Kafka存取原理与实现分析,打破面试难关
系列文章目录
上手第一关,手把手教你安装kafka与可视化工具kafka-eagle
Kafka是什么,以及如何使用SpringBoot对接Kafka
架构必备能力——kafka的选型对比及应用场景
Kafka存取原理与实现分析,打破面试难关
- 系列文章目录
- 一、主题与分区
- 1. 模型
- 2. 消息与分发
- 二、分区内数据的存储
- 1. 消息的存储
- ① 偏移量与日志文件
- ② 索引的构成
- 2. 消息的读取
- ① 消费偏移量的存储
- ②Compaction策略
- ③查找并读取消息
- 3. 快速存取实现
- 总结

在前面的几篇内容中,我们依次讲了Kafka的安装、与Spring Boot的结合,还有选型与应用场景。但是笔者也知道,对于很多小伙伴来说,原理及实现才算重头戏,而且也是面试热点,那么本次我们先来进行存取原理的分析,当然抱着疑问去学习才是最快的,因此在开始之前,我也先抛出一些Kafka的重点与热点问题,希望大家在学习过程中能总结印证
- Kafka为什么吞吐量这么高?
- Kafka的数据存与取有什么特点?
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 kafka 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis dubbo docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、主题与分区
1. 模型
我们其实在《架构必备能力——kafka的选型对比及应用场景》 一文中其实讲到了Kafka的模型,我们这里再把老图拿出来用一遍
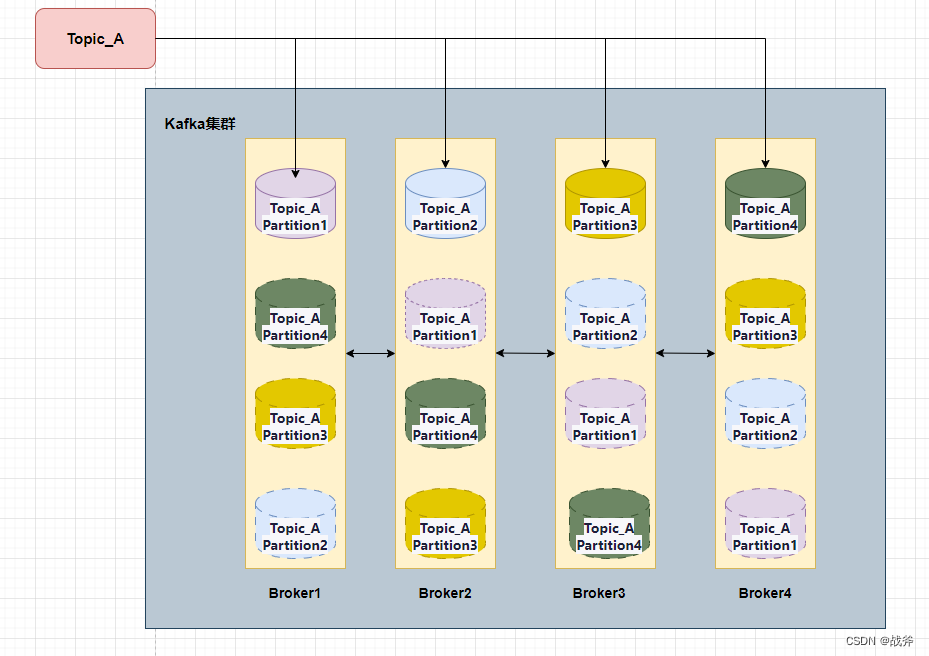
不难看出,逻辑上的源头就是主题,也即Topic,而主题又划分为多个分区。我们先来谈谈主题与分区的实现,在Kafka中,可以使用以下命令来声明一个主题并指定分区:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 4 --topic my-topic
其中:
–create: 声明一个新的主题。
–zookeeper: 指定 ZooKeeper 的地址和端口号。
–replication-factor: 指定副本因子,即每个分区在集群中的副本数量。这里指定为1,表示每个分区只有一个副本。
–partitions: 指定分区数。这里指定为4,表示该主题有4个分区。
–topic: 指定主题名称,这里为 my-topic。
注意:如果要指定分区数量,必须在创建主题的时候指定,之后无法更改。因此,在创建主题时应该仔细考虑分区数量,以满足业务需求。
当然,如果有同学还记得前面的内容,应该知道我们在对接Spring Boot时,并没有提前建立主题而是直接使用了。其中的原因是,我们在Spring Boot中使用Kafka,如果在发送消息时指定的主题不存在,Kafka会自动创建该主题。在创建时,Kafka将使用默认的分区数量(通常为1),以及默认的副本因子(通常为1)来创建分区。
2. 消息与分发
然后当我们发布者向某个主题发送消息时,其就会被“分发”到某一个分区里
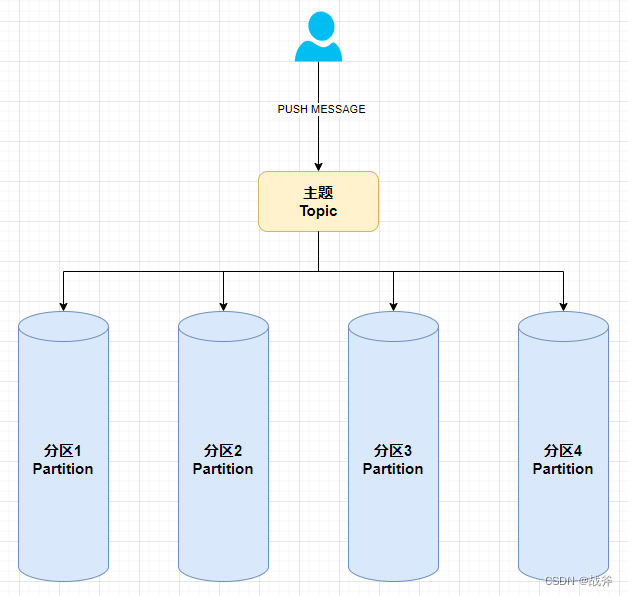
那么有小伙伴肯定会问:
Kafka的主题消息会进哪个分区是我们可以决定的吗?默认是进入哪个分区?
答案是Kafka的主题消息可以由生产者自己决定要发送到哪个分区,也可以使用Kafka提供的默认分区分配算法来自动决定消息要进入哪个分区。
-
指定分区:如果生产者自己决定要发送到哪个分区,可以在发送消息时指定消息要发送到的分区编号。此时,如果指定的分区编号存在,则消息会被发送到该分区;如果指定的分区编号不存在,则会抛出异常。
-
自动分区:如果使用默认的分区分配算法,Kafka提供了多种分配算法,例如
轮询(Round-Robin)、随机(Random)、哈希(Hash)等。默认情况下,Kafka使用哈希算法将消息均匀地分配到所有可用的分区中
当然在此之前,我们可以看下KafkaTemplate前面提供的API
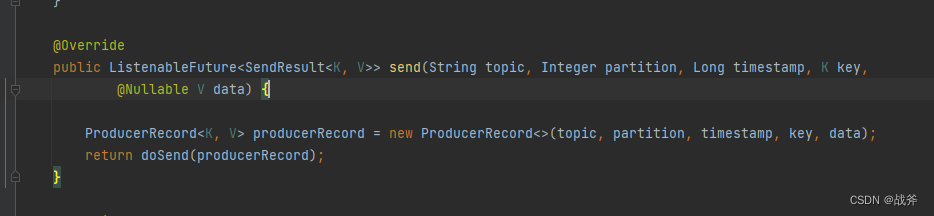
不难知道Kafka消息除了指明主题以外,还由以下要素组成:
- 消息的key:是一个可选项,用于标识消息的唯一性和分区。如果不指定key,则会随机分配一个key,并将消息发送到随机的分区。
- 消息的value:是消息的实际内容,也是必填项。
- 消息的时间戳:是可选项,用于标识消息的时间戳。Kafka可以根据时间戳来处理消息的顺序、分配和延迟。
- 消息的分区:指定消息应该发送到哪个分区。如果不指定分区,则使用默认的分区器来决定分区。
二、分区内数据的存储
从逻辑上来说,kafka的分区是一个消息队列,当我们发送的消息经由分区器进行分发后,就会进入某个分区并被顺序的保存下来。在实现上,Kafka的分区更像一个日志记录系统,把消息当作日志,顺序的写入磁盘
1. 消息的存储
我们需要知道,Kafka中,每个分区被组织为一组日志段(Log Segment),其中每个日志段都包含了一个连续的消息序列。当一个日志段被写满后,它将被关闭并分配一个更高的编号,新的消息将被追加到一个新的日志段中。而日志段的核心又由两个部分组成:索引文件(index file)和数据文件(data file)
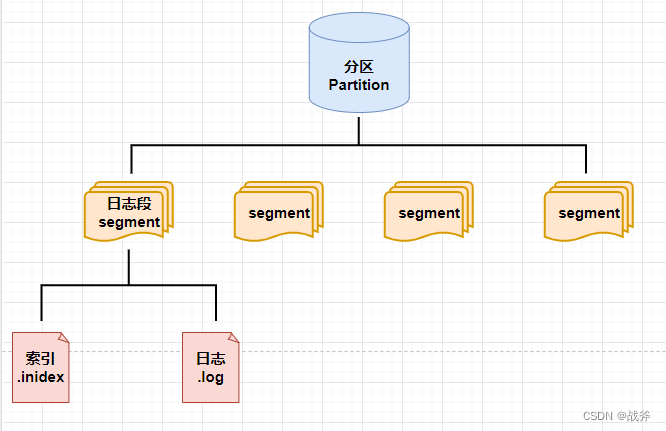
-
数据文件: 也叫日志文件,数据文件是消息分区的核心部分,它是以追加方式写入的文件。当有新的消息写入分区时,Kafka会根据协议、消息头、消息体等信息将消息封装成字节流,然后追加写入数据文件。
-
索引文件: 索引文件是一个不可变的有序映射,它将消息偏移量映射到数据文件中的位置。当一个消费者读取一个分区的消息时,它会使用
偏移量读取索引文件中的位置,并从该位置读取数据文件中的消息。
如下图,就是我们上期发送了一条消息,而建立的目录test_topic-0,代表该目录是test_topic主题下的 0 号分区,可以看到里面的 index文件 和 log 文件
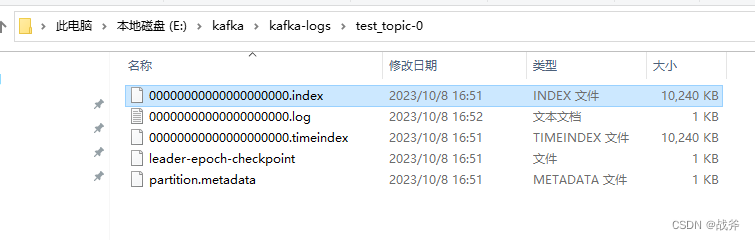
① 偏移量与日志文件
要想更深入的了解,我们必须先解释一下kafka中消息偏移量(offset) 的概念:当一条记录需要写入分区的时候,它会被追加到 log 文件的末尾,同时会被分配一个唯一的序号,称为 Offset(偏移量)。Offset 是一个递增的、不可变的数字,由 Kafka 自动维护。需要注意的是,在后续内容中,我们还会提到各种不同的偏移量,请注意区分,不要混淆了
由于Offset 初始值为 0,所以当第一条消息达到分区后,就会建立起 00000000000000000000.log 这样的文件来进行消息的存储,后续消息将会在这个文件内追加写入,直到文件大小超出限制(其默认值为1GB)
举个例子,当第170411个消息(Offset = 170410)来到时,发现 00000000000000000000.log 已经超过了 1 G,此时其就会新创建一个日志段,同时以本offset为名,新建一个日志文件,命名为 0000000000000170410.log,此时本分区就形成了两个日志段,情况如下:
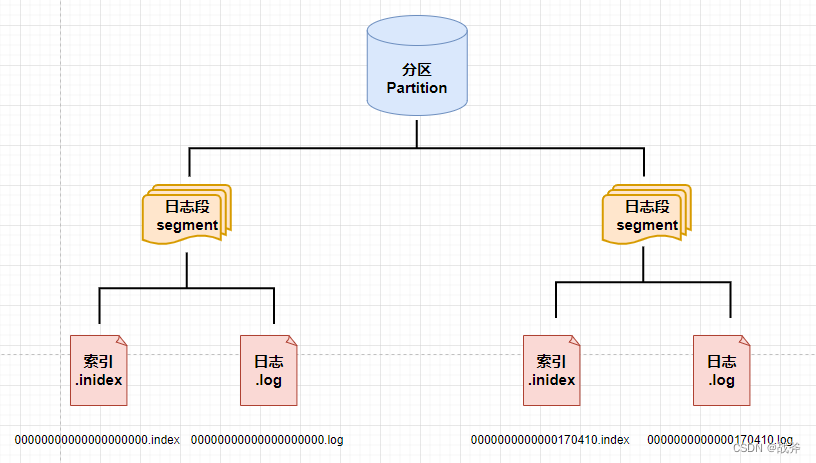
② 索引的构成
我们上面讲了 .log 文件,也即数据文件的创建机制。但是还没讲段的另一个组成部分,也即索引文件。索引其实就像字典的目录,是帮助大家快速找到某条消息的工具,索引文件存储的内容主要就是 消息偏移量(offset) 与 消息存储地址(position) 的映射关系。
Kafka的索引文件由多个索引条目(index entry)组成,每个索引条目包含两个核心字段:
- offset:消息的偏移量(这里是相对偏移量,每个索引文件都以0起始,其对应的真实偏移量为段初始偏移 + 本offset);
- position:消息在日志文件中的磁盘位置(相对偏移量,偏移量仅适用于对应的日志文件)
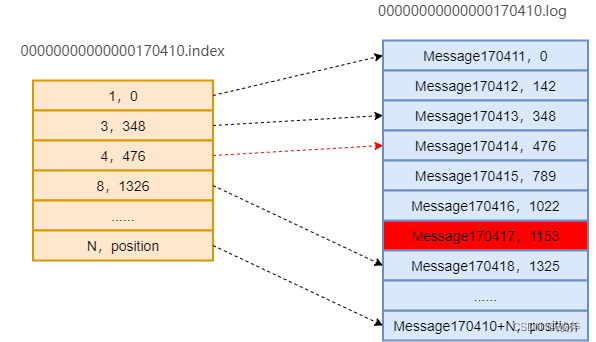
需要注意的是,不是每一条消息都会有索引。这里有参数 index.interval.bytes 的控制,其默认值为 4 KB,即表示当前分区 log 文件写入了 4 KB 数据后才会在索引文件中增加一个索引条目
2. 消息的读取
现在我们已经存储了一些数据,下面就要开始读取了,我们目前掌握了这些文件,那么怎么才能找到并读取消息呢?
① 消费偏移量的存储
我们不难理解,每个消费者负责需要消费分配给它的分区上的消息,并记录自己在每个分区上消费的最新偏移量。对于消费者而言,怎么知道自己应该要消费哪个offset的消息?消费者可以通过以下两种方式记录消费的偏移量:
-
手动提交偏移量:消费者在消费消息时,可以手动调用 consumer.commitSync() 或 consumer.commitAsync() 方法将消费的偏移量提交到 Kafka 中。该方法接收的参数表示要提交的偏移量的值,提交后,Kafka 会将该偏移量记录到内部的偏移量管理器中。
-
自动同步提交偏移量:消费者可以将 enable.auto.commit 参数设置为 true,开启自动提交偏移量的功能。启用该功能后,Kafka 会自动记录消费者消费过的最新偏移量,并定期将其定期提交到 Kafka 中。
但不管怎么样,这个消费的偏移量最终都是由kafka来进行保存的,那么其具体的存储是怎么实现的呢?Kafka其实提供了将给定消费者组的所有偏移存储在一个叫做组协调器(group coordinator)的组件。

通过官方文档不难看出,当组协调器收到偏移量变动的请求时,会将对应数据存储在内置的主题 __consumer_offsets 中(在旧版本中偏移量是存在ZK中的),我们可以在ZK中看到这个主题的情况:
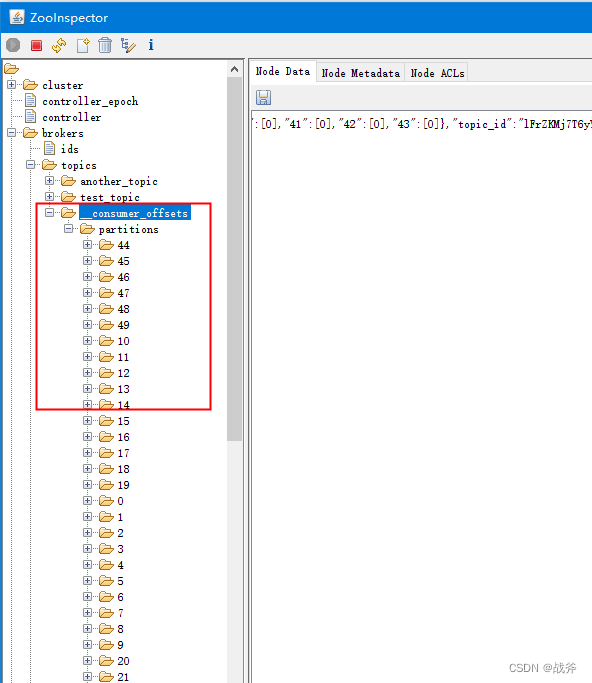
在我们的本地目录中也能看到这个 __consumer_offsets 主题一共建了50个分区(默认):
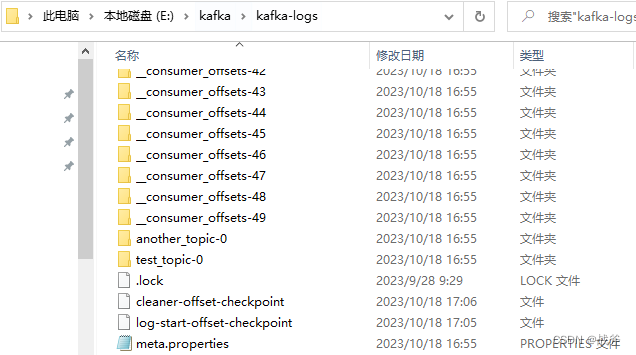
当然它分区的个数,可以在Kafka服务器配置文件中通过参数offsets.topic.num.partitions 进行配置。
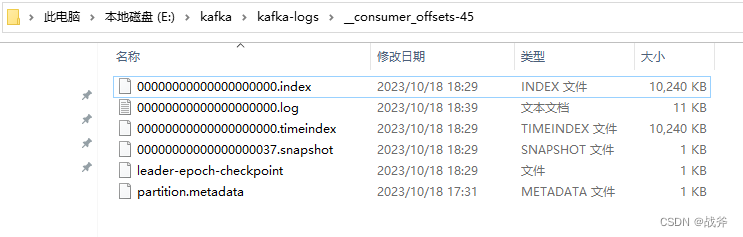
当我们以某个消费者组消费掉某条消息并提交偏移量后,偏移量会被提交到 __consumer_offsets Topic的一个特定分区,该分区由所消费的主题和消费者组的哈希值决定。在我的例子里,是被提交到了 __consumer_offsets-45,如下:
②Compaction策略
相信你会对这种存储消费位置的方式有所困惑,因为按照我们前面的说法,Kafka的内容都是以日志形式存储的,在使用的过程中,日志岂不是会越来越大?到最后找一次偏移量都很麻烦?这就不得不提到Kafka中的Compaction策略
compaction是一种保留最后N个版本的消息的消息清理策略,它保留特定键的最新值,同时删除无用的键值,从而减少存储空间。具体来说,Compaction会保留每个消息主题中最新的一组键值对,并删除所有键相同但值较旧的消息。
使用Compaction策略需要满足以下条件:
- 消息的键必须是唯一的
- 消息的键必须是可序列化的
- 消息必须按照键进行划分
- 消息的存储时间必须足够长,以便新消息可以替换旧消息
而这些消费偏移量的数据,存储的内容如下
key = group.id+topic+分区号
value= offset 的值
这样就导致某个消费组在某个分区的消费数据只会有一条,所以找起来并没有那么复杂
③查找并读取消息
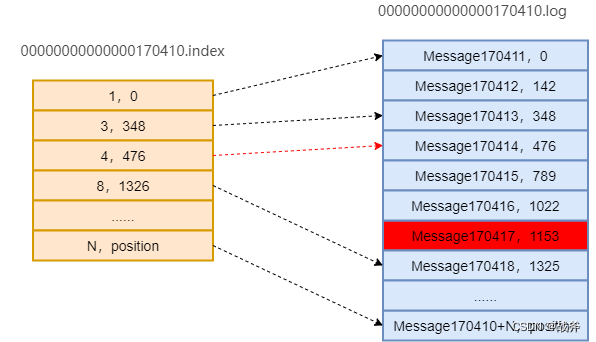
上面我们讲了消费偏移量的存储,其实查找偏移量的过程也是一样的,同一个消费组会先从特定的 __consumer_offsets 拿取偏移量,拿到偏移量以后,比如偏移量是 170417,我们仍以上面的文件情况为例,那么它找到消息的逻辑如下:
-
首先用二分查找确定它是在哪个Segment文件中,其中0000000000000000000.index为最开始的文件,第二个文件为0000000000000170410.index(起始偏移为170410+1 = 170411),而第三个文件为0000000000000239430.index(起始偏移为239430+1 = 239431)。所以这个offset = 170417就落在第二个文件中。其他后续文件可以依此类推,以起始偏移量命名并排列这些文件,然后根据二分查找法就可以快速定位到具体文件位置。
-
用该offset减去索引文件的编号,即170417 - 170410 = 7,也用二分查找法找到索引文件中等于或者小于7的最大的那个编号。可以看出我们能够找到[4,476]这组数据,476即offset=170410 + 4 = 170414的消息在log文件中的偏移量。
-
打开数据文件(0000000000000170410.log),从位置为476的那个地方开始顺序扫描直到找到offset为170417的那条Message。
总结来说:就是通过二分法先找到index文件,然后再在index文件中通过二分法找到某一条索引条目,然后根据该索引条目给出的地址去log文件中快速定位,最后从这个定位开始,顺序扫描下去直到找到我们指定的偏移量数据
3. 快速存取实现
我们上面讲了Kafka的一大堆的奇特设计,不知道小伙伴们是否产生过疑问,比如为什么一个主题要分成多个分区 ?一个分区为什么要划成多个段?以及为什么把数据存储成日志格式 ? 其实这些都是在优化性能,我们从快速存取的角度讲一下Kafka都做了哪些努力【面试重点】:
-
多分区负载均衡:Kafka支持将一个主题的数据分散至多个分区,不同分区位于多个broker节点上,实现了集群负载均衡,从而提高了写入和读取的性能。
-
分段存储:Kafka会将数据分段存储,每个段的大小和时间可以根据需求进行配置,这样可以提高读取性能并减少删除操作对IO的影响。
-
批量写入:Kafka允许客户端一次性写入多条消息到broker,减少了网络传输的时间。
-
零拷贝:Kafka使用
mmap映射磁盘上的文件到虚拟内存空间,然后通过直接内存访问(Direct Memory Access)的方式将数据从磁盘读取到内存中,还使用sendfile系统调用来实现网络发送时的零拷贝,这样网络数据也可以直接从内核空间中发送,避免了数据拷贝到用户空间的过程。 -
异步刷盘:Kafka支持异步刷盘,即将消息写入日志后,不会立即将数据从内存刷入磁盘,而是会缓存一段时间再批量写入磁盘,减少了磁盘I/O的次数,提高了写入性能。
-
稀疏索引:Kafka会为每个段维护一个索引,以便在读取数据时快速定位到所需数据的位置。这样可以避免全盘扫描,提高数据读取性能。但如果每个消息都写进索引,会导致索引文件臃肿,且降低存储速度,所以采用了稀疏索引的方式
如果你按照《Kafka是什么,以及如何使用SpringBoot对接Kafka》中的动手操作过,我们可以继续来做个实现,我们先看一下log文件,如下
然后我们把发送的代码改成如下,这样一次发送1000条消息,注意,我们在这里还加上了 kafkaTemplate.flush(),因为当使用Kafka Template发送消息时,消息并不会立即发送到Kafka Broker,而是会被缓存在Kafka Template中,以减少通信次数,如果我们需要立即发送,这时候就可以使用kafkaTemplate.flush()方法来实现立即发送。
@Service
public class KafkaService {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String message) {for (int i = 0; i < 1000; i++) {kafkaTemplate.send("another_topic2", 0,"key",message + i);}kafkaTemplate.flush();System.out.println("we have send message");}
}
但当我们发送消息,成功输出 we have send message ,并又成功接收到消息后,如图
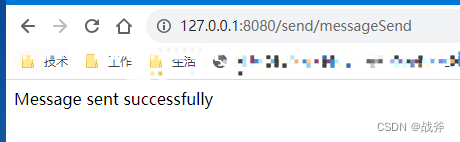
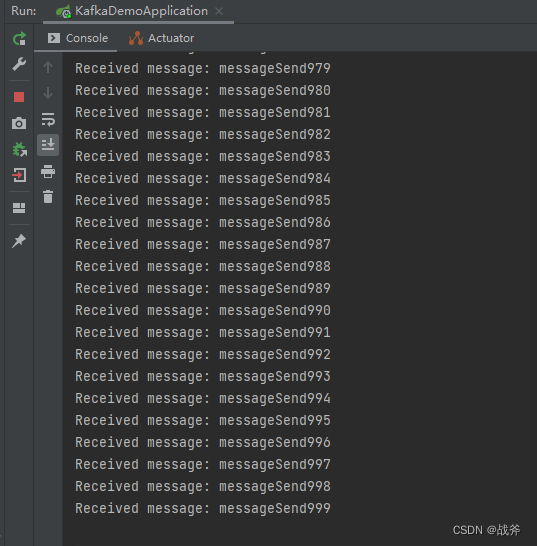
我们却会看到 log 文件的大小没有发生变化,即便是不停的刷新目录也无济于事
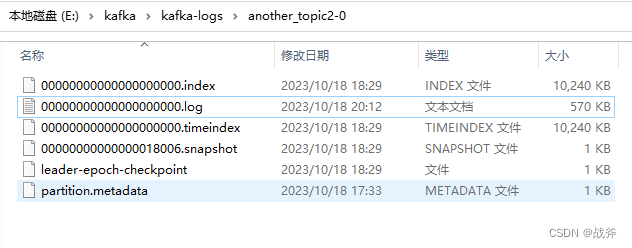
然而如果我们单击并右键选中该文件,就会看到该文件被更新,且大小发生变动
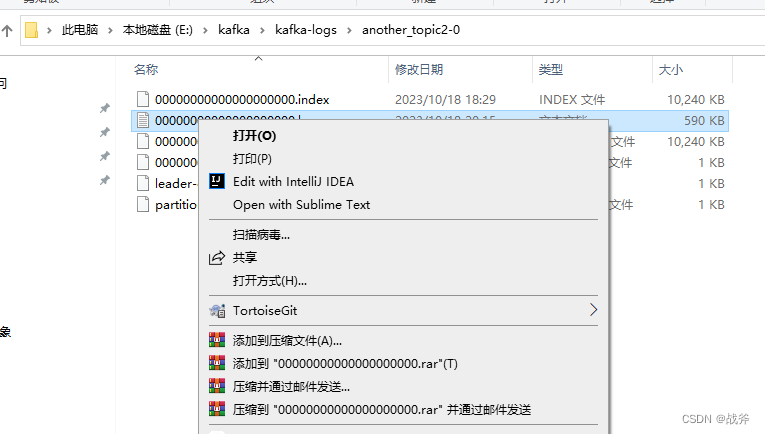
这就说明了其写入硬盘的过程是异步且有延迟的,使用了操作系统的延迟写入(delayed write)机制。但其传输数据却可以脱离硬盘,使用内存缓存作为收发介质,直接实现传达
总结
今天我们详细讲解了消息在kafak中的存与取,也介绍了不少细节点,知道了Kafka采用批量传输设计减少网络访问次数,然后用分区、分段、追加日志等方案来提高吞吐量,并且利用了操作系统的零拷贝、异步刷盘等方式来减少磁盘写入的瓶颈,最终成为了一款性能优异、吞吐量极大的中间件。希望通过今天的学习,能对大家有所帮助,我们将在后面继续讲解kafka的其他实现细节。如果你对此有兴趣,可以直接订阅本 kafka 专栏
相关文章:
Kafka存取原理与实现分析,打破面试难关
系列文章目录 上手第一关,手把手教你安装kafka与可视化工具kafka-eagle Kafka是什么,以及如何使用SpringBoot对接Kafka 架构必备能力——kafka的选型对比及应用场景 Kafka存取原理与实现分析,打破面试难关 系列文章目录一、主题与分区1. 模型…...

JavaWeb——IDEA相关配置(Tomcat安装)
3、Tomcat 3.1、Tomcat安装 可以在国内一些镜像网站中下载Tomcat,同样也可以在[Tomcat官网](Apache Tomcat - Welcome!)下载 3.2、Tomcat启动和配置 一些文件夹的说明 启动,关闭Tomcat 启动:Tomcat文件夹→bin→startup.bat 关闭&#…...

MySQL:BETWEEN AND操作符的边界
文档原文: expr BETWEEN min AND maxIf expr is greater than or equal to min and expr is less than or equal to max, BETWEEN returns 1, otherwise it returns 0. This is equivalent to the expression (min < expr AND expr < max) if all the argume…...

无人机UAV目标检测与跟踪(代码+数据)
前言 近年来,随着无人机的自主性、灵活性和广泛的应用领域,它们在广泛的消费通讯和网络领域迅速发展。无人机应用提供了可能的民用和公共领域应用,其中可以使用单个或多个无人机。与此同时,我们也需要意识到无人机侵入对空域安全…...
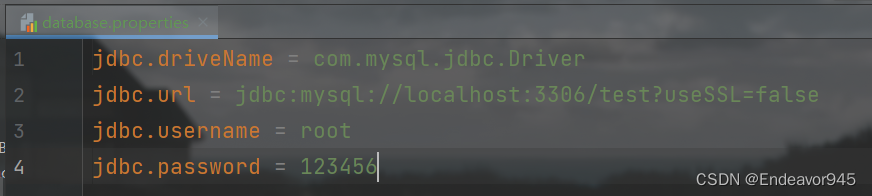
Spring中配置文件参数化
目录 一、什么是配置文件参数化 二、配置文件参数化的开发步骤 一、什么是配置文件参数化 配置文件参数化就是将Spring中经常需要修改的字符串信息,转移到一个更小的配置文件中。那么为什么要进行配置文件参数化呢?我们看一个代码 <bean id"co…...
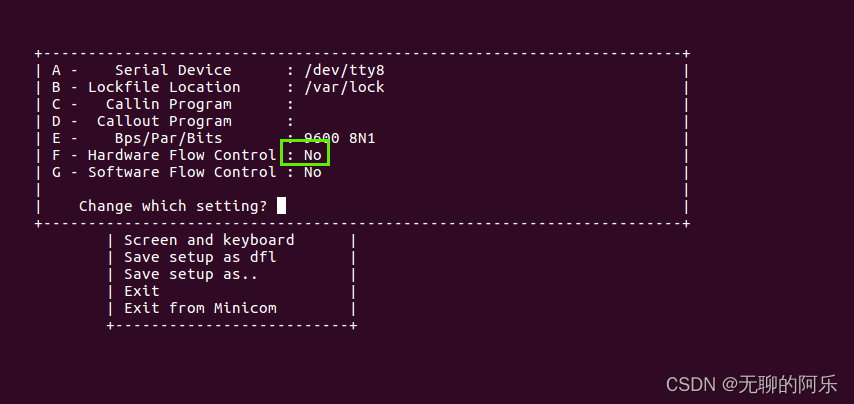
linux minicom 调试串口
1、使用方法 1. 打开终端 2. 输入命令:minicom -D /dev/ttyS0 3. 按下回车键,进入minicom终端界面 4. 在终端界面中发送指令或数据,查看设备返回的数据 5. 按下CtrlA,松开释放,再按下X,退出minicom2、一些…...

#力扣:2651. 计算列车到站时间@FDDLC
2651. 计算列车到站时间 - 力扣(LeetCode) 一、Java class Solution {public int findDelayedArrivalTime(int arrivalTime, int delayedTime) {return (arrivalTimedelayedTime)%24;} }...
小县城蔬菜配送小程序制作全攻略
随着互联网的普及和人们对生活品质要求的提高,越来越多的小县城开始开发蔬菜配送小程序,以满足当地居民对新鲜蔬菜的需求。制作一个小县城蔬菜配送小程序,需要经过以下步骤: 步骤一:登录乔拓云平台 首先,打…...

JavaPTA练习题 7-4 计算给定两数之间的所有奇数之和
本题目要求接收输入的2个整数a和b,然后输出a~b之间的所有奇数之和。 输入格式: 分别用两行输入两个整数a,b 输出格式: 输出a~b之间的所有奇数之和 输入样例: 在这里给出一组输入。例如: 1 30输出样例: 在这里给出相应的输出。例如: …...
基于SSM的大学校医管理系统
基于SSM的大学校医管理系统、学校医院管理系统的设计与实现~ 开发语言:Java数据库:MySQL技术:SpringSpringMVCMyBatisVue工具:IDEA/Ecilpse、Navicat、Maven 系统展示 主页 登录系统 用户界面 管理员界面 摘要 大学校医管理系统…...

【递归、搜索与回溯算法】第一节.初识递归、搜索与回溯算法
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:递归、搜索与回溯算法 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!&am…...

第十二届蓝桥杯模拟赛第一期
A填空题 问题描述 如果整数a是整数b的整数倍,则称b是a的约数。 请问,有多少个正整数是2020的约数。 答案提交 这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数࿰…...

【生成对抗网络】
生成对抗网络(Generative Adversarial Networks,简称GANs)是深度学习领域的一种创新结构,由Ian Goodfellow在2014年首次提出。GANs包括两个深度神经网络——一个生成器和一个判别器,它们通常以对抗的方式进行训练。 以…...

Redis性能滑坡:哈希表碰撞的不速之客【redis第二部分】
Redis性能滑坡:哈希表碰撞的不速之客 前言第一部分:Redis哈希表简介第二部分:哈希表冲突原因第三部分:Redis哈希函数第四部分:哈希表冲突的性能影响第五部分:解决冲突策略第六部分:redis是如何解…...

科技与教育的盛宴——探讨监控易在82届教装展的新机遇
在第82届中国教育装备展示会这个融合了科技与教育的盛宴上,监控易将展现其最新的教育信息化解决方案和技术创新成果。这不仅是一次产品的展示,更是一次理念、技术与需求的交流和碰撞。在这里,我们将一同探讨在科技日新月异的今天,…...
Bazzite:专为 Steam Deck 和 PC 上的 Linux 游戏打造的发行版
导读对于一个专为 Linux 游戏定制的发行版,你是否感兴趣呢?如果答案是肯定的,那么我们为你准备了绝佳选择。 Bazzite 是一个新推出的基于 Fedora 的发行版,它是为 Linux 桌面上的游戏,以及越来越火热的 Steam Deck 定…...

【MySQL】数据库数据类型
文章目录 1. 整体概要2. 数值类型(有符号) tinyint 创建表(无符号) tinyint 创建表bit类型float 类型(无符号)floatdecimal 3. 二进制类型char类型varchar类型 4. 日期时间日期时间类型 5. string 类型enum类型和set类型enum类型和set类型的查找在枚举中的查找在set中的查找 1.…...

计算机组成原理 new07 真值和机器数 无符号整数 定点整数 定点小数 $\color{red}{Δ}$
文章目录 真值和机器数 无符号整数无符号整数的定义无符号整数的特征无符号整数的表示范围无符号整数的加法无符号数的减法 有符号整数(定点整数)有符号整数的定义原码原码的特点反码反码的特点补码补码的特点快速求解n位负数补码的方法为什么补码能够多表示一个范围(重点)变形…...
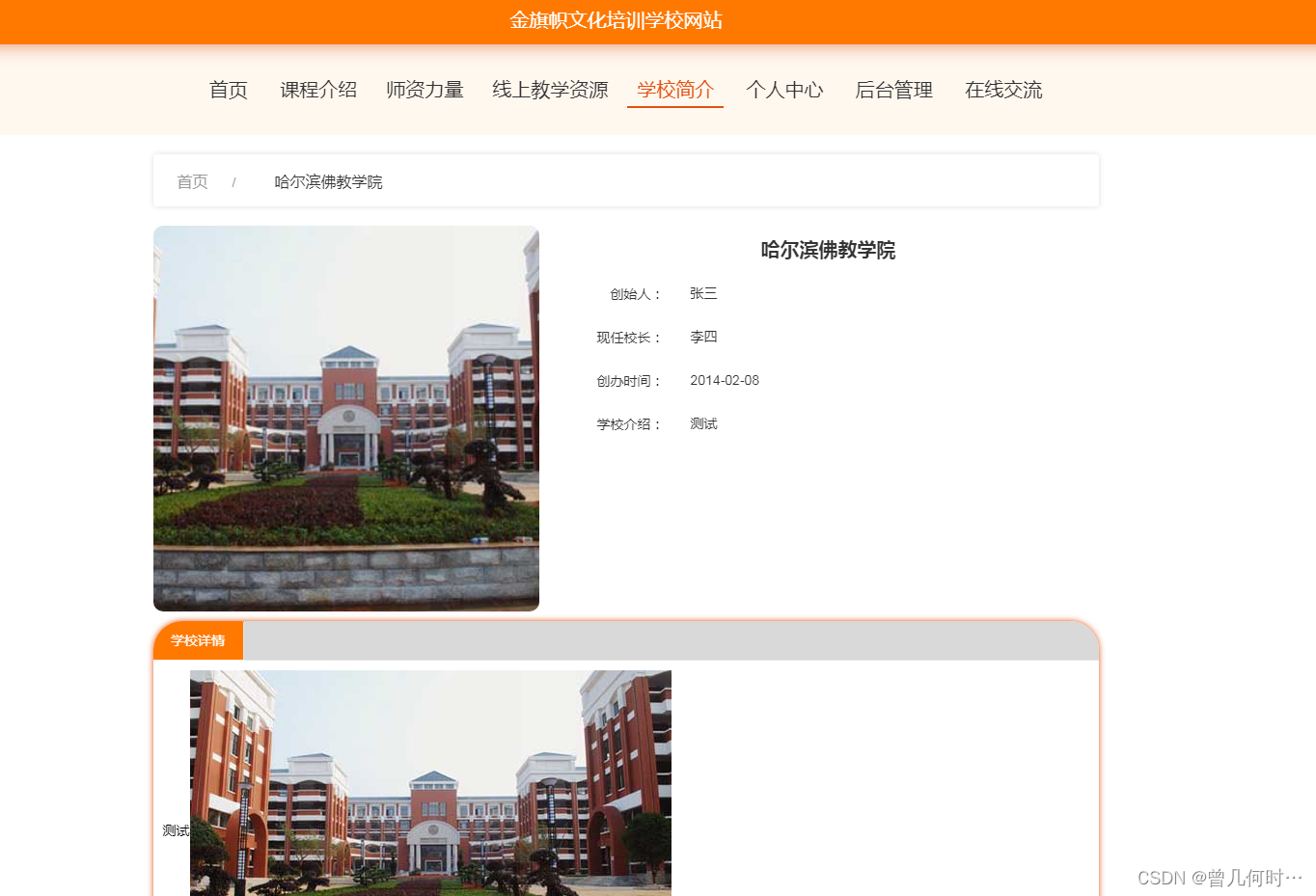
基于SSM的文化培训学校网站的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

gitee-git使用
克隆gitee某代码仓库某分支流程 1.克隆远程gitee仓库某分支到本地 2.如果克隆gitee仓库是私有的系统会弹出弹框让你输入gitee的账户和密码 3.克隆远程分支完成 git所需命令 克隆远程仓库到本地 git clone 仓库URLgit克隆远程分支到本地 git clone -b 分支名 仓库URLgit 拉…...

本体论不知道在哪用?怎么用?一篇说清楚
有读者问:这个东西到底在什么情况下最有用?我手头的项目值不值得用?今天就来回答这个问题。我把本体论真正派得上用场的场景归纳成六种典型情况,每个都配了具体例子,你可以对照着看看自己遇到的是不是这类问题。场景一…...

如何在Windows上实现原生Btrfs支持:专业级跨平台文件系统解决方案终极指南
如何在Windows上实现原生Btrfs支持:专业级跨平台文件系统解决方案终极指南 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs WinBtrfs是一款革命性的Windows平台原生Btrfs文件…...
Y形动态Transformer:解码红外与可见光图像融合的全局与局部协同之道
1. 当红外遇见可见光:为什么我们需要图像融合? 想象一下,你正在夜间驾驶,车载摄像头捕捉到的红外图像能清晰显示行人轮廓却丢失了环境细节,而可见光图像恰好相反——这就是多模态图像融合要解决的核心问题。在安防监控…...

BabelDOC:如何解决专业PDF文档翻译中的格式丢失难题
BabelDOC:如何解决专业PDF文档翻译中的格式丢失难题 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 在全球化协作日益频繁的今天,你是否曾为翻译技术文档、学术论文或研…...

nli-MiniLM2-L6-H768实战教程:将NLI打分嵌入CI/CD流程实现文档更新语义回归测试
nli-MiniLM2-L6-H768实战教程:将NLI打分嵌入CI/CD流程实现文档更新语义回归测试 1. 模型介绍 nli-MiniLM2-L6-H768是一个轻量级的自然语言推理(NLI)模型,专注于文本对关系判断。与生成式模型不同,它的核心能力是评估两段文本之间的语义关系…...

GD32替代STM32,除了改时钟和Boot0,你的延时函数和功耗测试做了吗?
GD32替代STM32的深度调优指南:从基础移植到性能优化 当开发者从STM32转向GD32时,往往只关注了最基础的时钟配置和Boot0设置,却忽略了那些真正影响系统稳定性和性能的关键细节。本文将带你深入GD32的底层特性,解决那些"代码能…...

有哪些开源免费的pdf编辑器
根据截至2026年4月的公开资料,以下为开源且免费的全能PDF编辑器推荐。这些工具不仅免费使用,还支持本地处理、无广告、部分具备OCR或深度编辑功能,适合日常办公与隐私敏感场景。 一、主流开源免费全能PDF编辑器 1、PDF补丁丁 …...

PDF-Extract-Kit-1.0效果实测:PDF中带颜色/阴影/透明度的公式完美还原
PDF-Extract-Kit-1.0效果实测:PDF中带颜色/阴影/透明度的公式完美还原 1. 引言:PDF公式提取的痛点与曙光 处理过学术论文或技术文档的朋友都知道,从PDF里提取公式是个老大难问题。普通的OCR工具对付文字还行,一遇到复杂的数学公…...

PyTorch加载.pth预训练模型,别再傻傻等下载了!3种离线下载+加载避坑指南
PyTorch预训练模型离线加载实战:3种高效方案与避坑指南 当你兴奋地运行PyTorch示例代码准备调用预训练模型时,突然弹出的网络超时错误就像一盆冷水浇下来。这种场景在国内开发者中太常见了——不是技术门槛高,而是网络环境成了拦路虎。本文将…...

2009-2024年上市公司竞争对手退市DID数据
在过去五年中,论文中“竞争企业”这一关键词的学术传播度展现出了显著的增长趋势。识别退市公司的产品市场竞争对手主要采用基于文本相似度的分析方法:首先从上市公司年报中提取"报告期内从事的主要业务和产品"文本内容,然后使用pk…...