力扣第501题 二叉树的众数 c++ (暴力 加 双指针优化)
题目
501. 二叉搜索树中的众数
简单
相关标签
树 深度优先搜索 二叉搜索树 二叉树
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
假定 BST 满足如下定义:
- 结点左子树中所含节点的值 小于等于 当前节点的值
- 结点右子树中所含节点的值 大于等于 当前节点的值
- 左子树和右子树都是二叉搜索树
示例 1:
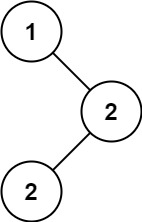
输入:root = [1,null,2,2] 输出:[2]
示例 2:
输入:root = [0] 输出:[0]
提示:
- 树中节点的数目在范围
[1, 104]内 -105 <= Node.val <= 105
进阶:你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
思路和解题方法一(暴力)
- 定义一个私有函数
searchBST,用于前序遍历二叉搜索树,并统计每个元素的频率。函数参数包括当前节点指针cur和存储元素频率的unordered_mapmap。- 在
searchBST函数中,如果当前节点为空,则直接返回;否则,对当前节点的值进行统计,将当前节点的值作为map的键,并将对应的值加1,表示该元素出现的频率。- 递归调用
searchBST函数,传入当前节点的左子节点和map,再传入当前节点的右子节点和map,实现前序遍历。- 定义一个静态成员函数
cmp,用于比较两个pair类型的元素,按照频率降序排列。在排序时使用此比较函数。- 在
findMode函数中,首先创建一个空的unordered_map类型的map,用于存储元素及其频率。- 如果输入的根节点为空,直接返回空的结果数组。
- 调用
searchBST函数,传入根节点和map,统计二叉搜索树中每个元素的频率。- 将
map转化为vector类型,并使用sort函数对vector进行排序,排序方式为按照元素的频率降序排列。- 创建一个空的结果数组
result,将排序后的第一个元素的键(也就是出现频率最高的元素)添加到result中。- 遍历排序后的vector,从第二个元素开始,如果其频率和第一个元素的频率相同,则将其键添加到
result中;否则结束遍历。- 返回结果数组
result。
复杂度
时间复杂度:
O(n logn)
时间复杂度:
- 前序遍历二叉树的时间复杂度为 O(n),其中 n 是二叉树的节点数。
- 构建哈希表的过程中,对每个节点进行插入操作的平均时间复杂度为 O(1)。因此构建哈希表的时间复杂度也是 O(n)。
- 对哈希表进行排序的时间复杂度为 O(nlogn)。
- 综上所述,算法的时间复杂度为 O(n) + O(n) + O(nlogn) = O(nlogn)。
空间复杂度
O(n)
空间复杂度:
- 使用了一个哈希表来存储元素及其频率,哈希表的空间复杂度是 O(n)。
- 将哈希表转换成了向量,空间复杂度仍然是 O(n)。
- 保存结果的向量,最多可能存储所有节点的值,因此空间复杂度也是 O(n)。
- 综上所述,算法的空间复杂度为 O(n)。
c++ 代码
class Solution {
private:// 前序遍历二叉搜索树,统计每个元素的频率void searchBST(TreeNode* cur, unordered_map<int, int>& map) {if (cur == NULL) return ;map[cur->val]++; // 统计元素频率searchBST(cur->left, map); // 遍历左子树searchBST(cur->right, map); // 遍历右子树return ;}// 静态成员函数,用于比较两个pair类型元素,按照频率降序排列static bool cmp(const pair<int, int>& a, const pair<int, int>& b) {return a.second > b.second;}
public:vector<int> findMode(TreeNode* root) {unordered_map<int, int> map; // 存储元素及其频率的map,key为元素,value为频率vector<int> result; // 结果数组if (root == NULL) return result; // 根节点为空,直接返回空结果数组searchBST(root, map); // 统计二叉搜索树中每个元素的频率vector<pair<int, int>> vec(map.begin(), map.end()); // 将map转换为vectorsort(vec.begin(), vec.end(), cmp); // 按照频率降序排列result.push_back(vec[0].first); // 将频率最高的元素添加到结果数组中for (int i = 1; i < vec.size(); i++) {// 遍历排序后的vector,如果元素频率与第一个元素的频率相同,则添加到结果数组中;否则结束遍历if (vec[i].second == vec[0].second) result.push_back(vec[i].first);else break;}return result; // 返回结果数组}
};
思路和解题方法二(双指针 加 时时优化)
- 使用了一个全局变量
maxCount来记录最大频率,使用count来统计当前节点值出现的频率。同时,引入了一个pre变量来记录前一个访问的节点,以便比较当前节点与前一个节点的值是否相同。- 函数
searchBST是进行中序遍历的辅助函数,通过递归遍历左子树、处理当前节点、递归遍历右子树的顺序进行搜索。在处理当前节点时,首先判断当前节点值与前一个节点值是否相同,若相同则将count增加 1,否则将count重置为 1。然后,根据count的大小与maxCount进行比较,并更新maxCount和result。如果count与maxCount相同,说明当前节点值出现的频率与最大频率相同,将其加入result中。如果count大于maxCount,则更新maxCount并清空result,将当前节点值放入result中。- 在
findMode函数中,初始化各个变量,然后调用searchBST开始搜索,并返回结果数组result。
复杂度
时间复杂度:
O(n)
时间复杂度是O(n),其中n是二叉搜索树中的节点数。因为我们需要遍历所有的节点来统计它们的频率。
空间复杂度
O(1)
不利用额外空间
c++ 代码
class Solution {
private:int maxCount = 0; // 最大频率int count = 0; // 统计频率TreeNode* pre = NULL; // 前一个节点vector<int> result; // 存储结果的向量// 中序遍历二叉搜索树,搜索出现频率最高的节点值void searchBST(TreeNode* cur) {if (cur == NULL) return; // 递归终止条件,当前节点为空searchBST(cur->left); // 左子树// 统计频率if (pre == NULL) { // 第一个节点count = 1;} else if (pre->val == cur->val) { // 与前一个节点数值相同count++;} else { // 与前一个节点数值不同count = 1;}pre = cur; // 更新上一个节点if (count == maxCount) { // 如果和最大频率相同,将节点值放进result中result.push_back(cur->val);}if (count > maxCount) { // 如果频率大于最大频率maxCount = count; // 更新最大频率result.clear(); // 清空result,之前result中的元素都无效了result.push_back(cur->val);}searchBST(cur->right); // 右子树return ;}public:vector<int> findMode(TreeNode* root) {count = 0;maxCount = 0;pre = NULL; // 初始化前一个节点为空result.clear(); // 清空result向量searchBST(root); // 调用中序遍历函数搜索出现频率最高的节点值return result; // 返回结果向量}
};
觉得有用的话可以点点赞,支持一下。
如果愿意的话关注一下。会对你有更多的帮助。
每天都会不定时更新哦 >人< 。
相关文章:
力扣第501题 二叉树的众数 c++ (暴力 加 双指针优化)
题目 501. 二叉搜索树中的众数 简单 相关标签 树 深度优先搜索 二叉搜索树 二叉树 给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。 …...

MARKDOWN 文档图片编码嵌入方案
#1 写在前面 开始写这篇文章时,标题怎么定困扰我良久,缘于不晓得如何给接下来要做的事定个简单明了的标题:在📱终端只能纯文本交互的前提下,优雅展示 markdown 文档中的图片。这也许比问题本身还要棘手😄。…...

KubeVela可持续测试应用部署之Mock基础设施
Mock接口是我们常用的功能测试方案,有时候依赖的接口未开发完成或者依赖的第三方接口不提供测试环境等,只有Mock才能跑通流程。 我们基于KubeVela开发的云原生应用交付平台,提供如初始化基础设施导入、中间件部署共用基础设施等相关能力的测试,需要依赖基础设施。虽然terr…...

代理IP、Socks5代理与网络工程:解析技术世界的无限可能
在当今数字化的世界中,网络工程师不仅需要保证网络的稳定性,还要应对多样的技术挑战。代理IP和Socks5代理技术已经成为网络工程师工具箱中不可或缺的利器,在跨界电商、爬虫、出海、网络安全、游戏等领域发挥关键作用。本文将深入探讨这两项技…...

OpenCV级联分类器识别车辆实践笔记
1. OpenCV 级联分类器的基本原理 基于Haar特征的级联分类器的目标检测是Paul Viola和Michael Jones在2001年的论文中提出的一种有效的目标检测方法。这是一种基于机器学习的方法,从大量的正面和负面图像中训练级联函数。然后用它来检测其他图像中的物体。 Haar特征…...
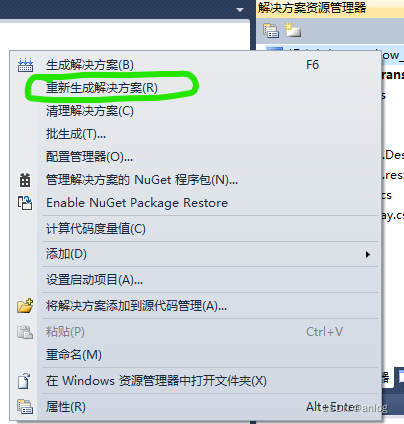
VS编译的时候不生成Release文件夹
方法描述: Build>Configuration Manager>Release 编译》配置管理》选择发布版本 再编译就有了 具体操作过程 第一步: 第二步: 第三步: 特此记录 anlog 2023年10月12日...
14.2 Socket 反向远程命令行
在本节,我们将继续深入探讨套接字通信技术,并介绍一种常见的用法,实现反向远程命令执行功能。对于安全从业者而言,经常需要在远程主机上执行命令并获取执行结果。本节将介绍如何利用 _popen() 函数来启动命令行进程,并…...
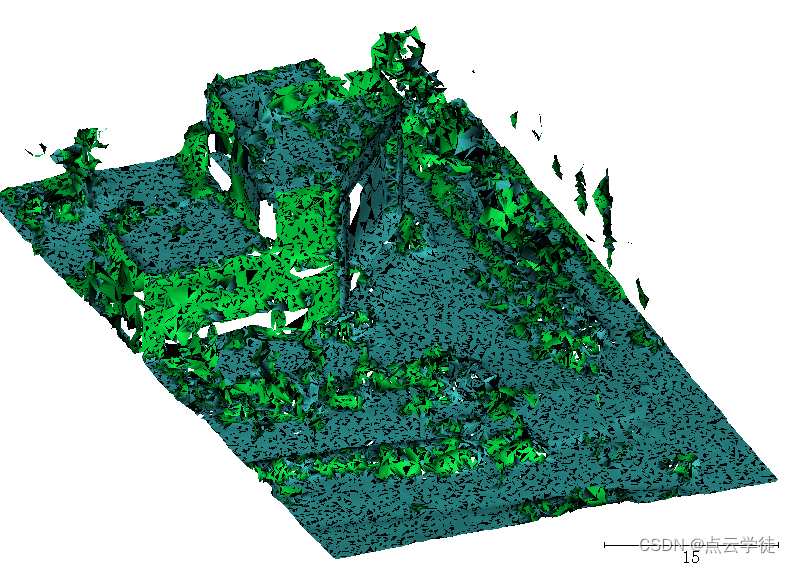
PCL点云处理之点云重建为Mesh模型并保存到PLY文件 ---方法二 (二百一十一)
PCL点云处理之点云重建为Mesh模型并保存到PLY文件 ---方法二 (二百一十一) 一、算法介绍二、算法实现1.代码2.效果一、算法介绍 离散点云重建为mesh网格模型,并保存到PLY文件中,用于其他软件打开查看,代码非常简短,复制粘贴即可迅速上手使用,具体参数根据自己的点云数据…...
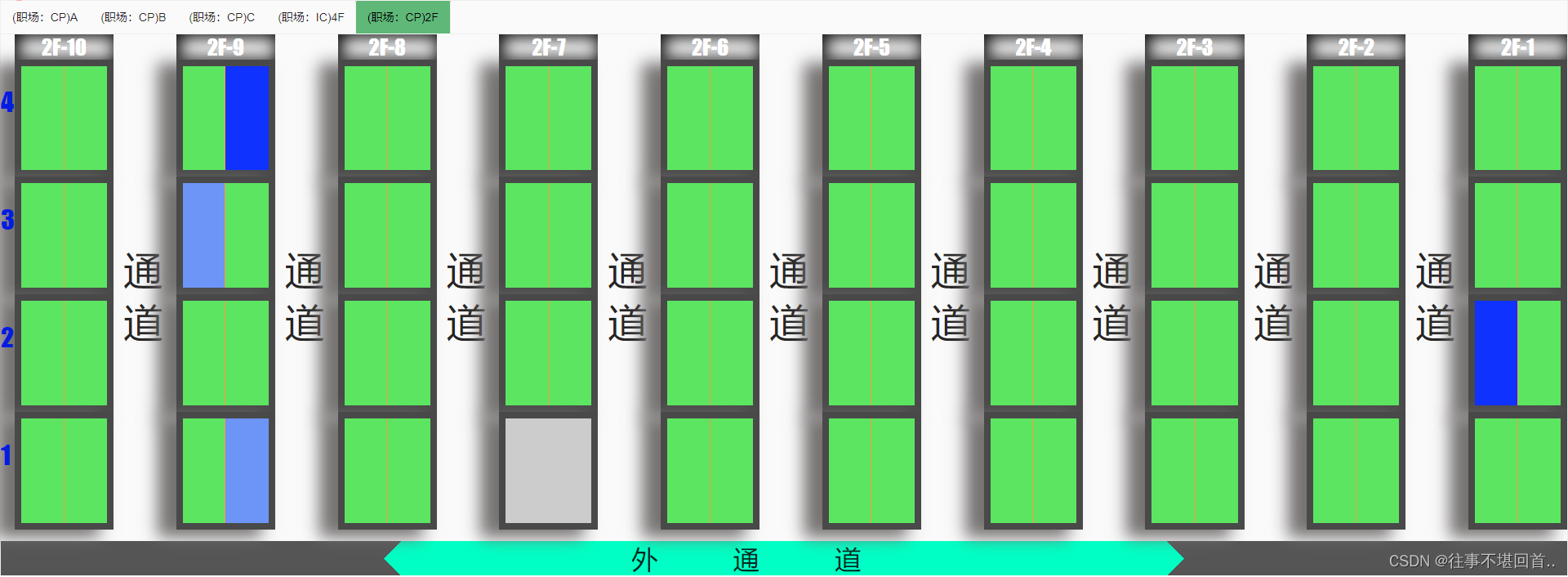
CSS 中::after的妙用(实现在margin中显示内容)
效果图如下: 背景: 如上图,之前只是当纯的写一个参考货架平面图,用作物料系统的在库状态可视化,当完成页面body分成10等份时,货架之间需要有通道,为了实现实际的样式,我给每个等份都…...
SentenceTransformer使用多GPU加速向量化
文章目录 前言代码 前言 当我们需要对大规模的数据向量化以存到向量数据库中时,且服务器上有多个GPU可以支配,我们希望同时利用所有的GPU来并行这一过程,加速向量化。 代码 就几行代码,不废话了 from sentence_transformers i…...

架构师-软件工程习题选择题
架构师-软件工程习题选择题 真题案例题 真题 c 瀑布模型:针对软件需求明确的情况,将前一个阶段做完,才能开始下一个阶段 原型模型:针对需求不明确的情况,快速搭建出系统原型,然后根据系统原型和客户确认需求…...

springboot单独在指定地方输出sql
一般线上项目都是将日志进行关闭,因为mybatis日志打印,时间长了,会占用大量的内存,如果我想在我指定的地方进行打印sql情况,怎么玩呢! 下面这个场景: 某天线上的项目出bug了,日志打印…...
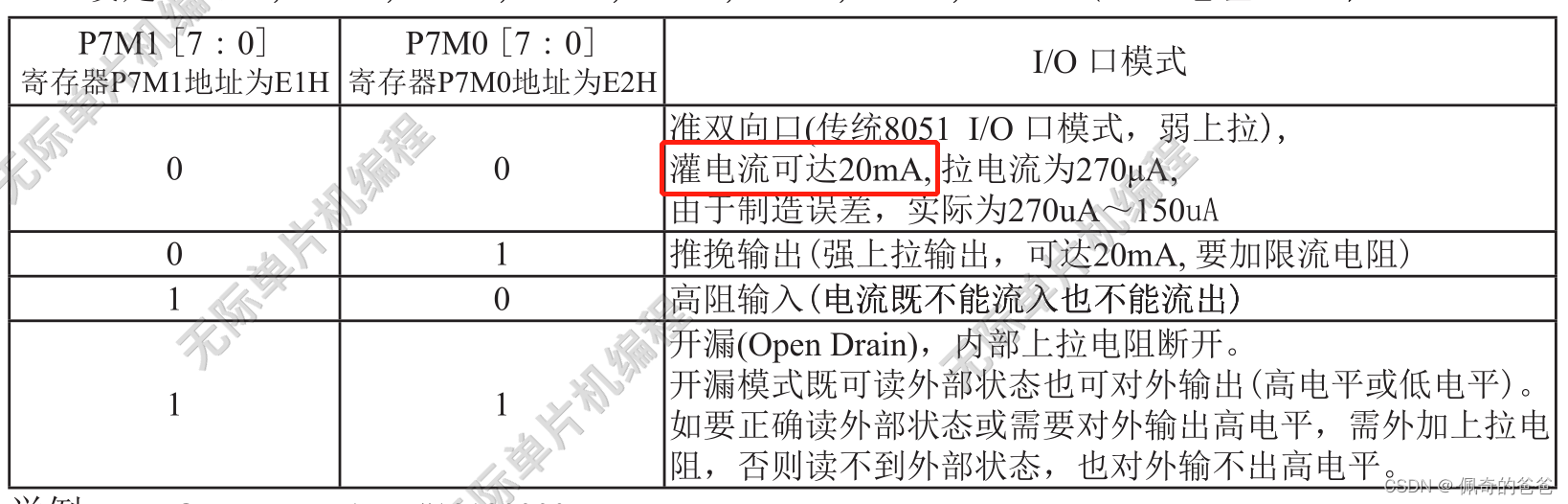
gpio内部结构(一)
一,GPIO内部结构 1,保护二极管 * 引脚内部加上这两个保护二级管可以防止引脚外部过高或过低的电压输入。 * 当引脚电压高于 VDD_FT 或 VDD 时,上方的二极管导通吸收这个高电压。 * 当引脚电压低于 VSS 时,下方的二极管导通&…...

【C++14保姆级教程】变量模板,Labmda泛型
文章目录 前言一、变量模板(Variable Templates)1.1 变量模板是什么1.2 泛型大概使用1.3 示例代码11.4 示例代码21.5 示例代码3 二、Lambda泛型(Lambda Generics)2.1 Lambda表达式泛型是什么?2.2 函数原型怎么写&#…...

LLM - 旋转位置编码 RoPE 代码详解
目录 一.引言 二.RoPE 理论 1.RoPE 矩阵形式 2.RoPE 图例形式 3.RoPE 实践分析 三.RoPE 代码分析 1.源码获取 2.源码分析 3.rotary_emb 3.1 __init__ 3.2 forward 4.apply_rotary_pos_emb 4.1 rotate_half 4.2 apply_rotary_pos_emb 四.RoPE 代码实现 1.Q/K/V …...

Vue之VueX知识探索(一起了解关于VueX的新世界)
目录 前言 一、VueX简介 1. 什么是VueX 2. VueX的作用及重要性 3. VueX的应用场景 二、VueX的使用准备工作 1. 下载安装VueX 2. vuex获取值以及改变值 2.1 创建所需示例 2.2 将创建好的.vue文件页面显示 2.3 创建VueX的相关文件 2.4 配置VueX四个js文件 2.5 加载到vue示…...
提升吃鸡战斗力,分享顶级作战干货!
大家好!作为一名吃鸡玩家,你是否也希望提高自己的游戏战斗力?在这里,我将为大家分享一些顶级游戏作战干货,以及方便吃鸡作图和查询装备皮肤库存的实用工具。 首先,让我们提到绝地求生作图工具推荐。通过使用…...

【rust】cargo的概念和使用方法
啥是cargo 包管理器 cargo 提供了一系列的工具,从项目的建立、构建到测试、运行直至部署,为 Rust 项目的管理提供尽可能完整的手段,与 Rust 语言及其编译器 rustc 紧密结合。 创建项目 使用cargo创建一个项目: $ cargo new wo…...

MySQL数据库——SQL优化(2)-order by 优化、group by 优化
目录 order by 优化 概述 测试 优化原则 group by 优化 测试 优化原则 order by 优化 概述 MySQL的排序,有两种方式: Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbuffer中完成排…...
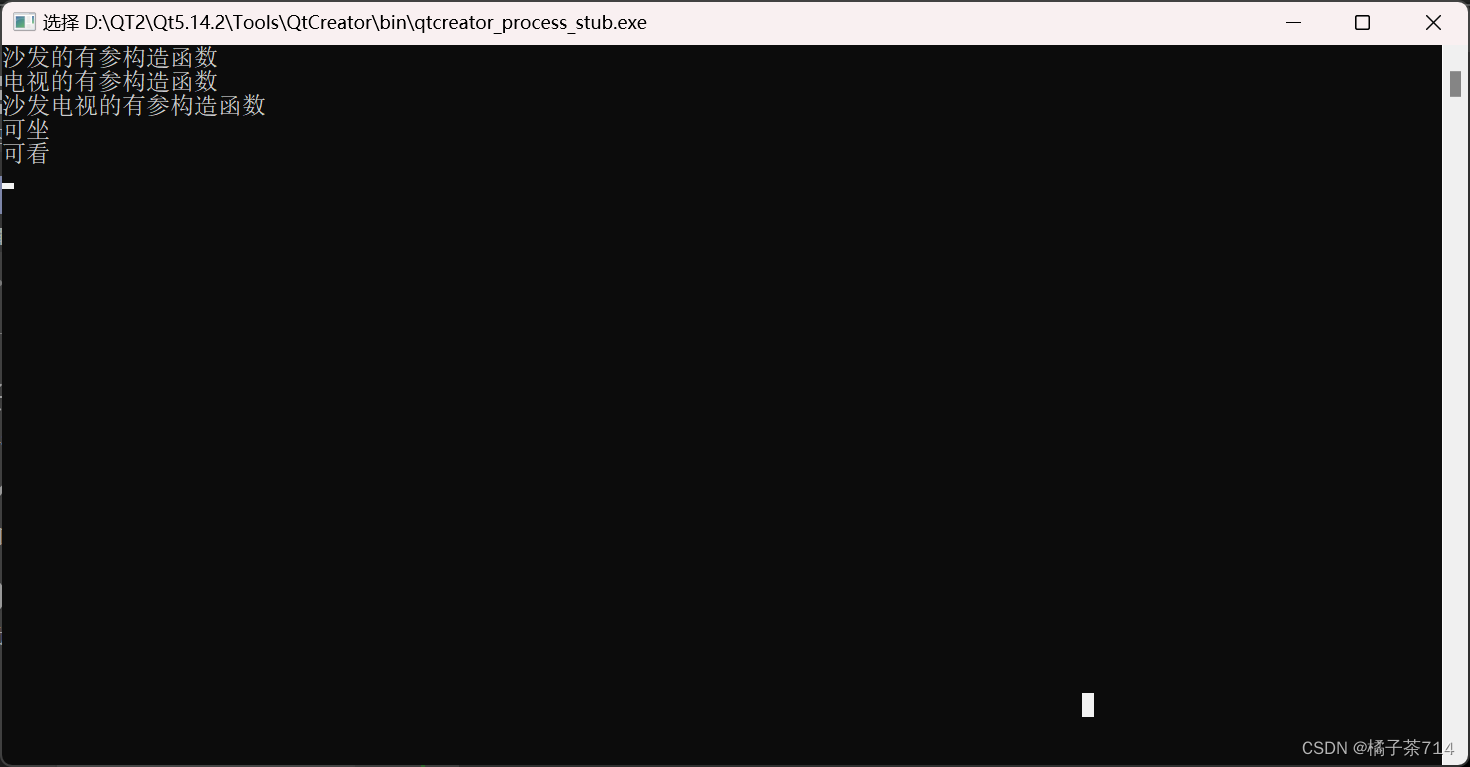
C++DAY43
#include <iostream>using namespace std;//封装 沙发 类 class Sofa { private:string living; public:Sofa(){cout << "沙发的无参构造函数" << endl;}Sofa(string l):living(l){cout << "沙发的有参构造函数" << endl;}v…...

No.1085 ‘基于S7-200 PLC和组态王的邮件分拣控制系统设计
No.1085 基于S7-200 PLC和组态王的邮件分拣控制系统设计快递分拣中心里,传送带上的包裹像流水般划过,机械臂精准抓取分类——这种工业自动化场景的实现,离不开PLC和上位机的黄金组合。今天咱们就以西门子S7-200 PLC搭配组态王6.55,…...

时间放大器:从亚稳态到数字训练式的硬件实现解析
1. 时间放大器的核心价值与应用场景 时间放大器(Time Amplifier)这个名词听起来有点科幻,但它的原理其实非常接地气。想象一下你用两根手指同时按下钢琴的两个琴键,如果两次按键的时间差只有几毫秒,普通人耳朵可能分辨…...

嵌入式工程师的中年危机与转型策略
1. 嵌入式工程师的中年危机:一个行业的缩影44岁的梧桐,一位拥有21年嵌入式开发经验的资深架构师,在2023年的寒冬里收到了人生第一封解约通知书。这个场景让我想起公司上周的招聘会——38岁的候选人简历被默默放进了"待定"文件夹&am…...

宿主机与虚拟机网络配置打通
Kali 虚拟机网络配置笔记 一、基础网络模式 1. 桥接模式 (Bridged) 目的:让虚拟机加入物理局域网配置: 选择物理网卡(非VMnet1/VMnet8)启用"复制物理网络连接状态"(推荐笔记本用户) 结果…...
一)
大一C语言期末必考|程序结构+流程控制(详解+例题+易错点)一
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

嵌入式滚动平均滤波库:SimpleSmooth轻量级实现
1. 项目概述 SimpleSmooth 是一个专为嵌入式系统设计的轻量级滚动平均值计算库,其核心目标是为模拟信号采集(如 ADC 读数)提供低开销、无动态内存分配、零依赖的数字滤波能力。该库并非从零构建,而是对 Arduino 官方示例中经典平…...
)
TikTok直播卡顿、发布失败?可能是你的动态IP池没调好(附IPIPD轮询策略设置)
TikTok直播与内容发布的动态IP优化实战指南 直播突然中断、视频上传失败——这些看似随机的网络问题,往往源于动态IP池的配置不当。许多运营者投入大量成本获取优质IP资源,却因参数设置不合理导致实际效果大打折扣。本文将深入解析TikTok平台的风控机制与…...

论文降重降AI难?自带双功能黑科技的实用工具盘点
论文降重和消除AI生成痕迹是很多创作者面临的双重难题,选对工具能节省大量时间精力。下面整理了几款自带降AIGC率功能的实用工具,覆盖中文、英文、应急、轻量优化等不同使用场景,附实际使用效果与核心特点,帮你快速找到适配需求的…...

2026届学术党必备的降重复率平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 正在逐渐发生改变的是学术写作模式,借助的是人工智能论文工具,它的核…...

基于MPC的四旋翼高度动力学及X-Y平面位置控制设计的实践与仿真
基于MPC的四旋翼高度动力学以及x-y平面位置控制设计 简介:本项目侧重于MPC控制器设计,用于控制四旋翼的高度动力学以及x-y平面位置 就方向动力学而言,使用了定制的离散PID(DPID)控制器 该项目在MATLAB 2022b中进行了完全编码和仿真 此外&…...