AWK语言第二版 第3章.探索性数据分析 3.1泰坦尼克号的沉没
这章也是第一版没有,第二版新增的。
3. 探索性数据分析
上一章给出了一些个人使用的小脚本,通常是特制或专用的。在本章中,我们还会展示Awk在现实中的典型使用场景:使用Awk和其他工具来非正式地探索一些真实的数据,目的是为了看看它们是什么样的。这叫做探索性数据分析(exploratory data analysis 或 EDA),该术语由统计学先驱John Tukey 首次使用。
Tukey 发明了大量基本的数据化可视技术如箱线图(boxplot),启发了统计编程语言S(即广泛使用的R语言的前身),合作发明了快速傅里叶变换,并创造了 bit 和 software 这两个词。作为朋友和同事,作者们在上世纪80和90年代期间与 Tukey 相识于贝尔实验室,在这许多非常聪明且极富创造力的人之中,他也是相当突出而特别的。
探索性数据分析的本质,是在提出假设和给出结论之前,先玩转数据。如Tukey本人所说:“找出问题通常比发现答案更重要,探索性数据分析是态度,是灵活性,是对展示的依赖,而不是一堆技术。”
在很多情况下,这需要涉及:计数,简单的统计,用不同方式排列数据,寻找模式、共同点和奇异值,并绘制基本的图表等可视化内容。重点在于,通过做一些小而快的实验,以期能得出一些有用的启示。注意一开始不需要精雕细琢,那可以在我们对数据有了更好的认识之后再来做。
对于EDA,我们通常使用标准Unix工具如 wc、diff、 sort、uniq、grep,当然还有正则表达式。这些工具与Awk结合在一起使用效果很好,也经常结合其他语言如Python一起使用。
下面我们将遇到好几种文件格式,包括逗号或制表符分隔的值(CSV和TSV),JSON、HTML和XML。其中一些,如CSV和TSV,很容易用Awk处理,而其他类型有时用其他工具处理更好。
3.1 泰坦尼克号的沉没
第一个数据集是基于1912年4月15日的泰坦尼克号沉没事件。本书的作者之一会选择这个例子,不完全是出于巧合,当时他正经历跨大西洋的航行,在泰坦尼克沉没点的不远处经过。
汇总数据:titanic.tsv
titanic.tsv 文件内容来源于维基百科,包含了泰坦尼克号乘客和船员的汇总数据。对CSV和TSV格式来说,通常第一行会是表头,用来标识后面的数据。列之间用制表符tab分隔。
Type Class Total Lived Died
Male First 175 57 118
Male Second 168 14 154
Male Third 462 75 387
Male Crew 885 192 693
Female First 144 140 4
Female Second 93 80 13
Female Third 165 76 89
Female Crew 23 20 3
Child First 6 5 1
Child Second 24 24 0
Child Third 79 27 52许多(也许是所有的)数据集都包含错误。这里可以做个快速检查:每行要有5个域,第3个域要等于第4和第5个域的和(total = lived + died)。下面的程序打印出所有不符合条件的行:
NF != 5 || $3 != $4 + $5如果数据格式正确而且数值也正确,只会打出一行,即表头:
Type Class Total Lived Died一旦完成这些最简单的检查后,我们就能看看其他东西了。比如,每个类别的人有多少?
这些类别不是用数字,而是用单词标识的,如Male和Crew。幸运的是,Awk数组的下标或者说索引可以是任意的字符串,因此 gender["Male"] 和 class["Crew"] 都是合法的表达式。
允许用任意字符串做下标的数组称为关联数组;其他语言也提供相同的机制,称之为字典、映射或者哈希映射。关联数组特别地方便、灵活,因此我们将会大量地用到它。
NR > 1 { gender[$1] += $3; class[$2] += $3 }END {for (i in gender) print i, gender[i]print ""for (i in class) print i, class[i]
}上面的程序会输出
Male 1690
Child 109
Female 425Crew 908
First 325
Third 706
Second 285Awk的 for 语句有个特殊形式,可用于遍历关联数组的索引:
for (i in array) { statements }会将变量 i 依次设置为数组的索引,并在执行 statements 时使用对应 i (即当前索引)的值 。数组元素的访问顺序是不确定的,你不能依赖于任何特定的顺序。【注:上面的例子用awk和gawk得到的结果顺序就不一样】
下面来看看生存率是怎么样的。社会阶层、姓名和年龄会如何影响这些乘客的生存机会?我们可以用这些汇总数据来做个简单的实验,例如计算每类人的生存率:
NR > 1 { printf("%6s %6s %6.1f%%\n", $1, $2, 100 * $4/$3) }可以将awk的输出通过管道传给Unix 命令 sort -k3 -nr(按第三列倒序排序),得到结果:
Child Second 100.0%
Female First 97.2%
Female Crew 87.0%
Female Second 86.0%Child First 83.3%
Female Third 46.1%Child Third 34.2%Male First 32.6%Male Crew 21.7%Male Third 16.2%Male Second 8.3%显然妇女和儿童的生存率高于平均水平。
注意上面的例子都将表头行当作特例进行排除(用NR > 1)。如果你要做很多实验,那么把表头从数据集中删去,也许会比每次写代码去忽略首行要简单。
乘客数据:passengers.csv
passengers.csv 文件较大,它包含了乘客的详细信息,但没有包含船员信息。原始文件是把一个广泛使用的机器学习数据集和另一个维基百科的列表合并起来得到的。文件共有11列,其中包含了乘客们的故乡、所分配的救生艇、票价等:
"row.names","pclass","survived","name","age","embarked","home.dest","room","ticket","boat","sex"
...
"11","1st",0,"Astor, Colonel John Jacob",47,"Cherbourg","New York, NY","","17754 L224 10s 6d","(124)","male"
...这文件有多大?可以使用Unix的 wc 命令来统计行数、单词数和字符数:
$ wc passengers.csv1314 6794 112466 passengers.csv或者使用我们在第一章写的两行Awk程序来统计:
{ nc += length($0) + 1; nw += NF }
END { print NR, nw, nc, FILENAME }得到的结果是一样的(当然两者在输出格式上稍微有区别,比如空格数量不一样)
passengers.csv 文件是 CSV格式(comma-separated values)。尽管CSV格式没有严格的定义,但通常都有这样的规则:如果某一域的内容包含逗号或者双引号,则整个域都要用双引号包起来。任何域都可以用双引号包起来,不管它的内容是否包含逗号或者双引号。空的域表示为""(两个双引号),而域内容里的双引号用两个双引号表示,例如 """,""" (前后共6个双引号)表示 ","。CSV文件的输入域可以包含换行符。更多细节参见附录 A.5.2。
这种格式大致也是Ms Excel和其他电子表格程序如Apple Numbers和Google Sheets所采用的。这种格式还是Python的Panda库和R语言默认的data frame格式。
2023年以来的Awk版本,如果加入命令行参数 --csv ,则会将输入行按上面的格式进行拆分。如果只是简单的用 FS=, 来设置域分隔符,则无法做到这一点,这种做法只能处理最简单的CSV格式,即不包含双引号的。如果你使用旧版本的Awk,也许最简单的做法是用其他工具(如Excel或Python的CSV模块),把数据转换成其他格式。
另一个有用的替代格式是TSV(制表符分隔的值)。它和CSV思想是一样的,但更简单:域之间用单个tab制表符分隔,没有双引号机制,因此域就不能包含嵌套的tab或换行。这种格式用Awk处理很简单,只要通过 FS="\t" 将域分隔符设置为tab,或者在命令行参数中带 -F"\t" ,效果也是一样的。
另外提一下,在处理文件内容之前验证一下它的格式是否正确,会比较明智。例如,校验所有的记录行是否都有相同的域数量,可以使用
awk '{print NF}' file | sort | uniq -c | sort -nr其中第一个sort 排序命令能够将所有相同的行都聚在一起;之后的 uniq -c 命令会将连续的相同行合并成一行,给出相同行的计数以及该行的内容;最后的 sort -nr 把结果按数值倒序排列,因此最大值输出在最前面。
对passengers.csv文件,用上面的脚本,再额外加上 --csv 选项来对CSV格式进行正确处理,得到:
1314 11可见每条记录的域数量都相同,这是合法数据的必要条件,当然不是充分条件。如果发现某些行的域数量不一样,接着就可以使用Awk把它们找出来,比如用 NF != 11 条件来过滤。
如果使用老版本即不支持CSV的Awk,用 -FS, 来处理文件,会得到:
624 12
517 13
155 1415 153 11可见基本上所有的记录里都包含了内嵌的逗号。
顺带一提,生成CSV是很容易的。下面这个函数 to_csv ,通过将双引号替换成两个双引号,并在得到的结果两边加上双引号,就能把字符串转换成符合CSV格式要求的字符串。这个函数也可以添加到第二章所述的个人库里面。
# to_csv - convert s to proper "..."function to_csv(s) {gsub(/"/, "\"\"", s)return "\"" s "\""
}(注意在字符串中引号使用反斜杠进行转义处理)
我们可以在循环中使用这个函数,并在数组的元素之间插入逗号,来将一个数组(关联数组或索引数组)转换成一条格式合法的CSV记录。参见如下两个函数 rec_to_csv 和 arr_to_csv:
# rec_to_csv - convert a record to csvfunction rec_to_csv( s, i) {for (i = 1; i < NF; i++)s = s to_csv($i) ","s = s to_csv($NF)return s
}# arr_to_csv - convert an indexed array to csvfunction arr_to_csv(arr, s, i, n) {n = length(arr)for (i = 1; i <= n; i++)s = s to_csv(arr[i]) ","return substr(s, 1, length(s)-1) # remove trailing comma
}下面的程序从原始文件中选择五个属性(类别、是否生还、姓名、年龄、性别)输出,域之间用制表符tab分隔:
NR > 1 { OFS="\t"; print $2, $3, $4, $5, $11 }输出结果如下:
1st 0 Allison, Miss Helen Loraine 2 female
1st 0 Allison, Mr Hudson Joshua Creighton 30 male
1st 0 Allison, Mrs Hudson J.C. (Bessie Waldo Daniels) 25 female
1st 1 Allison, Master Hudson Trevor 0.9167 male年龄字段大部分是整数,但也有部分是小数,如上面的最后一行。Helen Allison是两岁, Master Hudson Allison看起来是11个月大,而且是他们家族的唯一幸存者。(从其他来源我们得知,Allison家的司机George Swane,18岁,也遇难了,但女佣和厨师都得救了)
泰坦尼克上有多少婴儿?执行命令
$4 < 1并用tab作为域分隔符,可以得到8行:
1st 1 Allison, Master Hudson Trevor 0.9167 male
2nd 1 Caldwell, Master Alden Gates 0.8333 male
2nd 1 Richards, Master George Sidney 0.8333 male
3rd 1 Aks, Master Philip 0.8333 male
3rd 0 Danbom, Master Gilbert Sigvard Emanuel 0.3333 male
3rd 1 Dean, Miss Elizabeth Gladys (Millvena) 0.1667 female
3rd 0 Peacock, Master Alfred Edward 0.5833 male
3rd 0 Thomas, Master Assad Alexander 0.4167 male练习3-1、修改单词计数程序,使之能为每个输入文件产生一个单独的计数结果,就像Unix命令wc一样。
更进一步的检查
另一类要探索的问题,是两个数据源的一致性。两个数据都来自维基百科,但它并不总是完全精确的数据源。假如我们检查一些最基本的,比如有多少乘客在 passengers 文件中:
$ awk 'END {print NR}' passengers.csv
1314这里还包含了表头行,所以是1313个乘客。而我们还可以从汇总文件第三个域中统计非船员的人数:
$ awk '!/Crew/ { s += $3 }; END { print s }' titanic.tsv
1316差了3个人,肯定哪里错了。
再来个例子,算算有多少儿童?
awk --csv '$5 <= 12' passengers.csv结果有100行,和汇总文件titanic.tsv里得到的109人对不上。
也许儿童的定义是不超过13岁?但结果是105。用14岁试试?结果是112。通过计算被称为“Master”的乘客数量,我们可以猜测用的是哪个数字:
awk --csv '/Master/ {print $5}' passengers.csv | sort -n里面最大的年龄是13岁,尽管不能确定,但也许这个猜测最接近实际。
上面两种情况下,数字都应该是相同的,但实际上却不同,这说明数据还是不太靠谱。可见在探索数据时,你要总是准备好应付数据在形式和内容上的错误和不一致。在开始下结论之前,要做大量的工作来保证你已经识别并处理了潜在的问题。
在本节中,我们已尽力展示如何用简单的计算来帮助识别这样的问题。如果你收集一些工具来做公共的操作,如分离域,按类分组,打印最常见和最少见的条目,等等,你就更好地进行这些检查操作。
练习3-2、根据你自己的需要和品味,为自己写一些工具。
相关文章:

AWK语言第二版 第3章.探索性数据分析 3.1泰坦尼克号的沉没
这章也是第一版没有,第二版新增的。 3. 探索性数据分析 上一章给出了一些个人使用的小脚本,通常是特制或专用的。在本章中,我们还会展示Awk在现实中的典型使用场景:使用Awk和其他工具来非正式地探索一些真实的数据,目…...
微信小程序设计之主体文件app-json-window
一、新建一个项目 首先,下载微信小程序开发工具,具体下载方式可以参考文章《微信小程序开发者工具下载》。 然后,注册小程序账号,具体注册方法,可以参考文章《微信小程序个人账号申请和配置详细教程》。 在得到了测…...

WebDAV之π-Disk派盘 + 密码键盘
密码键盘是一款密码管理器,可以存储和管理需要受保护的数据。为方便日常使用,同时也是一款安全输入法,帮您安全便捷地填写账号密码、通用内容、卡包信息。 密码键盘使用军事级的 PBKDF2 有损加密算法保护您的根密码,使用军事级的 AES 加密算法保护您的存储数据。云端再额外…...

LeetCode讲解篇之77. 组合
文章目录 题目描述题解思路题解代码 题目描述 题解思路 遍历nums,让当前数字添加到结果前缀中,递归调用,直到前缀的长度为k,然后将前缀添加到结果集 题解代码 func combine(n int, k int) [][]int {var nums make([]int, n)fo…...

【openwrt学习笔记】Dying Gasp功能和pstore功能的配置(高通 ipq95xx)
目录 一、Dying Gasp信号1.1 概念1.2 实现原理 二、pstore 功能2.1 概念2.2 实现原理 三、openwrt中开启pstore功能3.1 软硬件参数3.2 各文件修改3.2.1 defconfig3.2.2 dts(ipq9574-default-memory.dtsi)3.2.3 fs/pstore/ram.c 四、测试4.1 挂载4.2 触发命令和效果 参考资料&am…...

使用RestSharp和C#编写程序
以下是一个使用RestSharp和C#编写的爬虫程序,用于爬取www.zhihu.com上的视频。此程序使用了https://www.duoip.cn/get_proxy来获取代理IP。 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks…...

Leetcode 2911. Minimum Changes to Make K Semi-palindromes
Leetcode 2911. Minimum Changes to Make K Semi-palindromes 1. 解题思路2. 代码实现 题目链接:2911. Minimum Changes to Make K Semi-palindromes 1. 解题思路 这一题属实也是把我坑惨了…… 坦率地说,这道题本身并没有啥难度,但是坑爹…...
Node学习笔记之包管理工具
一、概念介绍 1.1 包是什么 『包』英文单词是package ,代表了一组特定功能的源码集合 1.2 包管理工具 管理『包』的应用软件,可以对「包」进行 下载安装 , 更新 , 删除 , 上传 等操作 借助包管理工具,可…...
分发糖果[困难]
优质博文:IT-BLOG-CN 一、题目 n个孩子站成一排。给你一个整数数组ratings表示每个孩子的评分。你需要按照以下要求,给这些孩子分发糖果: 【1】每个孩子至少分配到1个糖果。 【2】相邻两个孩子评分更高的孩子会获得更多的糖果。 请你给每个孩…...

Java验证邮箱格式是否正确的正则表达式
Java验证邮箱格式是否正确的正则表达式 import java.util.regex.Pattern;public class EmailUtil {final static Pattern partern Pattern.compile("[a-zA-Z0-9][\\.]{0,1}[a-zA-Z0-9][a-zA-Z0-9]\\.[a-zA-Z]");/*** 验证输入的邮箱格式是否符合* param email* ret…...

快速排序原理JAVA和Scala实现-函数式编程的简洁演示
快速排序原理JAVA和Scala实现-函数式编程的简洁演示 目录 快速排序原理JAVA和Scala实现-函数式编程的简洁演示 C语言快速排序实现 Java 快速排序实现 Scala 快速排序实现 本文章向大家介绍快速排序原理JAVA和Scala实现-函数式编程的简洁演示,主要内容包括C语言…...
如何在linux服务器上安装Anaconda与pytorch
如何在linux服务器上安装Anaconda与pytorch 1,安装anaconda1.1 下载anaconda安装包1.2 安装anaconda1.3 设计环境变量1.4 安装完成验证 2 Anaconda安装pytorch2.1 创建虚拟环境2.2 查看现存环境2.3 激活环境2.4 选择合适的pytorch版本下载2.5 检测是否安装成功&…...
FPGA设计FIR滤波器低通滤波器,代码及视频
名称:FIR滤波器低通滤波器 软件:Quartus 语言:Verilog/VHDL 本资源含有verilog及VHDL两种语言设计的工程,每个工程均可实现以下FIR滤波器的功能。 代码功能: 设计一个8阶FIR滤波器(低通滤波器ÿ…...
【数据结构】排序--快速排序
目录 一 概念 二 快速排序的实现 1. hoare版本 (1)代码实现 (2)单趟排序图解 (3) 递归实现图解 (4)细节控制 (5)时间复杂度 (6)三数取中优化 2 挖坑法 (1)代码实现 (2)单趟图解 3 前后指针法 (1) 代码实现 (2) 单趟图解 4 优化子区间 5 非递归快速排序 …...
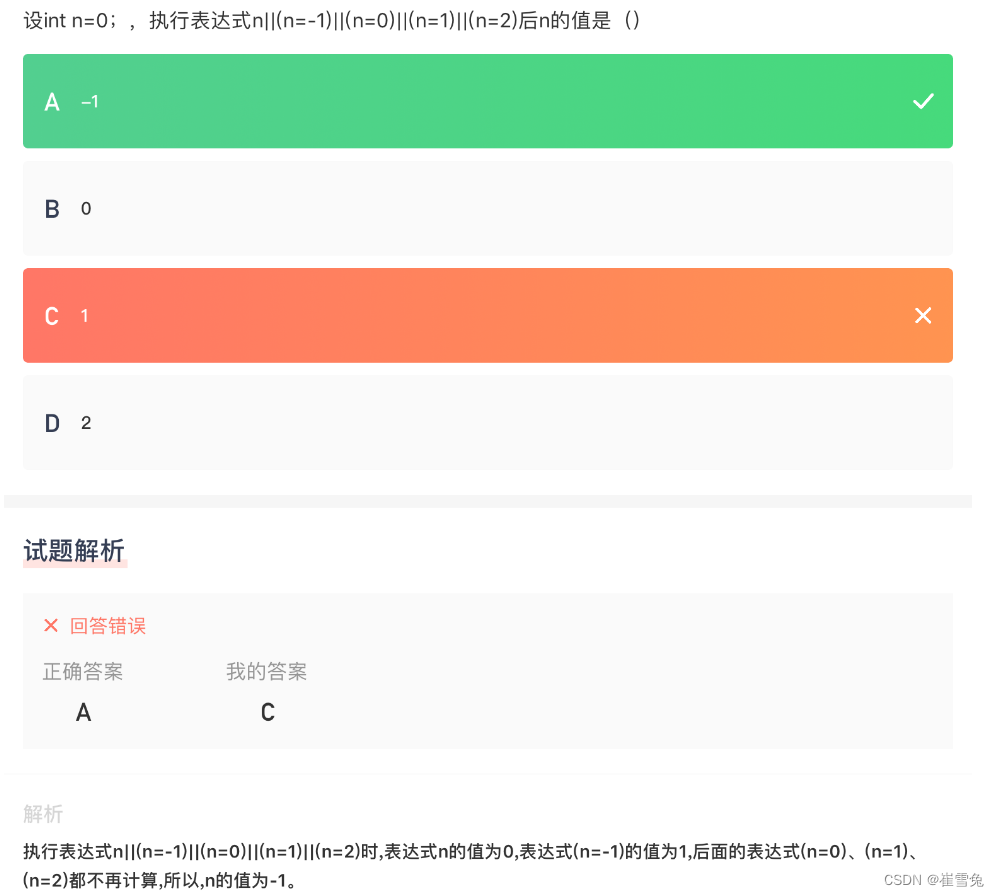
【试题040】多个逻辑或例题2
1.题目:设int n0;,执行表达式n ||(n-1) ||(n0)||(n1)||(n2)后n的值是 ? 2.代码解析: 逻辑或 || 运算符是一个短路运算符,它从左到右依次计算表达式,如果遇到一个为真(非零)的值&am…...

自然语言处理---Self Attention自注意力机制
Self-attention介绍 Self-attention是一种特殊的attention,是应用在transformer中最重要的结构之一。attention机制,它能够帮助找到子序列和全局的attention的关系,也就是找到权重值wi。Self-attention相对于attention的变化,其实…...
推荐收藏系列!2万字图解Hadoop
今天我用图解的方式讲解pandas的用法,内容较长建议收藏,梳理不易,点赞支持。 学习 Python 编程,给我的经验就是:技术要学会分享、交流,不建议闭门造车。一个人可能走的很快、但一堆人可以走的更远。如果你…...
:生成器)
Python高级篇(08):生成器
一、生成器定义和作用 定义:Python中,一边循环一边计算的机制,生成器对象也是迭代器对象,支持for循环、next()方法…等。作用:循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而…...
)
力扣100114. 元素和最小的山形三元组 II(中等)
题目描述: 给你一个下标从 0 开始的整数数组 nums 。 如果下标三元组 (i, j, k) 满足下述全部条件,则认为它是一个 山形三元组 : i < j < knums[i] < nums[j] 且 nums[k] < nums[j] 请你找出 nums 中 元素和最小 的山形三元组…...
--lcdseg - 段式lcd)
LuatOS-SOC接口文档(air780E)--lcdseg - 段式lcd
常量 常量 类型 解释 lcdseg.BIAS_STATIC number 没偏置电压(bias) lcdseg.BIAS_ONEHALF number 1/2偏置电压(bias) lcdseg.BIAS_ONETHIRD number 1/3偏置电压(bias) lcdseg.BIAS_ONEFOURTH number 1/4偏置电压(bias) lcdseg.DUTY_STATIC number 100%占空比(d…...

6 文件保存功能优化
6 文件保存功能优化 6.1 开发流程 流程说明 实现保存文件的功能,包含以下逻辑: 检查当前是否有已打开的文件如果没有打开的文件,弹出保存文件对话框让用户选择保存位置将文本编辑框中的内容写入到文件中 代码实现 void Widget::on_btnSave_cl…...

MusePublic圣光艺苑完整指南:CSDN图床集成+真迹分享链接生成机制
MusePublic圣光艺苑完整指南:CSDN图床集成真迹分享链接生成机制 1. 引言:当古典艺术遇见现代技术 想象一下,你走进一间19世纪的画室,空气中弥漫着亚麻籽油和矿物颜料的味道。阳光透过高窗,洒在铺着亚麻画布的画架上。…...

Ostrakon-VL-8B实战落地:深夜食堂风格终端生成货架巡检报告
Ostrakon-VL-8B实战落地:深夜食堂风格终端生成货架巡检报告 1. 项目背景与核心价值 在零售和餐饮行业,货架巡检是一项耗时且容易出错的工作。传统方法需要人工逐一检查商品摆放、价签信息、库存状态等,不仅效率低下,还容易遗漏细…...

深入解析XDG_RUNTIME_DIR:从Linux桌面到Docker容器的环境变量配置实战
1. 理解XDG_RUNTIME_DIR的前世今生 第一次在终端里看到"XDG_RUNTIME_DIR not set"的警告时,我盯着这行字发了五分钟呆。这个看起来像乱码的变量名,其实是Linux桌面环境中一个至关重要的配置项。让我们从一个真实案例说起:上周同事在…...

WinUtil:告别Windows系统臃肿烦恼,一键打造流畅高效的操作体验
WinUtil:告别Windows系统臃肿烦恼,一键打造流畅高效的操作体验 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否…...

Anthropic造了个“太危险不敢发“的AI,OpenAI 7天后正面刚
4月7号,Anthropic发了一篇博客,标题平平无奇,“Claude Mythos Preview”。 但博客里有一句话,直接把安全圈炸了:“这是我们有史以来构建的最强大的AI模型。” 三天后,Tom’s Hardware挖出了更猛的细节&…...

富集分析结果太杂乱?3个ggplot2技巧让你的气泡图秒变高颜值SCI配图
富集分析结果太杂乱?3个ggplot2技巧让你的气泡图秒变高颜值SCI配图 科研论文中的图表质量直接影响审稿人对研究成果的第一印象。对于生物信息学分析而言,富集分析(如GO、KEGG、GSEA)的结果可视化尤为关键——它不仅需要准确传达数…...

时序抖动:概念、测量与系统设计优化
1. 时序抖动的基础概念与影响机制在数字系统设计中,时序抖动(Jitter)是指时钟信号边沿相对于理想位置的偏差。这种看似微小的偏差会对系统性能产生深远影响,特别是在高速数据传输和精密信号处理领域。想象一下交响乐团的指挥手势出…...

MedGemma Medical Vision Lab效果展示:病理切片WSI低倍镜下肿瘤区域与淋巴细胞浸润密度文本评估
MedGemma Medical Vision Lab效果展示:病理切片WSI低倍镜下肿瘤区域与淋巴细胞浸润密度文本评估 1. 引言:当AI遇见病理切片分析 病理切片分析是医学诊断中的重要环节,但传统的人工分析方式存在效率低、主观性强等挑战。今天我们要展示的Med…...

SLAM从未消失,只是在各产业中悄悄完成「位置下沉、角色重组」
对未来SLAM形态的核心判断下沉为底层基础能力:未来SLAM不会以完整独立模块存在,其核心能力将拆解融入定位、建图等各环节,实现底层下沉。混合式系统成主流选择:纯几何方法在可解释性、效率和稳定性上仍有优势,而融合多…...