Elasticsearch系列组件:Kibana无缝集成的数据可视化和探索平台
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。
Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析等,都有广泛的应用。
本文将介绍 Elastic Stack 组件 Kibana 的介绍、安装与简单使用。
文章目录
- 1、Kibana介绍与安装
- 1.1、Kibana简介
- 1.2、下载安装
- 1.3、关于配置
- 1.4、启动访问
- 2、Kibana数据可视化
- 2.1、演示数据准备
- 2.2、数据可视化配置
- 2.3、配置柱状图
- 2.4、配置线图
- 2.5、配置饼状图
- 3、Kibana更多功能
- 3.1、数据探索
- 3.2、仪表盘
1、Kibana介绍与安装
1.1、Kibana简介
Kibana 是一个开源的数据分析和可视化平台,它是 Elastic Stack(包括 Elasticsearch、Logstash、Kibana 和 Beats)的一部分,主要用于对 Elasticsearch 中的数据进行搜索、查看、交互操作。
Kibana 的主要功能和用途包括:
-
数据可视化:Kibana 提供了丰富的数据可视化选项,如柱状图、线图、饼图、地图等,帮助用户以图形化的方式理解数据。
-
数据探索:Kibana 提供了强大的数据探索功能,用户可以使用 Elasticsearch 的查询语言进行数据查询,也可以通过 Kibana 的界面进行数据筛选和排序。
-
仪表盘:用户可以将多个可视化组件组合在一起,创建交互式的仪表盘,用于实时监控数据。
-
机器学习:Kibana 还集成了 Elasticsearch 的机器学习功能,可以用于异常检测、预测等任务。
-
定制和扩展:Kibana 提供了丰富的 API 和插件系统,用户可以根据自己的需求定制和扩展 Kibana。
总的来说,Kibana 是一个强大的数据分析和可视化工具,它可以帮助用户更好地理解和探索他们的数据。
1.2、下载安装
Elastic 公司的官方下载页面的链接。在这个页面上,你可以下载 Elastic Stack 的各个组件,包括 Elasticsearch、Kibana、Logstash、Beats 等。这个页面提供了各个组件的最新版本下载链接,以及历史版本的下载链接:Past Releases of Elastic Stack Software | Elastic
在这里,我们将选择 Kibana,并确保所选的 Kibana 版本与我们正在使用的 Elasticsearch 版本一致:

选择后选择「Download」开始下载,并在下载成功后解压到指定位置即可。
1.3、关于配置
Kibana 的配置文件通常是 kibana.yml,位于 Kibana 安装目录的 config 文件夹下。这个配置文件是 YAML 格式,用于定义 Kibana 的运行参数。
...
# =================== System: Kibana Server (Optional) ===================
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "localhost"# =================== System: Elasticsearch ===================
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://localhost:9200"]# If your Elasticsearch is protected with basic authentication, these settings provide
# the username and password that the Kibana server uses to perform maintenance on the Kibana
# index at startup. Your Kibana users still need to authenticate with Elasticsearch, which
# is proxied through the Kibana server.
elasticsearch.username: "kibana_system"
elasticsearch.password: "pass"
...
以下是一些常用的 Kibana 配置项:
- server.port:Kibana 服务监听的端口,默认为 5601。
- server.host:Kibana 服务的主机地址。默认情况下,它设置为本地主机。如果你希望 Kibana 服务可以被远程主机访问,你可以将此设置为远程主机的 IP 地址。
- server.name:Kibana 服务的名称。默认情况下,它设置为
your-hostname。 - elasticsearch.hosts:Kibana 连接 Elasticsearch 服务的地址。默认情况下,它设置为连接到本地主机的 Elasticsearch,端口为
9200,即localhost:9200。 - elasticsearch.username 和 elasticsearch.password:连接到 Elasticsearch 服务时使用的用户名和密码。默认情况下,Elasticsearch 是没有用户名和密码的。但是,如果你在 Elasticsearch 中安装了 X-pack 插件并设置了密码,你需要在这里填写正确的用户名和密码。
这里如果我们 Elasticsearch 是在本地的,那么不用修改任何配置直接启动就可以了
设置页面中文:
# Supported languages are the following: English (default) "en", Chinese "zh-CN", Japanese "ja-JP", French "fr-FR".
i18n.locale: "zh-CN"
1.4、启动访问
启动文件位于 /bin/Kibana 目录下。启动 Kibana 后,可能需要稍等片刻,Kibana 才能完成启动过程。一旦启动完成,你就可以通过访问 http://localhost:5601 来使用 Kibana 了。
2、Kibana数据可视化
2.1、演示数据准备
为了让 Kibana 的图形更美观,我们需要准备一些具有多元化数据的索引。以下是一个简单的例子,我们将创建一个包含销售数据的索引,数据包括日期、产品类别、销售额等字段。
首先,我们需要在 Elasticsearch 中创建一个名为 “sales” 的索引,并添加一些数据。以下是使用 Elasticsearch 的 REST API 添加数据的示例:
# 创建索引
curl -X PUT "localhost:9200/sales"# 添加销售数据
curl -X POST "localhost:9200/sales/_doc" -H 'Content-Type: application/json' -d'
{"date": "2020-01-04","category": "Groceries","revenue": 2000
}
'
curl -X POST "localhost:9200/sales/_doc" -H 'Content-Type: application/json' -d'
{"date": "2020-01-05","category": "Electronics","revenue": 3000
}
'
curl -X POST "localhost:9200/sales/_doc" -H 'Content-Type: application/json' -d'
{"date": "2020-01-06","category": "Books","revenue": 2500
}
'
curl -X POST "localhost:9200/sales/_doc" -H 'Content-Type: application/json' -d'
{"date": "2020-01-07","category": "Clothing","revenue": 1200
}
'
curl -X POST "localhost:9200/sales/_doc" -H 'Content-Type: application/json' -d'
{"date": "2020-01-08","category": "Groceries","revenue": 1800
}
'
# ... 添加更多数据 ...2.2、数据可视化配置
在 Kibana 中,我们可以使用 “Visualize” 功能来创建各种数据可视化。以下是创建柱状图、线图、饼图等的基本步骤:
- 打开 Kibana:在浏览器中输入 Kibana 的地址,打开 Kibana 的主界面;
- 进入 Visualize 页面:在左侧导航栏中,点击 “Visualize Library” 图标,进入 Visualize 页面;
- 创建数据视图:点击「创建数据视图」按钮,选择想要创建的可视化类型,如柱状图、线图、饼图等:
- 选择数据源:在新的页面中,选择你想要可视化的数据源。你可以选择已经存在的索引模式,也可以创建新的索引模式:
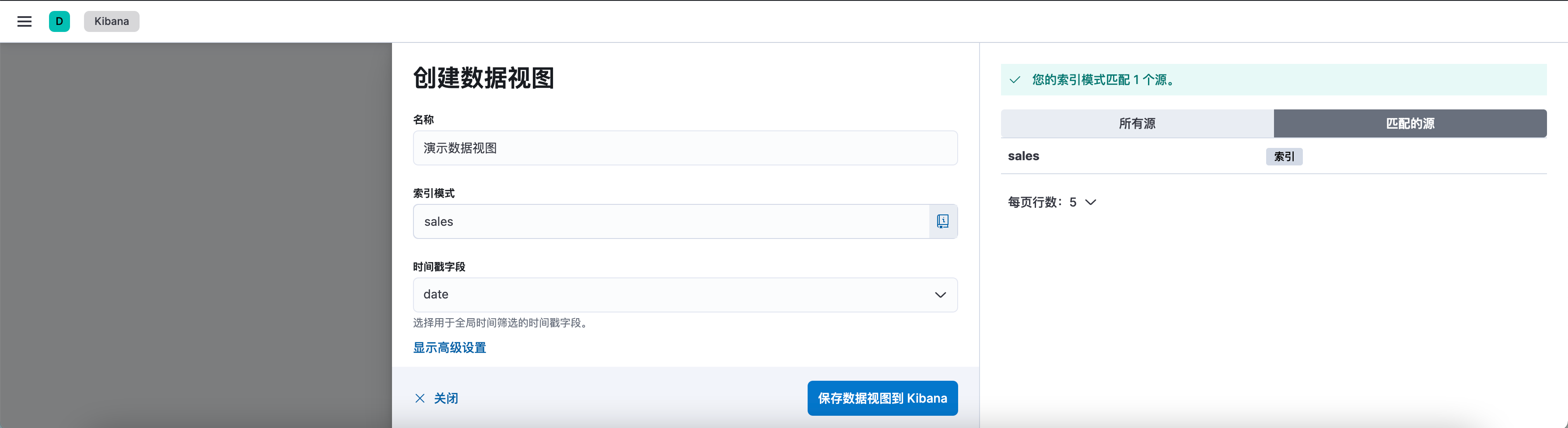
- 保存视图:点击「保存数据视图到 Kibana」,保存成功;
- 配置可视化:根据你选择的可视化类型,配置相应的参数。例如,对于柱状图,你需要选择 X 轴和 Y 轴的字段;对于线图,你需要选择时间字段和度量字段;对于饼图,你需要选择分割切片的字段。
2.3、配置柱状图
点击「新建可视化」按钮,选择 “垂直条形图” 选项来创建柱状图。
在 “桶” 部分,你需要选择 X 轴和 Y 轴的字段。对于 X 轴,你可以选择一个分类字段;对于 Y 轴,你可以选择一个数值字段,并选择一个聚合函数,如 “计数”、“平均值”、“总和” 等。
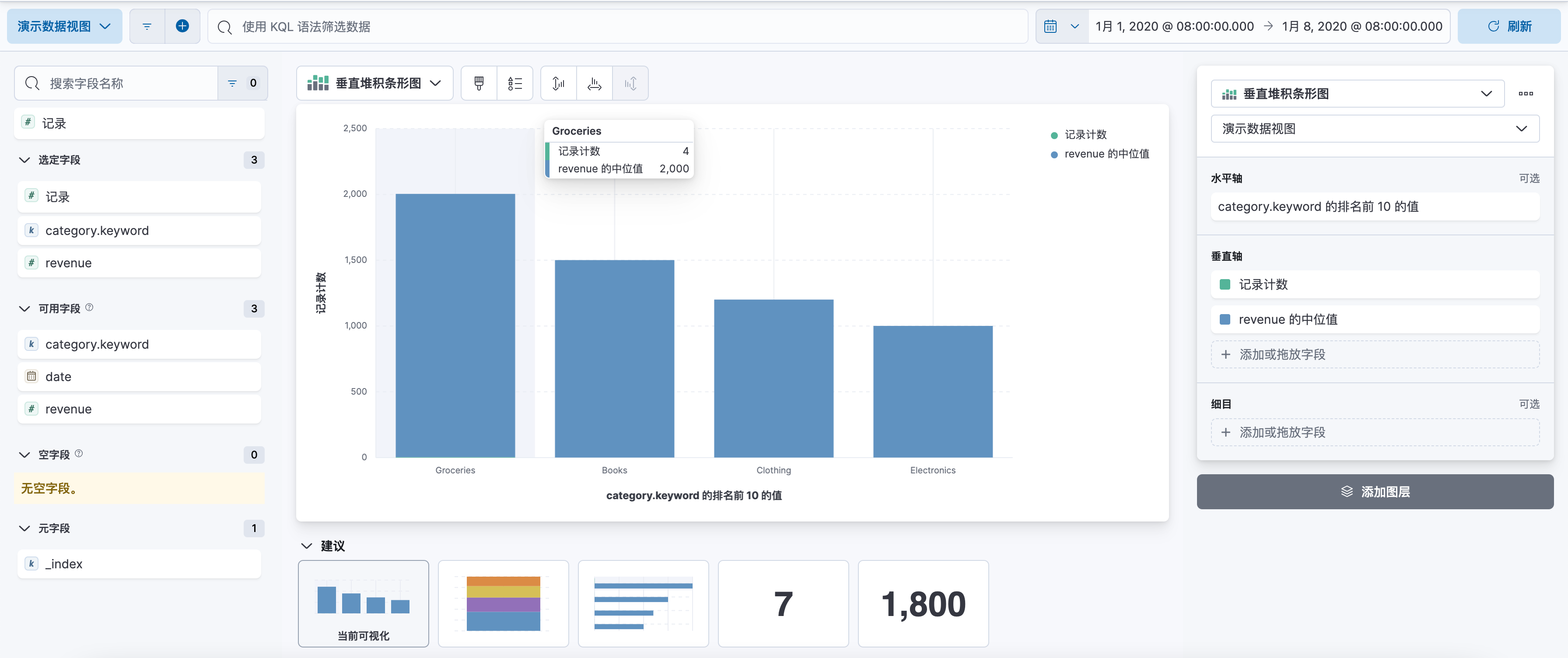
配置完成后,你可以预览你的柱状图。如果满意,点击「保存」按钮,为你的柱状图命名并保存。
2.4、配置线图
点击「新建可视化」按钮,选择 “折线图” 选项来创建线图。
在 “桶” 部分,你需要选择 X 轴和 Y 轴的字段。对于 X 轴,你通常会选择一个时间字段;对于 Y 轴,你可以选择一个数值字段,并选择一个聚合函数,如 “计数”、“平均值”、“总和” 等。
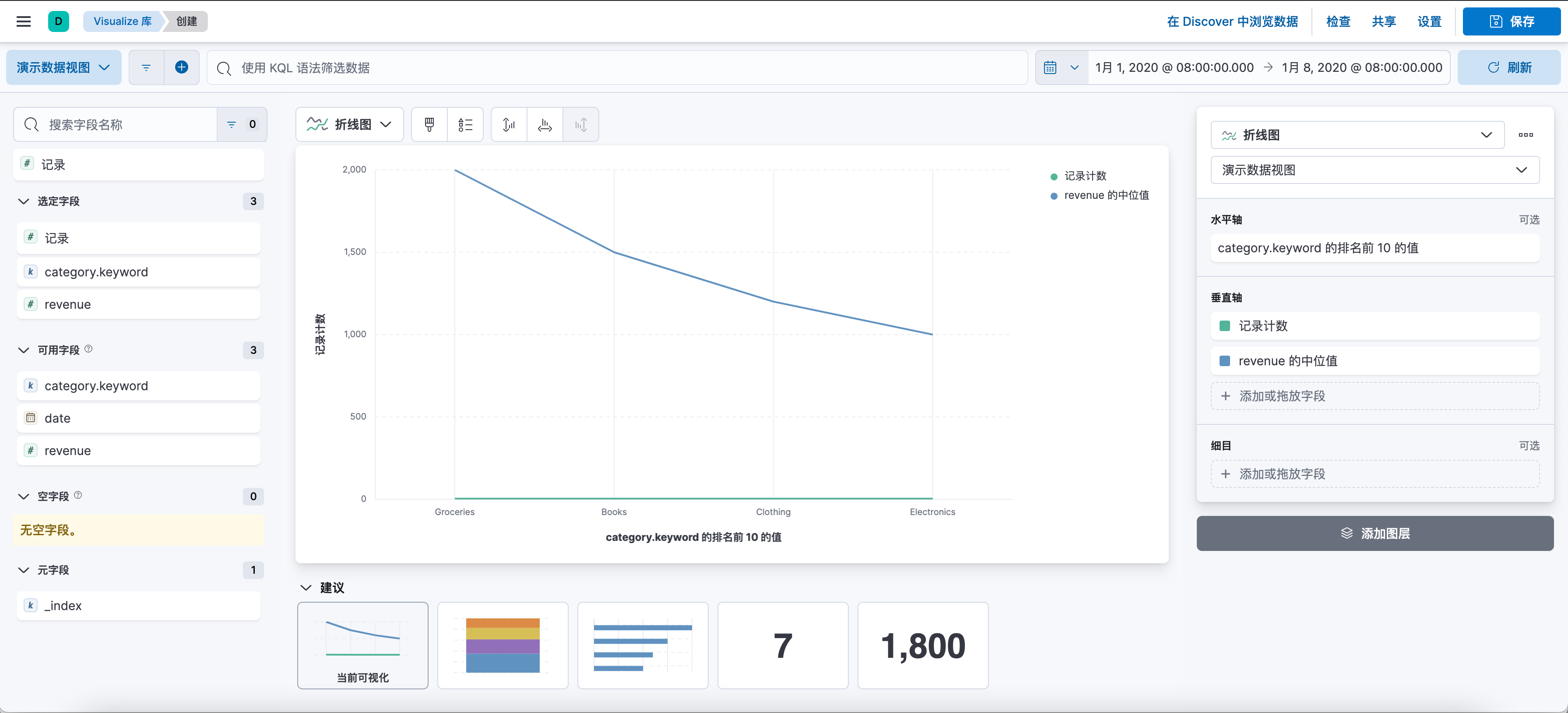
配置完成后,你可以预览你的线图。如果满意,点击「保存」按钮,为你的线图命名并保存。
2.5、配置饼状图
点击「新建可视化」按钮,选择 “饼状图” 选项来创建饼状图图。
在 “桶” 部分,你需要选择一个或多个字段来分割饼状图。你可以选择一个分类字段,并选择一个聚合函数,如 “计数”、“平均值”、“总和” 等。
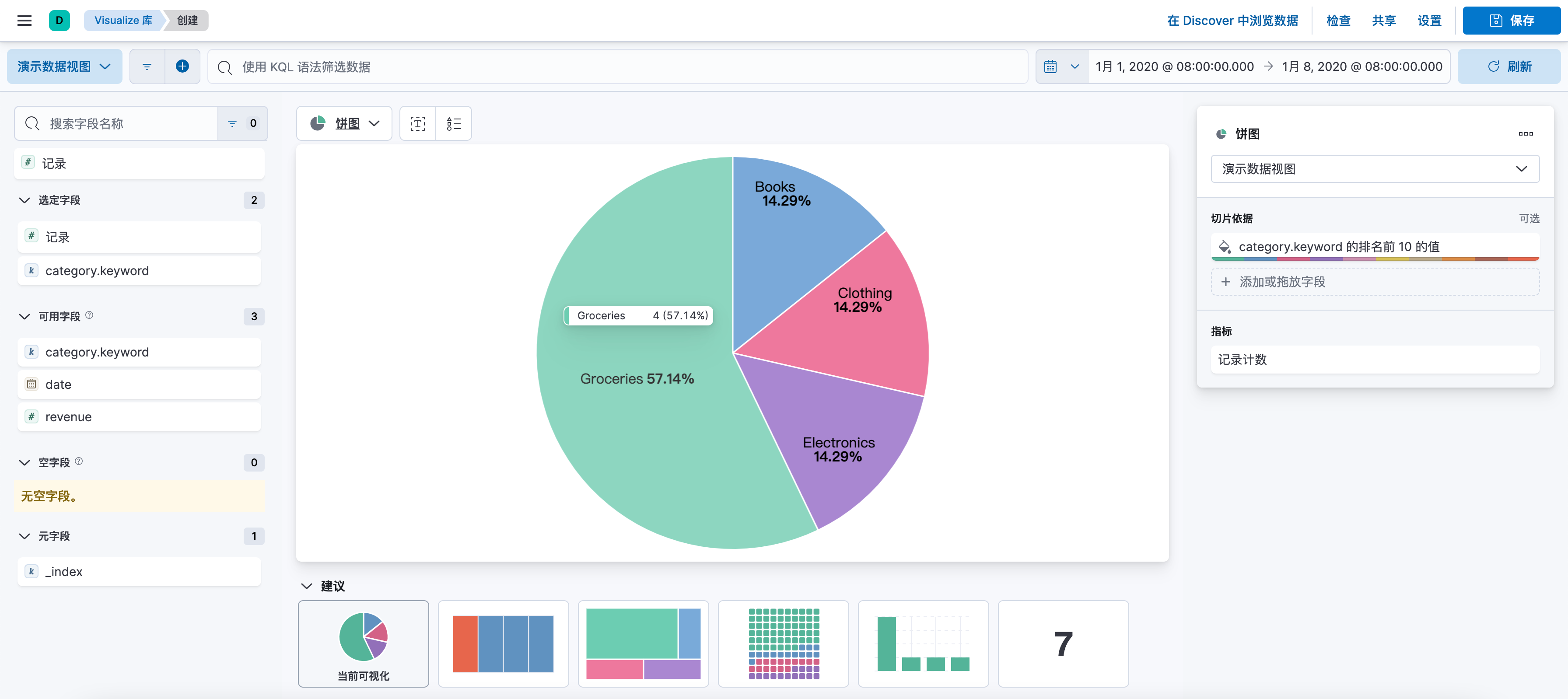
配置完成后,你可以预览你的饼状图。如果满意,点击「保存」按钮,为你的饼状图命名并保存。
3、Kibana更多功能
3.1、数据探索
Kibana 提供了强大的数据探索功能,用户可以使用 Elasticsearch 的查询语言进行数据查询,也可以通过 Kibana 的界面进行数据筛选和排序。以下是使用这些功能的基本步骤:
-
打开 Kibana:在浏览器中输入 Kibana 的地址,打开 Kibana 的主界面。
-
进入 Discover 页面:在左侧导航栏中,点击 “Discover” 图标,进入 Discover 页面。
-
选择索引模式:在 Discover 页面的顶部,你可以选择一个索引模式。Kibana 会显示该索引模式对应的数据。
-
进行数据查询:在查询栏中,你可以输入 Elasticsearch 的查询语句,然后按回车键执行查询。查询结果会在下方的表格中显示。
-
进行数据筛选:在表格的顶部,你可以看到所有的字段名。点击字段名,你可以添加一个筛选条件,只显示满足该条件的数据。
-
进行数据排序:在表格的表头,你可以点击任何一列的列名,对该列进行升序或降序排序。
以上就是在 Kibana 中进行数据探索的基本步骤。需要注意的是,不同的数据源可能需要不同的查询语句和筛选条件,你需要根据实际情况进行操作。
3.2、仪表盘
在 Kibana 中,你可以使用 “仪表盘” 功能来组合多个可视化成一个统一的界面。以下是配置仪表盘的基本步骤:
-
打开 Kibana:在浏览器中输入 Kibana 的地址,打开 Kibana 的主界面。
-
进入仪表盘页面:在左侧导航栏中,点击 “仪表盘” 图标,进入仪表盘页面。
-
创建新的仪表盘:点击 “创建仪表盘” 按钮,开始创建新的仪表盘。
-
添加可视化:在新的仪表盘页面中,点击 “添加” 按钮,你可以看到一个列表,列出了所有已经创建的可视化。选择你想要添加到仪表盘的可视化,点击 “添加” 按钮。
-
调整布局:添加了可视化后,你可以通过拖拽和缩放来调整它们在仪表盘中的位置和大小。
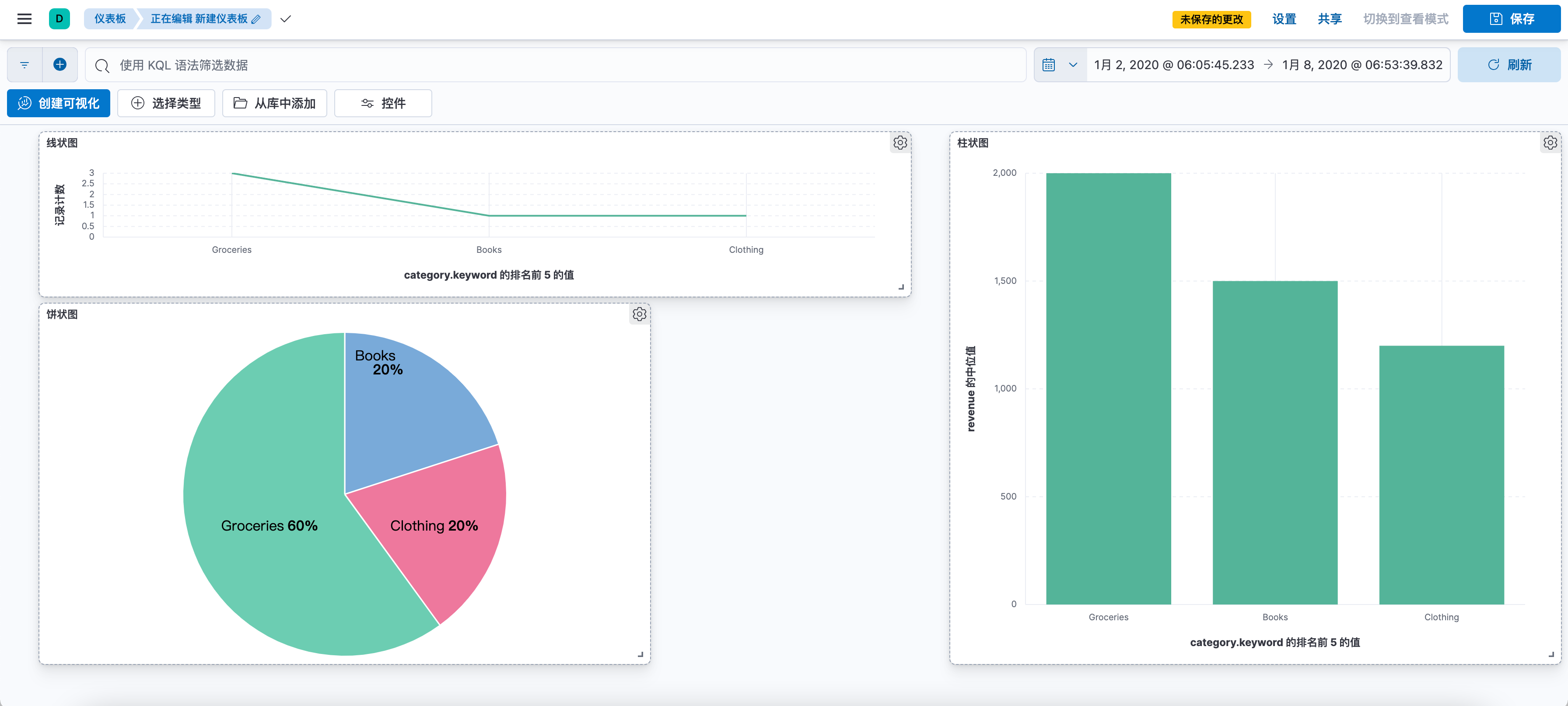
- 保存仪表盘:调整好布局后,点击「保存」按钮,为你的仪表盘命名并保存。
以上就是在 Kibana 中配置仪表盘的基本步骤。需要注意的是,仪表盘只能包含已经创建的可视化,因此在创建仪表盘之前,你需要先创建好所有需要的可视化。
相关文章:
Elasticsearch系列组件:Kibana无缝集成的数据可视化和探索平台
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个…...
phpcms_v9模板制作及二次开发常用代码
0:调用最新文章,带所在版块 {pc:get sql"SELECT a.title, a.catid, b.catid, b.catname, a.url as turl ,b.url as curl,a.id FROM v9_news a, v9_category b WHERE a.catid b.catid ORDER BY a.id DESC " num"15" cache"300"} {lo…...
-概述)
自然语言处理(NLP)-概述
NLP 一、什么是自然语言处理(NLP)二、NLP的发展三、相关理论1 语言模型2 词向量表征和语义分析3 深度学习 一、什么是自然语言处理(NLP) 什么是自然语言处理 二、NLP的发展 三、相关理论 1 语言模型 序列数据形式多样…...

Python开发者的宝典:CSV和JSON数据处理技巧大公开!
更多资料获取 📚 个人网站:涛哥聊Python 在Python中处理CSV和JSON数据时,需要深入了解这两种数据格式的读取、写入、处理和转换方法。 下面将详细介绍如何在Python中处理CSV和JSON数据,并提供一些示例和最佳实践。 CSV数据处理…...

Unity中Commpont类获取子物体的示例
// 本脚本用于演示Component类 方法 //任何一个组件 都可以从游戏物体获取或者从其父对象哪里 子对象哪里获取,一个组件也可以拿到同一个物体上的其他组件 using System.Collections; using System.Collections.Generic; using UnityEngine; public class Component…...
【Vue面试题二十一】、Vue中的过滤器了解吗?过滤器的应用场景有哪些?
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:Vue中的过滤器了解吗&am…...

Unity 3D基础——缓动效果
1.在场景中新建两个 Cube 立方体,在 Scene 视图中将两个 Cude的位置错开。 2.新建 C# 脚本 MoveToTarget.cs(写完记得保存) using System.Collections; using System.Collections.Generic; using UnityEngine;public class MoveToTarget : M…...

高校教务系统登录页面JS分析——南京邮电大学
高校教务系统密码加密逻辑及JS逆向 本文将介绍南京邮电大学教务系统的密码加密逻辑以及使用JavaScript进行逆向分析的过程。通过本文,你将了解到密码加密的基本概念、常用加密算法以及如何通过逆向分析来破解密码。 本文仅供交流学习,勿用于非法用途。 一…...
css实现排行榜样式(vue组件)
先看效果图: <template><div class"lawyer-refund-wrap"><div class"content"><divv-for"(item, index) in dataList" :key"index":style"{width: calc(100% - ${(index 1) * 10}px)}"c…...

I2VGen-XL高清图像生成视频大模型
本项目I2VGen-XL旨在解决根据输入图像生成高清视频任务。I2VGen-XL由达摩院研发的高清视频生成基础模型之一,其核心部分包含两个阶段,分别解决语义一致性和清晰度的问题,参数量共计约37亿,模型经过在大规模视频和图像数据混合预训…...
-每天10个小知识)
Angular知识点系列(1)-每天10个小知识
目录 1. Angular工作原理和与其他前端框架的区别2. 使用Angular的经验和最喜欢的特性3. 使用的最复杂的Angular组件或指令4. Angular的依赖注入系统和示例5. Angular的模块和组件生命周期6. 使用Angular路由和路由保护7. 在Angular应用中实现延迟加载8. 处理Angular应用中的状态…...
【从0开发】百度BML全功能AI开发平台【实操:以部署情感分析模型为例】
目录 一、全功能AI开发平台介绍二、AI项目落地应用流程(以文本分类为例)2-0、项目开始2-1、项目背景2-2、数据准备介绍2-3、项目数据2-4、建模调参介绍2-5、项目的建模调参2-6、开发部署2-7、项目在公有云的部署 附录:调用api代码总结 一、全…...

源码解析FlinkKafkaConsumer支持punctuated水位线发送
背景 FlinkKafkaConsumer支持当收到某个kafka分区中的某条记录时发送水位线,比如这条特殊的记录代表一个完整记录的结束等,本文就来解析下发送punctuated水位线的源码 punctuated 水位线发送源码解析 1.首先KafkaFetcher中的runFetchLoop方法 public…...
--- 父子组件传值)
vue3学习(五)--- 父子组件传值
文章目录 defineProps普通写法TS写法 defineEmits普通写法TS写法 defineExpose defineProps 和 defineEmits 都是只能在 <script setup> 中使用的编译器宏。他们不需要导入,且会随着 <script setup> 的处理过程一同被编译掉。 defineProps 接收父组件传…...

寻找AI时代的关键拼图,从美国橡树岭国家实验室读懂AI存力信标
超算,是计算产业的明珠,是人类探索未知的航船。超算的发展与变化,不仅代表着各个国家与地区间的科技竞争力,更将作为趋势风向标,影响整个数字化体系的走向。 在目前阶段,超算与AI计算的融合是大势所趋。为了…...

多线程并发篇---第十二篇
系列文章目录 文章目录 系列文章目录一、说说ThreadLocal原理?二、线程池原理知道吗?以及核心参数三、线程池的拒绝策略有哪些?一、说说ThreadLocal原理? hreadLocal可以理解为线程本地变量,他会在每个线程都创建一个副本,那么在线程之间访问内部 副本变量就行了,做到了…...

P7537 [COCI2016-2017#4] Rima
由于题目涉及到后缀,不难想到用 trie 树处理。 将每个字符串翻转插入 trie,后缀就变成了前缀,方便处理。 条件 LCS ( A , B ) ≥ max ( ∣ A ∣ , ∣ B ∣ ) − 1 \text{LCS}(A,B) \ge \max(|A|,|B|)-1 LCS(A,B)≥max(∣A∣,∣B∣)−1&…...
SwiftUI Swift CoreData 计算某实体某属性总和
有一个名为 Item 的实体,它有一个名为 amount 的 Double 属性,向你的 View 添加一个计算属性: Code: struct ContentView: View {Environment(\.managedObjectContext) private var viewContextFetchRequest(sortDescriptors: [NSSortDescri…...
docker安装skyWalking笔记
确保安装了docker和docker-compose sudo docker -v Docker version 20.10.12, build 20.10.12-0ubuntu4 sudo docker-compose -v docker-compose version 1.29.2, build unknown 编写docker-compose.yml version: "3.1" services: skywalking-oap:image: apach…...

【Codeforces】 CF1097G Vladislav and a Great Legend
题目链接 CF方向 Luogu方向 题目解法 首先一个套路是普通幂转下降幂(为什么?因为观察到 k k k 很小,下降幂可以转化组合数问题,从而 d p dp dp 求解) 即 f ( X ) k ∑ i 0 k { k i } i ! ( f ( X ) i ) f(X)^k…...

Tree of Thoughts终极指南:5分钟掌握思维树算法原理与实战应用
Tree of Thoughts终极指南:5分钟掌握思维树算法原理与实战应用 【免费下载链接】tree-of-thought-llm [NeurIPS 2023] Tree of Thoughts: Deliberate Problem Solving with Large Language Models 项目地址: https://gitcode.com/gh_mirrors/tr/tree-of-thought-l…...

input-overlay多语言支持:如何为全球观众轻松定制直播输入显示
input-overlay多语言支持:如何为全球观众轻松定制直播输入显示 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay 想要让全球观众都能轻松理解你的游戏操作吗&a…...

新手入门DetectionLab:10个步骤掌握企业网络安全检测基础
新手入门DetectionLab:10个步骤掌握企业网络安全检测基础 【免费下载链接】DetectionLab clong/DetectionLab: DetectionLab是一个开源项目,旨在建立一个高度可配置的虚拟环境以模拟企业网络,用于检测恶意活动、演练入侵检测系统(…...

CMake构建类型避坑指南:为什么你的Release模式没有优化?CMAKE_BUILD_TYPE常见问题排查
CMake构建类型避坑指南:为什么你的Release模式没有优化? 在C项目开发中,构建类型的选择直接影响最终生成的可执行文件性能。许多开发者在使用CMake时都遇到过这样的困惑:明明设置了CMAKE_BUILD_TYPERelease,但生成的代…...

React Native Chart Kit 性能优化技巧:大数据量下的流畅图表渲染
React Native Chart Kit 性能优化技巧:大数据量下的流畅图表渲染 【免费下载链接】react-native-chart-kit 📊React Native Chart Kit: Line Chart, Bezier Line Chart, Progress Ring, Bar chart, Pie chart, Contribution graph (heatmap) 项目地址:…...

当前主流的AI编程助手Trae、Cursor、通义灵码功能对比分析
Trae、Cursor和通义灵码是当前主流的AI编程助手,它们在功能定位、技术架构和使用体验上各有特色。以下是三款工具的详细对比分析: Trae详细操作手册和常见问题解决,请访问http://www.zrscsoft.com/sitepic/12166.html 一、核心功能对比 功能…...

AI与数据库融合:从经典论文到前沿实践
1. AI与数据库融合的起源与演进 数据库和人工智能这两个看似独立的领域,其实早在计算机科学发展的初期就已经产生了交集。上世纪70年代,当关系型数据库理论刚刚确立时,研究者们就开始探索如何让数据库系统具备一定的"智能"。当时的…...
)
实战避坑:用Playwright+Selenium绕过电商网站验证码的3种方法(附Python代码)
实战避坑:用PlaywrightSelenium绕过电商网站验证码的3种方法(附Python代码) 电商平台的反爬虫机制日益复杂,验证码作为核心防线之一,已经从简单的图文识别升级到行为验证、智能风控等多维度拦截。本文将聚焦淘宝、京东…...

告别重复造轮子:用快马AI一键生成高复用性imToken集成代码模块
告别重复造轮子:用快马AI一键生成高复用性imToken集成代码模块 开发涉及钱包集成的DApp时,最让人头疼的就是那些重复性的基础代码。每次新项目都要重新写一遍连接钱包、处理授权、监听网络切换的逻辑,不仅浪费时间,还容易引入安全…...
)
图解Linux内核DRM框架:从用户态ioctl到plane更新的完整数据流(以4.14版本为例)
图解Linux内核DRM框架:从用户态ioctl到plane更新的完整数据流(以4.14版本为例) 在图形显示技术领域,Linux内核的DRM(Direct Rendering Manager)框架扮演着核心角色。本文将聚焦于DRM_IOCTL_MODE_SETPLANE这…...