MapReduce编程:检索特定群体搜索记录和定义分片操作
文章目录
- MapReduce 编程:检索特定群体搜索记录和定义分片操作
- 一、实验目标
- 二、实验要求及注意事项
- 三、实验内容及步骤
- 附:系列文章
MapReduce 编程:检索特定群体搜索记录和定义分片操作
一、实验目标
- 熟悉MapReduce编程涉及的主要类和接口的含义和用法
- 熟练掌握Mapper类,Reducer类和main函数的编写
- 熟练掌握在本地测试方法
- 熟练掌握集群上进行分布式程序测试
二、实验要求及注意事项
- 给出每个实验的主要实验步骤、实现代码和测试效果截图。
- 对本次实验工作进行全面的总结分析。
- 所有程序需要本地测试和集群测试,给出相应截图。
- 建议工程名,类名或包名等做适当修改,显示个人学号或者姓名
三、实验内容及步骤
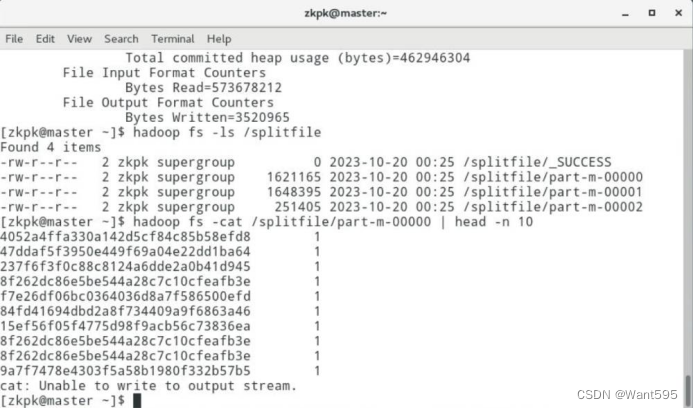
实验任务1:检索特定偏好用户和群体操作:使用mapreduce编程,读取文本文件sogou.500w.utf8,查找搜索过“仙剑奇侠传”用户的uid,利用mapreduce的特性对uid进行去重并输出,实现效果参考图1。
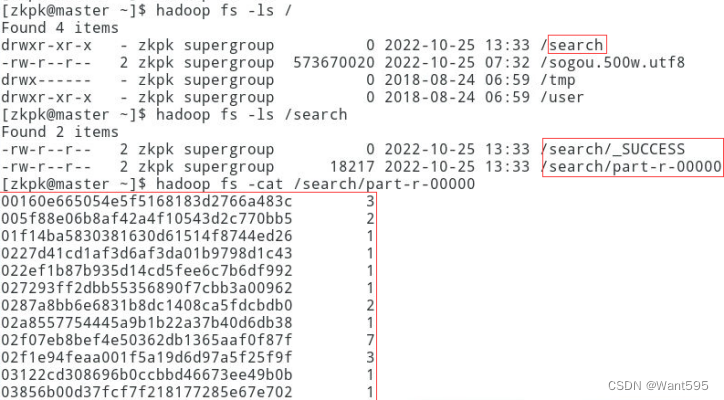
图1 搜索过“仙剑奇侠传”用户的uid及搜索次数输出结果
主要实现步骤和运行效果图:
(1)进入虚拟机并启动Hadoop集群,完成文件上传。
(2)启动Eclipse客户端,新建一个java工程;在该工程中创建package,导入jar包,完成环境配置,依次创建包、Mapper类,Reducer类和主类等;
(3)完成代码编写。
SearchMap
package hadoop;
import java.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.io.*;public class WjwSearchMap extends Mapper<Object, Text, Text, Text>{public void map(Object key, Text value, Context context) throws IOException,InterruptedException{String arr[] = value.toString().split("\t");if(arr != null && arr.length==6){String uid = arr[1];String keyword = arr[2];if(keyword.indexOf("仙剑奇侠")>=0){context.write(new Text(uid), new Text(keyword));}}}
}
SearchReduce
package hadoop;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import java.io.*;public class WjwSearchReduce extends Reducer<Text, Text, Text, IntWritable>{@SuppressWarnings("unused")protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException{int s=0;for(Text word:values){s++;}context.write(key, new IntWritable(s));}
}
SearchMain
package hadoop;
import java.io.IOException;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.fs.*;@SuppressWarnings("unused")
public class WjwSearchMain {@SuppressWarnings("deprecation")public static void main(String[] args) throws IllegalArgumentException,IOException,ClassNotFoundException,InterruptedException{if(args.length != 2 || args == null){System.out.println("please input args");}Job job = new Job(new Configuration(), "WjwSearchMain");job.setJarByClass(WjwSearchMain.class);job.setMapperClass(WjwSearchMap.class);job.setReducerClass(WjwSearchReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true)?0:1);}
}
(4)测试程序,并查看输出结果。
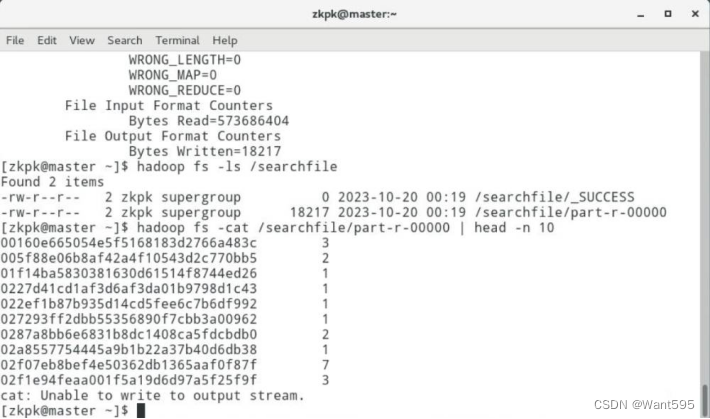
实验任务2:MapReduce自定义分片(Split)操作:使用mapreduce编程,设置mr过程中Map Task读取文件时的split大小。实现效果:

主要实现步骤和运行效果图:
(1)进入虚拟机并启动Hadoop集群,完成文件上传。
(2)启动Eclipse客户端,新建一个java工程;在该工程中创建package,导入jar包,完成环境配置,依次创建包、Mapper类,Reducer类和主类等;
(3)完成代码编写。
SplitMap
package hadoop;
import java.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.io.*;public class WjwSplitMap extends Mapper<Object, Text, Text, IntWritable>{public void map(Object key, Text value, Context context) throws IOException,InterruptedException{String arr[] = value.toString().split("\t");if(arr != null && arr.length==6){String uid = arr[1];String keyword = arr[2];if(keyword.indexOf("电影")>=0){context.write(new Text(uid), new IntWritable(1));}}}
}
SplitMain
package hadoop;
import java.io.IOException;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.fs.*;@SuppressWarnings("unused")
public class WjwSplitMain {@SuppressWarnings("deprecation")public static void main(String[] args) throws IllegalArgumentException,IOException,ClassNotFoundException,InterruptedException{if(args.length != 2 || args == null){System.out.println("please input args");}Job job = new Job(new Configuration(), "WjwSplitMain");job.setJarByClass(WjwSplitMain.class);job.setMapperClass(WjwSplitMap.class);job.setNumReduceTasks(0);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setMinInputSplitSize(job, 256*1024*1024);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true)?0:1);}
}
(4)测试程序,并查看输出结果。
附:系列文章
| 实验 | 文章目录 | 直达链接 |
|---|---|---|
| 实验01 | Hadoop安装部署 | https://want595.blog.csdn.net/article/details/132767284 |
| 实验02 | HDFS常用shell命令 | https://want595.blog.csdn.net/article/details/132863345 |
| 实验03 | Hadoop读取文件 | https://want595.blog.csdn.net/article/details/132912077 |
| 实验04 | HDFS文件创建与写入 | https://want595.blog.csdn.net/article/details/133168180 |
| 实验05 | HDFS目录与文件的创建删除与查询操作 | https://want595.blog.csdn.net/article/details/133168734 |
| 实验06 | SequenceFile、元数据操作与MapReduce单词计数 | https://want595.blog.csdn.net/article/details/133926246 |
| 实验07 | MapReduce编程:数据过滤保存、UID 去重 | https://want595.blog.csdn.net/article/details/133947981 |
| 实验08 | MapReduce 编程:检索特定群体搜索记录和定义分片操作 | https://want595.blog.csdn.net/article/details/133948849 |
| 实验09 | MapReduce 编程:join操作和聚合操作 | https://want595.blog.csdn.net/article/details/133949148 |
| 实验10 | MapReduce编程:自定义分区和自定义计数器 | https://want595.blog.csdn.net/article/details/133949522 |
相关文章:
MapReduce编程:检索特定群体搜索记录和定义分片操作
文章目录 MapReduce 编程:检索特定群体搜索记录和定义分片操作一、实验目标二、实验要求及注意事项三、实验内容及步骤 附:系列文章 MapReduce 编程:检索特定群体搜索记录和定义分片操作 一、实验目标 熟悉MapReduce编程涉及的主要类和接口…...
pytorch 入门 (四)案例二:人脸表情识别-VGG16实现
实战教案二:人脸表情识别-VGG16实现 本文为🔗小白入门Pytorch内部限免文章 参考本文所写记录性文章,请在文章开头注明以下内容,复制粘贴即可 🍨 本文为🔗小白入门Pytorch中的学习记录博客🍦 参…...

数据结构--线性表回顾
目录 线性表 1.定义 2.线性表的基本操作 3.顺序表的定义 3.1顺序表的实现--静态分配 3.2顺序表的实现--动态分配 4顺序表的插入、删除 4.1插入操作的时间复杂度 4.2顺序表的删除操作-时间复杂度 5 顺序表的查找 5.1按位查找 5.2 动态分配的方式 5.3按位查找的时间…...
ChatGPT(1):ChatGPT初识
1 ChatGPT原理 ChatGPT 是基于 GPT-3.5 架构的一个大型语言模型,它的工作原理涵盖了深度学习和自然语言处理技术。以下是 ChatGPT 的工作原理的一些关键要点: 神经网络架构:ChatGPT 的核心是一个深度神经网络,采用了变种的 Tran…...

PostgreSQL 插件 CREATE EXTENSION 原理
PostgreSQL 提供了丰富的数据库内核编程接口,允许开发者在不修改任何 Postgres 核心代码的情况下以插件的形式将自己的代码融入内核,扩展数据库功能。本文探究了 PostgreSQL 插件的一般源码组成,梳理插件的源码内容和实现方式;并介…...

Android常见分区
一、Google官方标准分区 1. Boot分区 包含Linux内核和一个最小的root文件系统(装载到ramdisk中),用于挂载系统和其他的分区并开始Runtime。正如名字所代表的意思(注:boot的意思是启动),这个分区使Android设备可以启动…...

华为鸿蒙4谷歌GMS安装教学
目录 问题描述 参考视频 教学视频1 配套文档 教学视频2 资源包(配套视频1) 设备未经 play 保护机制认证 问题描述 很多国外的最新应用需要再Google商店才能下载比如ChatGPT 华为手机不支持 Google Play 服务的原因主要是由于谷歌服务框架(GMS)未…...
原型设计工具:Balsamiq Wireframes 4.7.4 Crack
原型设计工具:Balsamiq Wireframes是一种快速的低保真UI 线框图工具,可重现在记事本或白板上绘制草图但使用计算机的体验。 它确实迫使您专注于结构和内容,避免在此过程后期对颜色和细节进行冗长的讨论。 线框速度很快:您将产生更多想法&am…...
Nginx Proxy代理
代理原理 反向代理产生的背景: 在计算机世界里,由于单个服务器的处理客户端(用户)请求能力有一个极限,当用户的接入请求蜂拥而入时,会造成服务器忙不过来的局面,可以使用多个服务器来共同分担成…...
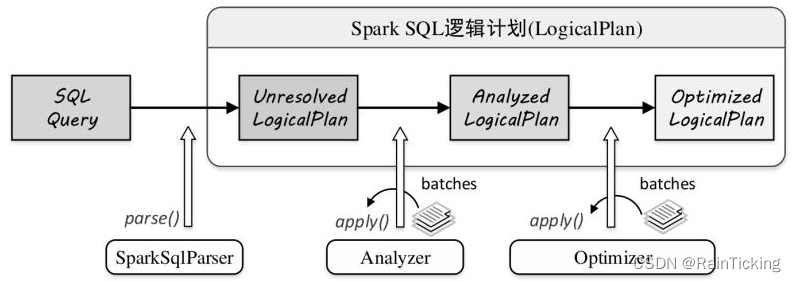
SparkSQL之LogicalPlan概述
逻辑计划阶段在整个流程中起着承前启后的作用。在此阶段,字符串形态的SQL语句转换为树结构形态的逻辑算子树,SQL中所包含的各种处理逻辑(过滤、剪裁等)和数据信息都会被整合在逻辑算子树的不同节点中。逻辑计划本质上是一种中间过…...

Ubuntu 安装 kubectl、kubeadm 和 kubelet
你需要在每台机器上安装以下的软件包: kubeadm:用来初始化集群的指令。 kubelet:在集群中的每个节点上用来启动 Pod 和容器等。 kubectl:用来与集群通信的命令行工具。 kubeadm 不能帮你安装或者管理 kubelet 或 kubectl&#…...

C语言获取文件长度
C语言获取文件长度 文章目录 C语言获取文件长度一、使用标准库方法二、使用Linux系统调用 一、使用标准库方法 #include <stdio.h>long get_file_size(const char * filename ){long size 0;FILE * fp fopen(filename,"rb");if( fp NULL ) {printf("o…...

【面试经典150 | 哈希表】快乐数
文章目录 写在前面Tag题目来源题目解读解题思路方法一:哈希集合判重方法二:快慢指针判重 其他语言python3 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章,欢迎催更…… 专栏内容以分析题目为…...
ETL实现实时文件监听
一、实时文件监听的作用及应用场景 实时文件监听是一种监测指定目录下的文件变化的技术,当产生新文件或者文件被修改时,可实时提醒用户并进行相应处理。这种技术广泛应用于数据备份、日志管理、文件同步和版本控制等场景,它可以帮助用户及时…...
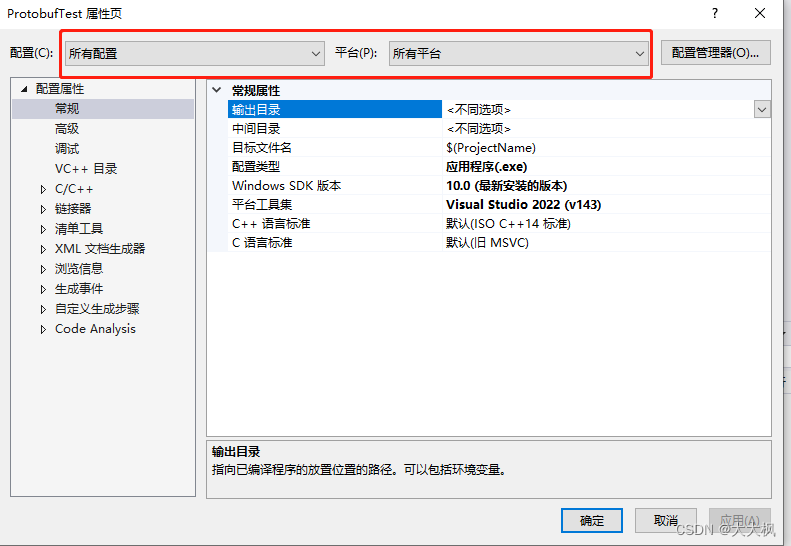
Openssl数据安全传输平台003:Protobuf - 部署
文章目录 Github代码仓库位置一、Windows环境配置生成库文件之后—>参考3.3 配置VS1. 先将平台设置为所有平台2. 配置属性 >> C/C >> 常规 >> 附加包含目录3. 配置属性 >> C/C >> 预处理器 >> 预处理器定义,添加4. 配置属性 >> C…...
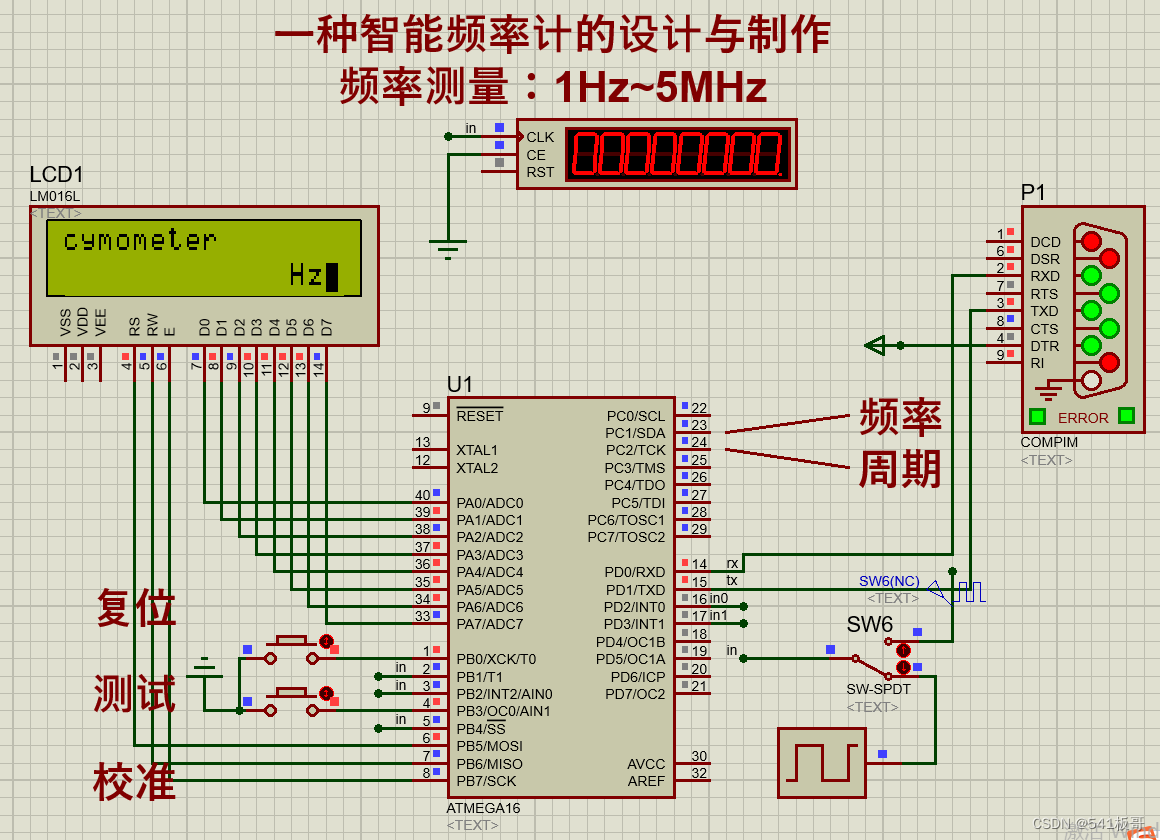
Proteus仿真--一种智能频率计的设计与制作(AVR单片机+proteus仿真)
本文介绍一种基于AVR单片机实现的一种智能频率计Proteus仿真实现(完整仿真源文件及代码见文末链接) 简介 硬件电路主要分为单片机主控模块、频率计模块、LCD1602液晶显示模块以及串口模块 (1)单片机主控模块:单片机…...
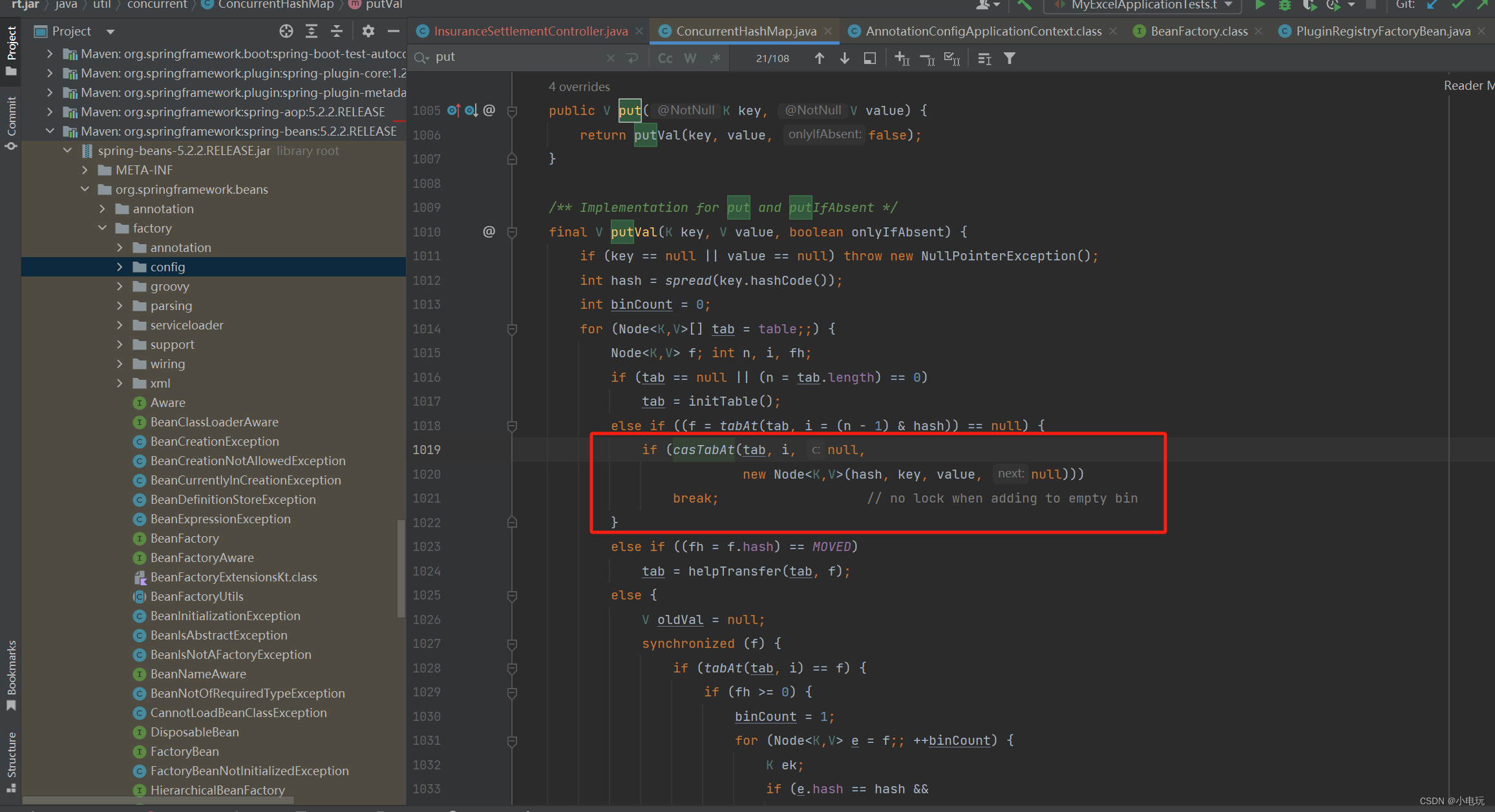
CAS是“Compare and Swap“(比较并交换)
CAS是"Compare and Swap"(比较并交换) 一,介绍 CAS是"Compare and Swap"(比较并交换)的缩写,是一种多线程同步的原子操作。它基于硬件的原子性保证,用于解决并发环境下的…...

前端数据可视化之【series、series饼图配置】配置项
目录 🌟Echarts配置项🌟series🌟饼图 type:pie🌟写在最后 🌟Echarts配置项 ECharts开源来自百度商业前端数据可视化团队,基于html5 Canvas,是一个纯Javascript图表库,提供直观&…...

03.MySQL事务及存储引擎笔记
事务 查看/设置事务 select autocommit; --查看当前数据库的事务状态,1表示开启,0表示关闭 set autocommit 0; --关闭自动事务提交采用关闭自动事务提交我们就可以手动进行事务提交,但是这种设置方式是对整个数据库起作用,一些可…...
input框输入中文时,输入未完成触发事件。Vue中文输入法不触发input事件?
前言 在做搜索输入框时,产品期待实时搜索,就是边输入边搜索,然而对于中文输入法出现的效果,不同的产品可能有不同的意见,有的觉得输入未完成也应该触发搜索。但有的却认为应该在中文输入完成后再触发搜索。我发现在vu…...

5分钟搞定万字提示词的底层方法论是什么?
最近有很多人想问六哥写提示词的方法论是什么?兄弟,你想学写提示词?说实话,大家赚钱都不容易,千万别走弯路去背什么“提示词语法”或“代码公式”。六哥写提示词的核心方法论就四个字:“借势喂养”。高质量…...

TF-IDF BM25 原理及应用
1. 什么是TF-IDFTF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文档频率),是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在…...

gopher-os社区贡献指南:从代码提交到功能开发的完整参与流程
gopher-os社区贡献指南:从代码提交到功能开发的完整参与流程 【免费下载链接】gopher-os A proof of concept OS kernel written in Go 项目地址: https://gitcode.com/gh_mirrors/go/gopher-os gopher-os是一个用Go语言编写的操作系统内核概念验证项目&…...

台达AS系列PLC的Modbus TCP通信C#源代码及生产数据监控与Excel表格生成
台达AS系列PLC modbus TCP网口上位机通信,项目现场使用设备的C#源代码,监控设备每月每天的生产数据并生成Excel表格。最近在工业现场折腾台达AS系列PLC的Modbus TCP通讯,发现这玩意儿的协议实现和常规设备还真有点不一样。项目需求是抓取设备…...

终极DevSecOps安全测试工具大全:OWASP ZAP、Brakeman等实战应用指南
终极DevSecOps安全测试工具大全:OWASP ZAP、Brakeman等实战应用指南 【免费下载链接】awesome-devsecops An authoritative list of awesome devsecops tools with the help from community experiments and contributions. 项目地址: https://gitcode.com/gh_mir…...

2026.04.07随记
1、PyTorch1、dir(模块):查看任意模块的方法2、X.sum(0, keepdimTrue):keepdimTrue保留维度X torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]) # (2,3) X.sum(0, keepdimTrue), X.sum(1, keepdimTrue)…...

5分钟解锁你的首个Gemini AI智能体:全栈开发终极指南
5分钟解锁你的首个Gemini AI智能体:全栈开发终极指南 【免费下载链接】gemini-fullstack-langgraph-quickstart Get started with building Fullstack Agents using Gemini 2.5 and LangGraph 项目地址: https://gitcode.com/gh_mirrors/ge/gemini-fullstack-lang…...
)
Java虚拟线程落地避坑指南(生产环境血泪总结:从Spring Boot 3.3集成到Project Loom异常传播链断裂修复)
第一章:Java 25虚拟线程核心原理与高并发演进全景Java 25正式将虚拟线程(Virtual Threads)从预览特性转为标准特性,标志着JVM并发模型进入轻量级线程时代。虚拟线程由JVM在用户态调度,底层复用有限的平台线程ÿ…...

KIMI AI API本地化部署指南:从技术原理到企业级应用
KIMI AI API本地化部署指南:从技术原理到企业级应用 【免费下载链接】kimi-free-api 🚀 KIMI AI 长文本大模型逆向API【特长:长文本解读整理】,支持高速流式输出、智能体对话、联网搜索、探索版、K1思考模型、长文档解读、图像解析…...

BiliTools终极指南:2026年跨平台B站资源下载解决方案
BiliTools终极指南:2026年跨平台B站资源下载解决方案 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools 你…...