大规模爬虫系统面临的主要挑战及解决思路
在构建大规模爬虫系统时,我们常常面临一系列挑战。这些挑战包括高效爬取、频率限制、分布式处理、存储和数据管理等方面。为了应对这些挑战,我们需要采取一些解决思路和策略。在本文中,我将与大家分享大规模爬虫系统面临的主要挑战以及解决思路,希望对你构建高效稳定的爬虫系统有所帮助。
- 高效爬取
高效爬取是大规模爬虫系统的关键。主要的挑战在于如何尽可能地从目标网站上获取信息,同时保持高速和高质量。以下是一些解决思路和策略:
- 使用异步请求:采用异步请求可以提高爬取效率,避免请求的阻塞等待时间。
- 多线程/多进程处理:通过利用多线程或多进程,可以同时进行多个请求和数据处理操作,提升爬取速度。
- 分布式爬取:将爬虫系统拆分成多个分布式节点,同时工作,从而加快爬取速度。
以下是一个简单的使用多线程爬取的示例代码:
import requests
from threading import Thread, Lockdef crawl(url):response = requests.get(url)# 进行相应的数据处理
def main():urls = [...]threads = []for url in urls:t = Thread(target=crawl, args=(url,))t.start()threads.append(t)for t in threads:t.join()
if __name__ == "__main__":main()
- 频率限制
目标网站通常会实施防爬措施,如频率限制机制,用于阻止爬虫过于频繁的请求。为了应对频率限制挑战,可以采取以下策略:
- 合理设置请求间隔时间:模拟人类行为,设置合理的请求间隔时间,避免被检测到为机器。
- 修改请求头部信息:使用不同的User-Agent、Referer等信息,使请求看起来更像普通用户的行为。
以下是一个简单设置请求间隔时间的示例代码:
import requests
import time
def crawl(url):response = requests.get(url)# 进行相应的数据处理
def main():urls = [...]interval = 1 # 设置请求间隔时间为1秒for url in urls:crawl(url)time.sleep(interval)
if __name__ == "__main__":main()
- 分布式处理和存储
大规模爬虫系统需要处理和存储大量的数据,这也是一个重要的挑战。以下是一些解决思路和策略:
- 利用分布式消息队列:将爬取任务分发到多个爬虫节点,并利用消息队列来协调任务的顺序和分配。
- 使用分布式文件系统:将爬取的数据存储到分布式文件系统中,如Hadoop HDFS或云存储服务,以确保数据的可扩展性和安全性。
以下是一个简单利用分布式消息队列处理爬虫任务的示例代码:
import requests
import time
from queue import Queue
from threading import Thread
def crawl(url):response = requests.get(url)# 进行相应的数据处理
def worker(queue):while True:url = queue.get()crawl(url)queue.task_done()
def main():urls = [...]num_workers = 10 # 设置工作线程数量queue = Queue()for url in urls:queue.put(url)for _ in range(num_workers):t = Thread(target=worker, args=(queue,))t.start()queue.join()
if __name__ == "__main__":main()
大规模爬虫系统面临着高效爬取、频率限制、分布式处理和存储等主要挑战。为应对这些挑战,我们可以采取一些解决思路和策略,如使用异步请求、多线程/多进程处理、分布式爬取、合理设置请求间隔时间、修改请求头部信息等。此外,利用分布式消息队列和分布式文件系统可以优化分布式处理和存储。这些解决思路和策略可以帮助我们构建高效稳定的大规模爬虫系统。
相关文章:

大规模爬虫系统面临的主要挑战及解决思路
在构建大规模爬虫系统时,我们常常面临一系列挑战。这些挑战包括高效爬取、频率限制、分布式处理、存储和数据管理等方面。为了应对这些挑战,我们需要采取一些解决思路和策略。在本文中,我将与大家分享大规模爬虫系统面临的主要挑战以及解决思…...
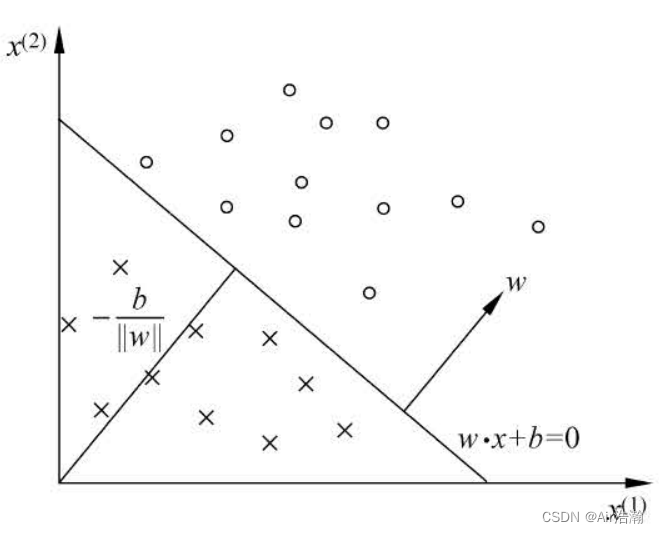
统计学习方法 感知机
文章目录 统计学习方法 感知机模型定义学习策略学习算法原始算法对偶算法 学习算法的收敛性 统计学习方法 感知机 读李航的《统计机器学习》时,关于感知机的笔记。 感知机(perceptron)是一种二元分类的线性分类模型,属于判别模型…...
之wc)
Linux命令(103)之wc
linux命令之wc 1.wc介绍 linux命令wc是用来统计文件的字数、行数和字节数 2.wc用法 wc [参数] [filename] wc参数 参数说明-l统计总行数,备注:常用于查看进程是否启动-L统计最长一行的字符数-c统计字节数-m统计字符数-w统计单词数 3.实例 3.1.统计…...

京东店铺公司名爬虫
内容仅供学习参考,如有侵权联系删除 先通过京东非自营的店铺名拿到的公司名,再通过公司名称去其他平台拿到联系方式(代码省略) from aioscrapy.spiders import Spider from aioscrapy.http import Request, FormRequest import dd…...

如何解决不同浏览器的样式兼容性问题?
目录 1. 理解浏览器差异: 2. 使用标准CSS属性和值: 3. CSS Reset 或 Normalize: 4. 使用浏览器引擎前缀: 5. 使用CSS兼容性工具: 6. 测试和调试: 7. 使用Polyfill: 8. 条件注释…...

C++ 中迭代器的使用
在C中,"iter"通常是一个缩写,代表迭代器(iterator),用于遍历容器类(如数组、列表、向量等)中的元素。迭代器允许你按顺序访问容器中的元素,而无需了解底层容器的实现细节。…...
如何使用BERT生成单词嵌入?
阿比贾特萨拉里 一、说明 BERT,或来自变形金刚(Transformer)的双向编码器表示,是由谷歌开发的强大语言模型。它已广泛用于自然语言处理任务,例如情感分析、文本分类和命名实体识别。BERT的主要特征之一是它能够生成单词…...
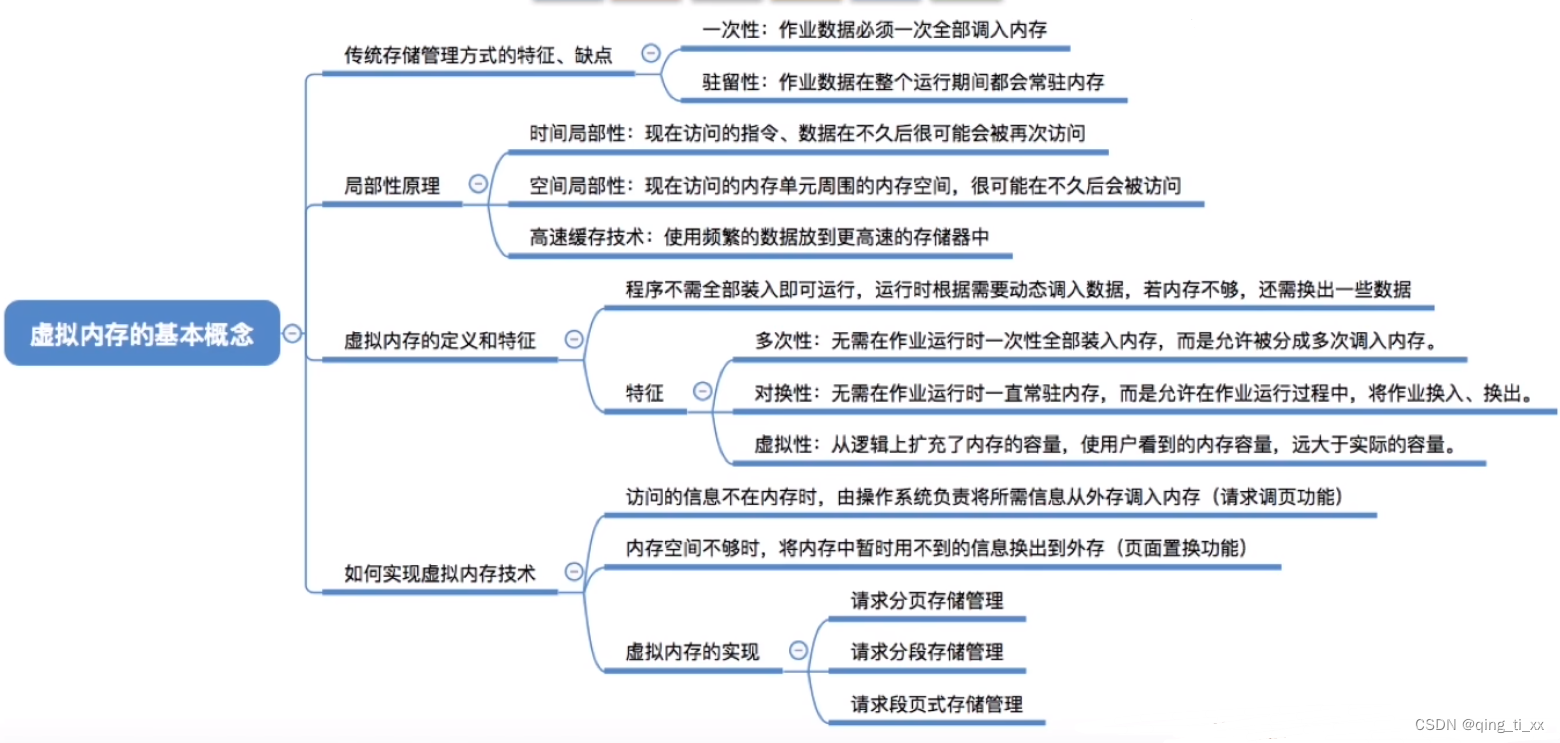
第三章 内存管理 十一、虚拟内存的基本概念
目录 一、传统存储管理 1、缺点 二、局部性原理 1、时间局部性: 2、空间局部性: 三、虚拟内存的定义和特征 1、结构 编辑 2、定义 3、特征 (1)多次性: (2)对换性: (3)…...

web前端面试-- http的各个版本的区别(HTTP/0.9、HTTP/1.0、HTTP/1.1、HTTP/2.0、HTTP/3.0)
本人是一个web前端开发工程师,主要是vue框架,整理了一些面试题,今后也会一直更新,有好题目的同学欢迎评论区分享 ;-) web面试题专栏:点击此处 http的各个版本的区别 HTTP(超文本传输协议&…...
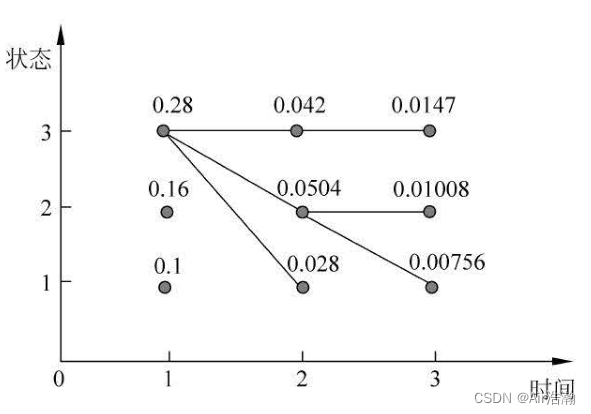
统计学习方法 隐马尔可夫模型
文章目录 统计学习方法 隐马尔可夫模型基本概念概率计算问题直接计算法前向算法后向算法前向概率和后向概率 学习问题监督学习算法Baum-Welch 算法E 步M 步参数估计公式算法描述 解码问题近似算法Viterbi 算法 统计学习方法 隐马尔可夫模型 读李航的《统计学习方法》时&#x…...

Cypress 与 Selenium WebDriver
功能测试自动化工具的王座出现了新的争夺:Cypress.io。赛普拉斯速度快吗?是的。赛普拉斯是交互式的吗?是的。赛普拉斯可靠吗?你打赌。最重要的是……这很酷! 但 Cypress 是Selenium WebDriver的替代品吗?S…...

Leetcode 第 365 场周赛题解
Leetcode 第 365 场周赛题解 Leetcode 第 365 场周赛题解题目1:2873. 有序三元组中的最大值 I思路代码复杂度分析 题目2:2874. 有序三元组中的最大值 II思路代码复杂度分析思路2 题目3:2875. 无限数组的最短子数组思路代码复杂度分析 题目4&a…...

什么是软件测试? 软件测试都有什么岗位 ?软件测试和调试的区别? 软件测试和开发的区别?软件测试等相关概念入门篇
1、什么是软件测试? 常见理解: 软件测试就是找BUG,发现缺陷 真正理解: 软件测试就是验证软件产品特性是否满足用户的需求 测试定义: 测试人员验证软件是否符合需求的这个过程就是测试 2、为什么要有测试 标准情况下&a…...

VI/VIM的使用
1、vi的基本概念 基本上vi可以分为三种状态,分别是命令模式(command mode)、插入模式(Insert mode)和底行模式(last line mode),各模式的功能区分如下: 1) 命令行模…...

【虹科干货】Redis Enterprise vs ElastiCache——如何选择缓存解决方案?
使用Redis 或 Amazon ElastiCache 来作为缓存加速已经是业界主流的解决方案,二者各有什么优势?又有哪些区别呢? 文况速览: - Redis 是什么? - Redis Enterprise 是什么? - Amazon ElastiCache 是什么&…...
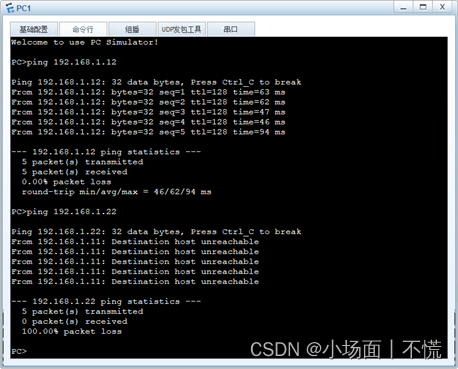
2.2.2 交换机间相同vlan的通信
实验2.2.2 交换机间相同vlan的通信 一、任务描述二、任务分析三、实验拓扑四、具体要求五、任务实施1.设置交换机的名称,创建VLAN,配置access并分配接口。对两台交换机进行相同的VLAN划分,下面是SWA配置过程,同理可实现SWB的配置。…...

C的魅力在于指针
原有的adrv9025 代理框架很好用,在其原有的平台上做改进...

【Linux常用命令14】Linux系统监控常用命令
proc文件系统 /proc/cmdline 加载kernel时的相关指令与参数 /proc/cpuinfo CPU相关信息,包含频率、类型与运算功能 /proc/devices 记录了系统各个主要设备的主设备号码 /proc/filesystems 记录系统加载的文件系统 /proc/loadavg 平均负载值 top看到就是这个 /proc/…...

Python Watchdog:高效的文件系统监控
1. 写在前面 在软件开发中,有时候需要通过 Python 去监听指定区域文件或目录的创建、修改,或者删除,从而引发特定的事件处理。本篇博客为你介绍第三方模块 Watchdog 实现对文件事件的监控。 公众号: 滑翔的纸飞机 2. Watchdog 2…...

C++中多态的原理【精华】
虚函数表 通过一道题我们先感受一下编译器针对多态的处理 #include <iostream> using namespace std;class Base { public:virtual void Func1(){cout << "Func1()" << endl;} private:int _b 1;char _c };int main() {cout << sizeof(B…...

家庭实验室应用:OpenClaw+gemma-3-12b-it管理个人科研数据
家庭实验室应用:OpenClawgemma-3-12b-it管理个人科研数据 1. 为什么需要AI助手管理科研数据 去年冬天,我在整理三年积累的植物生长实验数据时,发现了一个尴尬的事实:有37个Excel文件分散在6个不同文件夹里,命名规则混…...

黑丝空姐-造相Z-Turbo场景应用:为你的内容创作提供无限灵感
黑丝空姐-造相Z-Turbo场景应用:为你的内容创作提供无限灵感 1. 镜像概述与核心能力 黑丝空姐-造相Z-Turbo是一款基于Xinference部署的文生图模型服务,通过gradio提供直观的交互界面。该镜像专注于生成特定风格的视觉内容,为创意工作者提供高…...

快速验证openclaw抓取能力:用快马一键生成部署原型
最近在做一个内容抓取的小项目,尝试用openclaw框架快速搭建原型。这个开源机器人框架功能强大,但配置起来确实有点麻烦,特别是环境依赖和部署环节。经过一番折腾,我发现用InsCode(快马)平台可以省去很多重复劳动,分享下…...

亚马逊Buy for Me代购服务全流程实测:从下单到收货的完整避坑手册
亚马逊Buy for Me代购服务实战解析:从入门到精通的完整指南 跨境购物早已不是新鲜事,但每次看到海外电商平台上那些国内买不到的好物,心里总免不了痒痒的。亚马逊最新推出的Buy for Me服务,或许正是解决这一痛点的钥匙。作为一名长…...

Graphormer开源模型多场景落地:高校科研、药企CADD、新材料研发实操路径
Graphormer开源模型多场景落地:高校科研、药企CADD、新材料研发实操路径 1. 项目概述 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM4M…...
通义千问Qwen2-VL模型部署避坑指南:如何用transformers库绕过Flash-Attention2安装
通义千问Qwen2-VL模型轻量化部署实战:避开Flash-Attention2的安装陷阱 最近在测试通义千问的多模态模型Qwen2-VL时,发现官方推荐的Flash-Attention2依赖项安装过程异常繁琐,不仅编译耗时数小时,还经常因环境配置问题报错。经过多次…...

停止学习新语言!2026年技术人的反内耗宣言
一、技术内耗的困局:语言焦虑与效率陷阱2026年的技术圈,Python稳居TIOBE榜首,Rust强势崛起,TypeScript重构前端生态……语言迭代的速度远超人类学习极限。测试从业者深陷三重内耗漩涡:工具链绑架:70%自动化…...

OpenClaw语音交互:Phi-3-mini接入麦克风输入实战
OpenClaw语音交互:Phi-3-mini接入麦克风输入实战 1. 为什么需要语音交互能力 上周我在整理电脑文件时突然想到一个问题:当我的双手被占用时(比如正在做饭或修理设备),如何让OpenClaw帮我执行任务?传统的键…...

cv_resnet101_face-detection_cvpr22papermogface真实应用:社区门禁抓拍图自动人数统计
cv_resnet101_face-detection_cvpr22papermogface真实应用:社区门禁抓拍图自动人数统计 1. 项目简介 今天给大家介绍一个特别实用的工具——基于MogFace模型的高精度人脸检测系统。这个工具最大的特点就是能在本地电脑上快速准确地识别人脸,自动统计人…...

SEO网站广告如何与本地化营销相结合
SEO网站广告与本地化营销的结合:如何提升本地企业的市场竞争力 在当今数字化经济的浪潮中,SEO网站广告和本地化营销已经成为企业营销的两大重要手段。如何将这两者有机地结合,以实现最大的营销效益,是许多企业面临的重要课题。本…...