手写一个PrattParser基本运算解析器3: 基于Swift的PrattParser的项目概述

点击查看 基于Swift的PrattParser项目
PrattParser项目概述
前段时间一直想着手恶补 编译原理 的相关知识, 一开始打算直接读大学的 编译原理, 虽然内容丰富, 但是着实抽象难懂. 无意间看到B站的熊爷关于普拉特解析器相关内容, 感觉是一个非常好的切入点.所以就写了基于Swift版本的 PrattParser.
下面是我整理的项目中各个类以及其中函数的作用.

更加具体的请查看 PrattParser解释器项目类与函数
接下来, 我把整个项目UML图发出来, 大家可以借鉴查看.
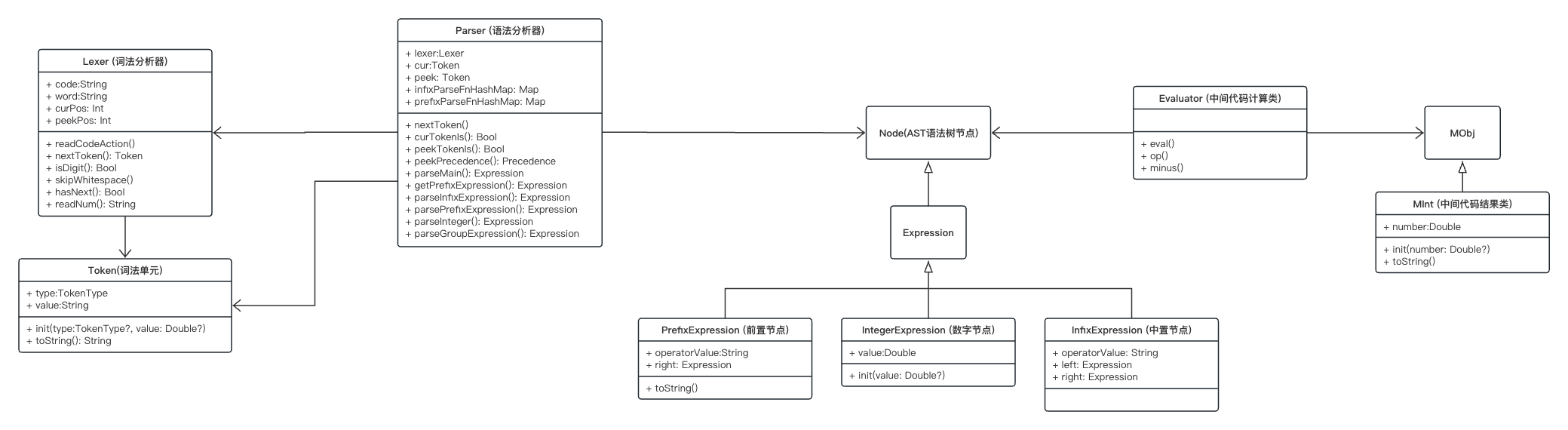
更加具体的请查看 PrattParser的Swift项目UML图
接下来, 我就以 词法分析 、语法分析 、 中间代码生成 三部分逐步来说明一下这个 基于Swift的PrattParser项目
词法分析
词法分析的核心类是 Lexer, 输入的原始代码字符串 code, 输出的是一组词法单元 Token.

在词法分析器 Lexer 中, 核心函数就是 nextToken, nextToken函数职责一共有两个职责.
-
去除代码格式化的逻辑, 例如, 去除
空格换行等等. 这一步主要是通过调用skipWhitespace()函数实现的.public func skipWhitespace() {while (hasNext()) {if (word == " " || word == "\t" || word == "\n" || word == "\r") {readCodeAction();} else {break}} } -
读取数学符号与数字并且生成
词法单元Tokenswitch(word) { case "+" :token = PrattParser.Token(TokenType.PLUS, "+")break case "-" :token = PrattParser.Token(TokenType.MINUS, "-")break case "*" :token = PrattParser.Token(TokenType.ASTERISK, "*")break case "/" :token = PrattParser.Token(TokenType.SLASH, "/")break case "(" :token = PrattParser.Token(TokenType.LPAREN, "(")break case ")" :token = PrattParser.Token(TokenType.RPAREN, ")")break case "^" :token = PrattParser.Token(TokenType.HAT, "^")break case nil :token = PrattParser.Token(TokenType.EOF, "")break default:if (isDigit(word)) {let num: String = readNum();token = PrattParser.Token(TokenType.NUM, num);return token;} else {throw LexerError.lexerError(message: "Lexer error")} }
生成词法单元函数 nextToken 的整体逻辑流程图如下所示. 基本涉及了词法分析器 Lexer 的所有函数.

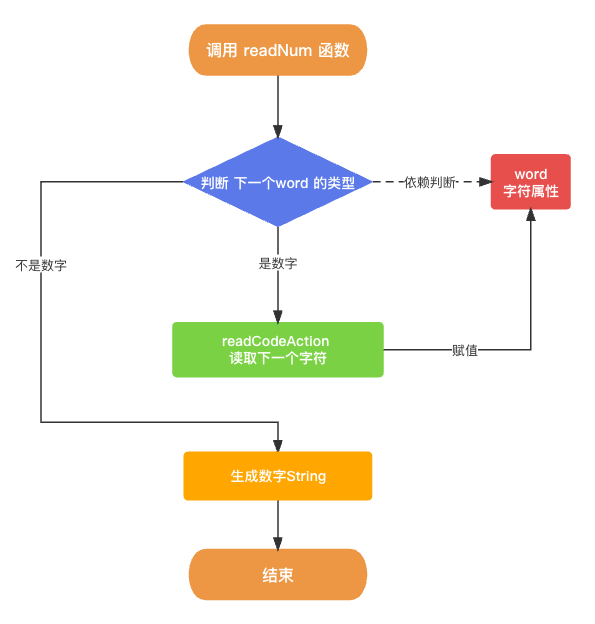
这里要补充的一点的就是由于数学符号大部分是单个字符, 例如 + - * / ( ), 这个读取直接生成即可. 但是数字可能是有多位的, 所以生成的过程需要通过循环一直查找. 在该项目中的代码实现中读取数字字符的逻辑代码主要存在于 readNum 函数中.
public func readNum() -> String {var num: String = ""while (isDigit(word)) {num += word ?? ""readCodeAction()}return num;
}
生成数字函数 readNum 的整体逻辑流程图如下所示.
在该项目中, 词法分析器Lexer 的外部驱动力是 语法分析器Parser, 也就是说语法分析器Parser一直在调用 Lexer 的 nextToken 函数从而不断地生成词法单元 Token.

语法分析
在 词法分析 模块, 我们了解到了 词法分析器Lexer 会为 语法分析器Parser 提供源源不断生成的词法单元 Token.
语法分析器Parser 则会这些词法单元 Token根据 符号的优先级 生成一颗 AST语法树.
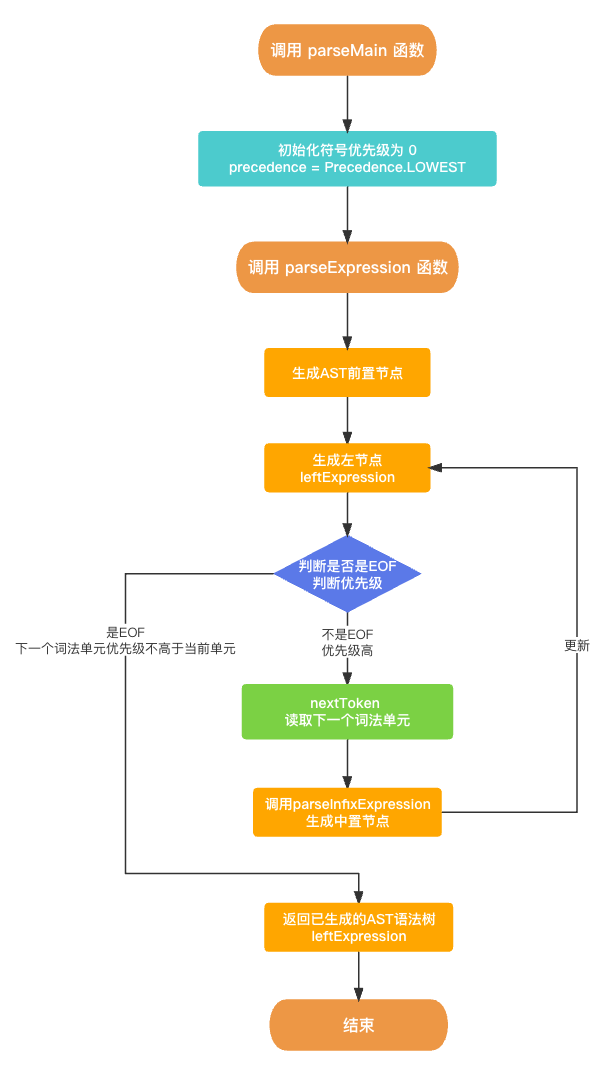
在 语法分析器Parser 生成 AST语法树 的过程中, 其入口函数是 parseMain(), 核心函数是 parseExpression(), 具体代码如下所示.
func parseExpression(_ precedence: Precedence) -> Expression? {let funcName: String? = prefixParseFnHashMap[cur?.type ?? TokenType.None];if (funcName == nil) {print("未找到AST节点构建函数名称")return nil}// 生成前置节点, 获取左节点var leftExpression: Expression? = getPrefixExpression(funcName);// 能递归的原因 判断下一个词法单元是否是EOF, 判断下一个词法单元的优先级是否大于当前的优先级while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}//读取下一个词法单元nextToken();// 生成中置节点, 更新AST语法树leftExpression = parseInfixExpression(leftExpression);}return leftExpression
}
由于递归过程比较复杂, 我整理了一下整体的逻辑流程图.
当我们看到上一个图的时候, 我们会诧异, 说好的递归过程在哪呢? 其实递归过程主要隐藏在生成中置节点函数 parseInfixExpression() 中, 由于 parseExpression() → parseInfixExpression() → parseExpression() → .... 的调用关系会最终产生递归效果.

在中置节点生成函数parseInfixExpression中, 右节点的生成依然会依赖 parseExpression(), 这也就递归产生的驱动力.
// 中置节点生成函数
func parseInfixExpression(_ left: Expression?) -> Expression? {let infixExpression = InfixExpression();infixExpression.left = left;infixExpression.operatorValue = cur?.value;let precedence: Precedence = Precedence.getPrecedence(cur?.type);nextToken();// 右节点的生成是递归产生的驱动力infixExpression.right = parseExpression(precedence);return infixExpression
}
中置节点生成函数parseInfixExpression的逻辑流程图如下所示.

粗略的说了大致的流程, 接下来, 我们就详情的说一下具体的执行流程.
具体的以 1 + 4 - 3 和 1 + 2 * 3 两个数学运算为示例.
1 + 4 - 3 的AST语法树构建过程
强烈建议大家一边项目断点, 一边对照该模块的流程!!!
-
整体还是以
parseMain()为入口, 初始过程中会传入一个最低的优先级(Precedence.LOWEST)用于驱动整个AST语法树的构建. 当然了, 这时候词法单元读取模块也已经准备就绪了.// 构建AST树主入口 public func parseMain() -> Expression? {return parseExpression(Precedence.LOWEST); }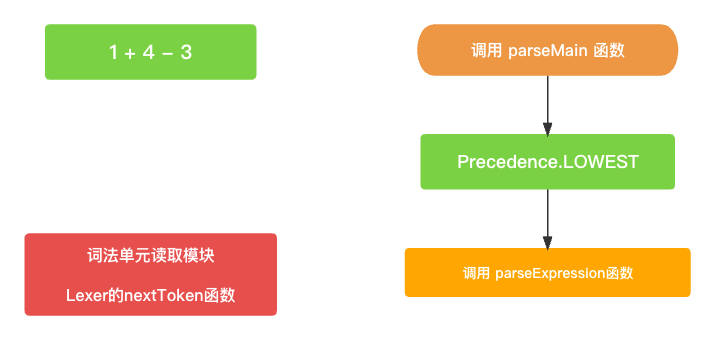
-
通过
parseMain函数进入的parseExpression()函数中, 首先找的就是前置节点, 通过词法单元读取模块获取到第一个词法单元1. 并且生成根据前置节点的类型生成数字类型的AST前置节点.getPrefixExpression就不过多叙述了, 比较简单.let funcName: String? = prefixParseFnHashMap[cur?.type ?? TokenType.None]; if (funcName == nil) {print("未找到AST节点构建函数名称")return nil } // 获取左节点 var leftExpression: Expression? = getPrefixExpression(funcName);func getPrefixExpression(_ funcName: String?) -> Expression? {switch(funcName) {case "parseInteger" :return parseInteger()case "parsePrefixExpression":return parsePrefixExpression()case "parseGroupExpression":return parseGroupExpression()default:return nil} }func parseInteger() -> Expression? {let number = Double(cur?.value ?? "0")let integerExpression = IntegerExpression(value: number)return integerExpression }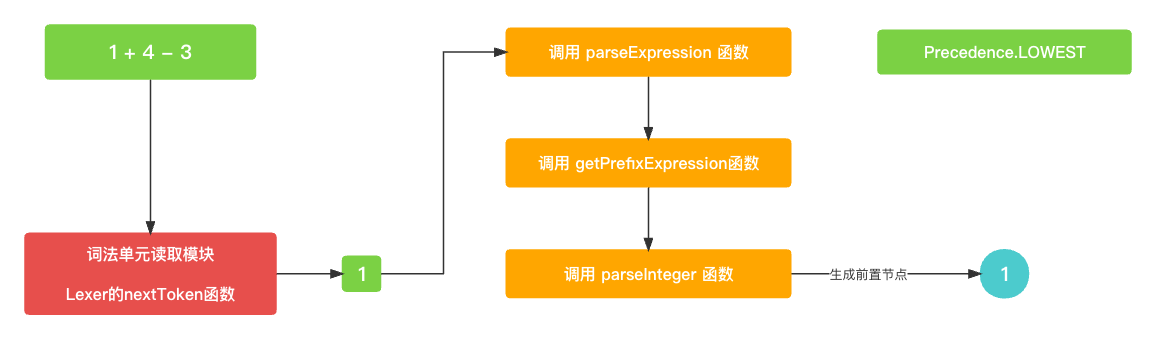
-
紧接着就是去找到中置节点, 这时候通过
peekPrecedence()知道下一个词法单元为+, 优先级较高, 满足优先级条件. 进入递归循环. 然后nextToken()读取下一个词法单元+, 然后通过调用parseInfixExpression()尝试生成AST中的中置节点.while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}nextToken();leftExpression = parseInfixExpression(leftExpression); }
-
在中置节点生成函数
parseInfixExpression()中, 由于当前的词法单元为+, 左节点为前置节点1, 我们可以直接构建出这一部分的AST语法树.let infixExpression = InfixExpression(); infixExpression.left = left; infixExpression.operatorValue = cur?.value;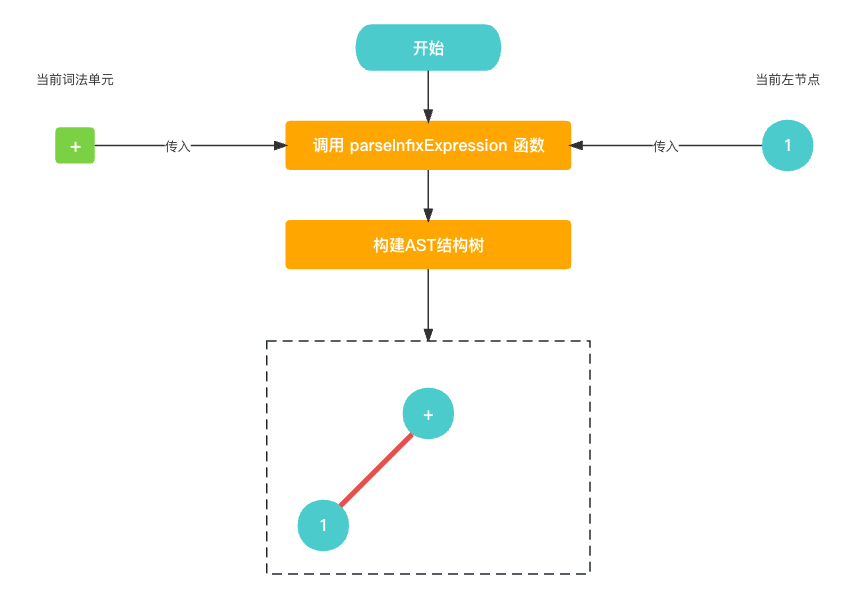
-
构建了中置节点的值和左节点, 我们尝试用
parseExpression()递归的形式找到+的中置节点的右节点, 我们需要先读取当前+的优先级(Precedence.SUM), 然后读取下一个节点.let precedence: Precedence = Precedence.getPrecedence(cur?.type); nextToken(); infixExpression.right = parseExpression(precedence);
-
在
parseExpression()寻找+的中置节点的右节点, 首先, 就是获取数字词法单元4生成前置节点, 然后往后读取, 发现是符号词法单元-优先级与 当前符号词法单元+的优先级相同, 所以就不进入while循环, 故+的中置节点的右节点是前置节点4.// 参数优先级为 Precedence.SUM func parseExpression(_ precedence: Precedence) -> Expression? {let funcName: String? = prefixParseFnHashMap[cur?.type ?? TokenType.None];if (funcName == nil) {print("未找到AST节点构建函数名称")return nil}// 获取左节点, 生成 数字前置节点 4var leftExpression: Expression? = getPrefixExpression(funcName);// - 与 + 的优先级相同不进入while循环while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}nextToken();leftExpression = parseInfixExpression(leftExpression);}// 返回 数字前置节点 4return leftExpression }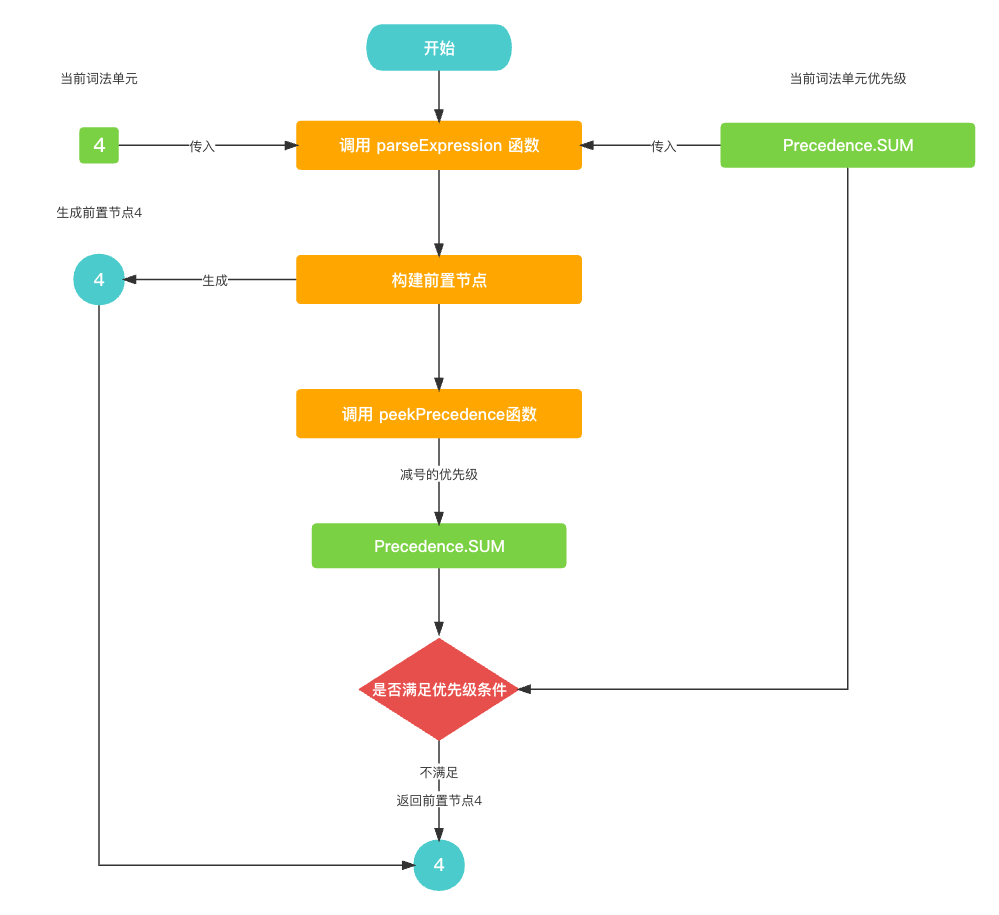
-
这时候, 对于
中置节点+号的AST语法树就构建完成了, 如图所示.
-
然后外部又一次进行while循环, 这次找到的是
➖ 号, 然后把中置节点+号 的AST语法树整体作为➖中置节点的左节点传入.// 这时候再次进入 减号➖ 的循环中 while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}// 读取词法单元减号➖nextToken();// 这里的leftExpression是 加号➕ 的AST语法树// +// ╱ ╲// 1 4leftExpression = parseInfixExpression(leftExpression); }
-
在
➖ 号的中置节点构建过程中,中置节点+号 的AST语法树作为其左节点,-作为其值, 右节点继续通过parseExpression()寻找.let infixExpression = InfixExpression(); // 这里的left是 加号➕ 的AST语法树 // + // ╱ ╲ // 1 4 infixExpression.left = left; infixExpression.operatorValue = cur?.value;
-
和
中置节点+号寻找右节点的逻辑是一样. 我们继续尝试用parseExpression()递归的形式找到-的中置节点的右节点, 我们需要先读取当前-的优先级(Precedence.SUM), 然后读取下一个节点.let precedence: Precedence = Precedence.getPrecedence(cur?.type); nextToken(); infixExpression.right = parseExpression(precedence);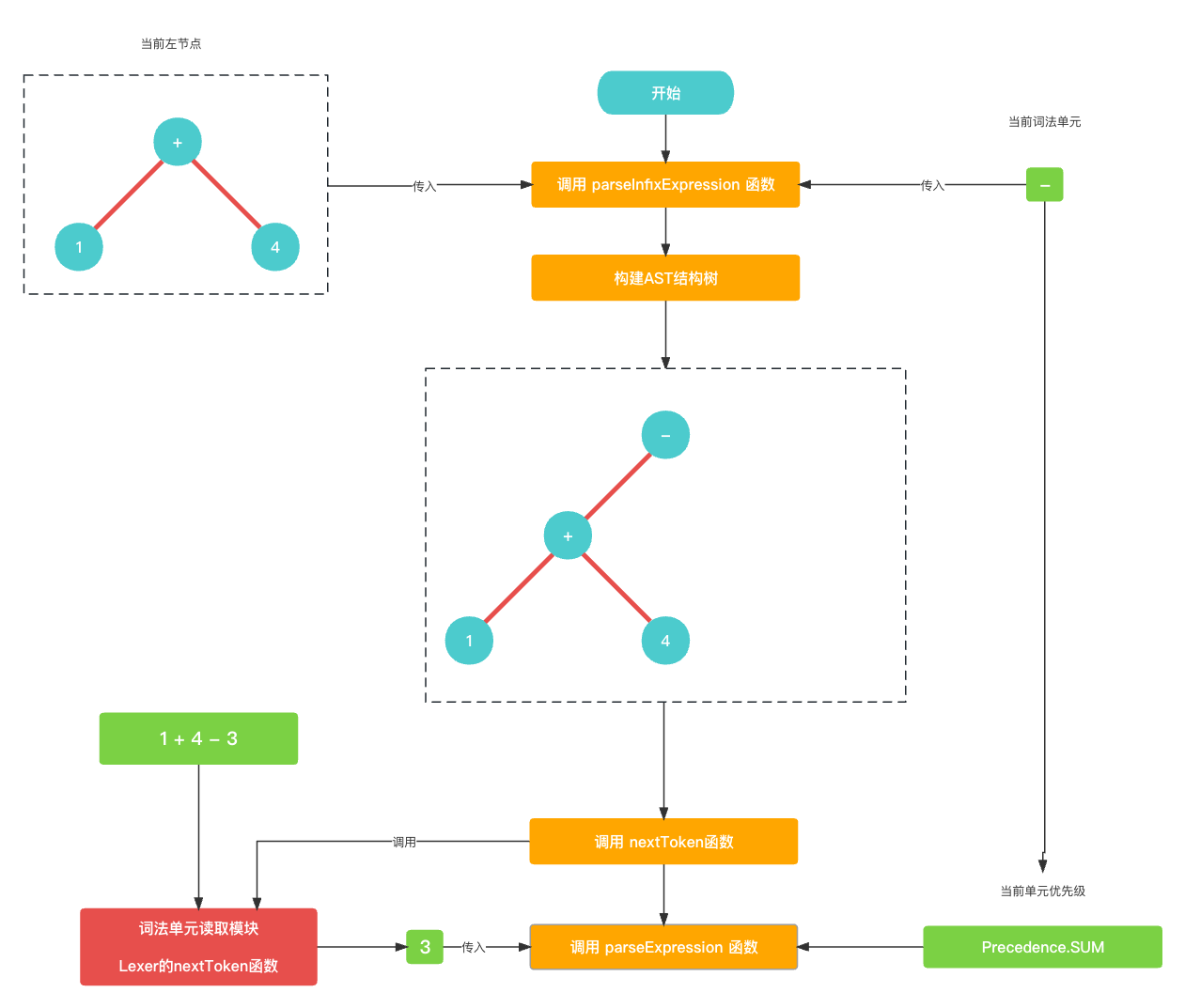
-
这次在
parseExpression()就很简单了, 我们先构建了前置节点3然后往后查找过程发现是结束词法单元EOF, 我们直接返回前置节点3即可.func parseExpression(_ precedence: Precedence) -> Expression? {let funcName: String? = prefixParseFnHashMap[cur?.type ?? TokenType.None];if (funcName == nil) {print("未找到AST节点构建函数名称")return nil}// 构建 前置节点3var leftExpression: Expression? = getPrefixExpression(funcName);// peekToken == EOF 不满足while循环条件while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}nextToken();leftExpression = parseInfixExpression(leftExpression);}// 返回 前置节点3return leftExpression }
-
返回了右节点之后, 我们就直接构建
➖减号的AST语法树, 这里看一下整体的构建过程.
-
➖减号的AST语法树然后再次返回整体的循环, 发现当前的词法节点以及全部循环完成了, 所以就跳出了while循环, 返回最终的AST语法树. 这里就把整理的流程贴图如下所示.
-
所以
1 + 4 - 3形成的AST语法树是这样的. 如下图所示.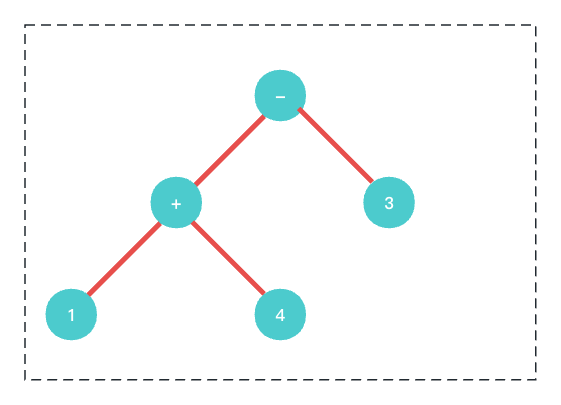
1 + 2 * 3 的AST语法树构建过程
相比于 1 + 4 - 3 的最终结果来说, 1 + 2 * 3 其中 乘法* 一定要比 加法+ 优先级高. 最终应该是这样的 1 + (2 * 3) . 也就是我们预想的AST语法树应该如下所示.

接下来, 我们就一起看一下 1 + 2 * 3 的AST语法树构建逻辑.
-
对于
1 + 2 * 3一直到加法的中置节点寻找右节点之前的逻辑都是与先前一样的. 这里直接贴图了, 就不过多叙述代码了.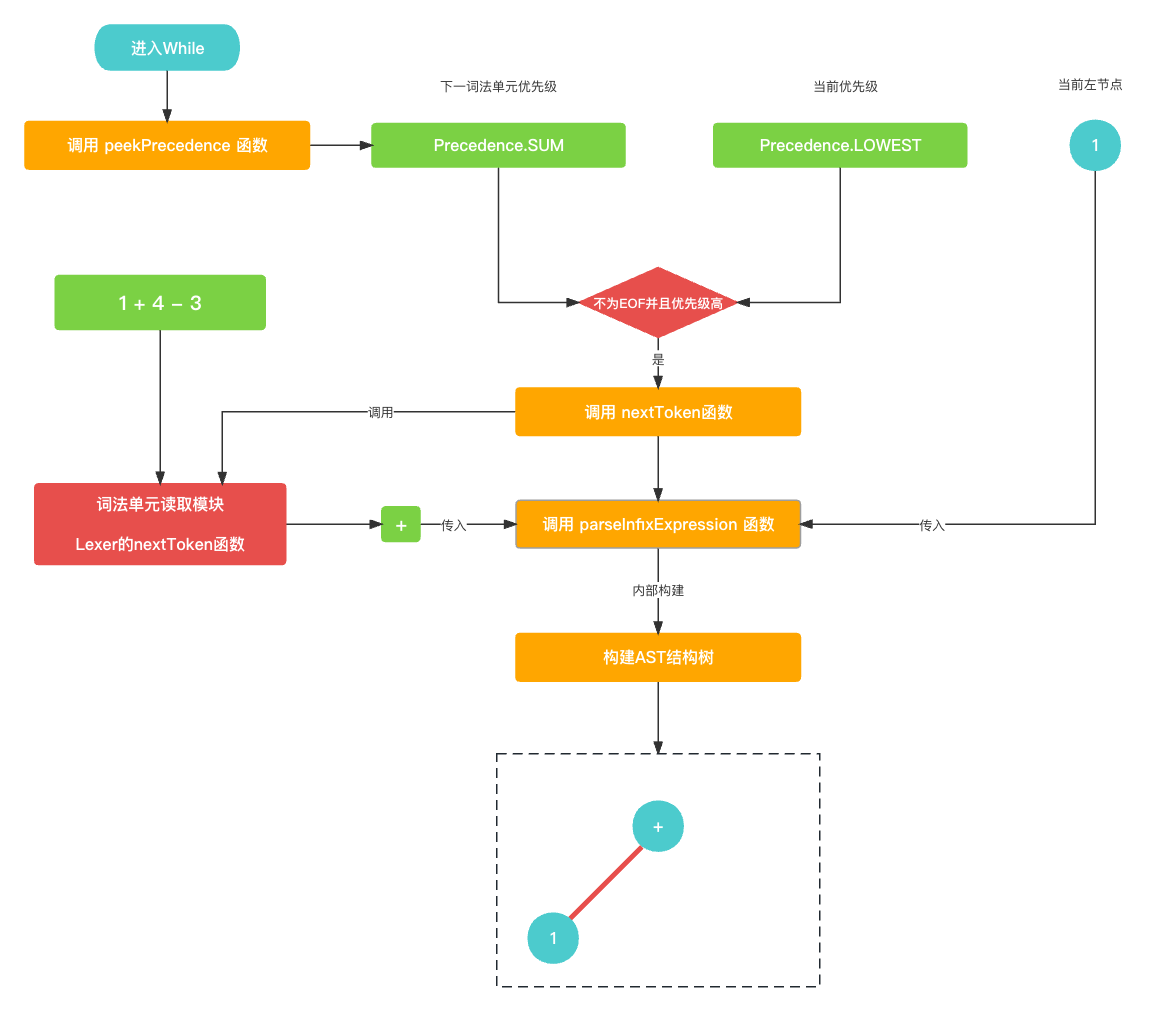
-
接下来, 对于
中置节点加号+需要通过parseExpression()去寻找它自身的右节点. 这时候准备工作也要做好, 读取下一个词法单元2, 获取当前加号的优先级(Precedence.SUM).// 当前加号的优先级为 Precedence.SUM let precedence: Precedence = Precedence.getPrecedence(cur?.type); // 下一个词法单元为 词法单元2 nextToken(); // 寻找 中置节点加号+ 的 右节点 infixExpression.right = parseExpression(precedence);
-
然后, 在
parseExpression()就是先构建前置节点2, 然后查看后一个词法单元, 发现是乘法符号*, 乘法符号的优先级(Precedence.PRODUCT) 要比 加法符号的优先级(Precedence.SUM) 要高, 所以进入while循环中. 继续构建关于中置节点乘法*的相关AST语法树.// 当前优先级是 Precedence.SUM, 当前Token是 2 func parseExpression(_ precedence: Precedence) -> Expression? {let funcName: String? = prefixParseFnHashMap[cur?.type ?? TokenType.None];if (funcName == nil) {print("未找到AST节点构建函数名称")return nil}// 构建左节点 前置节点2var leftExpression: Expression? = getPrefixExpression(funcName);// 乘法符号的优先级比当前加号优先级高, 正常进入while循环while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}// 读取下一个词法单元 乘法符号*nextToken();// 生成乘法符号的中置节点并且更新leftExpressionleftExpression = parseInfixExpression(leftExpression);}return leftExpression }let infixExpression = InfixExpression(); infixExpression.left = left; infixExpression.operatorValue = cur?.value; // 当前的乘法符号 的AST语法树 // * // ╱ ╲ // 2 ?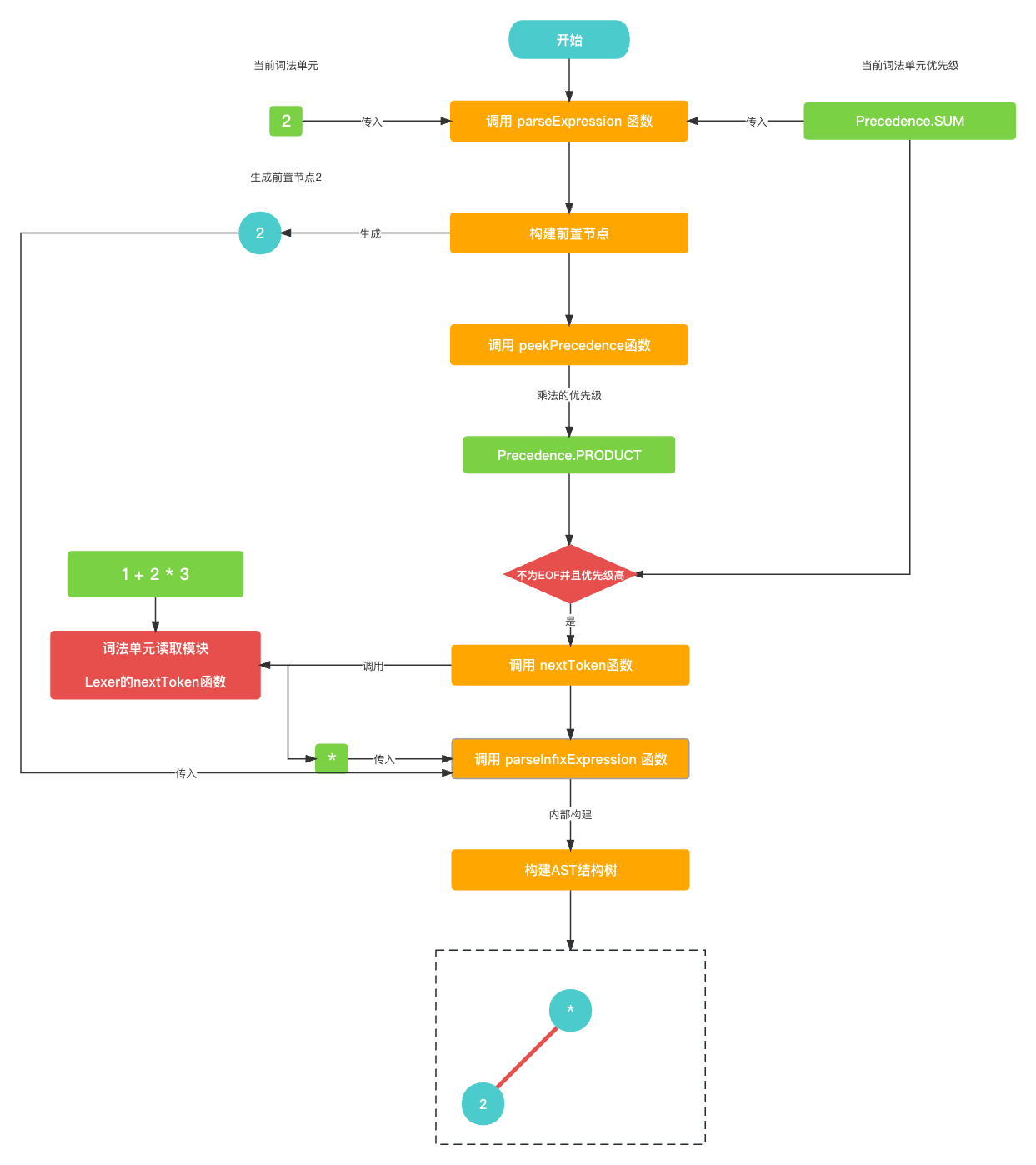
-
紧接着, 就是寻找乘法AST语法树的右节点, 仍然是通过
parseExpression()函数, 传入的Token则是词法单元3, 乘法符号的优先级为Precedence.PRODUCT,// 乘法符号的优先级为 Precedence.PRODUCT let precedence: Precedence = Precedence.getPrecedence(cur?.type); // 读取词法单元3 nextToken(); infixExpression.right = parseExpression(precedence);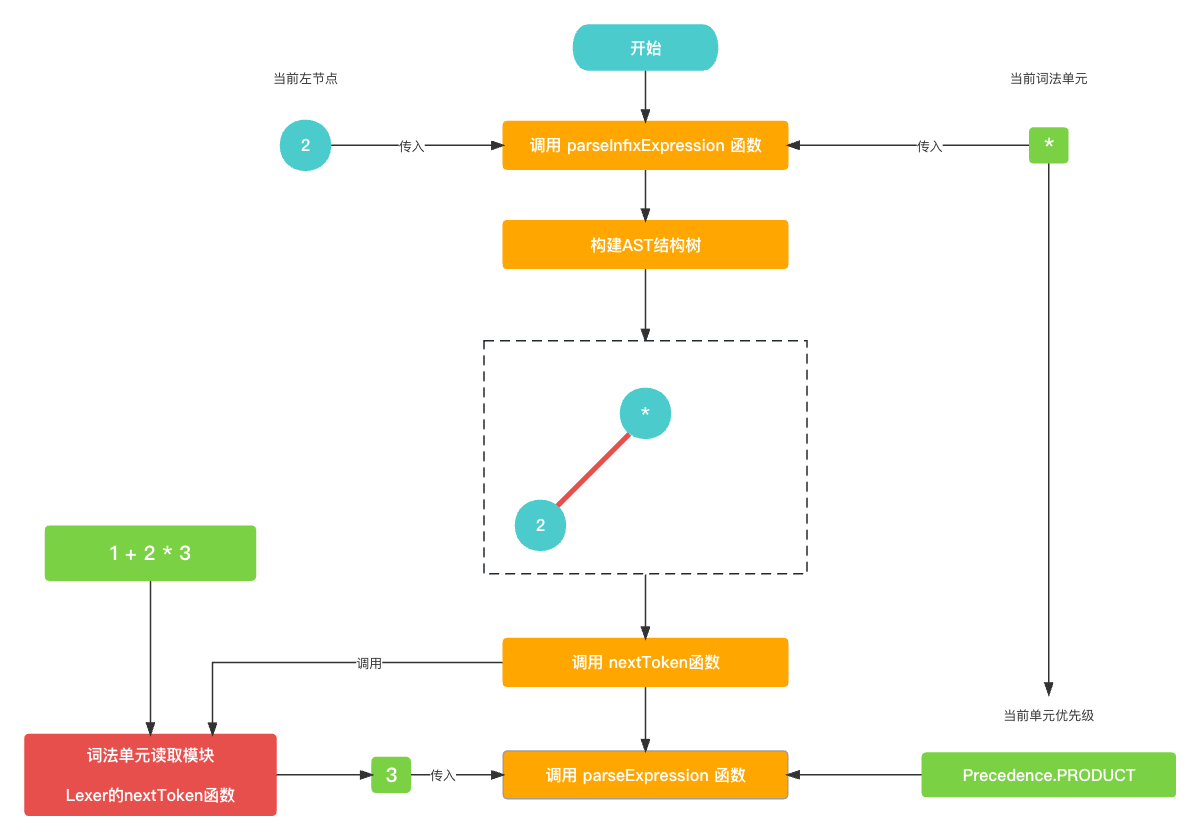
-
在这次乘法符号寻找右节点的
parseExpression()中, 首先构建了前置节点3, 由于看到下一个节点是结束词法单元EOF, 所以不进入循环, 直接返回前置节点3.func parseExpression(_ precedence: Precedence) -> Expression? {let funcName: String? = prefixParseFnHashMap[cur?.type ?? TokenType.None];if (funcName == nil) {print("未找到AST节点构建函数名称")return nil}// 构建 前置节点3var leftExpression: Expression? = getPrefixExpression(funcName);// peekToken == EOF 不满足while循环条件while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}nextToken();leftExpression = parseInfixExpression(leftExpression);}// 返回 前置节点3return leftExpression }
-
这时候也就构建完成了乘法的AST语法树部分了. 我们一起看一下整体的乘法符号的AST语法树构建过程.
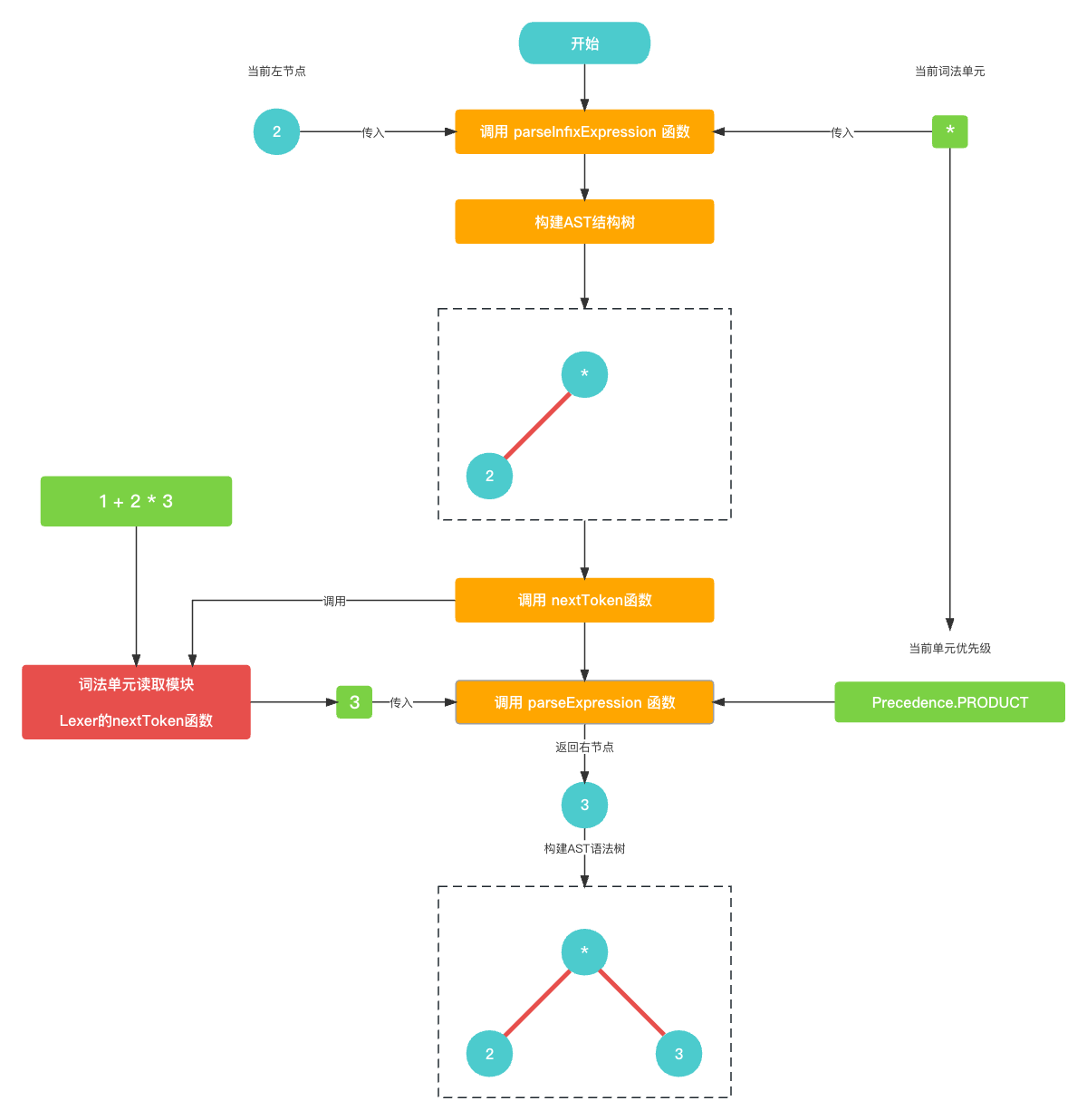
-
由于已经遍历到了最后(遇到了
EOF), 紧接着就跳出了 加法符号寻找右节点的parseExpression()过程中的while循环. 并把 乘法符号的AST语法树作为 加法符号的右节点进行了添加.// 这里是加法符号寻找右节点的递归方法 // 当前优先级是 Precedence.SUM, 当前Token是 2 func parseExpression(_ precedence: Precedence) -> Expression? {let funcName: String? = prefixParseFnHashMap[cur?.type ?? TokenType.None];if (funcName == nil) {print("未找到AST节点构建函数名称")return nil}// 构建左节点 前置节点2var leftExpression: Expression? = getPrefixExpression(funcName);// 乘法符号的优先级比当前加号优先级高, 正常进入while循环while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}// 读取下一个词法单元 乘法符号*nextToken();// 生成乘法符号的中置节点并且更新leftExpressionleftExpression = parseInfixExpression(leftExpression);}// 最终 leftExpression 是乘法符号的AST语法树// *// ╱ ╲// 2 3return leftExpression }上述代码就是下图中 红色的parseExpression()的内部过程.

-
最后返回初始那一层 由
parseMain()进入的parseExpression()过程, 也是已经遍历到了最后(遇到了EOF), 跳出循环, 返回最终的AST语法树.// 这里是由 `parseMain()` 进入的 `parseExpression()` func parseExpression(_ precedence: Precedence) -> Expression? {let funcName: String? = prefixParseFnHashMap[cur?.type ?? TokenType.None];if (funcName == nil) {print("未找到AST节点构建函数名称")return nil}// 构建左节点 前置节点1var leftExpression: Expression? = getPrefixExpression(funcName);// 构建了加法的AST语法树之后, 就退出了循环while (!peekTokenIs(TokenType.EOF) && precedence.rawValue < peekPrecedence()?.rawValue ?? 0) {let infixParseFnName: String? = infixParseFnHashMap[peek?.type ?? TokenType.None];if (infixParseFnName == nil) {print("未找到AST节点构建函数名称")return leftExpression;}nextToken();leftExpression = parseInfixExpression(leftExpression);}// 最终 leftExpression 是加法符号的AST语法树// +// ╱ ╲// 1 *// ╱ ╲// 2 3return leftExpression }
-
这样我们对于数学表达式的
1 + 2 * 3的 AST语法树构建过程就有整体的了解,最终输出的AST语法树如下所示.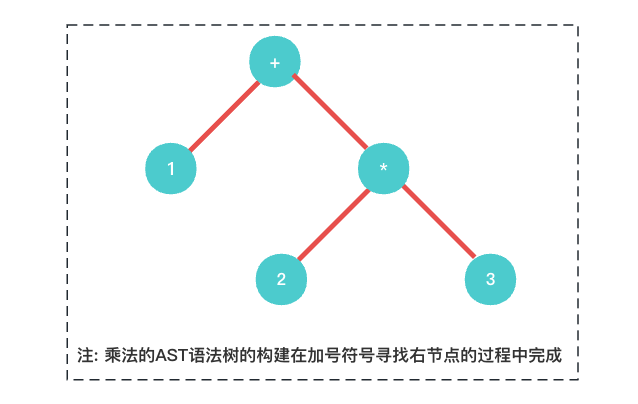
中间代码生成与验证
对于上面的 1 + 4 - 3 和 1 + 2 * 3 的两个示例, 我们对PrattParser构建AST语法树的过程有了大体的了解.
接下来就是中间代码生成过程(其实不太准确, 大体模拟吧~), 我们会直接输入一个结果对象(MInt), 模拟中间代码的生成.
中间代码生成是由 Evaluator 来实现的, 其主要作用就是解析AST语法树, 生成中间代码结果对象(MInt). 这部分也是很简单, 主要是通过 eval() 函数来递归解析AST语法树, 然后通过 op() 函数进行各种数学计算. 整体的计算也是由递归完成的.
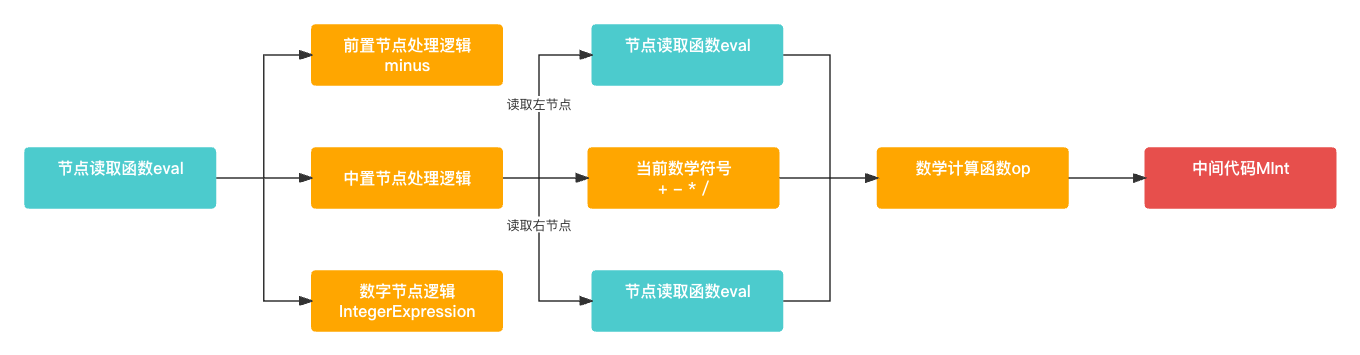
-
eval()函数中 主要有三个逻辑分支, 一个是数字的前置节点一个是符号的前置节点, 最后一个是中置节点.数字的前置节点和中置节点没有什么好说的,符号的前置节点主要应对于第一个前置节点带符号的情况例如-1和+349等等.public static func eval(_ node: Node?) -> MObj? {if let nodeValue = node as? IntegerExpression {// 纯数字节点逻辑return MInt(nodeValue.value)} else if let nodeValue = node as? PrefixExpression {// 带符号的数字节点逻辑if (nodeValue.operatorValue == "-") {return minus(node);} else if (nodeValue.operatorValue == "+") {return eval(nodeValue.right);}} else if let nodeValue = node as? InfixExpression {// 中置节点逻辑let left = eval(nodeValue.left);let right = eval(nodeValue.right);return op(left, right, nodeValue.operatorValue);}return nil; } -
op()就是根据符号进行不同的数学运算, 整体逻辑比较简单, 这里就不过多叙述了.public static func op(_ left: MObj?, _ right: MObj?, _ operatorValue: String?) -> MObj? {if let leftValue = left as? MInt,let rightValue = right as? MInt {switch(operatorValue) {case "+" :return MInt(leftValue.number + rightValue.number)case "-" :return MInt(leftValue.number - rightValue.number)case "*" :return MInt(leftValue.number * rightValue.number)case "/" :return MInt(leftValue.number / rightValue.number)case "^" :return MInt(pow(leftValue.number, rightValue.number))default:return nil;}}return nil; } -
minus()函数主要是用来处理带符号的前置节点情况. 整体逻辑也比较简单, 这里就不过多叙述了.public static func minus(_ node: Node?) -> MObj? {if let nodeValue = node as? PrefixExpression {let m : MObj? = eval(nodeValue.right);if let mValue = m as? MInt {if (nodeValue.operatorValue == "-") {mValue.number = -mValue.number}return mValue;}}return nil; }
最后, 我们就能看到最终的输出结果.
var code = "1+2*3"var lexer: Lexer! = Lexer(code: code)var parser: Parser! = Parser(lexer)var expression: Expression? = parser.parseMain()if let intObj = Evaluator.eval(expression) as? MInt {print(intObj.toString())
}

总结
通过这篇博客详细大家对 PrattParser解析器的前端工作有个大体的了解了. 希望看这篇博客是可以一边断点项目, 一边查看, 主要是递归过程比较绕, 希望有耐心看完.
点击查看 基于Swift的PrattParser项目

相关文章:
手写一个PrattParser基本运算解析器3: 基于Swift的PrattParser的项目概述
点击查看 基于Swift的PrattParser项目 PrattParser项目概述 前段时间一直想着手恶补 编译原理 的相关知识, 一开始打算直接读大学的 编译原理, 虽然内容丰富, 但是着实抽象难懂. 无意间看到B站的熊爷关于普拉特解析器相关内容, 感觉是一个非常好的切入点.所以就写了基于Swift版…...

三江学院“火焰杯”软件测试高校就业选拔赛颁奖仪式
11月25日下午,“火焰杯”软件测试开发选拔赛及三江-慧科卓越工程师班暑期编程能力训练营颁奖仪式在s楼会议室隆重举行。计算机科学与工程学院院长刘亚军、副院长叶传标、曹阳、吴德、院党总支副书记王兰英、系主任杨少雄、慧科企业代表尹沁伊人、项目负责人王旭出席…...

面试题-消息中间件篇-主流的消息中间件
消息中间件篇 第一章 主流的消息中间件对比 1、主流的消息中间件有 Kafka、RabbitMQ、ActiveMQ 等。 Kafka: Kafka 是一种高吞吐量、分布式、可扩展的发布/订阅消息系统,主要用于大数据处理和分析。Kafka 采用消息日志的方式来存储消息,可以…...

PyQt学习笔记-获取Hash值的小工具
目录 一、概述1.1 版本信息:1.2 基本信息:1.2.1 软件支持的内容:1.2.2 支持的编码格式 1.3 软件界面图 二、代码实现2.1 View2.2 Controller2.3 Model 三、测试示例 一、概述 本工具居于hashlibPyQtQFileDialog写的小工具,主要是…...

【(数据结构)— 双向链表的实现】
(数据结构)— 双向链表的实现 一.双向链表的结构二. 双向链表的实现2.1 头文件 ——双向链表的创建及功能函数的定义2.2 源文件 ——双向链表的功能函数的实现2.3 源文件 ——双向链表功能的测试2.4 双向链表各项功能测试运行展示2.4.1 双向链表的初始化…...
酷克数据发布HD-SQL-LLaMA模型,开启数据分析“人人可及”新时代
随着行业数字化进入深水区,企业的关注点正在不断从“数字”价值转向“数智”价值。然而,传统数据分析的操作门槛与时间成本成为了掣肘数据价值释放的阻力。常规的数据分析流程复杂冗长,需要数据库管理员设计数据模型,数据工程师进…...
FL Studio21最新中文破解进阶高级完整版安装下载教程
目前水果软件最版本是FL Studio21,它让你的计算机就像是全功能的录音室,大混音盘,非常先进的制作工具,让你的音乐突破想象力的限制。喜欢音乐制作的小伙伴千万不要错过这个功能强大,安装便捷的音乐软件哦!如…...

MDN--Web性能
CSS 动画与 JavaScript 动画 动画的实现可以有很多种方式,比如 CSS transition 和 animation 或者基于 JavaScript 的动画(使用 requestAnimationFrame()) CSS 过渡和动画 CSS transiton :创建当前样式与结束状态样式之间的动画。尽管一个元素处于过渡状态中&…...

Vue3.js:自定义组件 v-model
Vue3的自定义v-model和vue2稍有不同 文档 https://cn.vuejs.org/guide/components/v-model.html 目录 原生组件自定义组件CustomInput实现代码1CustomInput实现代码2 v-model 的参数 原生组件 <input v-model"searchText" />等价于 <input:value"s…...
)
AI虚拟主播开发实战(附源码)
人工智能 文章目录 人工智能前言 前言 https://blog.csdn.net/icemanyandy/article/details/124035967...

innoDB如何解决幻读
Mysql的事务隔离级别 Mysql 有四种事务隔离级别,这四种隔离级别代表当存在多个事务并发冲突时,可能出现的脏读、不可重复读、幻读的问题。其中 InnoDB 在 RR 的隔离级别下,解决了幻读的问题 事务隔离级别脏读不可重复读幻读未提交读ÿ…...
、忽略(gitignore)、隐藏(Stash)、合并冲突(merge)的解决方法)
Git - 导出(archive)、忽略(gitignore)、隐藏(Stash)、合并冲突(merge)的解决方法
概述 本次集中总结了Git4个常规操作,导出(archive)、忽略(gitignore)、隐藏(Stash)、合并冲突(merge)的解决方法,希望帮助到正在辛苦寻找的你。 .gitignore忽略文件 之前开发和部署服务比较仓促,所以有很多图片文件一起加载到服务中&#…...
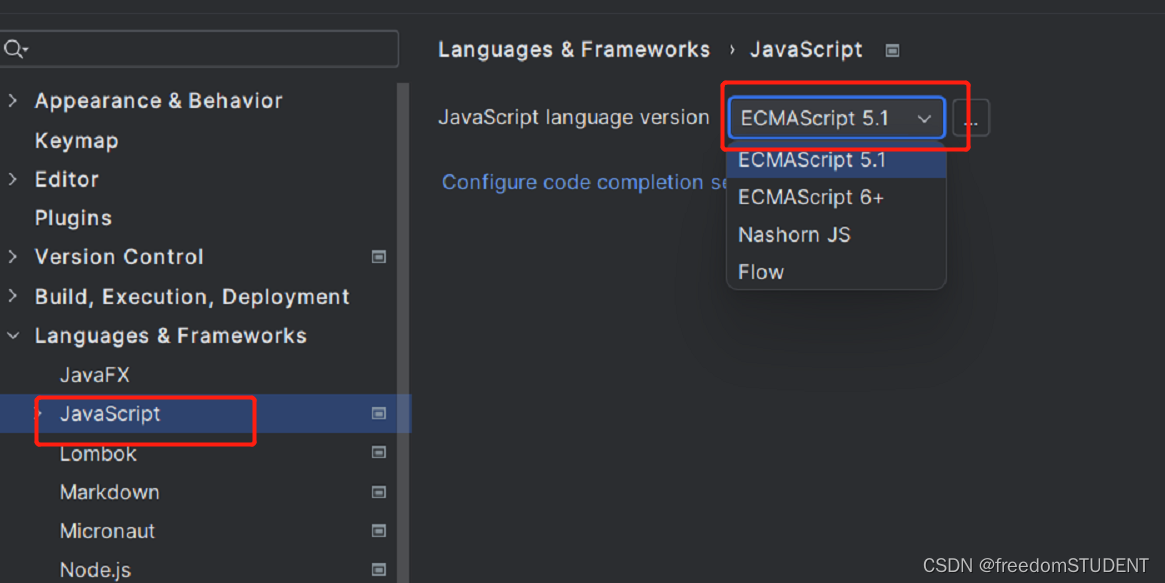
【Javascript】‘var‘ is used instead of ‘let‘ or ‘const‘
解决: 设置完之后,var 就不会再出现黄色波浪线警告...

金融统计学方法:神经网络
目录 1.神经网络 2.深度神经网络 3.案例分析 1.神经网络 神经网络是模仿人脑神经元工作原理而设计的一种算法模型。在一个基本的神经网络中,存在多个“神经元”或称为“节点”,这些节点被组织成多个层次。每个节点都接收前一层的输入,进行…...

任何人不知道这款超实用的配音软件,我都会伤心的OK?
看完一段精彩的视频,令人陶醉的原因之一就是配音,有的充满感情,有的字正腔圆,相信很多人都不知道这样的声音是怎么配出来的?今天,小编就来给大家分享一款超实用的配音软件,不仅操作简单…...

Linux查看日志文件的常用命令
1、查看文件最后1000行内容 tail -n 1000 filename 2、实时查看文件最后1000行内容,动态刷新 tailf -n 1000 filename tail -f -n 1000 filename 3、按照关键字搜索日志 cat filename | grep 关键字 4、按照关键字搜索并包含前(后)多少行 【(A前B后C前…...

AcWing算法分享系列——二分图
这是AcWing算法分享系列的第一篇文章,我们先从图论的知识下手(因为我觉得图论的只是好理解些)。 这次我们主要讲的就是二分图,二分图这次我们主要讲的就是最基础的两个板块: 二分图的判定(染色法)二分图的完美匹配(匈牙利算法)我们这一篇文章先从二分图的概念开始入手…...

【Excel单元格类型的解析校验】Java使用POI解析excel数据
一、使用的maven依赖: <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>2.1.7</version> </dependency> <dependency><groupId>org.apache.poi</groupId&…...

【运维知识高级篇】超详细的Jenkins教程5(pipeline流水线配置+分布式构建)
CI/CD是持续集成,持续部署,集成就是开发人员通过自动化编译,发布,测试的手段集成软件,在开发的测试环境上测试发现自己的错误;持续部署是自动化构建,部署,通常也是在测试环境上进行&…...

为什么要在电影院装监控?有什么作用?
近期小编在网上看到有很多人在讨论:电影院的摄像头有多高清?看电影时的小动作放映员都能看得一清二楚?答案是:是的。但大家也不必有心理负担,电影院的监控目的不是为了监控观众,更多的是为了保障观影者的权…...

航天电子器件辐射效应与加固技术解析
1. 航天电子器件的辐射环境挑战在距离地球表面100公里以上的太空环境中,电子系统面临着地面应用从未遇到的严酷挑战。根据NASA的统计数据,近地轨道每立方厘米平均存在4-5个高能粒子,而地球同步轨道则高达20个/cm。这些粒子主要来源于三个渠道…...

运维实战:监控与维护生产环境的DeOldify模型服务
运维实战:监控与维护生产环境的DeOldify模型服务 作为一名运维工程师,最怕的不是服务上线,而是上线之后。尤其是像DeOldify这样的AI模型服务,它不像普通的Web应用,背后是复杂的深度学习模型和GPU计算资源。服务跑起来…...

LFM2.5-1.2B-Instruct镜像免配置:预装transformers+gradio+unsloth
LFM2.5-1.2B-Instruct镜像免配置:预装transformersgradiounsloth 1. 模型概述 LFM2.5-1.2B-Instruct是一个1.2B参数量的轻量级指令微调大语言模型,专为边缘设备和低资源服务器设计。这个模型特别适合需要本地AI对话能力的场景,比如嵌入式AI…...

Vibe Coding:大语言模型辅助编程实践指南
1. 项目概述最近在尝试一种新的编程方式——让大语言模型辅助完成编码任务。这种被称为"Vibe Coding"的方法,核心在于将复杂开发任务拆解为可管理的子任务,并通过质量监督机制确保代码产出。经过三个月的实践,我发现这种方式能显著…...

视觉语言模型在智能视频异常检测中的创新应用
1. 项目概述:视觉语言模型在异常检测中的创新应用视频监控系统在现代社会中扮演着越来越重要的角色,从城市安防到交通管理,无处不在的摄像头每天产生海量视频数据。传统的人工监控方式早已无法应对如此庞大的数据量,智能视频分析技…...
)
手机就是开发终端:Telegram + OpenCode 实现随时随地写代码(5分钟搭建:用 Telegram 接管 OpenCode,实现真正的移动办公)
文章目录 📖 介绍 📖 🏡 演示环境 🏡 📒 移动办公新姿势:用Telegram远程操控OpenCode 📒 📝 整体架构解析 🚀 快速上手 📦 环境准备 🤖 创建 Telegram Bot 🖥️ 启动本地服务 ⚡ 安装与配置 💡 核心功能体验 📱 基础交互 🔄 实时会话跟踪 🛠️ …...

知网AI率53%紧急压低:嘎嘎降AI 35分钟出结果实测2026
知网AI率53%紧急压低:嘎嘎降AI 35分钟出结果实测2026 知网 AIGC 报告打开是 53.4%,离学校 20% 红线还差着两倍。送检前一天的下午接到这个数字,很多人第一反应是放弃这一稿重新写。嘎嘎降AI(www.aigcleaner.com)做的事…...

正宗阳澄湖大闸蟹:5款高口碑礼盒推荐 佳节送礼首选
每年中秋送礼,我最怕的一件事:👉 买到“假阳澄湖大闸蟹”😭真的不是夸张,现在市面上太多“写着阳澄湖,其实不是阳澄湖”的蟹了…踩过一次坑之后,才慢慢搞明白怎么选。今年这套我选对了ÿ…...
,仅开放给通过等保2.0三级认证企业)
MCP插件私有化部署终极方案(含国密SM4加密通道、离线证书链、Air-Gap环境适配包),仅开放给通过等保2.0三级认证企业
更多请点击: https://intelliparadigm.com 第一章:VS Code MCP 插件生态搭建手册 MCP(Model Context Protocol)是新一代 AI 工具链中用于标准化模型调用与上下文管理的关键协议。在 VS Code 中集成 MCP 支持,可实现本…...

大语言模型在文档伪造检测中的创新应用与实践
1. 大语言模型在文档伪造检测领域的创新应用在信息安全领域,文档伪造检测一直是个棘手的难题。传统方法主要依赖人工编写验证规则,不仅效率低下,而且难以应对日益复杂的伪造手段。想象一下,一位海关工作人员每天需要核验数百份护照…...