tf loss构建常用到函数
1、tf.map_fn
tf.map_fn是TensorFlow中的一个函数,用于对给定的函数和输入进行逐元素的映射,其定义如下:
tf.map_fn(fn,elems,dtype=None,parallel_iterations=None,back_prop=True,swap_memory=False,infer_shape=True,name=None,fn_output_signature=None
)tf1.x中tf.map_fn没有fn_output_signature参数
tf.map_fn案例
tf.map_fn(fn=lambda t: tf.range(t, t + 3), elems=tf.constant([3, 5, 2]))https://www.tensorflow.org/api_docs/python/tf/map_fn
tf.map_fn( )的用法-CSDN博客
<tf.Tensor: shape=(3, 3), dtype=int32, numpy=
array([[3, 4, 5],[5, 6, 7],[2, 3, 4]], dtype=int32)>
2、tf.pad
定义 :tf.pad()函数是TensorFlow中的一个方法,用于在张量的边界上进行填充。
tf.pad(tensor, paddings, mode='CONSTANT', constant_values=0)
参数解释:
- tensor:需要填充的张量。
- paddings:填充的大小,格式为[[pad_top, pad_bottom], [pad_left, pad_right], ...],其中每个维度的填充大小为两个元素的列表。例如,如果填充第一个维度10个元素,则paddings为[[10, 0], [0, 0]]。
- mode:填充模式。可选值有'CONSTANT'、'REFLECT'、'SYMMETRIC'。默认为'CONSTANT',表示使用常数进行填充。
- constant_values:当mode为'CONSTANT'时,用于填充的常数值,默认为0。
返回值: 返回填充后的张量。
案例:
import tensorflow as tf# 创建一个输入张量
x = tf.constant([[1, 2], [3, 4]])# 使用tf.pad函数在各个维度上进行填充
result = tf.pad(x, paddings=[[1, 1], [2, 2]])print(result)
paddings=[[1, 1], [2, 2]]是指在第1维的上下均填充1维,在第2维的左右都填充2维
输出结果
<tf.Tensor: shape=(4, 6), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0],[0, 0, 1, 2, 0, 0],[0, 0, 3, 4, 0, 0],[0, 0, 0, 0, 0, 0]], dtype=int32)>
https://www.tensorflow.org/api_docs/python/tf/pad
3、tf.where
tf.where(condition, x=None, y=None, name=None
)tf.where是一个用于根据条件选择元素的函数。它的作用类似于Python中的条件表达式(ternary expression)。
tf.where函数接受一个条件张量和两个张量(或者相同形状的数组)作为输入,并返回一个新的张量,其中根据条件选择了对应位置的元素。
以下是一个示例,演示如何使用tf.where函数选择满足条件的元素:
import tensorflow as tf# 创建一个条件张量和两个输入张量
condition = tf.constant([True, False, True])
x = tf.constant([1, 2, 3])
y = tf.constant([4, 5, 6])# 使用tf.where根据条件选择元素
result = tf.where(condition, x, y)print(result)
输出结果
<tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 5, 3], dtype=int32)>
4、tf.expand_dims
定义
tf.expand_dims(input, axis, name=None
)tf.expand_dims是TensorFlow中的一个函数,用于在张量的特定维度上插入新的维度。
tf.expand_dims函数接受一个输入张量和一个axis参数,它在输入张量的axis位置插入一个新的维度。
以下是一个示例,展示如何使用tf.expand_dims函数在张量的特定维度上插入新的维度:
import tensorflow as tf# 创建一个输入张量
x = tf.constant([1, 2, 3, 4])# 在维度1上插入新的维度
result = tf.expand_dims(x, axis=1)print(result)
在这个示例中,我们首先创建了一个输入张量x,其中包含了四个元素。然后,我们使用tf.expand_dims函数在维度1上插入新的维度。最后,打印结果。
tf.Tensor(
[[1][2][3][4]], shape=(4, 1), dtype=int32)
5、tf.tile
定义
tf.tile(input: _atypes.TensorFuzzingAnnotation[TV_Tile_T],multiples: _atypes.TensorFuzzingAnnotation[TV_Tile_Tmultiples],name=None
) -> _atypes.TensorFuzzingAnnotation[TV_Tile_T]tf.tile是TensorFlow中的一个函数,用于在给定维度上复制张量的值。
tf.tile函数接受一个输入张量和一个multiples参数,它在输入张量的每个维度上复制相应倍数的值,并返回一个新的张量。
以下是一个示例,演示如何使用tf.tile函数在给定维度上复制张量的值
import tensorflow as tf# 创建一个输入张量
x = tf.constant([1, 2, 3])# 在维度0上复制2次
result = tf.tile(x, multiples=[2])print(result)
输出结果:
tf.Tensor([1 2 3 1 2 3], shape=(6,), dtype=int32)
可以看到,通过tf.tile函数在维度0上复制了两次输入张量的值,得到了一个形状为(6,)的新张量。
需要注意的是,multiples参数是一个列表,表示在每个维度上复制的倍数。如果multiples的长度小于输入张量的维度数,则会自动在后续维度上复制一次。例如,如果输入张量的形状是(3, 4, 5, 6),而multiples为[2, 3],则会在维度0上复制2次,在维度1上复制3次,在维度2和维度3上各复制1次。
tf.tile函数在很多情况下非常有用,特别是在需要进行张量形状扩展或对齐操作时。
6、tf.gather_nd
tf.gather_nd是TensorFlow中的一个函数,用于根据索引获取多维张量中的元素的值。定义
tf.gather_nd(params, indices, batch_dims=0, name=None
)tf.gather_nd函数接受一个输入张量和一个索引张量作为输入,它根据索引张量中指定的索引位置,从输入张量中获取对应的元素值,并返回一个新的张量。
以下是一个示例,演示如何使用tf.gather_nd函数获取多维张量中的元素值:
import tensorflow as tf# 创建一个输入张量
x = tf.constant([[1, 2], [3, 4], [5, 6]])# 创建一个索引张量
indices = tf.constant([[0, 0], [2, 1]])# 使用tf.gather_nd函数获取元素值
result = tf.gather_nd(x, indices)print(result)
在这个示例中,我们首先创建了一个输入张量x,它是一个 3x2 的张量。然后,我们创建了一个索引张量indices,其中包含了两个索引位置的坐标。接下来,我们使用tf.gather_nd函数根据索引张量获取输入张量中对应位置的元素值。最后,打印结果。
tf.Tensor([1 6], shape=(2,), dtype=int32)
7、tf.reduce_min
tf.reduce_min是TensorFlow中的一个函数,用于计算张量在指定维度上的最小值。当在tf.reduce_min函数中不指定axis参数时,它会计算整个张量的最小值。定义
output = tf.reduce_min(input_tensor, axis=None, keepdims=False, name=None)
案例
不指定axis时,计算整个张量的最小值
import tensorflow as tf# 创建一个输入张量
x = tf.constant([[1, 2, 3], [4, 5, 6]])# 计算整个张量的最小值
result = tf.reduce_min(x)print(result)
输出如下:
tf.Tensor(1, shape=(), dtype=int32)
指定aixs时,计算aixs的维度的最小值
import tensorflow as tf# 创建一个输入张量
x = tf.constant([[1, 2], [3, 4]])# 计算张量在维度0上的最小值
result = tf.reduce_min(x, axis=0)print(result)
输出:
tf.Tensor([1 2], shape=(2,), dtype=int32)
8、tf.stack
tf.stack将一系列 R 阶张量堆叠到一个 (R+1) 阶张量中。 定义
tf.stack(values, axis=0, name='stack'
)通过沿轴维度将值中的张量列表打包为比每个张量高一级的张量。给定长度为 N 的形状为 (A, B, C) 的张量列表;如果 axis == 0 那么输出张量将具有形状 (N, A, B, C)。如果 axis == 1 那么输出张量将具有形状 (A, N, B, C)。
案例
x = tf.constant([1, 4])
y = tf.constant([2, 5])
z = tf.constant([3, 6])
tf.stack([x, y, z])tf.stack([x, y, z], axis=1)
tf.stack([x,y,z])的输出
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[1, 4],[2, 5],[3, 6]], dtype=int32)>tf.stack([x,y,z],axis=1)的输出
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[1, 2, 3],[4, 5, 6]], dtype=int32)>9、tf.concat
tf.concat 是 TensorFlow 中的一个函数,用于沿指定的轴拼接张量。它接受一个张量列表,并沿着指定的轴拼接它们。定义
tf.concat(values, axis, name='concat'
)案例
import tensorflow as tf# 创建两个张量
tensor1 = tf.constant([[1, 2, 3], [4, 5, 6]])
tensor2 = tf.constant([[7, 8, 9], [10, 11, 12]])# 沿轴0拼接
result = tf.concat([tensor1, tensor2], axis=0)with tf.Session() as sess:print(sess.run(result))
结果输出
<tf.Tensor: shape=(4, 3), dtype=int32, numpy=
array([[ 1, 2, 3],[ 4, 5, 6],[ 7, 8, 9],[10, 11, 12]], dtype=int32)>10、tensor.get_shape().as_list()
tensor.get_shape()获取tensor的维度,.as_list()以list的形式返回
x = tf.constant([[1, 2, 3], [4, 5, 6]])
shape = x.get_shape().as_list()
输出
[2, 3]11、tf.unique_with_counts
tf.unique_with_counts 函数用于对输入张量中的元素进行去重,并返回去重后的元素、元素在原始张量中的索引、元素在原始张量中的计数。x为1-d tensor,定义:
y, idx, count = tf.unique_with_counts(x, out_idx=tf.int64)
https://github.com/tensorflow/docs/blob/r1.12/site/en/api_docs/python/tf/unique_with_counts.md
案例:
x = tf.constant([1, 2, 3, 1, 2, 1, 3, 3, 3])
y, idx, count = tf.unique_with_counts(x)输出结果
不重复的元素y:<tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 2, 3], dtype=int32)>
索引下标idx:<tf.Tensor: shape=(9,), dtype=int32, numpy=array([0, 1, 2, 0, 1, 0, 2, 2, 2],dtype=int32)>
不重复元素对应的计数count: <tf.Tensor: shape=(3,), dtype=int32, numpy=array([3, 2, 4], dtype=int32)>
12、tf.greater_equal
tf.greater_equal 是 TensorFlow 中用于比较两个张量元素是否满足大于等于的元素级别比较的函数。定义如下:
result = tf.greater_equal(x, y, name=None)
案例:
两个张量比较大小
# 创建输入张量
x = tf.constant([1, 2, 3, 4])
y = tf.constant([2, 2, 2, 2])# 进行元素级别的大于等于比较
result = tf.greater_equal(x, y)输出:
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, True])>张量和一个数值比较大小
# 创建输入张量
x = tf.constant([1, 2, 3, 4])
y = 2# 进行元素级别的大于等于比较
result = tf.greater_equal(x, y)输出
<tf.Tensor: shape=(4,), dtype=bool, numpy=array([False, True, True, True])>13、tf.reshape
tf.reshape 是 TensorFlow 中用于改变张量形状的函数。它可以用来重新排列张量的维度,以适应不同的计算需求。
reshaped_tensor = tf.reshape(tensor, shape, name=None)
案例
x = tf.constant([[1, 2, 3], [4, 5, 6]])# 改变张量形状
reshaped_x = tf.reshape(x, [3, 2])输出结果
<tf.Tensor: shape=(3, 2), dtype=int32, numpy=
array([[1, 2],[3, 4],[5, 6]], dtype=int32)>14、tf.cast
将一个 tensor 变为新的类型 type。定义
tf.cast(x, dtype, name=None
)案例
x = tf.constant([1.8, 2.2], dtype=tf.float32)
tf.cast(x, tf.int32)输出
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([1, 2], dtype=int32)>
15、tf.div_no_nan
计算不安全除法,如果y等于0,则返回0。定义:
tf.div_no_nan(x,y,name=None
)案例:
x = tf.constant([1, 2, 3, 4], dtype=tf.float32)
y = tf.constant([0, 2, 0, 4], dtype=tf.float32)
z=tf.div_no_nan(x,y)输出:
<tf.Tensor: shape=(4,), dtype=float32, numpy=array([0., 1., 0., 1.], dtype=float32)>
16、tf.nn.softmax_cross_entropy_with_logits_v2
计算labels和logits之间的交叉熵,定义如下:
tf.nn.softmax_cross_entropy_with_logits_v2(_sentinel=None,labels=None,logits=None,dim=-1,name=None
)
https://github.com/tensorflow/docs/blob/r1.12/site/en/api_docs/python/tf/nn/softmax_cross_entropy_with_logits_v2.md
案例
import tensorflow as tf# 创建标签张量和预测得分张量
labels = tf.constant([[0, 1, 0], [1, 0, 0]], dtype=tf.float32)
logits = tf.constant([[1, 2, 3], [4, 5, 6]], dtype=tf.float32)# 计算 softmax 交叉熵损失
loss = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)输出
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([1.4076059, 2.407606 ], dtype=float32)>
17、tf.math.log1p
tf.math.log1p 是 TensorFlow 中的一个数学函数,用于计算输入张量加1后的自然对数。
tf.math.log1p 的基本用法如下:
output = tf.math.log1p(input)案例
x = tf.constant([1, 2, 3],dtype=tf.float32)
output = tf.math.log1p(x)输出
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.6931472, 1.0986123, 1.3862944], dtype=float32)>参考文献
https://www.tensorflow.org/api_docs/python/tf/map_fn
tf.map_fn( )的用法-CSDN博客
tensorflow tf.pad解析_tensorflow.pad-CSDN博客
相关文章:

tf loss构建常用到函数
1、tf.map_fn tf.map_fn是TensorFlow中的一个函数,用于对给定的函数和输入进行逐元素的映射,其定义如下: tf.map_fn(fn,elems,dtypeNone,parallel_iterationsNone,back_propTrue,swap_memoryFalse,infer_shapeTrue,nameNone,fn_output_sign…...

行为型模式-备忘录模式
备忘录模式保存一个对象的某个状态,以便在适当的时候恢复对象。备忘录模式属于行为型模式。 意图:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。 主要解决:所谓备忘录模式就是在不破坏…...

Android Studio初学者实例:RecyclerView学习--模仿今日头条--续
新学期开始了,这篇文章收到了很多人的评论有很多地方不懂,所以写下了以下的文章--续篇 首先使用RecyclerView也好还是使用ListView,更或是GridView你都要先构思需要什么 这些东西无一例外通常都是用在列表显示下,那么需要一些&a…...
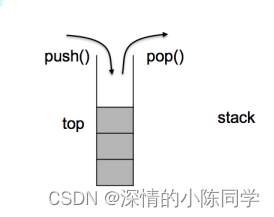
栈和队列的C++模拟实现
一、栈stack 1.介绍(库里面的文档介绍) 1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。 2. stack是作为容器适配器被实现的,容器适配器即是对…...
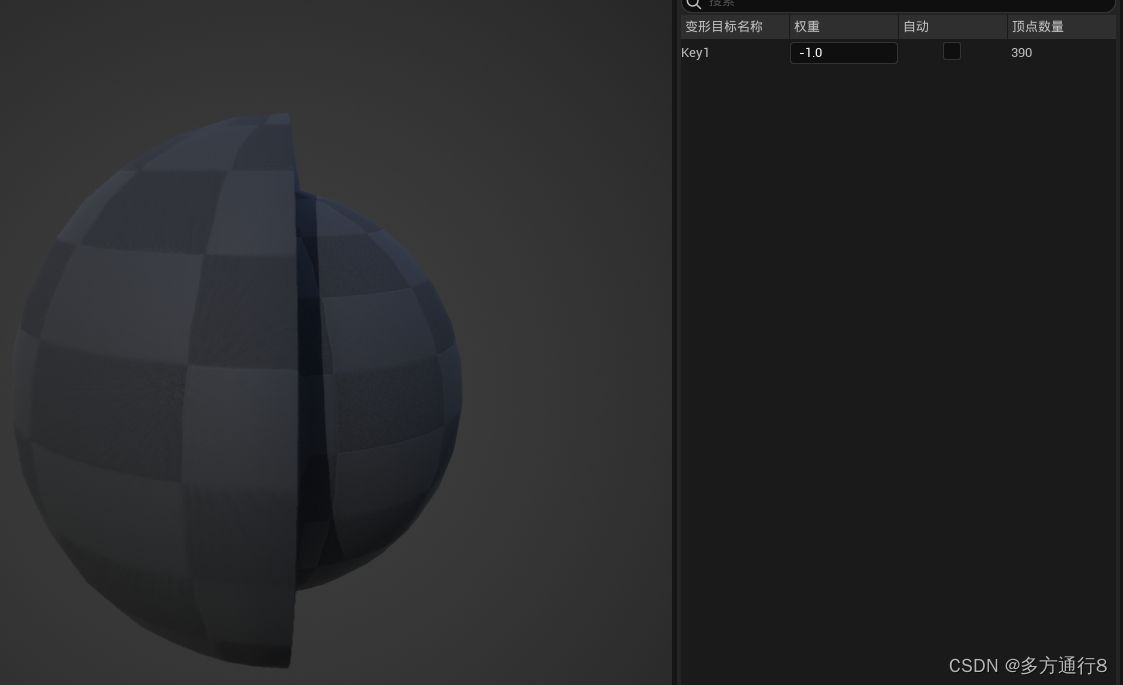
UE4/5:通过Blender制作BlendShape导入【UE4/5曲线、变形目标,blender形态键】
UE4/5里面,我们经常可以在一些骨骼模型上面看到相关的曲线,如Metahuman里面就是通过这个曲线来改变人物的脸部表情。 而这里笔者将教导如何去制作这种曲线。 这种曲线都是存在于骨骼模型上的,所以我们要么直接制作骨骼模型导入ue࿰…...

微信小程序进阶——后台交互
目录 一、后台准备 1.1 pom.xml 1.2 配置数据源 1.3 整合mybatis 二、前后端交互 2.1 method1 2.2 method2 2.2.1 封装request 2.2.2 头部引用util 2.2.3 编写方法 2.2.4 展示效果 三、WXS的使用 3.1 会议状态 3.1.2 引入wxs 3.1.3 修改代码 3.1.4 展示效果 3…...

二维码智慧门牌管理系统升级解决方案:突破传统,实现质检与抽检的个性化配置
文章目录 前言一、引入“独立质检”二、个性化抽检类别设定三、触发重采要素的功能升级四、升级优势与展望 前言 在数字化时代,智慧门牌管理系统已经成为社会管理的重要工具。为了满足各种复杂需求,系统升级是必然趋势。本次升级主要针对质检和抽检两大…...

《动手学深度学习 Pytorch版》 9.4 双向循环神经网络
之前的序列学习中假设的目标是在给定观测的情况下对下一个输出进行建模,然而也存在需要后文预测前文的情况。 9.4.1 隐马尔可夫模型中的动态规划 数学推导太复杂了,略。 9.4.2 双向模型 双向循环神经网络(bidirectional RNNs)…...

【Axure高保真原型】可视化图表图标
今天和粉丝们免费分享可视化图表图标原型模板,包括柱状图、条形图、环形图、散点图、水波图等常用的可视化图表图标。 【原型效果】 【原型预览】 https://axhub.im/ax9/d402c647c82f9185/#c1 【原型下载】 这个模板可以在 Axure高保真原型哦 小程序里免费下载哦…...
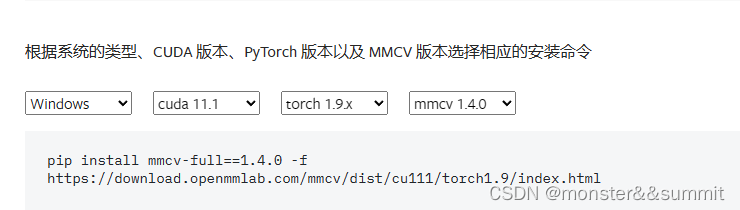
安装mmcv及GPU版本的pytorch及torchvision
一、先装GPU版本的pytorch和torchvision pip install torch1.9.1cu111 torchvision0.10.1cu111 torchaudio0.9.1 -f https://download.pytorch.org/whl/torch_stable.html注意:以上适用cuda11.1版本 如果想离线安装,就看这篇文章 二、安装mmcv 看这篇…...
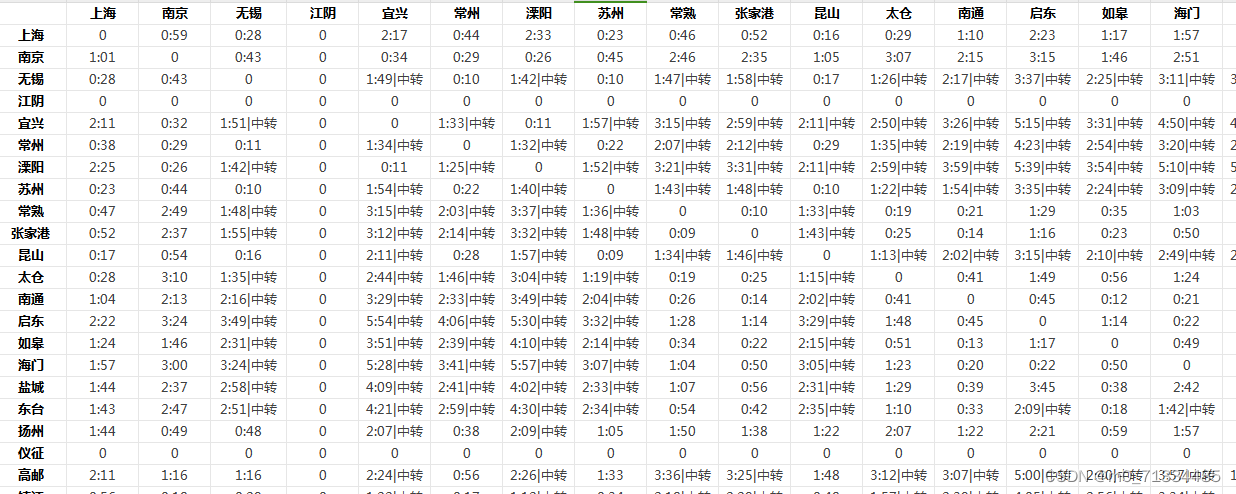
全国342个城市往返最短通勤时间(铁路)数据
全国342个城市往返最短通勤时间(铁路)数据 1、时间:采集时间是2022年 2、来源:12306 3、数据说明:数据采集12306数据,整理全国342个城市往返最短通勤时间,本数据是铁路包含动车、高铁所有路线…...

AWK语言第二版 第3章.探索性数据分析 3.1泰坦尼克号的沉没
这章也是第一版没有,第二版新增的。 3. 探索性数据分析 上一章给出了一些个人使用的小脚本,通常是特制或专用的。在本章中,我们还会展示Awk在现实中的典型使用场景:使用Awk和其他工具来非正式地探索一些真实的数据,目…...
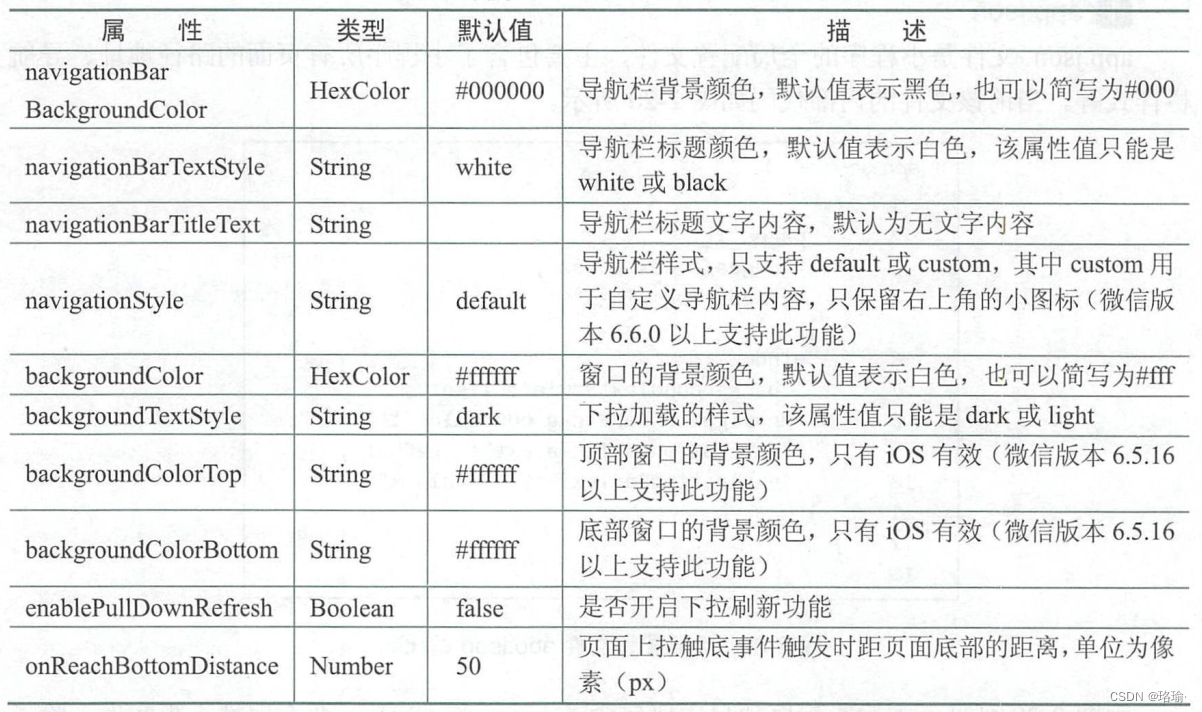
微信小程序设计之主体文件app-json-window
一、新建一个项目 首先,下载微信小程序开发工具,具体下载方式可以参考文章《微信小程序开发者工具下载》。 然后,注册小程序账号,具体注册方法,可以参考文章《微信小程序个人账号申请和配置详细教程》。 在得到了测…...

WebDAV之π-Disk派盘 + 密码键盘
密码键盘是一款密码管理器,可以存储和管理需要受保护的数据。为方便日常使用,同时也是一款安全输入法,帮您安全便捷地填写账号密码、通用内容、卡包信息。 密码键盘使用军事级的 PBKDF2 有损加密算法保护您的根密码,使用军事级的 AES 加密算法保护您的存储数据。云端再额外…...

LeetCode讲解篇之77. 组合
文章目录 题目描述题解思路题解代码 题目描述 题解思路 遍历nums,让当前数字添加到结果前缀中,递归调用,直到前缀的长度为k,然后将前缀添加到结果集 题解代码 func combine(n int, k int) [][]int {var nums make([]int, n)fo…...

【openwrt学习笔记】Dying Gasp功能和pstore功能的配置(高通 ipq95xx)
目录 一、Dying Gasp信号1.1 概念1.2 实现原理 二、pstore 功能2.1 概念2.2 实现原理 三、openwrt中开启pstore功能3.1 软硬件参数3.2 各文件修改3.2.1 defconfig3.2.2 dts(ipq9574-default-memory.dtsi)3.2.3 fs/pstore/ram.c 四、测试4.1 挂载4.2 触发命令和效果 参考资料&am…...

使用RestSharp和C#编写程序
以下是一个使用RestSharp和C#编写的爬虫程序,用于爬取www.zhihu.com上的视频。此程序使用了https://www.duoip.cn/get_proxy来获取代理IP。 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks…...

Leetcode 2911. Minimum Changes to Make K Semi-palindromes
Leetcode 2911. Minimum Changes to Make K Semi-palindromes 1. 解题思路2. 代码实现 题目链接:2911. Minimum Changes to Make K Semi-palindromes 1. 解题思路 这一题属实也是把我坑惨了…… 坦率地说,这道题本身并没有啥难度,但是坑爹…...
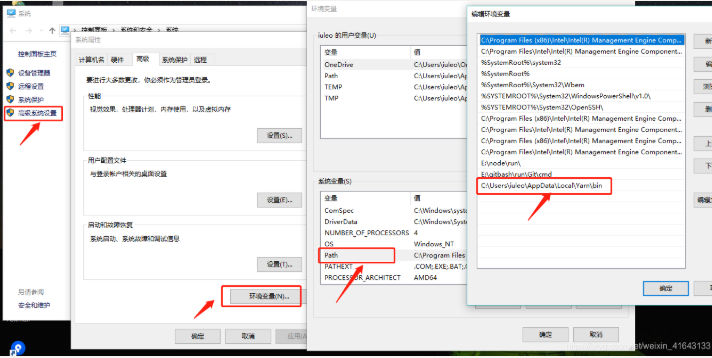
Node学习笔记之包管理工具
一、概念介绍 1.1 包是什么 『包』英文单词是package ,代表了一组特定功能的源码集合 1.2 包管理工具 管理『包』的应用软件,可以对「包」进行 下载安装 , 更新 , 删除 , 上传 等操作 借助包管理工具,可…...
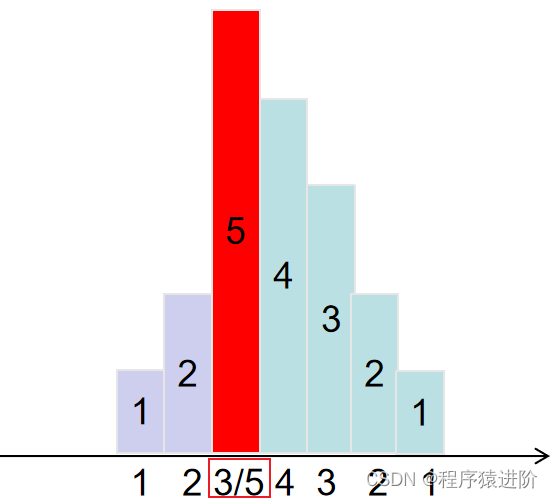
分发糖果[困难]
优质博文:IT-BLOG-CN 一、题目 n个孩子站成一排。给你一个整数数组ratings表示每个孩子的评分。你需要按照以下要求,给这些孩子分发糖果: 【1】每个孩子至少分配到1个糖果。 【2】相邻两个孩子评分更高的孩子会获得更多的糖果。 请你给每个孩…...
)
GitHub Copilot X vs. Cursor Pro vs. Tabnine Ultra vs. 通义灵码2.0:2026奇点智能技术大会独家实测数据曝光(附IDE响应延迟毫秒级对比表)
第一章:2026奇点智能技术大会:AI编程助手对比评测 2026奇点智能技术大会(https://ml-summit.org) 在2026奇点智能技术大会上,来自全球12家主流厂商的AI编程助手接受了统一基准测试——包括代码补全准确率、跨文件上下文理解、调试建议有效性…...

从仿真到实战:如何用MATLAB生成的白光干涉信号验证你的测量算法?
从仿真到实战:MATLAB白光干涉信号生成与算法验证全流程指南 在光学测量领域,白光干涉技术因其独特的优势成为表面形貌检测、薄膜厚度测量等精密工程应用的核心手段。然而,实际系统开发中最令人头疼的环节往往不是硬件搭建,而是测量…...

SAP FI模块避坑指南:修改已过账凭证文本时,FB03和BAPI FI_DOCUMENT_CHANGE的权限与风险
SAP FI模块凭证文本修改实战:权限管控与合规操作全景指南 财务凭证作为企业经济活动的法定记录载体,其任何修改行为都直接关联审计合规性与内部控制有效性。在SAP系统中,已过账凭证的文本修改看似简单的技术操作,实则暗藏权限分离…...

迅雷链接在线解密解析工具系统源码_本地化API_开源
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示一、详细介绍 迅雷链接在线解密解析工具系统源码/本地化API/开源 本地化API后无需担心API失效的烦恼,还可以改成加密链接等,自行探索 二、效果展示 1.部分代码 代码如下(示例&am…...

国产化迁移笔记:在龙芯/飞腾的银河麒麟V10中,为OpenJDK 8补全Icedtea-netx插件全记录
国产化迁移实战:在银河麒麟V10中为OpenJDK 8补全Icedtea-netx插件全流程解析 当企业级应用从传统x86架构向国产化平台迁移时,Java Web Start技术的兼容性问题往往成为拦路虎。最近在将某金融系统迁移到龙芯3A5000平台时,我们遇到了一个典型场…...

C# OnnxRuntime 部署 DDColor
说明地址:https://github.com/piddnad/DDColor效果模型信息Model Properties ------------------------- ---------------------------------------------------------------Inputs ------------------------- name:input tensor:Float[1, 3,…...

深度解析MIST显微图像拼接工具:从原理到实战的高效拼接方案
深度解析MIST显微图像拼接工具:从原理到实战的高效拼接方案 【免费下载链接】MIST Microscopy Image Stitching Tool 项目地址: https://gitcode.com/gh_mirrors/mist3/MIST 在生物医学研究、材料科学和病理诊断等领域,科研人员经常面临一个关键挑…...

从HTB CozyHosting靶机渗透实战看SpringBoot应用安全与权限提升
1. 靶机环境初探与信息收集 第一次接触HTB的CozyHosting靶机时,我习惯性地从基础信息收集开始。用nmap快速扫描目标IP(10.10.11.230),发现开放了四个关键端口:22(SSH)、80(HTTP)、8000(HTTP)、8081(未知服务)。这里有个…...

从零开始:Neovim安装与高效配置指南
1. Neovim入门:为什么选择它? 如果你经常和代码打交道,肯定听说过Vim的大名。作为程序员界的"上古神器",Vim以其高效的编辑方式和强大的可定制性闻名。而Neovim则是Vim的现代化分支,它保留了Vim的所有优点&a…...

GitHub汉化插件:5分钟让你的GitHub界面说中文,开发者效率提升40%
GitHub汉化插件:5分钟让你的GitHub界面说中文,开发者效率提升40% 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese …...