单链表---结构体实现
定义
链表称为线性表的链式存储,顺序表逻辑上相邻的数据,存储位置也相邻。链表逻辑上相邻的数据,存储位置是随机分布在内存的各个位置上的。
故
对于每一个结点,定义的结构体是:
typedef struct _LinkNode
{int date; //数据域,存储数据,这里是int类型的数据struct _LinkNode* next; // 指针域,指向了后继元素(下一个结点)的地址
}LinkNode , LinkList; //两个别名的作用是一模一样的,只是为了区分头结点和结点链表的初始化
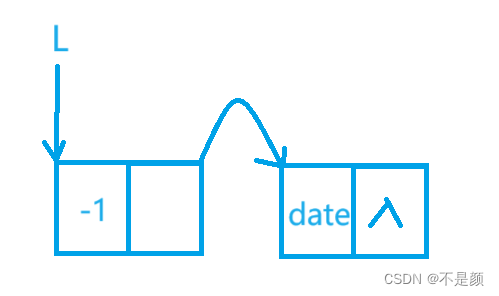
我们用一个结构体指针L来指向链表,最开始是带一个头结点的空链表,头结点的数据域一般赋值为-1,也可以存储着链表的长度。头结点的指针域指针第一个元素结点,最开始是没有元素结点的空链表(有头结点),如图:

代码实现
bool initLinkList(LinkList*& L) //参数是对结构体指针的引用
{L = new LinkList; //也可以写成 L = new LinkNode ;if (!L){return false; // 申请内存失败,返回了一个空指针}L->next = NULL;return true;
}链表的插入
头插法
将新结点插到头结点的后面,有两种形式,一是链表为空,二是链表中已有元素结点,如图
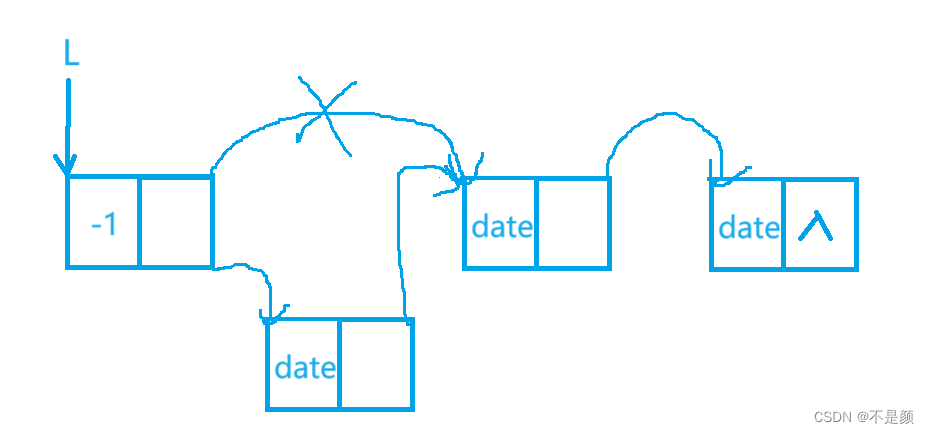
你可以分情况,不过也可以不用,例如:
bool insertLinkList(LinkList*& L, LinkNode *node) //node指向要添加的结点
{if (!L || !node) return false;node->next = L->next; //包含两种情况L->next = node;return true;
}尾插法
尾插,顾名思义就是在最后一个结点插入之后,也分两种情况,一是链表为空,二是链表中已有元素结点,第一种情况的图和头插法的第一种情况的图一样,就是插入方式不同,以下是第二种情况的图: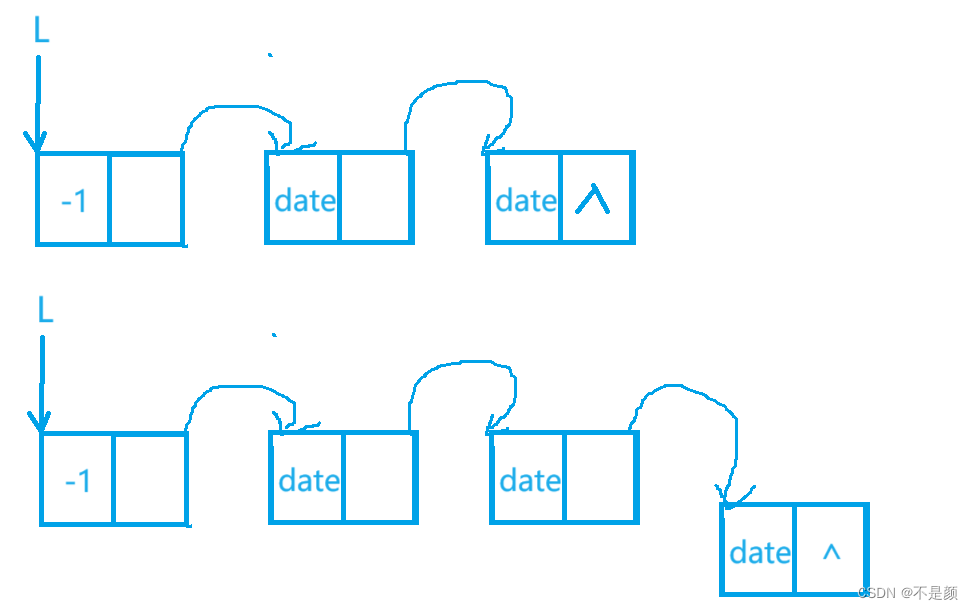
我们只需要找到 next 指向 NULL 的这个结点就好了
bool LinkListinsert(LinkList*& L, LinkNode *node)
{if (!L || !node) return false;LinkNode* p = NULL;p = L;while (p->next != NULL) //如果是空链表,p == L,所以是包含两种情况{p = p->next;}node->next = p->next;p->next = node;return true;
}指定位置插入
在第 i 个结点前插入,那么我们就必须有个临时指针指向第 i-1 个结点
bool InsertLink(LinkList*& L, int i, int e) // 这里也可以用之前的LinkNode *node参数,不过可能i不合法
{if (!L) return false;LinkNode* p = L , *s = NULL ;int j = 0;while (p && j < i - 1) // 指向第 i-1 个结点{ p = p->next;j++;}//如果在第0个位置之前插入(i<1) || 如果在最后一个结点+2的位置之前插入(i>n+1,n为链表长度)---都是非法的if (i < 1 || !p) return false;s = new LinkNode;s->date = e;s->next = p->next;p->next = s;return true;
}遍历链表(打印链表)
bool PrintLinkList(LinkList *& L)
{if(!L) return false; LinkNode* p = L->next; //首先指向第一个结点,如果为空链表就会指向 NULLwhile (p != NULL) // 直到指向最后一个结点的 next 指针(NULL){printf("%d ", p->date);p = p->next;}cout << endl;return true;
}遍历链表,也可以用来求链表的长度,代码与这个类似。
链表的获取
获取链表第 i 个结点的数据域。
bool GetElemLink(LinkList*& L, int i, int &e) //e返回获取的数据域
{LinkNode* p = L;int j = 0;while ( p!=NULL && j < i){p = p->next;j++;}if (p==NULL || i < 1) //i是非法的:i > n(n为链表长度,例如:获取第n+1个结点的数据域)或者是 i < 1(例如:获取了第0个结点的数据域){return false;}e = p->date;return true;
}链表的查找
查找我们输入的元素在链表中出现的第一个位置。
bool FindElem(LinkList* L, int e,int &index) // index返回位置
{if (!L || !L->next) return false; //空链表LinkNode* p = L->next; // 现在指向第一个结点int j = 1; while (p != NULL && p->date != e) {p = p->next;j++;}if (p == NULL)return false;else{index = j;return true;}
}
链表的删除
删除第 i 个结点,i 可能不合法,注意不合法的原因。
bool DeleteLinkNode(LinkList*& L, int i)
{LinkNode* p = NULL , *q = NULL;p = L;int j = 0;while ( p->next!=NULL && j < i - 1){p = p->next;j++;}// 指向第 i-1 个结点if (i < 1 || p->next == NULL) //i非法,删除第0个结点(i<1) 或者是 删除第n+1个结点(i>n,n为链表的长度)return false;else{q = p->next;p->next = q->next ;delete q;return true;}}链表的销毁(清空)
销毁就是要归还所申请的内存,删除某个结点时,一定要保存下一个结点的地址。简要解释:先保存第一个结点的地址,随后删除头结点(也申请了空间),再保存第二个结点的地址,删除第一个结点,再保存第三个结点……以此类推,可以将全部结点删除。
void DestoryLink(LinkList*& L)
{LinkNode* p = NULL, * q = NULL;p = L;while (p != NULL){ q = p->next;//cout << "删除元素" << p->date << endl;delete p;p = q;}}总代码
以下是全部代码,链表的函数有不同的实现方法。也许我的代码和别人有些差异,所以可以看看 main 函数中是怎样的。
#define _CRT_SECURE_NO_WARNINGS 1#include <iostream>using namespace std;typedef struct _LinkNode
{int date; //数据域struct _LinkNode* next; // 指针域}LinkNode , LinkList;//初始化链表
bool initLinkList(LinkList*& L)
{L = new LinkList;if (!L){return false;}L->next = NULL;return true;
}//前插法
bool insertLinkList(LinkList*& L, LinkNode *node)
{if (!L || !node) return false;node->next = L->next;L->next = node;return true;
}//尾插法
bool LinkListinsert(LinkList*& L, LinkNode *node)
{if (!L || !node) return false;LinkNode* p = NULL;p = L;while (p->next != NULL){p = p->next;}node->next = p->next;p->next = node;return true;
}//在第i个结点前插入---指定位置插入
bool InsertLink(LinkList*& L, int i, int e)
{if (!L) return false;LinkNode* p = L , *s = NULL ;int j = 0;while (p && j < i - 1){ p = p->next;j++;}//如果在第0个位置之前插入(i<1) || 如果在最后一个结点+2的位置之前插入(i>n+1,n为链表长度)---都是非法的if (i < 1 || !p) return false;s = new LinkNode;s->date = e;s->next = p->next;p->next = s;return true;
}//打印链表
void PrintLinkList(LinkList *& L)
{LinkNode* p = L->next;while (p != NULL){printf("%d ", p->date);p = p->next;}cout << endl;
}//获取第i个结点的数据元素
bool GetElemLink(LinkList*& L, int i, int &e)
{LinkNode* p = L;int j = 0;while ( p!=NULL && j < i){p = p->next;j++;}if (p==NULL || i < 1){return false;}e = p->date;return true;
}//在链表中查找元素,并且用index返回位置
bool FindElem(LinkList* L, int e,int &index)
{if (!L || !L->next) return false;LinkNode* p = L->next;int j = 1;while (p && p->date != e){p = p->next;j++;}if (p == NULL)return false;else{index = j;return true;}
}//删除第i个结点
bool DeleteLinkNode(LinkList*& L, int i)
{LinkNode* p = NULL , *q = NULL;p = L;int j = 0;while ( p->next!=NULL && j < i - 1){p = p->next;j++;}if (i < 1 || p->next == NULL) //删除第0个结点(i<1) 或者是 删除第n+1个结点(i>n,n为链表的长度)return false;else{q = p->next;p->next = q->next ;delete q;return true;}}//清空(销毁)链表
void DestoryLink(LinkList*& L)
{LinkNode* p = NULL, * q = NULL;p = L;while (p != NULL){ q = p->next;//cout << "删除元素" << p->date << endl;delete p;p = q;}}
int main(void)
{LinkList* L = NULL; //指向表头(头结点)的指针LinkNode* e = NULL; //指向结点的指针initLinkList(L);int elem = 0; //结点的数据元素int i; //第几个结点int n = 0; //输入的个数int flag = -1;while (flag != 0){cout << "1.前插链表" << endl<< "2.尾插链表" << endl<< "3.指定位置前插入" << endl<< "4.打印链表" << endl<< "5.获取第i个结点的数据" << endl<< "6.查找元素" << endl<<"7.删除元素"<<endl<< "0.退出(销毁链表)" << endl;cout << "请选择:";cin >> flag;switch (flag){case 1:cout << "请输入前插法插入链表的个数";cin >> n;cout << "请依次输入" << n << "个数:";while (n--){e = new LinkNode;cin >> e->date;insertLinkList(L, e);}break;case 2:cout << "请输入尾插入链表的个数";cin >> n;cout << "请依次输入" << n << "个数:";while (n--){e = new LinkNode;cin >> e->date;LinkListinsert(L, e);}break;case 3:cout << "请输入插入的位置和元素:";cin >> i >> elem;InsertLink(L, i, elem);break;case 4:PrintLinkList(L);break;case 5:cout << "请输入要获取的结点i:";cin >> i;if (GetElemLink(L, i, elem)){cout << "第" << i << "个结点的值为" << elem << endl;}else{cout << "获取元素失败" << endl;}break;case 6:cout << "请输入要查找的元素:";cin >> elem;if (FindElem(L, elem, i)){cout << "找到了,此元素的位置是" << i << endl;}else{cout << "表中无此值" << endl;}break;case 7:cout << "请输入要删除的结点i:";cin >> i;if (DeleteLinkNode(L, i)){cout << "删除成功" << endl;}else{cout << "删除失败" << endl;}break;case 0:DestoryLink(L);break;default:cout << "输入非法! " << endl;break;}}return 0;
}这里也可以将代码复制,自己调试测试一下,删除某些代码,看看会有什么影响,更能理解。
相关文章:
单链表---结构体实现
定义 链表称为线性表的链式存储,顺序表逻辑上相邻的数据,存储位置也相邻。链表逻辑上相邻的数据,存储位置是随机分布在内存的各个位置上的。 故 对于每一个结点,定义的结构体是: typedef struct _LinkNode {int d…...

Linux Shell 编程基础语法汇总
读 Jetson 脚本 把脚本设置为可执行 假设要将脚本 test.sh 设置为可执行,需要: 使用 chmod x test.sh 改变文件模式为可执行;使用 ./ 指定路径,比如先将当前工作区设置为脚本所做位置(使用 cd 命令),然后…...
github 中关于Pyqt 的module view 操作练习
代码摘自,Pyside6 中的示例代码部分 # -*- coding: utf-8 -*- import sys from PySide6.QtWidgets import * from PySide6.QtGui import * from PySide6.QtCore import * from PySide6.QtSql import QSqlDatabase, QSqlQueryModel, QSqlQuery import os os.chdir(os…...
【操作系统】磁臂黏着现象
文章目录 什么是磁臂黏着?为什么 FCFS(First Come First Service) 可以避免磁臂黏着?为什么 scan,cscan 会产生磁臂黏着?为什么 NsetpScan 可以避免磁臂黏着?NScan 原理简介NScan 避免磁臂黏着的…...
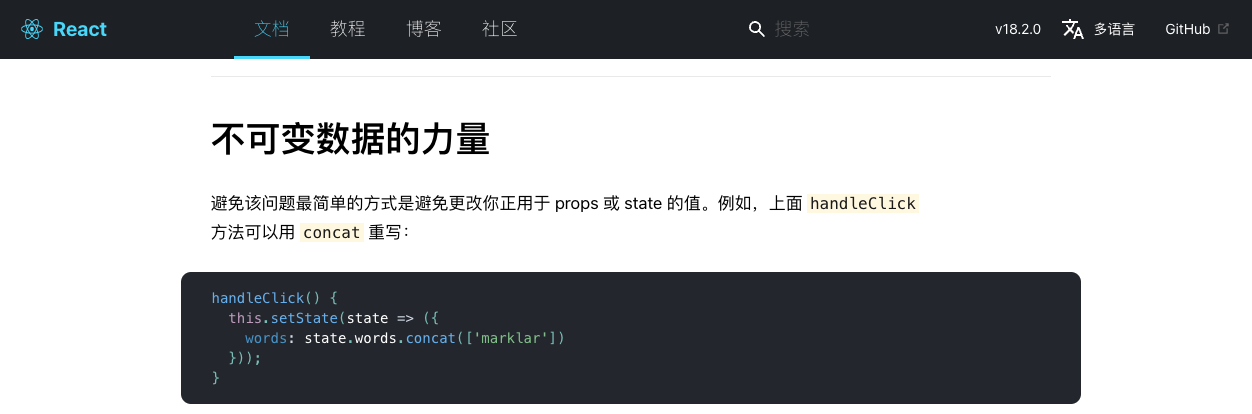
面试题-React(十二):React中不可变数据的力量
一、不可变数据的概念 不可变数据意味着数据一旦创建,就不能被更改。在React中,每次对数据的修改都会返回一个新的数据副本,而不会改变原始数据。这种方式确保了数据的稳定性和一致性。 二、Props中的不可变数据 在React中,组件…...
conda 创建虚拟环境
1.为什么要创建虚拟环境 我们在做开发或者跑论文实验可能会同时进行多个任务,这些任务可能会依赖于不同的python环境,比如有的用到3.6有的用到3.7,这时我们创建不同版本的python,放到虚拟环境中给不同的任务分别提供其所需要的版本…...

Java的HTML转义工具
引言 在开发web应用程序时,我们经常需要处理用户输入的数据并将其显示在网页上。然而,用户输入的数据可能包含HTML标签或特殊字符,如果直接在网页上显示这些数据,会导致XSS攻击或显示错误的结果。为了解决这个问题,我…...
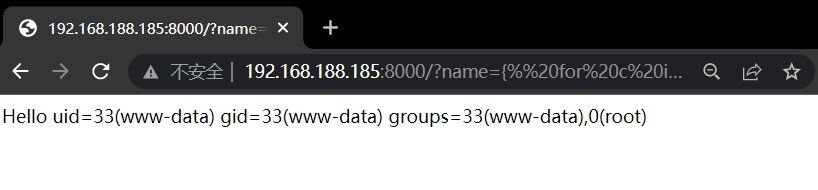
Flask (Jinja2) 服务端模板注入漏洞复现
文章目录 Flask (Jinja2) 服务端模板注入漏洞1.1 漏洞描述1.2 漏洞原理1.3 漏洞危害1.4 漏洞复现1.4.1 漏洞利用 1.5 漏洞防御 Flask (Jinja2) 服务端模板注入漏洞 1.1 漏洞描述 说明内容漏洞编号漏洞名称Flask (Jinja2) 服务端模板注入漏洞漏洞评级高危影响版本使用Flask框架…...

file_get_contents 与curl 的对比
在讲区别前大家对file_get_contents 只是停留在get 方法其实file_get_contents也可以进行post请求该方法如下 $content []; $options array(http > array(method > POST,// header 需要设置为 JSONheader > Content-type:application/json,content > json_en…...

两个el-date-picker进行互相关联
elementui两个el-date-picker进行互相关联_element-ui两个时间控件进行联动_沈清秋.的博客-CSDN博客...
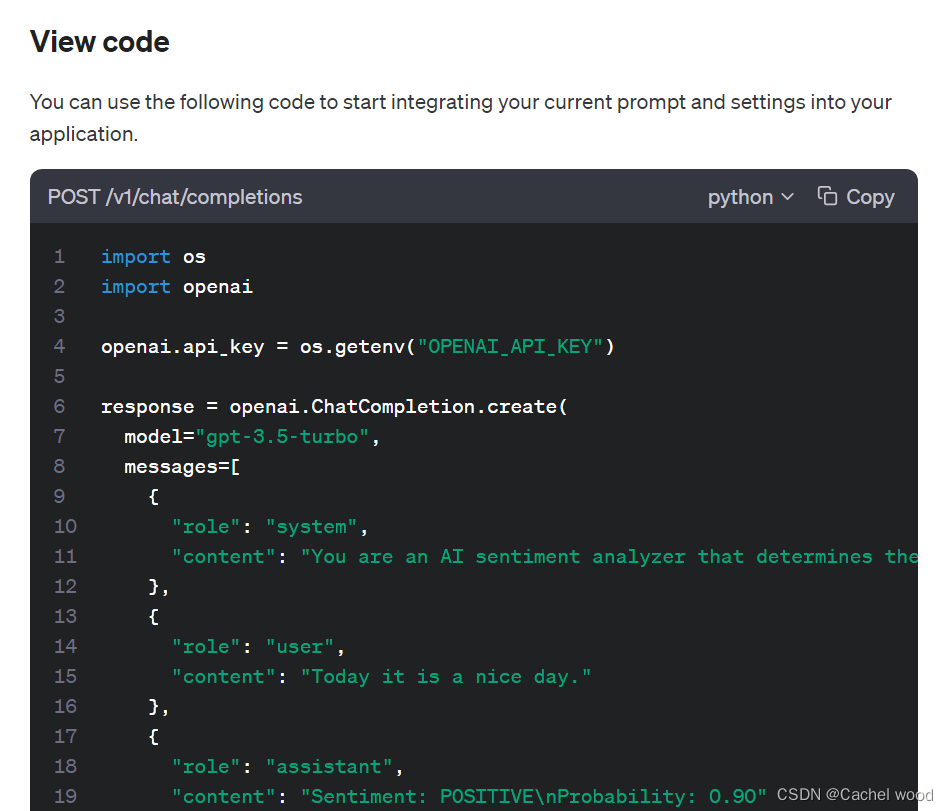
python openai playground使用教程
文章目录 playground介绍Playground特点模型设置和参数选择四种语言模型介绍 playground应用构建自己的playground应用playground python使用 playground介绍 OpenAI Playground是一个基于Web的工具,旨在帮助开发人员测试和尝试OpenAI的语言模型,如GPT-…...

DOCKER本地仓库
概述 随着docker的应用越来越多,安装部署越来越方便,批量自动化的镜像生成和发布都需要docker仓库的本地化应用。 试用了docker的本地仓库功能,简单易上手,记录下来以备后用。 环境 centos:CentOS release 7.0 (F…...

python写着玩
摄氏温度转化为华氏温度 #摄氏温度转化为华氏温度 celsius float(input("请输入摄氏度:")) fahrenheit(9/5)*celsius32 print("华氏温度是%.1f"%fahrenheit) 计算圆柱体的体积 #计算圆柱体的体积 radius , length map( float,input("请…...
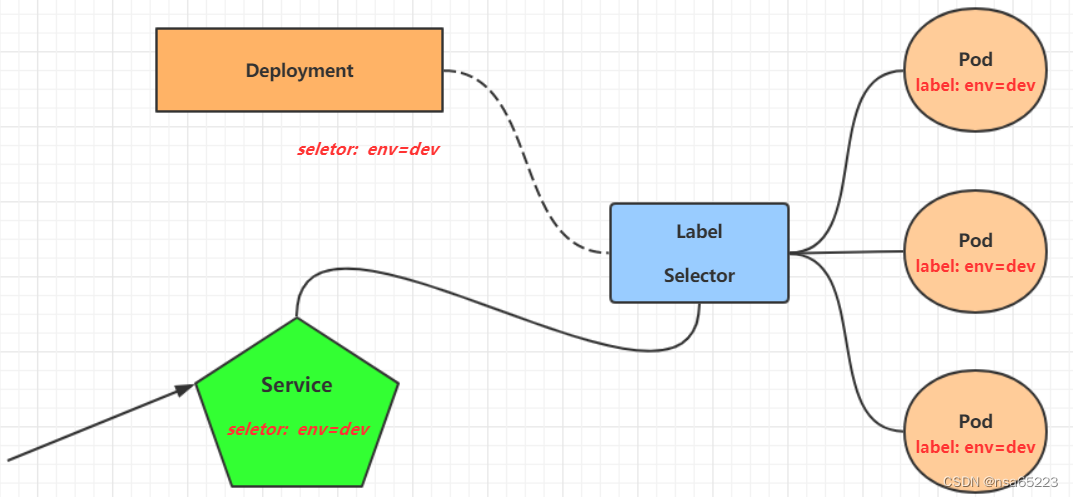
K8s Kubernetes Namespave Pod Label Deployment Service 实战
本章节将介绍如何在kubernetes集群中部署一个nginx服务,并且能够对其进行访问。 Namespace Namespace是kubernetes系统中的一种非常重要资源,它的主要作用是用来实现多套环境的资源隔离或者多租户的资源隔离。 默认情况下,kubernetes集群中…...

SpringBoot使用随机端口启动
1.获取可用端口工具类 import java.net.InetAddress; import java.net.Socket; import java.util.Random;public class ServerPortUtil {private static final int MAX_PORT 65535;private static final int MIN_PORT 8000;public static String getAvailablePort() {Random…...
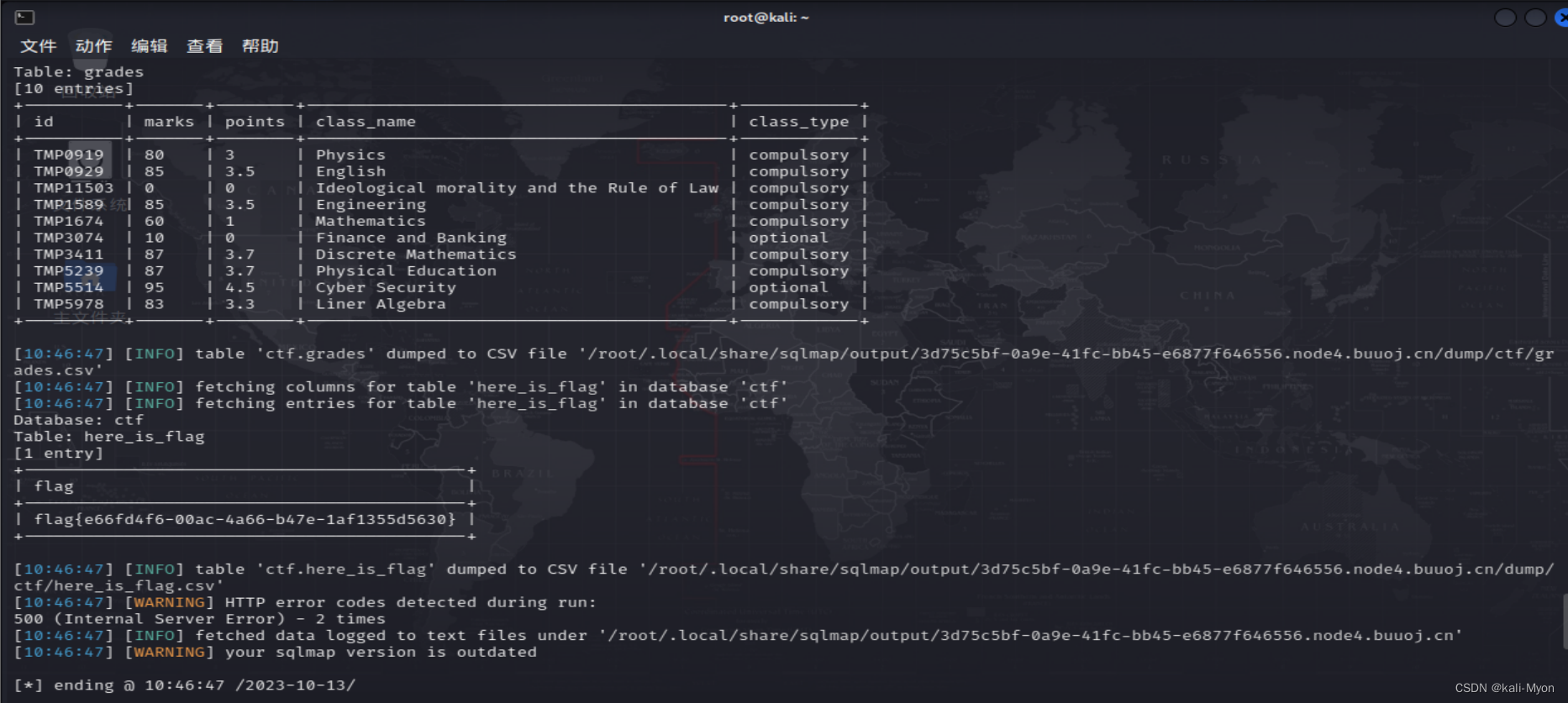
NewStarCTF2023week2-ez_sql
闭合之后尝试判断字段数,存在WAF,使用大小写绕过(后面的sql语句也需要进行大小写绕过) ?id1 Order by 5-- 测出有5列 ?id1 Order by 6-- 查一下数据库名、版本、用户等信息 ?id1Union Select database(),version(),user(),4,…...

力扣-434.字符串中的单词数
Idea 利用C中的 stringstream 指定字符分割字符串 class Solution { public:int countSegments(string s) {int cnt 0;stringstream ss(s);string word;while(ss >> word){cnt;}return cnt;} };...
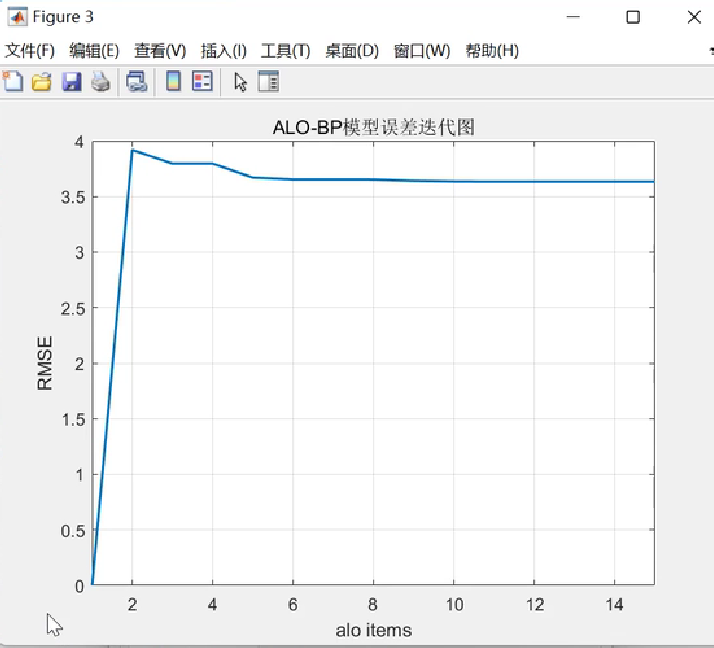
【ALO-BP预测】基于蚁狮算法优化BP神经网络回归预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
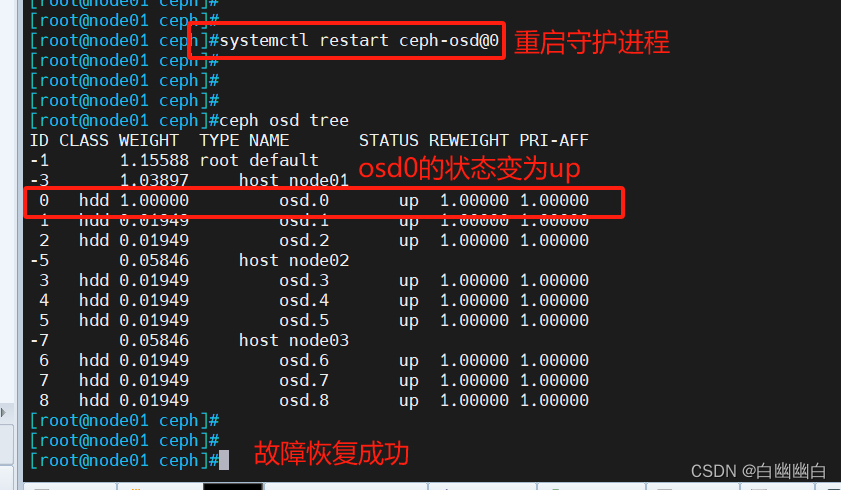
分布式存储系统Ceph应用详解
Ceph的应用 一、Ceph 存储池(Pool)1.1 Ceph存储池的基本概念1.2 原理1.3 一个Pool资源池应该包含多少PG数?1.4 Ceph 存储池相关管理命令1.4.1 创建1.4.2 查看1.4.3 修改1.4.4 删除 二、 CephFS文件系统MDS接口三、创建CephFS文件系统MDS接口3.1 服务端操作Step1 在管…...

人工智能轨道交通行业周刊-第63期(2023.10.9-10.15)
本期关键词:一体化智慧列车运行系统、车辆数字化运维管理、智能传感器、PHM、LKJ 1 整理涉及公众号名单 1.1 行业类 RT轨道交通人民铁道世界轨道交通资讯网铁路信号技术交流北京铁路轨道交通网上榜铁路视点ITS World轨道交通联盟VSTR铁路与城市轨道交通RailMetro…...

GLM-4.1V-9B-Base保姆级教学:Web界面截图+问题输入框最佳实践
GLM-4.1V-9B-Base保姆级教学:Web界面截图问题输入框最佳实践 1. 认识GLM-4.1V-9B-Base GLM-4.1V-9B-Base是智谱开源的视觉多模态理解模型,专门用于处理图像内容识别、场景描述、目标问答和中文视觉理解任务。这个模型已经完成了Web化封装,可…...

如何将笔记从 iCloud 传输到 iPhone:分步指南
iPhone 上的“备忘录”应用是一款便捷的工具,可以用来记录待办事项、日记、想法等等。它能帮助我们追踪需要完成的事情。借助 iCloud 的自动同步功能,你的备忘录可以安全地存储在云端,并可通过任何 Apple 设备甚至电脑访问。将笔记从 iPhone …...
Pixel Couplet Gen实操手册:自定义门神像素图替换与SVG动画扩展方法
Pixel Couplet Gen实操手册:自定义门神像素图替换与SVG动画扩展方法 1. 项目概述 Pixel Couplet Gen是一款融合传统春节元素与现代像素艺术风格的AI春联生成工具。通过ModelScope大模型的文本生成能力,结合精心设计的8-bit视觉风格,为用户提…...

Serilog:从结构化日志认知到 .NET 工程落地
MySQL 中的 count 三兄弟:效率大比拼! 一、快速结论(先看结论再看分析) 方式 作用 效率 一句话总结 count(*) 统计所有行数 最高 我是专业的!我为统计而生 count(1) 统计所有行数 同样高效 我是 count(*) 的马甲兄弟…...

通义千问1.8B-Chat部署教程:Supervisor管理服务,稳定运行不中断
通义千问1.8B-Chat部署教程:Supervisor管理服务,稳定运行不中断 1. 项目概述 通义千问1.5-1.8B-Chat-GPTQ-Int4是阿里云推出的轻量级对话模型,经过GPTQ-Int4量化后,显存需求仅约4GB,非常适合在消费级GPU或边缘设备上…...
)
手把手教你用Qwen2.5-Omni-7B:一个模型搞定文本、图片、音频和视频(附Python代码示例)
实战Qwen2.5-Omni-7B:全模态AI开发指南 第一次听说一个模型能同时处理文本、图片、音频和视频时,我的反应和大多数开发者一样——既兴奋又怀疑。直到亲手用Python调用了Qwen2.5-Omni-7B的API,看着它准确描述视频内容、回答图片问题、甚至生成…...

Qwen3.5-2B图文理解教程:GIF动图逐帧理解+动态内容总结生成方法
Qwen3.5-2B图文理解教程:GIF动图逐帧理解动态内容总结生成方法 1. 引言 Qwen3.5-2B是一款轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。这款模型主打低功耗、低门槛部署,特别适配端侧和边缘设备&am…...

Qt桌面应用集成PaddleOCR:从环境搭建到精准识别的实践指南
1. 环境准备:搭建PaddleOCR的Qt开发环境 第一次在Qt里折腾PaddleOCR时,我对着官方文档折腾了半天还是报错,后来发现是第三方库的路径没配好。这里分享下我踩坑后总结的可靠方案。 核心依赖三件套:PaddlePaddle推理库、PaddleOCR C…...

Anaconda虚拟环境管理:为春联生成模型创建独立Python空间
Anaconda虚拟环境管理:为春联生成模型创建独立Python空间 你是不是也遇到过这种情况?电脑上装了好几个Python项目,有的需要TensorFlow 2.0,有的却只能用TensorFlow 1.x,结果为了运行一个项目,把整个系统的…...

MongoDB高级面试:进阶面试题50题及答案详解
更多内容请见: 《深入掌握MongoDB数据库》 - 专栏介绍和目录 文章目录 一、高级查询优化与执行计划 (8题) 二、高级索引策略 (8题) 三、高级分片策略与优化 (8题) 四、性能调优与瓶颈分析 (7题) 五、高级复制集配置与故障处理 (6题) 六、高级事务与一致性模型 (5题) 七、安全高…...