Elasticsearch:什么是大语言模型 (LLMs)?

假设你想参加流行的游戏节目 Jeopardy(这是一个美国电视游戏节目,参赛者将获得答案并必须猜测问题)。 要参加演出,你需要了解任何事情的一切。 所以你决定在接下来的三年里每天都花时间阅读互联网上的所有内容。 你很快就会意识到这比最初看起来更难,并且需要投入巨大的时间。 你还意识到互联网上有大量的信息。 其中一些是事实,一些是观点,而大多数则介于两者之间。 Jeopardy 是基于事实的,因此将大部分时间花在两者之间并不明智。
你决定采用不同的方法来进行 Jeopardy 训练。 你不必尝试了解任何事物的一切,而是专注于如何预测句子中的下一个单词。 如果有人说 “Have a nice…”,你的训练就会告诉你下一个词可能是 “day”。 这是一种完全不同的 Jeopardy 训练方式,但可能是你每日双倍的优势!
所以你专注于英语。 你想阅读所有已写的句子,以(希望)发现模式。 然后,当有人向你提出想法时,你可以使用这些模式来预测下一个单词。 使用这种新方法需要训练什么样的数据? 你要如何记住所有的模式?
这是大型语言模型(Large Language Model - LLM)可以解决的挑战。 它们很大,因为它们接受过大量数据的训练(如互联网上的所有公共内容)。 它们是一种语言模型,因为它们可以使用大量的训练数据来理解如何用给定语言(例如英语、西班牙语或法语)完成句子。 由于互联网上的信息涵盖了如此广泛的观点、方言、想法等,因此模型非常擅长从所提出的问题中推断出模式。
大型语言模型是人工智能 (AI) 的一种形式。 他们接受过大量数据的训练,可以像人类一样智能地完成想法。 换句话说,它们是人工智能的。
大型语言模型如何工作?
当人们开始创 LLM 时,首先要回答的问题是,该模型的目标是什么,以及你可以收集多少有关该目标的数据? 像 GPT 这样的 LLM 有一个相当广泛的目标 —— 完成任何想法。 模型的目标可能更加集中,例如对大量文档建立索引以使它们可搜索。 大型语言模型之所以 “大”,是因为它们的预期目标通常是一个非常大的想法,并且了解该目标所需的数据是巨大的。 事实上,对于 GPT 来说,要完成任何思维目标,可能不存在足够数量的数据来真正训练它。
几乎每个 LLM 都有一些细微差别。 要么是训练数据的差异,要么是训练方式的差异,要么是学习路径的优化,要么是如何完成想法的差异。 比较 Google 的 Bard 模型和 OpenAI 的 GPT 模型。 当你与其中任何一个聊天时,感觉都是一样的。 你分享一个想法或提出一个问题,模型就会用与对话相关的内容进行回应。 但在幕后,情况却大不相同。
如果你与 LLM 的第一次互动是使用 ChatGPT 这样的网站,那么你可能会倾向于认为 LLM 是为了回答你的问题而设计的。 事实上,人工智能模型根本不回答问题,而是完成思想。 用 “It’s a lovely day.” 来提示 (prompt) 模特。 与 “Is it a lovely day?” 会得到不同的回应。 不是因为其中的一个是问题,另一个是陈述。 为了完成一个想法,模型试图找到(统计上)最合适的下一组单词。 然后是下一组单词,依此类推。 该响应称为 “完成 (complete)”,因为模型试图弄清楚接下来会发生什么。 对我们来说,这确实感觉像是一个问题和答案。
机器学习模型和 LLM 有什么区别?
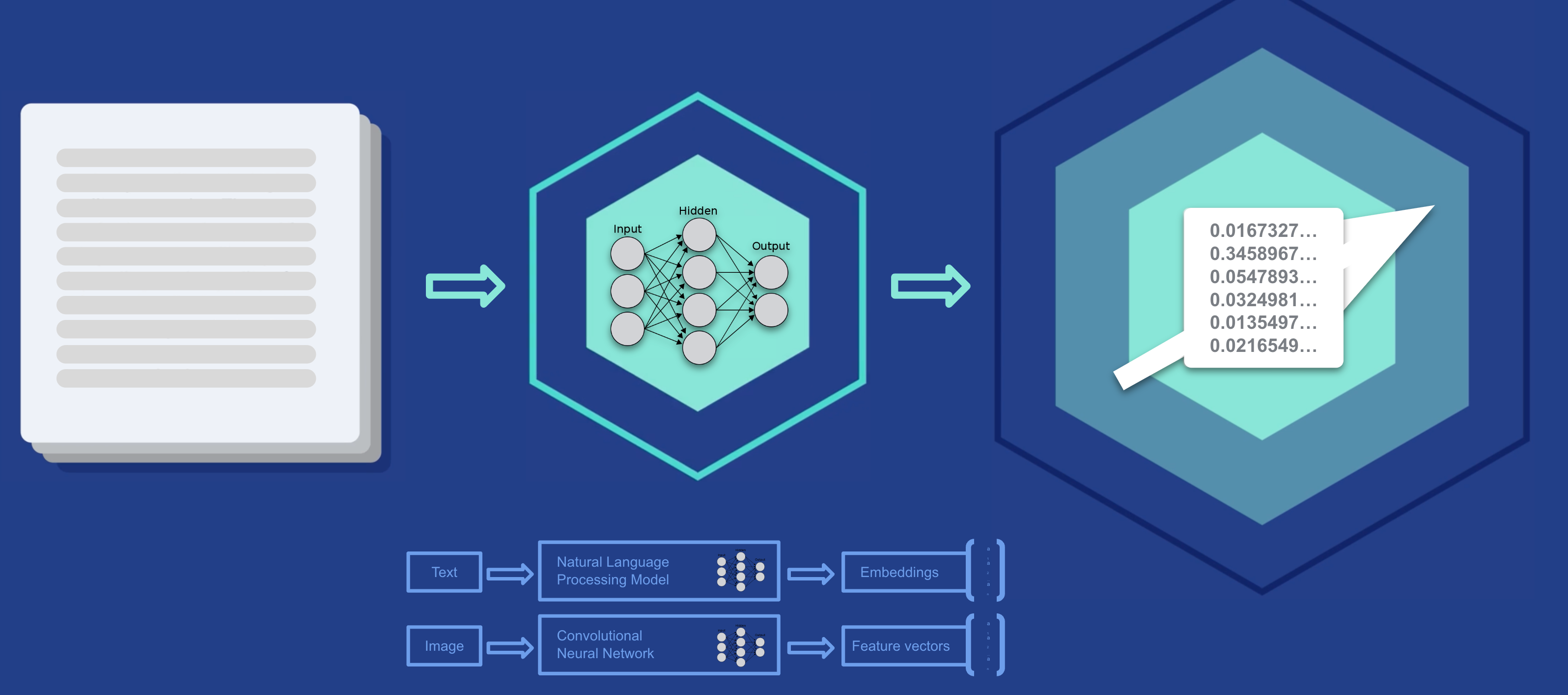
许多机器学习模型和 LLM 之间的一个显着区别是:后者基于神经网络。 顾名思义,神经网络模拟人类神经元的工作方式。 这是一个试图模拟人类功能的计算模型。 正如你可以想象的那样,这可能会变得非常混乱。 为了表达 LLM 的复杂程度,你可以参考数十亿的参数数量。 非常复杂。 较小的机器学习模型的需求通常不需要使用神经网络。 这使得它们的复杂性更容易处理,但也限制了它们的计算能力。
LLM 是如何训练的?
LLM(或者实际上任何机器学习系统)并不是立即聪明的。 就像人类一样,他们必须接受有关特定主题的教育(或培训)。 训练模型与你我学习某个主题的方式非常相似。
假设我们想了解甜甜圈食谱。 典型成分是什么? 制作面团有哪些变体? 甜甜圈上可以放什么配料(几乎任何东西!)? 什么食谱不做甜甜圈?
要了解所有这些,你需要从你知道值得信赖的来源收集一堆食谱。 然后你就去读书。 很多。 随着时间的推移,你会在所有食谱中看到模式。 就像大多数人使用面粉一样。 不使用面粉的通常被认为是无麸质的。 这称为训练数据。
甜甜圈通常上面撒有糖粉之类的甜食。 你可以使用这些常见模式来阅读其他食谱并了解它是否适用于甜甜圈。 你还会注意到,甜甜圈是圆形的,中间有一个洞。 食谱可能需要与甜甜圈类似的成分,但也可能用于制作煎饼。 你需要找到一致的模式来解决这个问题。
培训 LLM 与此非常相似。 食谱示例越多,模型就越能判断给定的食谱是否用于制作甜甜圈。 你需要大量食谱,以便你的模型能够非常擅长识别甜甜圈食谱。
LLM 有何用途?
训练一个模型来确定一个食谱是否适合甜甜圈是有帮助的,但还有很多不足之处。 训练模型并不是一件容易的事,因此你希望包含尽可能多的功能。 在这种情况下,我们可能希望模型知道正在制作哪种甜甜圈。
当你为模型提供所有这些甜甜圈食谱时,你可以在每个食谱中包含甜甜圈的类型。 这称为数据标记。 使用这种方法意味着模型不仅可以确定食谱是否要制作甜甜圈,而且还可以回答正在制作哪种甜甜圈! 现在有人可以问你的模型 “这个食谱可以制作巧克力甜甜圈吗?” 你的模型接受了带有类型标签的甜甜圈食谱的训练,因此它应该能够提供非常准确的答案。
LLM 有多种形式和规模。 然而,由于它们非常复杂并且需要大量数据进行训练,因此它们的设计目标很广泛。 想象一下,创建一个模型,以世界上任何歌曲的 5 秒时间来识别其艺术家。 这不是一件容易的事,需要了解每首歌曲的知识。
假设你想要创建一个模型来识别给定歌曲是否在特定专辑中。 LLM 在这方面做得不好,因为你不需要用世界上所有的歌曲来训练它。 你所需要了解的只是该专辑中的几首歌曲。 这些数据不足以提供准确的响应。 世界上有很多歌曲听起来与专辑中的歌曲有点相似。
LLMs 旨在完成非常抽象的想法,几乎没有背景。 比如 “为什么鸡要过马路?” 当给出清晰的示例和所需内容的描述时,它们还旨在提供精确准确的答案。 为了擅长这两种用途,需要大量的数据进行学习。
LLM 示例
截至本文档发布之日,这里是一些公开的 LLM 示例。 我们试图提供一些有关每个模型的目标以及如何开始使用它们的背景信息。
所有这些模型都是自然语言处理 (NLP) 模型,这意味着它们经过训练可以处理人类说话的方式(字母、单词、句子等)。
OpenAI GPT-3(生成式预训练 Transformer 3)
该 LLM 由 OpenAI 于 2020 年发布。 它被归类为具有约 1750 亿个参数的生成式大型语言模型。 OpenAI 使用几个不同的数据集在整个互联网上训练 GPT,其中最大的是 Common Crawl。
GPT 的目标是提供连续的想法。 这个想法可以是完整的,比如 “这是美好的一天”,也可以是一个问题,比如 “鸡为什么过马路?”。 GPT 从左到右读取文本并尝试预测接下来的几个单词。
BERT(来自 Transformers 的双向编码器表示)
Google 在 2018 年发布了这个 LLM。它基于 Transformer 架构。 BERT 采用与 GPT 不同的方法,它从左侧和右侧读取文本,然后预测接下来的几个单词。 这使模型可以更好地理解单词的上下文。
T5(文本到文本传输转换器)
T5 模型由 Google Research 在 2019 年发表的一篇论文中介绍,旨在以统一的方式处理所有 NLP 任务。 它通过将这些任务转换为文本到文本的问题来实现这一点。 输入和输出都被视为文本字符串。 这扩展了模型的能力,包括文本分类、翻译、摘要、问答等。
CTRL( Conditonal Transformer Language Model - 条件转换器语言模型)
该模型由 Salesforce Research 在 2019 年发表的一篇研究论文中创建。该模型旨在生成以特定指令或控制代码为条件的文本,从而可以对语言生成过程进行细粒度控制。 它使用控制代码来调节语言模型的输出。 这些代码在文本生成过程中充当模型的指令。 控制代码指导模型生成特定样式、流派或具有特定属性的文本。 这使得可以根据用户指定的约束对语言生成过程进行微调定制。
威震天-图灵 (MT-NLG)
该模型是微软的 DeepSpeed 深度学习优化库和 NVIDIA 的 Megatron-LM 大型变压器模型的结合。 在发布时,它声称拥有 “世界上最大的基于 Transformer 的语言模型” 称号,拥有 5300 亿个参数(明显多于 GPT-3)。 其庞大的参数规模使得该模型在零次、一次和几次提示方面表现得非常好。 它在现代 LLM 的规模和质量方面树立了新的标杆。
如何使用 LLM 开始生成人工智能
一旦你为生成式人工智能项目设定了目标,你就可以选择最适合需求的 LLM。 LLM 很可能提供与其交互的 API(即:提交提示并接收响应)。 你需要提示在项目目标和 LLM 的特征之间取得平衡。 该平衡将包括 LLM 不知道的其他信息。 了解有关 prompt engineering 的更多信息。
通常,你使用向量数据库将用户的输入与预制文本进行匹配,以创建完美的提示 (prompt)。 这将确保 LLM 的反应是可预测的和足够稳定的,以包含在你更大的努力中。 最简单的流程是:
- 接受用户查询
- 在最新的向量化数据中查找更多上下文
- 将附加数据于你预先制作的文本相结合
- 向 LLM 提交最终 promt
- 使用 LLM 回复回复用户
虽然这听起来可能很复杂,但 Elasticsearch 可以通过完全集成的解决方案为你处理大部分工作,该解决方案提供上下文数据所需的所有部分。 从基于数据管道构建的神经系统到嵌入,一直到核心存储以及易于使用的云平台中的检索、访问和处理。 立即免费试用 Elastic Cloud。
相关文章:
Elasticsearch:什么是大语言模型 (LLMs)?
假设你想参加流行的游戏节目 Jeopardy(这是一个美国电视游戏节目,参赛者将获得答案并必须猜测问题)。 要参加演出,你需要了解任何事情的一切。 所以你决定在接下来的三年里每天都花时间阅读互联网上的所有内容。 你很快就会意识到…...

神奇的python的生成器
函数生成器代码 def num():print("message 1")yield 1print("message 2")yield 2print("message 3")yield 3f num() x next(f) # message 1 print(x) # 输出1x next(f) # message 2 print(x) # 输出2x next(f) # message 3 print(x) …...

【来点小剧场--项目测试报告】个人博客项目自动化测试
前述 针对个人博客项目进行测试,个人博客主要由七个页面构成:注册页、登录页、个人博客列表页、博客发布页、博客修改页、博客列表页、博客详情页,主要功能包括:注册、登录、编辑并发布博客、修改已发布的博客、查看详情、删除博…...

【安卓环境搭建报错的解决】
安卓环境搭建报错的解决 问题描述解决方法 问题描述 电脑中新安装的 Android Studio Giraffe | 2022.3.1 Patch ,运行 studio 系统工程,提示如下错误 Duplicate class kotlin.collections.jdk8.CollectionsJDK8Kt found in modules kotlin-stdlib-1.8.…...

Pruning Pre-trained Language Models Without Fine-Tuning
本文是LLM系列文章,针对《Pruning Pre-trained Language Models Without Fine-Tuning》的翻译。 修剪未微调的预训练语言模型 摘要1 引言2 相关工作3 背景4 静态模型剪枝5 实验6 分析7 结论8 局限性 摘要 为了克服预训练语言模型(PLMs)中的过度参数化问题…...

Java内存模型-Java Memory Model(JMM)-可见性、原子性、有序性
5. Java内存模型之JMM 5.1 先从大场面试开始 你知道什么是Java内存模型JMM吗? JMM和volatile他们两个之间的关系? JMM没有那些特征或者它的三大特征是什么? 为什么要有JMM,它为什么出现?作用和功能是什么…...
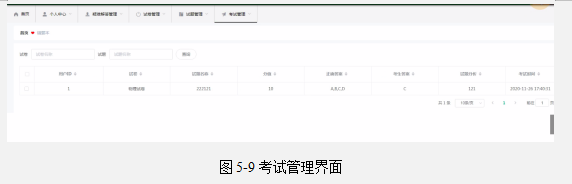
基于Springboot实现在线答疑平台系统项目【项目源码+论文说明】
基于Springboot实现在线答疑平台系统演示 摘要 社会的发展和科学技术的进步,互联网技术越来越受欢迎。网络计算机的生活方式逐渐受到广大师生的喜爱,也逐渐进入了每个学生的使用。互联网具有便利性,速度快,效率高,成本…...
)
前端工程化知识系列(1)
目录 1. 什么是前端工程化,以及它为前端开发带来了哪些好处?2. 你使用过哪些版本控制系统?描述一下你在团队中如何处理代码合并和冲突解决的经验。3. 什么是Git,它的工作原理是什么?可以解释一下常用的Git命令吗&#…...
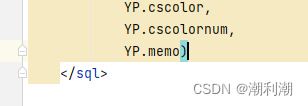
xml文件报错 ORA-00907: 缺失右括号
原来的sql 更改之后 加一个select * from ()...
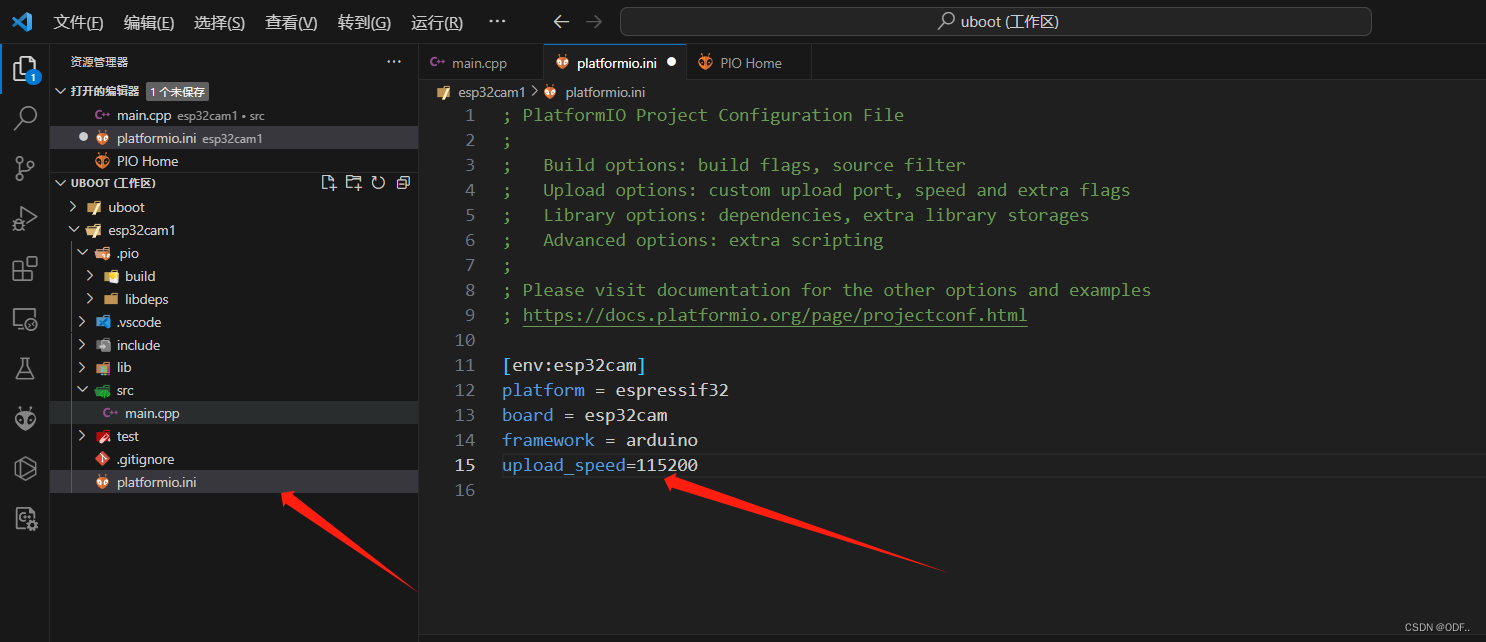
VScode platformio的使用
一、platformio 工程创建 打开vscode界面你会发现左下多了个家的小图标,点击这里就可以进入platformio。 在右侧Quick Access栏中,有4个选项。可以看得出来,我们这里直接点击创建一个新的工程。 点击New Project打开project配置界面&#x…...
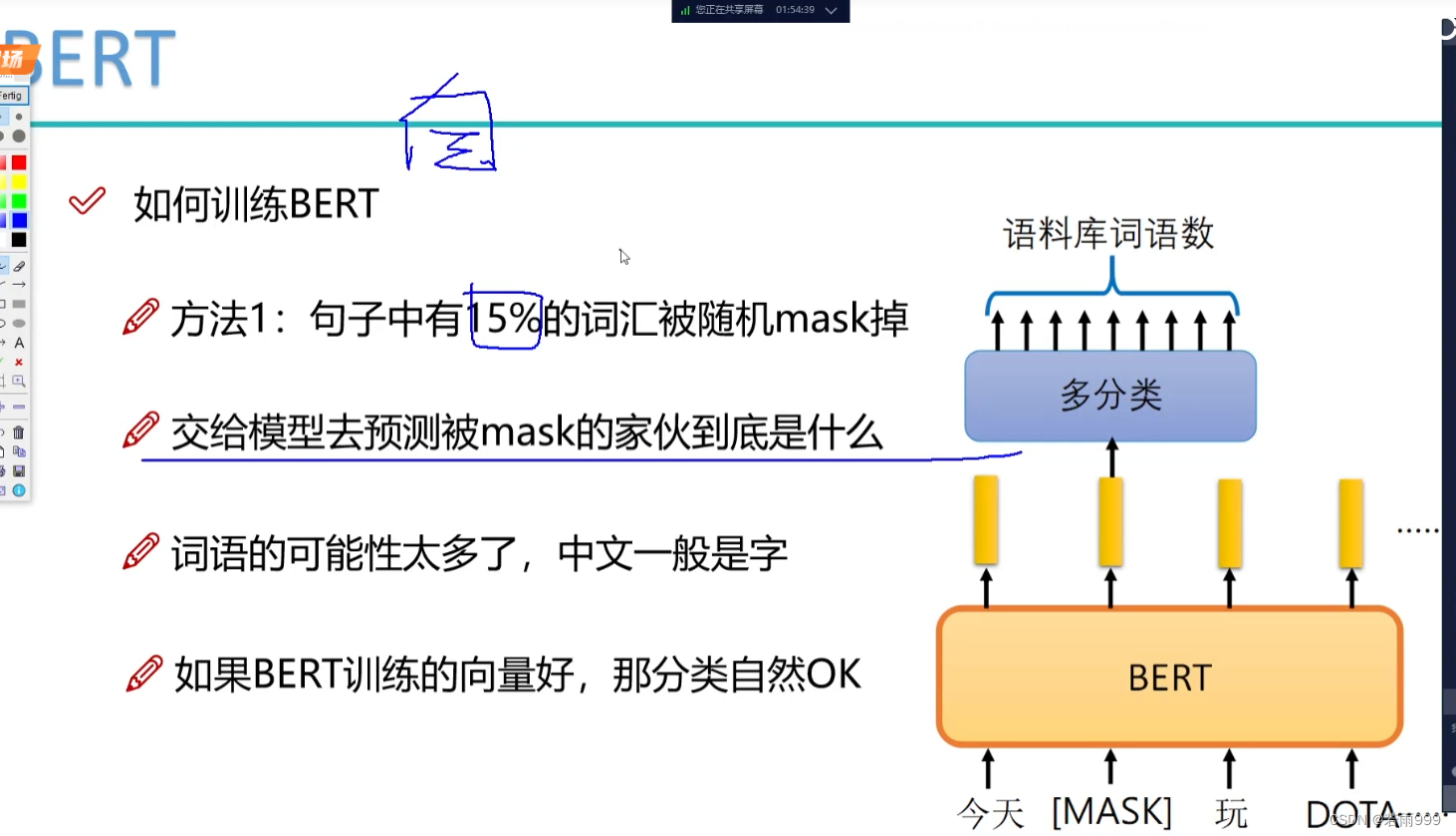
transformer_01
一、传统RNN存在的问题 1.序列前序太长,每个xi要记住前面的特征,而且一直在学,没有忘记,可能特征不能学的太好 2.串行,层越多越慢,难以堆叠很多层; 3.只能看到过去,不能看到未来 搞…...

JavaSE入门---认识方法
文章目录 什么是方法?方法定义实参和形参的关系没有返回值的方法 方法重载方法签名 什么是方法? 在编程中某段功能的代码可能频繁使用到,如果在每个位置都重新实现一遍,会有一些缺点,比如: 使程序变得繁琐…...

编译[Bug]——too few arguments for template template parameter “Tuple“ detected
项目场景: 当使用高版本的cuda去安装低版本pytorch,并且编译用低版本pytorch写的cuda算子时,或者说是VS的版本过高如2022和2019,都有可能会出现某个.h文件或者.c文件报错,如: error: too few arguments f…...

网工内推 | 南天软件,base北京,需持有CCIE认证,最高25k
01 北京南天软件有限公司 招聘岗位:IPT运维工程师 职责描述: 负责客户Cisco语音网络IPT ,CUCM的日常运维,扩容和项目支持,支持路由交换,无线等项目,实施工作以及相关实施文档。 任职要求: 1、…...

Unity有限状态机的简易实现
本人嘴笨,不会说。 该代码实现一个功能较为齐全的有限状态机,可用于大部分的应用场景。 大致实现几个功能 状态更新状态转换状态消息处理全局状态转换和反转状态(转换为前一个状态) 代码分为 状态类状态管理类枚举(…...

什么是NetApp的DQP和如何安装DQP?
首先看看什么是DQP,DQPDisk Qualification Package,文字翻译就是磁盘验证包。按照NetApp的最佳实践,要定期升级DQP包,保证对最新磁盘和磁盘扩展柜的兼容。 本文主要介绍7-mode下如何升级DQP,至于cluster mode另外文章…...

Vue之Vue的介绍安装开发实例生命周期钩子
博主心得: keyup必须与change一起使用v-on.click可以直接写成clickclick“setVal”里的setVal换成数字之后有惊喜VS Code是真的狗,一些报错根本不会直接显示总结:VS code太狗了 1.vue介绍 1.1 什么是vue vue是一个构建用户界面UI的渐进式jav…...

【计网】计算机网络概述
目录 一、计算机网络的概念 二、计算机网络的组成 1、从组成部分上看 2、从工作方式上看 3、从功能组成上看 三、计算机网络的功能 1、数据通信 2、资源共享 3、分布式处理 4、提高可用性 5、负载均衡 四、计算机网络的分类 1、按分布范围 1.广域网 2.城域网 3.…...

初识Java 14-1 测试
目录 测试 单元测试 JUnit 测试覆盖率 前置条件 断言 Java提供的断言语法 Guava提供的更方便的断言 契约式设计中的断言 DbC 单元测试 Guava中的前置条件 本笔记参考自: 《On Java 中文版》 测试 ||| 如果没有经过测试,代码就不可能正常工作…...

react常用的hooks有哪些?
React常用的Hooks包括以下几种: 1.useState:用于在函数组件中创建和管理状态。它返回一个数组,第一个值是当前状态的值,第二个值是更新状态的函数。 使用时,首先通过解构赋值获取状态值和更新函数,并设置初…...

ncmdumpGUI:3分钟解锁网易云音乐NCM加密文件,让音乐自由流动
ncmdumpGUI:3分钟解锁网易云音乐NCM加密文件,让音乐自由流动 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 当智能音箱对你说"不…...

Git使用问题汇总
参考资料 Git教程-廖雪峰的官方网站 Pro git,有简体中文翻译 下载指定版本号 git clone https://github.com/xx.git -b x.x.x更新到最新 git pull origin master当使用git clone --recursive下载中断时,使用下面的命令可以继续 git submodule update --init --recursive…...

企业微信 Webhook 回调详解
Webhook 回调,是企业微信自动化开发中最核心的能力之一。很多开发者在做企业微信自动化时,都会先关注“消息发送”。 但真正影响系统自动化能力的,其实是“消息回调”。因为只有实时接收到客户消息、群消息与事件通知,系统才能真正…...
 架构设计)
Data Connection (数据连接) 架构设计
description: “移动数据连接 (Data Connection) 与 PDN 会话架构设计,深入剖析 DataNetwork 状态机、数据可用性评估引擎、重试退避算法、以及跨 APN 的并发管理策略。” 当手机完成网络注册(ServiceStateTracker 确定已注册到运营商网络)后,用户最关心的一件事就是:能不…...

程序员会被产品经理替代吗?——当AI让“全栈”成为常态,我们的价值在哪里?
程序员会被产品经理替代吗?——当AI让“全栈”成为常态,我们的价值在哪里? 最近,V2EX上一个帖子引发了激烈讨论:随着AI能力的指数级增长,一个人就能完成从前需要整个团队才能做到的全栈开发。如果产品经理借…...

BilibiliDown音频提取终极指南:如何从B站视频中提取高质量音乐
BilibiliDown音频提取终极指南:如何从B站视频中提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_m…...
 (75 - 94))
Solidity 知识点速记整理 - (2026年) (75 - 94)
文章目录前言Solidity 知识点速记整理 - (2026年) (75 - 94)前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差,实在白嫖的话,那…...

【Linux内核模块】模块的编译:从代码到可加载模块的 “变身术“
一、内核模块编译的特殊性:为什么不能直接用 gcc?普通 C 程序编译很简单,gcc hello.c -o hello就行,但内核模块可不行。这就像做面包和做蛋糕的区别 —— 虽然都是面粉做的,但烤箱温度、配料比例完全不同。1.1 内核模块…...

波兰市场语音本地化迫在眉睫,ElevenLabs波兰语支持深度评测:WAV质量、时延、重音准确率98.7%实测数据曝光
更多请点击: https://kaifayun.com 第一章:波兰市场语音本地化战略紧迫性分析 波兰作为欧盟第六大经济体和中东欧数字化转型先锋,其语音技术采纳率正以年均23.7%的速度攀升。截至2024年Q2,波兰智能音箱渗透率达38%,而…...

暗黑破坏神2存档修改器终极指南:告别重复刷装备,5分钟打造完美角色!
暗黑破坏神2存档修改器终极指南:告别重复刷装备,5分钟打造完美角色! 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否厌倦了在暗黑破坏神2中反复刷装备&am…...