竞赛选题 深度学习 植物识别算法系统
文章目录
- 0 前言
- 2 相关技术
- 2.1 VGG-Net模型
- 2.2 VGG-Net在植物识别的优势
- (1) 卷积核,池化核大小固定
- (2) 特征提取更全面
- (3) 网络训练误差收敛速度较快
- 3 VGG-Net的搭建
- 3.1 Tornado简介
- (1) 优势
- (2) 关键代码
- 4 Inception V3 神经网络
- 4.1 网络结构
- 5 开始训练
- 5.1 数据集
- 5.2 关键代码
- 5.3 模型预测
- 6 效果展示
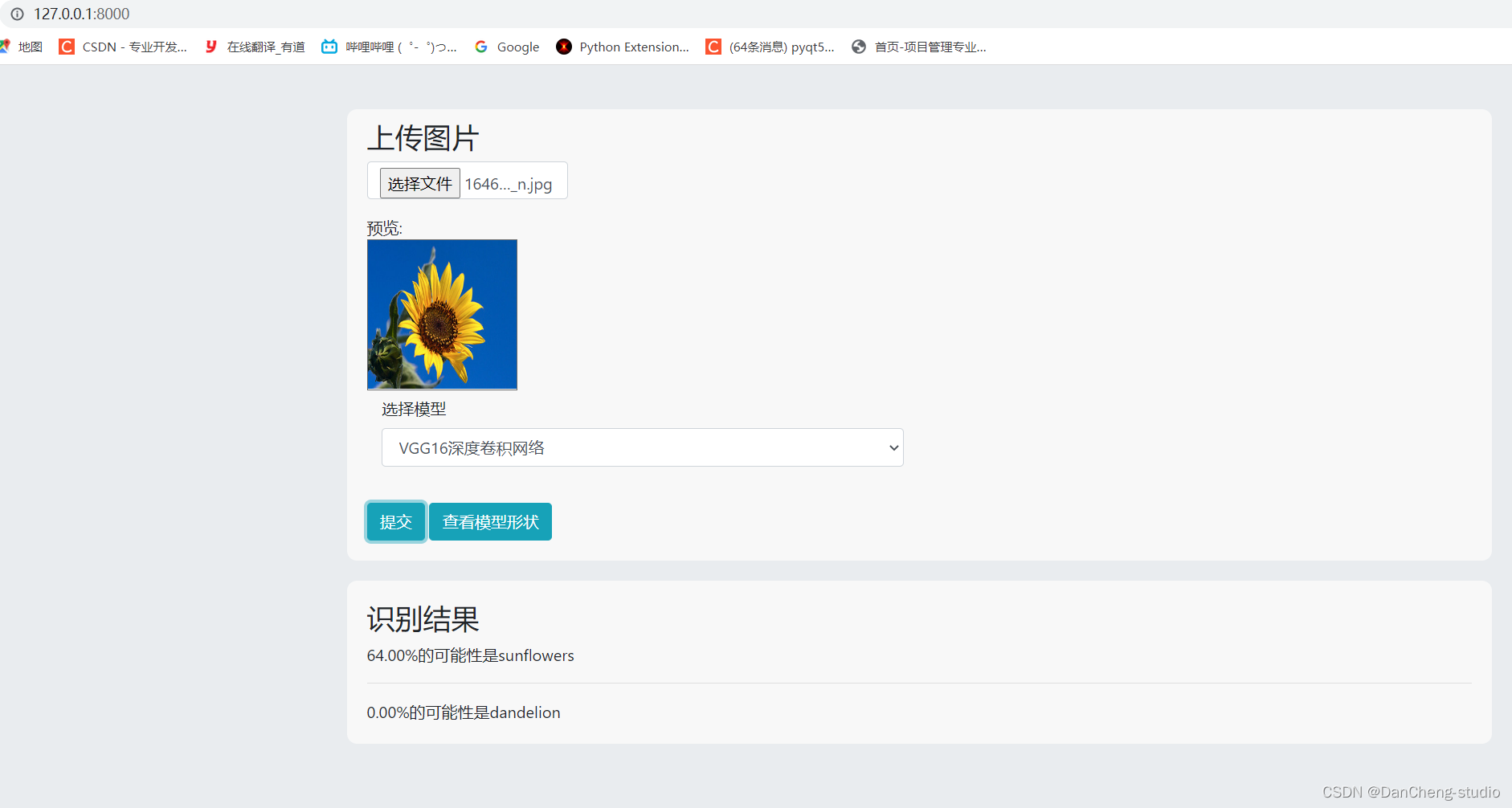
- 6.1 主页面展示
- 6.2 图片预测
- 6.3 三维模型可视化
- 7 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于深度学习的植物识别算法研究与实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
2 相关技术
2.1 VGG-Net模型
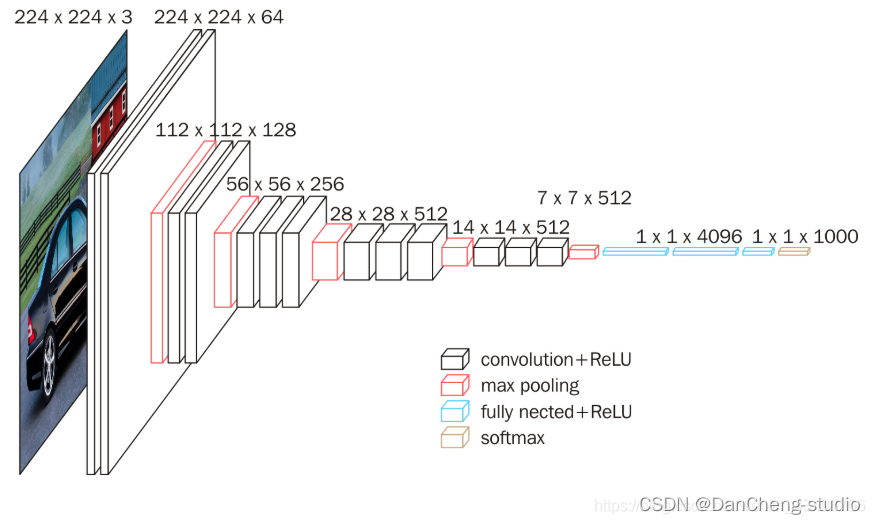
Google DeepMind公司研究员与牛津大学计算机视觉组在2014年共同研发出了一种全新的卷积神经网络–VGG-
Net。在同年举办的ILSVRC比赛中,该网络结构模型在分类项目中取得了十分出色的成绩,由于其简洁性和实用性,使得其在当时迅速,飞快地成为了最受欢迎的卷积神经网络模型。VGG-
Net卷积神经网络在近年来衍生出了A-
E七种不同的层次结构,本次研究使用其中的D结构,也就是VGG-16Net结构,该结构中包含了13个卷积层,5个池化层和3个全连接层。针对所有的卷积层,使用相同的5x5大小的卷积核,针对所有的池化层,使用相同的3x3大小的池化核。VGG-
Net结构如图所示。

2.2 VGG-Net在植物识别的优势
在针对植物识别问题上,VGG-Net有着一些相较于其他神经网络的优势,主要包括以下几点:
(1) 卷积核,池化核大小固定
网络中所有的卷积核大小固定为3x3,所有的池化核大小固定为5x5。这样在进行卷积和池化操作的时候,从数据中提取到的特征更加明显,同时在层与层的连接时,信息的丢失会更少,更加方便后续对于重要特征的提取和处理。
(2) 特征提取更全面
VGG-
Net网络模型中包含了13个卷积层。卷积层数目越多,对于特征的提取更加的全面。由于需要对于植物的姿态、颜色等进行判定,植物的特征较多,需要在提取时更加的全面,细致,才有可能得到一个更加准确的判定。VGG-
Net符合条件。
(3) 网络训练误差收敛速度较快
VGG-
Net网络在训练时收敛速度相对较快,能够较快地得到预期的结果。具有这一特点的原因有两个,一个是网络中每一个卷积层和池化层中的卷积核大小与池化核大小固定,另一个就是对于各个隐藏层的参数初始化方法使用专门针对ReLU激活函数的Kaiming正态初始化方法。
3 VGG-Net的搭建
本次研究基于Pytorch深度学习框架进行网络的搭建,利用模块化的设计思想,构建一个类,来对于整个的网络进行结构上的封装。这样搭建的好处是可以隐藏实现的内部细节,提高代码的安全性,增强代码的复用效率,并且对于一些方法,通过在内部集成,可以方便之后对于其中方法的调用,提升代码的简洁性。
在网络搭建完成后,将数据集传入网络中进行训练,经过一段时间后即可得到植物识别的分类识别结果。
3.1 Tornado简介
Tornado全称Tornado Web
Server,是一个用Python语言写成的Web服务器兼Web应用框架,由FriendFeed公司在自己的网站FriendFeed中使用,被Facebook收购以后框架在2009年9月以开源软件形式开放给大众。
(1) 优势
- 轻量级web框架
- 异步非阻塞IO处理方式
- 出色的抗负载能力
- 优异的处理性能,不依赖多进程/多线程,一定程度上解决C10K问题
- WSGI全栈替代产品,推荐同时使用其web框架和HTTP服务器
(2) 关键代码
class MainHandler(tornado.web.RequestHandler):def get(self):self.render("index.html")def post(self):keras.backend.clear_session()img = Image.open(BytesIO(self.request.files['image'][0]['body']))img = imgb_img = Image.new('RGB', (224, 224), (255, 255, 255))size = img.sizeif size[0] >= size[1]:rate = 224 / size[0]new_size = (224, int(size[1] * rate))img = img.resize(new_size, Image.ANTIALIAS).convert("RGB")b_img.paste(img, (0, random.randint(0, 224 - new_size[1])))else:rate = 224 / size[1]new_size = (int(size[0] * rate), 224)img = img.resize(new_size, Image.ANTIALIAS).convert("RGB")b_img.paste(img, (random.randint(0, 224 - new_size[0]), 0))if self.get_argument("method", "mymodel") == "VGG16":Model = load_model("VGG16.h5")else:Model = load_model("InceptionV3.h5")data = orc_img(Model,b_img)self.write(json.dumps({"code": 200, "data": data}))def make_app():template_path = "templates/"static_path = "./static/"return tornado.web.Application([(r"/", MainHandler),], template_path=template_path, static_path=static_path, debug=True)def run_server(port=8000):tornado.options.parse_command_line()app = make_app()app.listen(port)print("\n服务已启动 请打开 http://127.0.0.1:8000 ")tornado.ioloop.IOLoop.current().start()4 Inception V3 神经网络
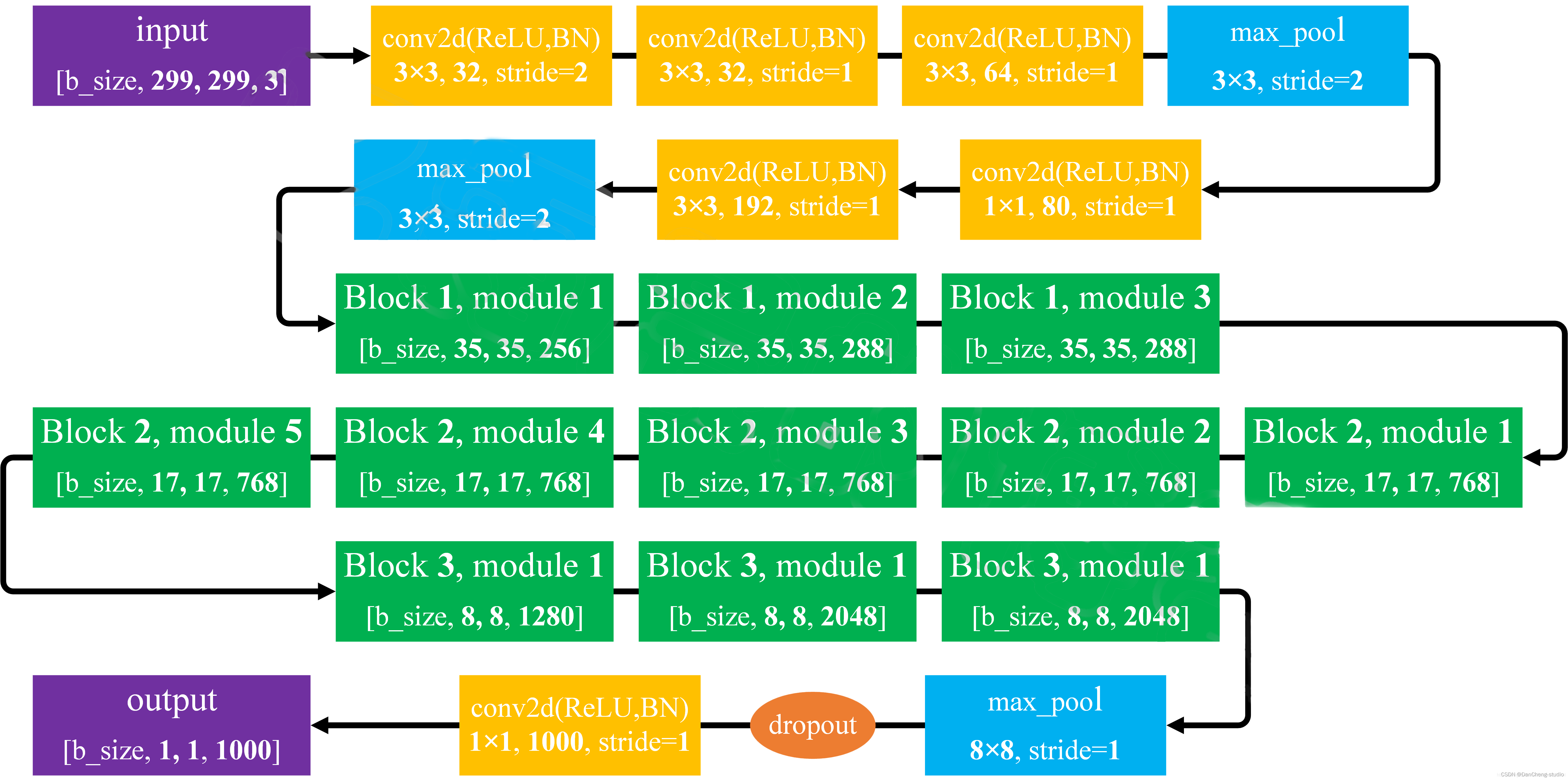
GoogLeNet对网络中的传统卷积层进行了修改,提出了被称为 Inception
的结构,用于增加网络深度和宽度,提高深度神经网络性能。从Inception V1到Inception
V4有4个更新版本,每一版的网络在原来的基础上进行改进,提高网络性能。
4.1 网络结构
inception结构的作用(inception的结构和作用)
作用:代替人工确定卷积层中过滤器的类型或者确定是否需要创建卷积层或者池化层。即:不需要人为决定使用什么过滤器,是否需要创建池化层,由网络自己学习决定这些参数,可以给网络添加所有可能值,将输入连接起来,网络自己学习需要它需要什么样的参数。
inception主要思想
用密集成分来近似最优的局部稀疏解(如上图)
- 采用不同大小的卷积核意味着有不同大小的感受野,最后的拼接意味着不同尺度特征的融合。
- 之所以卷积核大小采用1x1、3x3和5x5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding = 0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起。
- 很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
- 网络越到后面特征越抽象,且每个特征涉及的感受野也更大,随着层数的增加,3x3和5x5卷积的比例也要增加。
- 最终版inception,加入了1x1 conv来降低feature map厚度。
5 开始训练
5.1 数据集
训练图像按照如下方式进行分类,共分为9文件夹。
5.2 关键代码
from keras.utils import Sequenceimport mathclass SequenceData(Sequence):def __init__(self, batch_size, target_size, data):# 初始化所需的参数self.batch_size = batch_sizeself.target_size = target_sizeself.x_filenames = datadef __len__(self):# 让代码知道这个序列的长度num_imgs = len(self.x_filenames)return math.ceil(num_imgs / self.batch_size)def __getitem__(self, idx):# 迭代器部分batch_x = self.x_filenames[idx * self.batch_size: (idx + 1) * self.batch_size]imgs = []y = []for x in batch_x:img = Image.open(x)b_img = Image.new('RGB', self.target_size, (255, 255, 255))size = img.sizeif size[0] >= size[1]:rate = self.target_size[0] / size[0]new_size = (self.target_size[0], int(size[1] * rate))img = img.resize(new_size, Image.ANTIALIAS).convert("RGB")b_img.paste(img, (0, random.randint(0, self.target_size[0] - new_size[1])))else:rate = self.target_size[0] / size[1]new_size = (int(size[0] * rate), self.target_size[0])img = img.resize(new_size, Image.ANTIALIAS).convert("RGB")b_img.paste(img, (random.randint(0, self.target_size[0] - new_size[0]), 0))img = b_imgif random.random() < 0.1:img = img.convert("L").convert("RGB")if random.random() < 0.2:img = img.rotate(random.randint(0, 20)) # 随机旋转一定角度if random.random() < 0.2:img = img.rotate(random.randint(340, 360)) # 随 旋转一定角度imgs.append(img.convert("RGB"))x_arrays = 1 - np.array([np.array(i) for i in imgs]).astype(float) / 255 # 读取一批图片batch_y = to_categorical(np.array([labels.index(x.split("/")[-2]) for x in batch_x]), len(labels))return x_arrays, batch_y
5.3 模型预测
利用我们训练好的 vgg16.h5 模型进行预测,相关代码如下:
def orc_img(model,image):img =np.array(image)img = np.array([1 - img.astype(float) / 255])predict = model.predict(img)index = predict.argmax()print("CNN预测", index)target = target_name[index]index2 = np.argsort(predict)[0][-2]target2 = target_name[index2]index3 = np.argsort(predict)[0][-3]target3 = target_name[index3]return {"target": target,"predict": "%.2f" % (float(list(predict)[0][index]) * 64),"target2": target2,"predict2": "%.2f" % (float(list(predict)[0][index2]) * 64),}
6 效果展示
6.1 主页面展示
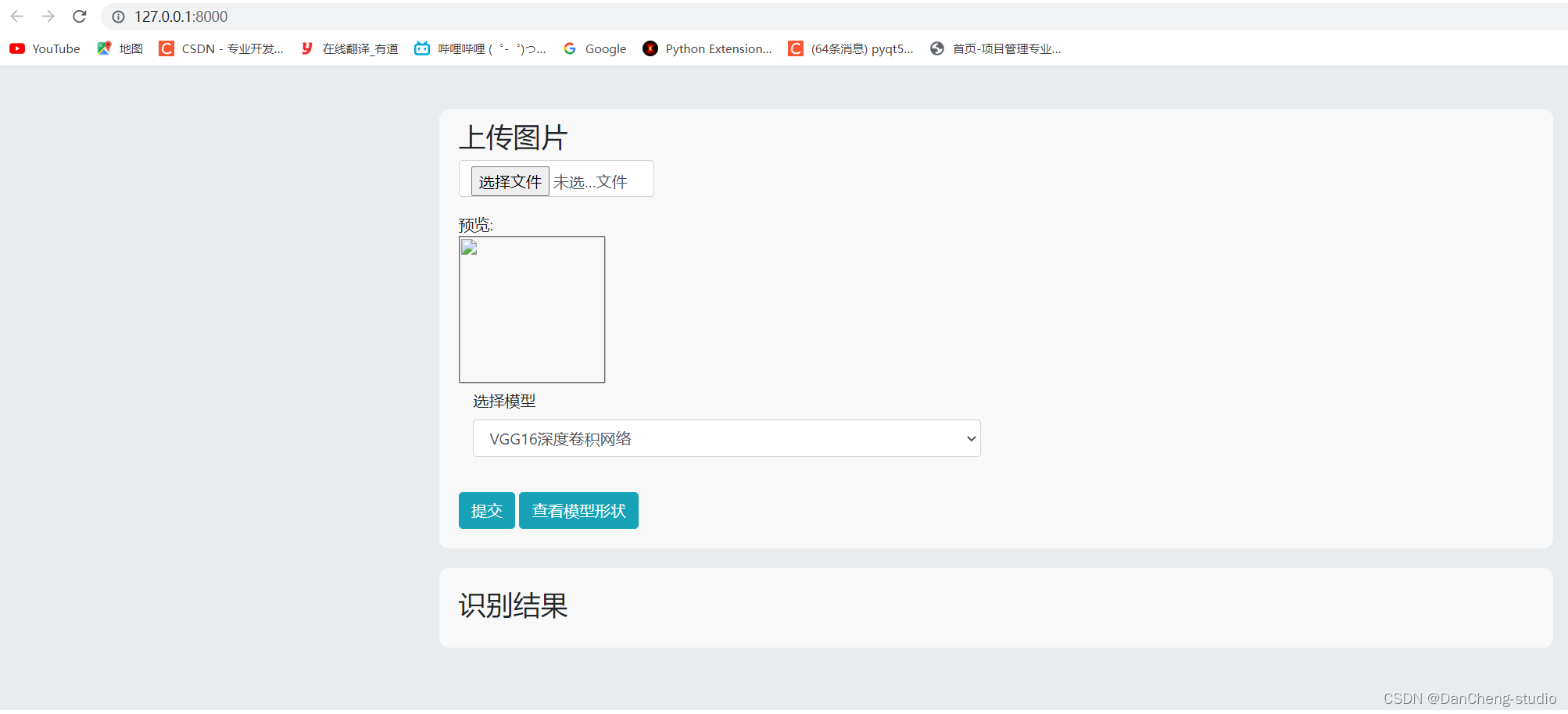
6.2 图片预测
6.3 三维模型可视化
学长在web页面上做了一个三维网络结构可视化功能,可以直观的看到网络模型结构



7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛选题 深度学习 植物识别算法系统
文章目录 0 前言2 相关技术2.1 VGG-Net模型2.2 VGG-Net在植物识别的优势(1) 卷积核,池化核大小固定(2) 特征提取更全面(3) 网络训练误差收敛速度较快 3 VGG-Net的搭建3.1 Tornado简介(1) 优势(2) 关键代码 4 Inception V3 神经网络4.1 网络结构 5 开始训练5.1 数据集…...
希尔贝壳受邀参加《人工智能开发平台通用能力要求 第4部分:大模型技术要求》标准第一次研讨会
随着大模型技术与经验的不断累积,该方向也逐渐从聚焦技术突破,到关注开发、部署、应用的全流程工程化落地。为完善人工智能平台标准体系建设,满足产业多样化需求,2023年9月7日,中国信通院云大所在线上召开《人工智能开…...
虹科方案 | AR助力仓储物流突破困境:规模化运营与成本节约
文章来源:虹科数字化AR 点击阅读原文:https://mp.weixin.qq.com/s/xis_I5orLb6RjgSokEhEOA 虹科方案一览 HongKe DigitalizationAR 当今的客户体验要求企业在人员、流程和产品之间实现全面的连接。为了提升整个组织的效率并提高盈利能力,物流…...

spring容器ioc和di
spring ioc 容器的创建 BeanFactory 接口提供了一种高级配置机制,能够管理任何类型的对象,它是SpringIoC容器标准化超接口! ApplicationContext 是 BeanFactory 的子接口。它扩展了以下功能: 更容易与 Spring 的 AOP 功能集成消…...

Maven 仓库地址
一、Maven 中央仓库地址 http://www.sonatype.org/nexus/http://mvnrepository.com/ (本人推荐仓库)http://repo1.maven.org/maven2 二、Maven 中央仓库地址大全 1、阿里中央仓库(首选推荐) <repository> <id>al…...
【2023研电赛】安谋科技企业命题特别奖:面向独居老人的智能居家监护系统
本文为2023年第十八届中国研究生电子设计竞赛安谋科技企业命题特别奖分享,参加极术社区的【有奖活动】分享2023研电赛作品扩大影响力,更有丰富电子礼品等你来领!,分享2023研电赛作品扩大影响力,更有丰富电子礼品等你来…...
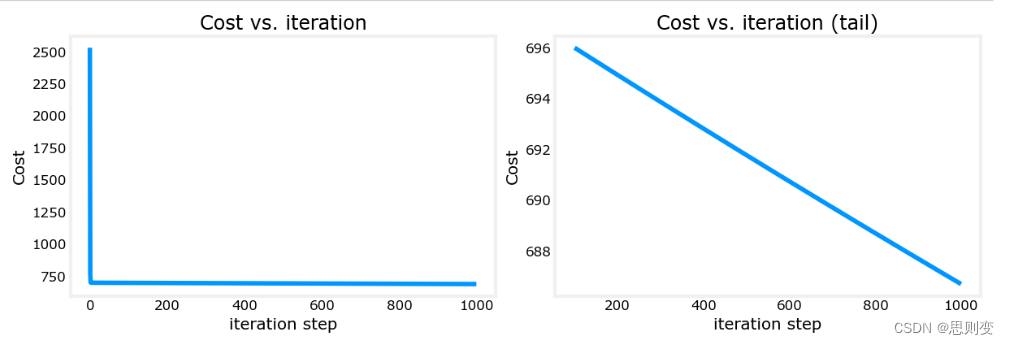
[Machine learning][Part4] 多维矩阵下的梯度下降线性预测模型的实现
目录 模型初始化信息: 模型实现: 多变量损失函数: 多变量梯度下降实现: 多变量梯度实现: 多变量梯度下降实现: 之前部分实现的梯度下降线性预测模型中的training example只有一个特征属性:…...

LCR 078. 合并 K 个升序链表
LCR 078. 合并 K 个升序链表 题目链接:LCR 078. 合并 K 个升序链表 代码如下: class Solution { public:ListNode* mergeKLists(vector<ListNode*>& lists) {ListNode *lsnullptr;for(int i0;i<lists.size();i){lsmergeList(ls,lists[i])…...

JVM面试题:(三)GC和垃圾回收算法
GC: 垃圾回收算法: GC最基础的算法有三种: 标记 -清除算法、复制算法、标记-压缩算法,我们常用的垃圾回收器一般 都采用分代收集算法。 标记 -清除算法,“标记-清除”(Mark-Sweep)算法,如它的…...
)
hive建表指定列分隔符为多字符分隔符实战(默认只支持单字符)
1、背景: 后端日志采集完成,清洗入hive表的过程中,发现字段之间的单一字符的分割符号已经不能满足列分割需求,因为字段值本身可能包含分隔符。所以列分隔符使用多个字符列分隔符迫在眉睫。 hive在建表时,通常使用ROW …...

android.app.RemoteServiceException: can‘t deliver broadcast
日常报错记录 android.app.RemoteServiceException: cant deliver broadcast W BroadcastQueue: Cant deliver broadcast to com.broadcast.test(pid 1769). Crashing it.E AndroidRuntime: FATAL EXCEPTION: main E AndroidRuntime: Process: com.broadcast.test, PID: 1769…...
信创办公–基于WPS的EXCEL最佳实践系列 (单元格与行列)
信创办公–基于WPS的EXCEL最佳实践系列 (单元格与行列) 目录 应用背景操作步骤1、插入和删除行和列2、合并单元格3、调整行高与列宽4、隐藏行与列5、修改单元格对齐和缩进6、更改字体7、使用格式刷8、设置单元格内的文本自动换行9、应用单元格样式10、插…...
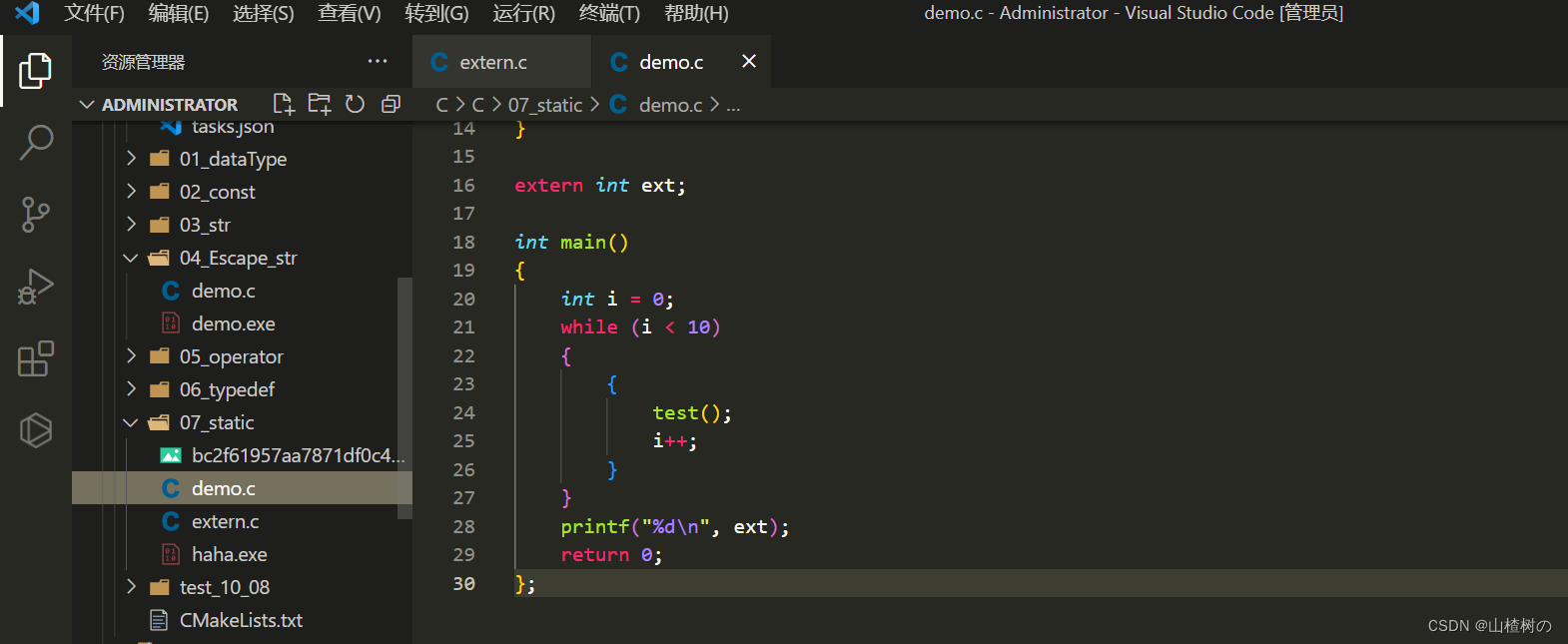
VsCode同时编译多个C文件
VsCode默认只能编译单个C文件,想要编译多个文件,需要额外进行配置 第一种方法 ——> 通过手动指定要编译的文件 g -g .\C文件1 .\C文件2 -o 编译后exe名称 例如我将demo.c和extern.c同时编译得到haha.exe g -g .\demo.c .\extern.c -o haha 第二种…...

Android绑定式服务
Github:https://github.com/MADMAX110/Odometer 启动式服务对于后台操作很合适,不过需要一个更有交互性的服务。 接下来构建这样一个应用: 1、创建一个绑定式服务的基本版本,名为OdometerService 我们要为它增加一个方法getDistance()&#x…...

系统韧性研究(1)| 何谓「系统韧性」?
过去十年,系统韧性作为一个关键问题被广泛讨论,在数据中心和云计算方面尤甚,同时它对赛博物理系统也至关重要,尽管该术语在该领域不太常用。大伙都希望自己的系统具有韧性,但这到底意味着什么?韧性与其他质…...

使用Perl脚本编写爬虫程序的一些技术问题解答
网络爬虫是一种强大的工具,用于从互联网上收集和提取数据。Perl 作为一种功能强大的脚本语言,提供了丰富的工具和库,使得编写的爬虫程序变得简单而灵活。在使用的过程中大家会遇到一些问题,本文将通过问答方式,解答一些…...

SAP内部转移价格(利润中心转移价格)的条件
SAP内部转移价格(利润中心转移价格) SAP内部转移价格(利润中心转移价格) SAP内部转移价格(利润中心转移价格)这个听了很多人说过,但是利润中心转移定价需要具备什么条件。没有找到具体的文档。…...

WRF如何批量输出文件添加或删除文件名后缀
1. 批量添加文件名后缀 #1----批量添加文件名后缀(.nc)。#指定wrfout文件所在的文件夹 path "/mnt/wtest1/"#列出路径path下所有的文件 file_names os.listdir(path) #遍历在path路径下所有以wrfout_d01开头的文件,在os.path…...
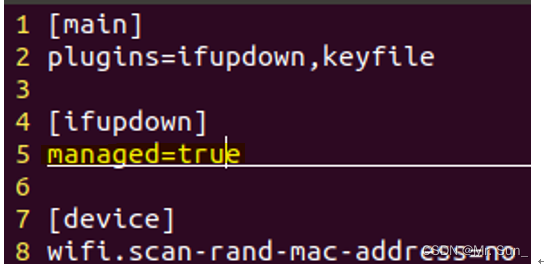
Ubuntu右上角不显示网络的图标解决办法
一.line5改为true sudo vim /etc/NetworkManager/NetworkManager.conf 二.重启网卡 sudo service network-manager stop sudo mv /var/lib/NetworkManager/NetworkManager.state /tmp sudo service network-manager start...

AM@数列极限
文章目录 abstract极限👺极限的主要问题 数列极限数列极限的定义 ( ϵ − N ) (\epsilon-N) (ϵ−N)语言描述极限表达式成立的证明极限发散证明常用数列极限数列极限的几何意义例 函数的极限 abstract 数列极限 极限👺 极限分为数列的极限和函数的极限…...

AI助手开发实战:从资源索引到生产级系统搭建指南
1. 项目概述:一个为AI助手开发者准备的“藏宝图” 如果你正在开发一个AI助手应用,或者正打算将大语言模型的能力集成到你的产品里,那你大概率会遇到一个经典难题:面对市面上眼花缭乱的模型、API和工具,我到底该怎么选&…...

Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案
Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏内置分辨率选项太少而烦恼?是否想在窗口模式下获得全屏游戏…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

Altium Designer实战:用xSignals搞定DDR4内存的等长布线,告别时序烦恼
Altium Designer实战:用xSignals实现DDR4内存精准等长布线 在高速PCB设计中,DDR4内存接口的布线一直是硬件工程师面临的技术高地。当信号速率突破2400MHz时,地址、命令与数据线之间哪怕几个ps的时序偏差都可能导致系统不稳定。传统手工计算网…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

VHDL转Verilog终极指南:如何用VHD2VL v3.0快速完成硬件描述语言转换
VHDL转Verilog终极指南:如何用VHD2VL v3.0快速完成硬件描述语言转换 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA开发领域,VHDL和Verilog是两大主流硬件描述语言,但团队协作或项目迁移时经常…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性
罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求…...

Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南
Scarab空洞骑士模组管理器:2024年最完整的安装与使用指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装的复杂流程而烦恼吗?…...