深度学习八股文: 模型训练全过程及各阶段的原因
深度学习模型的训练全过程通常包括以下步骤:
-
数据准备: 首先,需要准备用于训练的数据集。数据集应包含输入特征(通常是数值或图像数据)和相应的目标标签。数据通常需要被分为训练集、验证集和测试集,以便评估模型性能。
-
数据预处理: 数据通常需要进行预处理,包括标准化、归一化、缩放、特征工程等。预处理的目的是使数据对模型训练更有利,以及确保数据的一致性和可用性。
-
模型选择和设计: 选择适当的深度学习模型结构,如卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)、变换器(Transformer)等,或设计自定义模型。模型结构应根据任务的需求来确定。
-
初始化模型参数: 初始化模型的权重和偏差(参数)以进行训练。常见的初始化方法包括随机初始化和预训练模型加载。
-
定义损失函数: 选择适当的损失函数来衡量模型预测与实际目标之间的差异。损失函数的选择取决于任务类型,如均方误差(MSE)用于回归任务,交叉熵损失用于分类任务。
-
选择优化器: 选择合适的优化算法,如随机梯度下降(SGD)、Adam、RMSProp等,来更新模型参数以减小损失函数。设置学习率、动量和其他超参数。
-
训练模型: 在训练集上进行模型训练。训练过程中,输入数据通过模型前向传播,计算损失,然后通过反向传播(自动微分)计算梯度,最后使用优化器来更新模型参数。这个过程迭代进行多个周期(epochs)。
-
验证模型: 在验证集上周期性地评估模型性能,以检测过拟合或训练不足的情况。可以监视准确率、损失等指标来衡量模型性能。
-
调整超参数: 根据验证集的性能,可能需要调整超参数,包括学习率、批次大小、模型复杂度等,以改进模型性能。
-
测试模型: 使用独立的测试集来评估最终模型的性能。测试集通常与训练集和验证集是独立的,用于评估模型的泛化能力。
-
模型部署: 当满足性能要求后,可以将模型部署到实际应用中,如移动应用、Web服务、嵌入式系统等。
-
维护和更新: 深度学习模型通常需要定期维护和更新,以适应新的数据、任务需求和性能要求。
这些步骤构成了深度学习模型的训练全过程。训练深度学习模型通常是一个迭代的过程,需要仔细调整和监控,以确保模型能够成功解决任务并具有良好的泛化能力。
以下是一个使用 PyTorch 的简单深度学习训练模型的示例。这个示例展示了如何创建一个小型神经网络来解决二分类问题(如图像分类),并进行数据加载、训练和评估。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms# 1. 数据准备
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)# 2. 定义模型
class SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init()self.fc1 = nn.Linear(32 * 32 * 3, 128)self.fc2 = nn.Linear(128, 64)self.fc3 = nn.Linear(64, 2) # 2类分类def forward(self, x):x = x.view(-1, 32 * 32 * 3) # 将图像展平x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return xmodel = SimpleNN()# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)# 4. 训练模型
for epoch in range(10):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f'Epoch {epoch + 1}, Loss: {running_loss / (i + 1)}')print('Finished Training')# 5. 模型评估
correct = 0
total = 0
with torch.no_grad():for data in trainloader:inputs, labels = dataoutputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy: {100 * correct / total}%')
相关文章:

深度学习八股文: 模型训练全过程及各阶段的原因
深度学习模型的训练全过程通常包括以下步骤: 数据准备: 首先,需要准备用于训练的数据集。数据集应包含输入特征(通常是数值或图像数据)和相应的目标标签。数据通常需要被分为训练集、验证集和测试集,以便评…...

CY3-NHS ester良好的光稳定性介绍1032678-38-8
CY3-NHS ester通常表现出良好的光稳定性,这使得它在长时间的荧光成像和实验中非常有用。以下是关于CY3-NHS ester良好光稳定性的一些介绍: 1.抗光漂白性能:CY3-NHS ester通常对光漂白表现出相对高的抵抗力。这意味着在持续激发下,…...

大厂秋招真题【贪心】美团20230826秋招T2-小美的数组重排
文章目录 【贪心】美团2023秋招-小美的数组重排题目描述与示例题目描述输入描述输出描述示例输入输出 说明 解题思路代码PythonJavaC时空复杂度 华为OD算法/大厂面试高频题算法练习冲刺训练 【贪心】美团2023秋招-小美的数组重排 题目描述与示例 题目描述 小美有两个长度为n…...

UnitTest框架的使用
文章目录 一、UnitTest框架是什么?二、UnitTest核心要素三、TestCase四、TestSuite & TestRunner 一、UnitTest框架是什么? UnitTest框架是python自带的一个单元测试框架,主要用它来做单元测试,它有以下特点: 能…...

软件开发项目文档系列之四如何成功撰写一份引人注目的投标文件
目录 前言1 分析招标文件1.1 投标的基础要求分析1.2 投标重点要求分析1.3 评分标准分析1.4 技术需求分析 2 撰写完整的投标文件2.1 明确文件用途2.2 提供评分指引2.3 内容完整重点突出2.4 重视图表和图示 3 认真检查和经验积累3.1 深入的准备3.2 反复检查3.3 咨询和确认3.4 积累…...

Django设置跨域
1, 安装 pip install django-cors-headers 2, 添加应用 INSTALLED_APPS (...corsheaders,... ) 3, 中间层设置 MIDDLEWARE [corsheaders.middleware.CorsMiddleware,... ] 4, 添加白名单 # CORS CORS_ORIGIN_WHITELIST (127.0.0.1:8080,localhost:8080,www.meiduo.si…...
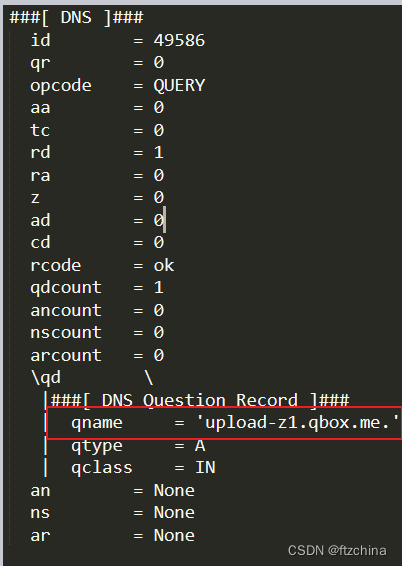
基于Python3的Scapy构造DNS报文
一:DNS协议 DNS(Domain Name System)协议是计算机网络中的一种基础协议,它用于将域名(如www.baidu.com)转换为IP地址(如192.168.0.1),从而实现计算机之间的通信。 DNS 分…...

Jupyter Notebook修改默认浏览器方法
Jupyter Notebook修改默认浏览器方法 Create a Jupyter Notebook Config file jupyter notebook --generate-config打开配置文件.jupyter/jupyter_notebook_config.py找到c.NotebookApp.browser 改成只向自己喜欢的浏览器路径’,这里给出选择google浏览器方法&…...

云计算系统与传统计算系统的比较
随着技术的不断发展,云计算系统逐渐成为了企业和个人使用的主要计算方式之一。然而,很多人对云计算系统与传统计算系统之间的区别和相似之处还存在一些疑惑。本文将以云计算系统和传统计算系统为方向,探讨它们之间的异同点。 首先࿰…...
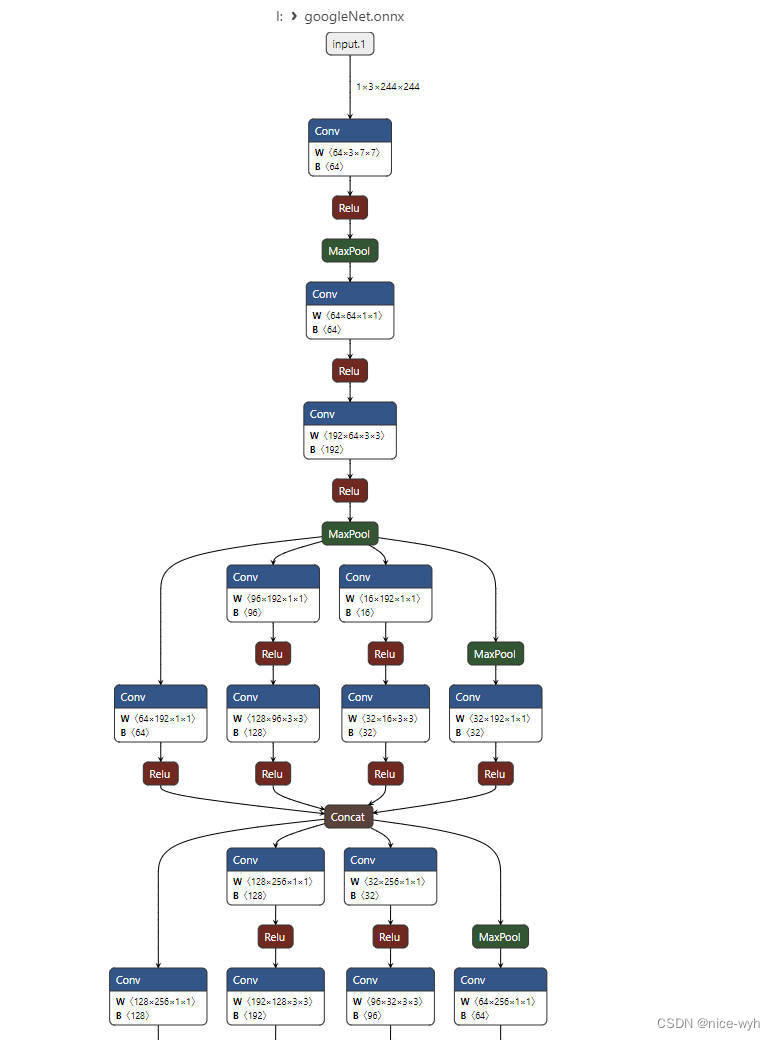
使用GoogleNet网络实现花朵分类
一.数据集准备 新建一个项目文件夹GoogleNet,并在里面建立data_set文件夹用来保存数据集,在data_set文件夹下创建新文件夹"flower_data",点击链接下载花分类数据集https://storage.googleapis.com/download.tensorflow.org/exampl…...

STM32之Bootloader、USB、IAP/DFU下载
STM32 IAP应用开发——通过内置DFU实现USB升级(方式2) STM32 IAP应用开发——通过内置DFU实现USB升级(方式1) STM32程序下载4:通过STM32CubePro-USB下载 STM32程序下载3:通过STM32CubePro-UART下载 STM…...

解决 Element-ui中 表格(Table)使用 v-if 条件控制列显隐时数据展示错乱的问题
本文 Element-ui 版本 2.x 问题 在 el-table-column 上需根据不同 v-if 条件来控制列显隐时,就会出现列数据展示错乱的情况(要么 A 列的数据显示在 B 列上,或者后端返回有数据的但是显示的为空),如下所示。 <tem…...

Android JNI笔记
JNI、java native interface 。可以实现Java和C、C之间的调用。 在Android开发中是必须要掌握的内容。 在应用开发中,编写JNI代码的注册可分为动态注册和静态注册 动态注册: 声明好方法、注意这些签名 在JNI_OnLoad中进行注册。 static const JNINativ…...
方法)
Web开发中会话跟踪的隐藏表单字段(隐藏input)方法
隐藏表单字段是一种会话跟踪方法,通过在HTML表单中添加一个隐藏字段来存储会话标识符。 这样,每次用户提交表单时,会话标识符将与请求一起发送到服务器,以便服务器可以跟踪用户的会话状态。 以下是一个隐藏表单字段的示例&#…...

线性代数相关笔记
线性基 导入 线性基,顾名思义,就是一个包含数字最少的集合,使得原集合中的任何数都能用线性基中的元素表示。 集合中的元素满足一些性质: 原集合中的任意元素都可以用线性基中的若干元素的异或和表示线性基中任意数异或和不为…...
】69 - Android 侧添加支持 busybox telnetd 服务)
【SA8295P 源码分析 (四)】69 - Android 侧添加支持 busybox telnetd 服务
【SA8295P 源码分析】69 - Android 侧添加支持 busybox telnetd 服务 一、下载 busybox-1.36.1.tar.bz2 源码包二、编译 busybox 源码三、将编译后的 busybox 打包编入Android 镜像中系列文章汇总见:《【SA8295P 源码分析 (四)】网络模块 文章链接汇总 - 持续更新中》 本文链接…...
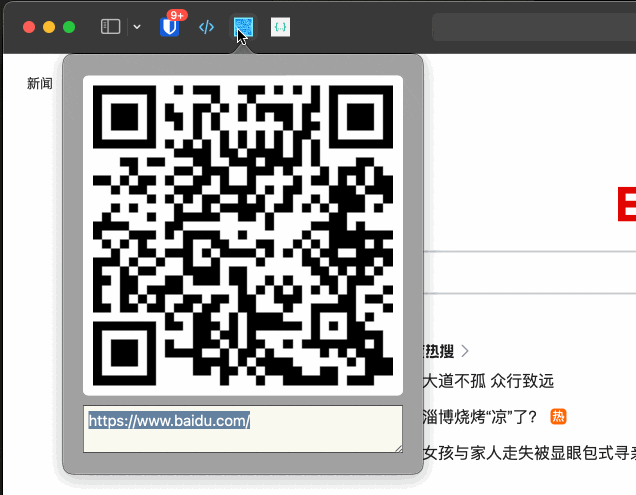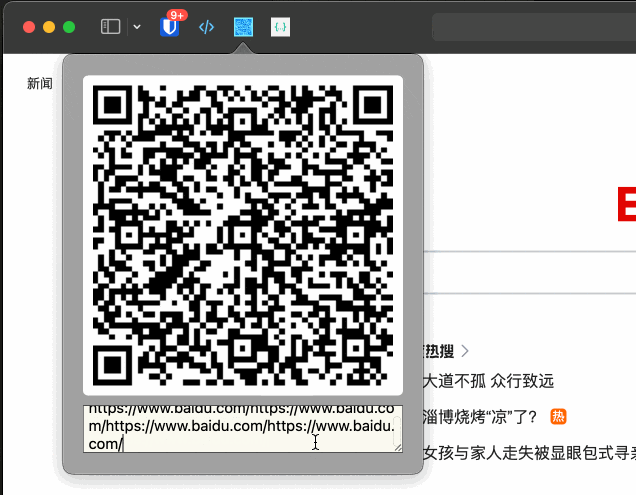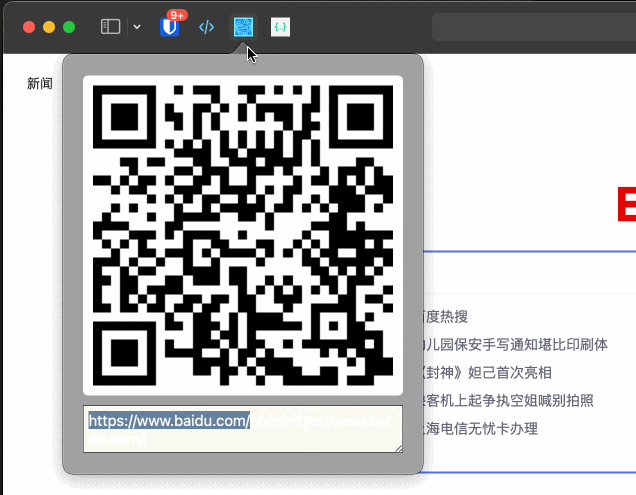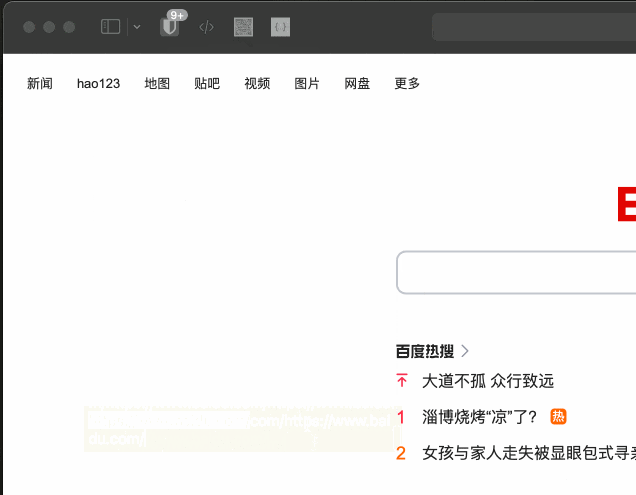
如何开发一个 Safari 插件
本文字数:2493字 预计阅读时间:15分钟 由于常用浏览器是Safari,而Safari浏览器的插件比不上Chrome,所以就有了自己开发常用的Safari插件的想法。 打算开发当前页面生成二维码的Extension,因为网络原因,AirD…...

n皇后问题,不用递归
注释如下: class Solution:def totalNQueens(self, n: int) -> int:if n < 1: # 如果 n 小于 1,直接返回 0return 0count 0 # 初始化解的个数为 0stack [(0, set(), set(), set())] # 初始化一个栈,元素为当前处理的行数、已经放…...
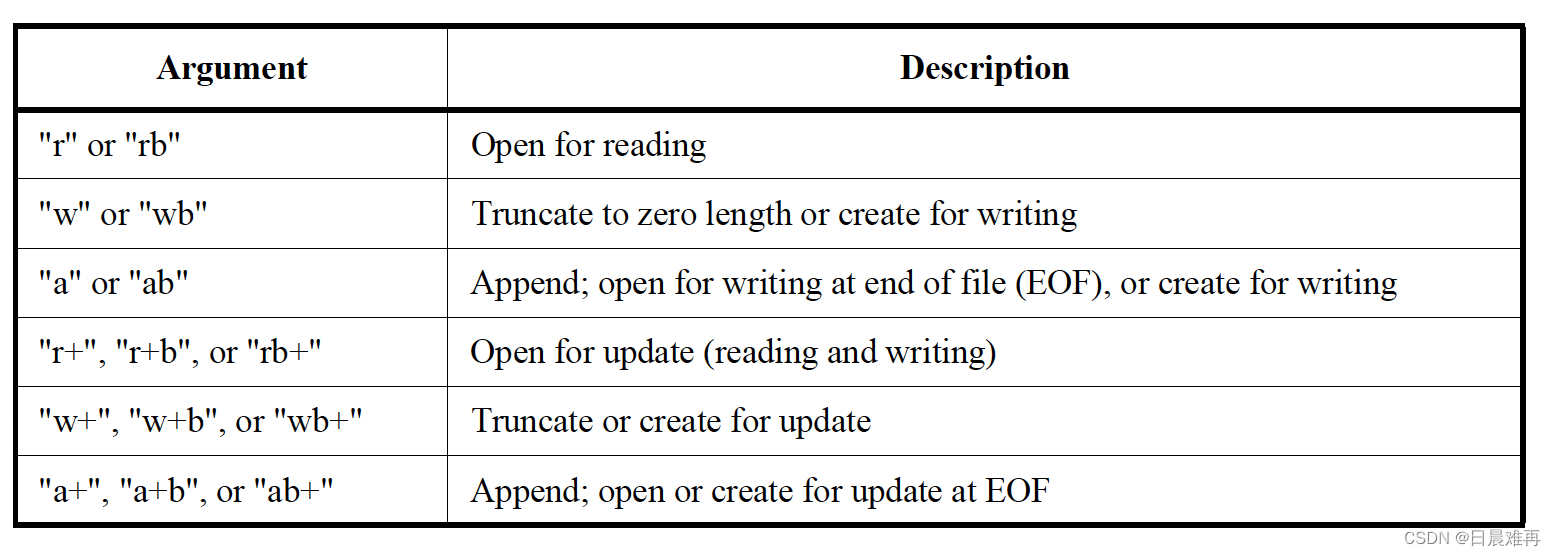
Verilog基础:$fopen和$fclose系统函数、任务的使用
相关阅读 Verilog基础https://blog.csdn.net/weixin_45791458/category_12263729.html?spm1001.2014.3001.5482 $fopen和$fclose是两个用于打开和关闭文件的系统函数、任务。最初,在Verilog-1995标准中,最多只能同时打开32个文件,其所使用的…...

python之字典的用法
python之字典的用法 Python中的字典是一种无序、可变、可迭代的数据类型,它由键值对组成,每个键都映射到一个值。字典在Python中被视为可变对象,这意味着我们可以随时更新、添加或删除字典中的键值对。 以下是一些关于Python字典的基本用法&a…...

Android应用集成:在移动端上传图片调用Ostrakon-VL-8B云服务
Android应用集成:在移动端上传图片调用Ostrakon-VL-8B云服务 你有没有想过,给你的手机应用加上一双“智能眼睛”?用户拍张照片,应用就能看懂图片里的内容,还能回答关于图片的各种问题。听起来像是科幻电影里的场景&am…...
避开这些坑!用Hugging Face Transformers本地部署Qwen2.5-Max的实战记录
避开这些坑!用Hugging Face Transformers本地部署Qwen2.5-Max的实战记录 上周尝试在本地工作站部署Qwen2.5-Max时,我经历了从环境配置到推理测试的全过程,遇到了不少官方文档没提及的"暗礁"。本文将分享实际部署中遇到的7类典型问题…...

小白程序员必看:零基础转型大模型应用开发,薪资涨幅超30%!收藏版学习路径分享
小白程序员必看:零基础转型大模型应用开发,薪资涨幅超30%!收藏版学习路径分享 本文分享了我从传统后端开发转型大模型应用开发的完整学习路径,分为入门启蒙、进阶夯实、核心突破、效率提升和思维升级五个阶段。重点介绍了提示词工…...

[具身智能-363]:Hugging Face LeRobot 详解:像训练语言模型一样训练机器人
LeRobot 是 Hugging Face 于 2024 年 5 月 正式开源的机器人学习框架,专注于模仿学习(Imitation Learning)与视觉-语言-动作基础模型(VLA)。它的核心目标是:降低机器人 AI 的开发门槛,提供从数据…...
 Kubernetes Operator 高可用实现)
KubeBlocks SQL Server(MSSQL) Kubernetes Operator 高可用实现
KubeBlocks SQL Server(MSSQL) K8s Operator 高可用实现 背景 Microsoft SQL Server(MSSQL)是由微软开发的一款关系型数据库管理系统。最初仅支持在 Windows 平台上运行,自 2017 版本起开始支持 Linux 系统,这一变化为 MSSQL 的…...

镜像视界提出3D Spatial Agent:AI正式进入空间时代——从“理解内容”到“计算空间”的范式跃迁
一、开篇:AI的下一个时代,不在模型,而在空间过去十年,人工智能行业迎来了以大模型为核心的爆发式增长浪潮,这一浪潮彻底重塑了机器与数据的交互方式。以OpenAI为代表的前沿机构,凭借突破性的语言模型技术&a…...

FlinkCDC实战:利用skipped.operations参数灵活过滤数据变更事件
1. 为什么需要过滤数据变更事件? 在实际的数据同步场景中,我们经常会遇到这样的需求:只需要处理某几种类型的数据变更,而忽略其他类型的变更。比如有些系统只需要关注新增数据,对更新和删除操作不感兴趣;有…...

一场源码泄露事故,验证了怎样的架构设计?
本文章节选自黄佳老师的《Claude Code 工程化实战》专栏,欢迎同学们去课程中围观全文。 你好,我是黄佳。 2026年 3 月 31 日,有人发现 anthropic-ai/claude-code 的 v2.1.88 npm 包中包含了一个不该出现的文件——cli.js.map。这是一份 sour…...

SQL在分布式数据库中执行JOIN_数据分片与节点交互原理解析
JOIN在分片表上慢是因为默认不广播小表,而是跨节点拉取数据,导致网络请求激增、重复扫描和中间结果膨胀;需确保JOIN字段为相同分片键才能单节点执行。JOIN 在分片表上为什么慢得像卡住?因为大多数分布式数据库(比如 Ti…...

Codesys程序模板:中大型设备模板,快速添加工位只需修改数组
Codesys程序模板 ,中大型设备模板,添加东西只要改数组就行了,底层已经写好 汇川PLC程序 AM600、AM800中型PLC程序模板,伺服轴调用写入底层循环程序,添加轴无需添加程序;整体控制框架标准统一,下…...