29 Python的pandas模块
概述
在上一节,我们介绍了Python的numpy模块,包括:多维数组、数组索引、数组操作、数学函数、线性代数、随机数生成等内容。在这一节,我们将介绍Python的pandas模块。pandas模块是Python编程语言中用于数据处理和分析的强大模块,它提供了许多用于数据操作和清洗的函数,使得数据处理和分析变得更为简单和直观。
在Python中使用pandas模块,需要先安装pandas库。可以通过pip命令进行安装:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas。安装完成后,就可以在Python脚本中导入pandas模块,并使用其函数和方法了。
Series
Series是一个一维数组,它不仅包含数据,还包含索引。Series可以被看作是一个字典,其中的索引是键,值是数据。每个索引只有一个对应的值,因此Series可以被看作是具有标签化的数值数据。
import pandas as pd# 创建一个Series
s = pd.Series([1, 2, 3, 4, 5])
# 输出:
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# dtype: int64
print(s)上面的示例代码创建了一个包含五个整数的Series,默认情况下,它的索引是从0开始的整数。
当然,我们也可以提供一个列表作为Series的索引和值。
import pandas as pd# 创建一个带有自定义索引和值的Series
index = ['C', 'S', 'D', 'N', 'P']
s = pd.Series([1, 2, 3, 4, 5], index = index)
# 输出:
# C 1
# S 2
# D 3
# N 4
# P 5
# dtype: int64
print(s)我们还可以直接使用字典创建带有自定义数据标签的数据,pandas会自动把字典的键作为数据标签,字典的值作为相对应的数据。
import pandas as pd# 创建一个带有自定义索引和值的Series
s = pd.Series({'C': 1, 'S': 2, 'D': 3, 'N': 4, 'P': 5})
# 输出:
# C 1
# S 2
# D 3
# N 4
# P 5
# dtype: int64
print(s)如果想访问Series里的数据,也非常简单,直接使用中括号加数据标签的方式即可。
import pandas as pds = pd.Series([1, 2, 3, 4, 5])
# 访问第二个元素,输出:3
print(s[2])s = pd.Series({'C': 1, 'S': 2, 'D': 3, 'N': 4, 'P': 5})
# 访问Key值为'D'的元素,输出:3
print(s['D'])使用Series,结合pandas强大的数据对齐功能,可以让我们快速对数据进行分析和处理。
import pandas as pds1 = pd.Series({'Red': 1, 'Blue': 2, 'Green': 3})
s2 = pd.Series({'Red': 100, 'Blue': 200, 'Green': 300})
s = s1 + s2
# 将两个Series进行相加,输出:
# Red 101
# Blue 202
# Green 303
# dtype: int64
print(s)s1 = pd.Series({'Red': 1, 'Blue': 2, 'Green': 3, 'White': 4})
s2 = pd.Series({'Red': 100, 'Blue': 200, 'Green': 300})
s = s1 + s2
# 数据标签不相同的数据,运算后结果是NaN,输出:
# Blue 202.0
# Green 303.0
# Red 101.0
# White NaN
# dtype: float64
print(s)# 数据标签不相同的数据,调用add函数,可以设置默认填充值,输出:
# Blue 202.0
# Green 303.0
# Red 101.0
# White 4.0
# dtype: float64
s = s1.add(s2, fill_value = 0)
print(s)DataFrame
DataFrame是一个二维的表格型数据结构,类似于Excel或数据库中的表。DataFrame中的数据可以是不同的数据类型,比如:整数、浮点数、字符串、布尔值等。
import pandas as pd# 创建DataFrame
data = {'Name': ['Jack', 'Tank', 'John'], 'Age': [20, 21, 19]}
df = pd.DataFrame(data)
# 输出:
# Name Age
# 0 Jack 20
# 1 Tank 21
# 2 John 19
print(df)使用DataFrame,我们可以很方便地对表中的行、列进行增删改查等操作。使用df['column_name']可以查看指定列的数据;使用df.iloc[row_number]可以查看指定行的数据;使用df.loc[row_label]可以基于标签访问指定行的数据;使用df[condition]可以筛选出满足条件的数据:使用df['new_column'] = values可以添加一个新列;使用del df['column_name']可以删除一列。
import pandas as pd# 创建DataFrame
data = {'Name': ['Jack', 'Tank', 'John'], 'Age': [20, 21, 19]}
df = pd.DataFrame(data)
# 输出:
# Name Age
# 0 Jack 20
# 1 Tank 21
# 2 John 19
print(df)df = pd.DataFrame(data, index = ['First', 'Second', 'Third'])
# 指定自定义索引,输出:
# Name Age
# First Jack 20
# Second Tank 21
# Third John 19
print(df)# 访问列数据,输出:
# First Jack
# Second Tank
# Third John
# Name: Name, dtype: object
print(df['Name'])
# 根据行索引访问行数据,输出:
# Name John
# Age 19
# Name: Third, dtype: object
print(df.iloc[2])
# 根据行标签访问行数据,输出:
# Name John
# Age 19
# Name: Third, dtype: object
print(df.loc['Third'])df['Age'] = [22, 18, 20]
# 修改列数据,输出:
# Name Age
# First Jack 22
# Second Tank 18
# Third John 20
print(df)df['Gender'] = ['M', 'F', 'F']
# 新增列数据,输出:
# Name Age Gender
# First Jack 22 M
# Second Tank 18 F
# Third John 20 F
print(df)del df['Gender']
# 删除列数据,输出:
# Name Age
# First Jack 22
# Second Tank 18
# Third John 20
print(df)# 筛选出年龄大于20的数据,输出:
# Name Age
# First Jack 22
print(df[df['Age'] > 20])数据读取和写入
使用pandas,可以方便地读取和写入各种数据格式,比如:CSV、Excel、SQL数据库等。我们以CSV文件的读写为例,来理解CSV表格数据的读取和写入。
import pandas as pd# 创建DataFrame
data = {'Name': ['Jack', 'Tank', 'John'], 'Age': [20, 21, 19]}
df = pd.DataFrame(data)# 将DataFrame写入CSV文件
df.to_csv('output.csv', index = False)在上面的示例代码中,我们首先创建了一个名为df的DataFrame,然后使用to_csv函数将其写入一个名为output.csv的CSV文件中。我们将index参数设置为False,以避免将DataFrame的索引写入CSV文件。
to_csv函数还有其他一些可选参数,包括:
sep:用于指定CSV文件中的分隔符,默认是逗号。
header:用于指定是否将DataFrame的列名写入CSV文件中,默认为True。
encoding:用于指定文件的编码格式,默认为UTF-8。
compression:用于指定文件的压缩格式,默认为None。
在下面的示例代码中,我们读取了上面保存的名为output.csv的CSV文件,并将其转化为一个pandas DataFrame。
import pandas as pd# 从CSV文件读取
df = pd.read_csv('output.csv')
# 输出:
# Name Age
# 0 Jack 20
# 1 Tank 21
# 2 John 19
print(df)read_csv函数还有其他一些可选参数,包括:
sep:指定分隔符,默认为逗号。
header:指定行号作为列名,默认为0。
index_col:将一列或多列设为DataFrame的索引。
usecols:返回的列的子集,可以是一个列表或函数。
dtype:为每一列设置数据类型。
skiprows:跳过指定的行数或行号。
na_values:用于识别空值的字符串或字符串列表。
keep_default_na:是否保留默认的识别空值的字符串。
相关文章:

29 Python的pandas模块
概述 在上一节,我们介绍了Python的numpy模块,包括:多维数组、数组索引、数组操作、数学函数、线性代数、随机数生成等内容。在这一节,我们将介绍Python的pandas模块。pandas模块是Python编程语言中用于数据处理和分析的强大模块&a…...
树叶识别系统python+Django网页界面+TensorFlow+算法模型+数据集+图像识别分类
一、介绍 树叶识别系统。使用Python作为主要编程语言开发,通过收集常见的6中树叶(‘广玉兰’, ‘杜鹃’, ‘梧桐’, ‘樟叶’, ‘芭蕉’, ‘银杏’)图片作为数据集,然后使用TensorFlow搭建ResNet50算法网络模型,通过对…...

【问题解决:配置】解决spring mvc项目 get请求 获取中文字符串参数 乱码
get类型请求的发送过程 前端发送一个get请求的过程: 封装参数进行URL编码,也就是将中文编码成一个带有百分号的字符串,具体可以在这个网站进行测试。http://www.esjson.com/urlEncode.html 进行Http编码,这里浏览器或者postman都…...

python每日一练(9)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

JVM第十四讲:调试排错 - Java 内存分析之堆内存和MetaSpace内存
调试排错 - Java 内存分析之堆内存和MetaSpace内存 本文是JVM第十四讲,以两个简单的例子(堆内存溢出和MetaSpace (元数据) 内存溢出)解释Java 内存溢出的分析过程。 文章目录 调试排错 - Java 内存分析之堆内存和MetaSpace内存1、常见的内存溢出问题(内存…...

【1day】泛微e-office OA SQL注入漏洞学习
注:该文章来自作者日常学习笔记,请勿利用文章内的相关技术从事非法测试,如因此产生的一切不良后果与作者无关。 目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现...

线上问题:所有用户页面无法打开
线上问题:所有用户页面无法打开 1 线上问题2 问题处理3 复盘3.1 第二天观察 1 线上问题 上午进入工作时间,Cat告警出现大量linda接口超时Exception。 随后,产品和运营反馈无法打开页面,前线用户大量反馈无法打开页面。 2 问题处…...

RabbitMQ和spring boot整合及其他内容
在现代分布式应用程序的设计中,消息队列系统是不可或缺的一部分,它为我们提供了解耦组件、实现异步通信和确保高性能的手段。RabbitMQ,作为一款强大的消息代理,能够协助我们实现这些目标。在本篇CSDN博客中,我们将探讨…...
iperf3交叉编译
简介 iperf3是一个用于执行网络吞吐量测量的命令行工具。它支持时序、缓冲区、协议(TCP,UDP,SCTP与IPv4和IPv6)有关的各种参数。对于每次测试,它都会详细的带宽报告,延迟抖动和数据包丢失。 如果是ubuntu系…...
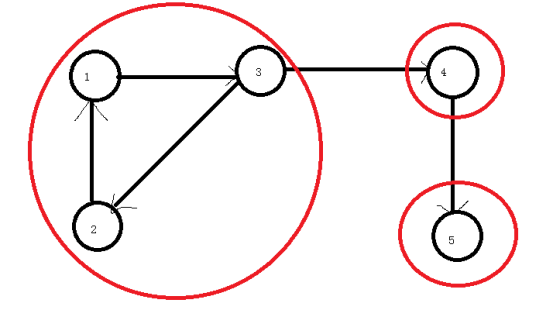
TARJAN复习 求强连通分量、割点、桥
TARJAN复习 求强连通分量、割点、桥 文章目录 TARJAN复习 求强连通分量、割点、桥强连通分量缩点桥割点 感觉之前写的不好, 再水一篇博客 强连通分量 “有向图强连通分量:在有向图G中,如果两个顶点vi,vj间(vi>vj)有…...

python实现批量数据库数据插入
import pandas as pd import pymysql # 连接 MySQL 数据库 conn pymysql.connect( hostlocalhost, useryour_username, passwordyour_password, databaseyour_database_name, charsetutf8mb4, ) # 读取已有数据 existing_data pd.read_csv("86w全…...

python安装,并搞定环境配置和虚拟环境
鄙人使用Python来进行项目的开发,一般都是通过Anaconda来完成的。Anaconda不但封装了Python,还包含了创建虚拟环境的工具。 anaconda安装 安装anaconda,可以搜索清华镜像源,然后搜索anaconda,点击进入,然…...
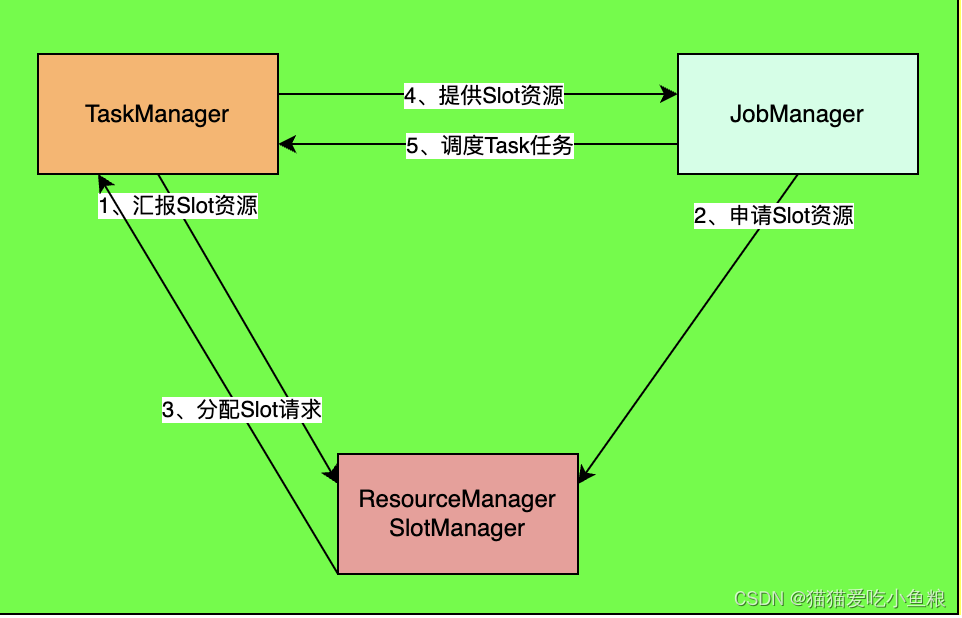
Flink 的集群资源管理
集群资源管理 一、ResourceManager 概述 1、ResourceManager 作为统一的集群资源管理器,用于管理整个集群的计算资源,包括 CPU资源、内存资源等。 2、ResourceManager 负责向集群资源管理器申请容器资源启动TaskManager实例,并对TaskManag…...

STM32学习笔记
前言 今天开始学习STM32,公司封闭git网络,所以选择CSDN来同步学习进度,方便公司和家里都能更新学习笔记。 参考学习资料 江科大STM32教学视频: 江科大自动协STM32视频_哔哩哔哩_bilibili...
Java应用性能问题诊断技巧
作者:张彦东 参考:https://developer.aliyun.com/ebook/450?spma2c6h.20345107.ebook-index.28.6eb21f54J7SUYc 文章目录 (一)内存1.内存2.内存-JMX3.内存-Jmap4.内存-结合代码确认问题 (二)CPU1.CPU-JMX或…...

监控系列(六)prometheus监控DMHS操作步骤
一、监控的操作逻辑 给操作系统安装expect命令expect脚本执行dmhs_console脚本执行 cpt / exec 命令用脚本进行过滤字符串过滤dm_export读取脚本与当前日期作比较,然后返回差值 二、安装步骤 1. linux中Expect工具的安装及使用方法 https://blog.csdn.net/wangta…...

SLAM从入门到精通(dwa速度规划算法)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 要说搜路算法,这个大家都比较好理解。毕竟从一个地点走到另外一个地点,这个都是直觉上可以感受到的事情。但是这条道路上机…...
嵌入式实时操作系统的设计与开发(aCoral线程学习)
真正的RTOS,基本上没有做到进程,只是停留在多线程,因为多进程要解决很多问题,且需要硬件支持,这样就使得系统复杂了,从而就可能影响系统实时性。 线程之间是共享地址的,也就是说当前线程的地址…...
JAVA基础(JAVA SE)学习笔记(二)变量与运算符
前言 1. 学习视频: 尚硅谷Java零基础全套视频教程(宋红康2023版,java入门自学必备)_哔哩哔哩_bilibili 2023最新Java学习路线 - 哔哩哔哩 正文 第一阶段:Java基本语法 1. Java 语言概述 JAVA基础(JAVA SE)学习…...

chatgpt 接口 和 jupyter版本安装
一 接口代码 有时间继续测试 import openai # 填入你的api_key openai.api_key ""models openai.Model.list()# 定义API参数 params {role: "user", "content": }# 定义循环 while True:# 获取用户输入user_input input("请输入您的消…...

BUUCTF [ZJCTF 2019]NiZhuanSiWei 通关详解:从PHP伪协议到反序列化的三层渗透
1. 题目初探与源码分析 第一次看到这道题的时候,我盯着屏幕上的PHP源码看了足足五分钟。题目给出了一个简单的PHP文件,要求我们通过三个参数来获取flag。这种层层递进的题目设计在CTF中很常见,但每一步都需要仔细思考。 源码的核心逻辑是这样…...

NV170D语音芯片在智能锁离线语音交互中的工程实践
1. 项目概述:当智能锁“开口说话”智能锁这东西,现在家里、公寓、办公室基本都普及了。从最早的密码、指纹,到现在的刷脸、手机NFC,解锁方式越来越花哨。但不知道你有没有过这样的体验:大晚上回家,楼道灯暗…...

终极微信小程序逆向解析指南:wxappUnpacker专业实战解析
终极微信小程序逆向解析指南:wxappUnpacker专业实战解析 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 微信小程序逆向解析是开发者深入理解小…...

硬件供电设计:解决模拟与数字电路噪声干扰的实战指南
1. 项目概述:从一次深夜宕机说起深夜两点,手机突然响起刺耳的告警铃声。一个关键的数据采集节点离线了。我睡眼惺忪地爬起来,远程登录,重启服务,一切如常。但半小时后,它又毫无征兆地“罢工”了。这种间歇性…...

新手PM如何快速成长?一套可落地的自我迭代复盘方法
新手 PM 想快速成长,不能只靠多做几个项目,更要学会从每个项目里复盘经验、发现问题、沉淀方法。尤其是从市场、运营、业务等岗位转型做项目经理的人,更需要通过复盘提升需求管理、进度管理和团队协作能力。本文分享一套适合项目经理新人的自…...

MySQL切换服务器数据迁移记录
老服务器性能不足,计划迁移数据至新服务器 一、查询 MySQL 数据库 / 表数据量大小 1、查询所有数据库的总大小 SELECTCONCAT(ROUND(SUM(data_length index_length) / 1024 / 1024, 2), MB) AS total_database_size,CONCAT(ROUND(SUM(data_length index_length) /…...

FlicFlac:3分钟掌握Windows音频格式转换的终极免费工具
FlicFlac:3分钟掌握Windows音频格式转换的终极免费工具 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备间的音频格式兼容性问…...

避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南
避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南 在芯片设计领域,可测试性设计(DFT)是确保产品质量的关键环节。而作为DFT的重要组成部分,存储器内建自测试(MBIST)的实现质量直接影响着…...

5分钟学会在Windows电脑上安装Android应用:APK Installer终极指南
5分钟学会在Windows电脑上安装Android应用:APK Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行手机应用吗&#x…...

革命性开源定价引擎Lotus:如何快速构建灵活的SaaS计费系统
革命性开源定价引擎Lotus:如何快速构建灵活的SaaS计费系统 【免费下载链接】lotus Open Source Pricing & Packaging Infrastructure 项目地址: https://gitcode.com/gh_mirrors/lot/lotus 在当今竞争激烈的SaaS市场中,定价策略已成为决定产品…...