Amazon图片下载器:利用Scrapy库完成图像下载任务

概述
本文介绍了如何使用Python的Scrapy库编写一个简单的爬虫程序,实现从Amazon网站下载商品图片的功能。Scrapy是一个强大的爬虫框架,提供了许多方便的特性,如选择器、管道、中间件、代理等。本文将重点介绍如何使用Scrapy的图片管道和代理中间件,以提高爬虫的效率和稳定性。
正文
1. 创建Scrapy项目
首先,我们需要创建一个Scrapy项目,命名为amazon_image_downloader。在命令行中输入以下命令:
scrapy startproject amazon_image_downloader
这将在当前目录下生成一个名为amazon_image_downloader的文件夹,其中包含以下文件和子文件夹:
amazon_image_downloader/scrapy.cfg # 配置文件amazon_image_downloader/ # 项目的Python模块__init__.pyitems.py # 项目中的item文件middlewares.py # 项目中的中间件文件pipelines.py # 项目中的管道文件settings.py # 项目的设置文件spiders/ # 存放爬虫代码的目录__init__.py
2. 定义Item类
接下来,我们需要在items.py文件中定义一个Item类,用来存储我们要爬取的数据。在本例中,我们只需要爬取商品图片的URL和名称,所以我们可以定义如下:
import scrapyclass AmazonImageItem(scrapy.Item):# 定义一个Item类,用来存储图片的URL和名称image_urls = scrapy.Field() # 图片的URL列表image_name = scrapy.Field() # 图片的名称
3. 编写爬虫代码
然后,我们需要在spiders文件夹中创建一个名为amazon_spider.py的文件,编写我们的爬虫代码。我们可以使用Scrapy提供的CrawlSpider类来实现自动跟进链接的功能。我们需要指定以下内容:
- name: 爬虫的名称,用来运行爬虫时使用。
- allowed_domains: 允许爬取的域名列表,防止爬虫跑到其他网站上。
- start_urls: 起始URL列表,爬虫会从这些URL开始抓取数据。
- rules: 规则列表,用来指定如何从响应中提取链接并跟进。
- parse_item: 解析函数,用来从响应中提取数据并生成Item对象。
我们可以参考Amazon网站的结构和URL规律,编写如下代码:
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from amazon_image_downloader.items import AmazonImageItemclass AmazonSpider(CrawlSpider):# 定义一个CrawlSpider类,用来实现自动跟进链接的功能name = 'amazon_spider' # 爬虫的名称allowed_domains = ['amazon.com'] # 允许爬取的域名列表start_urls = ['https://www.amazon.com/s?k=book'] # 起始URL列表rules = (# 定义规则列表,指定如何从响应中提取链接并跟进Rule(LinkExtractor(allow=r'/s\?k=book&page=\d+'), follow=True), # 匹配商品列表页的链接,并跟进Rule(LinkExtractor(allow=r'/dp/\w+'), callback='parse_item'), # 匹配商品详情页的链接,并调用parse_item函数)def parse_item(self, response):# 定义解析函数,从响应中提取数据并生成Item对象item = AmazonImageItem() # 创建一个Item对象item['image_urls'] = [response.xpath('//img[@id="imgBlkFront"]/@src').get()] # 从响应中提取图片的URL,并存入image_urls字段item['image_name'] = response.xpath('//span[@id="productTitle"]/text()').get().strip() # 从响应中提取图片的名称,并存入image_name字段return item # 返回Item对象
4. 配置图片管道和代理中间件
最后,我们需要在settings.py文件中配置图片管道和代理中间件,以实现图片的下载和代理的使用。我们需要修改以下内容:
- ITEM_PIPELINES: 项目中启用的管道类及其优先级的字典。我们需要启用Scrapy提供的ImagesPipeline类,并指定一个合适的优先级,如300。
- IMAGES_STORE: 图片管道使用的本地存储路径。我们可以指定一个名为images的文件夹,用来存放下载的图片。
- IMAGES_URLS_FIELD: 图片管道使用的Item字段,该字段的值是一个包含图片URL的列表。我们需要指定为image_urls,与我们定义的Item类一致。
- IMAGES_RESULT_FIELD: 图片管道使用的Item字段,该字段的值是一个包含图片信息的列表。我们可以指定为image_results,用来存储图片的路径、校验码、大小等信息。
- DOWNLOADER_MIDDLEWARES: 项目中启用的下载器中间件类及其优先级的字典。我们需要启用Scrapy提供的HttpProxyMiddleware类,并指定一个合适的优先级,如100。
- PROXY_POOL: 代理池,用来提供代理IP和端口。我们可以使用亿牛云爬虫代理提供的域名、端口、用户名、密码
- CONCURRENT_REQUESTS: Scrapy downloader 并发请求(concurrent requests)的最大值。我们可以根据我们的网络和代理的质量,设置一个合适的值,如16。
- CONCURRENT_REQUESTS_PER_DOMAIN: 对单个网站进行并发请求的最大值。我们可以根据目标网站的反爬策略,设置一个合适的值,如8。
- DOWNLOAD_DELAY: 下载两个页面之间等待的时间。这可以用来限制爬取速度,减轻服务器压力。我们可以根据目标网站的反爬策略,设置一个合适的值,如0.5秒。
修改后的settings.py文件如下:
# Scrapy settings for amazon_image_downloader projectassistant = 'amazon_image_downloader'SPIDER_MODULES = ['amazon_image_downloader.spiders']
NEWSPIDER_MODULE = 'amazon_image_downloader.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'amazon_image_downloader (+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = False# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 300, # 启用图片管道,并指定优先级为300
}# Configure images pipeline
# See https://docs.scrapy.org/en/latest/topics/images.html
IMAGES_STORE = 'images' # 指定图片管道使用的本地存储路径为images文件夹
IMAGES_URLS_FIELD = 'image_urls' # 指定图片管道使用的Item字段为image_urls
IMAGES_RESULT_FIELD = 'image_results' # 指定图片管道使用的Item字段为image_results# Configure downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 100, # 启用代理中间件,并指定优先级为100
}# Configure proxy pool
# 亿牛云代理 https://www.16yun.cn
PROXY_POOL = ['http://username:password@domain:port', # 使用亿牛云爬虫代理提供的域名、端口、用户名、密码'http://username:password@domain:port',...
]# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item exporters
## Configure concurrent requests and download delay
# See https://docs.scrapy.org/en/latest/topics/settings.html
CONCURRENT_REQUESTS = 16 # 设置Scrapy downloader 并发请求的最大值为16
CONCURRENT_REQUESTS_PER_DOMAIN = 8 # 设置对单个网站进行并发请求的最大值为8
DOWNLOAD_DELAY = 0.5 # 设置下载两个页面之间等待的时间为0.5秒
结语
本文介绍了如何使用Python的Scrapy库编写一个简单的爬虫程序,实现从Amazon网站下载商品图片的功能。我们使用了Scrapy的图片管道和代理中间件,以提高爬虫的效率和稳定性。我们还使用了多线程技术,提高采集速度。这个爬虫程序只是一个示例,你可以根据你的具体需求进行修改和优化,感谢你的阅读。
相关文章:
Amazon图片下载器:利用Scrapy库完成图像下载任务
概述 本文介绍了如何使用Python的Scrapy库编写一个简单的爬虫程序,实现从Amazon网站下载商品图片的功能。Scrapy是一个强大的爬虫框架,提供了许多方便的特性,如选择器、管道、中间件、代理等。本文将重点介绍如何使用Scrapy的图片管道和代理…...

Unity中Shader的Pass的复用
文章目录 前言一、怎么实现Pass的复用1、给需要引用的Pass给定特定的名字2、在需要引用 Pass 的Shader中,在Pass的平行位置使用 UsePass "ShaderPath PassName" 二、实现一个没被遮挡的部分显示模型原本的样子,遮挡部分显示模型的XRay效果1、…...

vue内容自适应方法
Vue中可以通过以下几种方式实现内容自适应: 使用CSS媒体查询:使用CSS媒体查询可以根据屏幕大小来动态改变元素的样式。例如,可以设置一个div元素在屏幕宽度小于600px时宽度为100%,在屏幕宽度大于600px时宽度为50%。 使用Vue的计算…...

RustDay05------Exercise[41-50]
41.使用模块的函数 mod 是用于创建模块的关键字。模块是一种组织代码的方式,它可以包含函数 (fn)、结构体 (struct)、枚举 (enum)、常量 (const)、其他模块 (mod) 等。模块用于组织和封装代码,帮助将代码分割成可管理的单元。模块可以形成层次结构&…...
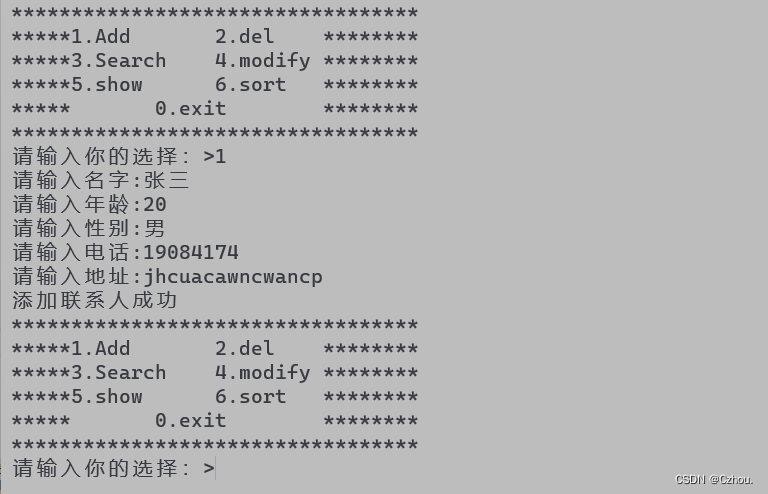
C语言实现通讯录(超详细)
1.实现怎样一个通讯录 实现一个通讯录联系人信息:1.可以保存100个人的信息名字2.添加联系人年龄3.删除指定联系人性别4.查找指定联系人电话5.修改指定联系人住址6.排序联系人7.显示所有联系人信息 2.通讯录的实现 2.1创建两个源文件和一个头文件 首先我们创建con…...

【Python机器学习】零基础掌握MinCovDet协方差估计
如何更精准地评估资产的风险和收益? 在投资领域,资产的风险和收益评估是至关重要的。传统的协方差矩阵虽然在某种程度上能反映资产间的关联性,但也存在一定的局限性。例如如果样本数量较少,传统的协方差矩阵可能会出现偏差,从而影响投资决策。 假设现在有一个投资组合,…...
2023年【四川省安全员A证】模拟试题及四川省安全员A证作业模拟考试
题库来源:安全生产模拟考试一点通公众号小程序 2023年四川省安全员A证模拟试题为正在备考四川省安全员A证操作证的学员准备的理论考试专题,每个月更新的四川省安全员A证作业模拟考试祝您顺利通过四川省安全员A证考试。 1、【多选题】36V照明适用的场所条…...

Flask项目log的集成
一、引入log 在项目的init.py文件中: import logging from logging.handlers import RotatingFileHandlerfrom flask_wtf.csrf import CSRFProtect from flask import Flask from flask_sqlalchemy import SQLAlchemy from redis import StrictRedis from flask_s…...

Open3D(C++) 最小二乘拟合平面(拉格朗日乘子法)
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。 一、算法原理 设拟合出的平面方程为: a x + b y + c...
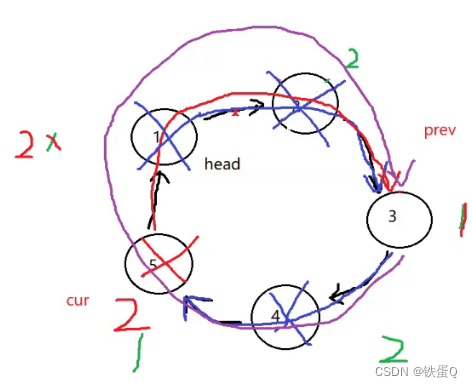
c语言练习93:环形链表的约瑟夫问题
环形链表的约瑟夫问题 环形链表的约瑟夫问题_牛客题霸_牛客网 描述 编号为 1 到 n 的 n 个人围成一圈。从编号为 1 的人开始报数,报到 m 的人离开。 下一个人继续从 1 开始报数。 n-1 轮结束以后,只剩下一个人,问最后留下的这个人编号是…...
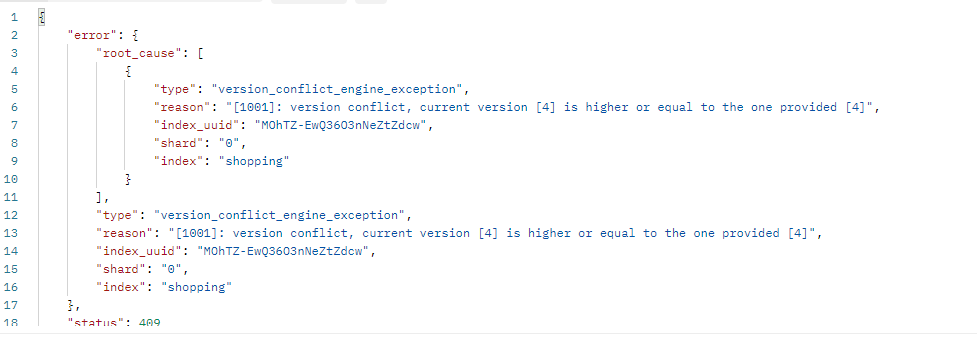
从入门到进阶 之 ElasticSearch 文档、分词器 进阶篇
🌹 以上分享 ElasticSearch 文档、分词器 进阶篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞💖收藏&#…...

亚马逊云科技多项新功能与服务,助力各种规模的组织拥抱生成式 AI
从初创企业到大型企业,各种规模的组织都纷纷开始接触生成式 AI 技术。这些企业希望充分利用生成式 AI,将自身在测试版、原型设计以及演示版中的畅想带到现实场景中,实现生产力的大幅提升并大力进行创新。但是,组织要怎样才能在企业…...

网站布局都有哪些?
网站布局是指网页中各元素的布局方式,以下是一些常见的网站布局: 栅格布局:将页面分成一个个小格子,再把内容放到对应的格子中。这种布局有利于提高网页的视觉一致性和用户体验,是网站设计中最常用的布局方式之一。流…...
)
第17章 MQ(一)
17.1 谈谈你对MQ的理解 难度:★ 重点:★★ 白话解析 MQ也要有一跟主线,先理解它是什么,从三个方面去理解就好了:1、概念;2、核心功能;3、分类。 1、概念:MQ(Message Queue),消息队列,是基础数据结构中“先进先出”的一种数据结构。指把要传输的数据(消息)放在队…...
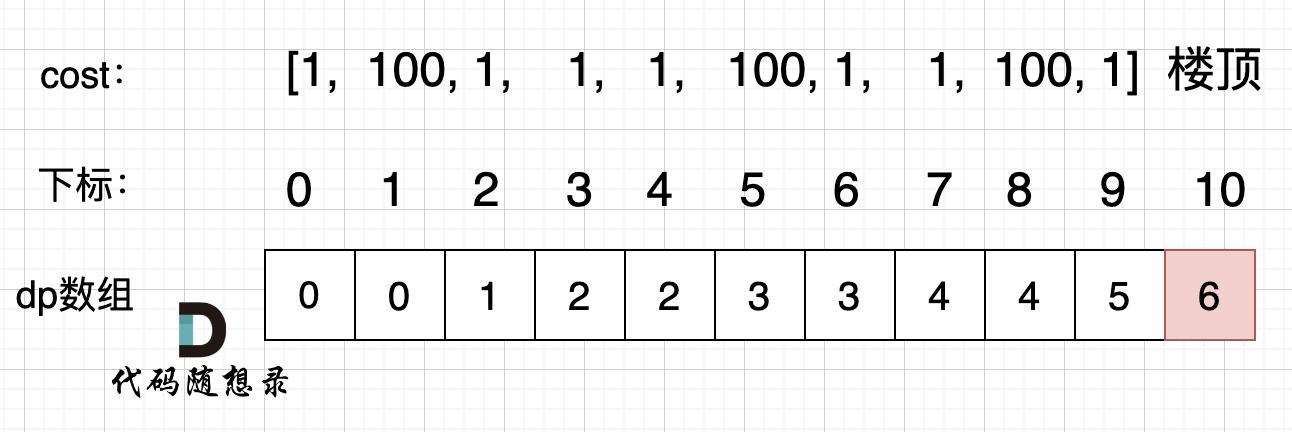
LeetCode算法刷题(python) Day41|09动态规划|理论基础、509. 斐波那契数、70. 爬楼梯、746. 使用最小花费爬楼梯
目录 动规五部曲LeetCode 509. 斐波那契数LeetCode 70. 爬楼梯LeetCode 746. 使用最小花费爬楼梯 动规五部曲 确定dp数组以及下标的含义确定递归公式dp数组如何初始化确定遍历顺序举例推导dp数组 LeetCode 509. 斐波那契数 力扣题目链接 本题最直观是用递归方法 class Sol…...
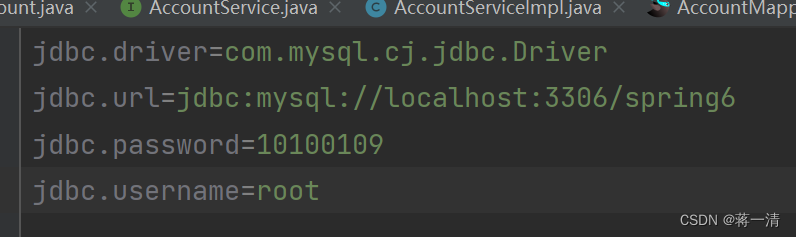
Spring(四)
1、Spring6整合JUnit 1、JUnit4 User类: package com.songzhishu.spring.bean;import org.springframework.beans.factory.annotation.Value; import org.springframework.stereotype.Component;/*** BelongsProject: Spring6* BelongsPackage: com.songzhishu.spring.bean*…...
)
2023-10-8讯飞大模型部署2024秋招后端一面(附详解)
1 mybatis的mapper是什么东西 在MyBatis中,mapper是一个核心概念,它起到了桥梁的作用,连接Java对象和数据库之间的数据。具体来说,mapper可以分为以下两个部分: Mapper XML文件: 这是一个XML文件ÿ…...
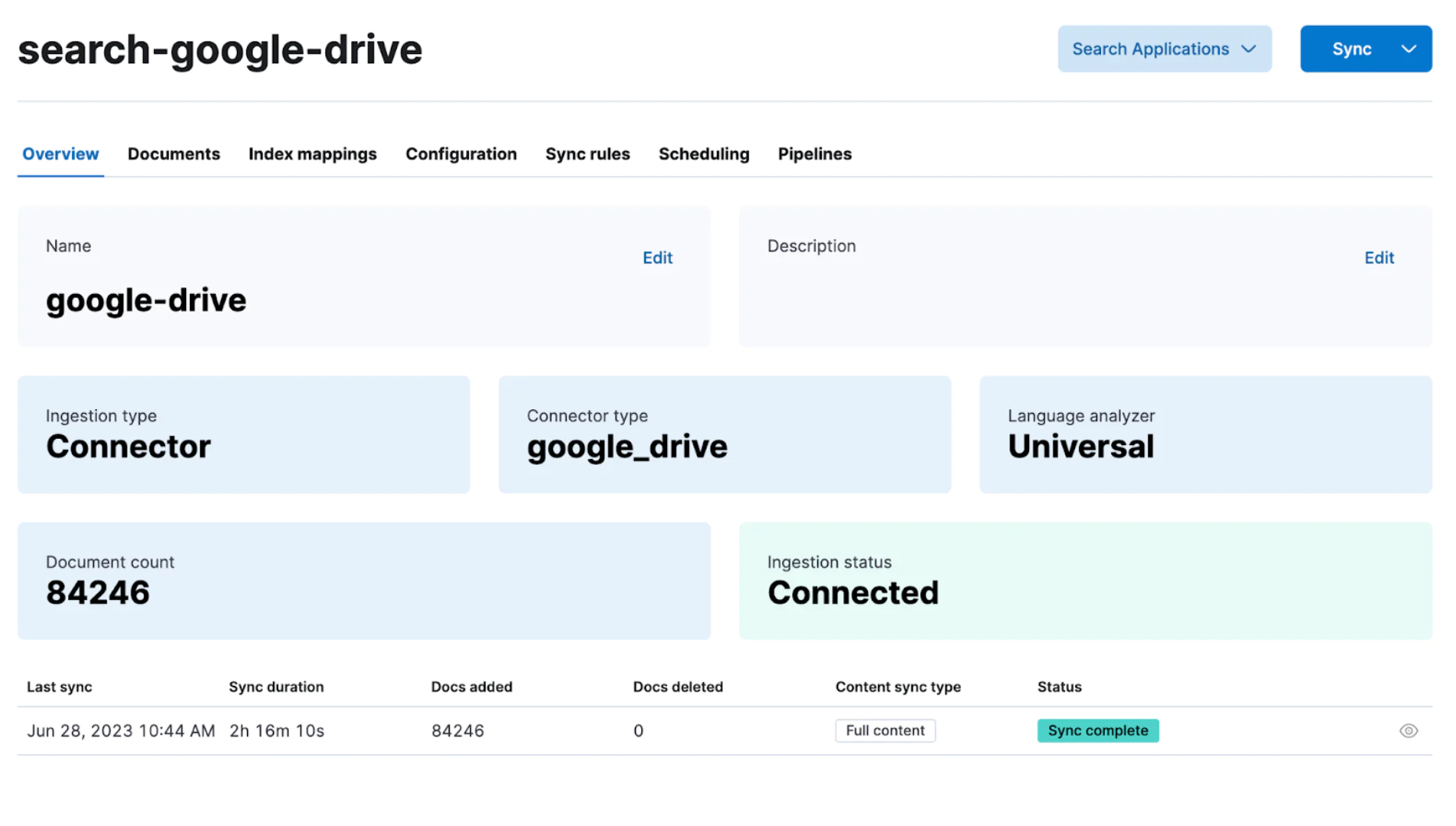
如何为 Elasticsearch 创建自定义连接器
了解如何为 Elasticsearch 创建自定义连接器以简化数据摄取过程。 作者:JEDR BLASZYK Elasticsearch 拥有一个摄取工具库,可以从多个来源获取数据。 但是,有时你的数据源可能与 Elastic 现有的提取工具不兼容。 在这种情况下,你可…...

Debian11 安装 OpenJDK8
1. 下载安装包 wget http://snapshot.debian.org/archive/debian-security/20220210T090326Z/pool/updates/main/o/openjdk-8/openjdk-8-jdk_8u322-b06-1~deb9u1_amd64.deb wget http://snapshot.debian.org/archive/debian-security/20220210T090326Z/pool/updates/main/o/op…...
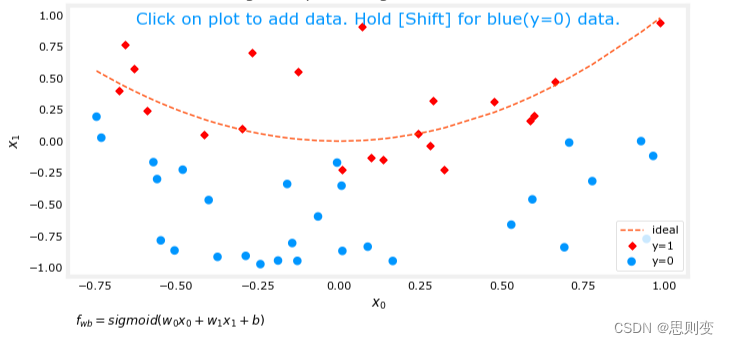
[Machine Learning][Part 6]Cost Function代价函数和梯度正则化
目录 拟合 欠拟合 过拟合 正确的拟合 解决过拟合的方法:正则化 线性回归模型和逻辑回归模型都存在欠拟合和过拟合的情况。 拟合 来自百度的解释: 数据拟合又称曲线拟合,俗称拉曲线,是一种把现有数据透过数学方法来代入一条…...

解锁Unity游戏插件开发:从概念到实战的MelonLoader全攻略
解锁Unity游戏插件开发:从概念到实战的MelonLoader全攻略 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 一、认知篇…...

当Excel图表无法表达你的数据故事时:Charticulator开启零代码可视化创作新纪元
当Excel图表无法表达你的数据故事时:Charticulator开启零代码可视化创作新纪元 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 问题:数据…...

VCNL4020 proximity与环境光传感器集成设计指南
1. VCNL4020传感器技术解析:面向嵌入式系统的 proximity 与环境光一体化解决方案VCNL4020 是 Vishay 公司推出的高集成度光学传感芯片,专为资源受限的嵌入式系统设计。其核心价值在于将红外发射器(IRED)、接近检测光电二极管、环境…...

Halcon点云拼接实战:如何用特征模板搞定3D扫描缺失问题?
Halcon点云拼接实战:特征模板技术在工业3D扫描中的应用 在工业检测和逆向工程领域,3D扫描常常面临一个棘手问题——单次扫描无法完整捕获复杂物体的所有表面细节。想象一下,当您需要检测一个汽车发动机缸体的内部结构,或者重建一…...

1.6.2 掌握Scala数据结构 - 列表
本次实战深入讲解了Scala中不可变列表与可变列表的核心操作。首先,详细演示了不可变列表的创建与元素添加,重点强调了其不可变特性——任何添加或合并操作(如::、)都会生成新列表而不改变原列表。接着,介绍了可变列表L…...
和CVaR风险管理,用于求解含高比例)
CSDN首页发布文章基于Min-Max-Max-Min四层优化架构的多能源系统日前-实时两阶段鲁棒调度模型,结合了Wasserstein分布鲁棒优化(DRO)和CVaR风险管理,用于求解含高比例
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

VibeVoice API接口调用案例:WebSocket流式通信实测
VibeVoice API接口调用案例:WebSocket流式通信实测 1. 项目概述 VibeVoice 是一个基于微软开源模型的实时语音合成系统,能够将文本内容快速转换为高质量的语音输出。这个系统特别适合需要实时语音交互的应用场景,比如语音助手、有声读物制作…...

如何通过5个关键步骤实现Altair GraphQL Client与GitHub的高效团队协作开发
如何通过5个关键步骤实现Altair GraphQL Client与GitHub的高效团队协作开发 【免费下载链接】altair ✨⚡️ A feature-rich GraphQL Client for all platforms. 项目地址: https://gitcode.com/gh_mirrors/alta/altair Altair GraphQL Client是一款功能丰富的跨平台Gra…...

突破限制:3大核心功能让MediaCreationTool.bat成为Windows安装自由的终极解决方案
突破限制:3大核心功能让MediaCreationTool.bat成为Windows安装自由的终极解决方案 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/Media…...

DeepSeek-Coder-V2-Lite-Instruct跨平台兼容性测试:在不同环境中的运行表现
DeepSeek-Coder-V2-Lite-Instruct跨平台兼容性测试:在不同环境中的运行表现 【免费下载链接】DeepSeek-Coder-V2-Lite-Instruct 开源代码智能利器——DeepSeek-Coder-V2,性能比肩GPT4-Turbo,全面支持338种编程语言,128K超长上下文…...