十大算法基础——上(共有20道例题,大多数为简单题)
一、枚举(Enumerate)算法
定义:就是一个个举例出来,然后看看符不符合条件。
举例:一个数组中的数互不相同,求其中和为0的数对的个数。
for (int i = 0; i < n; ++i)for (int j = 0; j < i; ++j)if (a[i] + a[j] == 0) ++ans;
例题1:204. 计数质数
题目 难度:中等
- 方法1:枚举(会超时)
考虑到如果 y 是 x 的因数,那么xy\dfrac{x}{y}yx也必然是 x 的因数,因此我们只要校验 y 或者xy\dfrac{x}{y}yx即可。而如果我们每次选择校验两者中的较小数,则不难发现较小数一定落在[2,x][2,\sqrt{x}][2,x]的区间中,因此我们只需要枚举[2,x][2,\sqrt{x}][2,x]中的所有数即可。
class Solution {
public:bool isPrime(int x) //判断x是否是质数{for (int i = 2; i * i <= x; ++i) {if (x % i == 0) {return false;//不是质数}}return true;//是质数}int countPrimes(int n) {int ans = 0;for (int i = 2; i < n; ++i) {ans += isPrime(i);}return ans;}
};
- 方法2:埃氏筛
如果 x 是质数,那么大于 x 的倍数 2x,3x,…一定不是质数,因此我们可以从这里入手。
class Solution
{
public:int countPrimes(int n) {vector<int> isPrime(n, 1);//一开始全标记为1int ans = 0;for (int i=2; i<n; ++i) {if (isPrime[i]) {ans += 1;//2,3必是质数 for (int j=2*i; j<n; j+=i) {isPrime[j]=0;//i是质数,i的倍数(j)肯定不是质数,赋值为0} }}return ans;}
};
例题2:等差素数列
题目 难度:简单
#include <iostream>
using namespace std;//判断n是否是素数
int check(int n)
{for(int i=2;i<n;i++){if(n%i==0) return 0;//不是素数}return 1;//是质数
}int main()
{int len=0;int gc;//公差int num;//序列的第一个数int ans=0;for(num=2;num<=1000;num++){if(check(num))//检查第一个数字是不是素数{for(gc=1;gc<=1000;gc++)//从1开始枚举公差{for(int j=1;j<1000;j++){if(check(num+j*gc)) ans++;//代表是素数else {ans=0;break;//推出当前for循环}if(ans==9) //从0开始计数,ans=0时就已经有一个{cout<<gc;return 0;}}}}}return 0;
}
例题3:1925. 统计平方和三元组的数目
题目 难度:简单
class Solution {
public:int countTriples(int n) {int ans=0;for(int a=1;a<=n;a++){for(int b=a+1;b<+n;b++){for(int c=b+1;c<=n;c++){if(a*a+b*b==c*c) ans+=1; }}}return ans*2;}
};
例题4:2367. 算术三元组的数目
题目 难度:简单
- 方法1:暴力
class Solution {
public:int arithmeticTriplets(vector<int>& nums, int diff) {int size=nums.size();int num=0;//算术三元组的数目for(int i=0;i<size;i++){for(int j=i+1;j>i&&j<size;j++){if(nums[j]-nums[i]==diff){for(int k=j+1;k>j&&k<size;k++){if(nums[k]-nums[j]==diff) {num=num+1;break;//退出当前for(k)循环}else continue;}} else continue; }}return num; }
};
- 方法2:哈希表,用哈希表记录每个元素,然后遍历 nums,看 nums[j]−diff 和 nums[j]+diff 是否都在哈希表中。
class Solution {
public:int arithmeticTriplets(vector<int>& nums, int diff) {int n = nums.size();unordered_set<int> st;for (int x : nums) st.insert(x);//将nums数组里的值插入到哈希表st中 int ans = 0;for (int i = 0; i < n; i++) {if (st.count(nums[i] +diff) > 0 && st.count(nums[i] + 2*diff) > 0) {ans++;}}return ans;}
};
例题5:2427. 公因子的数目(会)
题目 难度:简单
class Solution {
public:int commonFactors(int a, int b) {int min_data=min(a,b);//找a,b之间的最小值int num;for(int i=1;i<=min_data;i++)//公因数一定小于a和b的最小值{if(a%i==0&&b%i==0)//公因子的定义{++num;}}return num; }
};
例题6:2240. 买钢笔和铅笔的方案数(会)
题目 难度:中等
class Solution {
public:long long waysToBuyPensPencils(int total, int cost1, int cost2) {int total1=total/cost1;//最多买几支钢笔int total2=total/cost2;//最多买几支铅笔long long num=0;for(int i=0;i<=total1;i++){ if(total-i*cost1>=0)//买完钢笔后还能买几只铅笔{int new_total=total-i*cost1;num+=new_total/cost2; num=num+1; } }return num;}
};
例题7:2310. 个位数字为 K 的整数之和(不会)
题目 难度:中等
class Solution {
public:int minimumNumbers(int num, int k) {if(num==0) return 0;//当 num=0时,唯一的方法是选择一个空集合,答案为0for(int i=1;i<=10;i++)//num>0时,我们可以发现最多不会选择超过10个数。//这是因为如果这些数的个位数字为 k,并且我们选择了至少 11个数,由于11*k(10*k+k)的个位数字也为k,那么我们可以把任意的11个数合并成1个,使得选择的数仍然满足要求,并且集合更小。{if(i*k<=num&&(num-i*k)%10==0) return i;//i*k<=num:由于每个数最小为 k,那么这 i 个数的和至少为 i⋅k。如果i⋅k>num,那么无法满足要求。//这 i 个数的和的个位数字已经确定,即为 i*k mod 10。//我们需要保证其与 num 的个位数字相同,这样 num−i⋅k 就是 10 的倍数,我们把多出的部分加在任意一个数字上,都不会改变它的个位数字。} return -1; }
};
二、模拟算法
定义:模拟就是用计算机来模拟题目中要求的操作。
例题8:爬动的蠕虫
题目 难度:简单
#include <iostream>
using namespace std;
#include <algorithm>int main()
{int n,u,d;cin>>n>>u>>d;int x=0;//爬的高度int num=0;//爬的分钟数while (true) { // 用死循环来枚举x += u;num++;//爬一分钟if (x>= n) break; // 满足条件则退出死循环num++;//休息一分钟x -= d;}cout<<num;return 0;
}
例题9:1920. 基于排列构建数组
题目 难度:简单
class Solution {
public:vector<int> buildArray(vector<int>& nums) {int size=nums.size();vector<int> ans(size,0);for(int i=0;i<size;i++){ans[i]=nums[nums[i]];}return ans;}
};
例题10:方程整数解
题目 难度:简单
#include <iostream>
using namespace std;
int main()
{// 请在此输入您的代码for(int i=1;i<1000;i++){for(int j=i;j<1000;j++){for(int k=j;k<1000;k++){if(i*i+j*j+k*k==1000&&i!=6&&j!=8&&k!=30){cout<<min(min(i,j),k);return 0;}}}}return 0;
}
例题11:等差数列
题目 难度:简单
#include <iostream>
using namespace std;
#include <algorithm>
#include <vector>
int main()
{// 请在此输入您的代码int n;cin >> n;vector<int> arr(n);int diff;int ans = n;for (int i = 0; i < n; i++){cin >> arr[i];}sort(arr.begin(), arr.end());//cout << "从小到大排序后:";//for (int i = 0; i < n; i++)//{//cout << arr[i] <<" ";//}//cout << endl;vector<int> diff_vector(n-1);int min_value;for (int j = 0; j < n -1; j++){diff_vector[j] = arr[j + 1] - arr[j];}min_value = *min_element(diff_vector.begin(), diff_vector.end());//cout << min_value << endl;;for (int k = 0; k < n - 1; k++){if (arr[k + 1] - arr[k] != min_value){diff = arr[k + 1] - arr[k];ans += (diff / min_value)-1;}}if (arr[1] == arr[0]) cout << n;else cout << ans;return 0;
}
例题12:方格填数(不会)
题目 难度:简单
#include <iostream>
#include<algorithm>
using namespace std;
int main()
{// 请在此输入您的代码int ans=0;//填数方案int num[]={0,1,2,3,4,5,6,7,8,9};do{if(abs(num[0]-num[1])!=1&&abs(num[0]-num[3])!=1&&abs(num[0]-num[4])!=1&&abs(num[0]-num[5])!=1&&abs(num[1]-num[4])!=1&&abs(num[1]-num[2])!=1&&abs(num[1]-num[5])!=1&&abs(num[1]-num[6])!=1&&abs(num[2]-num[5])!=1&&abs(num[2]-num[6])!=1&&abs(num[3]-num[4])!=1&&abs(num[3]-num[7])!=1&&abs(num[3]-num[8])!=1&&abs(num[4]-num[5])!=1&&abs(num[4]-num[7])!=1&&abs(num[4]-num[8])!=1&&abs(num[4]-num[9])!=1&&abs(num[5]-num[8])!=1&&abs(num[5]-num[9])!=1&&abs(num[5]-num[6])!=1&&abs(num[6]-num[9])!=1&&abs(num[7]-num[8])!=1&&abs(num[8]-num[9])!=1){ans++;}}while(next_permutation(num,num+10));cout<<ans<<endl;return 0;
}
next_permutation 全排列函数
需要引用的头文件:
#include <algorithm>
函数原型:
bool std::next_permutation<int *>(int *_First, int *_Last)
(1)基本格式:
int a[];
do{
//循环体
}while(next_permutation(a,a+n));//表达式
//全排列生成好了next_permutation函数返回0,会跳出while循环。
(2)举例:
#include <algorithm>
#include <string>
#include <iostream>
#using namespace std;
int main()
{string s = "aba";sort(s.begin(), s.end());//排序aabdo {cout << s << '\n';//先执行一次这行,再去执行while的表达式} while(next_permutation(s.begin(), s.end()));//do…while 是先执行一次循环体,然后再判别表达式。//当表达式为“真”时,返回重新执行循环体,如此反复,直到表达式为“假”为止,此时循环结束。
}
//输出:aab
//aba
//baa
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{int a[4] = { 0 }, n;cin >> n;for (int i = 0; i <n; i++){cin >> a[i];}do{for (int i = 0; i <n; ++i){cout << a[i] << " ";}cout << endl;} while (next_permutation(a, a + n));return 0;
}
//输入:4
//2 5 1 3
//输出:
//2 5 1 3
//2 5 3 1
//3 1 2 5
//3 1 5 2
//3 2 1 5
//3 2 5 1
//3 5 1 2
//3 5 2 1
//5 1 2 3
//5 1 3 2
//5 2 1 3
//5 2 3 1
//5 3 1 2
//5 3 2 1
三、递归(Recursion)算法
递归代码最重要的两个特征:结束条件和自我调用。自我调用是在解决子问题,而结束条件定义了最简子问题的答案。
递归的缺点:在程序执行中,递归是利用堆栈来实现的。每当进入一个函数调用,栈就会增加一层栈帧,每次函数返回,栈就会减少一层栈帧。而栈不是无限大的,当递归层数过多时,就会造成栈溢出的后果。
如何优化递归:深度优先搜索(DFS)/记忆化搜索(动态规划的一种)
例题13:剑指 Offer 64. 求1+2+…+n
题目 难度:中等
使用递归会出现的问题:终止条件需要使用 if ,因此本方法不可取。
思考:除了 if还有什么方法?答:逻辑运算符
a&&b
如果a是false,那么就不会继续执行b
a||b
如果a是true,就不会继续执行b
class Solution {
public:int num=0;int sum=0;//总和int sumNums(int n) {//递归num=n;sum+=num;--num;num>=1&&sumNums(num);//也可换成num==0||sumNums(num);return sum;}
};
例题14:231. 2 的幂
题目 难度:简单
class Solution {
public:bool isPowerOfTwo(int n) {if(n==1) return true;//终止条件if(n<=0) return false;bool res=false;if(n%2==0){n=n/2;res=isPowerOfTwo(n);}return res;}
};
例题15:509. 斐波那契数
题目 难度:简单
class Solution {
public:int fib(int n) {//截至条件if(n==0) return 0;if(n==1) return 1;//递推关系return fib(n-1)+fib(n-2);}
};
四、分治(Divide and Conquer)算法
- 定义:就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
- 过程
分治算法的核心思想就是分而治之。大概的流程可以分为三步:分解-> 解决-> 合并。
- 分解原问题为结构相同的子问题。
- 分解到某个容易求解的边界之后,进行递归求解。
- 将子问题的解合并成原问题的解。
- 分治法能解决的问题一般有如下特征:
- 该问题的规模缩小到一定的程度就可以容易地解决。
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质,利用该问题分解出的子问题的解可以合并为该问题的解。
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题
- 区别
(1)递归与枚举的区别
递归和枚举的区别在于:枚举是横向地把问题划分,然后依次求解子问题;而递归是把问题逐级分解,是纵向的拆分。
(2)递归与分治的区别
递归是一种编程技巧,一种解决问题的思维方式;分治算法很大程度上是基于递归的,解决更具体问题的算法思想。
例题16:53. 最大子数组和(不会)
题目 难度:中等
class Solution {
public:struct Status {int lSum, rSum, mSum, iSum;};Status pushUp(Status l, Status r) {//lSum 表示[l,r] 内以 l 为左端点的最大子段和//rSum 表示 [l,r] 内以 r 为右端点的最大子段和//mSum 表示 [l,r] 内的最大子段和//iSum 表示 [l,r] 的区间和//首先最好维护的是iSum,区间 [l,r] 的iSum 就等于左子区间的 iSum 加上右子区间的 iSumint iSum = l.iSum + r.iSum;//对于[l,r]的lSum。存在两种可能,它要么等于左子区间的 lSum,//要么等于左子区间的 iSum加上右子区间的 lSum。二者取大。int lSum = max(l.lSum, l.iSum + r.lSum);//对于[l,r]的 rSum,同理,它要么等于右子区间的 rSum,//要么等于右子区间的 iSum 加上左子区间的 rSum,二者取大。int rSum = max(r.rSum, r.iSum + l.rSum);//当计算好上面的三个量之后,就很好计算[l,r]的mSum了。//我们可以考虑[l,r]的mSum对应的区间是否跨越 m。//它可能不跨越 m,也就是说 [l,r]的 mSum 可能是左子区间的 mSum 和右子区间的 mSum 中的一个//它也可能跨越 m,可能是左子区间的 rSum 和 右子区间的 lSum 求和。三者取大。int mSum = max(max(l.mSum, r.mSum), l.rSum + r.lSum);return (Status) {lSum, rSum, mSum, iSum};}Status get(vector<int> &a, int l, int r) {if (l == r) {return (Status) {a[l], a[l], a[l], a[l]};}int m = (l + r) >> 1;Status lSub = get(a, l, m);Status rSub = get(a, m + 1, r);return pushUp(lSub, rSub);}int maxSubArray(vector<int>& nums) {return get(nums, 0, nums.size() - 1).mSum;}};
五、十大排序算法
术语:
(1)稳定排序:如果 a 原本在 b 的前面,且 a=b,排序之后 a 仍然在 b 的前面,则为稳定排序。
(2)非稳定排序:如果 a 原本在 b 的前面,且 a=b,排序之后 a 可能不在 b 的前面,则为非稳定排序。
(3)原地排序:原地排序就是指在排序过程中不申请多余的存储空间,只利用原来存储待排数据的存储空间进行比较和交换的数据排序。
(4)非原地排序:需要利用额外的数组来辅助排序。
(一)选择排序
- 定义:首先,找到数组中最小的那个元素,其次,将它和数组的第一个元素交换位置(如果第一个元素就是最小元素那么它就和自己交换)。其次,在剩下的元素中找到最小的元素,将它与数组的第二个元素交换位置。如此往复,直到将整个数组排序。这种方法我们称之为选择排序。
- 性质:(1)时间复杂度:O(n2)O(n^2)O(n2) (2)空间复杂度:O(1)O(1)O(1) (3)非稳定排序 (4)原地排序
- 优点:不占用额外的内存空间。缺点:时间复杂度高
//从小到大排序
template<typename T>
void selection_sort(vector<T>& arr)
{for (int i = 0; i < arr.size()-1; i++) {int min = i;for (int j = i + 1; j < arr.size(); j++){if (arr[j] < arr[min]){min = j;//记录最小值}}swap(arr[i], arr[min]);//交换i与min对应的值}
}
例题17:2418. 按身高排序
题目 难度:简单
class Solution {
public:vector<string> sortPeople(vector<string>& names, vector<int>& heights) {for (int i = 0; i < heights.size()-1; i++) {int max = i;for (int j = i + 1; j < heights.size(); j++){if (heights[j] > heights[max]){max = j;//记录最大值}}swap(heights[i],heights[max]);//交换i与max对应的值swap(names[i], names[max]);}return names; }
};
(二)插入排序
- 定义:插入排序(Insertion sort)是一种简单直观的排序算法。它的工作原理为将待排列元素划分为已排序和未排序两部分,每次从未排序的元素中选择一个插入到已排序的元素中的正确位置。从数组第2个(从i=1开始)元素开始抽取元素key,把它与左边第一个(从j=i-1开始)元素比较,如果左边第一个元素比它大,则继续与左边第二个元素比较下去,直到遇到不比key大的元素(arr[j] <= key),然后插到这个元素的右边(arr[j+1] = key)。继续选取第3,4,…n个元素。
如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。 - 性质:(1)时间复杂度:O(n2)O(n^2)O(n2) (2)空间复杂度:O(1)O(1)O(1) (3)稳定排序 (4)原地排序
//从小到大排序
void insertion_sort(int a[], int n)
{for(int i= 1; i<n; i++){ int j= i-1;int key = a[i];while(j>=0 && a[j]>key)//采用顺序查找方式找到插入的位置,在查找的同时,将数组中的元素进行后移操作,给插入元素腾出空间{ a[j+1] = a[j];j--;}a[j+1] = key;//插入到正确位置 }
}
例题18:977. 有序数组的平方
题目 难度:简单
class Solution {
public:vector<int> sortedSquares(vector<int>& nums) {//耗时太长//先平方整个数组for(int i=0;i<nums.size();i++){nums[i]=nums[i]*nums[i];}//插入排序 for(int i=1;i<nums.size();i++){int key=nums[i];int j=i-1;while(j>=0&&key<nums[j])//当key>=nums[]时,把key插到num[i]的右边{nums[j+1]=nums[j];j--;}nums[j+1]=key;//这里j+1是因为上面j--}return nums;}
};
(三)希尔排序
- 定义:希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。 - 性质:(1)时间复杂度:O(nlogn)O(nlogn)O(nlogn) (2)空间复杂度:O(1)O(1)O(1) (3)非稳定排序 (4)原地排序
void shell_sort(vector<int>& arr,int n)
{int key;int j;//初始增量inc为n/2for(int inc=n/2;inc>0;inc/=2)//假设inc=12/2,6/2=3,3/2=1;{//每一趟采用插入排序for(int i=inc;i<n;i++)//搞清楚这里为什么是i++,因为是从inc开始一直到n-1,让inc和0,inc+1和1,inc+2和2……n-1与n-1-inc两两相比较{key=arr[i];for(j=i;j>=inc&&arr[j-inc]>key;j-=inc){arr[j]=arr[j-inc];}arr[j]=key;}}
}
例题19:912. 排序数组
题目 难度:中等
class Solution {
public:vector<int> sortArray(vector<int>& nums) {int n=nums.size();int key;int j;//初始增量inc为n/2for(int inc=n/2;inc>0;inc/=2)//假设inc=12/2,6/2=3,3/2=1;{//每一趟采用插入排序for(int i=inc;i<n;i++)//搞清楚这里为什么是i++,因为是从inc开始一直到n-1,让inc和0,inc+1和1,inc+2和2……n-1与n-1-inc两两相比较{key=nums[i];for(j=i;j>=inc&&nums[j-inc]>key;j-=inc){nums[j]=nums[j-inc];}nums[j]=key;}}return nums;}
};
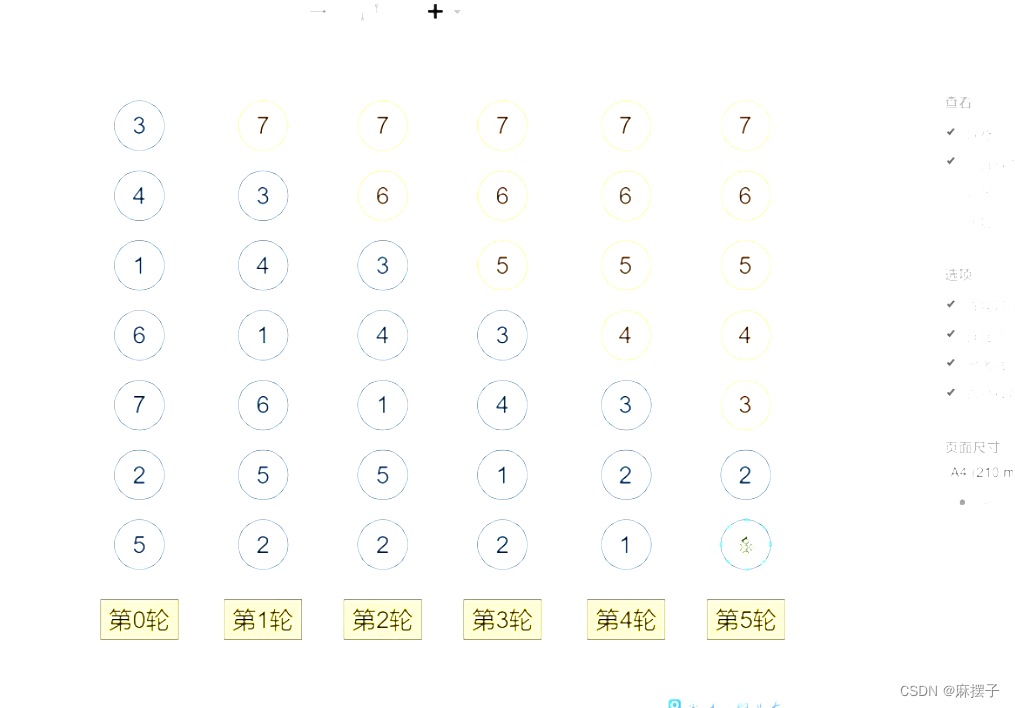
(四)冒泡排序
- 定义:冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
从小到大排序的步骤:
(1)比较相邻的元素。如果第一个比第二个大,就交换他们两个。
(2)对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
(3)针对所有的元素重复以上的步骤,除了数列末尾已经排序好的元素。持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。 - 性质:1、时间复杂度:O(n2)O(n^2)O(n2) 2、空间复杂度:O(1)O(1)O(1) 3、稳定排序 4、原地排序
#include <iostream>
using namespace std;
template<typename T> //整数或浮点数皆可使用,若要使用类(class)或结构体(struct)时必须重载大于(>)运算符
//从小到大排序
void bubble_sort(T arr[], int len) //len是arr的长度
{int i, j;for (i = 0; i < len - 1; i++)//轮数{for (j = 0; j < len - 1 - i; j++)//每一轮要交换几次{if (arr[j] > arr[j + 1]){swap(arr[j], arr[j + 1]);}}}
}
int main() {int arr[] = { 61, 17, 29, 22, 34, 60, 72, 21, 50, 1, 62 };int len = (int) sizeof(arr) / sizeof(*arr);bubble_sort(arr, len);for (int i = 0; i < len; i++)cout << arr[i] << ' ';cout << endl;float arrf[] = { 17.5, 19.1, 0.6, 1.9, 10.5, 12.4, 3.8, 19.7, 1.5, 25.4, 28.6, 4.4, 23.8, 5.4 };len = (float) sizeof(arrf) / sizeof(*arrf);bubble_sort(arrf, len);for (int i = 0; i < len; i++)cout << arrf[i] << ' '<<endl;return 0;
}
(五)计数排序
- 定义:计数排序(Counting sort)是一种线性时间的排序算法。它的工作原理是使用一个额外的计数数组 C,其中数组C中第 i 个元素是待排序数组 A 中值等于 i 的元素的个数,然后根据数组 C 来将 A 中的元素排到正确的位置。计数排序是一种适合于最大值和最小值的差值不是不是很大的排序。
算法的步骤如下:
(1)找出待排序的数组中最大和最小的元素,那么计数数组C的长度为最大值减去最小值+1。
(2)统计数组中每个值为i的元素出现的次数,存入数组C的第i项。
(3)对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)。
(4)反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。 - 性质:(1)时间复杂度:O(n+k)O(n+k)O(n+k) (2)空间复杂度:O(k)O(k)O(k) (3)稳定排序 (4)非原地排序
//a是待排序数组,b是排序后的数组,cnt是额外数组
//从小到大排序
void counting_sort()
{if(a.size()<2) return;//寻找最大元素//int max=a[0];//for(int i=0;i<a.size();i++)//{//if(a[i]>max) max=a[i];//}int max = *max_element(heights.begin(), heights.end());// void *memset(void *str, int c, size_t n) :复制字符 c(一个无符号字符)到参数 str 所指向的字符串的前 n 个字符。//分配一个长度为(max-min+1)的计数数组来存储计数// memset(cnt, 0, sizeof(int)*(max-min+1));//cnt变成全0数组,清零vector<int> count(max+1,0);//下标为0,1,2,……,max//计数for (auto x:a) ++cnt[x];//统计数组中每个值为x的元素出现的次数,存入数组cnt的第x项for (int i = 1; i <= w; ++i) cnt[i] += cnt[i - 1];//统计出现次数,w是cnt的长度for (int i=0;i<len;i++) {b[cnt[a[i]]-1] = a[i];--cnt[a[i]];}//反向填充目标数组,n是数组a的长度
}
例题20:1051. 高度检查器
题目 难度:简单
注意到本题中学生的高度小于等于100,因此可以使用计数排序。
class Solution {
public:int heightChecker(vector<int>& heights) {int len=heights.size();int num=0;//寻找最大元素// int max=a[0];// for(int i=0;i<a.size();i++)// {// if(a[i]>max) max=a[i];// }int max = *max_element(a.begin(), a.end());//计数数组初识化为0vector<int> count(max+1,0);//下标为0,1,2,……,max//计数for(int i=0;i<len;i++){count[heights[i]]++;}//统计计数的累计值for(int i=1;i<max+1;i++){count[i]+=count[i-1];}//创建输出数组expectedvector<int> expected(len);for(int i=0;i<len;i++){expected[count[heights[i]]-1]=heights[i];//count[heights[i]]-1是元素正确的位置count[heights[i]]--;}//找不同的下标数量for(int i=0;i<len;i++){if(heights[i]!=expected[i]) num++;}return num;}
};
相关文章:
十大算法基础——上(共有20道例题,大多数为简单题)
一、枚举(Enumerate)算法 定义:就是一个个举例出来,然后看看符不符合条件。 举例:一个数组中的数互不相同,求其中和为0的数对的个数。 for (int i 0; i < n; i)for (int j 0; j < i; j)if (a[i] …...
)
【PAT甲级题解记录】1018 Public Bike Management (30 分)
【PAT甲级题解记录】1018 Public Bike Management (30 分) 前言 Problem:1018 Public Bike Management (30 分) Tags:dijkstra最短路径 DFS Difficulty:剧情模式 想流点汗 想流点血 死而无憾 Address:1018 Public Bike Managemen…...
SpringCloud————Eureka概述及单机注册中心搭建
Spring Cloud Eureka是Netflix开发的注册发现组件,本身是一个基于REST的服务。提供注册与发现,同时还提供了负载均衡、故障转移等能力。 Eureka组件的三个角色 服务中心服务提供者服务消费者 Eureka Server:服务器端。提供服务的注册和发现…...
 分页)
原生django raw() 分页
def change_obj_to_dict(self,temp):dict {}dict["wxh_name"] temp.wxh_namedict["types"] temp.typesdict["subject"] temp.subjectdict["ids"] temp.ids# 虽然产品表里没有替代型号,但是通过sql语句的raw()查询可以…...

Android 9.0 Settings 搜索功能屏蔽某个app
1.概述 在9.0的系统rom产品定制化开发过程中,在系统Settings的开发功能中,最近产品需求要求去掉搜索中屏蔽某个app的搜索,就是根据包名,不让搜索出某个app., 在系统setting中,搜索功能中,根据包名过滤掉某个app的搜索功能,所以需要熟悉系统Settings中的搜索的相关功能,…...
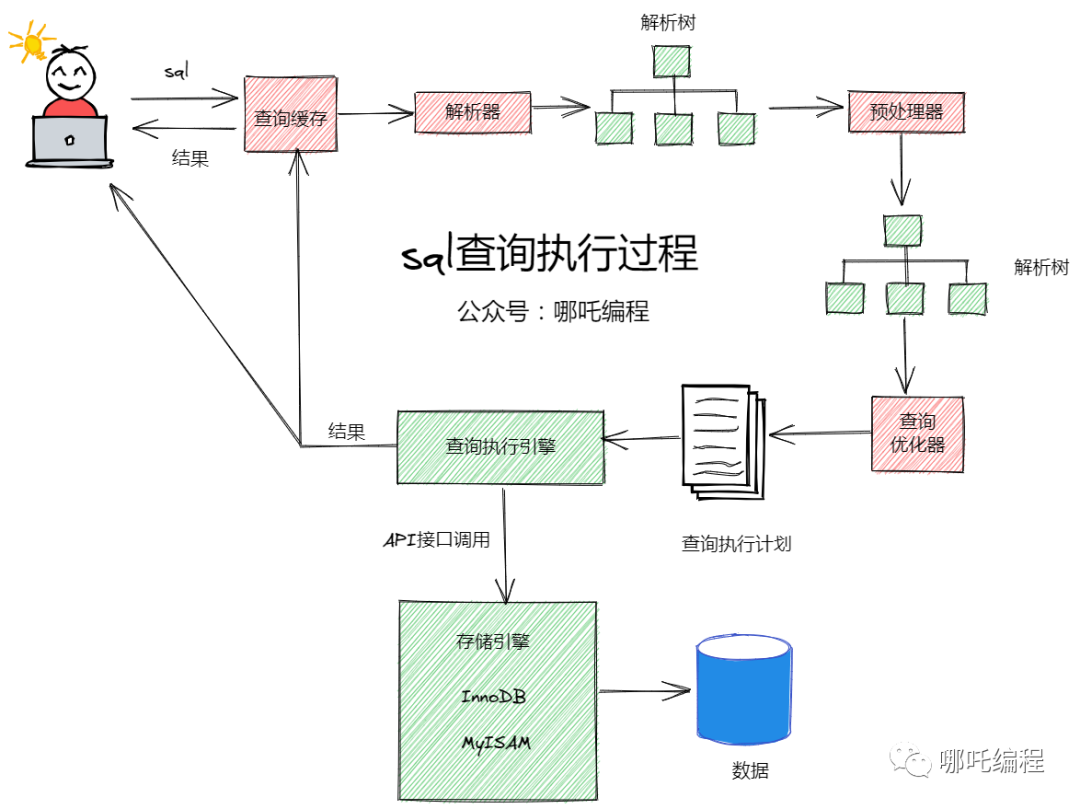
SQL性能优化的47个小技巧,果断收藏!
1、先了解MySQL的执行过程 了解了MySQL的执行过程,我们才知道如何进行sql优化。 客户端发送一条查询语句到服务器; 服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中的数据; 未命中缓存后,MySQL通…...

SE | 哇哦!让人不断感叹真香的数据格式!~
1写在前面 最近在用的包经常涉及到SummarizedExperiment格式的文件,不知道大家有没有遇到过。🤒 一开始觉得这种格式真麻烦,后面搞懂了之后发现真是香啊,爱不释手!~😜 2什么是SummarizedExperiment 这种cla…...

运行Qt后出现无法显示字库问题的解决方案
问题描述:运行后字体出现问题QFontDatabase: Cannot find font directory解决前提: 其实就是移植后字体库中是空的,字没办法进行显示本质就是我们只需要通过某种手段将QT界面中的字母所调用的库进行填充即可此处需要注意的是,必须…...
数据库浅谈之共识算法
数据库浅谈之共识算法 HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是数据库浅谈系列,收录在专栏 DATABASE 中 😜😜😜 本系列阿呆将记录一些数据库领域相关的知识 …...

代码随想录算法训练营 || 贪心算法 455 376 53
Day27贪心算法基础贪心的本质是选择每一阶段的局部最优,从而达到全局最优。刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心。做题的时候,只要想清楚 局部最优 是什么&…...

PMP考前冲刺2.25 | 2023新征程,一举拿证
题目1-2:1.项目经理正在进行挣值分析,计算出了当前的成本偏差和进度偏差。发起人想要知道基于当前的绩效水平,完成所有工作所需的成本。项目经理应该提供以下哪一项数据?A.完工预算(BAC)B.完工估算(EAC)C.完工尚需估算(ETC)D.完工偏差(VAC)2…...

【自然语言处理】Topic Coherence You Need to Know(主题连贯度详解)
Topic Coherence You Need to Know皮皮,京哥皮皮,京哥皮皮,京哥CommunicationUniversityofChinaCommunication\ University\ of\ ChinaCommunication University of China 在大多数关于主题建模的文章中,常用主题连贯度ÿ…...

C++入门:模板
模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。模板是创建泛型类或函数的蓝图或公式。库容器,比如迭代器和算法,都是泛型编程的例子,它们都使用了模板的概念。每个容器都有一个单一的定义,…...
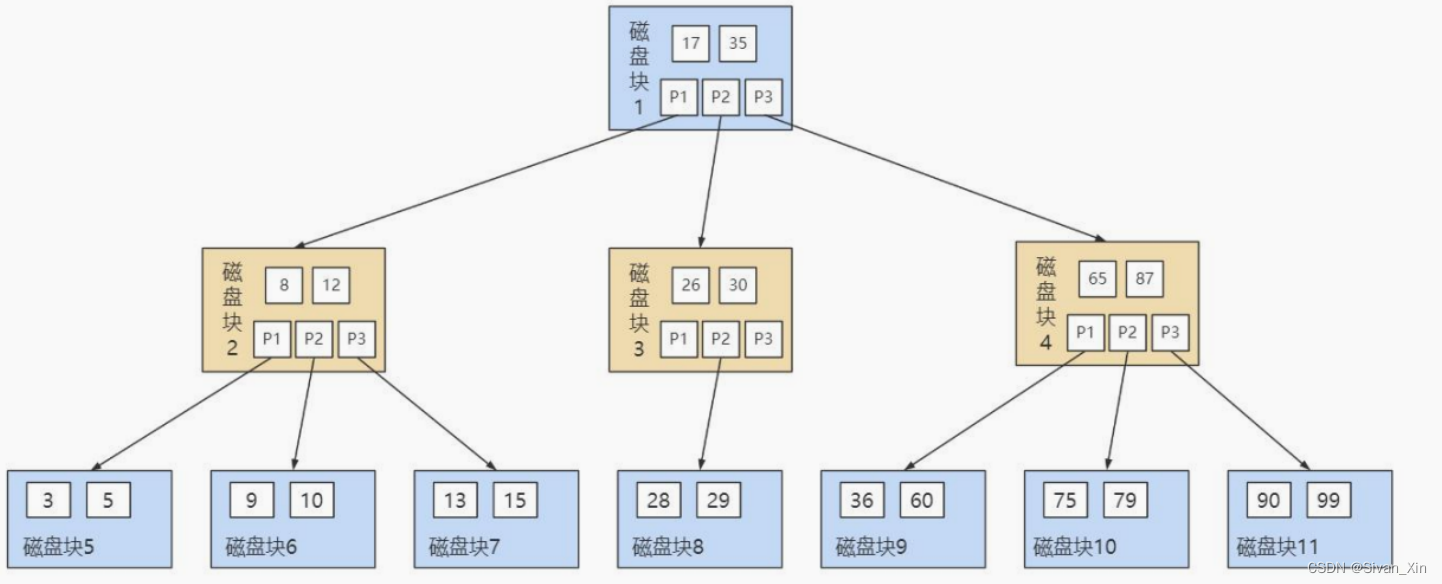
【MySQL】索引常见面试题
文章目录索引常见面试题什么是索引索引的分类什么时候需要 / 不需要创建索引?有什么优化索引的方法?从数据页的角度看B 树InnoDB是如何存储数据的?B 树是如何进行查询的?为什么MySQL采用B 树作为索引?怎样的索引的数…...

【Web逆向】万方数据平台正文的逆向分析(上篇--加密发送请求)—— 逆向protobuf
【Web逆向】万方数据平台正文的逆向分析(上篇--加密发送请求)—— 逆向protobuf声明一、了解protobuf协议:二、前期准备:二、目标网站:三、开始分析:我们一句句分析:先for循环部分:后…...

Amazon S3 服务15岁生日快乐!
2021年3月14日,作为第一个发布的服务,Amazon S3 服务15周岁啦!在中国文化里,15岁是个临界点,是从“舞勺之年”到“舞象之年”的过渡。相信对于 Amazon S3 和其他的云服务15周岁也将是其迎接更加美好未来的全新起点。亚…...

【python】函数详解
注:最后有面试挑战,看看自己掌握了吗 文章目录基本函数-function模块的引用模块搜索路径不定长参数参数传递传递元组传递字典缺陷,容易改了原始数据,可以用copy()方法避免变量作用域全局变量闭包closurenonlocal 用了这个声明闭包…...

AoP-@Aspect注解处理源码解析
对主类使用EnableAspectJAutoProxy注解后会导入组件, Import(AspectJAutoProxyRegistrar.class) public interface EnableAspectJAutoProxy {AspectJAutoProxyRegistrar类实现了ImportBeanDefinitionRegistrar接口中的registerBeanDefinitions()方法,此…...
宝塔搭建实战php悟空CRM前后端分离源码-vue前端篇(二)
大家好啊,我是测评君,欢迎来到web测评。 上一期给大家分享了悟空CRM server端在宝塔部署的方式,但是由于前端是用vue开发的,如果要额外开发新的功能,就需要在本地运行、修改、打包重新发布到宝塔才能实现功能更新&…...
FastASR+FFmpeg(音视频开发+语音识别)
想要更好的做一件事情,不仅仅需要知道如何使用,还应该知道一些基础的概念。 一、音视频处理基本梳理 1.多媒体文件的理解 1.1 结构分析 多媒体文件本质上可以理解为一个容器 容器里有很多流 每种流是由不同编码器编码的 在众多包中包含着多个帧(帧在音视…...
)
实战对比:用直方图均衡化与CLAHE拯救你的背光/过曝照片(附Python完整代码)
拯救逆光废片:直方图均衡化与CLAHE的实战效果对比每次旅行回来整理照片时,总会有几张因为光线问题几乎要删除的废片——要么是逆光下的人脸黑得看不清五官,要么是天空过曝失去所有云层细节。这些照片往往记录着重要时刻,直接删除实…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

WorkshopDL终极指南:无需Steam客户端也能轻松下载创意工坊模组
WorkshopDL终极指南:无需Steam客户端也能轻松下载创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在GOG或Epic Games Store购买了游戏࿰…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...

从零开始构建个人知识库:kepano-obsidian笔记模板完整指南
从零开始构建个人知识库:kepano-obsidian笔记模板完整指南 【免费下载链接】kepano-obsidian My personal Obsidian vault template. A bottom-up approach to note-taking and organizing things I am interested in. 项目地址: https://gitcode.com/gh_mirrors/…...

鼎讯AM-601光纤熔接机:交通通信建设与维护的可靠伙伴
在铁路、高速公路等交通基础设施的智能化建设中,稳定高效的光纤网络是指挥调度、安全监控等核心系统运行的生命线。鼎讯AM-601光纤熔接机,作为一款专为严苛环境设计的六马达便携式熔接设备,正成为保障这些关键通信链路畅通无阻的可靠选择。无…...

长期使用Taotoken Token Plan套餐带来的成本节约感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐带来的成本节约感受 1. 项目背景与成本挑战 我们团队负责一个持续进行文本分析与内容生成的内部…...

三招识别“纪律高危”学生?K-Means聚类助你构建精准考勤画像
助睿实验3 - 学生用户画像 - 考勤主题扩展标签构建第一部分:实验背景1.1实验目的本实验旨在基于已完成的学生考勤主题标签表,掌握使用K-Means聚类算法对学生考勤行为进行自动分群的核心技能。具体任务包括:通过迟到、早退、请假、校服违规次数…...

量子机器学习实战:从QSVM到QNN的构建、优化与避坑指南
1. 量子机器学习实战:从理论到落地的核心挑战量子机器学习(QML)听起来像是科幻小说里的概念,但作为一名在量子计算和机器学习交叉领域摸爬滚打了多年的从业者,我可以负责任地说,它已经从一个纯粹的学术构想…...