pytorch分布式数据训练结合学习率周期及混合精度
文章目录
- 1、SPAWN方式
- 2、torchrun 方式
正如标题所写,我们正常的普通训练都是单机单卡或单机多卡。而往往一个高精度的模型需要训练时间很长,所以DDP分布式数据并行和混合精度可以加速模型训练。混精可以增大batch size.
如下提供示例代码,经过官网查阅验证的。原始代码由百度文心一言提供。
问题:pytorch 分布式数据并行与学习率周期和混合精度训练的示例代码
该问题分别问了(当前2023年10月16日)百度文心一言,google bard,科大讯飞星火,chatgpt4,bing。目前看来只有文心给出最接近正确答案。当前版本 pythorch 2.0.1。关于混精 torch.cuda.amp.autocast(args...)`` is equivalent to ``torch.autocast("cuda", args...),混精可以参考:
- https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html?highlight=torch%20cuda%20amp%20autocast
- https://pytorch.org/docs/stable/amp.html#gradient-scaling
1、SPAWN方式
在使用这些助手(都是免费的)时,发现对于不同问题,各自的优劣不同,所以可以都试一下。
在PyTorch中,分布式数据并行(Distributed Data Parallel,DDP)可以在多个GPU上并行训练模型,提高训练速度。学习率周期(Learning Rate Schedules)用于调整训练过程中学习率的变化,而混合精度训练则可以提高训练速度并减少内存使用。
以下是一个使用PyTorch的分布式数据并行、学习率周期和混合精度训练的示例代码:
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim.lr_scheduler import ExponentialLR, CosineAnnealingLR
from torch.cuda.amp import GradScaler, autocastdef setup(rank, world_size):"""Args:rank: Unique identifier of each processworld_size: Total number of processes"""os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'# initialize the process groupdist.init_process_group(backend="nccl", rank=rank, world_size=world_size)torch.cuda.set_device(rank)def cleanup():dist.destroy_process_group()
# 定义模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 10)def forward(self, x):return self.fc(x)# 训练函数
def train(rank, world_size):print(f"Running basic DDP example on rank {rank}.")gpu=ranksetup(rank=rank,world_size=world_size,)torch.manual_seed(0)model = SimpleModel().cuda(gpu)ddp_model = DDP(model, device_ids=[gpu])# 使用混合精度训练scaler = GradScaler()optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)# 使用学习率周期scheduler1 = ExponentialLR(optimizer, gamma=0.9)scheduler2 = CosineAnnealingLR(optimizer, T_max=50, eta_min=0)# 模拟数据data = torch.randn(32, 10).to(gpu)target = torch.randn(32, 10).to(gpu)for epoch in range(100):optimizer.zero_grad()with autocast(): # 启用混合精度训练output = ddp_model(data)loss = nn.MSELoss()(output, target)scaler.scale(loss).backward() # 使用scaler进行梯度缩放scaler.step(optimizer) # 更新参数scaler.update() # 更新GradScaler状态scheduler1.step() # 使用ExponentialLR调整学习率scheduler2.step() # 使用CosineAnnealingLR调整学习率print(f"Rank {rank}, Epoch {epoch}, Loss {loss.item()}")cleanup()
if __name__ == "__main__":world_size = torch.cuda.device_count() # 获取可用GPU的数量mp.spawn(train, args=(world_size,), nprocs=world_size, join=True) # 在每个GPU上运行train函数这个示例代码在每个GPU上并行训练一个简单的线性模型。每个进程(即每个GPU)都有自己的模型副本,并且每个进程都独立计算梯度。然后,所有进程都会聚集他们的梯度并平均,然后用于一次总体参数更新。这个过程会根据学习率周期来调整每个epoch后的学习率
本部分参考官方的:https://pytorch.org/tutorials/beginner/ddp_series_multigpu.html?highlight=torch%20multiprocessing 是写单GPU和多GPU的区别。
2、torchrun 方式
首先是写一个ddp.py,内容如下:
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim.lr_scheduler import ExponentialLR, CosineAnnealingLR
from torch.cuda.amp import GradScaler, autocast# 定义模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 10)def forward(self, x):return self.fc(x)# 训练函数
def train():dist.init_process_group("nccl")rank = dist.get_rank()print(f"Start running basic DDP example on rank {rank}.")gpu = rank % torch.cuda.device_count()torch.manual_seed(0)model = SimpleModel().to(gpu)ddp_model = DDP(model, device_ids=[gpu])# 使用混合精度训练scaler = GradScaler()optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)# 使用学习率周期scheduler1 = ExponentialLR(optimizer, gamma=0.9)scheduler2 = CosineAnnealingLR(optimizer, T_max=50, eta_min=0)# 模拟数据data = torch.randn(32, 10).to(gpu)target = torch.randn(32, 10).to(gpu)for epoch in range(100):optimizer.zero_grad()with autocast(): # 启用混合精度训练output = ddp_model(data)loss = nn.MSELoss()(output, target)scaler.scale(loss).backward() # 使用scaler进行梯度缩放scaler.step(optimizer) # 更新参数scaler.update() # 更新GradScaler状态scheduler1.step() # 使用ExponentialLR调整学习率scheduler2.step() # 使用CosineAnnealingLR调整学习率print(f"Rank {rank}, Epoch {epoch}, Loss {loss.item()}")dist.destroy_process_group()
if __name__ == "__main__":train()
单机多卡,执行:
torchrun --nproc_per_node=4 --standalone ddp.py
如果是多机多卡:
torchrun --nnodes=2 --nproc_per_node=8 --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=$MASTER_ADDR:29400 elastic_ddp.py
本部分参考:
https://pytorch.org/tutorials/intermediate/ddp_tutorial.html#save-and-load-checkpoints
相关文章:

pytorch分布式数据训练结合学习率周期及混合精度
文章目录 1、SPAWN方式2、torchrun 方式 正如标题所写,我们正常的普通训练都是单机单卡或单机多卡。而往往一个高精度的模型需要训练时间很长,所以DDP分布式数据并行和混合精度可以加速模型训练。混精可以增大batch size. 如下提供示例代码,经…...

Looper分析
Looper分析 在 Handler 机制中,Looper 的作用是提供了一个消息循环 ( message loop ) 的机制,用于处理和分发消息。 Looper 是一个线程局部的对象,每个线程只能有一个 Looper 对象。它通过一个无限循环来不断地从消息队列中取出消息&#x…...

LoongArch单机Ceph Bcache加速4K随机写性能测试
LoongArch单机Ceph Bcache加速4K随机写性能测试 两块HDD做OSD [rootceph01 ~]# fio -direct1 -iodepth128 -thread -rwrandwrite -ioenginelibaio -bs4k -size100G -numjobs1 -runtime600 -group_reporting -namemytest -filename/dev/rbd0 mytest: (g0): rwrandwrite, bs(R)…...

景联文科技语音数据标注:AUTO-AVSR模型和数据助力视听语音识别
ASR、VSR和AV-ASR的性能提高很大程度上归功于更大的模型和训练数据集的使用。 更大的模型具有更多的参数和更强大的表示能力,能够捕获到更多的语言特征和上下文信息,从而提高识别准确性;更大的训练集也能带来更好的性能,更多的数据…...
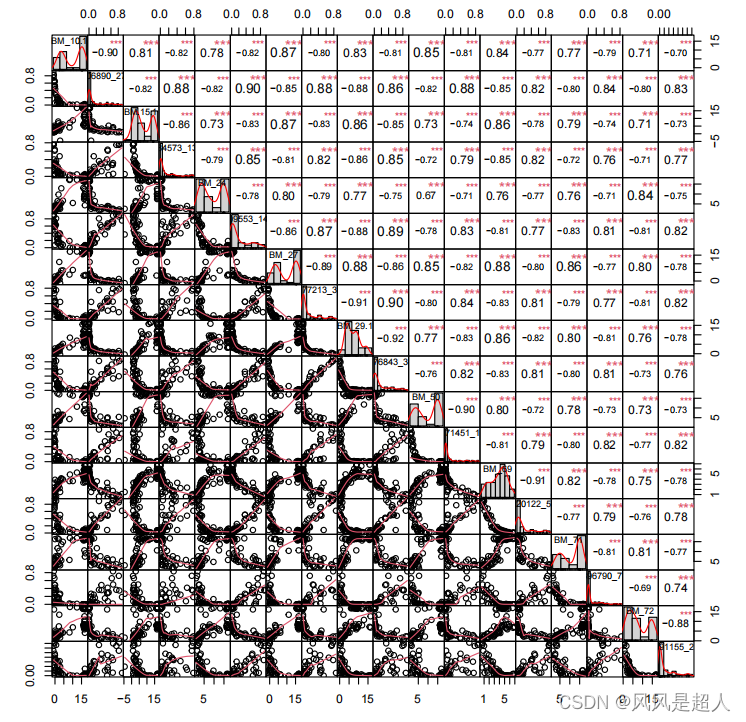
【R】数据相关性的可视化
一千零一技|相关性分析及其可视化:copy&paste,搞定 .libPaths(c("/bioinfo/home/software/miniconda3/envs/R4.0/lib/R/library")) #data("mtcars") library("PerformanceAnalytics") # pdf("test.pdf") #…...

Spring Security 6.x 系列【68】 授权篇之基于注解 缓存的访问控制方案
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.1.0 本系列Spring Security 版本 6.1.0 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 1. 前言2. 改造思路3. 实现3.1 基础工程3.2 数据库存储用户3.3 自定义3.4 测…...

QML(11)——qml界面之间通信方式详解
目录 一、属性绑定1、直接绑定 property01: property02实例代码 2、条件绑定 Qt.binding实例代码 二、信号传递1、on<Property>Changed实例代码 2、on<Signal>实例代码 3、条件信号传递 connect实例代码 4、Connections 一、属性绑定 属性绑定具有持续性 1、直接…...
图像检索算法 计算机竞赛
文章目录 1 前言2 图像检索介绍(1) 无监督图像检索(2) 有监督图像检索 3 图像检索步骤4 应用实例5 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 图像检索算法 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐ÿ…...

科学清理Windows系统垃圾,让你的电脑性能快如火箭
文章目录 1. 使用磁盘清理工具2. 清理临时文件2.1 清理用户临时文件夹2.2 清理系统临时文件夹2.3 清理系统临时文件 3.卸载不需要的程序4. 删除不必要的下载文件5. 清理回收站6. 压缩磁盘7. 删除旧的系统还原点8. 禁用休眠功能9. 定期进行磁盘碎片整理10. 禁用不必要的启动项11…...
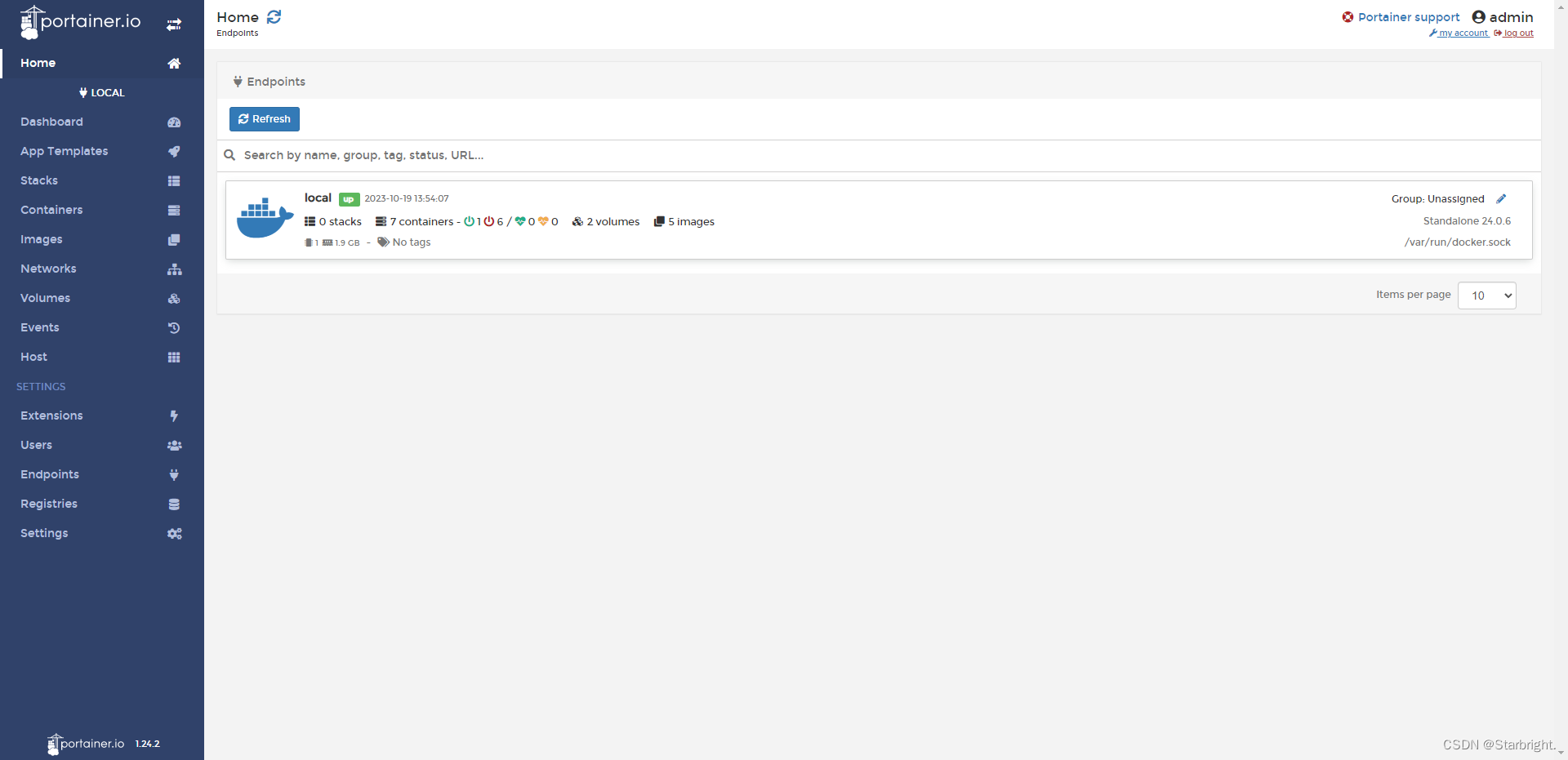
docker图形胡界面管理工具--Portainer可视化面板安装
1.安装运行Portainer docker run -d -p 8088:9000 \ > --restartalways -v /var/run/docker.sock:/var/run/docker.sock --privilegedtrue portainer/portainer--restartalways:Docker启动后容器自动启动 -p:端口映射 -v:路径映射2.通过…...

环形链表的约瑟夫问题
前言: 据说著名犹太历史学家Josephus有过如下故事: 在罗马人占领乔塔帕特后,39个犹太人和Josephus及他的朋友躲进一个洞里,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个…...

python requests.get发送Http请求响应结果乱码、Postman请求结果正常
最近在写爬虫程序,自己复制网页http请求的url、头部,使用python requests和postman分别请求,结果使用postman发送http get请求,可以得到正常的json数据,但是使用python的requests发送则接受到乱码,response…...

Dialog动画相关
最近需求一个问题,想要在dialog消失时增加动画,之前如上一个文章中遇到的,但是最后改了实现方式,要求在特定的地方缩放,原来的dialog高度是wrap_content的,这样是无法实现的,因此首先需要将dial…...
)
【java学习—八】==操作符与equals方法(2)
文章目录 1. 操作符2. equals方法String对象的创建 1. 操作符 (1)基本类型比较值 : 只要两个变量的值相等,即为 true. int a5; if(a6){…} (2)引用类型比较引用 ( 是否指向同一个对象 ): 只有指向同一个对象时&#…...

Linux系统编程_进程间通信第1天:IPC、无名管道pipe和命名管道mkfifo(半双工)、消息队列msgget(全双工)
1. 进程间通信概述(427.1) 2. 管道通信原理(428.2) 进程间的五种通信方式介绍 https://blog.csdn.net/wh_sjc/article/details/70283843 进程间通信(IPC,InterProcess Communication)ÿ…...
figma+windows系统
...

typescript实现一个简单的区块链
TypeScript 是一种由 Microsoft 推出的开源编程语言,它是 JavaScript 的超集,允许程序员使用面向对象的方式编写代码,并提供类型检查和语法提示等优秀的开发体验。区块链技术是一种分布式的、可靠的、不可篡改的数据库技术,用于记…...

服务器被暴力破解怎么解决
暴力破解分两种,一种是SSH暴力破解,属于Linux服务器。一种是RDP暴力破解,属于Windows服务器。两者其实攻击手法一样,都是黑客利用扫描工具对某一个IP段扫描,而Linux跟Windows登录端口为别是22和3389。那怎样才能有效避…...

用来生成二维矩阵的dcgan
有大量二维矩阵作为样本,为连续数据。数据具有空间连续性,因此用卷积网络,通过dcgan生成二维矩阵。因为是连续变量,因此损失采用nn.MSELoss()。 import torch import torch.nn as nn import torch.optim as optim import numpy a…...
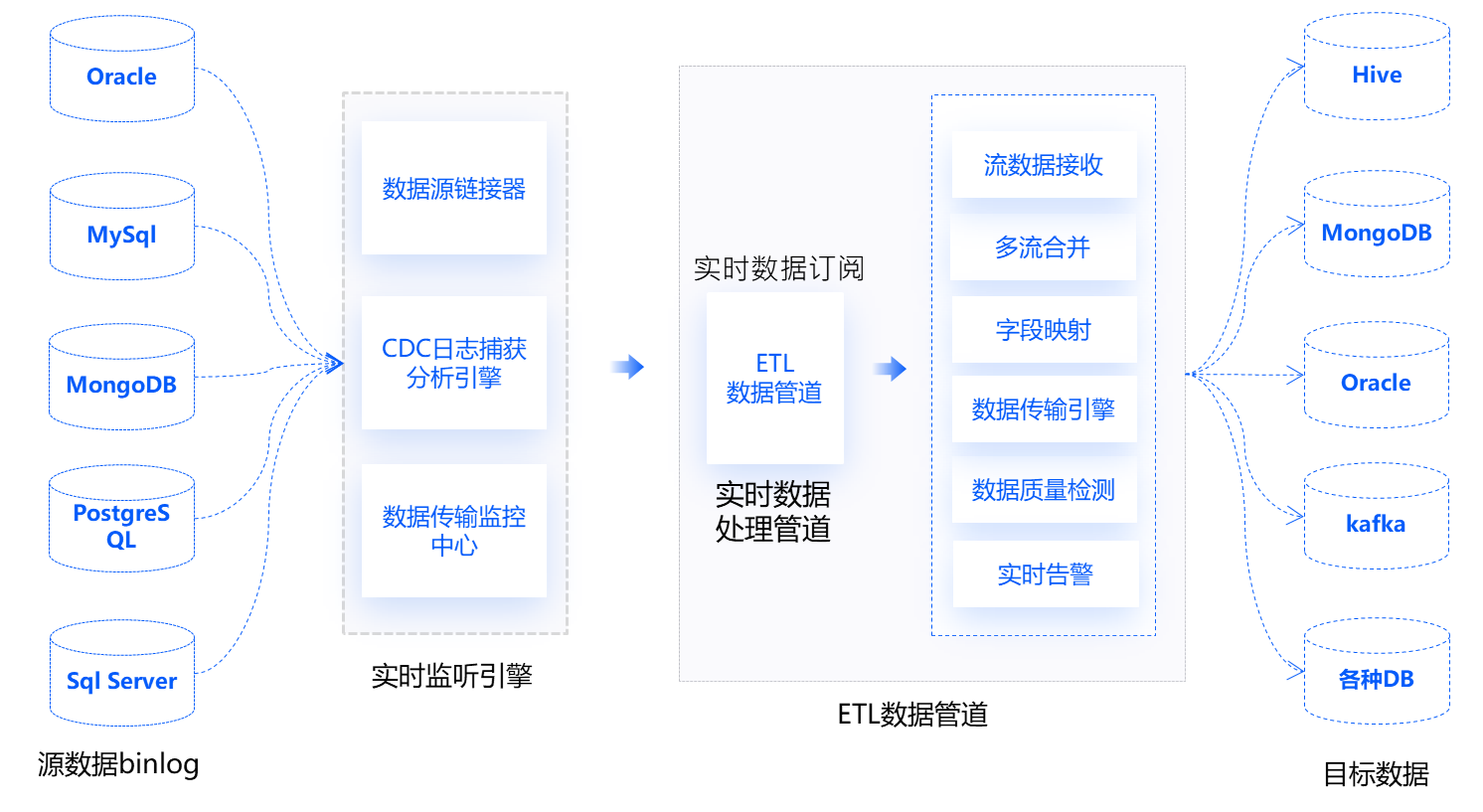
免费的国产数据集成平台推荐
在如今的数字化时代下,企业内部的数据无疑是重要资产之一。随着数据源的多样性和数量剧增,如何有效地收集、整合、存储、管理和分析数据变得至关重要。为了解决这些常见痛点,数据集成平台成为了现代企业不可或缺的一部分。 数据集成是现代数…...

革新性插件本地化突破:Obsidian-i18n让所有插件无缝切换你的语言
革新性插件本地化突破:Obsidian-i18n让所有插件无缝切换你的语言 【免费下载链接】obsidian-i18n 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-i18n 问题发现:当插件界面成为使用障碍 你是否曾遇到这样的场景:好不容易找…...

yz-bijini-cosplay惊艳效果:多光源环境下Cosplay角色面部光影层次还原
yz-bijini-cosplay惊艳效果:多光源环境下Cosplay角色面部光影层次还原 安全声明:本文仅讨论技术实现方案,所有生成内容均为技术演示用途,不涉及任何真人形象或不当内容。 1. 项目概述:专为Cosplay创作打造的AI图像生成…...

老显卡在Debian 12上重获新生:保姆级教程解决NVIDIA 390驱动安装与版本冲突
老显卡在Debian 12上的重生指南:NVIDIA 390驱动完整解决方案 当GeForce 600/700系列显卡遇上最新的Debian 12系统,就像让一位老将披上现代战甲——既充满情怀又颇具挑战。本文将带你穿越驱动安装的迷雾森林,从硬件识别到版本冲突解决…...
)
图解numpy轴运算:用动画演示argmin/argmax在不同维度下的工作原理(附可运行代码)
用空间思维理解NumPy轴运算:argmin/argmax的维度穿越指南 当你第一次在NumPy中遇到axis参数时,是否感觉像在解一道空间几何题?本文将通过视觉化的思维模型,带你穿透维度的迷雾,掌握argmin和argmax在不同维度数组中的行…...

Polar编码在UCI传输中的关键技术与实现细节
1. Polar编码在UCI传输中的核心作用 当我们需要在5G网络的PUSCH信道上传输UCI(上行控制信息)时,如果信息量超过12比特,Polar编码就成为了标准化的编码方案。这种编码方式之所以被选中,是因为它在短码和中长码场景下都能…...

apache-dolphinscheduler-3.4.1调度器配置虚拟机
1、下载文件3.4.1下载安装包https://mirrors.tuna.tsinghua.edu.cn/apache/dolphinscheduler/3.4.1/ 2、传到虚拟机/home/spark2下 3、解压并重命名 4、初始化 MySQL 数据库 (1)启动 MySQL 服务 (2)登录 MySQL(输入 r…...
——一个高效处理数据的时序数据库)
InfluxDB(一)——一个高效处理数据的时序数据库
目录 一、什么是时序数据库InfluxDB? 关系型数据库(行式存储)是怎么存的? 时序数据库(列式存储)是怎么存的? 二、InfluxDB的特点 1. 极致的写入性能 2. 高效的存储压缩 3. 独特的数据模型…...

LN2266 超小型 低电压启动 PWM 控制 升压 DC/DC 电压调整器
■ 产品概述 LN2266 是一款微型、高效率、升压 DC/DC 调整器。电路由电流模 PWM 控制环路,误差放大器,斜波产生电路,比较器和一个功率开关等模块组成。该芯片可在较宽负载范围内高效稳定的工作。低于 1V 的启动电压,可以使用 1-4节…...

ToClaw全方位介绍:你的第一只“龙虾”AI助手,一分钟轻松领养!
ToClaw全方位介绍:你的第一只“龙虾”AI助手,一分钟轻松领养! 一、先来聊聊这只“龙虾”的故事 2026年开年,如果问中文互联网最火爆的技术热词是什么,那一定非「OpenClaw」莫属。这个被大家亲切称为“龙虾”的开源项目…...

别再纠结了!用Python的Pymoo库5分钟搞定多目标优化,找到你的Pareto最优解
用Python的Pymoo库5分钟实现多目标优化:从理论到实战的完整指南 当你在设计一款新产品时,既要控制成本又要保证性能;当你在调整机器学习模型时,既要提高准确率又要降低计算资源消耗——这些看似矛盾的需求,正是多目标优…...