@Autowired 到底是怎么把变量注入进来的?
@[toc] 在 Spring 容器中,当我们想给某一个属性注入值的时候,有多种不同的方式,例如可以通过构造器注入、可以通过 set 方法注入,也可以使用 @Autowired、@Inject、@Resource 等注解注入。
今天我就来和小伙伴们聊一聊,@Autowired 到底是如何把数据注入进来的。
@Service
public class AService {@AutowiredBService bService;
}
1. Bean 的创建
这个问题我们就得从 Bean 的创建开始了,本文主要是和小伙伴们聊 @Autowired,所以 Bean 的创建我就不从第一步开始了,咱们直接来看关键的方法,那就是 AbstractAutowireCapableBeanFactory#doCreateBean 方法:
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)throws BeanCreationException {//....Object exposedObject = bean;try {populateBean(beanName, mbd, instanceWrapper);exposedObject = initializeBean(beanName, exposedObject, mbd);}//...return exposedObject;
}
在这个方法中,首先会创建原始的 Bean 对象,创建出来之后,会调用一个 populateBean 方法,这个方法就是给 Bean 的各个属性赋值的方法,标注了 @Autowired 注解的属性被自动赋值也是在这个方法中完成的。
2. populateBean
populateBean 方法内容比较多,我们来看一些关键的地方:
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {// Give any InstantiationAwareBeanPostProcessors the opportunity to modify the// state of the bean before properties are set. This can be used, for example,// to support styles of field injection.if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {if (!bp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {return;}}}//...if (hasInstantiationAwareBeanPostProcessors()) {if (pvs == null) {pvs = mbd.getPropertyValues();}for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {PropertyValues pvsToUse = bp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);if (pvsToUse == null) {return;}pvs = pvsToUse;}}boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);if (needsDepCheck) {PropertyDescriptor[] filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);checkDependencies(beanName, mbd, filteredPds, pvs);}if (pvs != null) {applyPropertyValues(beanName, mbd, bw, pvs);}
}
这里我贴出来的是部分关键代码。
首先来看上面有一个 if,这个 if 主要是判断是否需要后置处理器进行处理,如果不需要,那么就直接 return 掉了,默认情况下,这里并不会 return 掉,而是会继续走后面的流程,因为 postProcessAfterInstantiation 方法默认返回 true。
接下来第二个 if 就是比较关键的一个地方了,在这里会遍历所有相关的后置处理器,尝试通过这些处理器去获取到需要的 value。
负责处理 @Autowired 注解的后置处理器是 AutowiredAnnotationBeanPostProcessor,所以现在,我们就来到 AutowiredAnnotationBeanPostProcessor#postProcessProperties 方法了。
3. postProcessProperties。
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);try {metadata.inject(bean, beanName, pvs);}catch (BeanCreationException ex) {throw ex;}catch (Throwable ex) {throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);}return pvs;
}
这个方法其实就两步,第一步 findAutowiringMetadata,第二步 inject,就这两件事。分别来看。
3.1 findAutowiringMetadata
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, @Nullable PropertyValues pvs) {// Fall back to class name as cache key, for backwards compatibility with custom callers.String cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());// Quick check on the concurrent map first, with minimal locking.InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);if (InjectionMetadata.needsRefresh(metadata, clazz)) {synchronized (this.injectionMetadataCache) {metadata = this.injectionMetadataCache.get(cacheKey);if (InjectionMetadata.needsRefresh(metadata, clazz)) {if (metadata != null) {metadata.clear(pvs);}metadata = buildAutowiringMetadata(clazz);this.injectionMetadataCache.put(cacheKey, metadata);}}}return metadata;
}
这个方法会先尝试从缓存中获取 metadata,如果能够从缓存中获取到,那就直接返回,缓存中没有的话,那么最终会调用到 buildAutowiringMetadata 方法,去重新构建 metadata,并将构建结果存入到缓存中,以备下一次使用。
那么我们来看下 metadata 到底是如何构建出来的。
private InjectionMetadata buildAutowiringMetadata(Class<?> clazz) {if (!AnnotationUtils.isCandidateClass(clazz, this.autowiredAnnotationTypes)) {return InjectionMetadata.EMPTY;}List<InjectionMetadata.InjectedElement> elements = new ArrayList<>();Class<?> targetClass = clazz;do {final List<InjectionMetadata.InjectedElement> currElements = new ArrayList<>();ReflectionUtils.doWithLocalFields(targetClass, field -> {MergedAnnotation<?> ann = findAutowiredAnnotation(field);if (ann != null) {if (Modifier.isStatic(field.getModifiers())) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation is not supported on static fields: " + field);}return;}boolean required = determineRequiredStatus(ann);currElements.add(new AutowiredFieldElement(field, required));}});ReflectionUtils.doWithLocalMethods(targetClass, method -> {Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {return;}MergedAnnotation<?> ann = findAutowiredAnnotation(bridgedMethod);if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {if (Modifier.isStatic(method.getModifiers())) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation is not supported on static methods: " + method);}return;}if (method.getParameterCount() == 0) {if (logger.isInfoEnabled()) {logger.info("Autowired annotation should only be used on methods with parameters: " +method);}}boolean required = determineRequiredStatus(ann);PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz);currElements.add(new AutowiredMethodElement(method, required, pd));}});elements.addAll(0, currElements);targetClass = targetClass.getSuperclass();}while (targetClass != null && targetClass != Object.class);return InjectionMetadata.forElements(elements, clazz);
}
这个方法比较长,我来和大家说一下核心逻辑。
首先会调用 isCandidateClass 方法判断当前类是否为一个候选类,判断的依据就是 autowiredAnnotationTypes 变量的值,这个变量在该类的构造方法中进行了初始化,大家来看下这个构造方法:
public AutowiredAnnotationBeanPostProcessor() {this.autowiredAnnotationTypes.add(Autowired.class);this.autowiredAnnotationTypes.add(Value.class);try {this.autowiredAnnotationTypes.add((Class<? extends Annotation>)ClassUtils.forName("jakarta.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));logger.trace("'jakarta.inject.Inject' annotation found and supported for autowiring");}catch (ClassNotFoundException ex) {// jakarta.inject API not available - simply skip.}try {this.autowiredAnnotationTypes.add((Class<? extends Annotation>)ClassUtils.forName("javax.inject.Inject", AutowiredAnnotationBeanPostProcessor.class.getClassLoader()));logger.trace("'javax.inject.Inject' annotation found and supported for autowiring");}catch (ClassNotFoundException ex) {// javax.inject API not available - simply skip.}
}
小伙伴们看到,autowiredAnnotationTypes 集合中有两个注解是固定的:@Autowired 和 @Value,另外就是如果项目引入了 JSR-330 依赖,则 @Inject 注解也会被加入进来,以前 @Inject 存在于 javax 包中,现在最新版 @Inject 注解存在于 jakarta 包中,这里把两种情况都列出来了。
所以,isCandidateClass 方法实际上就是判断当前类在类、属性、方法等层面上是否存在上述三个注解,如果存在,则就是候选类,否则就不是候选类。如果不是候选类则返回一个空的 InjectionMetadata 对象,否则就继续后面的流程。
后面的流程,首先是一个 do{}while() 结构,通过这个循环把当前类以及当前类的父类中的满足条件的注解都找出来。具体的找法就是首先调用 ReflectionUtils.doWithLocalFields 方法,这个方法会遍历当前类的所有属性,找到那些包含了 autowiredAnnotationTypes 中定义的注解的属性,并将之封装为 AutowiredFieldElement 对象,然后存入到集合中,接下来就是调用 ReflectionUtils.doWithLocalMethods,这个是找到当前类中包含了上述三个注解的方法,然后把找到的满足条件的方法封装为 AutowiredMethodElement 然后存入到集合中。
另外大家需要注意,无论是 AutowiredFieldElement 还是 AutowiredMethodElement,都是 InjectionMetadata.InjectedElement 的子类。
这就是 findAutowiringMetadata 方法所做的事情,整体上来看,就是查找到添加了 @Autowired 或者 @Value 或者 @Inject 注解的属性或者方法,并将之存入到集合中。
3.2 inject
接下来就该调用 metadata.inject 了,我们来看下该方法:
public void inject(Object target, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {Collection<InjectedElement> checkedElements = this.checkedElements;Collection<InjectedElement> elementsToIterate =(checkedElements != null ? checkedElements : this.injectedElements);if (!elementsToIterate.isEmpty()) {for (InjectedElement element : elementsToIterate) {element.inject(target, beanName, pvs);}}
}
这里就是遍历刚刚上一步收集到的 InjectedElement,然后挨个调用其 inject 方法进行属性注入。以本文一开始的 demo 为例,@Autowired 注解加在属性上面,所以我们这里实际上调用的是 AutowiredFieldElement#inject 方法:
@Override
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {Field field = (Field) this.member;Object value;if (this.cached) {try {value = resolvedCachedArgument(beanName, this.cachedFieldValue);}catch (NoSuchBeanDefinitionException ex) {// Unexpected removal of target bean for cached argument -> re-resolvevalue = resolveFieldValue(field, bean, beanName);}}else {value = resolveFieldValue(field, bean, beanName);}if (value != null) {ReflectionUtils.makeAccessible(field);field.set(bean, value);}
}
这段代码首先会调用 resolvedCachedArgument 方法尝试从缓存中获取想要的对象,如果缓存中存在,则可以直接使用,如果缓存中没有,则调用 resolveFieldValue 方法去获取。获取到之后,通过反射调用 set 方法进行赋值就可以了。所以关键步骤又来到了 resolveFieldValue 方法中。
用缓存的好处就是,获取到对象存入到缓存之后,如果相同的 Bean 在多个类中注入,那么只有第一次需要去加载,以后就直接用缓存中的数据即可。
@Nullable
private Object resolveFieldValue(Field field, Object bean, @Nullable String beanName) {//...Object value;try {value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter);}//...return value;
}
这个方法的核心其实就是通过 beanFactory.resolveDependency 方法获取到想要的 Bean 对象,我们直接来看这个核心方法,由于 BeanFactory 是一个接口,所以这个方法的实现实际上是在 DefaultListableBeanFactory#resolveDependency:
@Nullable
public Object resolveDependency(DependencyDescriptor descriptor, @Nullable String requestingBeanName,@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());if (Optional.class == descriptor.getDependencyType()) {return createOptionalDependency(descriptor, requestingBeanName);}else if (ObjectFactory.class == descriptor.getDependencyType() ||ObjectProvider.class == descriptor.getDependencyType()) {return new DependencyObjectProvider(descriptor, requestingBeanName);}else if (javaxInjectProviderClass == descriptor.getDependencyType()) {return new Jsr330Factory().createDependencyProvider(descriptor, requestingBeanName);}else {Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(descriptor, requestingBeanName);if (result == null) {result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);}return result;}
}
这里一共是四个分支,处理四种不同的情况,分别是 Optional、ObjectFactory、JSR-330 以及其他情况,很明显,文章开头的案例应该属于第四种情况,我们继续来看 doResolveDependency 方法。
3.3 doResolveDependency
这个方法也是比较长,我列出来了一些关键的部分:
@Nullable
public Object doResolveDependency(DependencyDescriptor descriptor, @Nullable String beanName,@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) throws BeansException {//...Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);if (multipleBeans != null) {return multipleBeans;}Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);if (matchingBeans.isEmpty()) {if (isRequired(descriptor)) {raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);}return null;}String autowiredBeanName;Object instanceCandidate;if (matchingBeans.size() > 1) {autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);if (autowiredBeanName == null) {if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {return descriptor.resolveNotUnique(descriptor.getResolvableType(), matchingBeans);}else {// In case of an optional Collection/Map, silently ignore a non-unique case:// possibly it was meant to be an empty collection of multiple regular beans// (before 4.3 in particular when we didn't even look for collection beans).return null;}}instanceCandidate = matchingBeans.get(autowiredBeanName);}else {// We have exactly one match.Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();autowiredBeanName = entry.getKey();instanceCandidate = entry.getValue();}Object result = instanceCandidate;return result;}finally {ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);}
}
首先是调用 resolveMultipleBeans 方法去查找多个 Bean,这是因为我们在注入的时候,可以注入数组、集合和 Map,例如像下面这样:
@Service
public class AService {@AutowiredBService bService;@AutowiredBService[] bServices;@AutowiredList<BService> bServiceList;@AutowiredMap<String, BService> bServiceMap;
}
具体查找方法如下:
@Nullable
private Object resolveMultipleBeans(DependencyDescriptor descriptor, @Nullable String beanName,@Nullable Set<String> autowiredBeanNames, @Nullable TypeConverter typeConverter) {Class<?> type = descriptor.getDependencyType();if (descriptor instanceof StreamDependencyDescriptor streamDependencyDescriptor) {Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);//...return stream;}else if (type.isArray()) {Class<?> componentType = type.getComponentType();ResolvableType resolvableType = descriptor.getResolvableType();Map<String, Object> matchingBeans = findAutowireCandidates(beanName, componentType,new MultiElementDescriptor(descriptor));return result;}else if (Collection.class.isAssignableFrom(type) && type.isInterface()) {Class<?> elementType = descriptor.getResolvableType().asCollection().resolveGeneric();Map<String, Object> matchingBeans = findAutowireCandidates(beanName, elementType,new MultiElementDescriptor(descriptor));return result;}else if (Map.class == type) {ResolvableType mapType = descriptor.getResolvableType().asMap();Map<String, Object> matchingBeans = findAutowireCandidates(beanName, valueType,new MultiElementDescriptor(descriptor));return matchingBeans;}else {return null;}
}
这里会首先判断你的数据类型,针对 Stream、数组、集合 以及 Map 分别处理,处理代码都很好懂,以集合为例,首先获取到集合中的泛型,然后调用 findAutowireCandidates 方法根据泛型去查找到 Bean,处理一下返回就行了,其他几种数据类型也都差不多。
至于 findAutowireCandidates 方法的逻辑,我们就不去细看了,我大概和小伙伴们说一下,就是先根据 Bean 的类型,调用 BeanFactoryUtils.beanNamesForTypeIncludingAncestors 方法去当前容器连同父容器中,查找到所有满足条件的 Bean,处理之后返回。
接下来回到本小节一开始的源码中,处理完集合之后,接下来也是调用 findAutowireCandidates 方法去查找满足条件的 Bean,但是这个方法查找出来的 Bean 可能有多个,如果存在多个,则要通过 @Primary 注解或者其他优先级顺序,去确定到底使用哪一个(执行 determineAutowireCandidate 方法),如果查找到一个 Bean,那就把找到的 Bean 返回即可。
这就是 @Autowired 一个完整的解析过程。
4. 时序图
最后,结合如下时序图,我再和小伙伴们梳理一下上面的过程。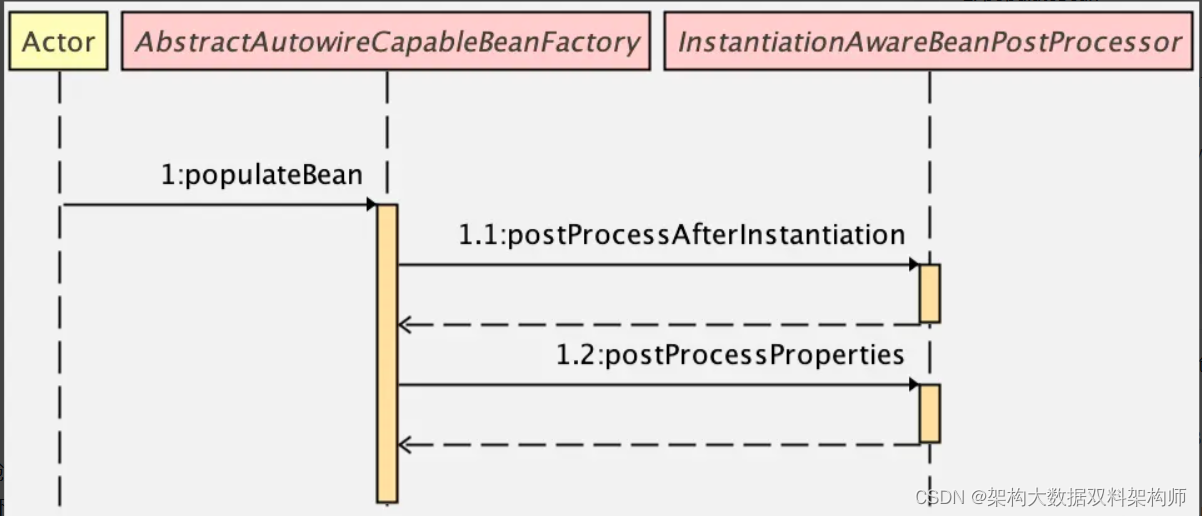
- 在创建 Bean 的时候,原始 Bean 创建出来之后,会调用 populateBean 方法进行 Bean 的属性填充。
- 接下来调用 postProcessAfterInstantiation 方法去判断是否需要执行后置处理器,如果不需要,就直接返回了。
- 调用 postProcessProperties 方法,去触发各种后置处理器的执行。
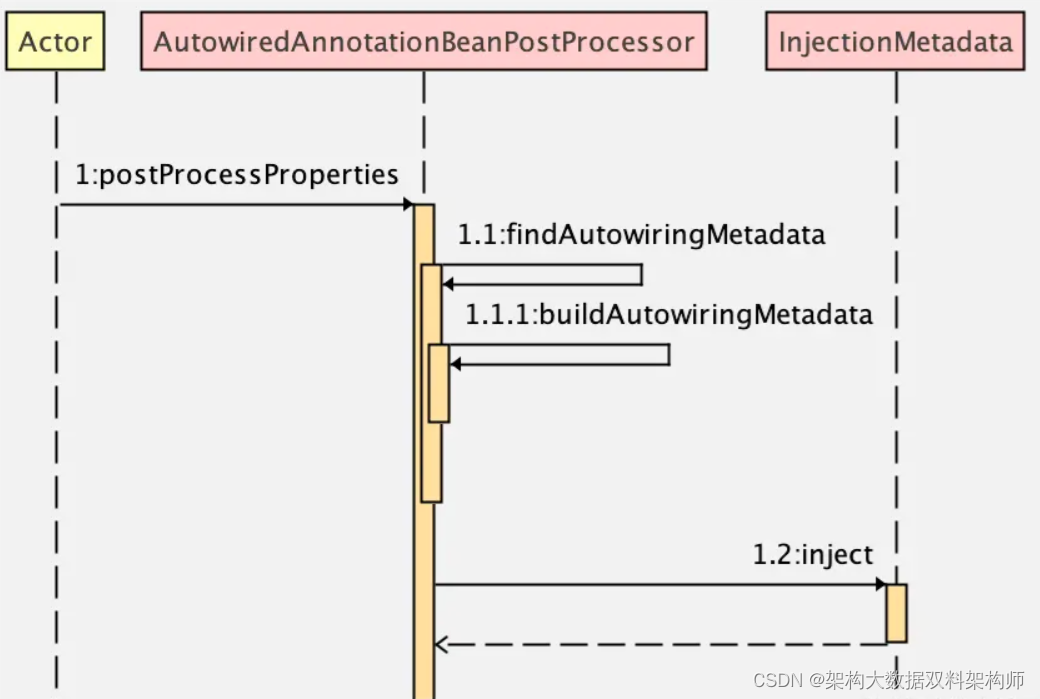
今天内容有点多,小伙伴们周末可以细细 DEBUG 验证一遍
- 在第 3 步的方法中,调用 findAutowiringMetadata,这个方法又会进一步触发 buildAutorwiringMetadata 方法,去找到包含了 @Autowired、@Value 以及 @Inject 注解的属性或者方法,并将之封装为 InjectedElement 返回。
- 调用 InjectedElement#inject 方法进行属性注入。
- 接下来执行 resolvedCachedArgument 方法尝试从缓存中找到需要的 Bean 对象。
- 如果缓存中不存在,则调用 resolveFieldValue 方法去容器中找到 Bean。
- 最后调用 makeAccessible 和 set 方法完成属性的赋值。
相关文章:
@Autowired 到底是怎么把变量注入进来的?
[toc] 在 Spring 容器中,当我们想给某一个属性注入值的时候,有多种不同的方式,例如可以通过构造器注入、可以通过 set 方法注入,也可以使用 Autowired、Inject、Resource 等注解注入。 今天我就来和小伙伴们聊一聊,Au…...

【Python学习笔记】函数
1. 函数组成 Python中,我们是这样定义函数的: def function(para1, para2):print("func start")print(para1)print(para2)print("func end")print("让技术总监面试 求职者")return "func return"def 是关键字…...

简单实现一个todoList(上移、下移、置顶、置底)
演示 html部分 <!DOCTYPE html> <html> <head><title>表格示例</title> </head> <body><table border"1"><thead><tr><th>更新时间</th><th>操作</th></tr></thead…...

计算机视觉:池化层的作用是什么?
本文重点 在深度学习中,卷积神经网络(CNN)是一种非常强大的模型,广泛应用于图像识别、目标检测、自然语言处理等领域。而池化层作为CNN中的一个关键步骤,扮演着优化神经网络、提升深度学习性能的重要角色。本文将深入探讨池化层的作用及其重要性,帮助读者更好地理解和应…...

luffy项目前端创建、配置、解决跨域问题、后端数据库迁移
前端 创建前端vue 使用vue-cil创建前端将无用的东西删除 配置 跟后端交互:axios 安装插件:cnpm install -S axios在main.js中写import axios from "axios"; Vue.prototype.$axios axios后续使用就直接this.$axios即可 操作cookie&am…...

电商数据API接口:新服务下电商网站、跨境电商独立站,移动APP的新型拉新武器
互联网的发展改变了我们的生活方式,也改变了企业商家们的营销方式,越来越多的企业商家把产品营销从线下转到线上,选择在线商城、移动APP、微信公众号等互联网工具进行营销活动。而随着营销模式的多元化和电子支付渠道的进一步发展,…...

多线程并发篇---第十一篇
系列文章目录 文章目录 系列文章目录前言一、CAS的原理二、CAS有什么缺点吗?三、引用类型有哪些?有什么区别?前言 一、CAS的原理 CAS叫做CompareAndSwap,比较并交换,主要是通过处理器的指令来保证操作的原子性,它包含 三个操作数: 变量内存地址,V表示旧的预期值,A表示…...

JVM第六讲:JVM 基础 - Java 内存模型引入
JVM 基础 - Java 内存模型引入 很多人都无法区分Java内存模型和JVM内存结构,以及Java内存模型与物理内存之间的关系。本文是JVM第六讲,从堆栈角度引入JMM,然后介绍JMM和物理内存之间的关系, 为后面JMM详解, JVM 内存结构详解, Java 对象模型详…...

机房安全管理制度
#安全运维管理制度# 1、总则 1.1、目的 为进一步规范XXXXX单位机房安全管理工作,防止未经授权的访问,做好机房的防火、防盗等工作,确保XXXXX单位机房物理设施的安全,制定本制度。 1.2、范围 本制度适用于XXXXX单位机房的安全…...
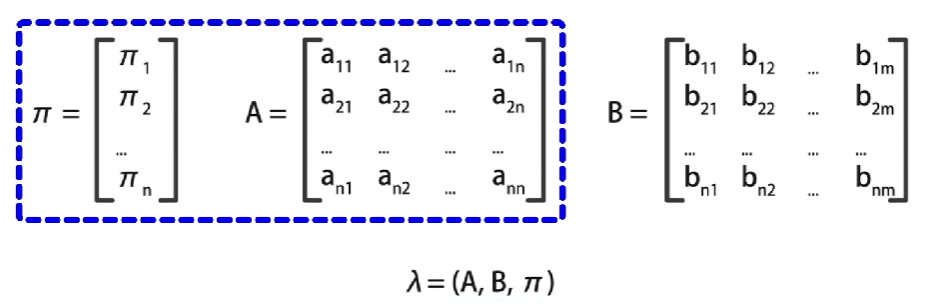
【自然语言处理】— 隐马尔可夫模型详解、例解
【自然语言处理】— 隐马尔可夫模型 【自然语言处理】— 隐马尔可夫模型引例隐马尔可夫模型概念隐马尔可夫模型的关键隐马尔可夫模型的数学表示隐含状态与观测结果状态转移矩阵观测概率矩阵初始状态概率向量 小结 【自然语言处理】— 隐马尔可夫模型 引例 假设有三种不同的骰…...

运行的 akrun 会打印信息到控制台,如何取消打印 -- chatGPT
gpt: 如果运行的程序 akrun 打印信息到控制台,但您希望取消或禁止它的输出,可以尝试以下方法: 1. **重定向输出到空文件**:您可以将程序的标准输出重定向到一个空文件,从而禁止信息输出到控制台。执行以下命令&#…...

【React】03-React面向组件编程2
文章目录 2.6. 组件的生命周期2.6.1. 效果2.6.2. 理解2.6.3. 生命周期流程图(旧)2.6.4. 生命周期流程图(新)2.6.5. 重要的勾子2.6.6. 即将废弃的勾子2.6.7 getSnapshotBeforeUpdate 2.7. 虚拟DOM与DOM Diffing算法2.7.1. 效果2.7.2. 基本原理图 2.6. 组件的生命周期 2.6.1. 效…...

【python编程】python无法import模块的一种原因分析
python系统路径添加错误 报错原因原因分析解决办法补充 最近写代码的时候遇到一个问题,就是想添加工程下fu_convert文件夹下自己编写的convert_fw.py模块,但是出现报错,是个比较低级的问题,但还是简单记录一下 报错原因 无法找到…...

vue3.0与vue2.0的区别
前言 Vue 3.0是一个用于构建用户界面的JavaScript框架。相比于Vue 2.x,Vue 3.0在性能、体积和开发体验上都有了很大的提升。 以下将从不同的角度上去分析Vue 3.0与Vue 2.0的区别: 一、项目架构 从项目搭建和打包工具的选择来看: Vue 2.0 中…...
09_Webpack打包工具
1 初识Webpack 1.1 什么是Webpack Webpack打包工具对项目中的复杂文件进行打包处理,可以实现项目的自动化构建,并且给前端开发人员带来了极大的便利。 目前,企业中的绝大多数前端项目是基于Webpack打包工具来进行开发的。 1.2 Webpack的安…...

小程序 | 小程序后端用什么语言开发比较好
目录 ♣️ 引言 选择合适的后端语言 推荐使用Node.js Node.js 的优点 其他备选语言 ♣️ 小结 ♣️ 引言 小程序的兴起已经成为了当今移动互联网时代的热点之一,而小程序后端的好坏直接影响着小程序的使用体验,因此,选择一种好的语言来…...
Websocket升级版
之前写过一个关于websocket的博客,是看书时候做的一个demo。但是纸上得来终觉浅,这次实战后实打实的踩了不少坑,写个博客记录总结。 1.安装postman websocket接口调试,需要8.5以及以上版本的postman 先把以前的卸载,…...
基于音频SOC开发板的主动降噪ANC算法源码实现
基于音频SOC开发板的主动降噪ANC算法源码实现 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群附加赠送降噪开发资料,...
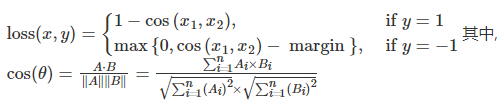
【Pytorch】深度学习之损失函数
文章目录 二分类交叉熵损失函数交叉熵损失函数L1损失函数MSE损失函数平滑L1(Smooth L1)损失函数目标泊松分布的负对数似然损失KL散度MarginRankingLoss多标签边界损失函数二分类损失函数多分类的折页损失三元组损失HingEmbeddingLoss余弦相似度CTC损失函数参考资料 学习目标&am…...

3.4 构造方法
思维导图: 3.4.1 定义构造方法 ### Java中的构造方法 #### **定义与目的** 构造方法,也称为构造器,是一个特殊的成员方法,用于在实例化对象时为对象赋值或执行初始化操作。其主要目的是确保对象在被创建时具有有效和合适的初始状…...
来帮忙)
Linux内存不够用吧 Linux 交换内存(Swap)来帮忙
Linux内存不够用吧 Linux 交换内存(Swap)来帮忙 Linux 交换内存(Swap)完全指南:概念、配置与性能优化 我开发了一款内存管理工具,内存管理工具下载地址 1. 什么是交换内存(Swap)&a…...

微信聊天记录年度报告怎么生成?实测这款工具,一键导出HTML还能做可视化分析
从数据到故事:用专业工具打造你的微信聊天年度可视化报告 微信聊天记录早已不只是简单的文字交流,它们承载着人际关系的发展脉络、重要时刻的见证以及日常生活的点滴。将这些碎片化的对话转化为结构化的年度报告,不仅能帮助我们回顾过去一年…...
)
如何在树莓派上用TinyProxy搭建轻量级HTTP代理(附性能优化技巧)
树莓派上部署TinyProxy的工程实践与深度调优指南 当你在咖啡厅用树莓派搭建的微型服务器调试物联网设备时,突然发现所有外网请求都需要经过代理——这就是TinyProxy在嵌入式场景下的典型应用。不同于x86服务器的部署,在ARM架构的树莓派上运行代理服务需要…...

别再死记硬背了!用74HC系列CMOS芯片,手把手带你理解逻辑门电平与噪声容限
74HC系列CMOS芯片实战:从数据手册到面包板的逻辑门电平全解析 当你在深夜调试一块74HC04反相器搭建的振荡电路时,示波器上本该清晰的方波却出现了毛刺和畸变——这种场景对电子爱好者来说再熟悉不过。本文将以74HC系列CMOS芯片为核心,通过五…...

、SEATA分布式事务——XA模式
指令替换 项目需求:将加法指令替换为减法 项目目录如下 /MyProject ├── CMakeLists.txt # CMake 配置文件 ├── build/ #构建目录 │ └── test.c #测试编译代码 └── mypass2.cpp # pass 项目代码 一,测试代码示例 test.c // test.c #includ…...

Bluesky AI助手Attie:用户不满下的未来挑战
Attie:定制化社交媒体动态新尝试Bluesky正在开发的新型AI助手Attie,以AT协议命名,可创建定制化的社交媒体动态。它作为一个独立的可选应用程序,目前处于仅限受邀用户参与的封闭测试阶段。其目标是打造一个比单纯搜索话题更全面的时…...

forkrun:革新数据处理,突破传统并行工具性能瓶颈
【导语:forkrun 作为一款自调优工具,可直接替代 GNU Parallel 和 xargs -P。它在现代 CPU 上能显著提升基于 Shell 的数据准备速度,尤其在 NUMA 架构上表现出色,为数据处理领域带来了新的变革。】数据处理速度的飞跃:5…...

Phi-4-mini-reasoning:轻量级推理模型在人工智能浪潮中的定位
Phi-4-mini-reasoning:轻量级推理模型在人工智能浪潮中的定位 1. 轻量级推理模型的时代价值 当ChatGPT等千亿参数大模型占据媒体头条时,一个容易被忽视的趋势正在悄然兴起——轻量级推理模型正在特定领域展现出惊人的实用性。Phi-4-mini-reasoning正是…...

大麦网自动购票工具:技术原理与多场景应用指南
大麦网自动购票工具:技术原理与多场景应用指南 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 在数字化票务时代,热门演出门票往往在开票瞬间售罄&…...

QueryExcel:解放双手的Excel批量查询神器,告别Ctrl+F的繁琐时代
QueryExcel:解放双手的Excel批量查询神器,告别CtrlF的繁琐时代 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 在日常工作中,你是否也曾被海量Excel文件中的数据查找…...