神经网络模型,效果就会好很多,关于CNN的相关知识以及实验,我们下篇文章在为大家介绍。最后就是我们的模型的预测。
6 识别效果
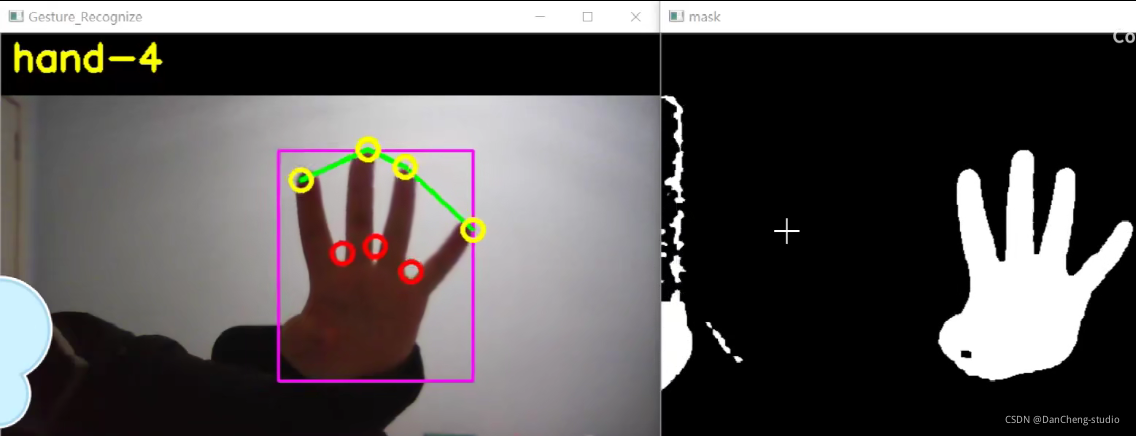
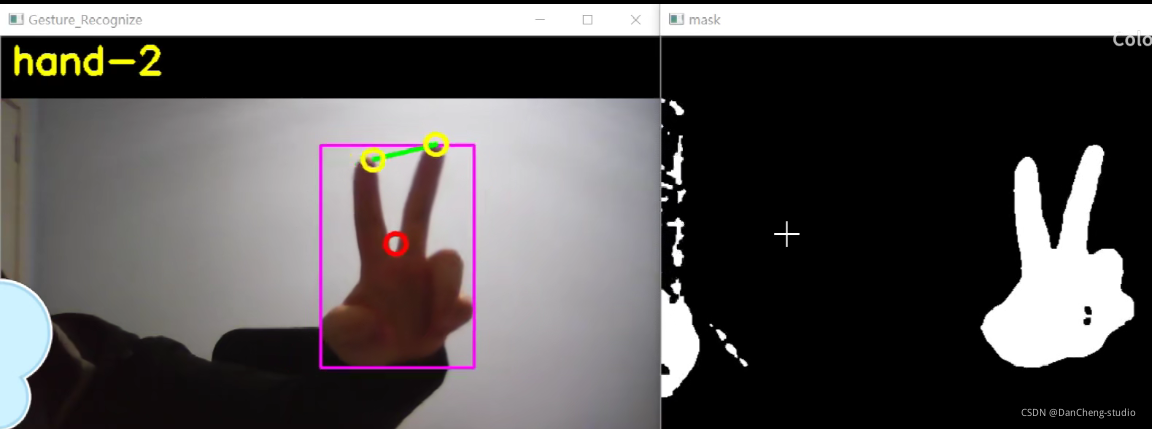

7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 题目:基于深度学习的手势识别实现
文章目录 1 前言2 项目背景3 任务描述4 环境搭配5 项目实现5.1 准备数据5.2 构建网络5.3 开始训练5.4 模型评估 6 识别效果7 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的手势识别实现 该项目较为新颖,适合作为竞赛课题…...

手撕各种排序
> 作者简介:დ旧言~,目前大一,现在学习Java,c,c,Python等 > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:掌握每种排序的方法,理解每种排序利弊…...
视频号的链接在哪,视频号视频链接地址获取办法!
不少人问视频号的链接在哪里可以获取,本质的在腾讯微信中目前视频号的链接是无法获取的,但好事多磨今天就分享一个第三方的视频号视频链接地址获取办法,希望对你有所帮助! 1:在微信客户端中,我们可以通过搜…...

深度学习笔记之优化算法(六)RMSprop算法的简单认识
深度学习笔记之优化算法——RMSProp算法的简单认识 引言回顾:AdaGrad算法AdaGrad算法与动量法的优化方式区别AdaGrad算法的缺陷 RMProp算法关于AdaGrad问题的优化方式RMSProp的算法过程描述 RMSProp示例代码 引言 上一节对 AdaGrad \text{AdaGrad} AdaGrad算法进行…...

10架构管理之公司整体技术架构
一句话导读 公司的整体技术架构一般是公司的架构组、架构管理部、技术委员会等部门负责,需要对公司整体的技术架构进行把控和管理,确保信息系统的稳定性和可靠性,避免因技术架构不合理而导致的系统崩溃和数据丢失等问题,为公司的业…...

联邦学习综述
《Advances and Open Problems in Federated Learning》 选题:Published 10 December 2019-Computer Science-Found. Trends Mach. Learn. 联邦学习定义 联邦学习是一种机器学习设置,其中多个客户端在中央服务器或服务提供商的协调下协作解决机器学习…...

几行cmd命令,轻松将java文件打包成jar文件
1. 在任意目录下建立一个.java文件 2. 在当前目录下使用cmd命令: javac filename编译 如果报错则使用此命令javac -encoding UTF-8 filename 3.此时已成功生成.class文件 4. 可以手动添加MANIFEST.MF文件 Manifest-Version: 1.0 Main-Class: fileName 5.直接一…...

BuyVM 卢森堡 VPS 测评
description: 发布于 2023-07-05 BuyVM 卢森堡 VPS 测评 产品链接:https://my.frantech.ca/cart.php?gid39 1G口不限流量,续约3个月后升级为10G口突发。抗DMCA版权投诉。抗一般投诉。 大陆连通性还可以,延迟略高,不绕美。 CP…...
JavaScript 编写一个 数值转换函数 万以后简化 例如1000000 展示为 100万 万以下原来数值返回
很多时候 我们看一些系统 能够比较只能的展示过大的数值 例如 到万了 他就能展示出 多少 多少万 看着很奇妙 但实现确实非常的基础 我们只需要一个这样的函数 //数值转换函数 convertNumberToString(num) {//如果传入的数值 不是数字 且也无法转为数字 直接扔0回去if (!parse…...
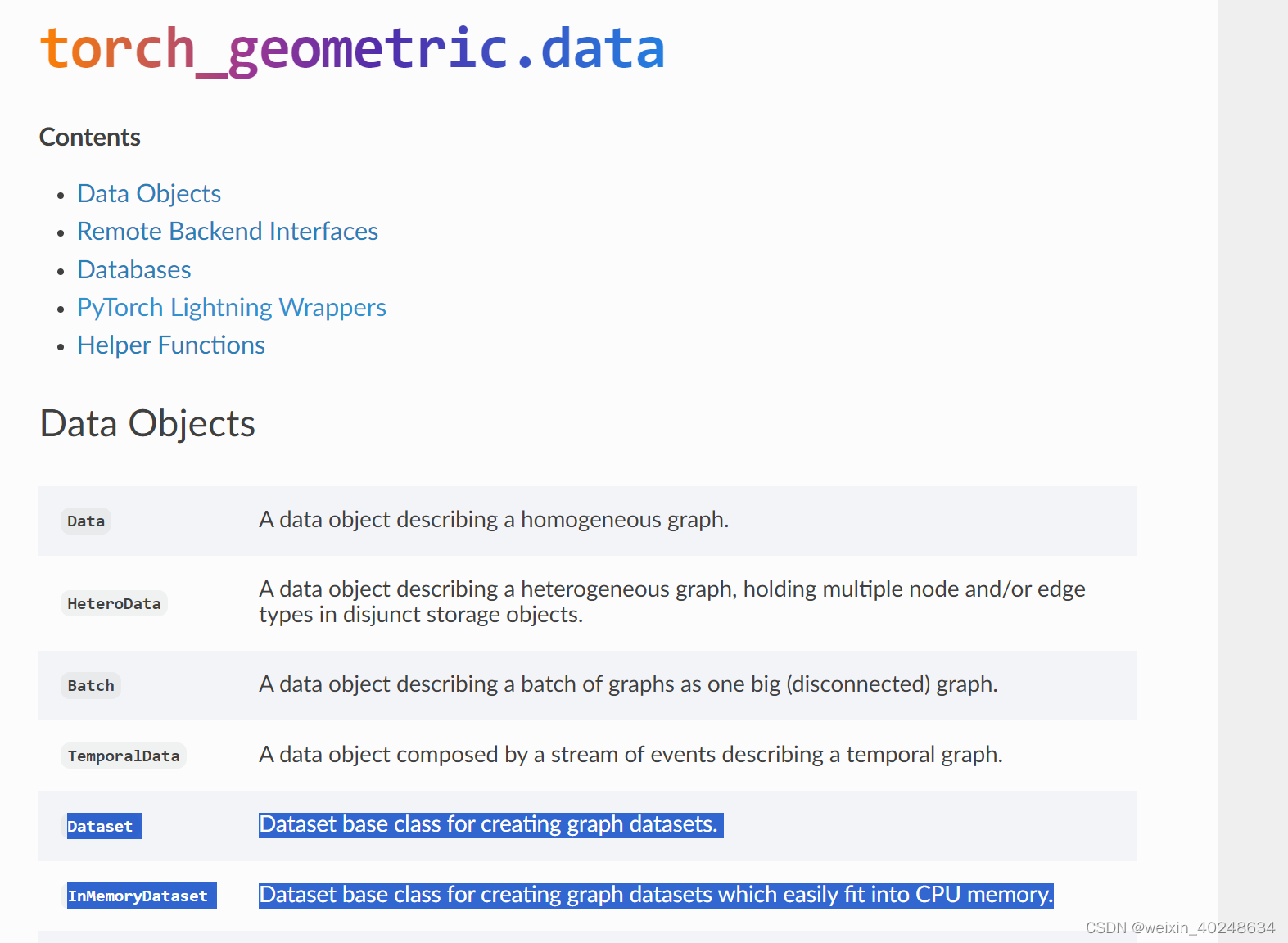
PyG两个data Datsaset v.s. InMemoryDataset
可以看到InMemoryDataset 对CPU更加友好 https://pytorch-geometric.readthedocs.io/en/latest/modules/data.html#pytorch-lightning-wrappers...

ArcGIS Engine:视图菜单的创建和鹰眼图的实现
目录 01 创建项目 1.1 通过ArcGIS-ExtendingArcObjects创建窗体应用 1.2 通过C#-Windows窗体应用创建窗体应用 1.2.1 创建基础项目 1.2.2 搭建界面 02 创建视图菜单 03 鹰眼图的实现 3.1 OnMapReplaced事件的触发 3.2 OnExtentUpdated事件的触发 04 稍作演示 01 创建项目…...
POI 和 EasyExcel 操作 Excel
一、概述 目前操作 Excel 比较流行的就是 Apache POI 和阿里巴巴的 easyExcel。 1.1 POI 简介 Apache POI 是用 Java 编写的免费开源的跨平台的 Java API,Apache POI 提供 API 给 Java 程序对 Microsoft Office 格式文档读和写的常用功能。POI 为 “Poor Obfuscati…...

pytorch算力与有效性分析
pytorch Windows中安装深度学习环境参考文档机器环境说明3080机器 Windows11qt_env 满足遥感CS软件分割、目标检测、变化检测的需要gtrs 主要是为了满足遥感监测管理平台(BS)系统使用的,无深度学习环境内容swin_env 与 qt_env 基本一致od 用于…...

Sublime text启用vim模式
官方教程:https://www.sublimetext.com/docs/vintage.html vintage的github:https://github.com/sublimehq/Vintage...
)
爬虫进阶-反爬破解6(Nodejs+Puppeteer实现登陆官网+实现滑动验证码全自动识别)
一、NodejsPuppeteer实现登陆官网 1.环境说明 Nodejs——直接从官网下载最新版本,并安装 使用npm安装puppeteer:npm install puppeteer npm install xxx -registry https://registry.npm.taobao.org Chromium会自动下载,前提是网络通畅 2.实践操作…...
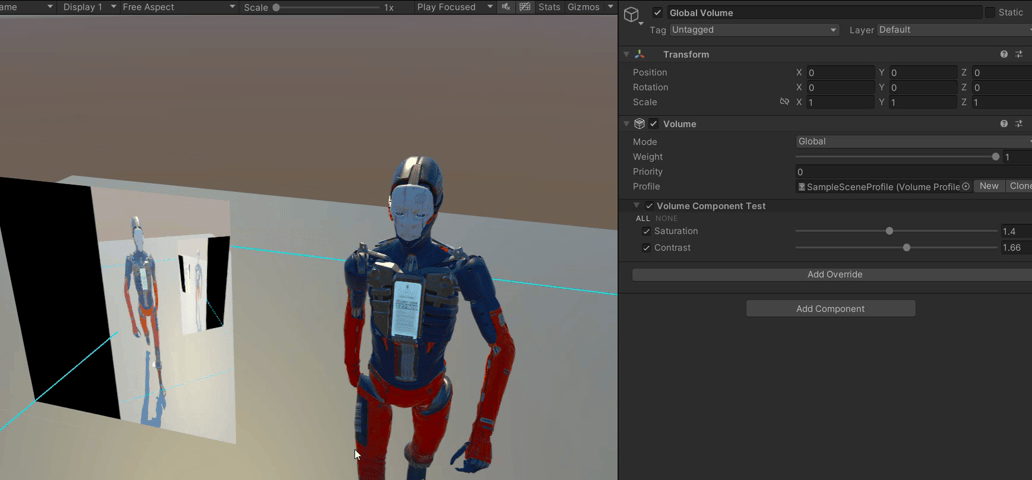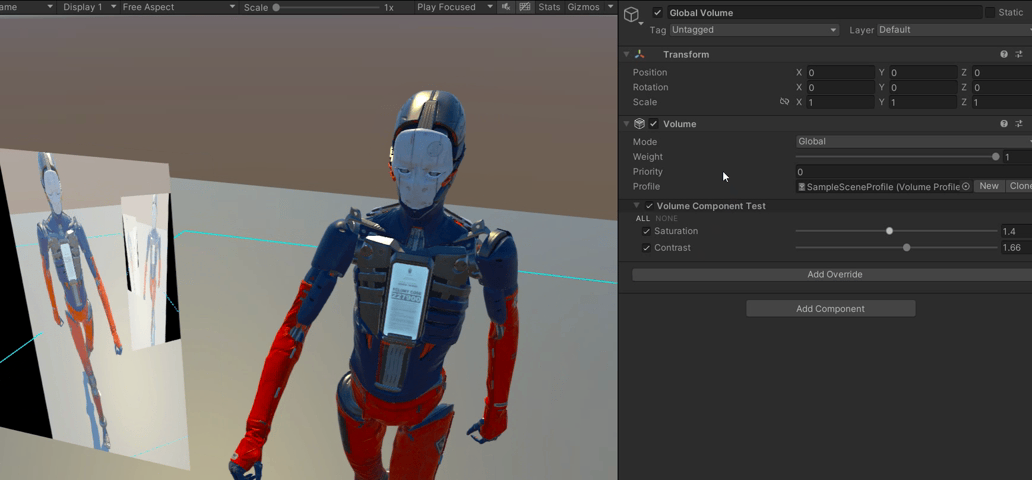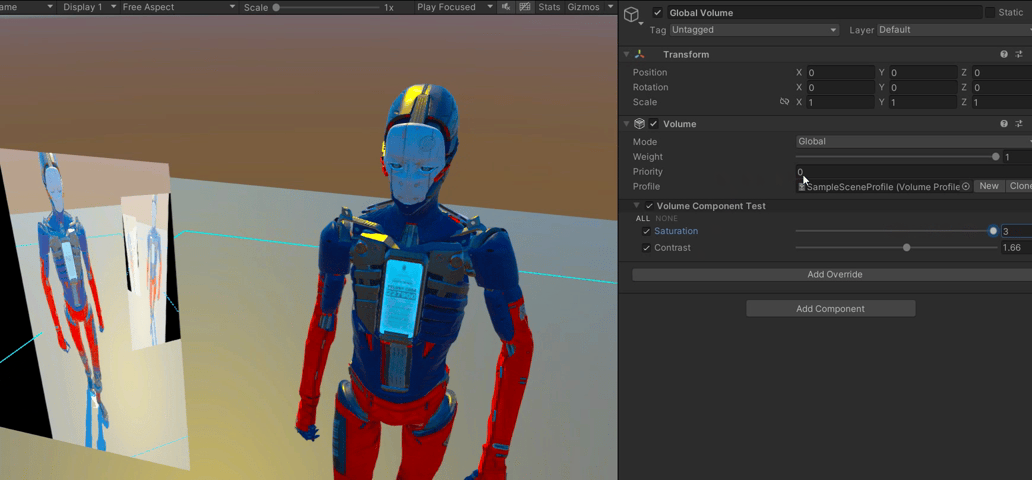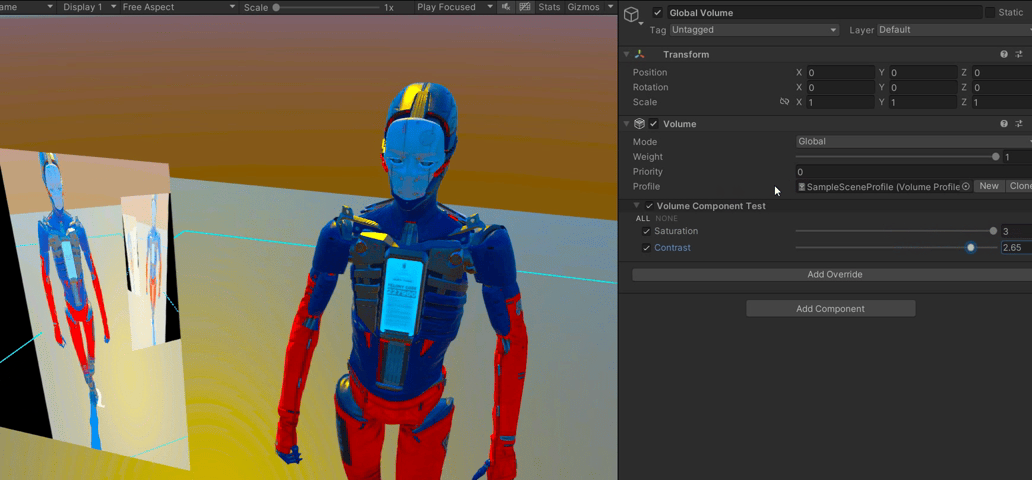
【Unity】RenderFeature笔记
【Unity】RenderFeature笔记 RenderFeature是在urp中添加的额外渲染pass,并可以将这个pass插入到渲染列队中的任意位置。内置渲染管线中Graphics 的功能需要在RenderFeature里实现,常见的如DrawMesh和Blit 可以实现的效果包括但不限于 后处理,可以编写…...
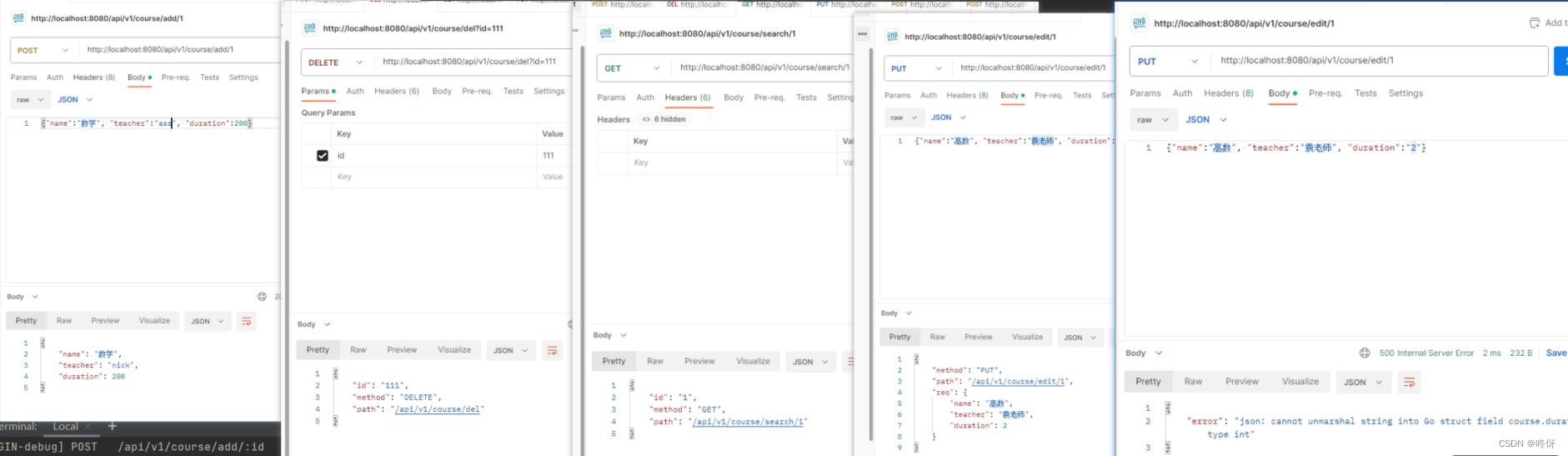
golang gin——controller 模型绑定与参数校验
controller 模型绑定与参数校验 gin框架提供了多种方法可以将请求体的内容绑定到对应struct上,并且提供了一些预置的参数校验 绑定方法 根据数据源和类型的不同,gin提供了不同的绑定方法 Bind, shouldBind: 从form表单中去绑定对象BindJSON, shouldB…...

办公技巧:Excel日常高频使用技巧
目录 1. 快速求和?用 “Alt ” 2. 快速选定不连续的单元格 3. 改变数字格式 4. 一键展现所有公式 “CTRL ” 5. 双击实现快速应用函数 6. 快速增加或删除一列 7. 快速调整列宽 8. 双击格式刷 9. 在不同的工作表之间快速切换 10. 用F4锁定单元格 1. 快速求…...
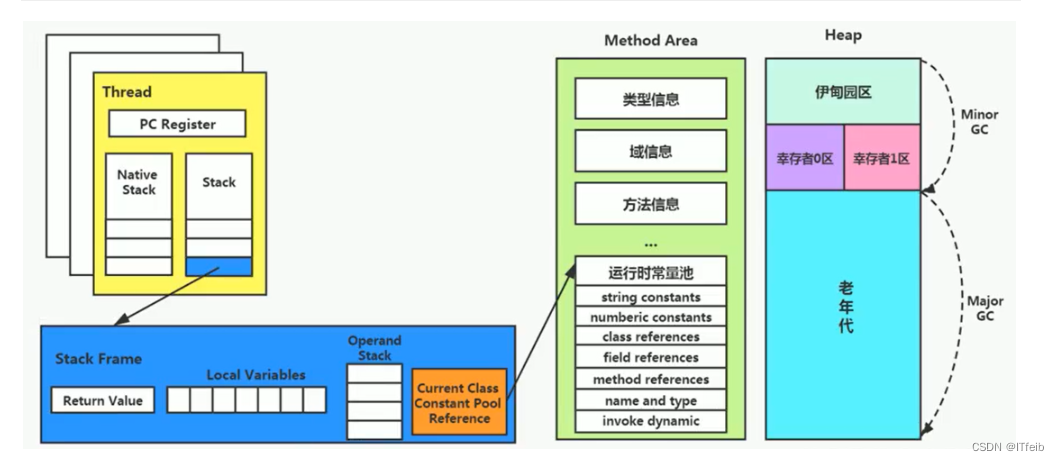
【jvm--方法区】
文章目录 1. 栈、堆、方法区的交互关系2. 方法区的内部结构3. 运行时常量池4. 方法区的演进细节5. 方法区的垃圾回收 1. 栈、堆、方法区的交互关系 方法区的基本理解: 方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区…...

智慧楼宇3D数据可视化大屏交互展示实现了楼宇能源的高效、智能、精细化管控
智慧园区是指将物联网、大数据、人工智能等技术应用于传统建筑和基础设施,以实现对园区的全面监控、管理和服务的一种建筑形态。通过将园区内设备、设施和系统联网,实现数据的传输、共享和响应,提高园区的管理效率和运营效益,为居…...

【knife4j】接口分组配置;登录拦截器放行;登录拦截器配置token;给全局异常处理类添加注解;解决上传文件不显示文件域;参数扁平化;@Parameter
Parameter Parameter 是用来为 API 接口参数添加元数据(描述信息)的注解,这些信息最终会生成到 OpenAPI 规范的文档中,供 Knife4j/Swagger UI 等工具展示 简单来说:它让 API 的使用者能清楚地知道每个参数的含义、是…...

closure-compiler-js迁移指南:如何从弃用版本平稳过渡到官方版本
closure-compiler-js迁移指南:如何从弃用版本平稳过渡到官方版本 【免费下载链接】closure-compiler-js Package for the JS version of closure-compiler for use via NPM 项目地址: https://gitcode.com/gh_mirrors/cl/closure-compiler-js 如果你正在使用…...

终极免费文档下载指南:kill-doc让你轻松保存百度文库等30+平台内容
终极免费文档下载指南:kill-doc让你轻松保存百度文库等30平台内容 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚…...

OpenHarmony Rust开发实战:GN构建配置与FFI互操作指南
1. 项目概述:为什么要在OpenHarmony里搞Rust?最近在折腾OpenHarmony开发板,想把一些对性能和安全性要求比较高的模块用Rust重写,结果发现官方文档里关于Rust构建的部分讲得比较零散。踩了一圈坑之后,我决定把OpenHarmo…...
)
别再只盯着PWM了!手把手教你为你的Arduino项目选择合适的DCDC调制方式(PFM/PWM/Burst Mode全解析)
别再只盯着PWM了!手把手教你为你的Arduino项目选择合适的DCDC调制方式(PFM/PWM/Burst Mode全解析) 当你为Arduino项目挑选电源模块时,是否曾被数据手册上PWM、PFM、Burst Mode这些术语搞得一头雾水?我曾在一个低功耗气…...

别再只盯着CVE-2017-7529复现了,聊聊Nginx缓存机制下的那些‘信息泄露’风险
深入解析Nginx缓存机制与敏感信息防护实践 Nginx作为现代Web架构的核心组件,其高效的缓存机制在提升性能的同时也隐藏着不容忽视的安全隐患。当开发者们热衷于讨论CVE-2017-7529这类高危漏洞的复现时,我们更需要将目光投向日常配置中那些容易被忽视的信息…...

.NET逆向工程新选择:dnSpyEx调试器与程序集编辑全解析
.NET逆向工程新选择:dnSpyEx调试器与程序集编辑全解析 【免费下载链接】dnSpy Unofficial revival of the well known .NET debugger and assembly editor, dnSpy 项目地址: https://gitcode.com/gh_mirrors/dns/dnSpy 你是否曾面对一个没有源代码的.NET程序…...

贪吃蛇游戏开发实战:从基础架构到错误监控与性能优化
1. 项目概述:一个“会说话”的贪吃蛇游戏最近在GitHub上看到一个挺有意思的项目,叫“BugSplat-Git/snake-game”。初看标题,你可能觉得这不就是个经典的贪吃蛇游戏吗?从诺基亚时代玩到现在的玩意儿,还能有什么新花样&a…...

Java后端开发德州扑克小酒馆小程序架构与源码解析
德州扑克小酒馆小程序的核心价值,在于依托休闲娱乐场景实现小酒馆线下引流,其Java后端的架构设计与源码实现,直接决定小程序的稳定性、可扩展性与合规性。 一、架构设计核心原则(贴合场景,合规优先) 德州…...
-东方仙盟)
安卓android无法创建文件夹权限-幽冥大陆(一百21)-东方仙盟
谷歌从安卓 6 开始强制规定直接锁死:根目录 /、system、storage 根目录 全部禁止 APP 写入。目的:防流氓软件乱改系统、乱建文件夹、乱篡改系统文件。瑞芯微等主板厂商二次加锁RK、全志、晶晨这类工控主板,还额外加了两层限制:分区…...