解锁机器学习-梯度下降:从技术到实战的全面指南
目录
- 一、简介
- 什么是梯度下降?
- 为什么梯度下降重要?
- 二、梯度下降的数学原理
- 代价函数(Cost Function)
- 梯度(Gradient)
- 更新规则
- 代码示例:基础的梯度下降更新规则
- 三、批量梯度下降(Batch Gradient Descent)
- 基础算法
- 代码示例
- 四、随机梯度下降(Stochastic Gradient Descent)
- 基础算法
- 代码示例
- 优缺点
- 五、小批量梯度下降(Mini-batch Gradient Descent)
- 基础算法
- 代码示例
- 优缺点
本文全面深入地探讨了梯度下降及其变体——批量梯度下降、随机梯度下降和小批量梯度下降的原理和应用。通过数学表达式和基于PyTorch的代码示例,本文旨在为读者提供一种直观且实用的视角,以理解这些优化算法的工作原理和应用场景。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
一、简介
梯度下降(Gradient Descent)是一种在机器学习和深度学习中广泛应用的优化算法。该算法的核心思想非常直观:找到一个函数的局部最小值(或最大值)通过不断地沿着该函数的梯度(gradient)方向更新参数。
什么是梯度下降?
简单地说,梯度下降是一个用于找到函数最小值的迭代算法。在机器学习中,这个“函数”通常是损失函数(Loss Function),该函数衡量模型预测与实际标签之间的误差。通过最小化这个损失函数,模型可以“学习”到从输入数据到输出标签之间的映射关系。
为什么梯度下降重要?
-
广泛应用:从简单的线性回归到复杂的深度神经网络,梯度下降都发挥着至关重要的作用。
-
解决不可解析问题:对于很多复杂的问题,我们往往无法找到解析解(analytical solution),而梯度下降提供了一种有效的数值方法。
-
扩展性:梯度下降算法可以很好地适应大规模数据集和高维参数空间。
-
灵活性与多样性:梯度下降有多种变体,如批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)和小批量梯度下降(Mini-batch Gradient Descent),各自有其优点和适用场景。
二、梯度下降的数学原理
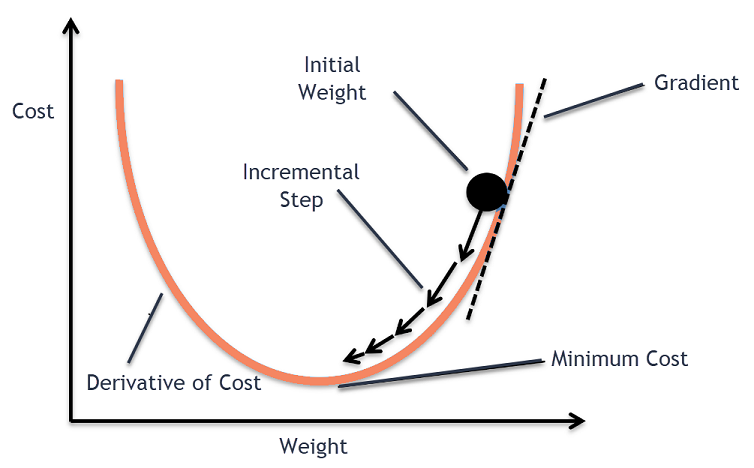
在深入研究梯度下降的各种实现之前,了解其数学背景是非常有用的。这有助于更全面地理解算法的工作原理和如何选择合适的算法变体。
代价函数(Cost Function)
在机器学习中,代价函数(也称为损失函数,Loss Function)是一个用于衡量模型预测与实际标签(或目标)之间差异的函数。通常用 ( J(\theta) ) 来表示,其中 ( \theta ) 是模型的参数。

梯度(Gradient)

更新规则

代码示例:基础的梯度下降更新规则
import numpy as npdef gradient_descent_update(theta, grad, alpha):"""Perform a single gradient descent update.Parameters:theta (ndarray): Current parameter values.grad (ndarray): Gradient of the cost function at current parameters.alpha (float): Learning rate.Returns:ndarray: Updated parameter values."""return theta - alpha * grad# Initialize parameters
theta = np.array([1.0, 2.0])
# Hypothetical gradient (for demonstration)
grad = np.array([0.5, 1.0])
# Learning rate
alpha = 0.01# Perform a single update
theta_new = gradient_descent_update(theta, grad, alpha)
print("Updated theta:", theta_new)
输出:
Updated theta: [0.995 1.99 ]
在接下来的部分,我们将探讨梯度下降的几种不同变体,包括批量梯度下降、随机梯度下降和小批量梯度下降,以及一些高级的优化技巧。通过这些内容,你将能更全面地理解梯度下降的应用和局限性。
三、批量梯度下降(Batch Gradient Descent)
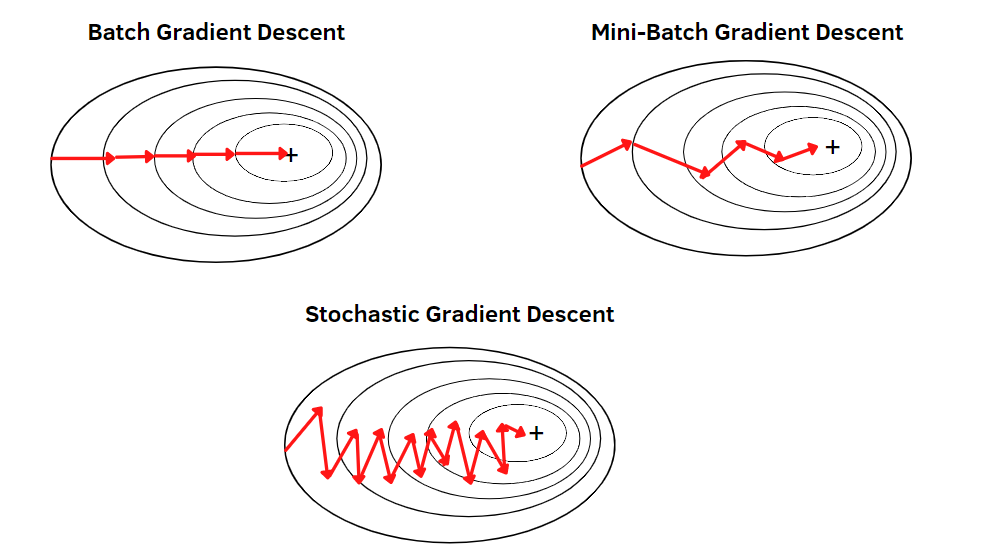
批量梯度下降(Batch Gradient Descent)是梯度下降算法的一种基础形式。在这种方法中,我们使用整个数据集来计算梯度,并更新模型参数。
基础算法
批量梯度下降的基础算法可以概括为以下几个步骤:

代码示例
下面的Python代码使用PyTorch库演示了批量梯度下降的基础实现。
import torch# Hypothetical data (features and labels)
X = torch.tensor([[1.0, 2.0], [2.0, 3.0], [3.0, 4.0]], requires_grad=True)
y = torch.tensor([[1.0], [2.0], [3.0]])# Initialize parameters
theta = torch.tensor([[0.0], [0.0]], requires_grad=True)# Learning rate
alpha = 0.01# Number of iterations
n_iter = 1000# Cost function: Mean Squared Error
def cost_function(X, y, theta):m = len(y)predictions = X @ thetareturn (1 / (2 * m)) * torch.sum((predictions - y) ** 2)# Gradient Descent
for i in range(n_iter):J = cost_function(X, y, theta)J.backward()with torch.no_grad():theta -= alpha * theta.gradtheta.grad.zero_()print("Optimized theta:", theta)
输出:
Optimized theta: tensor([[0.5780],[0.7721]], requires_grad=True)
批量梯度下降的主要优点是它的稳定性和准确性,但缺点是当数据集非常大时,计算整体梯度可能非常耗时。接下来的章节中,我们将探索一些用于解决这一问题的变体和优化方法。
四、随机梯度下降(Stochastic Gradient Descent)
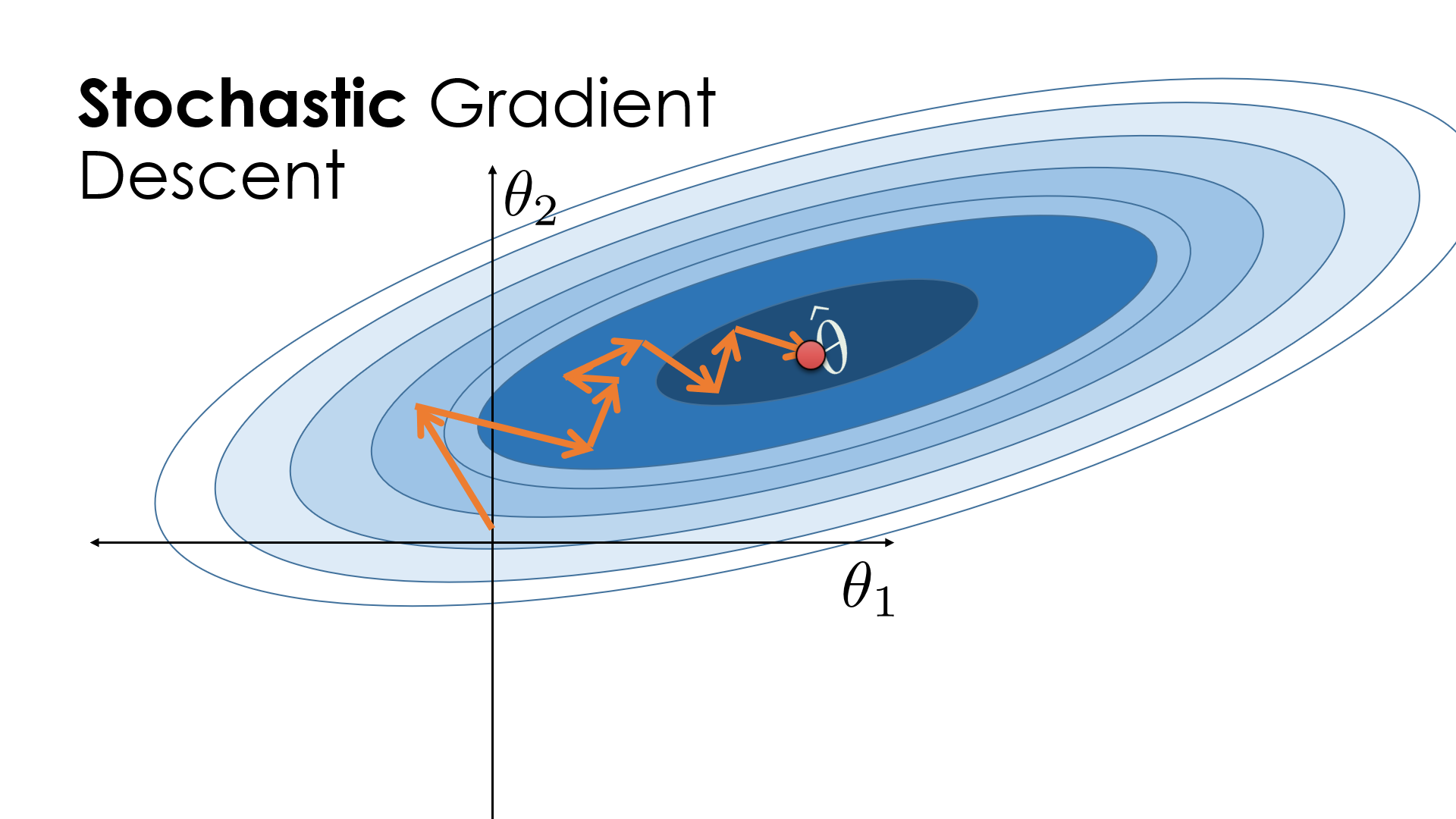
随机梯度下降(Stochastic Gradient Descent,简称SGD)是梯度下降的一种变体,主要用于解决批量梯度下降在大数据集上的计算瓶颈问题。与批量梯度下降使用整个数据集计算梯度不同,SGD每次只使用一个随机选择的样本来进行梯度计算和参数更新。
基础算法
随机梯度下降的基本步骤如下:

代码示例
下面的Python代码使用PyTorch库演示了SGD的基础实现。
import torch
import random# Hypothetical data (features and labels)
X = torch.tensor([[1.0, 2.0], [2.0, 3.0], [3.0, 4.0]], requires_grad=True)
y = torch.tensor([[1.0], [2.0], [3.0]])# Initialize parameters
theta = torch.tensor([[0.0], [0.0]], requires_grad=True)# Learning rate
alpha = 0.01# Number of iterations
n_iter = 1000# Stochastic Gradient Descent
for i in range(n_iter):# Randomly sample a data pointidx = random.randint(0, len(y) - 1)x_i = X[idx]y_i = y[idx]# Compute cost for the sampled pointJ = (1 / 2) * torch.sum((x_i @ theta - y_i) ** 2)# Compute gradientJ.backward()# Update parameterswith torch.no_grad():theta -= alpha * theta.grad# Reset gradientstheta.grad.zero_()print("Optimized theta:", theta)
输出:
Optimized theta: tensor([[0.5931],[0.7819]], requires_grad=True)
优缺点
SGD虽然解决了批量梯度下降在大数据集上的计算问题,但因为每次只使用一个样本来更新模型,所以其路径通常比较“嘈杂”或“不稳定”。这既是优点也是缺点:不稳定性可能帮助算法跳出局部最优解,但也可能使得收敛速度减慢。
在接下来的部分,我们将介绍一种折衷方案——小批量梯度下降,它试图结合批量梯度下降和随机梯度下降的优点。
五、小批量梯度下降(Mini-batch Gradient Descent)

小批量梯度下降(Mini-batch Gradient Descent)是批量梯度下降和随机梯度下降(SGD)之间的一种折衷方法。在这种方法中,我们不是使用整个数据集,也不是使用单个样本,而是使用一个小批量(mini-batch)的样本来进行梯度的计算和参数更新。
基础算法
小批量梯度下降的基本算法步骤如下:

代码示例
下面的Python代码使用PyTorch库演示了小批量梯度下降的基础实现。
import torch
from torch.utils.data import DataLoader, TensorDataset# Hypothetical data (features and labels)
X = torch.tensor([[1.0, 2.0], [2.0, 3.0], [3.0, 4.0], [4.0, 5.0]], requires_grad=True)
y = torch.tensor([[1.0], [2.0], [3.0], [4.0]])# Initialize parameters
theta = torch.tensor([[0.0], [0.0]], requires_grad=True)# Learning rate and batch size
alpha = 0.01
batch_size = 2# Prepare DataLoader
dataset = TensorDataset(X, y)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# Mini-batch Gradient Descent
for epoch in range(100):for X_batch, y_batch in data_loader:J = (1 / (2 * batch_size)) * torch.sum((X_batch @ theta - y_batch) ** 2)J.backward()with torch.no_grad():theta -= alpha * theta.gradtheta.grad.zero_()print("Optimized theta:", theta)
输出:
Optimized theta: tensor([[0.6101],[0.7929]], requires_grad=True)
优缺点
小批量梯度下降结合了批量梯度下降和SGD的优点:它比SGD更稳定,同时比批量梯度下降更快。这种方法广泛应用于深度学习和其他机器学习算法中。
小批量梯度下降不是没有缺点的。选择合适的批量大小可能是一个挑战,而且有时需要通过实验来确定。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
解锁机器学习-梯度下降:从技术到实战的全面指南
目录 一、简介什么是梯度下降?为什么梯度下降重要? 二、梯度下降的数学原理代价函数(Cost Function)梯度(Gradient)更新规则代码示例:基础的梯度下降更新规则 三、批量梯度下降(Batc…...

day62:ARMday9,I2c总线通信
作业:按键中断实现LED1、蜂鸣器、风扇 key_in.c: #include "key_in.h"void gpio_init() {//RCC使能//GPIOERCC->MP_AHB4ENSETR | (0x1<<4);//GPIOBRCC->MP_AHB4ENSETR | (0x1<<1);//PE10、PB6、PE9输出模式GPIOE->MODER & ~(0…...
【Python学习笔记】类型/运算/变量/注释
前言 人生苦短,追求生产力,做一只时代风口的猪,应该学python Python语言中,所有的数据都被称之为对象。 1. 对象类型 Python语言中,常用的数据类型有: 整数, 比如 3 小数(也叫浮…...
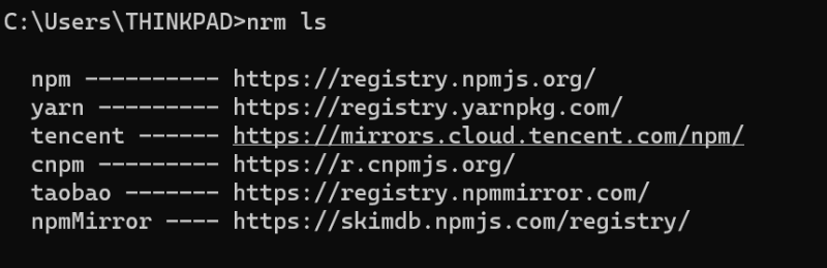
国内常用源开发环境换源(flutter换源,python换源,Linux换源,npm换源)
flutter换源 使用环境变量:PUB_HOSTED_URL FLUTTER_STORAGE_BASE_URL, upgrade出问题时可能会提示设置FLUTTER_GIT_URL变量。 flutter中国 PUB_HOSTED_URLhttps://pub.flutter-io.cn FLUTTER_STORAGE_BASE_URLhttps://storage.flutter-io.cn FLUTTER_GIT_URLhtt…...
关于一篇什么是JWT的原理与实际应用
目录 一.介绍 1.1.什么是JWT 二.结构 三.Jwt的工具类的使用 3.1. 依赖 3.2.工具类 3.3.过滤器 3.4.控制器 3.5.配置 3.6. 测试类 用于生成JWT 解析Jwt 复制jwt,并延时30分钟 测试JWT的有效时间 测试过期JWT的解析 四.应用 今天就到这了,希…...

【Method】把 arXiv论文 转换为 HTML5 网页
文章目录 MethodReference https://ar5iv.labs.arxiv.org/ Articles from arXiv.org as responsive HTML5 web pages. 可以将来自 arXiv 的 PDF 论文渲染成 HTML5 网页版本。 Method View any arXiv article URL by changing the X to a 5. 将 arXiv 网址中的 x 换成 5 再回…...

每日一题AC
4.小花和小草正在沙滩上玩挖沙洞的游戏。他们划了一条长度为n米的线作为挖沙洞的参考线路,小花和小草分别从两头开始沿着划好的线开始挖洞,小花每隔a米挖一个洞,小草每隔b米挖一个洞,碰到已经挖过洞的就不需要再挖了。那么&#x…...
后端:推荐 2 个 .NET 操作的 Redis 客户端类库
目录 Redis特点 Redis场景 1. StackExchange.Redis 2. FreeRedis 🚀 快速入门 🎣 Master-Slave (读写分离) 💻 Pipeline (管道)示例 🌌 Redis Cluster (集群) Redis ,是一个高性能(NOSQL)的key-value数据库,Re…...

华泰证券:京东营收增长或短期承压
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,华泰证券近期发布研报称京东营收增长或短期承压。华泰证券主要观点如下:营收增长或短期承压,聚焦长期内生能力建设 考虑到消费情绪的恢复仍需一定时间,我们预计…...
Java从resources文件下载文档,文档没有后缀名
业务场景:因为公司会对excel文档加密,通过svn或者git上传代码也会对文档进行加密,所以这里将文档后缀去了,这样避免文档加密。 实现思路:将文档去掉后缀,放入resources下,获取输入流࿰…...

【动手学深度学习-Pytorch版】BERT预测系列——BERTModel
本小节主要实现了以下几部分内容: 从一个句子中提取BERT输入序列以及相对的segments段落索引(因为BERT支持输入两个句子)BERT使用的是Transformer的Encoder部分,所以需要需要使用Encoder进行前向传播:输出的特征等于词…...

Python之元组、字典和集合练习
1、餐厅下午茶 (列表与元组 crr66) 某餐厅推出了优惠下午茶套餐活动。顾客可以以优惠的价格从给定的糕点和给定的饮 料中各选一款组成套餐。已知,指定的糕点包括松饼(Muffins)、提拉米苏(Tiramisu)、芝士蛋 糕(Cheese Cake)和三明治(Sandwic…...
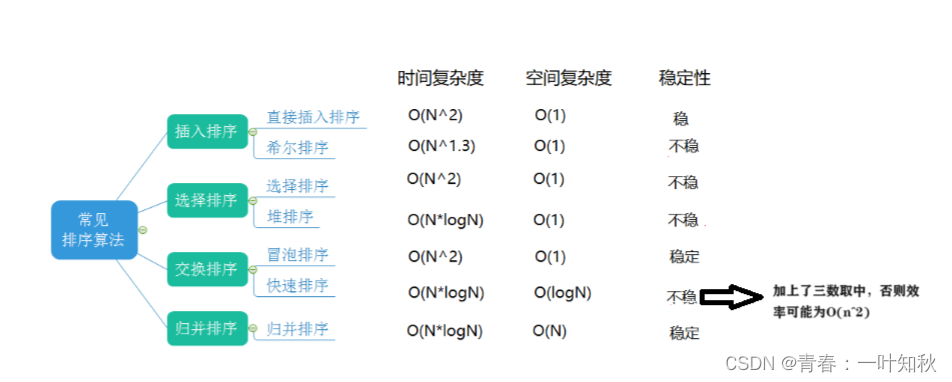
【数据结构】归并排序和计数排序(排序的总结)
目录 一,归并排序的递归 二,归并排序的非递归 三,计数排序 四,排序算法的综合分析 一,归并排序的递归 基本思想: 归并采用的是分治思想,是分治法的一个经典的运用。该算法先将原数据进行拆…...

某医疗机构:建立S-SDLC安全开发流程,保障医疗前沿科技应用高质量发展
某医疗机构是头部资本集团旗下专注大健康领域战略性投资与运营的实业公司,市场规模超300亿。该医疗机构已完成数字赋能,形成了标准化、专业化、数字化的疾病和健康管理体系,将进一步规划战略方向,为人工智能纳米技术、高温超导、生…...

验证二叉搜索树的后序遍历序列
LCR 152. 验证二叉搜索树的后序遍历序列 class VerifyTreeOrder:"""LCR 152. 验证二叉搜索树的后序遍历序列https://leetcode.cn/problems/er-cha-sou-suo-shu-de-hou-xu-bian-li-xu-lie-lcof/description/"""def solution(self, postorder: Lis…...
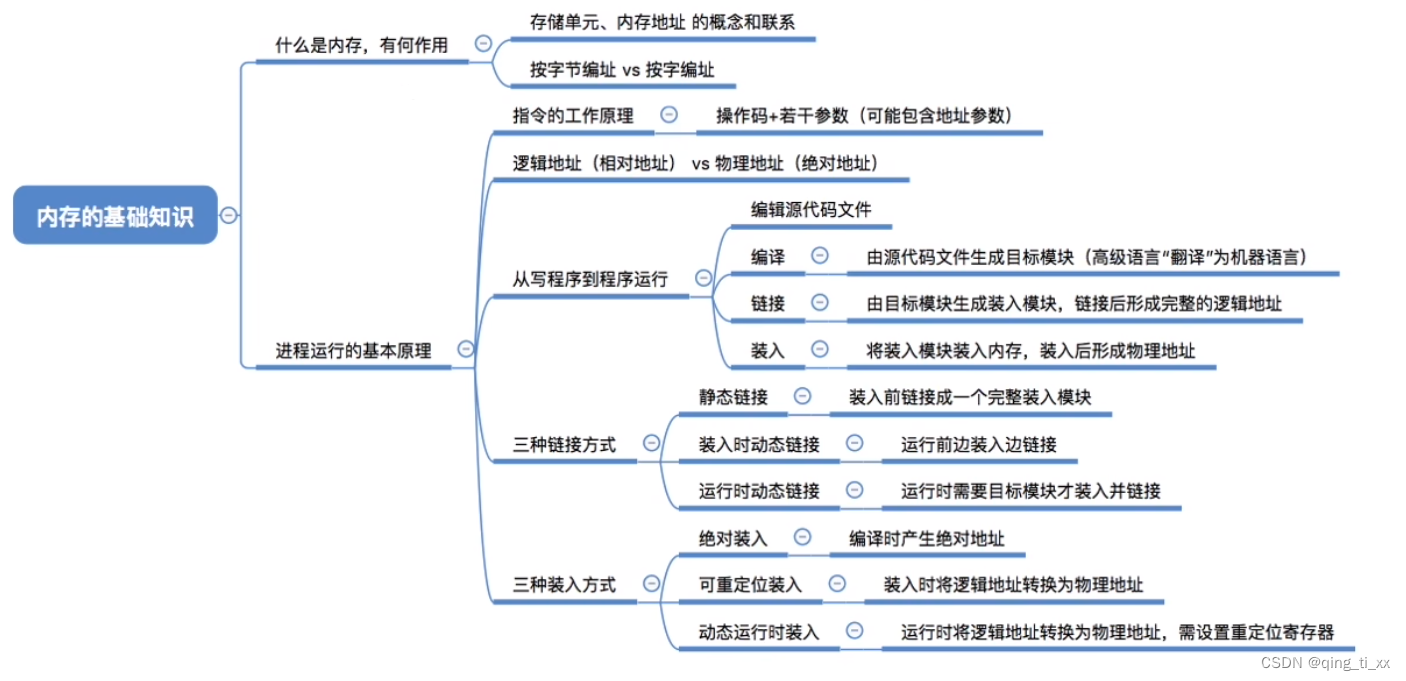
第三章 内存管理 一、内存的基础知识
目录 一、什么是内存 二、有何作用 三、常用数量单位 四、指令的工作原理 五、装入方式 1、绝对装入 2、可重定位装入(静态重定位) 3、动态运行时装入(动态重定位) 六、从写程序到程序运行 七、链接的三种方式 1、静态…...

【Java学习之道】Java常用集合框架
引言 在Java中,集合框架是一个非常重要的概念。它提供了一种方式,让你可以方便地存储和操作数据。Java中的集合框架包括各种集合类和接口,这些类和接口提供了不同的功能和特性。通过学习和掌握Java的集合框架,你可以更好地管理和…...
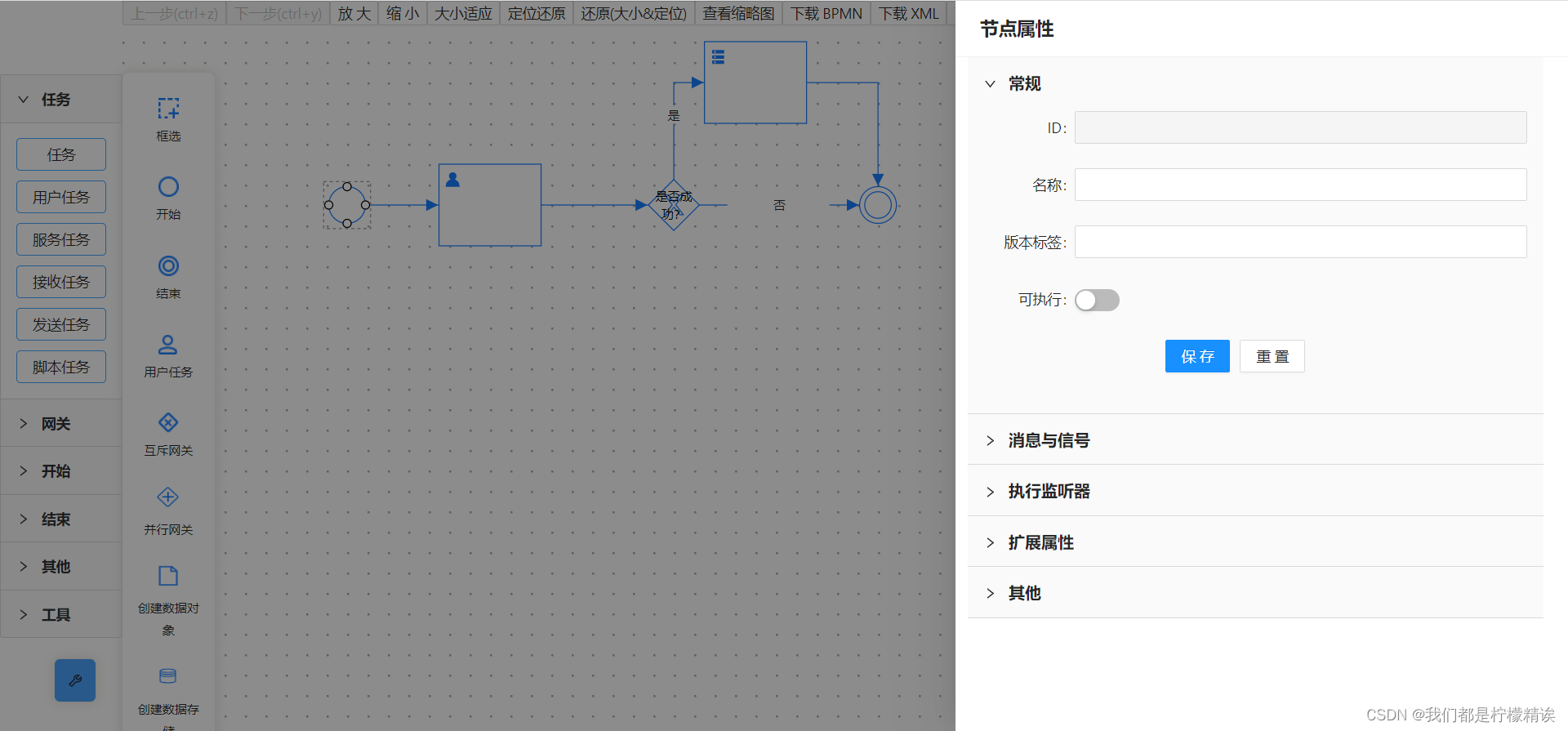
logicFlow 流程图编辑工具使用及开源地址
一、工具介绍 LogicFlow 是一款流程图编辑框架,提供了一系列流程图交互、编辑所必需的功能和灵活的节点自定义、插件等拓展机制。LogicFlow 支持前端研发自定义开发各种逻辑编排场景,如流程图、ER 图、BPMN 流程等。在工作审批配置、机器人逻辑编排、无…...
/OPTEE之动态代码分析汇总)
ATF(TF-A)/OPTEE之动态代码分析汇总
安全之安全(security)博客目录导读 1、ASAN(AddressSanitizer)地址消毒动态代码分析 2、ATF(TF-A)之UBSAN动态代码分析 3、OPTEE之KASAN地址消毒动态代码分析...

10-11 周三 shell xargs tr curl 做大事情
最近发现,shell的小工具非常的强大,简单记录下 tr命令 -d 删除字符串1中所有输入字符。-s 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串 -d 用于删除查询到的字符串中的空格。 [test3NH-DC-NM1…...

【Perplexity×知网双引擎文献检索术】:20年科研老炮亲授3步精准定位高引论文的私密工作流
更多请点击: https://kaifayun.com 第一章:【Perplexity知网双引擎文献检索术】:20年科研老炮亲授3步精准定位高引论文的私密工作流 为什么单靠知网或Google Scholar总在“相关文献”里打转? 单一学术搜索引擎存在固有偏见&…...

基于HPM5E00的EtherCAT从站开发板全流程实战:从硬件设计到软件配置
1. 项目概述:为什么我们要自己动手做一块EtherCAT开发板?如果你是一名从事工业自动化、运动控制或者机器人开发的工程师,最近几年一定没少听到EtherCAT的大名。它号称“以太网控制自动化技术”,本质上是一种基于标准以太网的实时工…...

性能优化实战:在Unity项目里管理多个Video Player,如何避免内存泄漏和卡顿?
Unity多视频管理实战:规避内存泄漏与卡顿的深度优化策略 在沉浸式游戏体验和交互式AR/VR应用中,视频内容已成为提升用户参与度的关键要素。但当场景中同时存在多个Video Player组件时,开发者往往会遭遇突如其来的性能断崖——内存占用飙升、播…...

3步掌握城通网盘解析工具:彻底告别30秒等待与限速困扰
3步掌握城通网盘解析工具:彻底告别30秒等待与限速困扰 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载的漫长等待和蜗牛般的速度而烦恼吗?城通网盘作为国内广…...

软件测试的“隐形赛道”:性能测试如何年入50w
一、性能测试:软件测试领域的“隐形黄金赛道”在软件测试的广阔版图中,性能测试长期处于“隐形”状态,却暗藏着年入50w的职业密码。相较于广为人知的功能测试,性能测试聚焦于系统在高并发、大数据量、复杂场景下的表现,…...

【linux学习】linux的一些奇怪知识,方便日常使用
我是程序员小青蛙,下面介绍关于linux的知识。前言一些基本知识,方便利用,比如热键[tab],[ctrl]-c,[ctrl]-d,粘滞位,权限等;xshell中的复制粘贴,Ctrlinsert,复制shiftinsert->粘贴一、重要的几…...
GitGitHub实操图文详解教程(05)—git init命令)
(最新版)GitGitHub实操图文详解教程(05)—git init命令
版权声明 本文原创作者:谷哥的小弟 作者博客地址:http://blog.csdn.net/lfdfhl 1. 应用场景 git init 用于将一个普通目录初始化为 Git 仓库,从而使 Git 开始对该目录及其文件进行版本管理。 在实际开发中,常见应用场景包括: 新建本地项目 当你创建一个 Spring Boot 项目…...

环境科学论文降AI工具免费推荐:2026年环境科学研究生毕业论文降AI知网维普99.26%4.8元完整指南
环境科学论文降AI工具免费推荐:2026年环境科学研究生毕业论文降AI知网维普99.26%4.8元完整指南 整理了一份环境科学论文降AI的完整选购指南,按性价比排序。 首推嘎嘎降AI(www.aigcleaner.com),4.8元,99.2…...

Linux内核PCIe热插拔驱动开发实战:从IDT芯片到稳定运行
1. 项目概述与核心价值最近在搞一个嵌入式设备项目,需要实现PCIe设备的热插拔支持。这玩意儿在服务器、存储阵列和工业控制领域太常见了,但真要在Linux内核里把它做稳定、做可靠,里面的门道可不少。我这次折腾的,就是一个基于Linu…...
)
从一次Keycloak弱口令通报说起:微服务架构下的密码管理‘避坑’全指南(附Docker Compose配置)
微服务架构下的密码安全实践:从Keycloak弱口令到全局防护体系 1. 当安全工具成为攻击入口:一次真实事件复盘 去年某科技公司的运维团队收到了一份来自监管部门的网络安全通报——部署在公有云上的Keycloak服务遭到境外IP爆破攻击。攻击者仅用"admin…...