Pytorch之ConvNeXt图像分类
文章目录
- 前言
- 一、ConvNeXt设计决策
- 1.设计方案
- 2.Training Techniques
- 3.Macro Design
- 🥇Changing stage compute ratio
- 🥈Change stem to "Patchify"
- 4.ResNeXt-ify
- 5. Inverted Bottleneck
- 6.Large Kernel Size
- 7.Micro Design
- ✨Replacing ReLU with GELU
- ✨Fewer activation functions
- ✨Fewer normalization layers
- ✨Substituting BN with LN
- ✨Separate downsampling layers
- 二、ConvNeXt网络结构
- 1.网络配置参数
- 2.ConvNeXt-T 结构
- 三、ConvNeXt-T网络实现
- 1.构建ConvNeXt-T网络
- 2.训练和测试模型
- 四、实现图像分类
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
CNN自1989年以来一直存在,当时第一个多层CNN,称为ConvNet,由Yann LeCun开发。该模型可以执行视觉认知任务,例如识别手写数字。1998年,LeCun开发了一种改进的ConvNet模型,称为LeNet。由于其在光学识别任务中的高精度,LeNet在发明后不久就被工业使用。从那时起,CNN一直是工业界和学术界最成功的机器学习模型之一。下图显示了 CNN 生命周期中架构发展的简要时间表,从 1989 年一直到 2020 年,

十年来,计算机视觉(CV)突飞猛进,VGGNet,GoogLeNet/Inception,ResNeXt,DenseNet,MobileNet 和 EfficientNet等一大批ImageNet竞赛的年度冠军等优秀模型蓬勃发展,你方唱罢我登场,精彩纷呈,卷积神经网络CNN作为图像处理的标配卷过了AI的大半边天。
在此之前,自然语言处理 (NLP) 和CV是像两条平行线,各自相对独立的发展。RNN和CNN是教科书中两个独立的章节,分别对应自然语言的序列(Sequence)和图像局部特征的特点。自从2017年,Google在NLP领域发表了Attention is all you need,提出基于自注意力(self-attention)的Transformer,随后ViT(Vision Transformer)在CV领域大放异彩,越来越多的研究人员开始拥入Transformer的怀抱。
之后在CV领域发的文章绝大多数都是基于Transformer的,比如2021年ICCV 的best paper Swin Transformer,而卷积神经网络已经开始慢慢淡出舞台中央,难道卷积神经网络要被Transformer取代了吗?也许会在不久的将来。
在2022年1月,A ConvNet for the 2020s一论文提出ConvNeXt,借鉴了 Vision Transformer 和 CNN 的成功经验,构建一个纯卷积网络,其性能超越了高大上(复杂的) 基于Transformer 的先进的模型。
ConvNeXt的出现证明,并不一定需要Transformer那么复杂的结构,只对原有CNN的技术和参数优化也能达到SOTA,未来CV领域,CNN和Transformer谁主沉浮?
一、ConvNeXt设计决策
1.设计方案
作者将设计 vision Transformer(Swin) 的技巧应用到标准的卷积网络(ResNet-50)。纵坐标代表采取的操作,横坐标表示在ImageNet数据集上的top1准确率。星星表示网络的计算量。斜条纹(kernel size=9/11)表示不采取该操作。实验结果展示 在计算量相同的情况下,纯卷积网络(ConvNext)表现优于Swin Transformer。

作者首先利用训练vision Transformers的策略去训练原始的ResNet50模型,发现比原始效果要好很多,并将此结果作为后续实验的基准baseline。然后作者罗列了接下来实验包含哪些部分:
∙ \bullet ∙ macro design
∙ \bullet ∙ ResNeXt
∙ \bullet ∙ inverted bottleneck
∙ \bullet ∙ large kerner size
∙ \bullet ∙various layer-wise micro designs
依次从宏观设计,深度可分离卷积(ResNeXt),逆瓶颈层(MobileNet v2),大卷积核,细节设计这五个角度依次借鉴Swin Transformer的思想,然后在ImageNet-1K上进行训练和评估,得到ConvNeXt的核心结构。
ConvNeXt本质上没有提出新的创新点,ConvNeXt使用的全部都是现有的结构和方法,没有任何结构或者方法的创新。
2.Training Techniques
随着深度学习在各个领域上的不断探索,残差网络采用的原始策略已经不能充分的压榨残差结构的性能。Vision Transformers不仅带来新的模块和框架设计,同时也介绍了不同的训练技巧。
在ConvNeXt中,它的优化策略借鉴了Swin-Transformer。具体的优化策略包括:
∙ \bullet ∙ 将训练的epochs从原先的90增加到300。
∙ \bullet ∙ 优化器从SGD改为使用AdamW优化器。
∙ \bullet ∙ 更复杂的数据扩充策略,包括Mixup,CutMix,RandAugment,Random Erasing
∙ \bullet ∙ 增加正则策略,例如随机深度,标签平滑,EMA等
实验结果显示,ResNet-50在ImageNet数据集上的Top1准确率从 76.1%增到78.8%(+2.7%)。这表明,传统的卷积网络和vision Transformer的差异可能源于训练技巧(training techniques)的不同。
更具体的预训练和微调的超参数如下图

3.Macro Design
Swin Transformer使用multi-stage的设计,即每个stage有不同的特征图分辨率,主要包括stage compute ratio和stem cell结构。
🥇Changing stage compute ratio
VGG提出了把骨干网络分成若干个网络块的结构,每个网络块通过池化操作将Feature Map降采样到不同的尺寸。在VGG中,每个网络块的网络层的数量基本是相同,当深层的网络块层数更多时,模型的表现更好。例如,ResNet-50中共有4个不同的网络块,它的每个网络块的层数是(3,4,6,3) ,比例大概是(1:1:2:1)。

在Swin-Transformer中,每个骨干网络被分成了4个不同的Stage,每个Stage又是由若干个Block组成,在Swin-Transformer中,这个Block的比例是**(1:1:3:1)**,而对于更大的模型来说,这个比例是(1:1:9:1) 。
ConvNeXt的改进是将ResNet-50的每个Stage的block的比例调整到(1:1:3:1) ,最终得到的block数是(3,3,9,3) ,进行调整后,准确率由78.8%提升到了79.4%。
🥈Change stem to “Patchify”
对于ImageNet数据集,通常采用224x224的输入尺寸,该尺寸对于Transformer的模型来说是非常大的,在Transformer模型中一般都是通过一个 卷积核非常大且相邻窗口之间没有重叠的(即stride等于kernel_size)卷积层进行下采样。比如在Swin Transformer中采用的是一个卷积核大小为4x4步距为4的卷积层构成patchify(补丁化),同样是下采样4倍,这一部分在Swin-Transformer中叫做stem层,它是位于输入之后的一个降采样层。
“patchify”策略作为 stem cell使用:
∙ \bullet ∙ 使用一个大的卷积核
∙ \bullet ∙ non-overlapping卷积(stride=kernel size)
通常情况下,stem cell主要在网络的最前头用于处理输入图像。即下采样输入图像到合适的图像尺寸。
在标准的ResNet中,一般最初的下采样模块stem一般都是通过一个卷积核大小为7x7步距为2的卷积层以及一个步距为2的最大池化下采样共同组成,高和宽都下采样4倍。
在ConvNeXt中,作者将Stem层也换成和Swin Transformer一样的patchify,使用一个步长为4,大小为4的卷积操作,这一操作将准确率从79.4%提升至79.5%,GFLOPs从4.5降到4.4%。
4.ResNeXt-ify
作者采用ResNext的思想,它比普通的ResNet具有更好的FLOPs/accuracy权衡。核心部分是分组卷积(grouped convolution)即卷积核被分成不同的组,用来提升模型的计算速度。
作者使用depthwise convolution,这是分组卷积的一种特殊情况,即分组的数量等于通道的数量。如下图所示。

在Swin-Tranformer的Self-Attention也是以通道为单位的运算单元,不同的是可分离卷积是可学习的卷积核,Self-Attention是根据数据动态计算的权值。
在ConvNeXt中,也引入了分组卷积的思想,它将bottleneck中3x3卷积替换成了3x3 的分组卷积,这个操作将GFLOPs从4.4降到了2.4,但是它也将准确率从79.5%降到了78.3%。**为了弥补准确率的下降,它将ResNet-50的基础通道数从64增加至96。**这个操作将GFLOPs增加到了5.3,但是准确率提升到了80.5%。
5. Inverted Bottleneck
作者认为Transformer block中的MLP模块(中间层维度数是两端的4倍)非常像MobileNetV2中的Inverted Bottleneck模块,即两头细中间粗。下图a是ReNet中采用的Bottleneck模块(大维度-小维度-大维度),b是MobileNetV2采用的Inverted Botleneck模块(小维度-大维度-小维度),c是ConvNeXt采用的是Inverted Bottleneck模块。

作者采用Inverted Bottleneck模块后,在较小的模型上准确率由80.5%提升到了80.6%,在较大的模型上准确率由81.9%提升到82.6%。
6.Large Kernel Size
Transformer中,non-local self-attention能够获得全局的感受野。研究者认为更大的感受野是ViT性能更好的可能原因之一,作者尝试增大卷积的kernel,使模型获得更大的感受野。
接着作者做了如下两个改动:
⋆ \star ⋆ Moving up depthwise conv layer,将depthwise conv提前到1x1 conv之前,之后用384个1x1x96的conv将模型宽度提升4倍,在用96个1x1x96的conv恢复模型宽度。
反映在上图中就是由(b)变为©,原来是1x1 conv -> depthwise conv -> 1x1 conv,现在变成了depthwise conv -> 1x1 conv -> 1x1 conv。这么做是因为在Transformer中,MSA模块是放在MLP模块之前的,所以这里进行效仿,将depthwise conv上移。由于3x3的conv数量减少,模型FLOPs由5.3G减少到4G,相应地性能暂时下降到79.9%。
⋆ \star ⋆ Increasing the kernel size,然后作者尝试增大depthwise conv的卷积核大小,证明7x7(Swin Transformer中也是7x7)大小的卷积核效果达到最佳,并且准确率从79.9% (3×3) 增长到 80.6% (7×7)。
7.Micro Design
接下来开始细节层面的讨论,主要体现在激活函数和归一化层的选择。
✨Replacing ReLU with GELU
ReLU是比较早期的激活函数,在卷积神经网络中比较常用。在Transformer中基本上选择使用GELU作为激活函数,如Swin Transformer。
GELU可以认为是ReLU的平滑版本。作者实验发现,在ConvNeXt将ReLu使用GELU代替,但是精度没有变化(80.6%)。但是为了对齐其它指标,ConvNeXt还是选择了GELU作为激活函数。
✨Fewer activation functions
在卷积神经网络中,一般会在每个卷积层或全连接后都接上一个激活函数。但在Transformer中并不是每个模块后都跟有激活函数。如下图所示,Swin Transformer block中只有MLP有一个激活函数(RELU)。

ConvNeXt也借鉴了Transformer的思想,它仅在两个1x1卷积之间添加了一个GELU激活函数。实验结果表明这个操作将准确率从80.6%提升至81.3%。
✨Fewer normalization layers
在Transformer中,Normalization使用的也比较少,接着作者也减少了ConvNeXt Block中的Normalization层,只保留了depthwise conv后的Normalization层。此时准确率已经达到了81.4%,已经超过了Swin-T。根据经验,作者发现,在block的开始添加一个额外的Normalization层并不能改善性能。
✨Substituting BN with LN
BatchNorm是卷积神经网络的重要组成部分,因为它提高了收敛性并减少了过拟合。虽然BN也有很多错综复杂的地方,会对模型的性能产生不利影响,但BN仍然是大多数视觉任务的首选方法。
但在Transformer中使用了更简单的Layer Normalization(LN),因为最开始Transformer是应用在NLP领域的,BN又不适用于NLP相关任务。接着作者将BN全部替换成了LN,发现准确率还有小幅提升达到了81.5%。
✨Separate downsampling layers
在ResNet网络中stage2-stage4的下采样都是通过将主分支上3x3的卷积层步距设置成2,short分支上1x1的卷积层步距设置成2进行下采样的。
但在Swin Transformer中是通过一个单独的Patch Merging实现的。接着作者就为ConvNext网络单独使用了一个下采样层,使用卷积核为2,步长为2的卷积层进行空间下采样操作,又因为这样会使训练不稳定,因此在每个下采样层前面增加了Laryer Normalization(LN)来稳定训练,更改后准确率就提升到了82.0%。
二、ConvNeXt网络结构
1.网络配置参数
对于ConvNeXt网络,作者提出了T/S/B/L/XL五个版本,这五个版本的配置如下:
∙ \bullet ∙ ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3)
∙ \bullet ∙ ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
∙ \bullet ∙ ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
其中C代表4个stage中输入的通道数,B代表每个stage重复堆叠block的次数,ConvNeXt-T版本如下图所示。

2.ConvNeXt-T 结构
ConvNeXt-T网络结构图如下,来自B站大佬的。

注意,ConvNeXt Block中还有一个Layer Scale操作,它就是将输入的特征层乘上一个可训练的参数,该参数就是一个向量,元素个数与特征层channel相同,即对每个channel的数据进行缩放。
三、ConvNeXt-T网络实现
1.构建ConvNeXt-T网络
"""
original code from facebook research:
https://github.com/facebookresearch/ConvNeXt
"""import torch
import torch.nn as nn
import torch.nn.functional as Fdef drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class LayerNorm(nn.Module):r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.The ordering of the dimensions in the inputs. channels_last corresponds to inputs withshape (batch_size, height, width, channels) while channels_first corresponds to inputswith shape (batch_size, channels, height, width)."""def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape), requires_grad=True)self.bias = nn.Parameter(torch.zeros(normalized_shape), requires_grad=True)self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise ValueError(f"not support data format '{self.data_format}'")self.normalized_shape = (normalized_shape,)def forward(self, x: torch.Tensor) -> torch.Tensor:if self.data_format == "channels_last": # 维度:(batch_size, height, width, channels)使用官方的函数return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first": # 维度:(batch_size, channels, height, width)自定义使用LN# [batch_size, channels, height, width]mean = x.mean(1, keepdim=True) # CHANNEL维度var = (x - mean).pow(2).mean(1, keepdim=True)x = (x - mean) / torch.sqrt(var + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return x# ConvNeXt block
class Block(nn.Module):r""" ConvNeXt Block. There are two equivalent implementations:(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute backWe use (2) as we find it slightly faster in PyTorchArgs:dim (int): Number of input channels.drop_rate (float): Stochastic depth rate. Default: 0.0layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6."""def __init__(self, dim, drop_rate=0., layer_scale_init_value=1e-6):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise convself.norm = LayerNorm(dim, eps=1e-6, data_format="channels_last")# 1x1的卷积层使用Linear实现self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layersself.act = nn.GELU()self.pwconv2 = nn.Linear(4 * dim, dim)# Layer Scaleself.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim,)),requires_grad=True) if layer_scale_init_value > 0 else Noneself.drop_path = DropPath(drop_rate) if drop_rate > 0. else nn.Identity()def forward(self, x: torch.Tensor) -> torch.Tensor:shortcut = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1) # [N, C, H, W] -> [N, H, W, C]x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.pwconv2(x)if self.gamma is not None:x = self.gamma * xx = x.permute(0, 3, 1, 2) # [N, H, W, C] -> [N, C, H, W]x = shortcut + self.drop_path(x)return xclass ConvNeXt(nn.Module):r""" ConvNeXtA PyTorch impl of : `A ConvNet for the 2020s` -https://arxiv.org/pdf/2201.03545.pdfArgs:in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]drop_path_rate (float): Stochastic depth rate. Default: 0.layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1."""def __init__(self, in_chans: int = 3, num_classes: int = 1000, depths: list = None,dims: list = None, drop_path_rate: float = 0., layer_scale_init_value: float = 1e-6,head_init_scale: float = 1.):super().__init__()self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers# 下采样:convd2d k4 s4 + LNstem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)# 对应stage2-stage4前的3个downsample:LN + conv2d k2 s2for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2))self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple blocksdp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]cur = 0# 构建每个stage中堆叠的blockfor i in range(4):stage = nn.Sequential(*[Block(dim=dims[i], drop_rate=dp_rates[cur + j], layer_scale_init_value=layer_scale_init_value)for j in range(depths[i])])self.stages.append(stage)cur += depths[i]self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layerself.head = nn.Linear(dims[-1], num_classes)self.apply(self._init_weights)self.head.weight.data.mul_(head_init_scale)self.head.bias.data.mul_(head_init_scale)def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):nn.init.trunc_normal_(m.weight, std=0.2)nn.init.constant_(m.bias, 0)def forward_features(self, x: torch.Tensor) -> torch.Tensor:for i in range(4):x = self.downsample_layers[i](x)x = self.stages[i](x)return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.forward_features(x)x = self.head(x)return xdef convnext_tiny(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pthmodel = ConvNeXt(depths=[3, 3, 9, 3],dims=[96, 192, 384, 768],num_classes=num_classes)return modeldef convnext_small(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pthmodel = ConvNeXt(depths=[3, 3, 27, 3],dims=[96, 192, 384, 768],num_classes=num_classes)return modeldef convnext_base(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth# https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pthmodel = ConvNeXt(depths=[3, 3, 27, 3],dims=[128, 256, 512, 1024],num_classes=num_classes)return modeldef convnext_large(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth# https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pthmodel = ConvNeXt(depths=[3, 3, 27, 3],dims=[192, 384, 768, 1536],num_classes=num_classes)return modeldef convnext_xlarge(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pthmodel = ConvNeXt(depths=[3, 3, 27, 3],dims=[256, 512, 1024, 2048],num_classes=num_classes)return model2.训练和测试模型
import os
import argparseimport torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsfrom my_dataset import MyDataSet
from model import convnext_tiny as create_model
from utils import read_split_data, create_lr_scheduler, get_params_groups, train_one_epoch, evaluatedef main(args):device = torch.device(args.device if torch.cuda.is_available() else "cpu")print(f"using {device} device.")if os.path.exists("./weights") is False:os.makedirs("./weights")tb_writer = SummaryWriter()train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)img_size = 224data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(img_size),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),"val": transforms.Compose([transforms.Resize(int(img_size * 1.143)),transforms.CenterCrop(img_size),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}# 实例化训练数据集train_dataset = MyDataSet(images_path=train_images_path,images_class=train_images_label,transform=data_transform["train"])# 实例化验证数据集val_dataset = MyDataSet(images_path=val_images_path,images_class=val_images_label,transform=data_transform["val"])batch_size = args.batch_sizenw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)val_loader = torch.utils.data.DataLoader(val_dataset,batch_size=batch_size,shuffle=False,pin_memory=True,num_workers=nw,collate_fn=val_dataset.collate_fn)model = create_model(num_classes=args.num_classes).to(device)if args.weights != "":assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)weights_dict = torch.load(args.weights, map_location=device)["model"]# 删除有关分类类别的权重for k in list(weights_dict.keys()):if "head" in k:del weights_dict[k]print(model.load_state_dict(weights_dict, strict=False))if args.freeze_layers:for name, para in model.named_parameters():# 除head外,其他权重全部冻结if "head" not in name:para.requires_grad_(False)else:print("training {}".format(name))# pg = [p for p in model.parameters() if p.requires_grad]pg = get_params_groups(model, weight_decay=args.wd)optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=args.wd)lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs,warmup=True, warmup_epochs=1)best_acc = 0.for epoch in range(args.epochs):# traintrain_loss, train_acc = train_one_epoch(model=model,optimizer=optimizer,data_loader=train_loader,device=device,epoch=epoch,lr_scheduler=lr_scheduler)# validateval_loss, val_acc = evaluate(model=model,data_loader=val_loader,device=device,epoch=epoch)tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]tb_writer.add_scalar(tags[0], train_loss, epoch)tb_writer.add_scalar(tags[1], train_acc, epoch)tb_writer.add_scalar(tags[2], val_loss, epoch)tb_writer.add_scalar(tags[3], val_acc, epoch)tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)if best_acc < val_acc:torch.save(model.state_dict(), "./weights/best_model.pth")best_acc = val_accif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--num_classes', type=int, default=100)parser.add_argument('--epochs', type=int, default=10)parser.add_argument('--batch-size', type=int, default=8)parser.add_argument('--lr', type=float, default=5e-4)parser.add_argument('--wd', type=float, default=5e-2)# 数据集所在根目录# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgzparser.add_argument('--data-path', type=str,default="F:/NN/Learn_Pytorch/flower_photos")# 预训练权重路径,如果不想载入就设置为空字符# 链接: https://pan.baidu.com/s/1aNqQW4n_RrUlWUBNlaJRHA 密码: i83tparser.add_argument('--weights', type=str, default='./convnext_tiny_1k_224_ema.pth',help='initial weights path')# 是否冻结head以外所有权重parser.add_argument('--freeze-layers', type=bool, default=False)parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')opt = parser.parse_args()main(opt)这里使用了预训练权重,在其基础上训练自己的数据集。训练10epoch的准确率能到达98%左右。

四、实现图像分类
这里使用花朵数据集,下载连接:https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
def main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print(f"using {device} device.")num_classes = 5img_size = 224data_transform = transforms.Compose([transforms.Resize(int(img_size * 1.14)),transforms.CenterCrop(img_size),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 加载图片img_path = 'sunflower1.jpg'assert os.path.exists(img_path), "file: '{}' does not exist.".format(img_path)image = Image.open(img_path)# image.show()# [N, C, H, W]img = data_transform(image)# 扩展维度img = torch.unsqueeze(img, dim=0)# 获取标签json_path = 'class_indices.json'assert os.path.exists(json_path), "file: '{}' does not exist.".format(json_path)with open(json_path, 'r') as f:# 使用json.load()函数加载JSON文件的内容并将其存储在一个Python字典中class_indict = json.load(f)# create modelmodel = create_model(num_classes=num_classes).to(device)# load model weightsmodel_weight_path = "./weights/best_model.pth"model.load_state_dict(torch.load(model_weight_path, map_location=device))model.eval()with torch.no_grad():# 对输入图像进行预测output = torch.squeeze(model(img.to(device))).cpu()# 对模型的输出进行 softmax 操作,将输出转换为类别概率predict = torch.softmax(output, dim=0)# 得到高概率的类别的索引predict_cla = torch.argmax(predict).numpy()res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)], predict[predict_cla].numpy())draw = ImageDraw.Draw(image)# 文本的左上角位置position = (10, 10)# fill 指定文本颜色draw.text(position, res, fill='green')image.show()for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)], predict[i].numpy()))
预测结果:

结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。
相关文章:
Pytorch之ConvNeXt图像分类
文章目录 前言一、ConvNeXt设计决策1.设计方案2.Training Techniques3.Macro Design🥇Changing stage compute ratio🥈Change stem to "Patchify" 4.ResNeXt-ify5. Inverted Bottleneck6.Large Kernel Size7.Micro Design✨Replacing ReLU wit…...
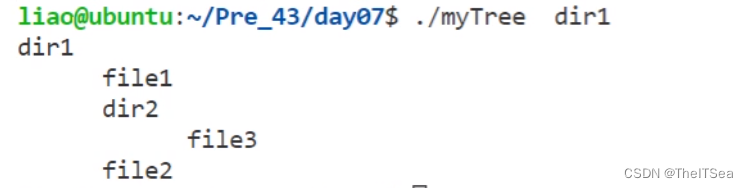
Linux系统编程:makefile以及文件系统编程
增量编译概念 首先回顾一下我们之前写的各种gcc指令用来执行程序: 可以看见非常繁琐,两个文件就要写这么多,那要是成百上千岂不完蛋。 所以为了简化工作量,很自然的想到了将这些命令放在一起使用脚本文件来一键执行,…...

《动手学深度学习 Pytorch版》 8.5 循环神经网络的从零开始实现
%matplotlib inline import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2lbatch_size, num_steps 32, 35 train_iter, vocab d2l.load_data_time_machine(batch_size, num_steps) # 仍然使用时间机器数据集8.…...

写一个宏,可以将一个整数的二进制位的奇数位和偶数位交换
我们这里是利用按位与来计算的 我们可以想想怎么保留偶数上的位?我们可以利用0x55555555按位与上这个数就保留了偶数 我们知道,16进制0x55555555转换为二进制就是0x01010101010101010101010101010101 我们知道,二进制每一位,如…...
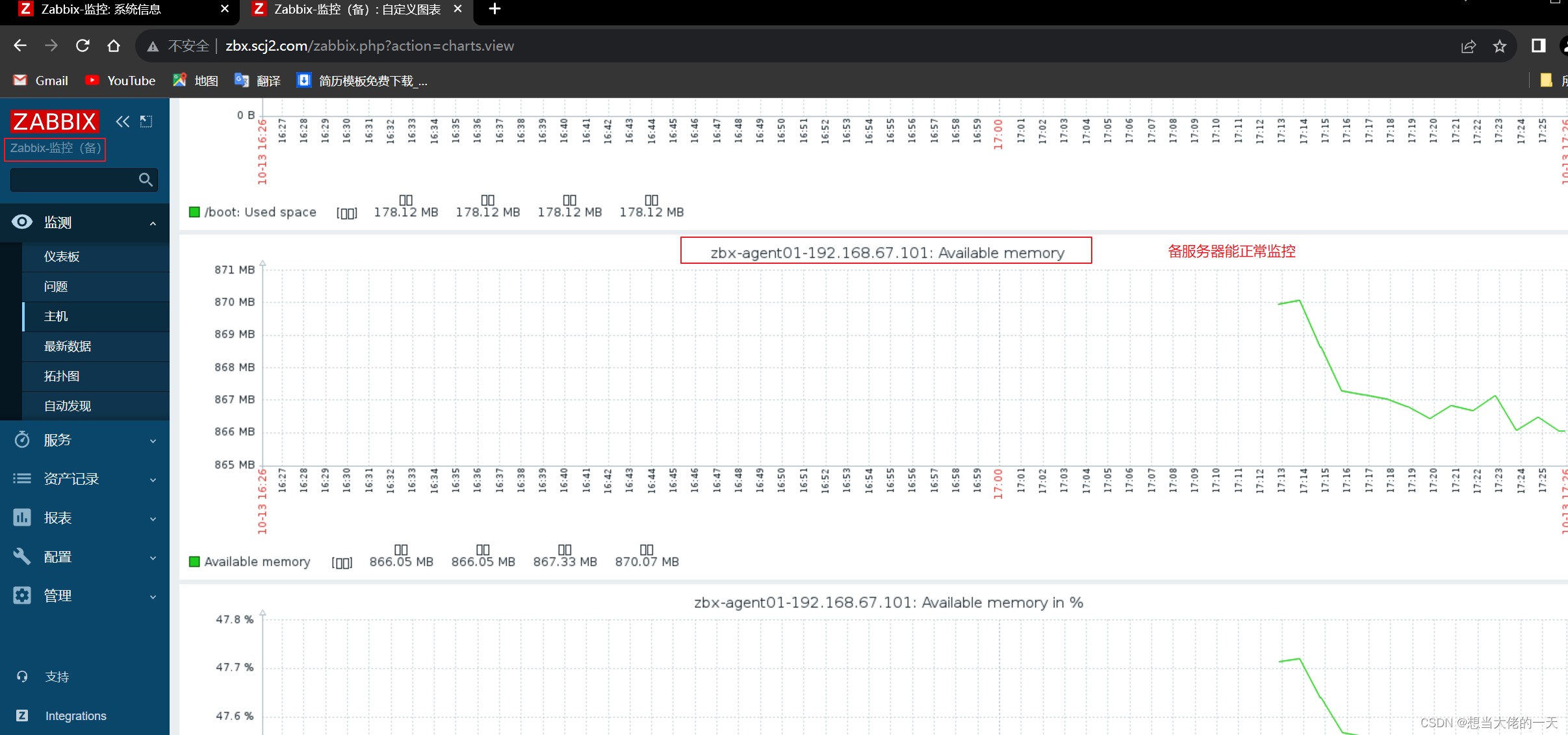
Zabbix监控系统详解2:基于Proxy分布式实现Web应用监控及Zabbix 高可用集群的搭建
文章目录 1. zabbix-proxy的分布式监控的概述1.1 分布式监控的主要作用1.2 监控数据流向1.3 构成组件1.3.1 zabbix-server1.3.2 Database1.3.3 zabbix-proxy1.3.4 zabbix-agent1.3.5 web 界面 2. 部署zabbix代理服务器2.1 前置准备2.2 配置 zabbix 的下载源,安装 za…...
docker 安装oracle
拉取镜像 拉取oracle_11g镜像 拉取oracle镜像(oracle 11.0.2 64bit 企业版 实例名: helowin) Oracle主要在Docker基础上安装,安装环境注意空间和内存,Oracle是一个非常庞大的一个软件, 建议使用网易镜像或阿里镜像网站这里以oracle 11.0.2…...
)
C++ vector 自定义排序规则(vector<vector<int>>、vector<pair<int,int>>)
vector< int > vector<int> vec{1,2,3,4};//默认从小到大排序 1234 sort(vec.begin(),vec.end()); //从大到小排序 4321 sort(vec.begin(),vec.end(),greater<int>());二维向量vector<vector< int >> vector<vector<int>> vec{{0…...

机器学习 Q-Learning
对马尔可夫奖励的理解 看的这个教程 公式:V(s) R(s) γ * V(s’) V(s) 代表当前状态 s 的价值。 R(s) 代表从状态 s 到下一个状态 s’ 执行某个动作后所获得的即时奖励。 γ 是折扣因子,它表示未来奖励的重要性,通常取值在 0 到 1 之间。…...

产品设计心得体会 优漫动游
产品设计需要综合考虑用户需求、市场需求和技术可行性,从而设计出能够满足用户需求并具有市场竞争力的产品。以下是我在产品设计方面的心得体会: 产品设计心得体会 1.深入了解用户需求:在产品设计之前,需要进行充分的用户调研…...

前端--CSS
文章目录 CSS的介绍 引入方式 代码风格 选择器 复合选择器 (选学) 常用元素属性 背景属性 圆角矩形 Chrome 调试工具 -- 查看 CSS 属性 元素的显示模式 盒模型 弹性布局 一、CSS的介绍 层叠样式表 (Cascading Style Sheets). CSS 能够对网页中元素位置的排版进行像素级精…...
实操指南|如何用 OpenTiny Vue 组件库从 Vue 2 升级到 Vue 3
前言 根据 Vue 官网文档的说明,Vue2 的终止支持时间是 2023 年 12 月 31 日,这意味着从明年开始: Vue2 将不再更新和升级新版本,不再增加新特性,不再修复缺陷 虽然 Vue3 正式版本已经发布快3年了,但据我了…...

系统架构设计:15 论软件架构的生命周期
目录 一 软件架构的生命周期 1 需求分析阶段 2 设计阶段 3 实现阶段 4 构件组装阶段...

金山wps golang面试题总结
简单自我介绍如果多个协程并发写map 会导致什么问题如何解决(sync.map,互斥锁,信号量)chan 什么时候会发生阻塞如果 chan 缓冲区满了是阻塞还是丢弃还是panicchan 什么时候会 panic描述一下 goroutine 的调度机制goroutine 什么时…...

计算机视觉实战--直方图均衡化和自适应直方图均衡化
计算机视觉 文章目录 计算机视觉前言一、直方图均衡化1.得到灰度图2. 直方图统计3. 绘制直方图4. 直方图均衡化 二、自适应直方图均衡化1.自适应直方图均衡化(AHE)2.限制对比度自适应直方图均衡化(CRHE)3.读取图片4.自适应直方图均…...

501. 二叉搜索树中的众数
501. 二叉搜索树中的众数 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, leftNone, rightNone): # self.val val # self.left left # self.right right class Solution:def findMode(self, root: Option…...

【Linux】常用命令
目录 文件解压缩服务器文件互传scprsync 进程资源网络curl发送简单get请求发送 POST 请求发送 JSON 数据保存响应到文件 文件 ls,打印当前目录下所有文件和目录; ls -l,打印每个文件的基本信息 pwd,查看当前目录的路径 查看文件 catless:可以左右滚动阅读more :翻…...
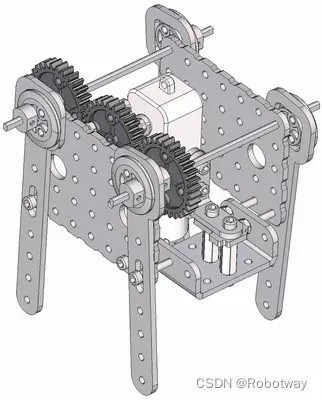
机器人制作开源方案 | 齿轮传动轴偏心轮摇杆简易四足
1. 功能描述 齿轮传动轴偏心轮摇杆简易四足机器人是一种基于齿轮传动和偏心轮摇杆原理的简易四足机器人。它的设计原理通常如下: ① 齿轮传动:通过不同大小的齿轮传动,实现机器人四条腿的运动。通常采用轮式齿轮传动或者行星齿轮传动…...
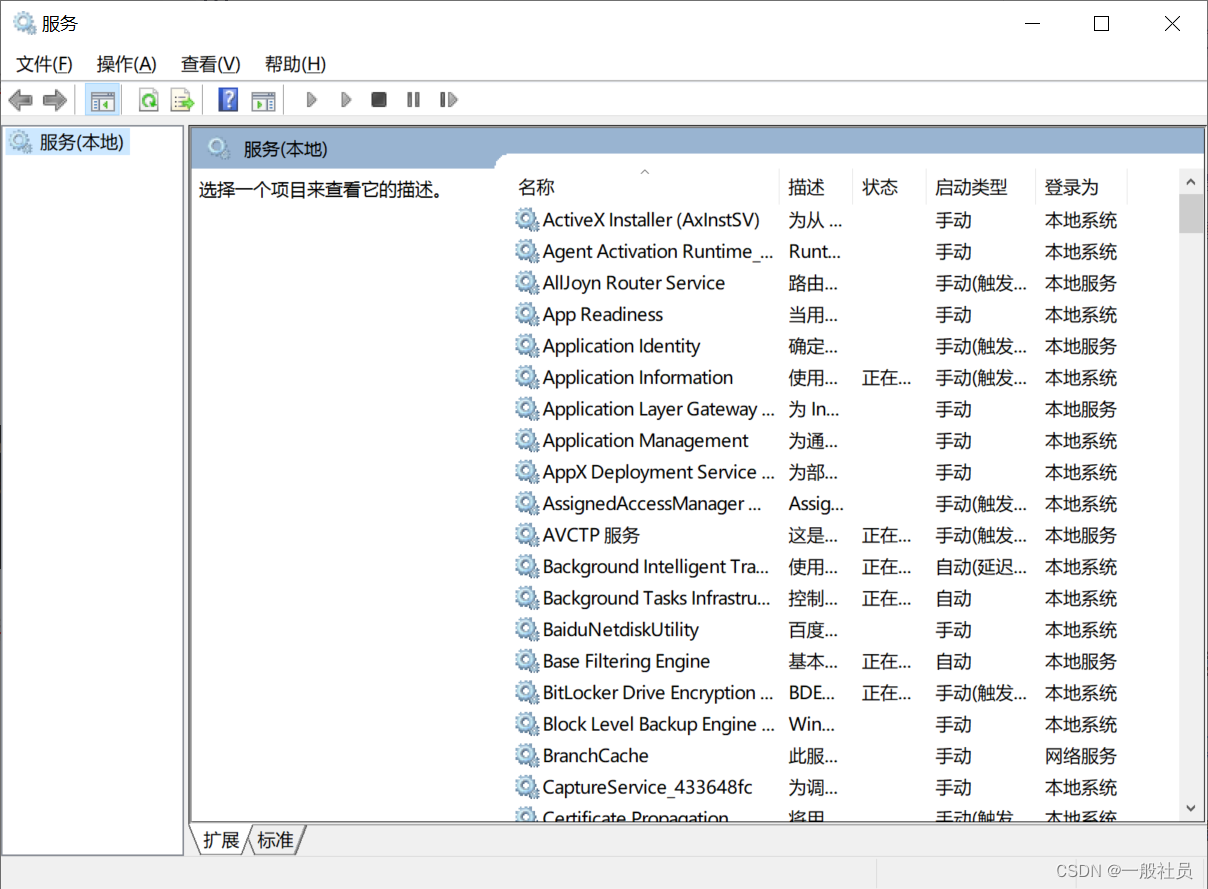
Windows中将tomcat以服务的形式安装,然后在服务进行启动管理
Windows中将tomcat以服务的形式安装,然后在服务进行启动管理 第一步: 在已经安装好的tomcat的bin目录下: 输入cmd,进入命令窗口 安装服务: 输入如下命令,最后是你的服务名,避免中文和特殊字符 service.…...
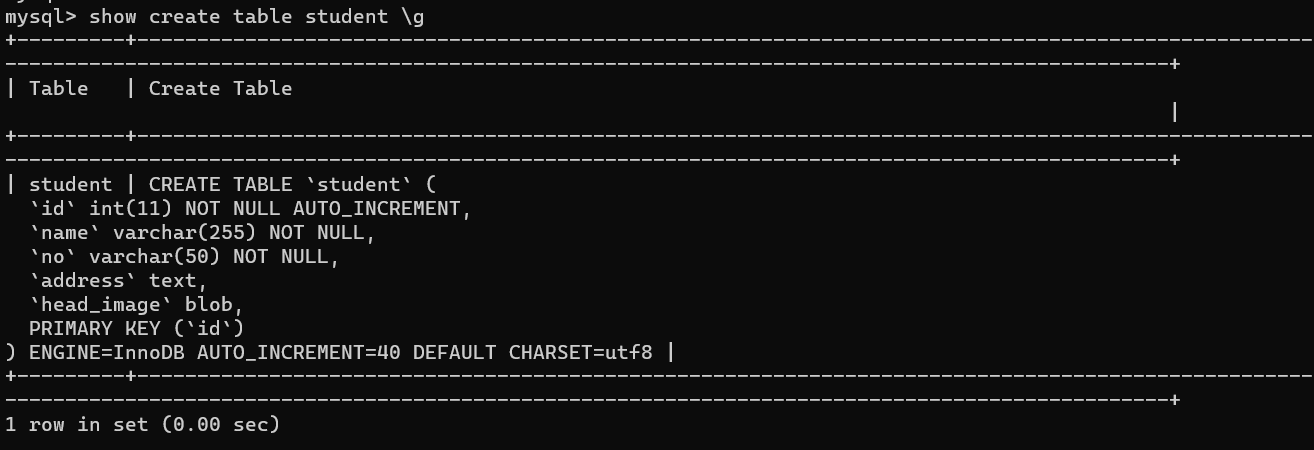
解决ERROR: No query specified的错误以及\G 和 \g 的区别
文章目录 1. 复现错误2. 分析错误3. 解决问题4. \G和\g的区别 1. 复现错误 今天使用powershell连接数据库后,执行如下SQL语句: mysql> select * from student where id 39 \G;虽然成功查询除了数据,但报出如下错误的信息: my…...

mysql中SUBSTRING_INDEX函数用法详解
MySQL中的SUBSTRING_INDEX函数用于从字符串中提取子字符串,其用法如下: SUBSTRING_INDEX(str, delim, count)参数说明: str:要提取子字符串的原始字符串。delim:分隔符,用于确定子字符串的位置。count&am…...

小红书自动评论的‘伪需求’与真风险:聊聊RPA工具养号背后的封号逻辑与合规玩法
小红书自动化评论的合规边界:效率与账号安全的博弈术 凌晨三点,某MCN机构运营负责人李然被连续不断的手机提示音惊醒——团队管理的12个小红书达人账号同时收到平台封禁通知,而这一切都源于他们三天前部署的那套"高效互动系统"。这…...

终极指南:PrivateGPT增量文档处理策略与动态更新解决方案
终极指南:PrivateGPT增量文档处理策略与动态更新解决方案 【免费下载链接】privateGPT 利用GPT的强大功能与你的文档进行互动,确保100%的隐私保护,无数据泄露风险 项目地址: https://gitcode.com/GitHub_Trending/pr/privateGPT Priva…...

从LVGL V7.11到V9.1:我维护中文文档这三年踩过的坑与实战经验
从LVGL V7.11到V9.1:一个中文文档维护者的技术叙事 三年前,当我第一次在嵌入式项目中尝试使用LVGL时,完全没想到这个轻量级图形库会成为我技术生涯中的重要篇章。作为国内最早系统维护LVGL中文文档的开发者之一,这段跨越三个大版本…...

C++ 自动微分引擎:基于模板元编程的静态反向传播梯度流构建
C 自动微分引擎:基于模板元编程的静态反向传播梯度流构建尊敬的各位专家、同行,大家好。今天,我们将深入探讨一个兼具理论深度与工程实践价值的主题:如何利用 C 的模板元编程(Template Metaprogramming)技术…...

Univer:企业级协作平台开发实战
Univer:企业级协作平台开发实战 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is driven directly throug…...

学习神经网络
一、神经网络概述:人工智能的核心基石(一)神经网络的定义与起源神经网络,全称为人工神经网络(Artificial Neural Network,ANN),是一种模仿生物神经网络(动物大脑神经元网…...

如何用Awesome-Obsidian打造个性化知识管理神器:终极美化指南
如何用Awesome-Obsidian打造个性化知识管理神器:终极美化指南 【免费下载链接】awesome-obsidian 🕶️ Awesome stuff for Obsidian 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-obsidian 想要将Obsidian从简单的Markdown编辑器变身为功…...

M2LOrder模型Typora写作辅助插件开发:实时监测文章情感基调
M2LOrder模型Typora写作辅助插件开发:实时监测文章情感基调 不知道你有没有过这样的经历:写了一篇技术文章,自己读起来总觉得哪里不对劲,但又说不出来具体问题。或者写产品文案时,明明想表达积极向上的情绪࿰…...

HoRain云--Vue3组件开发:从入门到精通的终极指南
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

**Flutter实战进阶:用自定义RenderObject打造高性能图表组件**在Flutter开发中,我们经
Flutter实战进阶:用自定义RenderObject打造高性能图表组件 在Flutter开发中,我们经常需要展示复杂的数据可视化效果,比如折线图、柱状图等。虽然社区已有不少成熟的图表库(如charts_flutter),但它们往往无法…...