五、DeepWalk、Node2Vec论文精读与代码实战【CS224W】(Datawhale组队学习)
开源内容:https://github.com/TommyZihao/zihao_course/tree/main/CS224W
子豪兄B 站视频:https://space.bilibili.com/1900783/channel/collectiondetail?sid=915098
斯坦福官方课程主页:https://web.stanford.edu/class/cs224w
文章目录
- DeepWalk算法
- 问题的定义
- 学习隐含特征表示
- 关键技术
- 相关工作
- 代码实战
- 获取维基百科网页引用关联数据
- 生成随机游走节点序列的函数
- 生成随机游走序列
- 训练Word2Vec模型
- 分析Word2Vec结果
- PCA降维可视化
- TSNE降维可视化
- Node2Vec算法
- Node2Vec
- 关键技术
- 代码实战
- 构建Node2Vec模型
- 节点Embedding聚类可视化
- 节点Embedding降维可视化
- 思考题
- 总结
DeepWalk算法
背景:机器学习在稀疏性数据上很难进行处理
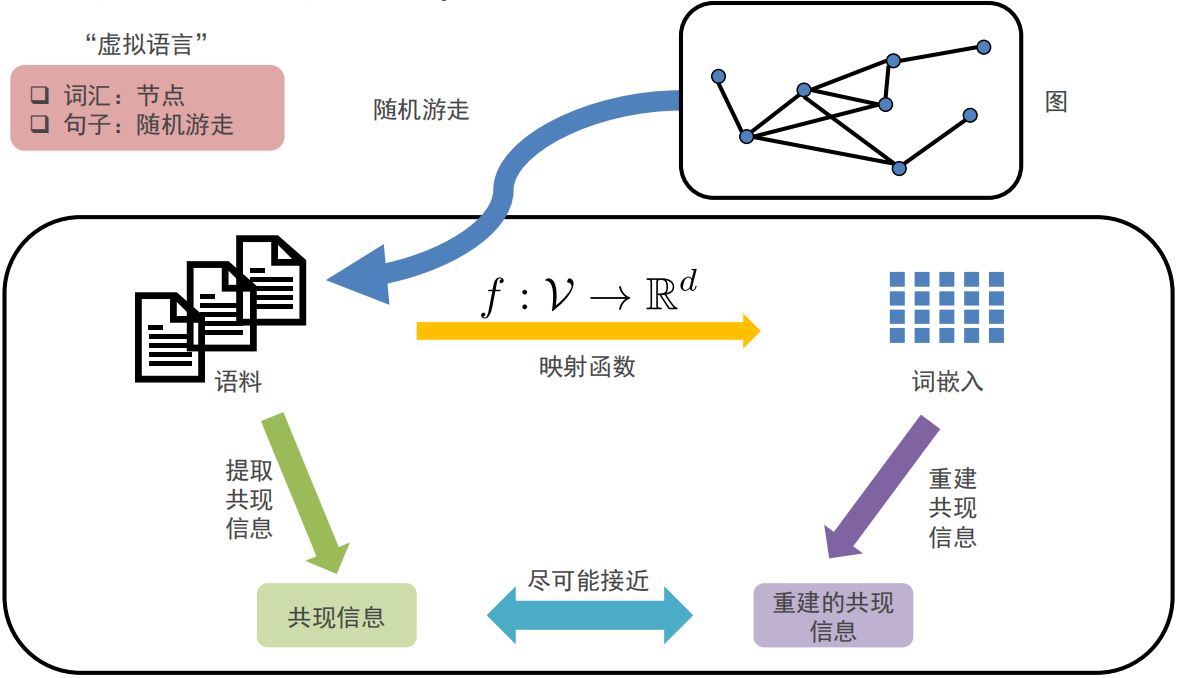
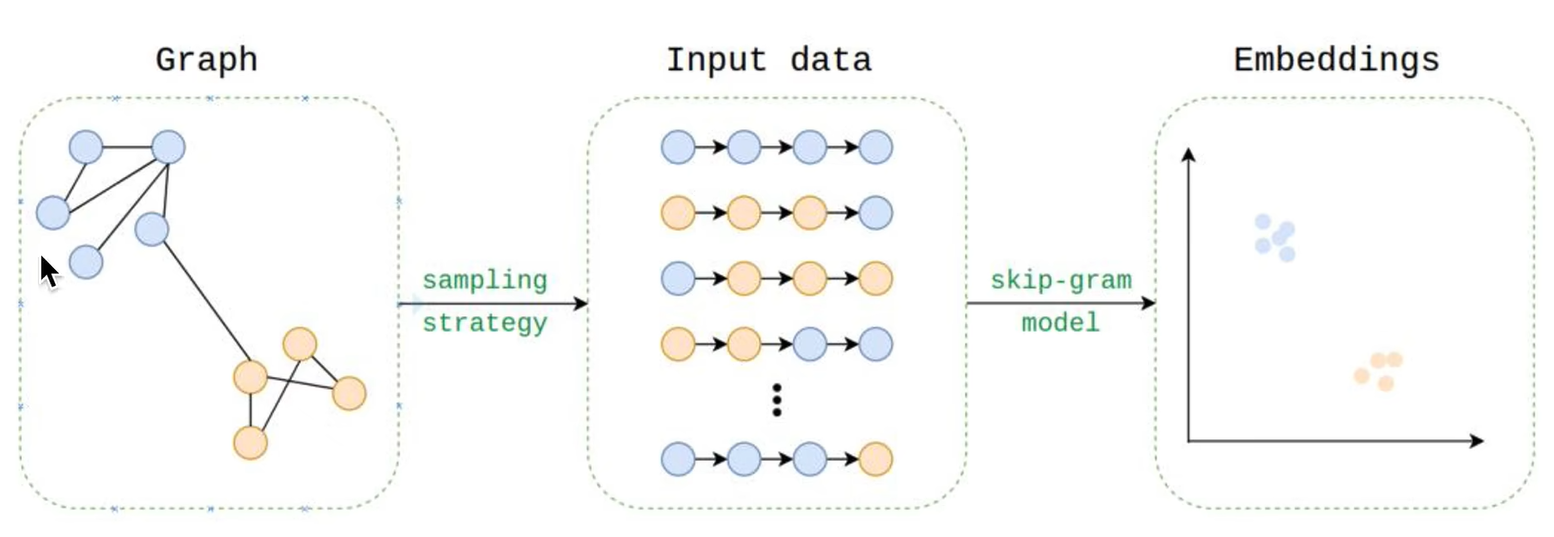
Deepwalk是用于图节点嵌入的在线机器学习算法
- 能够通过随机游走序列(邻居信息和社群信息)学习网络的连接结构信息,将节点编码为连续地维的稠密的向量空间
- 不需要重新训练,只需要输入新节点和新连接关系,再进行增量训练,可以进行并行计算
问题的定义
针对节点分类问题,假设图G=(V,E)G=(V,E)G=(V,E)其中E⊆(V×V)\subseteq(V×V)⊆(V×V),GL=(V,E,X,Y)G_{L}=(V,E,X,Y)GL=(V,E,X,Y)表示带标注的社交网络,每个节点有SSS维特征,YYY表示每个节点的标注
目标:通过反映连接信息的Embedding和反映节点本身的特征进行节点嵌入,得到一个XEX_{E}XE∈\in∈R∣V∣×dR^{\mid V\mid×d }R∣V∣×d的嵌入,最后结合机器学习算法解决分类问题
学习隐含特征表示
-
DeepWalk学习到的embedding的特性
-
Adaptability:灵活可变、弹性扩容
-
Community aware:反映社群聚类信息,原图中相近的点嵌入后依然相近
-
Low dimensional:低维度嵌入有助于防止过拟合
-
Continuous:元素的细微变化都会对模型产生影响,可以拟合出一个平滑的决策边界
-
-
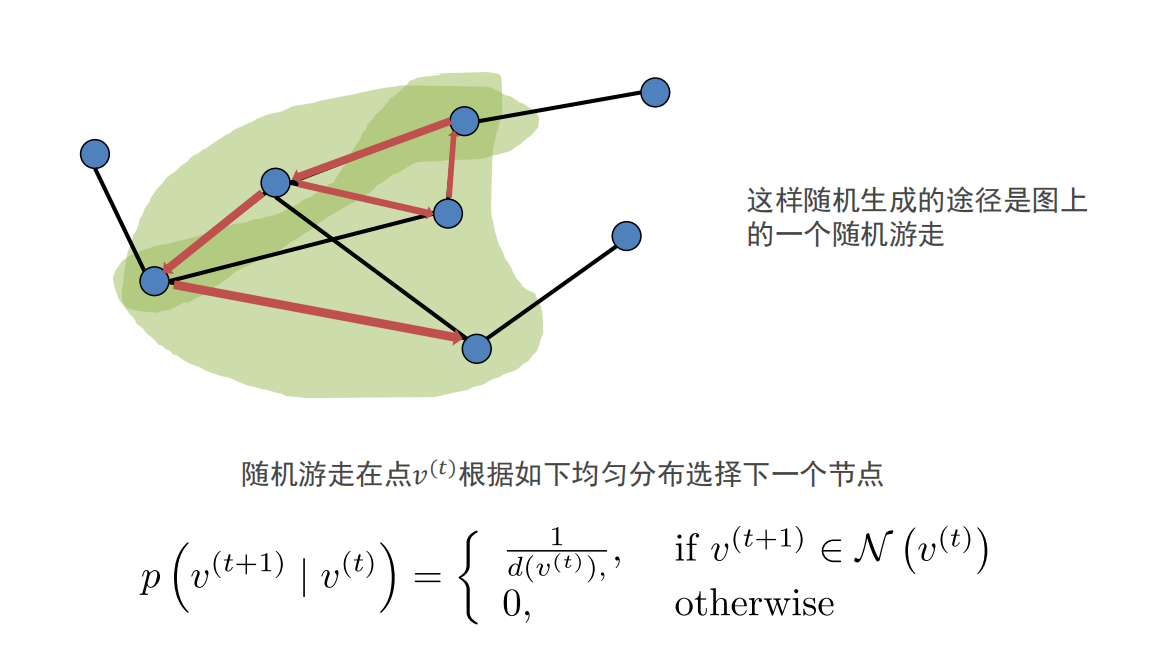
随机游走:可以使用并行方式,在线增量进行随机游走。
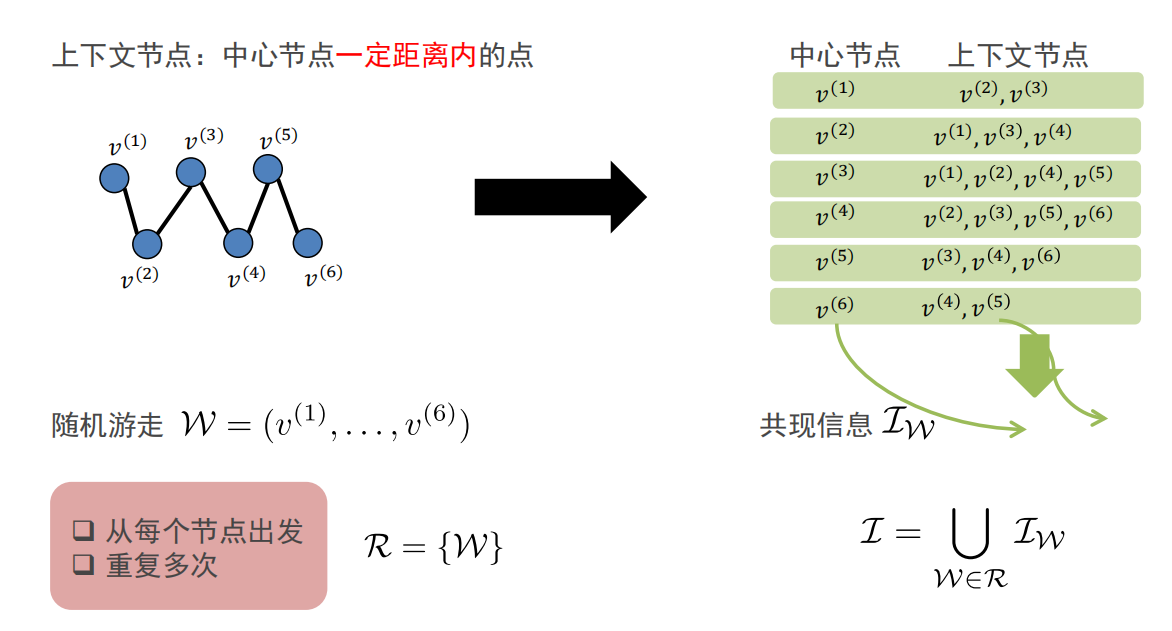
-
幂律分布:在一个无标度网络中,中枢节点的连接数远高于其他节点,会产生长尾现象,也称为Zipf定律(词频排序名次与词频成正比,只有极少数的词被经常使用)
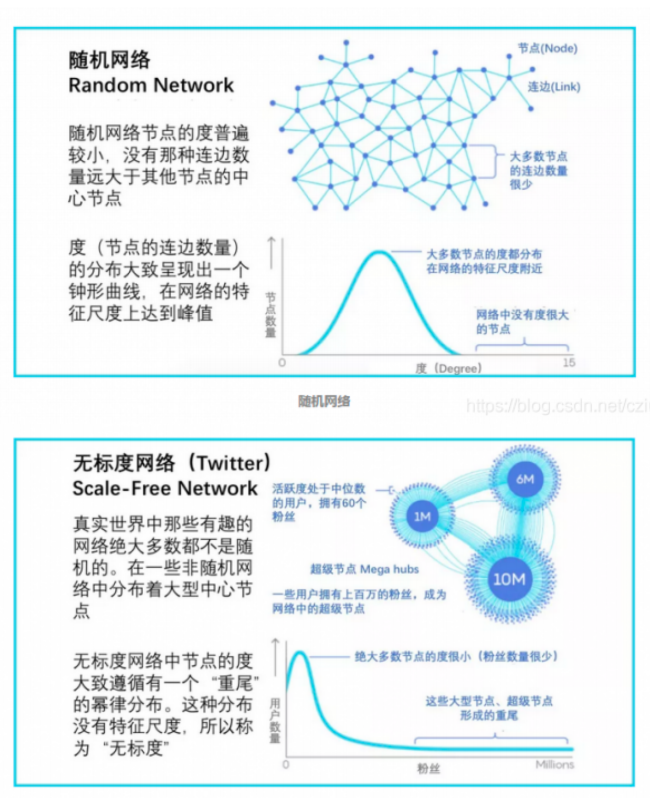
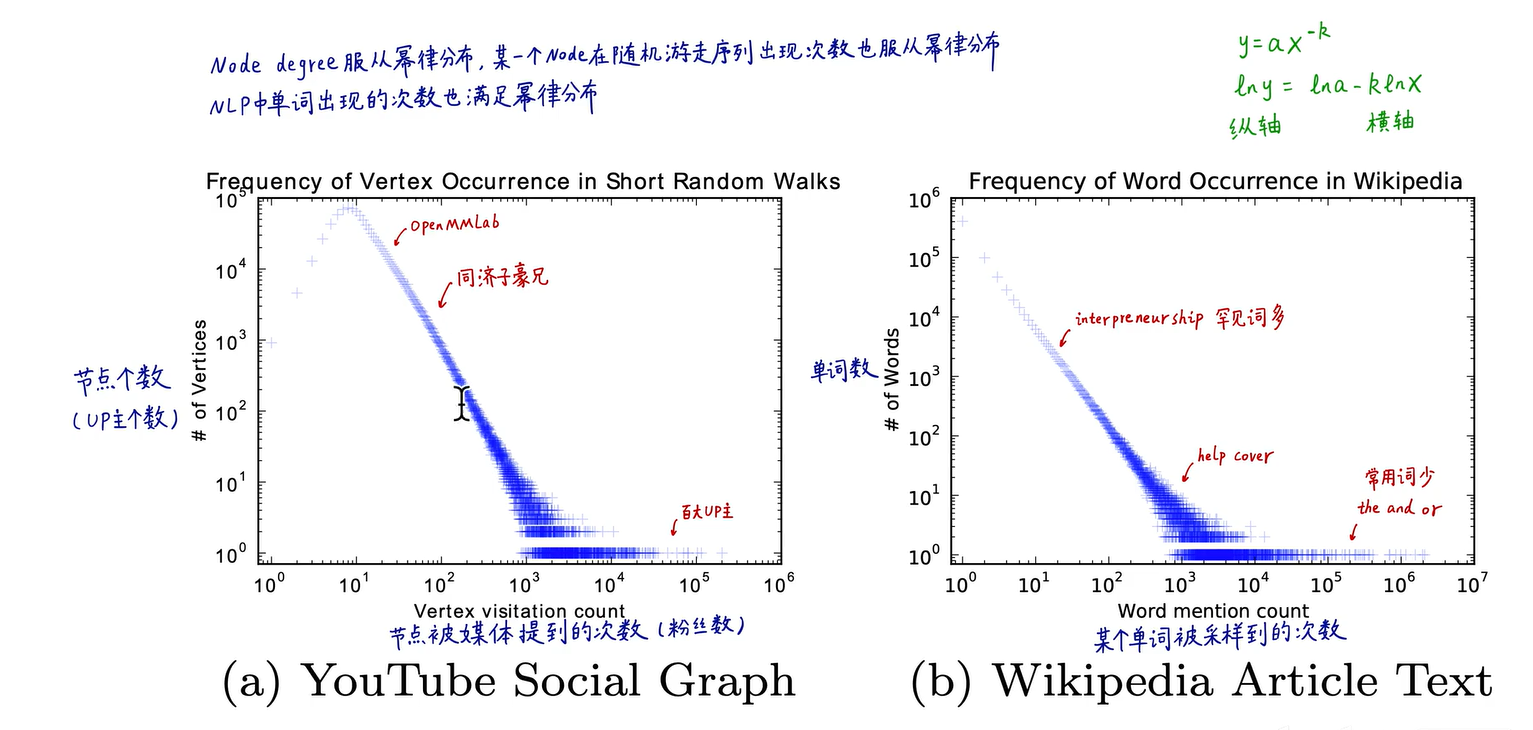
-
语言模型: 用前iii-1个词预测下文的第 iii个词,通过 Pr(vi∣(v1,v2,⋯,vi−1))Pr\left(v_{i} \mid\left(v_{1}, v_{2}, \cdots, v_{i-1}\right)\right)Pr(vi∣(v1,v2,⋯,vi−1)) ,使用提取Embedding的函数 Φ\PhiΦ: v∈V↦R∣V∣×dv \in V \mapsto R^{|V| \times d}v∈V↦R∣V∣×d ,可表示用 前iii-1个节点的Embedding预测第 iii 个节点
Pr(vi∣(Φ(v1),Φ(v2),⋯,Φ(vi−1)))Pr\left(v_{i} \mid\left(\Phi\left(v_{1}\right), \Phi\left(v_{2}\right), \cdots, \Phi\left(v_{i-1}\right)\right)\right)Pr(vi∣(Φ(v1),Φ(v2),⋯,Φ(vi−1)))
关键技术
DeepWalk

SkipGram算法

分层softmax:采用霍夫曼编码
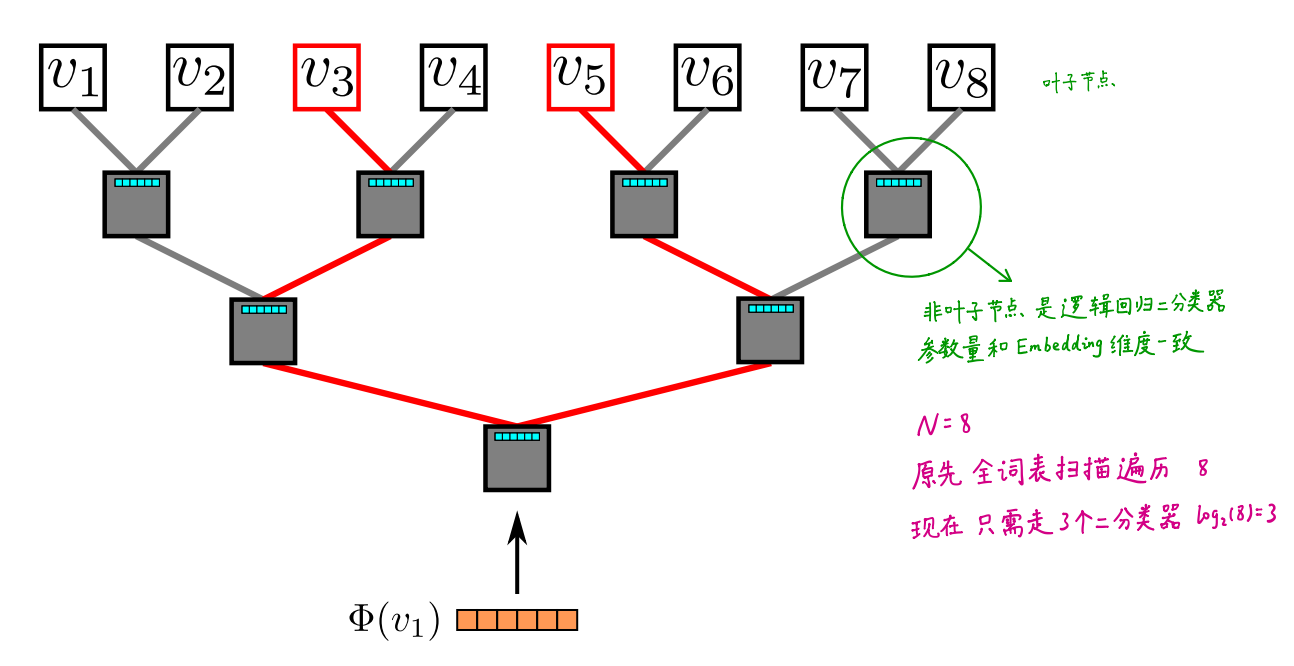
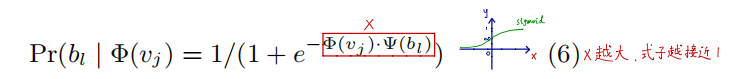
DeepWalk有两套权重
- N个节点的D维Embdding
- (N-1)个逻辑回归,每个有D个权重
相关工作
- 该算法通过机器学习得到的,而非人工统计构造得到的
- 该算法是无监督的,不考虑节点的label信息,只靠graph连接信息
- 在线学习,仅使用graph的局部信息
- 将无监督学习(深度学习)应用在图上
- DeepWalk将自然语言处理推广到了图,把随机游走序列作为特殊的句子,把节点作为特殊的单词,语言模型是对不可见的隐式Graph建模,对于可见Graph的分析方法可以促进非可见Graph的研究(例如自然语言处理)
代码实战
参考资料
https://www.analyticsvidhya.com/blog/2019/11/graph-feature-extraction-deepwalk/
https://github.com/prateekjoshi565/DeepWalk
import networkx as nx # 图数据挖掘# 数据分析
import pandas as pd
import numpy as npimport random # 随机数
from tqdm import tqdm # 进度条# 数据可视化
import matplotlib.pyplot as plt
%matplotlib inlineplt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
获取维基百科网页引用关联数据
-
打开网站
[https://densitydesign.github.io/strumentalia-seealsology](https://densitydesign.github.io/strumentalia-seealsology) -
Distance设置为
4 -
输入以下链接
https://en.wikipedia.org/wiki/Computer_vision
https://en.wikipedia.org/wiki/Deep_learning
https://en.wikipedia.org/wiki/Convolutional_neural_network
https://en.wikipedia.org/wiki/Decision_tree
https://en.wikipedia.org/wiki/Support-vector_machine -
点击
START CRAWLING,爬取1000个网页之后,点击STOP & CLEAR QUEUE -
Download-下载TSV文件,保存至代码相同目录,命名为
seealsology-data.tsv
df = pd.read_csv("seealsology-data.tsv", sep = "\t")
df.head()

构建无向图并进行可视化
G = nx.from_pandas_edgelist(df, "source", "target", edge_attr=True, create_using=nx.Graph())
plt.figure(figsize=(15,14))
nx.draw(G)
plt.show()

生成随机游走节点序列的函数
def get_randomwalk(node, path_length):'''输入起始节点和路径长度,生成随机游走节点序列'''random_walk = [node]for i in range(path_length-1):# 汇总邻接节点temp = list(G.neighbors(node))temp = list(set(temp) - set(random_walk)) if len(temp) == 0:break# 从邻接节点中随机选择下一个节点random_node = random.choice(temp)random_walk.append(random_node)node = random_nodereturn random_walkget_randomwalk('random forest', 5)
[‘random forest’,
‘out-of-bag error’,
‘bootstrap aggregating’,
‘cascading classifiers’,
‘boosting (meta-algorithm)’]
生成随机游走序列
gamma = 10 # 每个节点作为起始点生成随机游走序列个数
walk_length = 5 # 随机游走序列最大长度random_walks = []for n in tqdm(all_nodes): # 遍历每个节点for i in range(gamma): # 每个节点作为起始点生成gamma个随机游走序列random_walks.append(get_randomwalk(n, walk_length))# 生成随机游走序列个数
len(random_walks)
85600
训练Word2Vec模型
from gensim.models import Word2Vec # 自然语言处理model = Word2Vec(vector_size=256, # Embedding维数window=4, # 窗口宽度sg=1, # Skip-Gramhs=0, # 不加分层softmaxnegative=10, # 负采样alpha=0.03, # 初始学习率min_alpha=0.0007, # 最小学习率seed=14 # 随机数种子)# 用随机游走序列构建词汇表
model.build_vocab(random_walks, progress_per=2)
# 训练(耗时1分钟左右)
model.train(random_walks, total_examples=model.corpus_count, epochs=50, report_delay=1)
分析Word2Vec结果
# 查看某个节点的Embedding
model.wv.get_vector('random forest').shape
(256,)
# 找相似词语
model.wv.similar_by_word('decision tree')
[(‘behavior tree (artificial intelligence, robotics and control)’,
0.7099794745445251),
(‘drakon’, 0.6946774125099182),
(‘decision list’, 0.6726175546646118),
(‘self-documenting code’, 0.6475881934165955),
(‘decision matrix’, 0.6162508726119995),
(‘behavior trees (artificial intelligence, robotics and control)’,
0.6040382385253906),
(‘structured programming’, 0.5988644361495972),
(‘decision-tree pruning’, 0.5983075499534607),
(‘belief structure’, 0.5966054201126099),
(‘decision tree model’, 0.5922632813453674)]
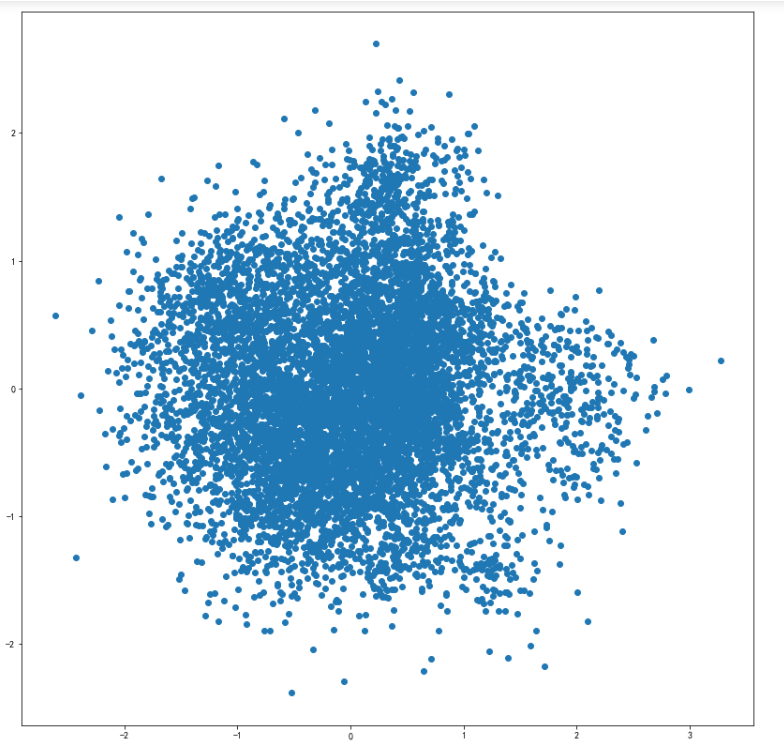
PCA降维可视化
可视化全部词条的二维Embedding
X = model.wv.vectors#(8560, 256)
# 将Embedding用PCA降维到2维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
embed_2d = pca.fit_transform(X)#(8560, 2)plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0], embed_2d[:, 1])
plt.show()
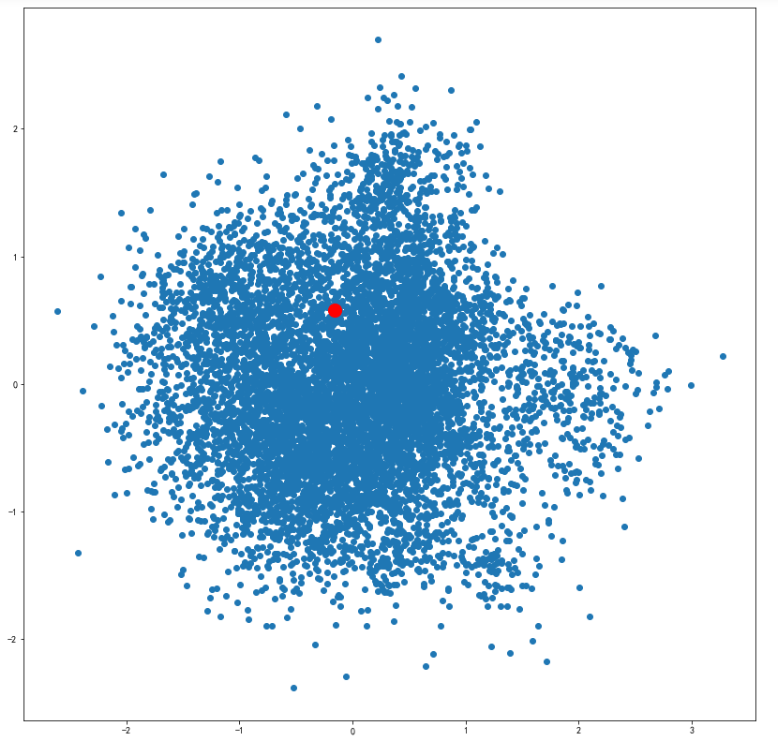
可视化某个词条的二维Embedding
term = 'computer vision'
term_256d = model.wv[term].reshape(1,-1)#(1, 256)
term_2d = pca.transform(term_256d)#(1, 2)plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:,0], embed_2d[:,1])
plt.scatter(term_2d[:,0],term_2d[:,1],c='r',s=200)
plt.show()
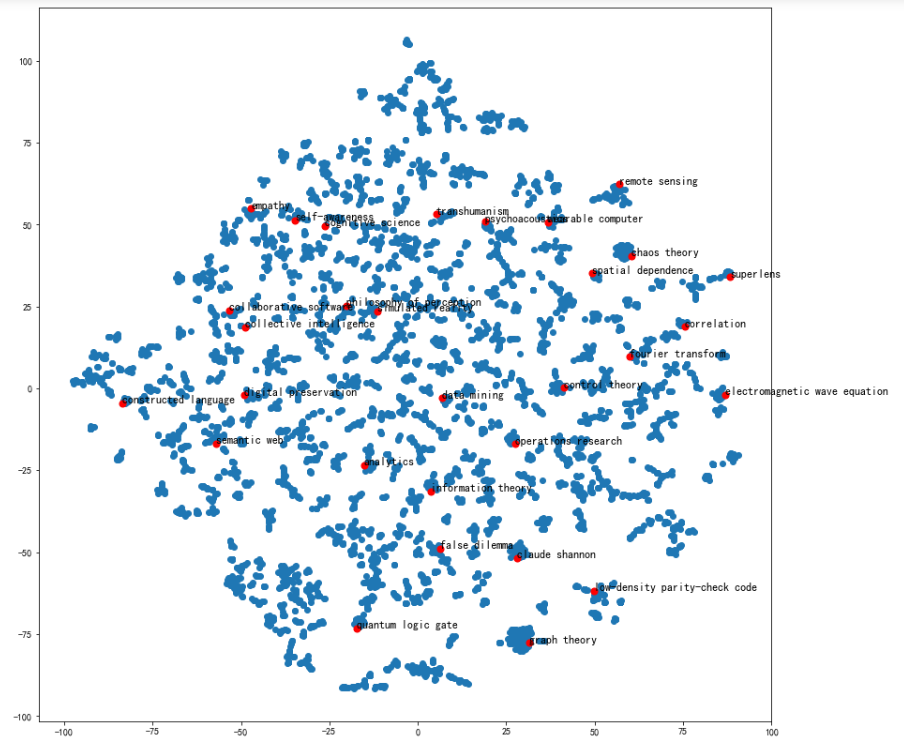
可视化某些词条的二维Embedding
# 计算PageRank重要度
pagerank = nx.pagerank(G)
# 从高到低排序
node_importance = sorted(pagerank.items(), key=lambda x:x[1], reverse=True)# 取最高的前n个节点
n = 30
terms_chosen = []
for each in node_importance[:n]:terms_chosen.append(each[0])# 输入词条,输出词典中的索引号
term2index = model.wv.key_to_index# 可视化全部词条和关键词条的二维Embedding
plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:,0], embed_2d[:,1])#绘制全部词条for item in terms_chosen:idx = term2index[item]#关键词条的索引号plt.scatter(embed_2d[idx,0], embed_2d[idx,1],c='r',s=50)#绘制关键词条plt.annotate(item, xy=(embed_2d[idx,0], embed_2d[idx,1]),c='k',fontsize=12)
plt.show()
TSNE降维可视化
可视化全部词条的二维Embedding
# 将Embedding用TSNE降维到2维
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, n_iter=1000)
embed_2d = tsne.fit_transform(X)plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0], embed_2d[:, 1])
plt.show()
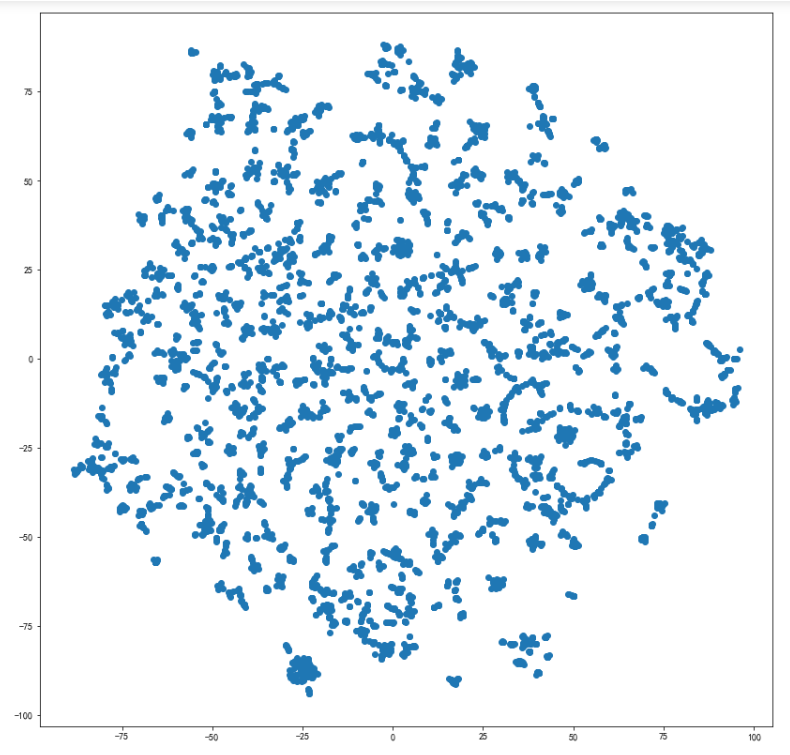
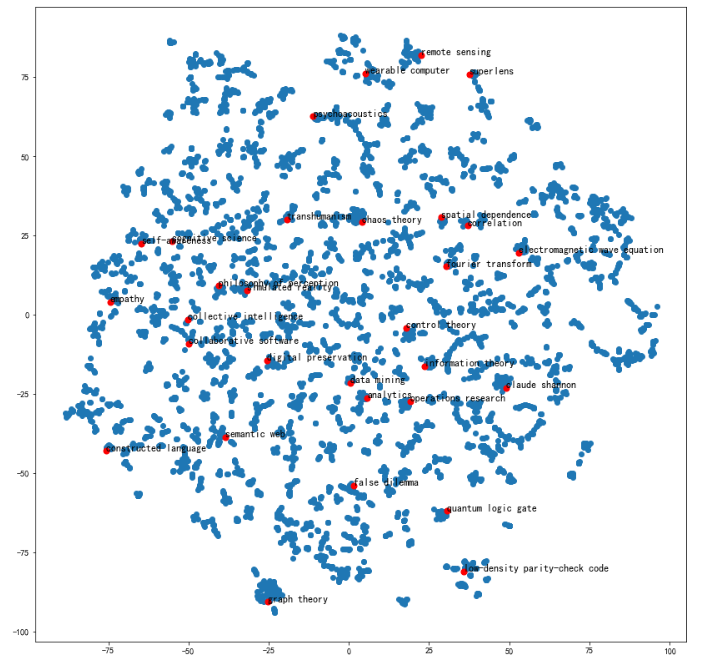
可视化全部词条和关键词条的二维Embedding
plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:,0], embed_2d[:,1])for item in terms_chosen:idx = term2index[item]plt.scatter(embed_2d[idx,0], embed_2d[idx,1],c='r',s=50)plt.annotate(item, xy=(embed_2d[idx,0], embed_2d[idx,1]),c='k',fontsize=12)
plt.show()
导出TSNE降维到二维之后的Embedding
terms_chosen_mask = np.zeros(X.shape[0])
for item in terms_chosen:idx = term2index[item]terms_chosen_mask[idx] = 1df = pd.DataFrame()
df['X'] = embed_2d[:,0]
df['Y'] = embed_2d[:,1]
df['item'] = model.wv.index_to_key
df['pagerank'] = pagerank.values()
df['chosen'] = terms_chosen_maskdf.to_csv('tsne_vis_2d.csv',index=False)
df
可视化全部词条的三维Embedding
# 将Embedding用TSNE降维到3维
from sklearn.manifold import TSNE
tsne = TSNE(n_components=3, n_iter=1000)
embed_3d = tsne.fit_transform(X)
导出TSNE降维到三维之后的Embedding
df = pd.DataFrame()
df['X'] = embed_3d[:,0]
df['Y'] = embed_3d[:,1]
df['Z'] = embed_3d[:,2]
df['item'] = model.wv.index_to_key
df['pagerank'] = pagerank.values()
df['chosen'] = terms_chosen_maskdf.to_csv('tsne_vis_3d.csv',index=False)
df
Node2Vec算法
DeepWalk的缺点
- 用完全随机游走,训练节点嵌入向量
- 仅能反映相邻节点的社群相似信息
- 无法反映节点的功能角色相似信息
Node2Vec
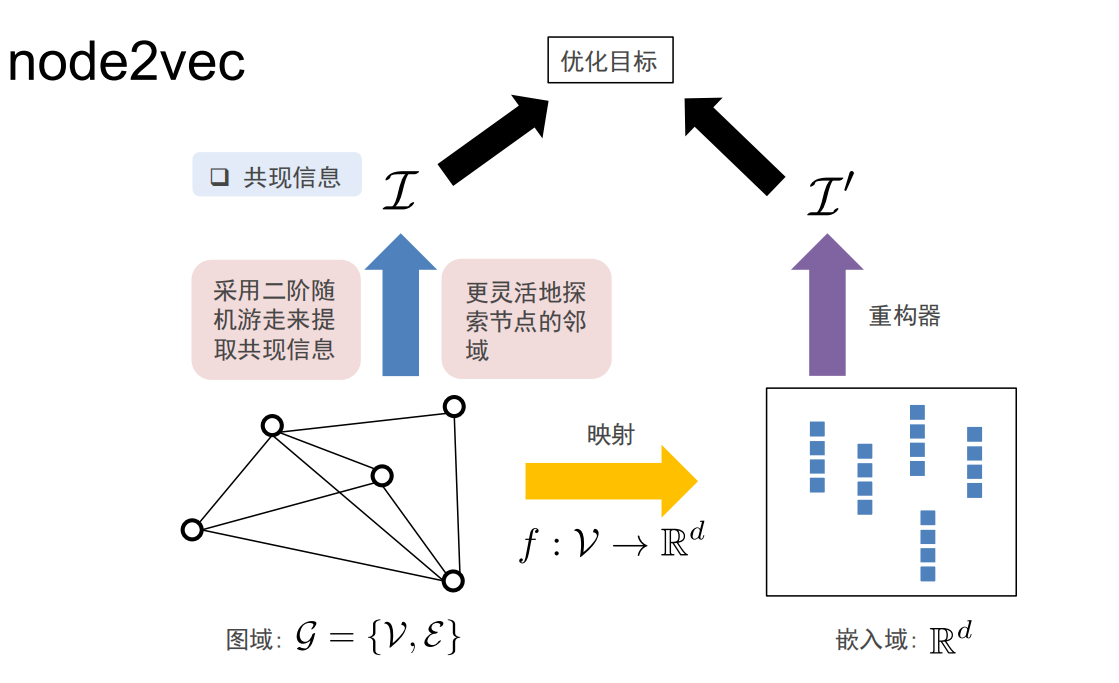
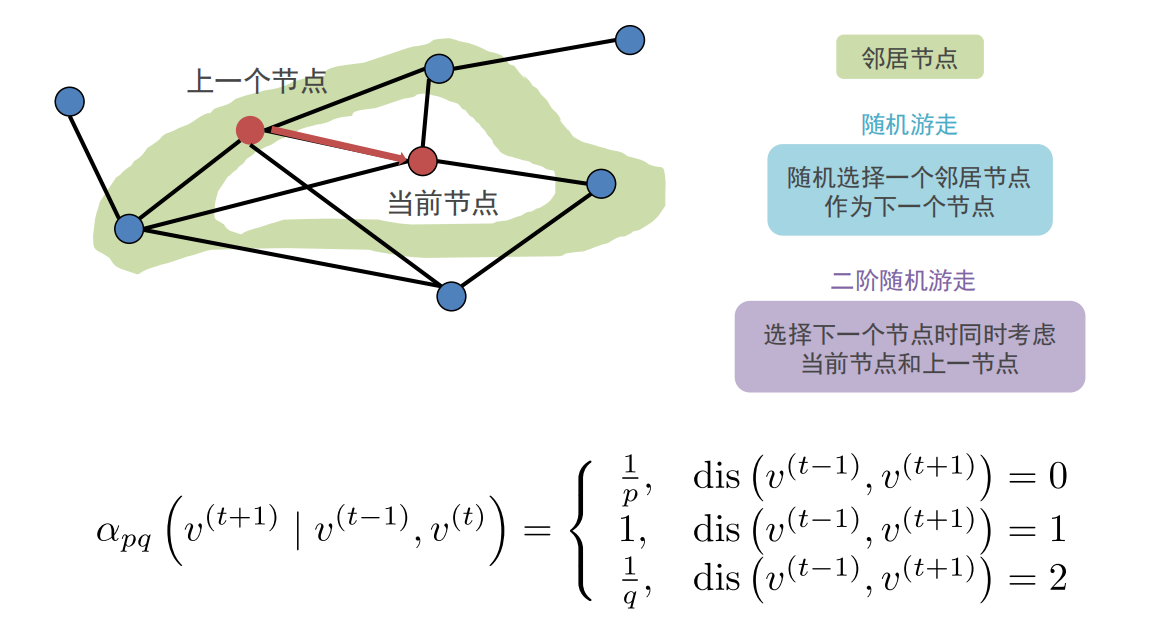
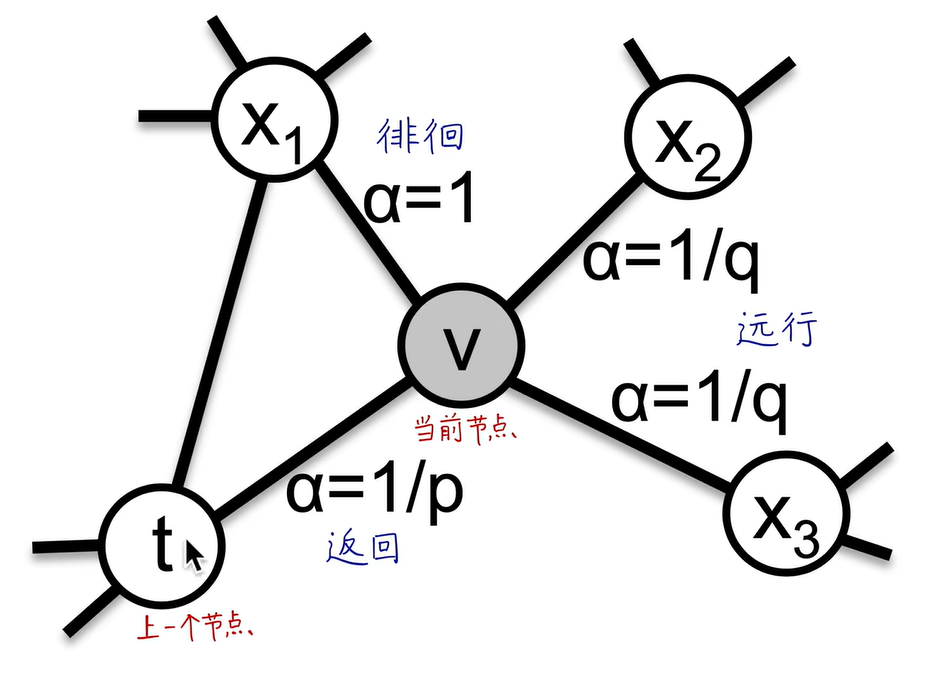
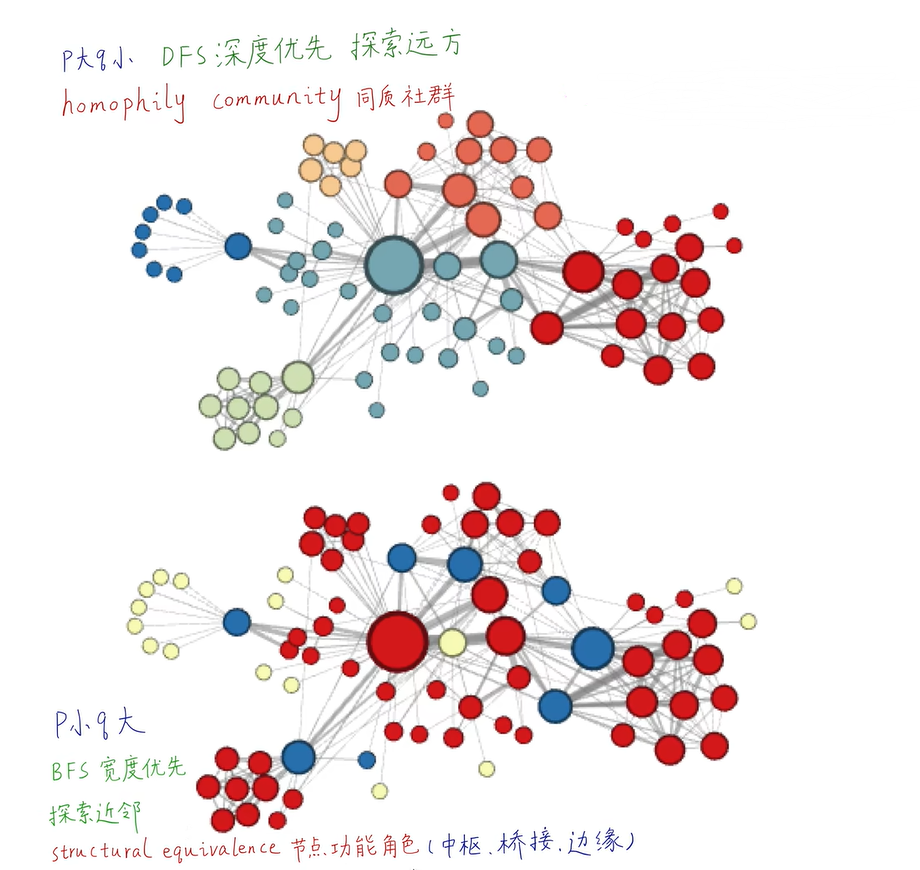
Node2Vec是有偏的随机游走:
-
超参数p控制从节点v(t−1)v^{(t-1)}v(t−1)游走到v(t)v^{(t)}v(t)之后立即重新访问v(t−1)v^{(t-1)}v(t−1)的概率,p越小,越可能访问已访问的节点
-
超参数q允许随机游走区分“向内”和“向外”的节点,q越小,越可能访问到离已访问节点更远的节点。
-
当p值很小时,属于广度优先搜索,反映微观的邻域
-
当q值很小时,属于深度优先搜索,反映宏观的视角
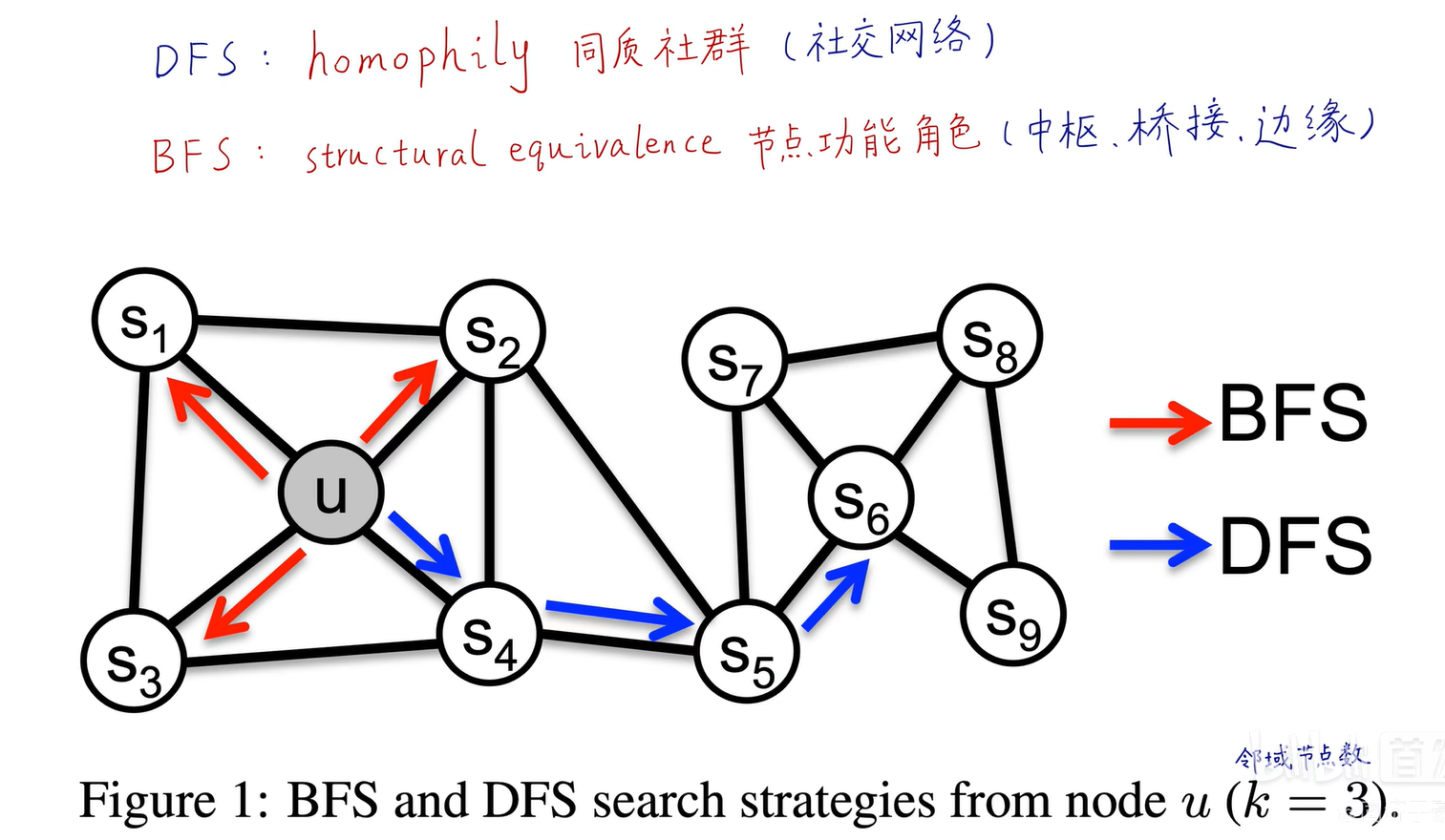
BFS和DFS只适合探索同质性和结构等价性的极端情况不同,现实世界中的网络常常同时表现出这两种等价性。
通过p、q参数控制的二阶随机游走,可以在BFS和DFS之间插值,从而反映不同的节点等价性概念。二阶是马尔可夫链的相关概念,表示下一节点是否被遍历不仅与**当前节点(第一阶)的拓扑结构有关,还与游走的上一个节点(第二阶)**相关
Node2Vec在空间和时间方面都具有较高的计算效率
-
空间复杂度为O(∣E∣)O(|E|)O(∣E∣)
对于二阶随机游走,存储每个节点邻居之间的相互关系有助于提高采样速度,其空间复杂度为O(a2∣V∣)O(a^{2}|V|)O(a2∣V∣),其中aaa是图的平均度数,对于实际网络来说通常很小。 -
时间复杂度O(lk(l−k))O(lk(l-k))O(lk(l−k))
通过在样本生成过程中强制图的连通性,随机游走提供了一种方便的机制,通过在不同的源节点之间重复使用样本来增加有效采样率。
通过模拟长度为lll的随机游走,我们可以一次性为l−kl-kl−k个节点生成kkk个样本,因为随机游走具有马尔可夫性质。
关键技术
node2vecWalk

由于任何随机游走都有由起始节点uuu选择所带来的隐含偏差,因此该算法从每个节点开始模拟rrr次固定长度为lll的随机游走来消除这种偏差。
在每一步的游走过程中,节点采样是基于转移概率πvxπvxπvx完成的,该概率可以预先计算。node2vec算法的三个阶段依次是:
- 预处理以计算转移概率,
- 模拟随机游走
- 使用SGD进行优化
每个阶段都可以并行执行,因此node2vec算法有很强的可扩展性。
Alias Sample
用于产生下一个随机游走节点,时间复杂度为O(1)O(1)O(1),用空间(预处理)换时间,适用于大量反复的抽样情况下,将离散分布抽样转化为均匀分布抽样
具体可以参考:https://www.cnblogs.com/Lee-yl/p/12749070.html
代码实战
import networkx as nx # 图数据挖掘
import numpy as np # 数据分析
import random # 随机数# 数据可视化
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
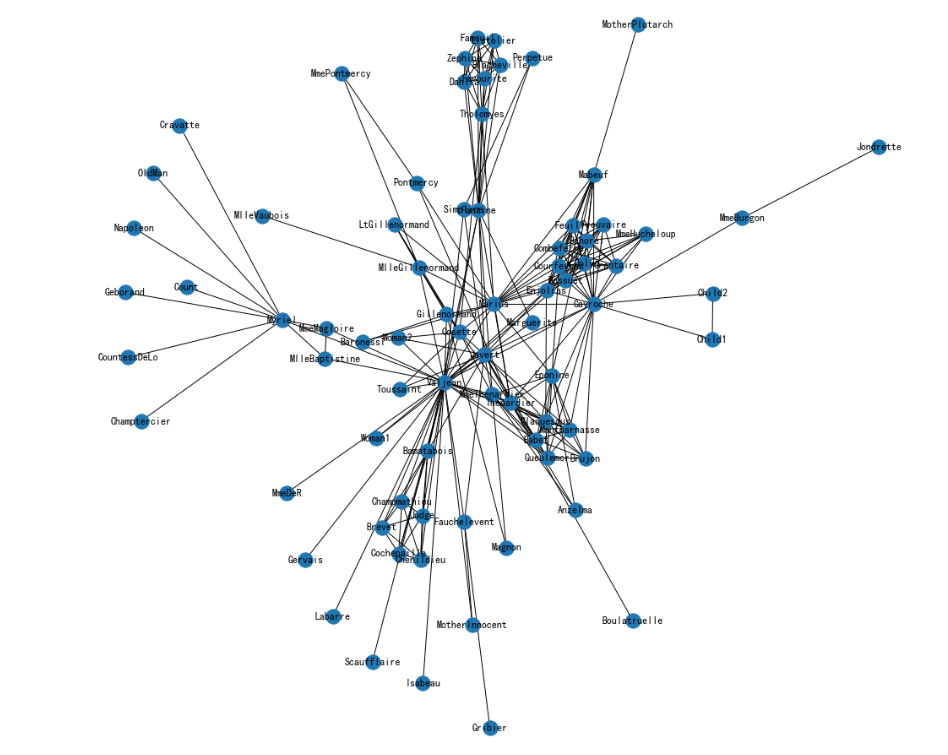
导入《悲惨世界》人物数据集并进行可视化
# 《悲惨世界》人物数据集
G = nx.les_miserables_graph()
# 可视化
plt.figure(figsize=(15,14))
pos = nx.spring_layout(G, seed=5)
nx.draw(G, pos, with_labels=True)
plt.show()
构建Node2Vec模型
from node2vec import Node2Vec
# 设置node2vec参数
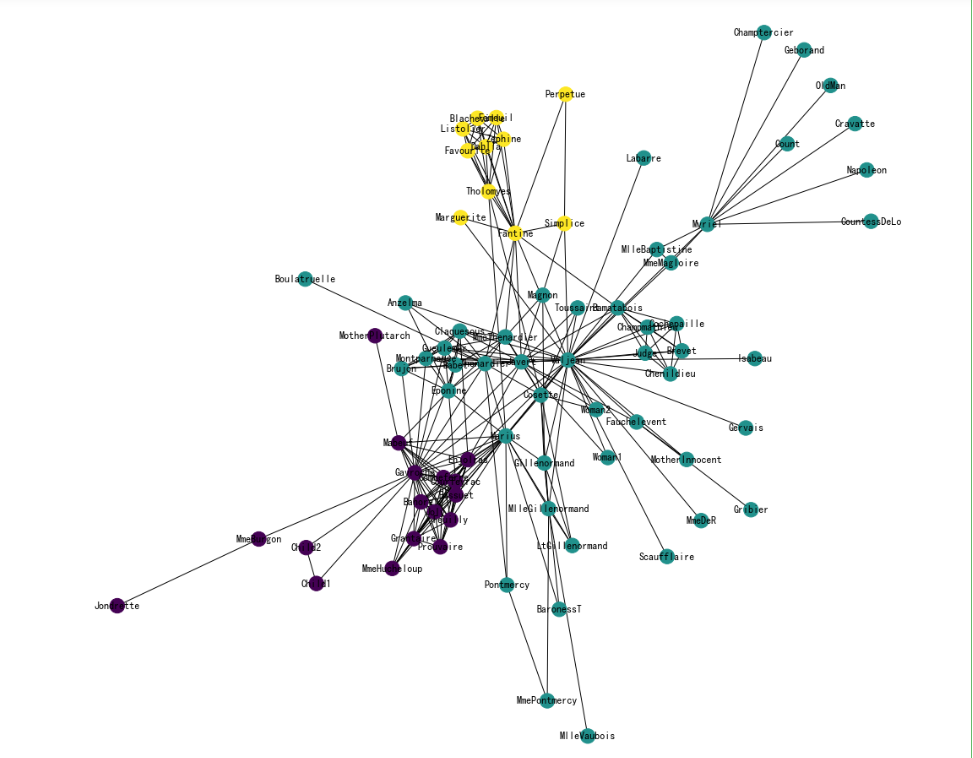
node2vec = Node2Vec(G, dimensions=32, # 嵌入维度p=1, # 回家参数q=3, # 外出参数walk_length=10, # 随机游走最大长度num_walks=600, # 每个节点作为起始节点生成的随机游走个数workers=4 # 并行线程数)# p=1, q=0.5, n_clusters=6。DFS深度优先搜索,挖掘同质社群
# p=1, q=2, n_clusters=3。BFS宽度优先搜索,挖掘节点的结构功能。# 训练Node2Vec,参数文档见 gensim.models.Word2Vec
model = node2vec.fit(window=3, # Skip-Gram窗口大小min_count=1, # 忽略出现次数低于此阈值的节点(词)batch_words=4 # 每个线程处理的数据量)
X = model.wv.vectors
节点Embedding聚类可视化
# # DBSCAN聚类
# from sklearn.cluster import DBSCAN
# cluster_labels = DBSCAN(eps=0.5, min_samples=6).fit(X).labels_
# print(cluster_labels)# KMeans聚类
from sklearn.cluster import KMeans
import numpy as np
cluster_labels = KMeans(n_clusters=3).fit(X).labels_
print(cluster_labels)
将networkx中的节点和词向量中的节点对应
将词汇表的节点顺序转为networkx中的节点顺序
colors = []
nodes = list(G.nodes)
for node in nodes: # 按 networkx 的顺序遍历每个节点idx = model.wv.key_to_index[str(node)] # 获取这个节点在 embedding 中的索引号colors.append(cluster_labels[idx]) # 获取这个节点的聚类结果
可视化聚类效果
plt.figure(figsize=(15,14))
pos = nx.spring_layout(G, seed=10)
nx.draw(G, pos, node_color=colors, with_labels=True)
plt.show()
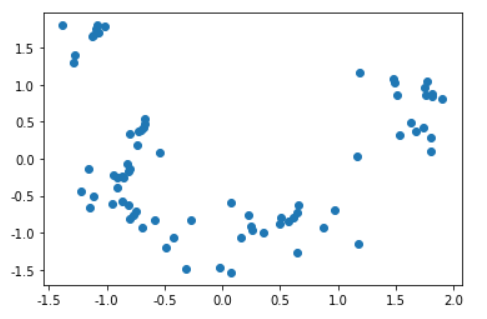
节点Embedding降维可视化
# 将Embedding用PCA降维到2维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
embed_2d = pca.fit_transform(X)# # 将Embedding用TSNE降维到2维
# from sklearn.manifold import TSNE
# tsne = TSNE(n_components=2, n_iter=5000)
# embed_2d = tsne.fit_transform(X)# plt.figure(figsize=(14,14))
plt.scatter(embed_2d[:, 0], embed_2d[:, 1])
plt.show()
查看Embedding
# 查看某个节点的Embedding
model.wv.get_vector('Napoleon')
# 查找 Napoleon 节点的相似节点
model.wv.most_similar('Napoleon')
# 查看任意两个节点的相似度
model.wv.similarity('Napoleon', 'Champtercier')
对Edge(连接)做Embedding
from node2vec.edges import HadamardEmbedder
# Hadamard 二元操作符:两个 Embedding 对应元素相乘
edges_embs = HadamardEmbedder(keyed_vectors=model.wv)# 查看 任意两个节点连接 的 Embedding
edges_embs[('Napoleon', 'Champtercier')]# 计算所有 Edge 的 Embedding
edges_kv = edges_embs.as_keyed_vectors()# 查看 关系与 某两个节点 最相似的 节点对
edges_kv.most_similar(str(('Bossuet', 'Valjean')))
思考题
DeepWalk
-
DeepWalk本质上是在解决什么问题?
-
DeepWalk和Word2Vec有哪些异同?
-
DeepWalk和Node2Vec有哪些异同?
-
DeepWalk的随机游走生成过程有哪些缺点?如何改进?
-
DeepWalk是否包含节点的类别和自身特征信息?
-
除了非标度网络和自然语言外,还有哪些分布服从幂律分布?
-
非标度网络和随机网络有什么区别?
-
如果两个节点隔得非常远,DeepWalk能否捕捉这样的关系?
-
DeepWalk为什么在稀疏标注场景下表现地更好?
-
除了对节点编码,DeepWalk能否对连接、子图、全图做编码?
-
随机游走的序列最大长度应设置为多少合适?
-
DeepWalk论文中对原生DeepWalk做了哪两种改进?
-
DeepWalk能否解决link prediction问题?为什么?
Node2Vec
-
为什么DFS探索的是节点社群属性,BFS探索的是节点功能角色属性?
-
Node2Vec中的BFS和DFS,和大学计算机本科《数据结构与算法》课程中的BFS、DFS搜索有什么异同?
-
Node2Vec中的随机游走,是相对于上一个节点和当前节点,为什么不是相对于起始节点和当前节点?
-
论文实验结果中,为什么PPI蛋白质图数据集上,Node2Vec相比DeepWalk,性能没有显著提升?
-
连接如果带权重的话,如何影响有偏随机游走序列生成?
-
有向图和无向图,如何影响有偏随机游走序列生成?
-
为什么使用Alias Sampling?简述Alias Sampling的基本原理
-
Node2vec的BFS是否能用在分析自然语言中单词的角色(中枢单词、桥接单词)
-
除了DeepWalk和Node2Vec,还有哪些随机游走方法?
-
Node2Vec算法有哪些缺点?如何弥补?
总结
本篇文章主要讲解了DeepWalk算法和Node2Vec算法
- DeepWalk算法能够通过随机游走序列(邻居信息和社群信息)学习网络的连接结构信息,将节点编码为连续地维的稠密的向量空间,新加入节点时不需要重新训练,只需要输入新节点和新连接关系,再进行增量训练,并且它可以进行并行计算。在代码实战部分,使用维基百科词条数据构建无向图,生成随机游走节点序列,训练Word2Vec模型,通过计算PageRank得到关键词条,并对embedding结果进行降维可视化。
- Node2Vec通过调节p、q值,实现有偏随机游走,探索节点社群、功能等不同属性。首次把节点分类用于Link Prediction,可解释性、可扩展性好,性能卓越。但是需要大量随机游走序列训练,弱水三千取—瓢,管中窥豹,距离较远的两个节点无法直接相互影响,看不到全图信息。仅编码图的连接信息,没有利用节点的属性特征,没有真正用到神经网络和深度学习。
相关文章:
五、DeepWalk、Node2Vec论文精读与代码实战【CS224W】(Datawhale组队学习)
开源内容:https://github.com/TommyZihao/zihao_course/tree/main/CS224W 子豪兄B 站视频:https://space.bilibili.com/1900783/channel/collectiondetail?sid915098 斯坦福官方课程主页:https://web.stanford.edu/class/cs224w 文章目录D…...
学习 Python 之 Pygame 开发魂斗罗(四)
学习 Python 之 Pygame 开发魂斗罗(四)继续编写魂斗罗1. 创建子弹类2. 根据玩家方向和状态设置子弹发射的位置(1). 站立向右发射子弹(2). 站立向左发射子弹(3). 站立朝上发射子弹(4). 蹲下发射子弹(5). 向斜方发射子弹(6). 奔跑时发射子弹(7). 跳跃时发射…...

Linux 基础知识:指令与shell
目录一、操作系统二、指令三、shell一、操作系统 什么是操作系统? 单纯的操作系统应该是指操作系统内核。内核的作用就是管理计算机的软硬件资源,让计算机在合适的时候干合适的事情。 但是有一个问题,并不是人人都会直接通过内核来操作计算机…...
【数通网络交换基础梳理1】二层交换机、以太网帧、MAC地址数据帧转发原理详解
一、网络模型 万年不变,先从模型结构分析,现在大家熟知的网络模型有两种。第一种是,OSI七层模型,第二种是TCP/IP模型。在实际运用中,参考更多的是TCP/IP模型。 OSI七层模型 TCP/IP模型 不需要全部理解,…...
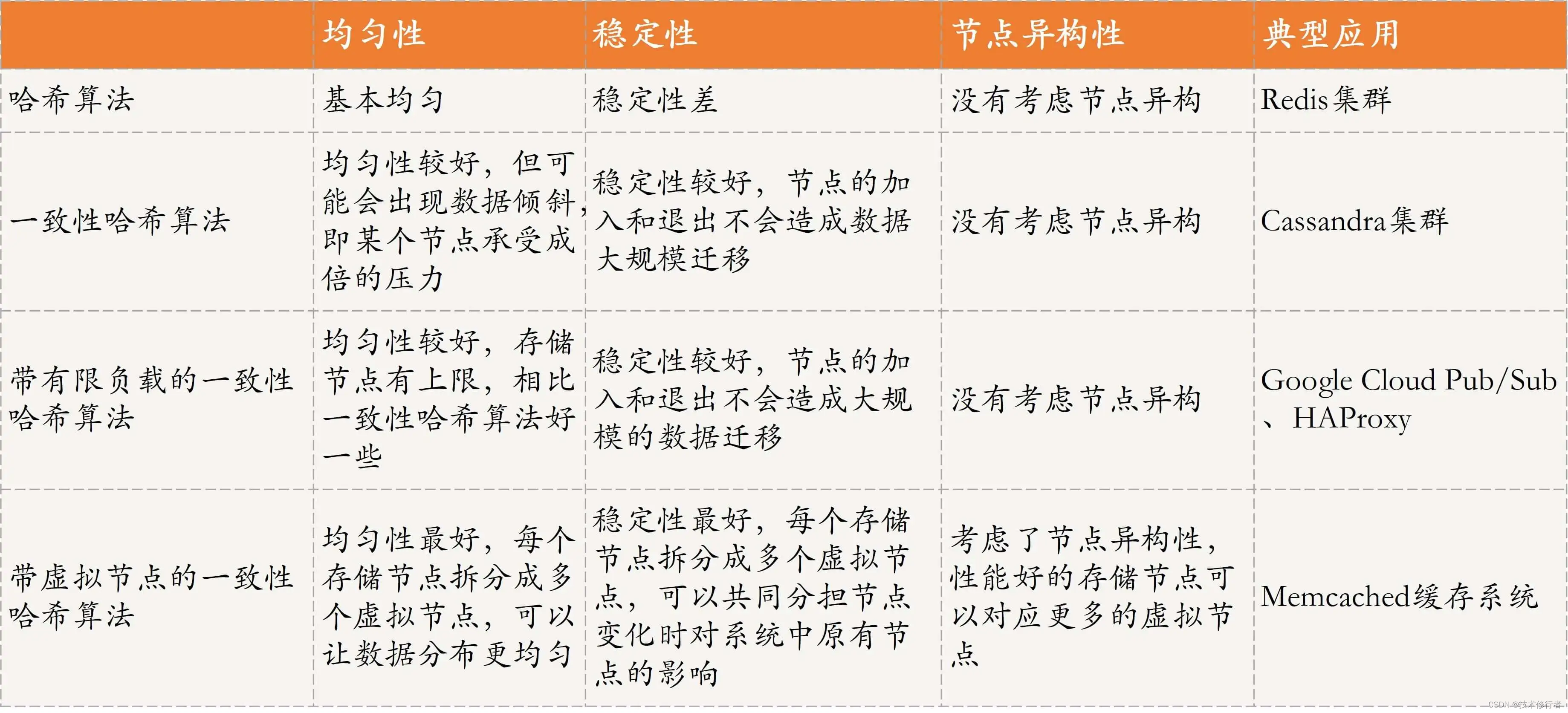
《分布式技术原理与算法解析》学习笔记Day22
哈希与一致性哈希 在分布式系统中,哈希和一致性哈希是数据索引或者数据分布的常见实现方式。 数据分布设计原则 在分布式数据存储系统中,做存储方案选型时,一般会考虑以下因素: 数据均匀数据稳定节点异构性隔离故障域性能稳定…...

[MySQL]MySQL数据类型
文章目录数据类型分类数值类型tinyint类型bit类型float类型decimal类型字符串类型char类型varchar类型char和varchar对比日期和时间类型enum和set类型数据类型分类 MySQL中,支持各种各样的类型,比如表示数值的整型浮点型,文本、二进制类型、…...
利用steam搬砖信息差赚钱,单账号200+,小白也能轻松上手!
现在很多人在做互联网而且也赚到钱了,但还是有很多人赚不到钱,这是为什么? 这里我不得不说一个词叫做赛道,也就是选择,选择大于努力,项目本身大于一切,90%的人都觉得直播带货赚钱,但…...
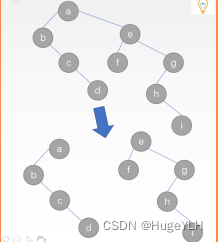
树与二叉树与森林的相关性质
文章目录树的度树的性质二叉树的性质二叉树与森林树的度 树的度指的是树内所有节点的度数的最大值。 节点的度:节点所拥有的子树的数量。简单来说,我们直接数分支即可,例如下图: 在这颗二叉树中,节点2的度为2&#…...

MySQL面试题
文章目录MySQL索引Mysql索引分类InnDB索引与MyISAM索引实现有什么区别一个表中如果没有创建索引,那么还会创建B树么?B树原理B树怎么来的B树 叶子节点和非叶子节点B树能存储多少数据?MySQL索引 Mysql索引分类 mysql 索引分为三类:…...

【蓝桥OJ—C语言】高斯日记、马虎的算式、第39级台阶
文章目录高斯日记马虎的算式第39级台阶总结高斯日记 题目: 大数学家高斯有个好习惯:无论如何都要记日记。 他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210。 后来人们知道&am…...
:dtu数据集介绍及PatchMatchNet中加载数据部分代码解析)
基于深度学习的三维重建网络PatchMatchNet(二):dtu数据集介绍及PatchMatchNet中加载数据部分代码解析
目录 1.dtu数据集介绍 2. PatchMatchNet中数据加载模块详解(dtu_yao_eval.py) 1.dtu数据集介绍 dtu数据集下载地址:dtu...

一文3000字从0到1实现基于requests框架接口自动化测试项目实战(建议收藏)
requests库是一个常用的用于http请求的模块,它使用python语言编写,在当下python系列的接口自动化中应用广泛,本文将带领大家深入学习这个库 Python环境的安装就不在这里赘述了,我们直接开干。 01、requests的安装 windows下执行…...
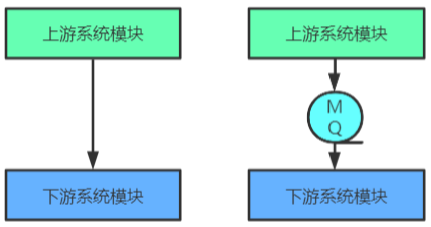
【RockerMQ】001-RockerMQ 概述
【RockerMQ】001-RockerMQ 概述 文章目录【RockerMQ】001-RockerMQ 概述一、MQ 概述1、MQ 简介2、MQ 用途限流削峰异步解耦数据收集3、常见 MQ 产品概述对比4、MQ 常见协议二、RocketMQ 概述1、简介2、发展历史一、MQ 概述 1、MQ 简介 MQ,Message Queue࿰…...

阿里是如何做Code Review的?
作为卓越工程文化的一部分,Code Review其实一直在进行中,只是各团队根据自身情况张驰有度,松紧可能也不一,这里简单梳理一下CR的方法和团队实践。 一、为什么要CR 提前发现缺陷 在CodeReview阶段发现的逻辑错误、业务理解偏差、性…...

内核调试:一次多线程调试与KASAN检测实例
内核调试:一次多线程调试与KASAN检测实例1. 环境说明2. 问题描述3. 问题排查与定位3.1 线程并发问题(减少线程数)3.2 轻量地跟踪对象的分配与释放3.3 检查空指针与潜在修改者3.4 KASAN检查4. 总结博主最近遇到一个非常顽固的多线程BUG&#x…...
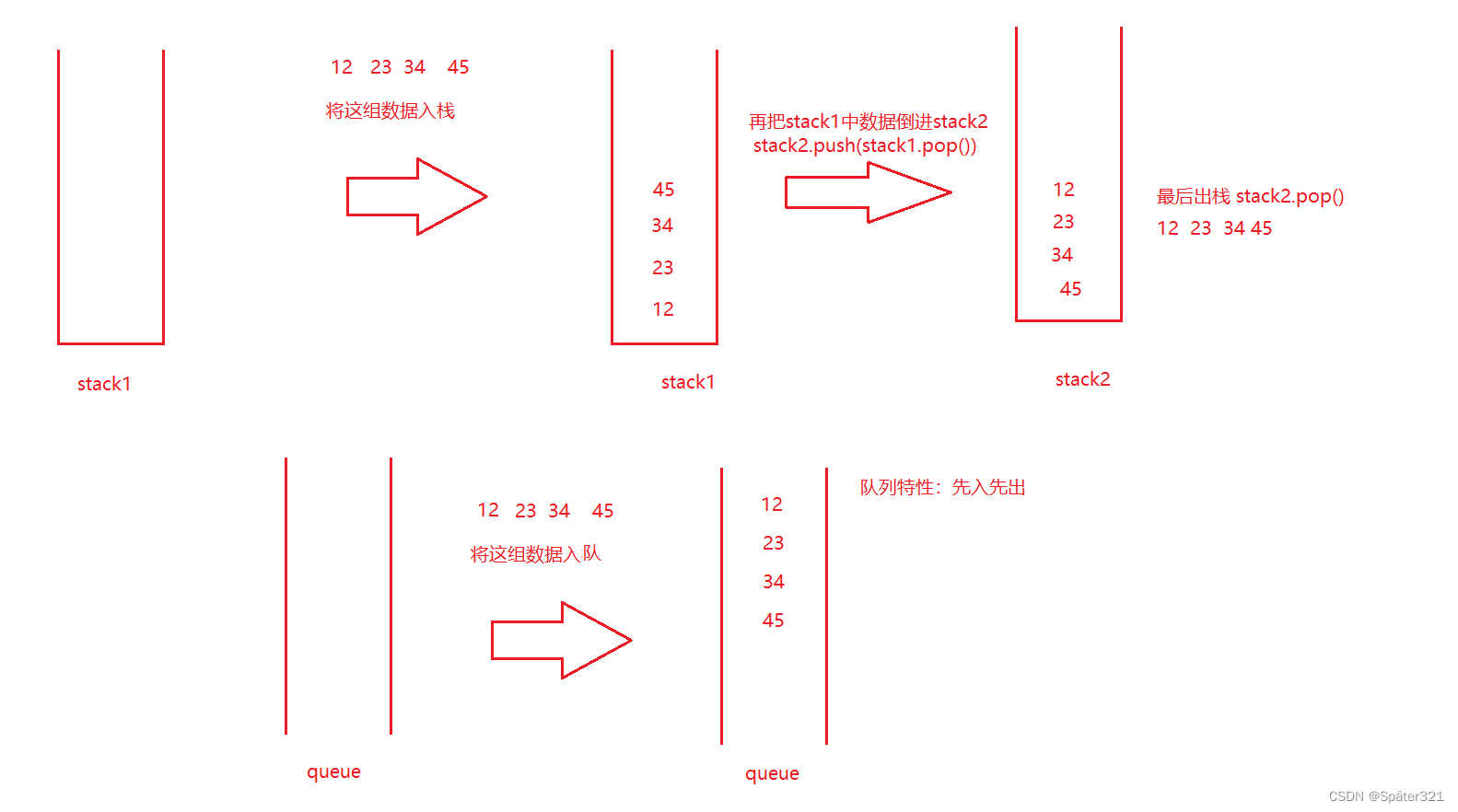
Java - 数据结构,队列
一、什么是队列 普通队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(FirstIn First Out) 入队列:进行插入操作的一端称为队尾(Tail/Rear) 出队列…...
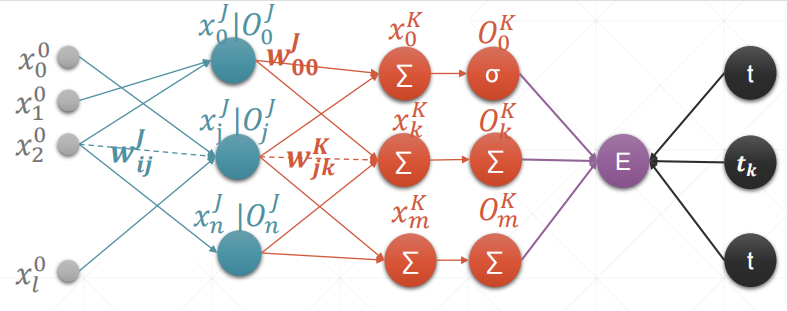
ccc-pytorch-感知机算法(3)
文章目录单一输出感知机多输出感知机MLP反向传播单一输出感知机 内容解释: w001w^1_{00}w001:输入标号1连接标号0(第一层)x00x_0^0x00:第0层的标号为0的值O11O_1^1O11:第一层的标号为0的输出值t:真实…...

LeetCode 225.用队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。实现 MyStack 类:void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元素。int top() …...

【面试】spring控制反转IOC
目录一.说明二.ioc的概念和作用三.优点四.实现机制五.IOC和DI的区别六.设计原则一.说明 1.ioc的概念2.ioc的作用3.ioc的优点4.ioc的实现机制 二.ioc的概念和作用 1.全称Inversion of Control2.控制:创建对象的控制权3.反转:以前对象是程序员主动去new…...

Spring 事务管理详解及使用
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
)
手把手教你:用SuperMap iServer发布3D Tiles服务,并在Cesium中加载(附完整代码)
从S3MB到3D Tiles:SuperMap iServer三维服务发布与Cesium集成实战指南 三维地理信息系统(3D GIS)正在重塑我们对空间数据的理解和交互方式。想象一下,你手中有一批精美的建筑模型或地形数据,如何让它们在网页上流畅展示…...

从Cityscapes到遥感图像:用MMSegmentation v1.0.0搞定不同领域语义分割数据集的完整配置流程
跨领域语义分割实战:MMSegmentation多场景数据集配置全解析 当计算机视觉工程师需要将语义分割技术从自动驾驶领域迁移到遥感图像分析时,最常遇到的障碍不是模型架构的选择,而是数据集的适配难题。不同领域的图像在分辨率、类别分布、标注格式…...
如何彻底解决TranslucentTB的Microsoft.VCLibs依赖缺失问题:3步诊断与修复指南
如何彻底解决TranslucentTB的Microsoft.VCLibs依赖缺失问题:3步诊断与修复指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB …...

OpenHarmony FA启动机制全解析:从本地到远程的分布式能力实现
1. 项目概述:从“点击图标”到“界面呈现”的旅程当我们谈论一个应用在OpenHarmony上的启动,尤其是FA(Feature Ability,特性能力)的启动时,很多人脑海里浮现的可能是“用户点击图标,然后应用打开…...

DownKyi终极指南:B站视频下载与管理的完整专业解决方案
DownKyi终极指南:B站视频下载与管理的完整专业解决方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

ArcGIS点符号压盖标注看不清?试试‘合并图层+制图表达’这个组合拳
ArcGIS点符号压盖标注看不清?试试‘合并图层制图表达’这个组合拳 在GIS制图工作中,点位数据密集区域的标注压盖问题堪称"地图美学杀手"。想象一下这样的场景:某村庄同时存在水文站、水位站和雨量站三个监测点,由于地理…...

技术分享 | 彻底解决图片“躺平”问题:Java 后端强制校准图片方向
在日常开发中,你是否遇到过这样的情况:前端上传了一张手机拍摄的照片,预览时明明是正的,存入服务器后却莫名其妙地“躺平”了,或者逆时针旋转了 90 度?以下方案用于强制旋转图片这通常是因为 JPEG 图片的 E…...

魔百盒CM311-1s刷机后体验:安卓9.0固件到底香不香?附5621DS无线实测
魔百盒CM311-1s刷机实战:安卓9.0系统深度评测与无线性能揭秘 当手中的魔百盒CM311-1s遇上安卓9.0系统,这场硬件与软件的碰撞会擦出怎样的火花?作为一款搭载S905L3B芯片的电视盒子,其原生系统往往受限于运营商定制化限制࿰…...

硬件知识 allegro16.6 3D 模型导入与其问题笔记
1. 嘉立创获取3D 模型(注意:网页版不行,需要现在专业版) 2. freecad 去去除 PCB 的封装。(这个过程可能额会导致 出现一个文件里面有两个相同的元器件,需要删掉一个,自己检查) 3. …...
的设计思路复用)
从游戏UI到工业HMI:聊聊Qt自定义控件(仪表盘、雷达、摇杆)的设计思路复用
从游戏UI到工业HMI:Qt自定义控件的跨领域设计思维 在数字界面设计领域,游戏UI与工业HMI看似分属两个极端——前者追求炫酷动效与沉浸体验,后者强调信息清晰与操作可靠。但当我们拆解那些优秀的仪表盘、雷达扫描和交互摇杆控件时,会…...