pytorch实现经典神经网络:VGG16模型之初探
文章链接
https://blog.csdn.net/weixin_44791964/article/details/102585038?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169675238616800211588158%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=169675238616800211588158&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-2-102585038-null-null.nonecase&utm_term=VGG&spm=1018.2226.3001.4450
VGG16原理链接
https://zhuanlan.zhihu.com/p/460777014
代码参考:
https://blog.csdn.net/m0_50127633/article/details/117045008?ops_request_misc=&request_id=&biz_id=102&utm_term=pytorch%20vgg16&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-117045008.142v95insert_down28v1&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_46676835/article/details/128730174?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169681442316800215096882%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169681442316800215096882&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-5-128730174-null-null.142v95insert_down28v1&utm_term=pytorch%20vgg16&spm=1018.2226.3001.4187
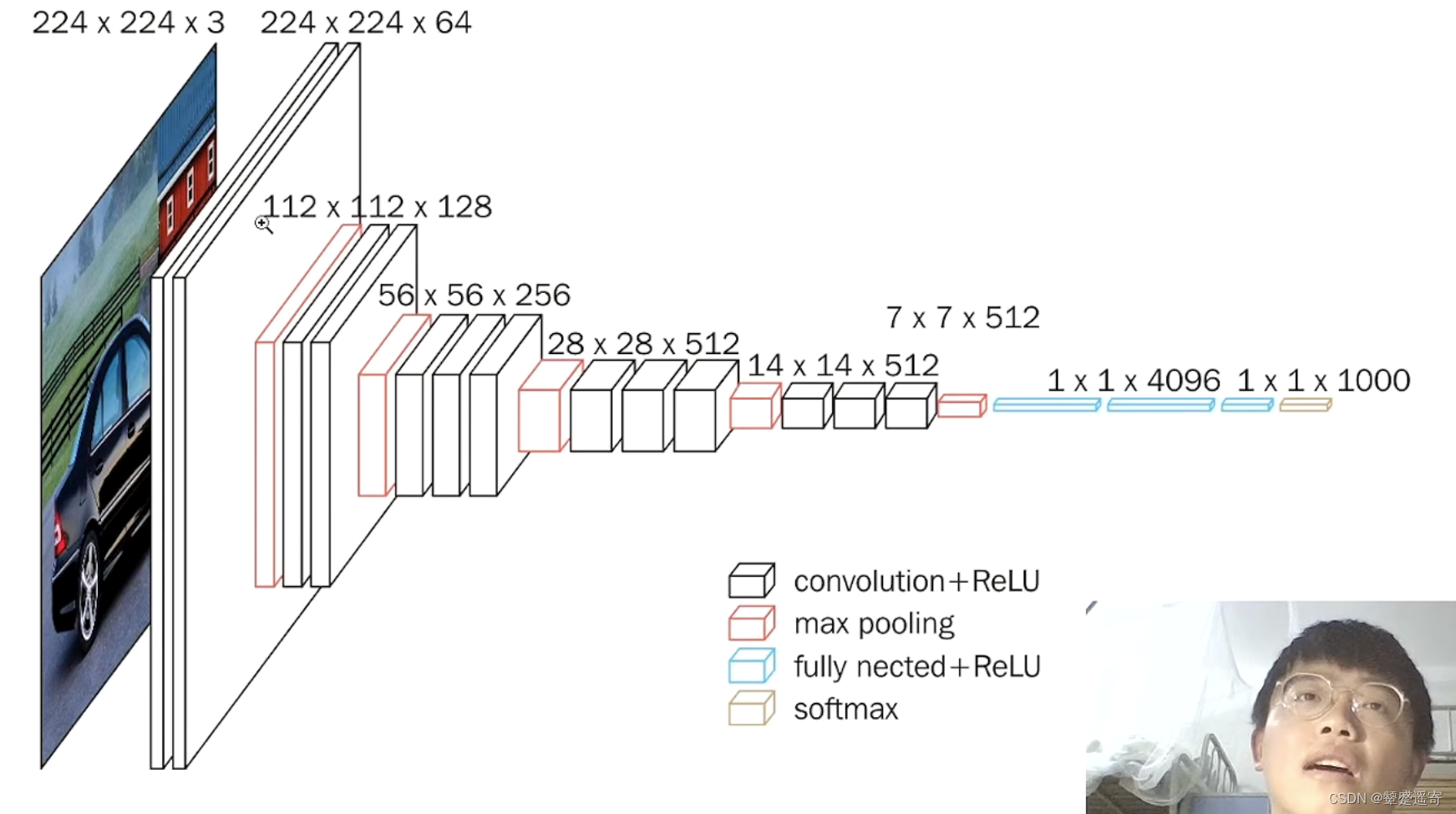

分解一下:
卷积提取特征,池化压缩。
1、一张原始图片被resize到(224,224,3)。
2、conv1两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再2X2最大池化,输出net为(112,112,64)。
注意 池化不会改变通道数

根据公式第一步取stride=1,padding=1

stride=2 padding=0(不用写)
nn.Conv2d(3,64,3,1,1),nn.Conv2d(64,64,3,1,1)nn.Conv2d(3,64,3,1,1),nn.Conv2d(64,64,3,1,1),nn.MaxPool2d(2,2)3、conv2两次[3,3]卷积网络,第一次输入的特征层为64,输出net为(112,112,128),再2X2最大池化,输出net为(56,56,128)。
nn.Conv2d(64,128,3,1,1),nn.Conv2d(128, 128, 3, 1, 1),nn.MaxPool2d(2,2),
4、conv3三次[3,3]卷积网络,输入的特征层为256,输出net为(56,56,256),再2X2最大池化,输出net为(28,28,256)。
nn.Conv2d(128,256,3,1,1),nn.Conv2d(256,256,3,1,1),nn.Conv2d(256,256,3,1,1),nn.MaxPool2d(2,2)
5、conv3三次[3,3]卷积网络,输入的特征层为256,输出net为(28,28,512),再2X2最大池化,输出net为(14,14,512)。
nn.Conv2d(256,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.MaxPool2d(2,2),
6、conv3三次[3,3]卷积网络,输出的特征层为256,输出net为(14,14,512),再2X2最大池化,输出net为(7,7,512)。
nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.MaxPool2d(2,2)7、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,4096)。共进行两次。
nn.Linear(25088,4096), #7×7×512nn.Linear(4096,4096),nn.Linear(4096,1000)
8、利用卷积的方式模拟全连接层,效果等同,输出net为(1,1,1000)。
最后输出的就是每个类的预测。
nn.Linear(4096,1000)
初步代码框架如下:
import torch
from torch import nnclass VGG(nn.Module):def __init__(self):super(VGG, self).__init__()self.MyVgg=nn.Sequential(nn.Conv2d(3,64,3,1,1),nn.Conv2d(64,64,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(64,128,3,1,1),nn.Conv2d(128, 128, 3, 1, 1),nn.MaxPool2d(2,2),nn.Conv2d(128,256,3,1,1),nn.Conv2d(256,256,3,1,1),nn.Conv2d(256,256,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(256,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.MaxPool2d(2,2),nn.Linear(25088,4096), #7×7×512nn.Linear(4096,4096),nn.Linear(4096,1000))
补充与完善
1、记得进行数据拉平:
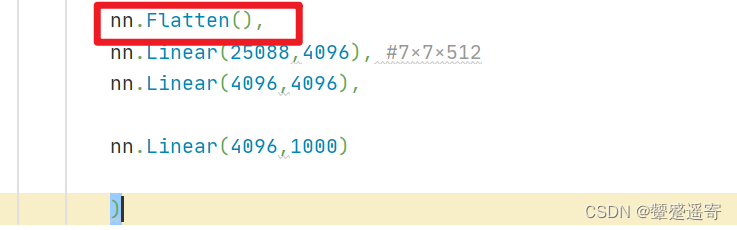
模型部分
class VGG(nn.Module):def __init__(self):super(VGG, self).__init__()self.MyVgg=nn.Sequential(nn.Conv2d(3,64,3,1,1),nn.Conv2d(64,64,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(64,128,3,1,1),nn.Conv2d(128, 128, 3, 1, 1),nn.MaxPool2d(2,2),nn.Conv2d(128,256,3,1,1),nn.Conv2d(256,256,3,1,1),nn.Conv2d(256,256,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(256,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.MaxPool2d(2,2),nn.Flatten(),nn.Linear(25088,4096), #7×7×512nn.Linear(4096,4096),nn.Linear(4096,1000))def forward(self,x):x=self.MyVgg(x)return x2、导入数据
使用cifar10数据集
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoaderdatasets_train=torchvision.datasets.CIFAR10("./data",train=True,download=True,transform=torchvision.transforms.ToTensor())
datasets_test=torchvision.datasets.CIFAR10("./data",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader_train=DataLoader(datasets_train,batch_size=64)
dataloader_test=DataLoader(datasets_test,batch_size=64)
3、创建损失函数
使用交叉熵CrossEntropyLoss
from torch import nn
los_fun=nn.CrossEntropyLoss()
4、创建优化器:
learning_rate=0.001
optimizer=torch.optim.SGD(fenlei.parameters(),lr=learning_rate)5、编写训练代码:
total_train_step=0
tatal_test_step=0
epoch=10for i in range(epoch):print("--------第{}轮训练开始-----".format(i+1))for data in dataloader_train:imgs,targets=dataoutputs=fenlei(imgs)loss=los_fun(outputs,targets)optimizer.zero_grad()loss.backward()total_train_step=total_train_step+1print("训练次数:{},Loss:{}".format(total_train_step, loss))
训练时报错:
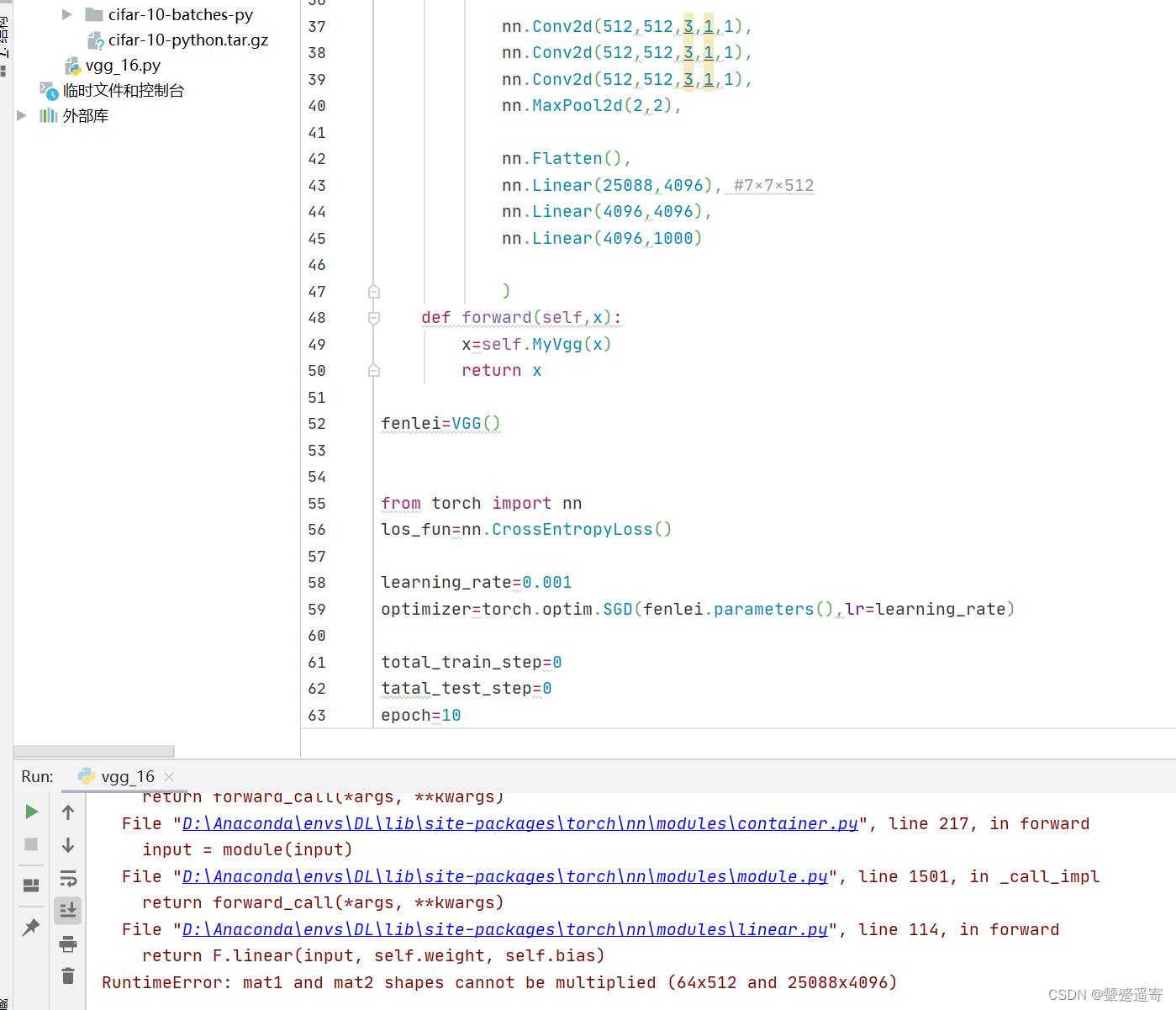
原因我们假设输入的是224×224×3了
然而cfar10的数据集是32×32×3
所以我们需要加入resize操作:
from torchvision import transforms
datasets_train=torchvision.datasets.CIFAR10("./data",train=True,download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Resize([224,224])]) )
6、使用GPU训练:
#定义训练设备
device=torch.device('cuda'if torch.cuda.is_available()else 'cpu')
fenlei.to(device)
los_fun=los_fun.to(device)
我的
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
datasets_train=torchvision.datasets.CIFAR10("./data",train=True,download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Resize([224,224])]) )
datasets_test=torchvision.datasets.CIFAR10("./data",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader_train=DataLoader(datasets_train,batch_size=24,drop_last=True)
dataloader_test=DataLoader(datasets_test,batch_size=64,drop_last=True)img,target=datasets_train[0]
print(img.shape)class VGG(nn.Module):def __init__(self):super(VGG, self).__init__()self.MyVgg=nn.Sequential(nn.Conv2d(3,64,3,1,1),nn.Conv2d(64,64,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(64,128,3,1,1),nn.Conv2d(128, 128, 3, 1, 1),nn.MaxPool2d(2,2),nn.Conv2d(128,256,3,1,1),nn.Conv2d(256,256,3,1,1),nn.Conv2d(256,256,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(256,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.MaxPool2d(2,2),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.Conv2d(512,512,3,1,1),nn.MaxPool2d(2,2),nn.Flatten(),nn.Linear(25088,4096), #7×7×512nn.Linear(4096,4096),nn.Linear(4096,1000))def forward(self,x):x=self.MyVgg(x)return xfenlei=VGG()from torch import nn
los_fun=nn.CrossEntropyLoss()learning_rate=0.001
optimizer=torch.optim.SGD(fenlei.parameters(),lr=learning_rate)total_train_step=0
tatal_test_step=0
epoch=10#定义训练设备
device=torch.device('cuda'if torch.cuda.is_available()else 'cpu')
fenlei.to(device)
los_fun=los_fun.to(device)for i in range(epoch):print("--------第{}轮训练开始-----".format(i+1))for data in dataloader_train:imgs,targets=dataimgs=imgs.to(device)targets=targets.to(device)outputs = fenlei(imgs)loss=los_fun(outputs,targets)optimizer.zero_grad()loss.backward()total_train_step=total_train_step+1if total_train_step%10==0:print("训练次数:{},Loss:{}".format(total_train_step, loss))为啥人家的代码训练这么快?
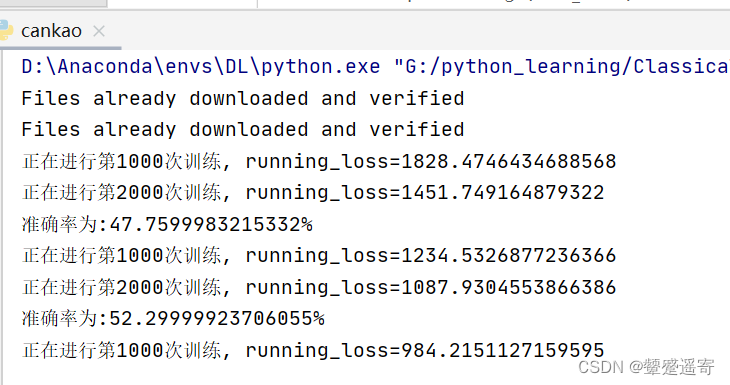
在PyTorch中,nn.Dropout和nn.ReLU是常用的神经网络模块,分别用于正则化和激活函数。
nn.Dropout是一种正则化技术,旨在减少神经网络的过拟合问题。过拟合是指模型在训练集上表现很好,但在测试集上表现较差的现象。Dropout通过在训练过程中随机将一定比例的神经元置为0,以强制网络学习到冗余特征,从而提高模型的泛化能力。这可以防止过拟合,并提高网络的鲁棒性。
nn.ReLU是一种常用的激活函数,它被广泛应用在神经网络中。ReLU的全称是Rectified Linear Unit,它的定义很简单:对于输入x,当x小于0时,输出为0;当x大于等于0时,输出为x。ReLU函数的优点是计算简单、非线性、减轻梯度消失等。
在神经网络中,ReLU函数能够引入非线性,增加模型的拟合能力,并且减少梯度消失问题。当输入为负时,ReLU将输出为0,这有助于稀疏表示,从而使得网络更加有效地学习特征。
综上所述,nn.Dropout用于减少过拟合,提高泛化能力,而nn.ReLU用于引入非线性和解决梯度消失问题。它们在神经网络中的应用非常常见,并且经过广泛验证的有效技术。
明天看录播有助于理解他的代码:
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plttransform_train = transforms.Compose([transforms.Pad(4),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),transforms.RandomHorizontalFlip(),transforms.RandomGrayscale(),transforms.RandomCrop(32, padding=4),])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]
)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainLoader = torch.utils.data.DataLoader(trainset, batch_size=24, shuffle=True)testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testLoader = torch.utils.data.DataLoader(testset, batch_size=24, shuffle=False)vgg = [96, 96, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']class VGG(nn.Module):def __init__(self, vgg):super(VGG, self).__init__()self.features = self._make_layers(vgg)self.dense = nn.Sequential(nn.Linear(512, 4096),nn.ReLU(inplace=True),nn.Dropout(0.4),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(0.4),)self.classifier = nn.Linear(4096, 10)def forward(self, x):out = self.features(x)out = out.view(out.size(0), -1)out = self.dense(out)out = self.classifier(out)return outdef _make_layers(self, vgg):layers = []in_channels = 3for x in vgg:if x == 'M':layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),nn.BatchNorm2d(x),nn.ReLU(inplace=True)]in_channels = xlayers += [nn.AvgPool2d(kernel_size=1, stride=1)]return nn.Sequential(*layers)model = VGG(vgg)
# model.load_state_dict(torch.load('CIFAR-model/VGG16.pth'))
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=5e-3)
loss_func = nn.CrossEntropyLoss()
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.4, last_epoch=-1)total_times = 40
total = 0
accuracy_rate = []def test():model.eval()correct = 0 # 预测正确的图片数total = 0 # 总共的图片数with torch.no_grad():for data in testLoader:images, labels = dataimages = images.to(device)outputs = model(images).to(device)outputs = outputs.cpu()outputarr = outputs.numpy()_, predicted = torch.max(outputs, 1)total += labels.size(0)correct += (predicted == labels).sum()accuracy = 100 * correct / totalaccuracy_rate.append(accuracy)print(f'准确率为:{accuracy}%'.format(accuracy))for epoch in range(total_times):model.train()model.to(device)running_loss = 0.0total_correct = 0total_trainset = 0for i, (data, labels) in enumerate(trainLoader, 0):data = data.to(device)outputs = model(data).to(device)labels = labels.to(device)loss = loss_func(outputs, labels).to(device)optimizer.zero_grad()loss.backward()optimizer.step()running_loss += loss.item()_, pred = outputs.max(1)correct = (pred == labels).sum().item()total_correct += correcttotal_trainset += data.shape[0]if i % 1000 == 0 and i > 0:print(f"正在进行第{i}次训练, running_loss={running_loss}".format(i, running_loss))running_loss = 0.0test()scheduler.step()# torch.save(model.state_dict(), 'CIFAR-model/VGG16.pth')
accuracy_rate = np.array(accuracy_rate)
times = np.linspace(1, total_times, total_times)
plt.xlabel('times')
plt.ylabel('accuracy rate')
plt.plot(times, accuracy_rate)
plt.show()print(accuracy_rate)
相关文章:
pytorch实现经典神经网络:VGG16模型之初探
文章链接 https://blog.csdn.net/weixin_44791964/article/details/102585038?ops_request_misc%257B%2522request%255Fid%2522%253A%2522169675238616800211588158%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id16967523861680…...

Newtonsoft.Json use
private void button3_Click(object sender, EventArgs e) { List<Student> students new List<Student>(); students.Add(new Student { Id 1, Name "张三", Sex "男", Description "班长" }); students.…...
MySQL-3(9000字详解)
一:索引 索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。 1.1索引的意义 索引的意义:加快查找速度,但需要…...

SLAM从入门到精通(3d 点云数据访问)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 3d 点云设备现在汽车上用的很多。之前3d lidar这种高端传感器,只能被少部分智能汽车使用。后来很多国产厂家也开始研发3d lidar之后&am…...

如何在 Spring Boot 中提高应用程序的安全性
如何在 Spring Boot 中提高应用程序的安全性 Spring Boot是一种流行的Java开发框架,用于构建Web应用程序和微服务。在构建应用程序时,安全性是至关重要的因素。不论您的应用程序是面向公众用户还是企业内部使用,都需要采取适当的措施来确保数…...
【Vuex+ElementUI】
一、导言 1、引言 Vuex是一个用于Vue.js应用程序的状态管理模式和库。它建立在Vue.js的响应式系统之上,提供了一种集中管理应用程序状态的方式。使用Vuex,您可以将应用程序的状态存储在一个单一的位置(即“存储”)中,…...
多媒体播放软件 Infuse mac中文特点介绍
Infuse mac是一款多媒体播放器应用,它支持播放多种格式的视频文件、音频文件和图片文件,并且可以通过AIrPlay将媒体内容投放到其他设备上。Infuse还支持在线视频流媒体播放和本地网络共享,用户可以通过它来访问家庭网络上的媒体文件。 Infuse…...
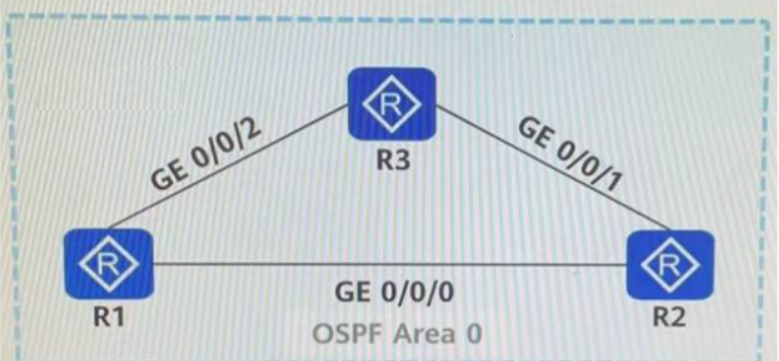
华为数通方向HCIP-DataCom H12-831题库(单选题:201-220)
第201题 如图所示,路由器所有的接口开启OSPF,链路的Cost值如图中标识。若在R2的OSPF进程中通过命令import-route direct type 1引入直连路由,则R1到达10.0.2.2 /32的Cost值是以下哪一选项? A、150 B、151 C、200 D、201 答案:C 解析: Loopback0的cost值默认为0,R1-R2的…...

【管理运筹学】第 9 章 | 网络计划(2,时间参数的计算 —— 工作时间的确定与事项的时间参数)
文章目录 引言一、工作时间的确定二、事项的时间参数2.1 事项的最早开始时间2.2 事项的最迟结束时间2.3 事项的时差2.4 利用事项的时间参数来确定关键线路 引言 计算网络图中有关的时间参数,主要目的是找到关键线路,为网络计划的优化、调增和执行提供明…...

英语——方法篇——单词——羊肉串记忆法——单词密码
在记忆英语单词的时候,我们习惯于一个字母一个字母地记忆,很少会以词或字母组合为单位来记忆。在这里我们要打开视野,学习以词或字母组合为单位,一组一组地记忆英语单词。英语单词数目庞大,但是构成单词的字母只有26个…...

【m98】视频帧的 jitterbuffer 1:
VCMJitterBuffer D:\XTRANS\m98_rtc\rtc-webrtc\src\modules\video_coding\jitter_buffer.h使用2个map和一个list管理VCMFrameBuffer 指针对象:UnorderedFrameList free_frames_ RTC_GUARDED_BY(mutex_);FrameList decodable_frames_ RTC_GUARDED_BY(mutex_);FrameList incomp…...

javascript中map和filter的区别与联系
javascript中map和filter的区别与联系如何获取对象数组中某个值 javascript中map和filter的区别与联系 在 JavaScript 中,map 和 filter 是两个常用的数组方法,用于对数组进行转换和过滤操作。它们的区别和联系如下: 功能不同: m…...
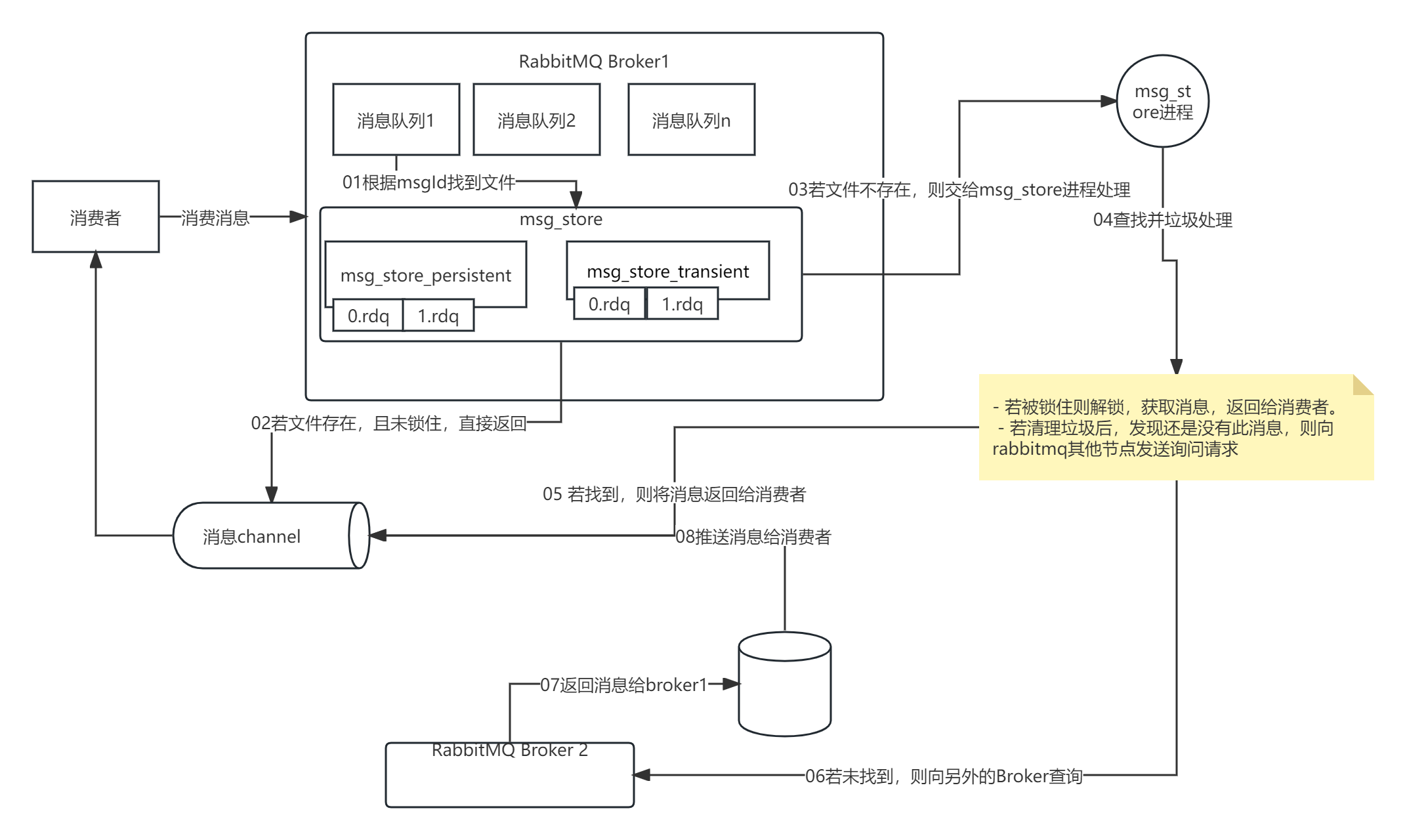
【RabbitMQ 实战】10 消息持久化和存储原理
一、持久化 1.1 持久化对象 rabbitmq的持久化分为三个部分: 交换器的持久化。队列的持久化。消息的持久化。 1.1.1 交换器持久化 交换器的持久化是通过在声明交换器时, 指定Durability参数为durable实现的。若交换器不设置持久化,在rabb…...
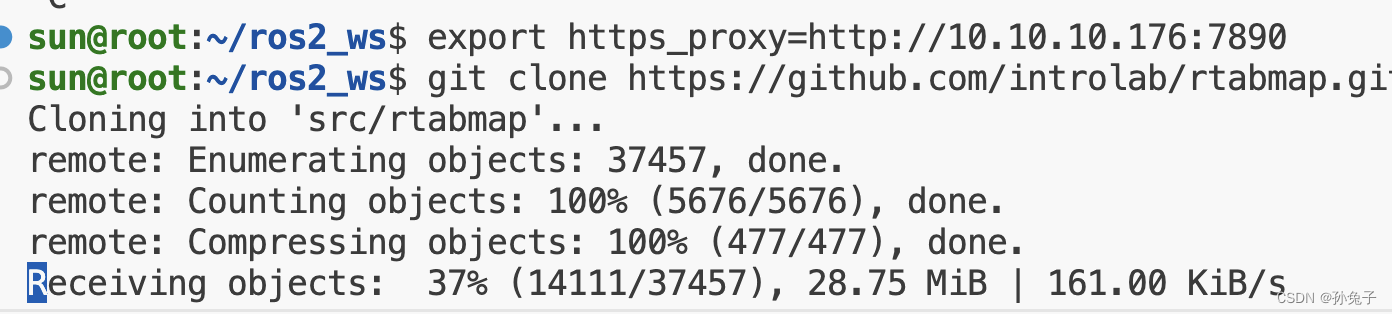
vscode 连接ubuntu git下载缓慢
在ubuntu20.04下载: git clone https://github.com/introlab/rtabmap.git src/rtabmap 挂掉情况 export https_proxyhttp://10.10.10.176:7890export http_proxyhttp://10.10.10.176:7890 其中 10.10.10.176是我本机的ip地址,7890是我的代理后几位 如…...

2731. 移动机器人
2731. 移动机器人有一些机器人分布在一条无限长的数轴上,他们初始坐标用一个下标从 0 开始的整数数组 nums 表示。当你给机器人下达命令时,它们以每秒钟一单位的速度开始移动。 给你一个字符串 s ,每个字符按顺序分别表示每个机器人移动的方…...

小程序实现人脸识别功能
调用api wx.startFacialRecognitionVerify 第一步: // 修改方法expertUpdate() {wx.startFacialRecognitionVerify({name: _this.registerForm.realName, //身份证名称idCardNumber: _this.registerForm.idCard, //身份证号码checkAliveType: 1, //屏幕闪烁(人脸核验的交互…...

【】javax.crypto.IllegalBlockSizeException: Input length not multiple of 8 bytes
问题描述 jdk版本:8 用DES进行加解密,其中转换模式为“DES/CBC/NoPadding”,要加密的明文为 “密码学浅析”,执行加密操作,报如下错误 Exception in thread "main" javax.crypto.IllegalBlockSizeExcepti…...
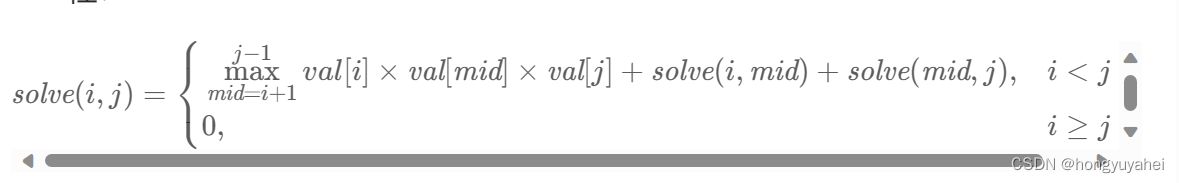
312.戳气球
将戳气球转换到添加气球,记忆搜索slove(i,j):在开区间(i,j)全部填满气球得到的最多硬币数,两端val[i]、val[j] class Solution { public:vector<vector<int>> ans;vector<int> val;int slove(int left,int right){if(left&…...

get_trade_detail_data函数使用
查阅股票持仓情况 positions get_trade_detail_data(‘8000000213’, ‘stock’, ‘position’) for dt in positions: print(f’股票代码: {dt.m_strInstrumentID}, 市场类型: {dt.m_strExchangeID}, 证券名称: {dt.m_strInstrumentName}, 持仓量: {dt.m_nVolume}, 可用数量:…...
【融合ChatGPT等AI模型】Python-GEE遥感云大数据分析、管理与可视化及多领域案例实践应用
目录 第一章 理论基础 第二章 开发环境搭建 第三章 遥感大数据处理基础与ChatGPT等AI模型交互 第四章 典型案例操作实践 第五章 输入输出及数据资产高效管理 第六章 云端数据论文出版级可视化 更多应用 随着航空、航天、近地空间等多个遥感平台的不断发展,近…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...
)
CentOS 8.5最小化安装后,这5个必做的安全与效率优化设置(附一键脚本)
CentOS 8.5最小化安装后的5个必做安全与效率优化刚完成CentOS 8.5最小化安装的系统就像一张白纸——干净但缺乏生产力。作为运维老手,我见过太多人跳过基础优化直接部署应用,结果在后续使用中频繁遇到权限混乱、软件安装慢、SSH爆破等问题。本文将分享我…...

2026这6款神级降AIGC平台大公开,一键让AIGC率直逼绝对安全线!
步入 2026 年,学术圈的风向早已不是从前的模样。曾经大家还在为查重率发愁,如今却陷入了更棘手的困境——如何在不破坏论文专业性的前提下,彻底消除 AI 痕迹?随着 AIGC 检测技术不断进化,高校对论文的审核标准也愈发严…...